融合云加端的制造产品在线质量预测研究*
2017-05-25唐向红易向华陆见光刘国凯
唐向红,易向华,陆见光,元 宁,刘国凯
(1a.贵州大学 现代制造技术教育部重点实验室;b.机械工程学院,贵阳 550025;2.贵州省公共大数据重点实验室,贵阳 550025)
融合云加端的制造产品在线质量预测研究*
唐向红1,2,易向华1a,陆见光1,2,元 宁1a,刘国凯1a
(1a.贵州大学 现代制造技术教育部重点实验室;b.机械工程学院,贵阳 550025;2.贵州省公共大数据重点实验室,贵阳 550025)
针对制造过程的在线质量预测的实时性问题,提出了一种融合云加端的在线质量预测架构。该架构在云加端提出一种基于遗传算法(GA)参数优化的隐含层节点自适应增长极端学习机(AG-ELM)方法,建立了优化的产品质量预测模型。同时,该架构在终端改进了k-means方法并将其应用于在线质量数据流聚类,并将聚类中心序列输入产品质量预测模型,预测产品的质量。通过点焊过程的实验表明该产品质量预测模型方法实时性较BP神经网络和贝叶斯方法有较大优势,能应用于当前制造过程的在线质量预测。
制造过程;在线质量预测;数据流;K-means
0 引言
随着人们对质量水平要求的不断提高,使得企业对于产品质量的控制不再仅仅满足于质量检验,而纷纷转向对生产制造过程的监控和分析,希望改善、消除不良的质量影响因素来确保生产过程顺利运行,同时生产成本得以减少。制造过程作为一种复杂生产过程,具有工艺参数众多、机理复杂、非线性显著和动态变化等特点,难以用常规方法建立其精确的数学模型。从质量管理的角度分析,对制造过程中的质量起关键作用的因素有5M1E,即:人(Man)、机(Machine)、料(Material)、法(Method)、环(Environment) 、测( Measurement )。近年来,随着数据采集技术和计算机技术的快速发展,制造过程质量特征参数的获取变得容易[1]。制造过程的数据呈现出高维、强耦合、非线性并且以数据流的形式存在,故传统的统计控制方法已经不能满足现代生产的需求。因而采用基于智能化方法的过程质量控制方法是必要的。生产过程质量预测是实现生产过程质量控制的基础。现有的预测方法如:人工神经网络[2],贝叶斯方法[3]、支持向量机[4]等方法可以对产品质量进行分析预测,并且取得了不错的效果。但是,上述方法并不能实时的预测当前的质量。
随着工业云[5]以及海量数据存储技术[6]的兴起和研究,使得通过云端强大的计算能力,并对在线的实时数据提供参考成为可能。本文针对制造过程中的质量数据以数据流的形式存在的特点,首先提出了一种融合云端的在线质量预测架构,通过云加端强大的计算能力构建AG-ELM模型,并且对模型的相关参数进行了GA优化;在线部分应用基于数据流计算框架的改进K-means方法对工况进行聚类;最后,将云加端优化的预测模型传输至在线部分完成质量的在线预测。
1 融合云加端的在线质量预测架构
云加端拥有着强大的计算能力,并且随着存储技术的不断发展,使得云端存储海量的历史生产数据变得可能。基于此,本文提出了一种融合云加端的在线质量预测架构,通过云加端辅助在线部分进行质量预测。如图1所示。

图1 融合云加端的在线质量预测架构
在线部分首先通过实验确定k值,并通过采样的方法确定初始聚类中心,极大限度的提升了K-means的收敛速度,然后本文改进了K-means算法并且将其引入数据流的计算框架,降低了算法的时间发杂度;同时,云加端首先通过历史数据构建AG-ELM模型,并且初始化AG-ELM,然后通过遗传算法(GA)优化学习机的参数(输入权值和隐含层阈值),并且通过均方根误差和验证集对AG-ELM网络进行验证,直到找到最优学习机;最后,在线部分通过调用云加端的GA-AG-ELM模型,于在线部分完成质量的在线预测。
2 云加端产品质量预测模型的构建
2.1 隐含层自适应增长极端学习机(AG-ELM)
隐含层节点自适应增长极端学习机(AG-ELM)[7]是一种特殊的极端学习机(ELM)[8]。与ELM一样,AG-ELM同样是一种基于单隐层前馈神经网络的学习方法,并且继承了ELM的所有特点,如学习时间短、算法运行快、结构确定简便等。在此基础上,AG-ELM对ELM中如何确定合适的网络结构做了研究,并给出了一种自适应的方式来确定极端学习机的网络结构,即已经存在的网络会被一个新产生的隐层节点数更少的泛化性能更好的网络所替代,并且AG-ELM有很好的逼近能力。ELM的网络结构图如图2所示。

图2 极端学习机的网络结构
一个有N个输入,n个隐含层节点,且一个线性输出的单隐层前馈神经网络可以简单用公式(1)表示:
(1)
其中, (ωj,tj)∈RN×R是第j个隐含层节点输入权值和隐含层阈值,αj∈R是第j个隐含层节点与输出节点之间的权值。
2.2 基于GA优化的AG-ELM算法
在AG-ELM中,输入权值是随机产生的,这种方式确定的输出权值准确率不高,而且极端学习机的输出层权重也是根据预设的输入层权重和隐含层阈值计算得出,这样就会导致极端学习机对未知的测试数据集不敏感[9]。遗传算法(GA)[10]是模拟自然界遗传机制和生物进化论而形成的一种过程搜索最优解算法,具有良好的全局并行搜索能力,鲁棒性强,简单通用,运行方式和实现步骤规范,能加速AG-ELM算法的训练过程并且获得更高的收敛精度。根据GA的思想,每个染色体由隐含层节点中的输入权值ω,输出权值α和阈值t组成。并且AG-ELM网络中所有参数都是基于真均匀分布[11]产生的。GA优化的隐层节点自适应增长极端学习机算法步骤如下:
(2)计算个体的适应值
(2)

(3)令f1ibest=f(C1i),f1best=min(f(C1i))1≤i≤L,即将这一代适应值最小的个体直接传给下一代,并且利用交叉和变异等操作算子对当前群体进行处理,产生下一代群体。交叉概率m在[0.5,1.0]之间取值,否则易导致搜索过程停滞;变异概率n取值范围为[0.01,0.2]。
(4)重复上述过程,直至选出最优个体,记为C1best,其对应的适应值为f(C1best)。
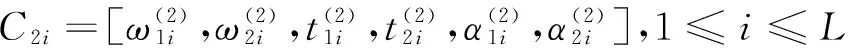
(3)

…
Steps:随机产生种群:
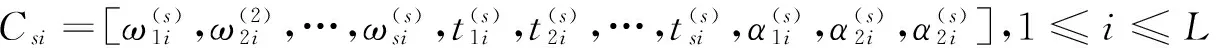
(4)
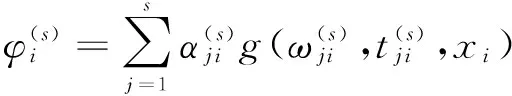
持续上面的过程,可得一组适应值序列C={f(C1best),f(C2best),…,f(Csbest)},选择其中最小的适应值所在的那个粒子作为最后的测试网络。
2.3 基于GA算法的AG-ELM建模
(1)将云端历史的过程数据作为建模数据,随机产生输入权值ω、隐含层阈值t,并通过实验初始化AG-ELM的网络结构;
(2) 应用计算出来的输出层权值α、根据式(1)对预测集进行预测和验证,计算出其标准均方根误差E。E的计算如式(5)所示。
(5)

(3)通过GA优化输入权值ω、隐含层阈值t和输出层权值α,并通过最优的染色体建立AG-ELM模型。
在步骤(2)中,应用GA对AG-ELM输入权值、隐含层阈值等参数的优化过程如图3所示。

图3 AG-ELM参数GA优化流程
3 在线数据流的处理
3.1 基于数据流计算框架的改进K-means算法
聚类分析[12]是数据挖掘研究的一项重要技术,属于无监督机器学习方法,它基于物以类聚原理,分析和探索事物的内在联系和本质。常用的聚类分析方法包括基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法、基于模型的方法和基于变换的聚类算法。
K-means方法是一种典型的基于划分的聚类算法,该算法将一个含有n个样本的集合划分为K个子集合,其中每个子集合代表一个类簇,同一类簇中的样本具有高度的相似性,不同类簇中的样本相似度较低。K-means算法以其思路简洁、收敛速度快成为应用最广泛的聚类算法。虽然K-means有着上述特点,但是其算法自身也存在一些缺陷,例如需要由用户指定k值、初始聚类中心随机选择、产生局部最优解甚至无解等。目前,许多算法均围绕着K-means算法进行扩展和改进。文献[13]提出基于K-means的Stream算法,使用质心和子簇表示聚类。Na S[14]提出了一种改进的K-means算法,通过设置简单的数据结构,存储每次迭代中的一些有用信息用于下一次迭代,减少了迭代次数。文献[15]通过将对数据集的多次采样,选取最终较优的初始聚类中心,使得改进后的算法受初始聚类中心选择的影响度大大降低。
以上国内外K-means算法的研究主要是基于集中式单节点环境下的。近几年,随着数据规模的无限扩大,分布式并行的K-means算法越来越受到人们的青睐。而MapReduce云计算框架作为当下管理大型计算机集群能力的一种流行方式得到重视。文献[16]提出了基于MapReduce的K-means算法,但是没有考虑初始聚类中心的选取问题。文献[17]提出了一种数据流计算框架,即通过将MapReduce框架中的Map操作和Reduce操作进一步拆分,并且拆分出来的操作可以自行组合,与此同时采用IPO (Input-Processor-Output)的运行模型。大大节省了数据处理的时间。
本文基于数据流的计算框架,通过上述算法思想改进K-means算法,并通过多次采样的方法(同样基于数据流的计算框架,将多次采样的处理过程并行化)确定初始聚类中心。
基于数据流的改进K-means算法执行过程如下:
(1)计算每个数据对象到k个初始聚类中心的距离,根据最近邻原则分配到簇,定义一个结构体{cluster[i],distance[i]},其中,cluster[i]表示第i个数据对象的类簇标签;distance[i]表示第i个数据对象到最近中心点的距离。
令cluster[i]=j,j为对象i最近的簇标签;
令distance[i]=d(xi,center[j]),其中,center[j]为第j个类的聚类中心,d(xi,center[j])为到最近中心点的距离。
(2)按照平均法计算各个簇的质心,得到新的簇中心。
(3)利用式(6)计算误差平方和V。
(6)
(4)重复如下操作
1)计算每个数据对象到新聚类中心的距离d;
①如果d≤distance[i],表示第i个数据对象仍近似的在原来的簇中,故将该数据对象分给原来的簇;
②否则将计算数据点到所有中心的距离d(xi,c[m])1≤m≤k分配到最近的簇中心,使得:distance[i]=d(xi,c[m]);cluster[i]=m;
2)更新簇中心;
3)计算误差平方和V,判断V是否收敛,若收敛,算法结束,输出最终聚类结果。
上述处理过程是基于数据流的计算框架上实现的,将整个K-means过程看成是一个大的计算任务,而这个大的计算任务包含了若干小的计算任务,这些小的任务包括将数据对象划分到相应的类簇中、保存相关信息、计算新的聚类中心等。
3.2 聚类算法的理论代价分析
改进的基于数据流计算框架的K-means算法在基于采样的初始聚类中心选取过程中,采样的样本远小于原始数据集,故而迭代的次数很少。当原始数据集的数据量很大时,此部分消耗的时间可以忽略;在基于数据流的计算模型中,由多个节点共同完成K-means聚类算法。假定每个节点协同完成M个任务,在进行数据分配过程时,首先将N个数据对象分配到k个簇,计算量为O(nk/M);在后续的迭代过程中,一部分数据对象仍然近似的保存在原来的簇中,另一部分被分到其他的簇里面。若仍然保存在原来的簇里面,时间复杂度为O(1),否则为O(k/M)。随着算法的不断收敛,簇中数据对象移动会越来越少,若移动的部分为总体数据对象的s(0≤s≤1)倍,此时时间复杂度为O(nks/M)。所以数据分配的总的时间复杂度为O(nkr/M),其中r为总的迭代次数。所以本文算法的总的时间复杂度为O(nkr/M)。
4 仿真实验分析
在以下的实验中,首先给出了本文在线数据流处理效果,然后通过对比BP神经网络、贝叶斯算法的时间和预测精度验证了本文方法的可行性和优越性。
本文以车身点焊过程为例,在实际生产过程中,影响点焊过程的过程质量参数有焊接电流、电极间电压、动态电阻、焊接时间、热膨胀电极位移、能量消耗、声发射、红外辐射的最大辐射量等,根据实际生产经验可知,点焊接头强度是点焊质量的重要指标,而点焊接头的强度主要取决于点焊熔核直径[18]。
预测模型以焊接电流(I)、电极间电压(U)、动态电阻(R)、焊接时间(T)为输入,以点焊熔核直径L做为输出,对点焊过程中的工序质量进行预测。
不考虑故障、干扰和数据不确定的情况下,通过生产过程中的200组过程参数数据,在PC上进行实验,实验硬件环境如下:Inter Core i3-4160 ,3.60GHz,4G内存。实验软件平台:MATLAB 7.6。通过MATLAB模拟一个云端,以上述200个样本数据作为训练集和测试集,在线部分通过模拟数据来进行进数据聚类处理,将聚类的结果作为云端模型的输入,得出预测值。图4为聚类效果图,其中k=4。
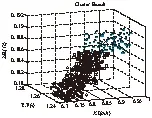
图4 聚类结果
图5为基于数据流计算框架的K-means算法与传统算法随着数据规模的扩大而变化的图,其中数据流计算框架的节点个数为8。由图5可知,随着数据量的增长,两个算法的执行时间都会增加;在处理相同规模的数据量,本文算法具有明显的优势;而随着数据量的增大,基于采样的方法确定初始聚类中心的时间优势会越来越明显,因为好的聚类中心能够大大的减少算法的迭代次数,而且随着数据规模增大,一次迭代的代价也会变得越来越大。

图5 不同算法在不同数据量之间执行时间的对比
将上述聚类得到的结果做为GA优化AG-ELM模型的输入,可以得到预测的熔核直径。同时得到了应用BP神经网络和贝叶斯方法得出的预测结果以及处理1组数据的平均处理时间,如图6和表1所示。

图6 部分样本三种方法预测值与实测值对比

方法平均处理时间(ms)本文方法8BP神经网络40贝叶斯方法18
由图6和表1我们可知,本文方法的预测平均相对误差在5%以内,因为本文在云加端采用了AG-ELM算法,并且在线部分基于数据流的计算框架,改进K-means方法极大限度的提高了算法的效率。反观神经网络,为了保持高精度必须经过大幅度的训练和测试,时间复杂度高。与贝叶斯方法相比,本文应用GA算法优化了输入权值和隐含层阈值,缩短了建模时间和提升了预测精度。
5 结束语
鉴于制造产品的在线质量预测是一个非常重要的研究领域,并且具有广阔的前景,而现有的方法不能满足日益提升的数据量和预测的实时性要求,本文提出了一种融合云加端的制造产品的在线质量预测方法。在线部分将改进的K-means方法应用于数据流框架下,完成聚类,并得到聚类中心;云加端通过庞大的历史生产数据,建立了基于GA优化的AG-ELM模型。最后在线处理完的数据通过调用云加端的模型,进行质量预测。实验结果表明,相对其他两种方法,本文方法具有良好的预测精度和较高的效率,能适应当前制造过程中产品质量的在线预测。
[1] 姜兴宇,干世杰,赵凯,等.面向网络化制造的智能工序质量控制系统[J].机械工程学报,2010,46(4):186-194.
[2] 徐兰, 方志耕, 刘思峰. 基于粒子群BP神经网络的质量预测模型[J]. 工业工程, 2012,15(4):17-20.
[3] 丁钢坚, 张小刚. 贝叶斯分类算法应用于回转窑烧结温度预测模型[J]. 计算机系统应用, 2011,20(9):200-203.
[4] 项前, 杨建国, 程隆棣. 基于支持向量机的纱线质量预测[J]. 纺织学报, 2008,29(4):43-46.
[5] 曾宇, 王洁, 吴锡兴,等. 工业云计算平台的研究与实践[J]. 中国机械工程, 2012, 23(1):69-74.
[6] 侯建, 帅仁俊, 侯文. 基于云计算的海量数据存储模型[J]. 通信技术, 2011, 44(5):163-165.
[7] Zhang R,Lan Y,Huang G B,et al.Universal approximation of extreme learning machine with adaptive growth of hidden nodes[J].Neural Networks and Learning Systems,IEEE Transactions on,2012,23(2):365-371.
[8] Jun Guo,Shunsheng Guo, Xiaobing Yu.Monitoring and Diagnosis of Manufacturing Process Using Extreme Learning Machine [J]Advanced Science Letters, 2011,4:2236-2239.
[9] Malathi V, Marimuthu N S, Baskar S. Intelligent approaches using support vector machine and extreme learning machine for transmission line protection[J].Neurocomputing,2010,73(10-12):2160-2167.
[10] 边霞, 米良. 遗传算法理论及其应用研究进展[J]. 计算机应用研究, 2010, 27(7):2425-2429.
[11] 赵敏汝. 基于粒子群优化的构造性极端学习机的研究[D]. 镇江:江苏大学,2015.
[12] Han Jiawei,Kamber M.Data Mining:Concepts and Techniques[M].2nded.Beijing,China:China Machine Press.2011.
[13] Guha S, Rastogi R, Shim K. Cure: an efficient clustering algorithm for large databases[J]. Information Systems, 1998, 26(1):35-58.
[14] Na S, Liu X, Yong G. Research on K-means Clustering Algorithm: An Improved K-means Clustering Algorithm[C]// Third International Symposium on Intelligent Information Technology and Security Informatics,IEEE, 2010:63-67.
[15] 黄韬, 刘胜辉, 谭艳娜. 基于K-means聚类算法的研究[J]. 计算机技术与发展, 2011, 21(7):54-57.
[16] 江小平, 李成华, 向文,等. K-means聚类算法的MapReduce并行化实现[J]. 华中科技大学学报:自然科学版, 2011, 39(S1):120-124.
[17] 王飞, 秦小麟, 刘亮,等. 云环境下基于数据流的K-means聚类算法[J]. 计算机科学, 2015, 42(11):235-239.
[18] 黄德智, 王治富. 利用点焊过程中的动态电阻监测车身焊点质量[J]. 焊接, 2003(3):9-13.
(编辑 李秀敏)
Research on Online Quality Prediction of Manufactured Products Based on the Framework of Cloud Computing Plus Terminal Computing
TANG Xiang-hong1,2,YI Xiang-hua1a, LU Jian-guang1,2,YUAN Ning1a,LIU Guo-kai1a
(1a.Key Laboratory of Advanced Manufacturing Technology, Ministry of Education;b.School of Mechanical Engineering, Guizhou University, Guiyang 550025, China; 2.Guizhou Provincial Key Laboratory of Public Big Data, Guiyang 550025, China)
According to real-time problems of online quality prediction in manufacturing,this paper proposed a framework of online quality prediction of manufactured products based on cloud computing and terminal computing. In the framework, a hidden layer node adaptive growth extreme learning machine (AG-ELM) method based on parameter optimization of the genetic algorithm (GA) is proposed and an optimized model of product quality prediction is established in cloud computing.The method of K-means is improved to cluster the online quality data stream and the sequence of clustering centers is input into the model of product quality prediction to predict the quality of the product in terminal computing.The experiment of spot welding showed that a framework of online quality prediction this paper proposed was super to BP neural network and Bayesian and could be applied to the online quality prediction of manufacturing process.
manufacturing process; online quality prediction; data stream; K-means
1001-2265(2017)05-0064-05
10.13462/j.cnki.mmtamt.2017.05.017
2016-08-06;
2016-09-18
贵州省重大科技专项(黔科合重大专项字[2013]6019,黔科合重大专项字[2012]6018);贵州省基础研究重大项目(黔科合JZ字[2014]2001)
唐向红(1979—),男,湖南永州人,贵州大学副教授,硕十研究生导师,研究方向为实时数据库系统、数据挖掘,(E-mail)txhwuhan@ 163.com。
TH164;TG506
A
