基于深度自编码网络的安全态势要素获取机制
2017-05-24朱江,明月,王森
朱 江,明 月,王 森
(重庆市移动通信重点实验室(重庆邮电大学),重庆 400065) (*通信作者电子邮箱mingy455@163.com)
基于深度自编码网络的安全态势要素获取机制
朱 江,明 月*,王 森
(重庆市移动通信重点实验室(重庆邮电大学),重庆 400065) (*通信作者电子邮箱mingy455@163.com)
针对大规模网络态势要素获取时间复杂度较高和攻击样本不平衡导致小类样本分类精度不高的问题,提出一种基于深度自编码网络的态势要素获取机制。在该机制下,利用优化后的深度自编码网络作为基分类器,识别数据类型。一方面,在自编码网络的逐层训练中,提出一种结合交叉熵(CE)函数和反向传播(BP)算法的训练规则,克服传统的方差代价函数更新权值过慢的缺陷;另一方面,在深度网络的微调和分类阶段,提出一种主动在线采样(AOS)算法应用于分类器中,通过在线选择用于更新网络权值的攻击样本,达到总样本的去冗余和平衡各类攻击样本数量的目的,从而提高小类攻击样本的分类精度。经对实例数据的仿真分析,该方案有较好的态势要素获取精度,并能有效减少数据传输时的通信开销。
网络安全;态势要素;深度自编码网络;交叉熵函数;主动学习
0 引言
网络的大规模化、异构化和复杂化使得网络入侵和攻击行为具有分布化、海量、多属性等特点,这对现有的单一的安全产品提出巨大挑战,管理员很难对整个网络有全面认识。态势感知[1]是一种通过提取整个网络中多源异构的安全要素进行主动、实时评估和预测网络状况的安全防御机制,态势要素获取是评估和预测的前提,是指在大量的网络安全数据中获取对网络产生影响的因素,并对其进行识别,经统计分析形成态势要素,其核心就是攻击数据的分类识别问题。
目前,相关技术还不成熟,态势要素获取研究仍具有重要意义。解决态势要素获取问题的关键就是找到一种方法识别海量的多源异构数据,如文献[2]利用粒子群优化(Particle Swarm Optimization, PSO)算法优化BP(Back Propagation)神经网络建立态势要素获取模型,可以取得很高的分类精度;文献[3]提出一种新的事件聚类模型和系统结构来解决跨组织的信息安全事件融合问题;文献[4] 利用神经网络并行学习的优势对大量安全数据分类,该算法对大类样本数据检测具有较高的精度,但是这些方法大多在网络安全数据量较少的情况下能获得较好的精度,并且需要人工特征提取,也没有解决目前网络数据的海量和多属性特征导致的识别精度相对较低、时间复杂度较高,以及攻击类型多样性且收集的样本往往类别不平衡导致小类样本训练得少、识别精度远远低于大类样本的问题。
深度学习[5]模拟了人脑的多层结构,能够提取数据的高层特征,消除无关属性的影响,在关联分析上比传统的神经网络更有优势。为此,针对目前信息安全保障呈现出来的网络复杂化、实时化等特点,本文提出基于深度自编码网络的安全态势要素获取方法,充分利用深度学习在处理大数据方面的优势[6]。为了降低时间复杂度,利用交叉熵(Cross Entropy, CE)作为代价函数取代传统的均方误差(Mean Square Error, MSE)函数,通过增加动量因子来进一步提高收敛性能;同时,为了解决由已标记攻击样本数不均衡引起的小类攻击样本精度较低的状况,从整体上提高样本的分类精度,还提出一种主动在线采样算法应用于分类器中以在线选择样本,更新网络权值。
1 态势要素获取模型
现有的网络分布广、节点多,所采用的网络设备和提供的应用服务具有多样性的特点,因此本文采用层次化态势要素获取模型,其结构如图1所示。主要原理是先局部后整体,通过对各个分块区域分别部署异构传感器来实现分布式网络的全局、动态、实时的网络安全事件采集。
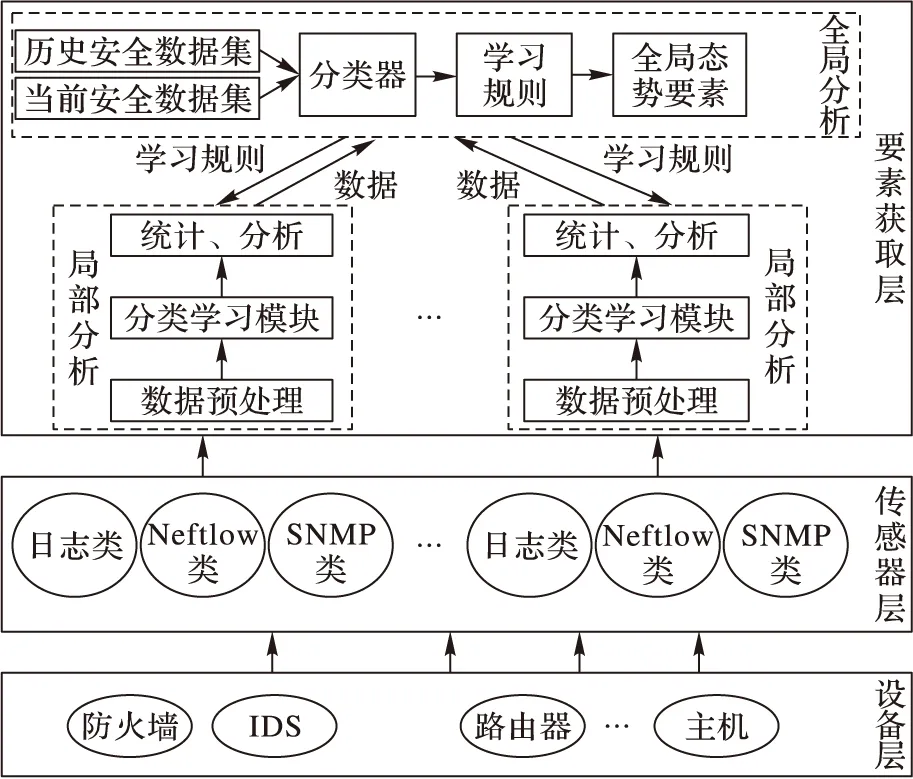
图1 层次化态势要素获取架构
要素获取层负责对从传感器层采集的大量的安全数据进行分析,并实现对网络攻击类型的学习;全局分析模块将各个分块区域收集的网络数据整合,统一学习,将学习的分类规则下发至局部模块,指导局部网络的安全数据的识别分类。本文利用改进的深度自编码网络对预处理后的信息进行分类学习,得到相应的分类规则,经统计分析后生成态势要素。
使用该框架不仅能够得到全局的态势要素,还能实时提取各个局部的态势要素。根据网络安全态势感知结果了解不同局部网络的信息,从而在网络出现威胁时,能快速找到相应的网络。
2 态势要素获取方法
在态势要素获取模型中,本文侧重于要素获取层,其核心的分类学习模块采用深度自编码网络,其具体的深度架构如图2所示。
深度自编码网络由若干层自编码器(Auto-Encoder, AE)和一层softmax组成[7]。其中,多层AE堆叠而成栈式自编码器(Stacked Auto-Encoder, SAE),分层地学习输入数据的特征。其训练过程主要分为两步:1)分别对每一层AE进行无监督训练,将训练得到的权值作为初始权值;2)将最后一层AE的输出作为softmax的输入进行有监督学习,同时微调深度网络。通过这种训练方法可以从底层学习更多能表示数据隐含特征的抽象特征[8],从而将合适的特征值用于模式分类。根据最近的一些研究[9]表明,深层模型比浅层模型在实现非线性函数逼近问题上效果更好。

图2 深度自编码网络
从深度学习的结构和训练过程可以看出,分类精度和训练时间与其训练方法相关,因此,考虑网络安全感知实时性要求和攻击数据中样本不平衡的情况,在分层训练AE时设计了一种结合交叉熵和反向传播算法的分层训练规则,在softmax进行训练和微调时采用本文所提的AOS算法进行采样选择更新网络权值的样本。
2.1 基于CE-BP的分层训练规则
传统的训练方法是利用均方误差作为损失函数,当数据量较大时训练时间较长,因此本文通过推导发现当激活函数为sigmoid函数时,利用交叉熵函数作为损失函数可以实现快速收敛。
自编码器是SAE的核心组件之一,由编码器、解码器以及激活函数f组成,其结构如图3所示。
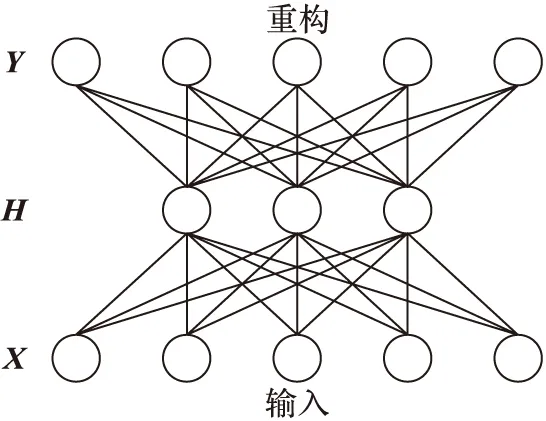
图3 自编码器结构
编码器是输入X到隐含层H的映射,解码器将数据重构回Y,假设输入数据为N维,隐含层节点数为M,则表示为:
H=f(WhX+bh)
(1)
Y=f(WyH+by)
(2)
(3)
其中:权值矩阵Wh∈RM*N,Wy∈RN*M;bh∈RM和by∈RN为偏置向量;非线性激活函数f(·)采用sigmoid函数。
设输入的样本集为x=[x1,x2,…,xm],即神经网络的输入有m个样本,每个样本有n个元素,xk=[v1,v2,…,vn](k=1,2,…,m),则损失函数为:
(4)
其中:i∈[1,m],表示第i个输入样本;k∈[1,n],表示某个输入样本的第k个元素;xik表示第i个输入样本的第k个元素;yik表示第i个输出样本的第k个元素。
最小化输入数据和输出数据之间的误差来训练权值和偏置值,即:
(5)
利用梯度下降法求式(5)的最优解,不同于文献[10]通过直接求式(4)对权值和偏置值的二次倒数,本文采用反向传播法算法。由上面的讨论可知,AE可以看成两层的感知机结构,因此将敏感度反向传递用以自顶向下修正网络的权值参数。
设p1=whx+bh,则编码器的实际输出为:
h=f(p1)=sigmoid(p1),且p2=wyh+by
则解码单元的敏感度为:
(6)
由重构层得出隐含层的敏感度:
(7)
f′(x)=f(x)[1-f(x)]
(8)
式(6)中:xik为第i个样本的第k个元素的输入,也即目标输出。从式(6)可以看出,重构层的训练不受f′(x)的影响,只与误差有关,所以当误差较大时,权值更新快;当误差较小时,权值更新慢。为了提高收敛性能,防止算法在发散时来回震荡,引入动量因子γ来平滑收敛时的震荡,所以参数更新公式为:
Δwl(d+1)=γΔwl(d)-(1-γ)ηsl(yl-1)T
(9)
Δbl(d+1)=γΔbl(d)-(1-γ)ηsl
(10)
其中:yl-1为前一层网络的输出,η是学习速度。
2.2 基于AOS-softmax的微调和分类
采用传统的softmax网络对整个特征向量进行训练,当样本数不平衡时训练过程更偏向于大类样本,导致小类样本的分类精度不高,同时大量的冗余数据浪费了训练时间,因此本文提出一种主动在线采样算法,通过分析数据本身的信息量来动态地选择用于训练softmax网络和微调深度网络的样本。
2.2.1softmax网络
softmax网络[11]是一种有监督分类器,它作为深度自编码网络的最后一层用于将自编码网络提取的态势数据特征向量进行分类并微调整个网络。softmax保证每个输出单元的总和为1,所以可以把输出视为条件概率。假设给定输入矢量R,即R为多层自编码网络的输出,则输入属于类别的概率为:
(11)
其中:W和b是logistic逻辑回归层的权重和偏置值,i为类别标签。
2.2.2AOS算法
为了解决样本不均衡问题,常见的方法包括过采样[12]和欠采样[13],这类方法容易造成数据冗余或者丢失了部分信息。后来,主动学习方法[14-15]被用于样本的抽样,它通过选择决策边界的样本来训练分类器,取得了很好的效果。鉴于此,本文设计了一种主动在线采样算法用于解决样本不平衡的问题,它运用主动学习思想并结合样本分布对数据进行采样,根据每条数据的信息量来选择微调的样本,去除冗余的数据,保留更有用的数据。
假设将态势要素分成m类,则分类器输出节点数为m。对于一个a类样本x,其目标输出为t={ti|ta=1,tj|j≠a=0}。
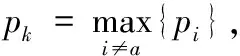
1)pa远大于pk:样本x被学习得好,所含信息量少。
2)pa接近于pk:样本x以一定的概率被误判,所含信息量大。
3)pa小于pk:样本x分类错误,需要重新训练,所含信息量大。
不难看出,第1)种情况已经能获得准确的类别,因此训练时应该更偏向于选择第2)和第3)种情况的样本。根据softmax网络前向传播,定义如下置信度函数:
C=pa-pk
(12)
由式(12)可知,C越大,表示样本被网络学习得越好,信息量就越少,网络权值被更新的可能性就越小;C<0时,说明样本被错误地分类。考虑到C∈[0,1],C与选择概率成反比关系,因此根据式(12)设置如下选择函数:
z=-ln(C)
(13)
运用式(13)可以解决数据冗余的问题,但是对于样本数分布不平衡的问题还没有解决。考虑到攻击数据中大类样本与小类样本差距太大,因此,在满足大样本分类精度的前提下提高小类样本被选择的概率,重新定义选择函数如下:
(14)
其中:ra为第a类样本的样本数量,rmax为最大样本的数量。C<0时,说明样本被错误地分类,因此取z=+∞。由式(14)可以看出,新的选择函数根据样本数量变化:对于小类样本,选择函数增大一定的比例;而对于大类样本,选择函数没有变化。将z与预先设定的阈值ε相比较:z>ε,则选择样本x反向微调网络;z≤ε,则样本x被遗弃。
通过分析上述选择机制,可以得出如下结论:
1)在当前迭代次数下,被网络错误分类的样本将被用于网络权值的更新;
2)在当前迭代次数下,被网络正确分类的样本中,置信度越低的样本被选择更新网络权值的概率就越大;
3)在当前迭代次数下,被网络正确分类的样本中,选择函数更偏向于小类样本;
4)在当前迭代次数下,被遗弃的样本仍可用于下一次迭代。
主动在线采样类似于欠采样,都是通过减少大类样本的样本数来提高小类样本的精度,但是不同之处在于它是在训练过程中在线采样;而与主动学习相比,它考虑了样本类别,而主动学习只考虑样本信息量,在选定样本后才对其进行类别判定。
2.2.3 面向softmax网络的主动在线采样算法
深度网络的分类和微调阶段是网络学习的关键部分,本文根据主动在线采样算法和初始化后的网络构造学习器,其算法如下。其中,样本xi为最后一层自编码网络的输出特征;softmaxF(xi)为对样本xi按式(11)进行前向传输得到属于每一类的概率值。
算法1 面向softmax网络的主动在线采样算法。
3 态势要素获取算法流程
本文对采集的安全数据进行分类识别,综合网络安全数据的特点,采用深度网络作为分类器,同时在深度网络逐层训练阶段利用交叉熵代替均方误差损失函数,提出一种主动在线采样算法应用于softmax网络训练和微调阶段。假设深度自编码网络的层数为K,算法流程如图4所示。
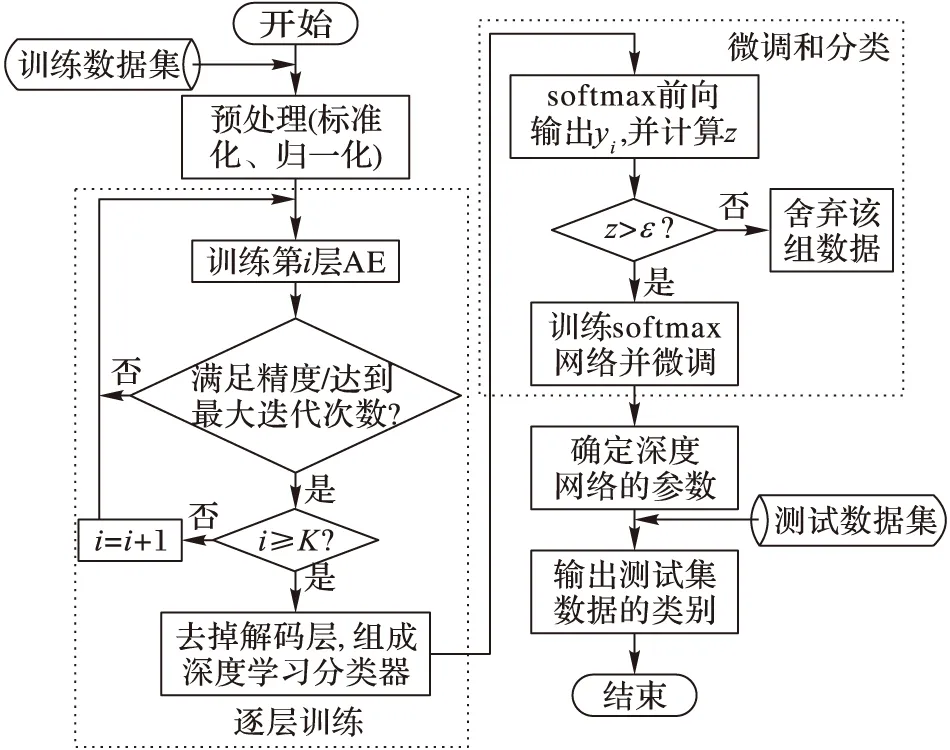
图4 态势要素获取算法流程
4 仿真及结果分析
影响网络运行的主要因素是攻击行为,因此态势要素获取层主要负责对攻击数据的识别,本文使用KDDcup99数据集,它主要将攻击分为四类:DenialofService(DoS)攻击、User-to-Root(U2R)攻击、Remote-to-Local(R2L)攻击和Probe攻击,其余的正常数据归Normal,每类样本都有相应的标签。
4.1 数据预处理
KDDcup99数据有41维特征,其中9维离散特征,32维连续特征。对于离散特征采取赋值的方法,而对于连续特征进行标准化和归一化处理。设处理前的数据为Xij,处理后的数据为X″ij。
4.1.1 数值标准化
对原始特征采用z-score标准化处理,如式(16)所示:
(16)
其中:Xij为第i条记录的第j个属性,Avgj为第j个属性的平均值,Stadj为平均绝对偏差。
4.1.2 数值归一化
采用Min-max方法进行归一化处理,如式(17)所示:
(17)

本文按照一定比例随机抽取KDDcup99中10%训练数据集的部分数据作为训练数据,并按同样的方法抽取KDDcup99测试子集中的数据。数据具体情况如表1所示。

表1 实验数据
4.2 仿真实验
4.2.1 网络的收敛性
首先检验自编码网络的收敛性,同时比较本文采用的交叉熵(CE)损失函数与传统的均方误差(MSE)在自编码网络训练时的误差变化趋势,训练过程中自编码网络的误差相对权值更新次数变化情况如图5所示。由图5可知,随着迭代次数的增加,误差都单调下降,网络是逐渐收敛的,可以明显看出采用交叉熵损失函数收敛更快。
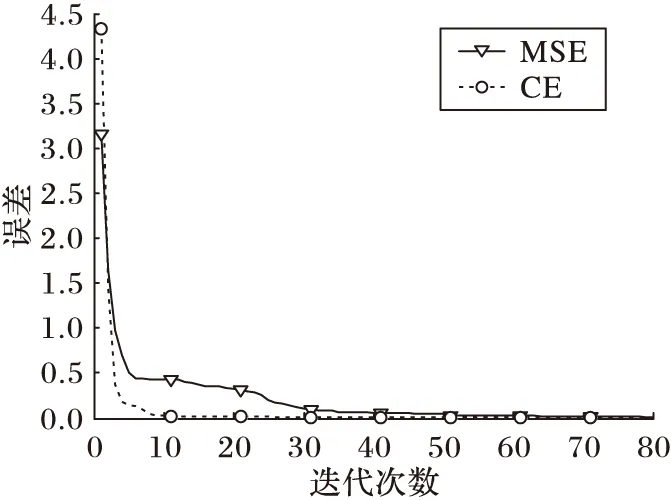
图5 误差随迭代次数变化曲线
4.2.2 深度网络结构对分类精度的影响
文献[16]指出,隐含层的节点数和网络的深度对分类效果有重要影响,网络层数的增加可以增强深度自编码网络的建模能力,但层数过多也可能降低网络的泛化能力。文献[17]已验证,3层自编码网络已经足够取得良好的效果,所以,采用本文所提的深度自编码网络,比较深度为2层和3层自编码网络下不同隐含层节点数对分类精度的影响,实验结果如图6。
选用trainData1作为训练数据,testData1作为测试数据。输入维数为41,分类器的输出维数为5,权重衰减参数为1E-4,动量因子γ=0.9,迭代次数为800。为了确定隐含层节点数对分类效果的影响,固定其他参数,修改网络隐含层节点数。
容易看出,2层自编码网络和3层自编码网络均在隐含层节点数为20时分类效果最好。这是因为在KDDcup99数据集的前41维属性中,并不是所有属性都适合作为特征,而经过降维后的特征向量对数据潜在特征的挖掘更有效。综合考虑时效性和精确度,确定网络结构为41—20—20—5。
4.2.3AOS算法对小类样本数据的影响
通过对比U2R类攻击的精确度来验证AOS算法对小样本的分类精度的影响。其中,阈值ε=3.5,选用trainData2作为训练数据,testData2作为测试数据。实验结果如图7所示。
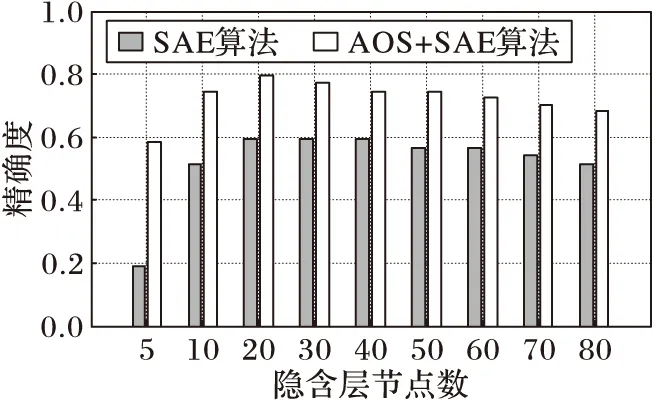
图7 AOS对小样本态势要素获取精确度影响
其中,SAE算法和AOS-SAE算法的自编码网络都采用交叉熵损失函数,由图7可以看出,不同隐含层节点数,AOS对小样本态势要素获取是有效的,提高了小样本态势要素获取的精确度。
4.2.4 与其他分类方法精确度比较
结合4.2.2节的结果,确定深度自编码网络的结构,各层都采用梯度下降算法。以每一类别的检测率和整体的检测率来衡量网络的性能,同时将本文算法(AOS-SAE)与未经主动在线采样的深度自编码网络(SAE)、支持向量机(SupportVectorMachine,SVM)、BP神经网络和经主动在线采样的BP网络相比较。其中深度自编码网络中AE均采用本文的训练规则,BP神经网络也采用三层感知机结构,以均方误差作为损失函数,sigmoid为激活函数,迭代次数和学习速度与深度自编码网络相同,SVM的核函数采用高斯函数,正则化参数设置为默认值1。trainData2作为训练数据,testData2作为测试数据,检测结果见表2。
由表2可以看出,本文算法的总体精确度明显高于其他方法,对小类样本U2R类攻击本文算法的检测率较未经主动在线采样的SAE提高了23.8%,对R2L类样本的检测率相比SAE也提高了4.2%。这说明经主动在线采样后的深度自编码网络由于缩小了各个样本数量的比例,对小类样本的检测率大幅度提高;同时对Probe类样本的检测率相比未经主动在线采样的深度网络却下降了1.7%,这是由于Probe类攻击与R2L类攻击较相似,抽样后的样本检测时发生混淆。

表2 不同方案态势要素获取精确度 %
4.2.5 算法时间复杂度分析
由于态势感知分析越来越重视时效性,因此必须在保证精确度的同时减少花费的时间。本实验通过比较分层训练中使用均方误差损失函数的深度自编码网络(MSE-SAE)、使用交叉熵损失函数的深度自编码网络(CE-SAE)和本文所提的分层训练时使用交叉熵损失函数并结合AOS算法进行微调和分类的深度自编码网络(AOS-SAE)的时间复杂度来说明本文方案在满足实时性上的优势。
由表3可以看出,结合AOS算法和交叉熵函数的深度自编码网络在时效性上有明显的优势。采用交叉熵作为误差函数来更新网络权值时避免了网络对激活函数的求导运算,从而使网络运行时间减少一半以上。利用AOS算法选取特征向量中更有效的数据,去掉相似的特征向量,避免重复学习,从而减少了用于训练softmax分类器和微调整个网络的输入向量个数,缩短了网络运行的时间。

表3 三种SAE算法时间复杂度对比
5 结语
针对网络安全态势要素获取问题,本文提出了一种基于深度自编码网络的获取方法。借鉴传统深度学习架构,考虑到sigmoid函数特点,结合交叉熵损失函数和反向传播算法更新网络权值,减少网络收敛时间,提高分类的准确度;同时为了有效提高小样本的分类精度,在softmax分类器进行有监督训练时采用主动在线采样算法来选择用于更新网络的连接权值的样本。选择样本的标准考虑类别不平衡的情况和每个样本的难易程度,从而使得改进后的网络能够同时满足小类的样本和更难被分类的样本,由于去除了一些对网络权值更新作用不大的数据,因此大幅度缩短了网络的训练时间。通过对KDDcup99数据的测试,得到了较好的效果,验证了态势获取模型的有效性。在下一步工作中,同时考虑到网络数据不断变化的特点,将增量式学习运用到态势要素获取中,提高网络的适应性。
)
[1]CORONATOA,DEPIETROG.Situationawarenessinapplicationsofambientassistedlivingforcognitiveimpairedpeople[J].MobileNetworksandApplications, 2013, 18(3): 444-453.
[2] 郭文忠, 林宗明, 陈国龙. 基于粒子群优化的网络安全态势要素获取[J]. 厦门大学学报:自然科学版, 2009, 48(2):202-206. (GUOWZ,LINZM,CHENGL.NetworksecuritysituationelementsextractionbasedonPSO[J].JournalofXiamenUniversity(NaturalScienceEdition), 2009, 48(2): 202-206.)
[3]SKOPIKF,WURZENBERGERM,SETTANNIG,etal.Establishingnationalcybersituationalawarenessthroughincidentinformationclustering[C]//Proceedingsofthe2015InternationalConferenceonCyberSituationalAwareness,DataAnalyticsandAssessment.Piscataway,NJ:IEEE, 2015: 1-8.
[4] 刘衍珩, 田大新, 余雪岗,等. 基于分布式学习的大规模网络入侵检测算法[J]. 软件学报, 2008, 19(4):993-1003. (LIUYH,TIANDX,YUXG,etal.Large-scalenetworkintrusiondetectionalgorithmbasedondistributedlearning[J].JournalofSoftware, 2008, 19(4): 993-1003.)
[5] 王知音,禹龙,田生伟,等.基于栈式自编码的水体提取方法[J].计算机应用,2015,35(9):2706-2709. (WANGZY,YUL,TIANSW,etal.Waterbodyextractionmethodbasedonstackedautoencoder[J].JournalofComputerApplications, 2015, 35(9): 2706-2709.)
[6]ZHANGQ,YANGLT,CHENZ.Deepcomputationmodelforunsupervisedfeaturelearningonbigdata[J].IEEETransactionsonServicesComputing, 2016, 9(1):161-171.
[7]SCHÖLKOPFB,PLATTJ,HOFMANNT.Greedylayer-wisetrainingofdeepnetworks[M]//AdvancesinNeuralInformationProcessingSystems19:Proceedingsofthe2006Conferences.Cambridge,MA:MITPress, 2007: 153-160.
[8]BENGIOY,COURVILLEA,VINCENTP.Representationlearning:areviewandnewperspectives[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2012, 35(8): 1798-1828.
[9]LEROUXN,BENGIOY.Deepbeliefnetworksarecompactuniversalapproximators[J].NeuralComputation, 2010, 22(8): 2192-2207.
[10]CHENY,LINZ,ZHAOX,etal.Deeplearning-basedclassificationofhyperspectraldata[J].IEEEJournalofSelectedTopicsinAppliedEarthObservations&RemoteSensing, 2014, 7(6): 2094-2107.
[11] 汪海波,陈雁翔,李艳秋.基于主成分分析和Softmax回归模型的人脸识别方法 [J].合肥工业大学学报(自然科学版),2015,38(6):759-763.(WANGHB,CHENYX,LIYQ.FacerecognitionmethodbasedonprincipalcomponentanalysisandSoftmaxregressionmodel[J].JournalofHefeiUniversityofTechnology(NaturalScience), 2015, 38(6): 759-763.)
[12]PEREZ-ORTIZM,GUTIERREZPA,HERVAS-MARTINEZC,etal.Graph-basedapproachesforover-samplinginthecontextofordinalregression[J].IEEETransactionsonKnowledge&DataEngineering, 2015, 27(5): 1233-1245.
[13]NGUYENHM,COOPEREW,KAMEIK.Acomparativestudyonsamplingtechniquesforhandlingclassimbalanceinstreamingdata[C]//Proceedingsofthe6thInternationalConferenceonSoftComputingandIntelligentSystems,andthe13thInternationalSymposiumonAdvancedIntelligenceSystems.Piscataway:IEEE, 2012: 1762-1767.
[14]QIY,ZHANGG.Strategyofactivelearningsupportvectormachineforimageretrieval[J].IETComputerVision, 2015, 10(1): 87-94.
[15]HASANM,ROY-CHOWDHURYAK.Acontinuouslearningframeworkforactivityrecognitionusingdeephybridfeaturemodels[J].IEEETransactionsonMultimedia, 2015, 17(11): 1909-1922.
[16]LAROCHELLEH,BENGIOY,LOURADOURJ,etal.Exploringstrategiesfortrainingdeepneuralnetworks[J].JournalofMachineLearningResearch, 2009, 10: 1-40.
[17]LVY,DUANY,KANGW,etal.Trafficflowpredictionwithbigdata:adeeplearningapproach[J].IEEETransactionsonIntelligentTransportationSystems, 2015, 16(2): 865-873.
ThisworkispartiallysupportedbytheNationalNatureScienceFoundationofChina(61271260, 61301122 ),theNaturalScienceFoundationofChongqingScienceandTechnologyCommission(cstc2015jcyjA40050).
ZHU Jiang, born in 1977, Ph. D., associate professor. His research interests include communication theory and technology, information security.
MING Yue, born in 1992, M. S. candidate. Her research interest include network security situational awareness.
WANG Sen, born in 1990, M. S. candidate. His research interest include network security situational awareness.
Mechanism of security situation element acquisition based on deep auto-encoder network
ZHU Jiang, MING Yue*, WANG Sen
(ChongqingKeyLaboratoryofMobileCommunicationsTechnology(ChongqingUniversityofPostsandTelecommunications),Chongqing400065,China)
To reduce the time complexity of situational element acquisition and cope with the low detection accuracy of small class samples caused by imbalanced class distribution of attack samples in large-scale networks, a situation element extraction mechanism based on deep auto-encoder network was proposed. In this mechanism, the improved deep auto-encoder network was introduced as basic classifier to identify data type. On the one hand, in the training of the auto-encoder network, the training rule based on Cross Entropy (CE) function and Back Propagation (BP) algorithm was adopted to overcome the shortcoming of slow weights updating by the traditional variance cost function. On the other hand, in the stage of fine-tuning and classification of the deep network, an Active Online Sampling (AOS) algorithm was applied in the classifier to select the samples online for updating the network weights, so as to eliminate redundancy of the total samples, balance the amounts of all sample types, improve the classification accuracy of small class samples. Simulation and analysis results show that the proposed scheme has a good accuracy of situation element extraction and small communication overhead of data transmission.
network security; situation element; deep auto-encoder network; cross-entropy function; active learning
2016- 08- 04;
2016- 09- 12。
国家自然科学基金资助项目(61271260,61301122); 重庆市科委自然科学基金资助项目(cstc2015jcyjA40050)。
朱江(1977—),男,湖北荆州人,副教授,博士,主要研究方向:通信理论与技术、信息安全; 明月(1992—),女,重庆人,硕士研究生,主要研究方向:网络安全态势感知; 王森(1990—),男,重庆人,硕士研究生,主要研究方向为:网络安全态势感知。
1001- 9081(2017)03- 0771- 06
10.11772/j.issn.1001- 9081.2017.03.771
TP393.08
A
