多语种文本图像中的文字语种辨识方法的研究
2017-06-01朴明姬崔荣一
朴明姬,崔荣一
(延边大学 计算机科学与技术学院 智能信息处理研究室,吉林 延吉133002)
多语种文本图像中的文字语种辨识方法的研究
朴明姬,崔荣一
(延边大学 计算机科学与技术学院 智能信息处理研究室,吉林 延吉133002)
本文针对汉字、朝鲜文字和英文单词混合的文本图像提出了基于主成分分析技术以文字为单位进行文种辨识的方法。首先,通过主成分分析方法构造特征空间,并且把分割的文字映射到此空间得到重构图像;其次,计算原图像和重构图像的水平和垂直方向直方图的相对熵;最后,根据原图像和重构图像之间的欧式距离和相对熵来判别文字语种。实验表明,本文提出的方法在没有分割错误的情况下,能获得99.78%的识别准确率,有效地解决了在汉、朝、英三种文字混合构成的文档图像中文种辨识问题。
文种辨识;主成分分析;相对熵;欧式距离;文字分割
1 引言
人类社会中语言的本质在于定义群体,即每一种语言界定了一个群体,而文字作为语言的视觉化表现,是群体身份认定的重要依据之一。在多语种信息服务、文本索引等各类应用中文字语种辨识扮演着不可替代的角色,将对扩大已有OCR系统的价值和开发面向多语种OCR系统具有重要意义[1]。
不同文字的文字图像所表现出的不同纹理特征,可以为文字语种辨识提供底层特征[2],而提取纹理特征的方法可分为两大类: 一类是基于文字结构的,如以文字的统计特性作为特征;另一类是基于视觉轮廓的方法,如基于Gabor滤波器的特征[3]。国内外研究对于文本图像的特征提取采用可控金字塔变换[4]、Gabor滤波器[5]等方法,并结合SVM[5-6]、决策树[7]、K-NN近邻[5,8]等分类器实现文字语种辨识。目前提出的方法普遍存在以下两种问题: (1)采用结合分类器的方式进行文字语种辨识,而训练分类器的参数需要花费大量的时间,并且参数的微小变动对实验结果带来很大的影响; (2)辨识对象都是以页、文本行、文本块作为基本单位,因此限制了文字语种辨识方法的灵活性。
本文针对朝鲜文字、汉字和英文字母混合出现的文本图像基于主成分分析方法提出了一种以一个文字为单位进行文字语种辨识的方法。通过分析三种文字的结构特性,首先,采用主成分分析方法分别对朝鲜文字和英文字母构造特征空间;然后对于待辨识的文本图像进行文字分割,并把分割出的文字映射到特征空间得到重构后的文字;最后,根据原图像与重构图像之间的相对熵和欧氏距离辨识文字语种。
2 文字语种辨识流程及预处理
由于文本图像在获取并数字化过程中会发生倾斜和出现噪声等现象,因此在辨识文字语种之前应进行倾斜校正和去除噪声等预处理。本文以一个文字为研究对象,因此经过倾斜校正和去除噪声等预处理之后需要进行文字分割。最普遍的分割方法是通过直方图的波谷判断文字的边缘,但对于不同的文字语种,只根据波谷位置判断一个文字的边缘是不可行的,还需要结合每种文字的形态结构特点。
2.1 文字语种辨识流程
首先,使用常用文字分别对英文字母、朝鲜文字和汉字构造特征空间,并对待识别的文本图像进行预处理和分割;然后,将分割出的文字先映射到由英文字母构造的特征空间进行重构,并分别求出原图像和重构图像的水平和垂直方向的直方图;最后,计算两个图像之间的欧式距离和直方图的相对熵。当欧式距离和相对熵满足限定条件时,辨识结果为英文单词,否则把原图像再次映射到由朝鲜文字构造的特征空间进行相同的步骤,根据欧式距离和相对熵判定是否为朝鲜文字,如果不满足限定条件则映射到由汉字构造的特征空间,并根据相对熵判定是否为汉字。其处理流程如图1所示。
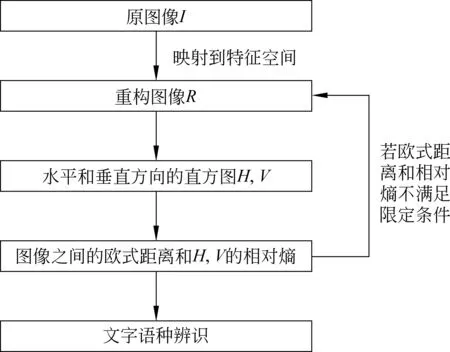
图1 文种辨识处理流程
2.2 文字分割
文字分割是文字语种辨识过程中最基本的预处理阶段,文字分割的效果将直接影响文字语种辨识正确率[9]。在进行文字分割时,如果只根据垂直方向投影的直方图中出现的波谷位置判断一个文字的边界,则会导致很高的误分割率。经过分析朝鲜语、汉语和英语三种文字的结构特点,以文字的宽度、质心和直方图的波谷位置作为分割依据,并对进行分割后的二值图像进行居中处理,使文字处于背景的中心,就会得到满足文种辨识需要的分割结果。

图2 两种不同的分割方法
3 基于主成分分析的汉朝英文字语种辨识方法
3.1 特征空间的构造
多语种文本图像中的文字语种辨识需要解决的核心问题是用低维特征来描述某一种语言文字的结构特点。每一种语言的文字有它本身的结构特点,即同一种语言的文字之间具有相关性,利用文字之间的相关性,可以用少量的数据描述文字的结构特点。主成分分析 (Parincipal Component Analysis,PCA)是一种对数据进行相关性分析的技术,可以揭示隐藏在复杂数据背后的简单结构,从而进行对原有数据的简化描述[10]。本文采用主成分分析方法构造能够描述特定文字语种的所有文字的特征空间。N×M维的文字图像I(x,y)可以表示成向量PiRk(k=N×M),则文字的平均图像可表示为式(1)。
(1)
而文字图像的协方差矩阵为式(2)。
(2)
其中,Φi=Pi-avg∈Rk(k=N×M),n表示文字总数。通过协方差矩阵的前几个最大特征值对应的特征向量可以构造出某一个文种的特征空间。
通过对朝鲜文字的统计分析发现,朝鲜文字可以分为12种结构[11],根据这一分类结果与英文单词和汉字的文字特点,本文对朝鲜文字、英文单词和汉字分别构造5、2、1个特征空间。在图3中,从左到右依次表示大写/小写英文字母、不含终声和含终声的朝鲜文字和汉字的一个特征向量以二维图像表示的结果,从图中可以看出英文字母的特征向量所占区域相对朝鲜文字以及汉字较小,并且集中在中心部分。

图3 不同语种文字的特征向量
3.2 文字的重构及文字语种辨识
通过对朝鲜文字、汉字和英文字母进行分析发现英文字母所占的区域相对朝鲜文字和汉字较小;朝鲜文字的结构相对汉字规律性更强。因此分别对英文字母、朝鲜文字和汉字构造特征空间,并通过式(3)对待辨识的文字图像PRk(k=N×M)进行重构获得重构图像。
(3-a)
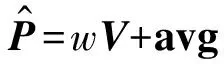
(3-b)
其中,VRk(k=N×M)为式(2)中协方差矩阵C的特征向量。
同一种语言的文字之间在结构上具有一定的相关性,因此当文字映射到相应的特征空间时,重构后的图像与原图像非常相似,如果映射到其他语言的特征空间,重构后的图像将失去原有的形状。当朝鲜文字和汉字映射到由朝鲜文字构造的特征空间时,重构后的文字示例如图4所示,从图中可以发现重构后的朝鲜文字4(b)与原图像4(a)非常相似,而重构后的汉字4(d)几乎失去了原图像4(c)的形状。
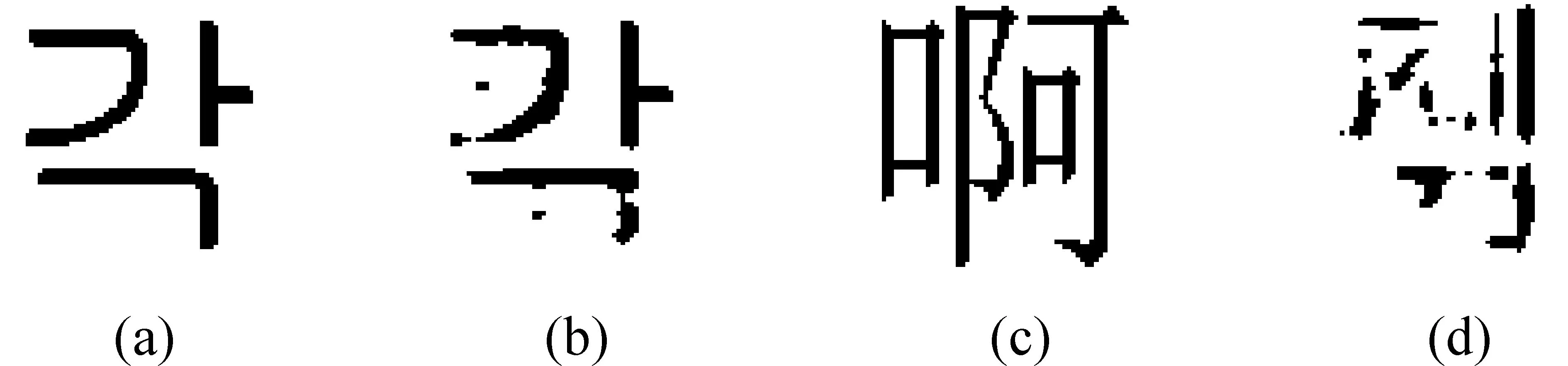
图4 原图像与重构后的图像
(4)
文字语种辨识算法描述如下:
Step 1 由式(1)分别计算出英文字母、朝鲜文字和汉字的平均图像;
Step 2 由式(2)计算出文字图像的协方差矩阵并求出协方差矩阵的特征向量,对英文字母、朝鲜文字和汉字分别选取前30、80、150个最大特征值所对应的特征向量作为各文字空间的基向量,从而分别构造2、5、1个特征空间;
Step 3 待辨识文字图像通过式(3)映射到英文字母特征空间求出重构图像;
Step 4 通过原图像与重构图像之间的欧式距离和由式(4)计算出的水平和垂直直方图的相对熵进行文字语种辨识,如果不满足限定条件则转到Step 3 将待辨识文字图像映射到朝鲜文字特征空间;
Step 5 如果原图像与其在英文字母和朝鲜文字特征空间重构后的图像都不满足限定条件,则映射到汉字的特征空间,并根据相对熵判定是否为汉字,如果不满足限定条件则拒绝识别。
上述算法的Step4、Step5中所指的“限定条件”为: 对于英文字母和朝鲜文字,原图像和重构图像之间的欧式距离小于D且水平直方图的相对熵小于EH,垂直直方图的相对熵小于EV;而对于汉字,水平和垂直方向的相对熵都小于E。
图5为对朝鲜语、汉语和英语的三种文字混合的文本图像进行文字语种辨识的结果示例,其中用圆圈、叉号和十字符号分别表示辨识结果为朝鲜文字、汉字和英文字母。

图5 文字语种的辨识结果示例
4 实验结果及分析
4.1 文字数据及文本图像中的文种辨识实验
我们通过对不同字体和大小的朝鲜文字、汉字、英文字母测试验证了本文方法的有效性。本文对分割后的文字进行归一化处理,因此对文字大小没有严格的要求。在字体方面选择了具有规整风格的字体,汉字选用宋体和仿宋体,朝鲜文字选择Batang和Gulim,英文字母则选择了Times New Roman 和Calibri等字体作为样本。对于文字间距方面的要求是间距大于1/4文字宽度。为了测试每种语言的所有文字,根据计算机系统提供的文字符号集生成了全部文字的图像数据,同时还采集了文档扫描图像,并采用本文提出的方法分割文字,构造了辨识对象数据集。文档扫描需采用200dpi以上分辨率,以保证文字图像的失真度,不影响文字的正确分割和有效构造特征空间。通过实验发现英文字母、朝鲜文字和汉字的前30、80、150个最大特征值占特征值总和的75.89%、67.80%和84.45%,并且对训练样本的实验结果分析后算法中的变量D、EH、EV、E确定为250、0.1、0.2、0.15。实验结果如表1所示。
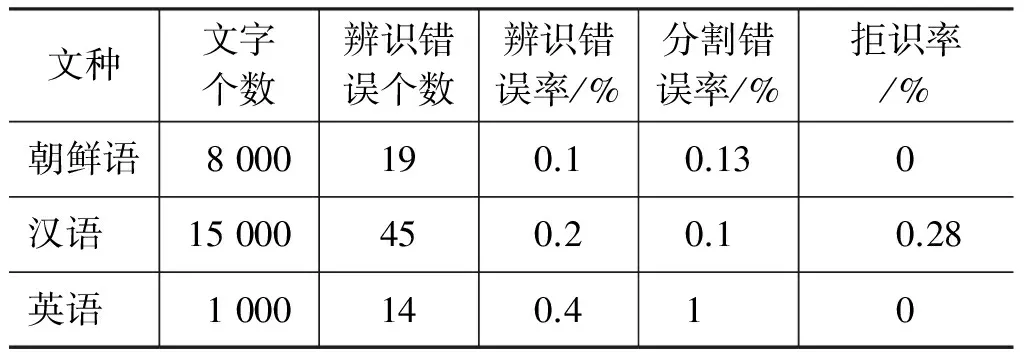
表1 文字语种辨识结果
表1中的辨识错误率是没有考虑分割错误率时得出的百分比(辨识错误个数=文字个数×(辨识错误率+分割错误率))。出现辨识错误的原因主要是有些汉字在结构方面简单(如汉字“一”),当它们映射到朝鲜文字特征空间时,重构的图像与原图像相似,因此辨识为朝鲜文字;而出现分割错误的主要原因是英文字母间的重叠现象。由于本文以一个文字作为识别对象,因此对于文章的篇幅等没有限制,可以提高识别准确率。文献[12]的方法对文本图像中文字的个数和文字间的间距有较严格的要求。
4.2 自然图像中的文字语种辨识实验
我们对自然图像中的文字语种进行了辨识实验,结果如图6所示。其中,用实线矩形框、虚线方框和点线方框分别表示文字语种辨识结果为朝鲜语、汉语和英语。从文字语种辨识结果中可以看出,测试图像中对于文字种类、文字的大小、字体和文字相对背景的颜色等多方面存在多样性,但本文方法不仅准确定位了文字所在的区域,而且正确辨识了文字语种。

图6 文字语种辨识示例
表2是对100幅自然图像进行文字语种辨识的结果。其中,训练样本个数和测试样本个数均代表文字的个数,朝鲜文字的正确辨识率为86.67%,汉字的正确辨识率为88.89%,英文的正确辨识率为85%。对朝鲜语、汉语和英语文种的整体正确辨识率达到87.37%,说明了本文方法具有较高的有效性和可行性。
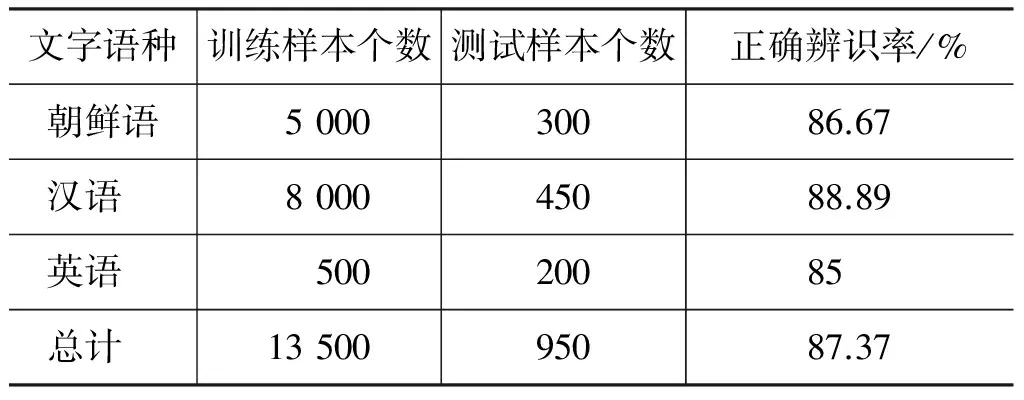
表2 文字语种辨识结果
造成文字语种辨识错误的原因可以归结为以下三类。
(1) 朝鲜文字和汉字在结构纹理上具有复杂性和相似性,如朝鲜文字的“丕”和汉字的“圣”具有结构相似性;
(2) 文本区域定位的精确性问题,如个别检测的文本区域未能包含完整的文字;
(3) 文字分割和提取过程中一些噪声的影响。
文献[12]利用基本图像特征辨识文本图像的文字语种,该文中的文本图像为通过版面分析后的纯文字图像,其方法对朝鲜文字的辨识结果为98.8%。本文的研究工作与文献[12]的区别之处在于以下三个方面。
(1) 本文的研究内容是辨识自然图像中的文字语种,而文献[12]是辨识纯文字文本图像的文字语种;
(2) 本文的自然图像同时包含多语种文字,而文献[12]的研究对象是单语种文本图像;
(3) 本文是以单个文字作为文字语种辨识对象,而文献[12]是以整个文本页作为文字语种辨识对象。
文献[12]所提出的文字语种辨识方法对朝鲜文字的辨识效果很高,但由于其方法对辨识对象的局限性,不能灵活地应用于自然图像中的文字语种辨识研究,而本文所提出的方法不仅能辨识文本图像,而且也能解决对自然图像的文字语种辨识问题。
5 结论及下一步工作
文字语种辨识方法的研究对于多语种文本环境下正确有效地使用OCR系统具有非常重要的意义,作为文字自动识别的前端处理技术的研究,本文提出了基于主成分分析并结合相对熵和欧式距离辨识文字语种的方法,并通过实验验证了所提出方法的有效性。
目前大多数研究集中于基于以页为单位的单一语种文本辨识和基于文本行或单词为单位的多语种文本识别,并且基本采用多通道的Gabor滤波器提取特征,结合SVM/K-NN/ANN等分类器辨识文字语种。这些方法对分类器参数具有很强的依赖性,参数值的变动可能产生完全不同的效果。因此训练一个识别准确率较高的分类器需要花费大量的时间,并且当选择文本行或块作为识别对象时,由于文字间不同宽度的空隙等问题很难从文本中抽取满足要求的文本块。而本文方法以一个文字作为文字语种识别单位,没有对待识别的文字提取特征,并且没有采用分类器。因此本文方法具有简单、有效的优点。
引入其他特征空间构造方法,构造具有判别能力的子特征空间,同时增加更多的文字语种进行验证以提高本文方法的泛化能力,并且引入文字识别的后处理技术是进一步研究的工作内容。
[1] Spitz A L. Determination of the Script and Language Content of Document Image[C]//Proceedings of IEEE Transactions on Pattern Analysis and Machine Intelligence.1997, 19(3): 235-245.
[2] Hidayet Takci, Tunga Gungor. A high performance centroid-based classification approach for language identification[J]. Pattern Recognition Letters.2012, 33: 2077-2084.
[3] Ghosh D, Dube T A P. Shivaprasad: Script Recognition - A Review[J]. IEEE Transaction on Pattern Analysis and Machine Intelligence.2010, 32(16): 2142-2161.
[4] 顾立娟, 邵命山, 郝玉保. 基于可控金字塔子带能量特征的文种识别方法[J]. 计算机应用与软件.2011, 28(3): 91-94.
[6] Script Identification-A Han & Roman Script Perspective[C]//Proceedings of the International Conference on Pattern Recognition. Istanbul, Turkey, 2010: 2708-2711.
[7] BilalBataineh, Siti Norul Huda Sheikh Abdullah, Khairuddin Omar. A novel statistical feature extraction method for textual image: Optical font recognition[J]. Expert Systems with Applications.2012, 39(5): 5470-5477.
[5] Peeta Basa Pati, A G Ramakrishnan. Word level multi-script identification[J]. Pattern Recognition Letters.2008, 29(9): 1218-1229.
[8] P S Hiremath, S Shivashankar. Wavelet based co-occurrence histogram features for texture classification with an application to script identification in a document image[J]. Pattern Recognition Letters.2008, 29(9): 1182-1189.
[9] Amjad Rehman, Tanzila Saba. Performance analysis of character segmentation approach for cursive script recognition on benchmark database[J]. Digital Signal Processing.2011, 21(3): 486-490.
[10] Matthew Turk, Alex Pentland. Eigenfaces for Recognition[J]. Journal of Cognitive Neuroscience.1991, 3(1): 71-72.
[11] 崔荣一, 金世珍. 朝鲜文字信息结构的研究[J]. 中文信息学报.2011, 25 (5): 114-119.
[12] 郭龙, 平西建, 周林, 童莉. 基本图像特征用于文本图像文种识别[J]. 应用科学学报.2011, 29(1): 56-60.
An Approach to Script Identification in Image with Multi-lingual Texts
PIAO Mingji, CUI Rongyi
(Intelligent Information Processing Lab., Dept. of Computer Science &Technology, Yanbian University, Yanji,Jilin 133002, China)
A PCA based character level script identification method is proposed to identify Korean, Chinese and English scripts in a image. First, the space of eigenvectors is constructed by using PCA, and the segmented character was reconstructed by projecting into the space. Second, relative entropy of vertical and horizontal histograms between the original and the reconstructed image is calculated. Finally, according to Euclidean distance and relative entropy between the original and the reconstructed image, the script is identified. The experiment results show that the proposed method achieves 99.78% accuracy under fully correct wrong segmentation, which successfully addresses the script identification problem in Korean, Chinese and English multi-lingual document image.
script identification; principal component analysis; relative entropy; Euclidean distance; character segmentation

朴明姬(1988—),硕士,主要研究领域为自然语言处理。E⁃mail:piaomingji123@hotmail.com崔荣一(1962—),通信作者,博士,教授,主要研究领域为智能计算,模式识别,机器学习,自然语言处理。E⁃mail:cuirongyi@ybu.edu.cn
2015-01-18 定稿日期: 2015-08-10
吉林省科技发展计划项目(20140101186JC);国家语委2015年度科研立项项目(教语信司函〔2015〕21号)
1003-0077(2017)00-0220-06
TP
A
