基于高阶相关聚类的脱机手写文本行分割
2017-06-01殷亚林刘爱民周祥东
殷亚林, 刘爱民, 周祥东
(1.江汉大学 数字媒体技术系, 武汉 430056; 2.华中师范大学 实验室与设备处, 武汉 430079;3.中国科学院 绿色智能技术研究院, 重庆 400714)
基于高阶相关聚类的脱机手写文本行分割
殷亚林1*, 刘爱民2, 周祥东3
(1.江汉大学 数字媒体技术系, 武汉 430056; 2.华中师范大学 实验室与设备处, 武汉 430079;3.中国科学院 绿色智能技术研究院, 重庆 400714)
从手写文档图像中提取出文本行是文档分析的一个重要预处理步骤,但是由于手写文本行之间通常行方向不平行,甚至存在着交叠和弯曲,所以它仍然是一个具有挑战性的问题. 针对该问题,提出了一种基于高阶相关聚类的脱机中文手写文本行的分割算法.首先,使用连通部件构成一个文档超图,然后,在学习所得的相似性度量准则的约束下,通过高阶相关聚类算法将连通部件对标记为属于或者不属于同一文本行;最后,使用union-find算法将连通部件连接成为不同的文本行.该算法在HIT-MW脱机手写数据库上的803幅文档上取得了较好的效果,召回率99.05%,错误率为1.96%.
手写文本行分割; 高阶相关聚类; 超图
文本行分割是文档分析的一个重要预处理步骤,它是字符分割,字符串识别和文档检索等一系列文档分析任务的基础.印刷文档文本行分割的难点在于它复杂的版面结构和低劣的图像质量;而手写文档文本行分割的难点来自于手写文档书写随意,不存在明显易于分割的版式特点.例如,印刷文档的文本行都是笔直而且相互平行的,但是手写文本行基本都存在不同程度的弯曲,而且行与行之间的空隙也不明确,甚至存在严重的重叠和粘连.因此,对手写文档进行文本行分割要比对印刷体文档进行文本行分割要难的多,大量成熟的印刷文档的文本行分割算法在手写文档上基本失去了作用.
近年来,很多研究者就手写文本行分割展开了深入的研究,并提出了一系列的解决方法.这些方法从解决问题的策略上可以分为3大类:自顶向下的方法、自底向上的方法和混合的方法.基于自顶向下的策略方法的主要思路是依照一定的规则将文档不断地细分为文本块、段落、直至文本行.这类方法包含基于投影(projection-profile)分析的方法[1]和基于蓄水池(water reservoir)的方法[2].自顶向下策略的分割方法虽然在文本行比较平直规则的图像上效果较好,但是在文本行存在严重的交叠和粘连的情况下性能会大幅下降.基于自底向上策略的方法可以看成是一类基于聚类的方法,在该策略下一些文档图像的基本组成部件(比如:像素,连通部件)在预定义的相似性度量的约束下聚类为文字,文本行,甚至文本段落.基于K近邻连通部件聚类的方法[3]、基于拖尾效应(smearing)的方法[4]、基于霍夫(Hough)变换的方法[5]和基于最小生成树聚类的方法[6]都是这一类算法的典型代表.基于自底向上策略方法的优点是能够较好的分割出弯曲,倾斜的文本行,但是它们的效果也受制于聚类时所利用的各种启发式规则、经验参数和聚类算法.基于混合策略的方法是采用不同的融合策略将多种自顶向下或者自底向上的方法结合在一起,以期得到更好的分割结果.文献[7]就是将基于拖尾效应方法和基于最小生成树聚类方法的分割结果通过图的集成聚类框架融合在一起.基于混合策略的方法相对前两种策略的方法,一般能够取得更好的结果,但是该类方法也有一个明显的缺点就是实现复杂、计算量大,而且效果也受制于算法中使用的融合策略.
本文提出了一种有效的采用自底向上策略的脱机手写文本行的分割方法.本方法首先使用连通部件构成一个文档超图,然后在学习所得的相似性度量准则的约束下,通过高阶相关聚类算法[8]将近邻连通部件对标记为属于或者不属于同一文本行;最后使用union-find算法[9]将连通部件连接成为不同的文本行.本方法最大的特点是不需要人工预先指定相似性度量,而是通过结构学习获取聚合相似性度量参数,这样有效地避免了经验参数的影响,大大地增强了算法在不同风格文档上的鲁棒性.
1文本行分割系统框架
文档的逻辑结构可以被描述为一个层次树.处于该层次树最顶端的是文档页面,处于第二层的是一个或多个文本段落,每个文本段落又由处于第三层的多个文本行组成,而每个文本行则包含几个到几十个不等的连通部件,处于最底层的则是构成文字的图像像素点.因此,只要能够方便地提取出该文档层次树中合适的基元,然后根据不同的任务设计出一系列有效的相似性度量准则,最后采用合适的聚类算法将这些基元自下而上的逐步聚合在一起,就能得到任何层次的文档逻辑结构.在本文的算法中,由于连通部件易于检测和数目远远小于文档中的文字像素的数目,所以我们把连通部件作为文档的基本组成结构来参与生成文本行的聚类过程.很显然,如何获取“相似性度量准则”和采用何种“聚类算法”是本文算法的两个关键问题.
一个好的相似性度量准则应该能够使得属于同一文本行的近邻连通部件对在特征空间中有着较近的距离,而不属于同一文本行的近邻连通部件对有着较远的距离.但是人工经验设置的相似性度量准则泛化性能欠佳,只是在其针对的某些类型的文档上拥有很好的性能.因此,本文采用基于结构学习的方法来获取相似性度量参数,这样既能得到更加准确的相似性度量准则,而且在面对不同风格的文档时,只需要添加对应的训练数据就能自动地调整相似性度量的参数,减轻人工干预的负担.
K近邻聚类和最小生成树聚类等算法常常被用来完成连通部件的聚类[3,6],但是我们认为这些算法并没有充分利用连通部件之间已有的信息,因为这类算法聚类时一般只考虑相邻的一对连通部件之间的相似关系,但是文本行分类通常需要综合考虑多个近邻连通部件的关系,才能更好的做出判断.高阶相关聚类正好能够将相邻两个连通部件对和多个近邻的连通部件集合之间的关系融合在一个聚类框架中,能够利用更多的已有信息完成聚类工作.
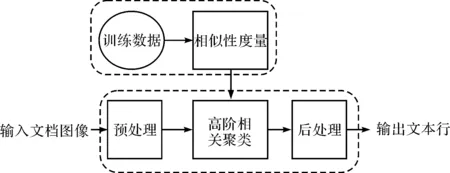
图1 手写文本行分割系统框架图Fig.1 The framework of handwritting textline segmentation system
因此,本文搭建的文本行分割系统包含两个主要的模块,它们分别是相似性度量学习模块和文本行聚合模块,如图1所示.该系统的输入为文档图像,输出为分割出来的文本行连通部件集合.相似性度量学习模块包含在图1上半部分的虚线框内,该模块在已知标记的训练数据集上,通过结构学习的方法学习出相似性度量参数;文本行聚合模块包含在图1下半部分的虚线框内,它包含预处理、高阶相关聚类和后处理3个子模块.其中,预处理子模块主要完成图像二值化,连通部件提取和粘连切分(由于直接提取得到的连通部件会包含文本行之间或者字符之间的笔画粘连,因此需要对文本行连通部件进行过切分来切断粘连笔画[10]);高阶相关聚类子模块主要完成连通部件的聚类,在该模块中首先使用联通部件生成文档超图, 接着将超图边集合分为二阶边集和高阶边集分别提取几何特征,然后采用高阶相关聚类将相邻连通部件对标记为是否属于同一文本行,最后使用union-find将连通部件连接成不同文本行;虽然高阶相关聚类能够得到很好的聚合结果,但是并不完美,得到的候选文本行可能存在“断行”的问题,因此,还需要采用类似文献[6]提出的后处理方法将断行进行拼接.
2文本行聚合算法
文本行聚合算法是本文系统的核心,而该算法又涉及到的4个关键问题:文档超图的构建、高阶相关聚类、几何特征提取和相似性度量学习.因此,本小节将对这些关键问题分别展开详细的论述.
2.1文档超图构建
对二值文档图像提取连通部件之后,得到连通部件的集合为C={ci|ci∈I,i=1,2,…,n}(I为文档中全部文字像素的集合).在此基础上,我们定义一个无向超图(hypergraph)HG=(V,E),其中:V=C为该图的顶点集合,即每个连通部件为该图的一个顶点;E={ej||ej|≥2;j=1,2,…,m}为该图超边(hyperdege)的集合,其中ej表示一条能够连接至少2个顶点的超边;因此,可以将超边划分为两个子集:二阶边集合E2={e∈E||e|=2}以及高阶边集合Eh={e∈E||e|>2},于是有E2∪Eh=E.显然,如果超图中只有二阶边集合,那么这个超图就会退化为一般的图.

图2 构建K+1阶边过程Fig. 2 Constructing K+1 order edge
2.2高阶相关聚类
当完成文档超图构建之后,对超边引入一个二值标签ye,那么对于超边e∈E有
(1)
那么,可以定义一个基于文档C和标签y的判别函数:
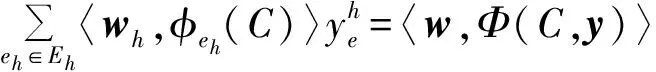
(2)
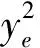
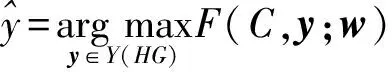
(3)
其中,Y(HG)代表合法分割集合.针对文本分割问题,通过观察还有两个实际的约束关系:1)当一条高阶边被标记为1时,其包含的二阶边关系对应元素的标签必然为1;2)如果高阶边被标记为0,那么其包含的所有二阶边中必然存在标签为0的二阶边.将这两个约束关系表示如下:
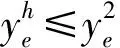
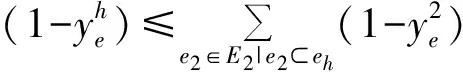
(4)
那么通过文献[11]中给出的线性规划松弛方法(linear programming relaxation)就可以得到上面优化问题的近似解.
2.3特征提取
针对文本行分割问题,构建一个98维的特征向量φe(C),该特征向量由两部分组成:二阶边特征向量φe2(C)和高阶边特征向量φeh(C).

表1 基于相邻连通部件的一元几何特征

表2 基于相邻连通部件的二元几何特征
表1和表2的最后一列表示该值是否需要采用文档连通部件平均高度归一化,该操作主要是为了文字大小不一的文档上的特征归一化到基本相当的尺度.
2.4相似性度量学习

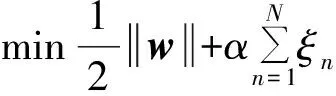
s.t. 〈w, ΔΦ(Cn,y)〉 ≥Δ(yn,y)-ξn,
∀n,y∈Yyn,
ξn≥0, ∀n,
(5)
其中,ΔΦ(Cn,y)=Φ(Cn,yn)-Φ(Cn,y),α>0用于控制模型的复杂度,Δ(yn,y)是损失函数,y由2.2小节的高阶相关聚类获取.由于汉明距离可以很方便地用来统计yn与y错误匹配的个数,所以我们定义损失函数为:
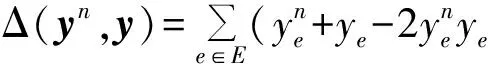
(6)
对于该模型,可以使用文献[12]介绍的切平面算法进行优化求解.
3实验结果
本文使用哈尔滨工业大学提供的HIT-MW脱机手写中文文档数据库[13],该数据库包含由780多人书写的853幅扫描文档,一共包含8677个手写文本行,每副图像大约包含530个连通部件.我们随机选取其中的50幅图像作为训练文档(包含509行),剩下的803幅图像作为测试集(包含8164行).
本文采用检测文本行与标记文本行的像素匹配率在文本行级别评价所有算法的性能.即任何一个检测的文本行和对应的标记文本行共享超过95%的像素,则定义该文本行被正确检测到了[7].因此,召回率为所有正确检测到的文本行与所有标记文本行的百分比;错误检测率为所有错误检测文本行占所有已检测文本行的百分比.
本文提出的基于高阶相关聚类的文本行分割算法用VS2008实现,在IntelCore(TM)i7-3770, 8GRAM的个人计算机上完成一幅图像的文本行分割大约需要1秒左右,其性能如表3所示.实验表明相对于文献[6]算法,由于本文算法可以利用更高阶的上下文信息,所以能取得更好的性能.尽管本文算法比文献[7]算法(一幅图像耗时大约6~8s)的速度快了至少5倍以上,但是检测性能稍逊,这表明本文算法需要寻找更合适的几何特征,在保证算法速度的情况下,进一步提升性能.
图3给出了一些文本分割失败的案例,可以看到,本文的算法还不能很好地处理倾斜度较大的文本行.

表3 测试集上文本行分割结果及对比

图3 错误分割样例Fig.3 Error segmentation samples
4结论
本文提出了一种采用自底向上策略的脱机手写文本行的分割方法.该方法首先在文档内构成超图,然后在学习所得的相似性度量准则的约束下,通过高阶相关聚类算法将近邻连通部件对标记为属于或者不属于同一文本行,最后使用union-find算法将连通部件连接成为不同的文本行.本方法不需要人工预先指定相似性度量,而是通过结构学习获取聚合相似性度量参数;并且与之前的工作相比,可以在保证较高分割精度的同时减少处理时间.接下来的工作中,我们可以寻找更合适的几何特征,在保证算法速度的情况下,进一步提升分割性能.
[1]PALU,DATTAS.SegmentationofBanglaunconstrainedhandwrittentext[C]//7thInt’lConferenceDocumentAnalysisandRecognition.Edinburgh,Scotland,UK,IEEEPress, 2003:1128-1132.
[2]SHIZ,SETLURS,GOVINDARAJUV.Textextractionfromgrayscalehistoricaldocumentimagesusingadaptivelocalconnectivitymap[C]//8thInt’lConferenceonDocumentAnalysisandRecognition.Seoul,Korea,IEEEPress, 2005: 794-798.
[3]O’GORMANL.Thedocumentspectrumforpagelayoutanalysis[J].IEEETransonPatternAnalysisandMachineIntelligence, 1993, 15(11): 1162-1173.
[4]BASUS,CHAUDHURIC,KUNDUM,etal.Textlineextractionfrommulti-skewedhandwrittendocuments[J].PatternRecognition, 2007, 40(6):1825-1839.
[5]LOULOUDISG,GATOSB,PRATIKAKISI,etal.Ablock-basedHoughtransformmappingfortextlinedetectioninhandwrittendocument[C]//10thInt’lWorkshoponFrontiersinHandwritingRecognition.LaBaule,France,IEEEPress, 2006: 515-520.
[6]YINF,LIUCL.Handwrittentextlinesegmentationbyclusteringwithdistancemetriclearning[J].PatternRecognition, 2009, 42(12): 3146-3157.
[7] 黄 亮, 殷 飞, 陈庆虎. 基于图聚类的脱机手写文档图像文本行分割[J]. 华中科技大学学报(自然科学版), 2014, 42(3) : 33-36.
[8]KIMSW,YOOCD,NOWOZINS,etal.Imagesegmentationusinghigher-ordercorrelationclustering[J].IEEETransonPatternAnalysisandMachineIntelligence, 2014, 36(9):1761-1774.
[9]SEDGEWICKR,WAYNEK.Algorithms[M].USA:Addison-WesleyProfessional, 2011.
[10]LIUCL,KOGAM,FUJISAWAH.Lexicon-drivensegmentationandrecognitionofhandwrittencharacterstringsforJapaneseaddressreading[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2002, 24(11):1425-1437.
[11]NOWOZINS,JEGELKAS.Solutionstabilityinlinearprogrammingrelaxations:Graphpartitioningandunsupervisedlearning[C]//Int’lConferenceonMachineLearning.Montreal,Canada,IEEEPress, 2009: 618-622.
[12]TSOCHANTARIDISI,JOACHIMST,HOFMANNT,etal.Largemarginmethodsforstructuredandindependentoutputvariables[J].JournalofMachineLearningResearch, 2005(6):1453-1484.
[13]SUTH,ZHANGTW.Corpus-basedHIT-MWdatabaseforofflinerecognitionofgeneral-purposeChinesehandwrittentext[J].InternationalJournalofDocumentAnalysisandRecognition, 2007, 10(1):27-38.
Offline handwritten text line segmentationbased on high-order correlation clustering
YIN Yalin1, LIU Aimin2, ZHOU Xiangdong3
(1.Department of Digital Media Technology, Jianghan University, Wuhan 430056;2.Laboratory and Equipment Department, Central China Normal University, Wuhan 430079;3.Institute of Green and Intelligent Technology, Chinese Academy of Sciences, Chongqing 400714)
Text line segmentation from handwritten document images is one of important pre-processing steps in document image analysis, however, it remains a challenge because the handwritten text lines are often multi-skewed, curved and overlapped. This paper proposed a novel handwritten text line segmentation method based on high-order correlation clustering. First, a hypergraph was constructed with the nodes corresponding to connected components and the edge connecting at least two connected components. Then under the learned similarity measure, the pairs of connected components were labeled as belonging or not belonging to the same text line. Finally, the connected components were merged into different text lines using union-find algorithm. In experiments on a database with 803 unconstrained handwritten Chinese document images(HIT-MW), the proposed method achieved a correct rate 99.05%, and an error rate of 1.96%.
handwritten text line segmentation; high-order correlation clustering; hypergraph
2016-09-11.
国家自然科学基金项目(61273269).
1000-1190(2017)01-0018-05
TP317.2
A
*E-mail: yinyalin@jhun.edu.cn.
猜你喜欢
杂志排行

华中师范大学学报(自然科学版)的其它文章
- 基于改进ICA算法对云南地区重力固体潮中地震前兆信息的提取与识别
- 2,3-二芳基-1,3-苯并噁嗪的合成及对利什曼原虫CYP51活性的初步研究
- W/Sn/Mg复合氧化物催化合成过氧乙酸的工艺研究
- Fabrication of PZT PCs with nanoporearrays by sol-gel process
- 3种木棉光合特性及碳汇能力研究
- Mechanism exploration of xylitol selenite-inducedapoptosis in a human hepatoma cell lineSMMC-7221 cells using real-time quantitative PCR