自由表述口语语音评测后验概率估计改进方法
2017-06-01许苏魁戴礼荣魏思刘庆峰高前勇
许苏魁,戴礼荣,魏思,刘庆峰,,高前勇
(1. 中国科学技术大学 语音及语言信息处理国家工程实验室,安徽 合肥230027;2. 科大讯飞信息股份有限公司,安徽 合肥230088)
自由表述口语语音评测后验概率估计改进方法
许苏魁1,戴礼荣1,魏思2,刘庆峰1,2,高前勇2
(1. 中国科学技术大学 语音及语言信息处理国家工程实验室,安徽 合肥230027;2. 科大讯飞信息股份有限公司,安徽 合肥230088)
该文研究了两种用于改善深度神经网络声学建模框架下自由表述口语语音评测任务后验概率估计的方法: 1)使用RNN语言模型对一遍解码N-best候选做语言模型得分重估计来获得更准确的识别结果以重新估计后验概率;2)借鉴多语种神经网络训练框架,提出将方言数据聚类状态加入解码神经网络输出节点,在后验概率估计中引入方言似然度得分以评估方言程度的新方法。实验表明,这两种方法估计出的后验概率与人工分相关度分别绝对提升了3.5%和1.0%,两种方法融合后相关度绝对提升4.9%;对于一个真实的评测任务,结合该文改进的后验概率评分特征,总体评分相关度绝对提升2.2%。
自由表述口语;语音评测;后验概率;深度神经网络;RNN语言模型
1 引言
传统的口语评测情境主要是朗读给定的参考文本,在此背景下,参考文本相对于发音矢量的后验概率是公认的最能反映发音质量好坏的测度[1-3]。在前端搭建好识别器后,以参考文本对应的HMM序列为标注对测试语音进行强制对齐(Force Alignment),再通过简化的GOP(Goodness of Pronunciation)算法[4]估计给定HMM序列相对于竞争序列的帧规整对数后验概率。大量实验表明,该后验概率与人工打分具有很高的相关度[5]。
然而,在自由表述的情境下,测试者往往是围绕某一给定主题进行一段限制时长的表述,这时是没有参考文本的。一种直观的做法是以识别器识别的最优结果为参考文本,估计识别结果相对于发音矢量的后验概率以进行发音好坏的评估;这种情境下的后验概率也是有一定效果的[6],但它对于识别结果的依赖性非常高,因为错误识别结果的后验概率是很难反映发音好坏性质的,尤其是发音较好,但却由于引入了语言模型而导致识别错误的情况。因此,提高识别系统的识别率,尤其是纠正因为语言模型导致的识别错误,对自由表述情境下后验概率的估计就显得非常重要。
目前,大多数针对大词汇量连续语流识别任务(Large Vocabulary Continuous Speech Recognition, LVCSR)设计的识别器使用的语言模型都是基于统计的n-gram模型[7],其中n一般为3~4,而且需要采用一些Backoff的平滑操作[8]来缓解语言模型词条在训练集中的稀疏问题。但这样的语言模型看到的历史过于短暂,一个词的语言模型得分仅由其前面2~3个词决定,再远的历史对该词的得分是没有影响的,这显然会大大降低语言模型得分的可靠性。
最近,Mikolov提出了一种新的基于循环神经网络(recurrent neural network, RNN)的语言模型[9],与传统的前馈神经网络(forward neural network)不同的是,这种网络结构将当前时刻隐含层的输出反馈至下一时刻,和下一时刻描述单词信息的输入一起拼成新的输入再进行网络前向传播。这里认为每一时刻隐含层的输出都一定程度上保留了该句话的历史信息,从而在语言模型训练过程中引入了更长的句子历史信息。但由于解码效率问题,该语言模型不适合直接应用在解码器的一遍解码中。我们尝试利用RNN语言模型对使用n-gram语言模型一遍解码出的N-best候选结果[10]进行得分的重估计(rescoring),以rescoring后的第一得分句子作为新的识别结果。文献[9]主要关注混淆度(perplexity)和识别率两个指标,本论文的关注点则是在识别率提升的基础上,希望能更准确的估计后验概率以衡量发音的好坏。实验表明,rescoring后句子识别率相对于一遍解码的1-best有了显著提高,依此估计出的新的后验概率也更适合作为发音质量好坏的度量。
对于第一语言学习者(L1 learner)的口语评测任务——如中国人说普通话,真正出现类似英文表述时发音错误的情形并不多,更多的是方言口音导致的发音质量下降;尤其在自由表述情境下,即兴表述导致难以提前准备,加上考试氛围使测试者感到紧张,日常表述中的方言口音现象可能会更加显著。而传统的后验概率策略,其声学模型一般是使用发音较好的语料训练,即所谓Golden模型[1],这样的模型是不能精确反映发音的方言程度的。为此,我们专门收集了一批真实的方言数据,借鉴多语种(multi-lingual)深度神经网络(Deep Neural NetWork, DNN)训练的思想[11],提出将方言数据经过HTK[10]标准声学模型训练流程聚类后的Tri-phone状态加在解码所需的DNN[12]的输出层,并且用方言数据仅更新方言状态节点和最后一个隐含层的权重以确保主网络的解码性能不受影响;通过引入方言数据似然度得分来衡量发音的方言程度。具体的,当估计后验概率时,如果发现某个音素对应的方言节点似然度得分大于主网络输出节点似然度得分,则认为该音素方言程度可能较严重,则将该方言似然度得分加入后验概率估计公式的分母以评估方言口音程度。
2 DNN框架下后验概率估计方法
在自由表述情境下,我们以识别器一遍解码的结果作为参考文本。对于一遍解码出的音素t,假设其对应的声学观测矢量为O=[o1,o2,…,oN],则t对应的帧规整对数后验概率pp(t|O)估计公式为式(1)。
这里假设所有音素出现的先验概率p(q)相等[1]。一般后验概率分母空间Qt可以选择所有发音音素空间,但研究表明如果以音素t易误发音成的音素来构成集合Qt,放在分母进行计算,则会更加有针对性[13]。
假设对于音素t,Viterbi解码出的最优路径为Θ={s1,s2,…,sN},则lnp(O|t)可近似累和为式(2)。
(2)
这里忽略了HMM的转移概率aij,认为只要aij>0便可完成从状态i到状态j的跳转,但aij本身不参与似然得分的计算。传统声学模型框架下,p(oj|sj)是由高斯混合模型(Gaussian Mixture Model, GMM)来描述的;但对于DNN声学模型,我们有[14]式(3)。
(3)
其中p(sj)是各HMM状态出现的先验概率,可从训练集合中统计得到;p(oj)对于解码而言是常数,解码中可以忽略。p(sj|oj)即为状态sj对应的神经网络输出softmax操作后的得分。从而p(O|t)可由网络输出和状态先验表示为式(4)。
(4)
此即为DNN声学模型框架下似然度得分的计算公式。
式(1)的分母,则是在分子解码确定的时间边界内[15],对每一个q∈Qt,根据q对应的HMM结构Tri-phone状态节点,重复以上Viterbi解码过程以获得q对应的最优状态路径Θq,再根据式(4)把Θq对应的神经网络输出累加以计算所需的p(O|q)。引入DNN声学模型,在训练时间上会有更大需求,一般采用GPU加速神经网络训练,目前实验中对730h语料迭代十次,大约需要三天时间。
当估计出解码得到的每个音素的后验概率后,对一句话内所有音素的后验概率取平均,再对一段语音的所有句子取平均,即可得到该段语音最终的后验概率估计值。
3 RNN语言模型对一遍解码结果的Rescoring
Mikolov提出基于RNN的语言模型[7],其网络结构如图1所示。
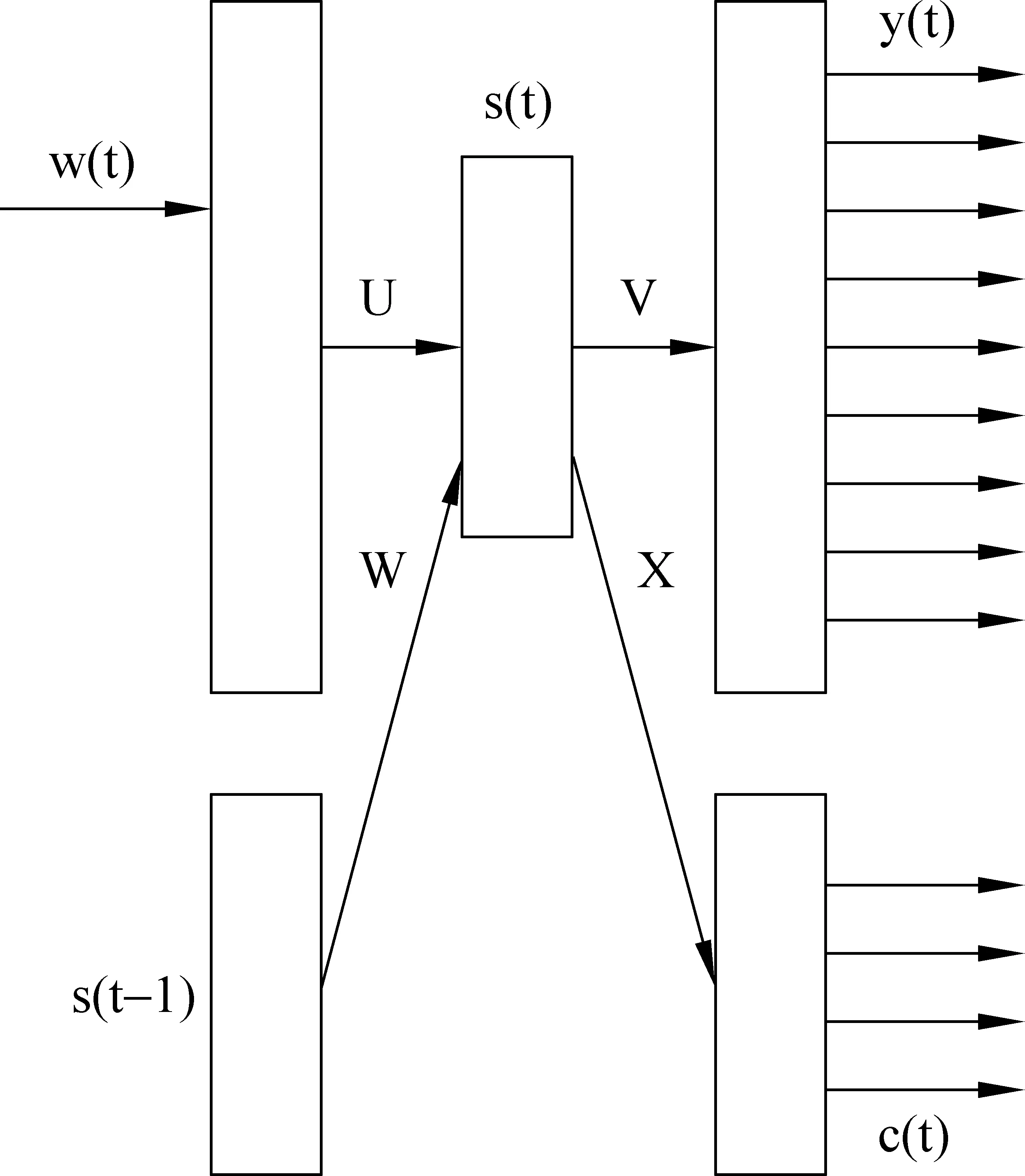
图1 RNN语言模型结构图
其中w(t)是当前输入单词的N维向量表示,N是词典大小,w(t)向量中只有表示该词的那一维是1,其余均为0;s(t)是t时刻隐含层的输出,上一时刻隐含层的输出s(t-1)在t时刻也会作为输入,从而体现网络的循环(recurrent)性。输出y(t)也是N维的向量,其每一维表示词典中的该词在下一时刻出现的概率。具体的公式如下:
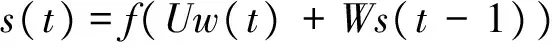
(5)
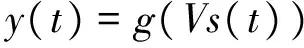
(6)
(7)
注意这里的输出y(t)是做了softmax函数的,从而保证了所有预测词出现的概率都在区间(0,1)内,不会取到0,从而无n-gram模型中复杂的backoff平滑操作。c(t)是为了训练加速而引入的单词聚类[16],设c(t)维度为M,则预先在训练集中根据单词的词频将单词分到M个不同的类,使得每一类中单词的词频之和大致相等;训练时只需要更新c(t)和y(t)中与输入词属于同一类的单词对应的权重即可。网络训练过程采用经典的BPTT(back propagation through time)算法[9],并且采用在线(on-line)更新方式,即每mini-batch个词更新一次而不必一句话所有词的梯度一起更新。
由于解码效率问题,目前是先用n-gram语言模型一遍解码获得每句话的N-best候选集合,再用RNN语言模型对N-best候选做得分rescoring。研究发现RNN语言模型在与n-gram语言模型插值后可以获得更好的性能[17],因此这里rescoring后新的语言模型得分也是二者插值所得,每个候选句子新的得分score计算公式如式(8)所示。
(8)
这里AcScore是句子的声学模型得分,在语言模型Rescoring过程中该部分保持不变;W是整个句子的词个数,C是词惩罚;lmngram和lmRNN分别是n-gram和RNN的语言模型得分,λ是插值系数,lmScale是解码中需要的语言模型得分伸缩因子。这样选取rescoring后得分最大的1-best候选作为新的参考文本,重新估计后验概率;由于语言模型导致的识别错误会有所降低,因此rescoring后估计出的后验概率会更合适。
4. 基于多语种-神经网络模型估计方言得分
多语种深度神经网络(multi-lingual DNN)模型已经被证实在资源受限的小语种情形下是非常有效的[11]。该模型的主要思想是把神经网络的隐含层当作一个通用的特征提取器,而最后一个隐含层和输出层间的权重主要起到分类的作用;另外,认为不同语言之间其特征提取具有较强的共享性,因此我们可以先用大语料的某种语言训练一个较好的DNN,然后对于资源受限的小语种,可以利用大语料训练的DNN隐含层进行特征提取,仅用小语种的数据更新最外层作为分类器的权重,这种方式性能明显优于用小语种语料从网络的随机初始状态开始更新整个网络权重。
我们这里沿用这种思想,使用发音较好的数据训练解码用的DNN,然后使用额外收集到的方言数据作为小语种,其聚类后的状态作为网络的添加节点,其结构如图2所示。
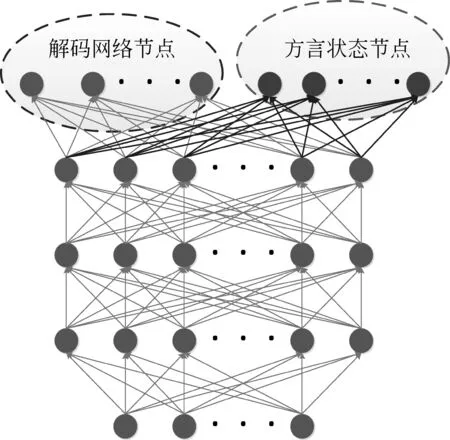
图2 方言得分提取模型结构
这里我们使用方言数据仅更新图2中最外层右边方言状态节点与最后一个隐含层的权重(图2中右边部分权重),其余权重保持不变,这样既可以保证主网络的解码性能不受任何影响,又能保证方言状态节点具有良好的状态分类特性。注意这里softmax操作针对解码节点和方言状态节点是分开来算的。
另一种multi-lingual DNN使用方法是把大语料训练好的整个网络作为一个更好的初始网络,然后用小语料的数据在此基础上更新全部网络参数[18];本文为了确保主网络正常解码性能不受影响,故不采用这种方法。
假设对于观测矢量O,先使用主网络viterbi解码出O对应音素t的状态序列为Θt={s1,s2,…,sN},其似然得分依式(4)计算出为p(O|t),同样得到t的竞争音素得分为p(O|q),q∈Qt;在音素t确定的时间边界内,使用方言状态节点输出同样做Viterbi解码,得到方言状态得分的最优序列为Θd={d1,d2,…,dN},从而估计方言数据的似然度得分如式(9)所示。
(9)
其中p(dj)同样是方言状态在训练集中出现的先验概率,从而得到修正后的后验概率pp(t|O)得分估计如式(10)所示。
(10)
即只有当方言状态节点估计出的似然度得分p(O|d)大于正常解码获得的似然度得分p(O|t)时,p(O|d)才会加入式(1)的分母进行后验概率的估计。这样特殊处理的原因主要是即使对于发音较好的情况,有时候p(O|d)也比p(O|t)小不了太多,这时候如果仍然把p(O|d)加入(1)的分母,可能使后验概率错误地偏低,造成误判;故认为只有当p(O|d)大于p(O|t)时,该音素的发音才有明显的方言口音现象,才会修正其后验概率的估计公式。
5. 实验与分析
5.1 语料库简介
主要介绍实验部分用到的三个数据集: 声学及语言模型训练集合、方言数据集合及发音评测集合。
1) 声学及语言模型训练集合
这里主要使用的是收集到的一批国内普通话水平测试[19]第四题考试的实录语音数据,该题型要求考生在规定的三分钟内,依据给定的主题进行一段自由表述,专家主要从表述的语音标准程度和方言口音程度等方面进行评分,与本论文的研究背景很匹配。我们从中抽取了总得分在80分以上(满分100分)的考生对应的第四题的约730小时数据作为声学模型训练集合,这部分数据的发音水平良好。另外对于总得分在60~100之间的考生,又随机抽取了15小时第四题的数据作为识别率验证的测试集;该测试集与声学模型训练集合没有重合的数据。所有数据都是16kHz采样,16bit量化、没有降噪处理的真实考场数据。
对于语言模型,我们使用大量第四题人工转写的文本作为语料,约464千条句子,分词后共有词语(Token)3.53MB。下文n-gram和RNN语言模型都是使用这批语料训练的。
2) 方言数据集合
我们收集到一批包含合肥、南昌、南京、山东、山西、武汉等地共约250小时的方言数据,将其全部用来训练解码DNN中输出方言状态节点与最后一个隐含层连接的权重。
3) 发音评测集合
我们收集到4 100份有精确人工分标注的第四题真实语音数据,每份语音数据都有两位专家独立评分,分差在3分以内,相关度约为0.8(认为这样的评分比较可靠)。取两位专家的平均分作为实验中最终使用的人工参考分。这里相关度的计算如式(11)所示。
(11)
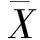
5.2 后验概率基线性能
由于汉语是带调语言,因此声学模型训练部分采用的是39维Mel频率倒谱系数(Mel Frequency Cepstral Coefficients,MFCC)特征加上四维基频特征[20],帧长25ms,帧移10ms。HMM是tri-phone模型,聚类后状态绑定到4 000,这也对应解码DNN的网络输出节点个数。
DNN采用的输入是当前帧的特征与前后扩展5帧拼接,即43×11=473维输入向量,共五个隐含层,每层2 048个节点,激活函数采用sigmoid函数;输出层采用softmax变换,使得输出可以表示为概率的形式且和为1。训练时使用随机梯度下降(stochastic gradient descend, SGD)的方式,并采用mini-batch更新策略,即每次输入1 024个样本,取它们的梯度平均更新;所有数据迭代十次,前三次固定学习率0.2,后七次每次折半。
一遍解码语言模型采用srilm工具[21]训练3-gram模型。在此基线配置下,15小时测试集上字识别率(accuracy, ACC)为84.71%;在发音评测集合上,依式(1)估计出每位考生的后验概率特征,该特征与人工分的相关度为0.535,以此作为后续实验的对比性能。
5.3 RNN语言模型Rescoring性能
RNN语言模型训练采用mikolov提供的开源代码[22],训练语料同n-gram模型。RNN网络中没有依词频对词典裁剪,因此输入w(t)即为词典大小;隐含层节点数500,输出c(t)类别数100。采用BPTT方法训练,每次递归展开数为4,并且每四个词更新一次;所有数据迭代十次,前七次固定学习率0.1,后三次每次都折半。
在rescoring时,一遍解码保留的候选N-best数为50,利用RNN与n-gram插值后的语言模型得分对每个候选best得分重估计,插值系数λ为0.5,声学得分保持不变。使用RNN模型做rescoring带来运算量的增加主要是额外训练了一个RNN语言模型网络,以及一遍解码保留N-best候选造成解码时间的增加。
表1给出在15小时测试集上rescoring之后字识别性能的改进。

表1 RNN Rescoring字识别性能
可见,rescoring 后,字识别率绝对提升了5%以上,识别性能提升较为显著;注意到这里我们没有使用任何额外的资源,只是使用相同的n-gram语言模型训练语料重训了一个RNN网络就获得了这样的提升。这里的增益主要来自于语言模型更好的算分,因此纠正的识别错误可能大多数都是语言模型历史不够长导致的。
接下来使用RNN语言模型对评测集合的4 100份数据每句话的N-best候选做rescoring,使用rescoring后的最大得分句子重新估计后验概率,其与人工分相关度如表2所示。
可见,RNN rescoring后,后验概率与人工分的相关度绝对提升3%以上。虽然这样的提升已经比较显著,但和识别性能的提升——错误率下降了约34%来说,相关度提升还是略显不足。这里分析可能有以下两个原因。

表2 RNN rescoring后验概率与人工分相关度
1) 特殊背景导致识别率提升较大
由于RNN语言模型看到的历史更长,会使整体更有逻辑性的句子获得更高的语言模型得分;而本文背景是中国人说普通话,因此即使存在发音不准确的现象,但表述有逻辑错误的可能性还是较小;这导致N-best中被RNN rescoring后找出的得分最大候选,其逻辑性也可能最强,从而该候选确实是正确识别结果的可能性也较大,从而识别率会有较大提升。
2) 识别率的提升和最终后验概率反映发音好坏并不完全等价
比如考生想说“是”,但其却发音为“si4”,如果这时候识别为“似”则会被判识别正确(假定识别为“似”也完全符合上下文逻辑),据此计算出的后验概率也会较高,然而这却掩盖了考生发音错误的事实!只有将其识别为考生“打算”的发音“shi4”(这里“打算的发音”类似于给定文本语音评测情境下的参考文本),据此“是”计算其后验概率得到一个较低的值,才能正确反映考生“发音确实有误”这个事实。因此,如何有效找出考生“打算”发音的内容而非其真正发音的内容,是后续非常重要的研究计划。
5.4 引入方言得分性能
方言数据的前端处理同基线系统里的声学模型训练特征提取配置。最后也聚类到4 000个状态,加在解码DNN输出层。使用方言数据更新解码DNN方言节点与最外隐含层的权重,SGD的配置与之前DNN也保持一致。这里网络中方言节点权重的更新会增加一些额外的训练时间;解码时网络最外层的矩阵相乘规模也会扩大一倍。依据式(10)调整后验概率的估计方法,性能统计如表3所示。
可以看到,无论是对基线系统直接引入方言得分,还是对rescoring后的系统再引入方言得分(即两种方法融合),相关度都会有进一步绝对1%的提升;特别的,注意到两种方法融合后,相关度相比于最初的基线有绝对4.9%的提升。
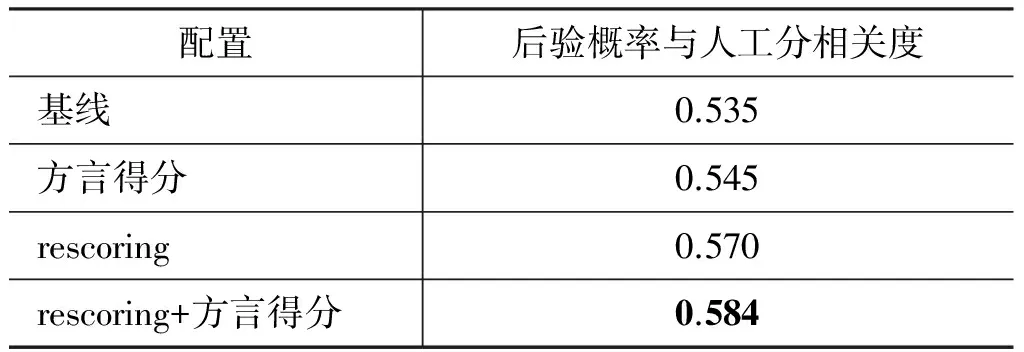
表3 引入方言得分估计的后验概率与人工分的相关度
5.5 总体评分预测性能
为了在普通话水平测试第四题上完成真实的最终预测评分,我们还需要一些针对该具体问题的辅助评分特征。
1) 静音段时长比例
由于自由表述是一种即兴表述,本身难度较大,再加上考场环境,很多考生都会在表述中出现一定的停顿,如果停顿时间过长,专家也会相应扣分,因此把识别结果中的静音段时长占总三分钟的比例作为一维特征。
2) 流畅度
考生表述的流畅程度也是专家评分的关注点,因此我们用每句话包含的总帧数除以该句话内的有效音素个数(去除sil和sp),得到每个音素的平均发音帧数,再按句子取平均;因为音素的平均发音帧数越多,表述可能越不流畅。
3) 发音错误个数
在自由表述这种连续语流背景下,发音检错是一个比较难的任务[15]。这里只是利用一些先验的统计信息,对每个音素按式(1)估计出的后验概率设一个门限,如果后验概率值低于该门限则认为发音错误,统计所有发音错误音素个数N作为一维特征。
辅助特征与人工分相关度在评测集合上统计如表4所示。

表4 辅助特征与人工分相关度
我们在评测集合的4 100份数据集上进行交叉验证来评估总体的评分预测性能。即将数据平均分为十堆,每堆410份数据;每次取其中九堆提取后验概率及上述三个辅助评分特征,并利用这些特征与人工分做线性回归,利用最小二乘法得到回归系数,在余下的一堆数据里利用回归系数和评分特征预测机器分,计算机器分与人工分的相关度;十次交叉验证的相关度取平均,作为最终的机器与人工总体评分相关度性能评估指标,如表5所示。
表5 10折交叉验证评分性能
上述四组对比中,三个辅助评分特征保持不变,仅有后验概率特征的估计方式不同: 基线采用的是4.2节中的估计方式;rescoring和方言得分分别采用4.3和4.4节中的估计方式。可以看到,对于使用rescoring和加入方言得分这两种方式估计的后验概率,最终交叉验证的评分平均相关度相比于基线都有绝对1%的提升;特别的,若将二者融合,则有绝对2.2%的提升;这表明本文提出的关于后验概率估计的改进方法,对评分这样一个具体任务最终性能的提升有一定的改善。
6 总结与展望
本文首先介绍了深度神经网络声学模型框架下自由表述口语语音评测的帧规整对数后验概率特征的一般估计方法,然后提出了两种改进的估计方法。(1)使用RNN语言模型对一遍解码结果的N-best候选做rescoring后再重新估计后验概率; (2)借用multi-lingual神经网络模型框架,提出在后验概率估计中,有选择的引入方言状态节点的似然度得分。实验表明,使用这两种方法估计的后验概率,相比于基线系统,在单一后验概率特征相关度和总体评分相关度上都有一定的性能提升。改进方法估计的后验概率与人工分相关度达到0.584,绝对提升4.9%,总体评分相关度达到0.757,绝对提升2.2%。
后续工作为一是收集更多方言数据以达到更好的覆盖率,因为对于真实情境而言,表述者来自全国各地,各种方言都有;二是对于RNN语言模型训练,将其利用GPU实现并行化,加速矩阵运算操作;三是可以尝试直接用RNN对声学模型建模,相关研究表明RNN声学模型在识别率上相对于DNN又会有进一步的提升[23],而识别率的提升则是整个自由表述口语语音评测任务的基础;最后是希望能结合自然语言处理相关的技术,有效的找出考生表述中“打算”说的内容,以使估计出的后验概率特征与发音好坏任务更好的匹配。
[1] Witt S M. Use of speech recognition in computer-assisted language learning[D]. University of Cambridge, 1999.
[2] 严可, 戴礼荣. 基于音素评分模型的发音标准度评测研究[J]. 中文信息学报, 2011, 25(5): 101-108.
[3] 严可, 魏思, 戴礼荣. 针对发音质量评测的声学模型优化算法[J]. 中文信息学报, 2013 (1): 98-107.
[4] Witt S M, Young S J. Phone-level pronunciationscoring and assessment for interactive language learning[J]. Speech communication, 2000, 30(2): 95-108.
[5] 魏思, 刘庆升, 胡郁, 等. 普通话水平测试电子化系统[J]. 中文信息学报, 2006, 20(6): 89-96.
[6] 严可, 胡国平, 魏思, 等. 面向大规模英语口语机考的复述题自动评分技术[J]. 清华大学学报 (自然科学版), 2009, 1: 1356-1362.
[7] Manning C D. Foundations of statistical natural language processing[M]. MIT press, 1999:194-234.
[8] Goodman J T. A bit of progress in language modeling[J]. Computer Speech & Language, 2001, 15(4): 403-434.
[9] Mikolov T. Statistical language models based on neural networks[D]. Brno University of Technology, 2012.
[10] Young S,Evermann G, Gales M, et al. The HTK book (for HTK version 3.4)[J]. Cambridge University Engineering Department,2006,2(2): 2-3.
[11] Huang J T, Li J, Yu D, et al. Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers[C]//Proceedings of the 2013 IEEE International Conference on. IEEE, 2013: 7304-7308.
[12] Dahl G E, Yu D, Deng L, et al.Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J]. Audio, Speech, and Language Processing, IEEE Transactions on, 2012, 20(1): 30-42.
[13] 刘庆升, 魏思, 胡郁, 等. 基于语言学知识的发音质量评价算法改进[J]. 中文信息学报, 2007, 21(4): 92-96.
[14] Bourlard H A, Morgan N. Connectionist speech recognition: a hybrid approach[M]. Springer Science & Business Media, 1994.
[15] 魏思. 基于统计模式识别的发音错误检测研究[D].中国科学技术大学博士学位论文, 2008.
[16] Mikolov T, Kombrink S, Burget L, et al. Extensions of recurrent neural network language model[C]//Proceedings of Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on. IEEE, 2011: 5528-5531.
[17] Mikolov T, Deoras A, Kombrink S, et al. Empirical Evaluation and Combination of Advanced Language Modeling Techniques [C]//Proceedings of the Interspeech. 2011 (s 1): 605-608.
[18] Thomas S, Seltzer M L, Church K, et al. Deep neural network features and semi-supervised training for low resource speech recognition[C]//Proceedings of Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013: 6704-6708.
[19] 国家语言文字工作委员会普通话培训测试中心.普通话水平测试实施纲要[M].北京: 商务印书馆,2004.
[20] Boersma P. Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound[C]//Proceedings of the institute of phonetic sciences. 1993, 17(1193): 97-110.
[21] Stolcke A. SRILM-an extensible language modeling toolkit[C]//Proceedings of the Interspeech. 2002; 901-904.
[22] Mikolov T, Kombrink S, Deoras A, et al. RNNLM-Recurrent neural network language modeling toolkit[C]//Proceedings of the 2011 ASRU Workshop. 2011: 196-201.
[23] Graves A, Mohamed A R, Hinton G. Speech recognition with deep recurrent neural networks[C]//Proceedings of the Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013: 6645-6649.
Improved Posterior Probability Estimation Methods forthe Freely-Spoken Speech Evaluation
XU Sukui1, DAI Lirong1, WEI Si2, LIU Qingfeng1,2, GAO Qianyong2
(1. National Engineering Laboratory of Speech and Language Information Processing,University of Science and Technology of China, Hefei,Anhui 230027, China;2. Anhui USTC iFlytek Co., Ltd., Hefei,Anhui 230088, China)
Two methods under the deep neural network acoustic modeling framework are proposed to improve the estimation of posterior probability for evaluation of pronunciation of freely-spoken speech: 1) the posterior probability is re-estimated with more accurate recognition results by employing RNN language model to re-score the N-best candidates produced from the first decoding process; 2) the influence of dialect to posterior probability is taken into account by involving likelihood scores produced by dialect clustered nodes added to deep neural network acoustic model which is re-trained as a multi-lingual style. Experimental results show that these methods increase the correlation (between posterior probabilities and human scores) for 3.5% and 1.0% respectively, and the combination of these two methods achieves 4.9% increase. In a real evaluation task, a 2.2% absolute improvement is observed in correlation between machine scores and human scores.
freely spoken speech; pronunciation quality evaluation; posterior probability; deep neural network; RNN language model

许苏魁(1991—),硕士研究生,主要研究领域为计算机辅助语言学习。E⁃mail:xskui@mail.ustc.edu.cn戴礼荣(1962—),教授,博士生导师,主要研究领域为语音识别、语音合成、基于内容的音视频检索等。E⁃mail:lrdai@ustc.edu.cn魏思(1981—),博士,高级工程师,主要研究领域为中英文语音评测,语种识别,语音识别,离线手写识别,自然语言处理等。E⁃mail:siwei@iflytek.com
2015-06-23 定稿日期: 2015-11-06
国家自然科学基金(61273264)
1003-0077(2017)02-0212-08
TP391
A
