基于关联关系的微博用户可信度分析方法
2017-05-24李付民佟玲玲杜翠兰李扬曦张仰森
李付民,佟玲玲,杜翠兰,李扬曦,张仰森
(1.北京信息科技大学 智能信息处理研究所,北京 100192; 2.国家计算机网络应急技术处理协调中心,北京 100190) (*通信作者电子邮箱tongling300@sina.com)
基于关联关系的微博用户可信度分析方法
李付民1,佟玲玲2*,杜翠兰2,李扬曦2,张仰森1
(1.北京信息科技大学 智能信息处理研究所,北京 100192; 2.国家计算机网络应急技术处理协调中心,北京 100190) (*通信作者电子邮箱tongling300@sina.com)
随着微博研究的深入,对微博用户可信度的评价成为一个研究热点。针对微博用户可信度评价的问题,提出了一种基于关联关系的用户可信度分析方法。以新浪微博为研究对象,首先从用户的资料信息、交互信息和行为信息三个方面出发,分析了用户的7个相关特征,利用层次分析法(AHP),进而得到用户自评价可信度;然后以用户自评价作为基点,以用户关系网络作为载体,结合用户之间潜在的用户互评关系,通过改进PageRank算法,提出了用户可信度评价模型User-Rank,进而,利用关系网络中其他用户对待分析用户的可信度进行综合评价。大规模的微博真实数据的实验表明,所提方法能够取得良好的用户可信度评价效果。
用户自评价;关系网络;用户可信度;用户关联关系;层次分析法;PageRank
0 引言
近年来,随着社交网络的快速发展,微博作为一种开放式社交网络媒体,凭借其实时、简洁、灵活、快捷的特点,快速地融入到人们生活的各个方面。它不仅具有社交媒体的特性,而且还具有今非昔比的社会服务价值。中国互联网络信息中心(China Internet Network Information Center, CNNIC)发布的《2015年中国社交应用用户行为研究报告》[1]指出,微博是用户获取和分享最新资讯和兴趣爱好的重要平台。新华网发布《2015年全国政务新媒体综合影响力报告》[2]统计数据显示:截止到2015年12月,我国政务微博认证账号(含新浪、腾讯两大微博平台)达到28.4万个,累计覆盖人次达45亿以上。微博作为时下流行的大众化信息传播媒介,处于网络舆论传播中心地位。它不仅满足用户及时了解新闻热点、兴趣内容、对新闻热点事件的评论等需求,同时在政府新闻机构也得到了广泛的应用和极大的推广。
由于微博的开放性和交互性等因素,越来越多的国内民众注册微博,成为微博这一草根媒体的一员。随着微博的普及,微博用户的可信度[3]问题成为亟待解决的问题。目前微博用户可信度的研究大都是基于统计学的方法,通过统计微博用户的粉丝数、原创或转发微博数量、用户交互频率、用户被@次数等特征来进行研究的,这些特征只是从静态的角度反映了该微博用户的可信度,并没有考虑用户关系网络[4]中其他微博用户的可信度对该用户的可信度造成的影响,因此难以全面地评价微博用户的可信度。
本文基于用户关联关系对用户可信度评价方法进行研究,创新性工作主要包括:
1)从用户资料信息、用户交互信息、用户行为信息[5-6]综合考虑出发,分析了用户可信度的相关度量特征,构建了用户可信度自评价模型。
2)结合用户自评价值,利用用户关系网络,完成对微博用户可信度评价模型的构建。
1 相关工作
针对微博用户可信度的问题,已有不少学者对微博用户进行了研究探讨。
Cha等[7]提出了三种度量用户影响力的方法(被关注数量、被转发次数、被提及次数),通过对三种方法的分析比较发现:被关注数量少的用户的影响力一定很低,但是拥有较多关注者的用户其影响力并不一定高。也就说,简单通过统计关注者数量来度量用户影响力的方法并不一定有效。
Bakshy等[8]把微博转发树作为用户影响力的度量指标,通过分析消息传播网络中消息传播的广度和深度,使用回归树的方法,来度量用户的社会影响力大小。该研究认为用户发布微博的转发规模决定了用户影响力的大小。
Castillo等[9]提取用户发布和转发行为、微博文本信息和外部链接引用等三类特征,并利用决策树来评估与相关的“趋势”的主题的微博帖子的可信度。针对微博用户,他们提取每个用户微博发布数量、关注的好友数量、微博注册时间和粉丝数量作为微博用户特征,由于缺乏对用户的权威性的考虑,因此,难以全面地衡量微博用户的可信度。
毛佳昕等[10]考虑用户行为因素和微博传播网络结构两方面的信息,通过分析微博的时效性、用户访问微博的时间分布和用户转发微博的喜好等用户行为因素的关系,提出了用户所发微博在全局范围内被转发的次数这一影响因子,并结合社会影响力在微博关系网络中的传播情况,来度量用户社会影响力。研究表明,用户传播信息能力的大小反映了用户的社会影响力。
张绍武等[11]针对消息传播过程中产生的影响力、用户的活跃程度以及微博消息的价值,提出了三种影响力度量方法(用户行为影响力、用户活跃度影响力和微博影响力),通过分析影响力指标之间关联程度,构建了一种融合上述三种度量方法的微博用户影响力度量模型。研究表明,用户影响力和用户活跃度影响力与微博影响力之间的关联较强,即活跃度较高的用户,其发布的有价值的微博更能提升自身影响力。
纵观国内外学者对于微博可信度的研究,大多集中研究了各种可能影响微博可信度的因素,但鲜有涉及用户关系网络对微博用户可信度的潜在影响及其作用机制。基于此,本文将研究对象锁定在国内新浪微博上,在国内外学者研究的基础上,引入用户关系网络中的用户关联关系对微博用户的可信度进行评价。
2 微博用户可信度模型分析
2.1 用户可信度的自评价模型
本文对新浪微博进行了详尽的分析,从用户资料信息、用户行为信息和用户交互信息三个方面出发,对影响微博用户可信度的自评价效果的相关特征进行度量,提出微博用户可信度的自评价模型。
2.1.1 用户资料信息
一般地,如果用户个人基本资料的公开程度越高,用户发布、转发以及评论微博时会保持较高的道德标准,公众对这类用户的信任程度通常也很高。用户资料信息的完整度一定程度上反映了用户的可信度。基于新浪微博对用户资料信息进行提取,包括用户资料信息中的10项标签的内容:性别、生日、地区、腾讯QQ、博客、简介、标签、教育信息、职业信息和认证信息。
构建向量A用以表示用户基本资料的填写情况,如式(1)所示:
A=(x1,x2,…,xn)
(1)
其中xi表示序号为i的标签是否包含信息:xi=0表示第i号标签不存在有效信息;xi=1表示第i号标签存在有效信息。
考虑到新浪微博用户注册时,用户提交的用户资料信息可能不准确,在数据预处理阶段,本文对用户提交的资料信息进行过滤预处理。对经过预处理的用户资料信息,本文把其作为判断用户可信度的一个维度。用户向量模型构建算法流程如图1所示。
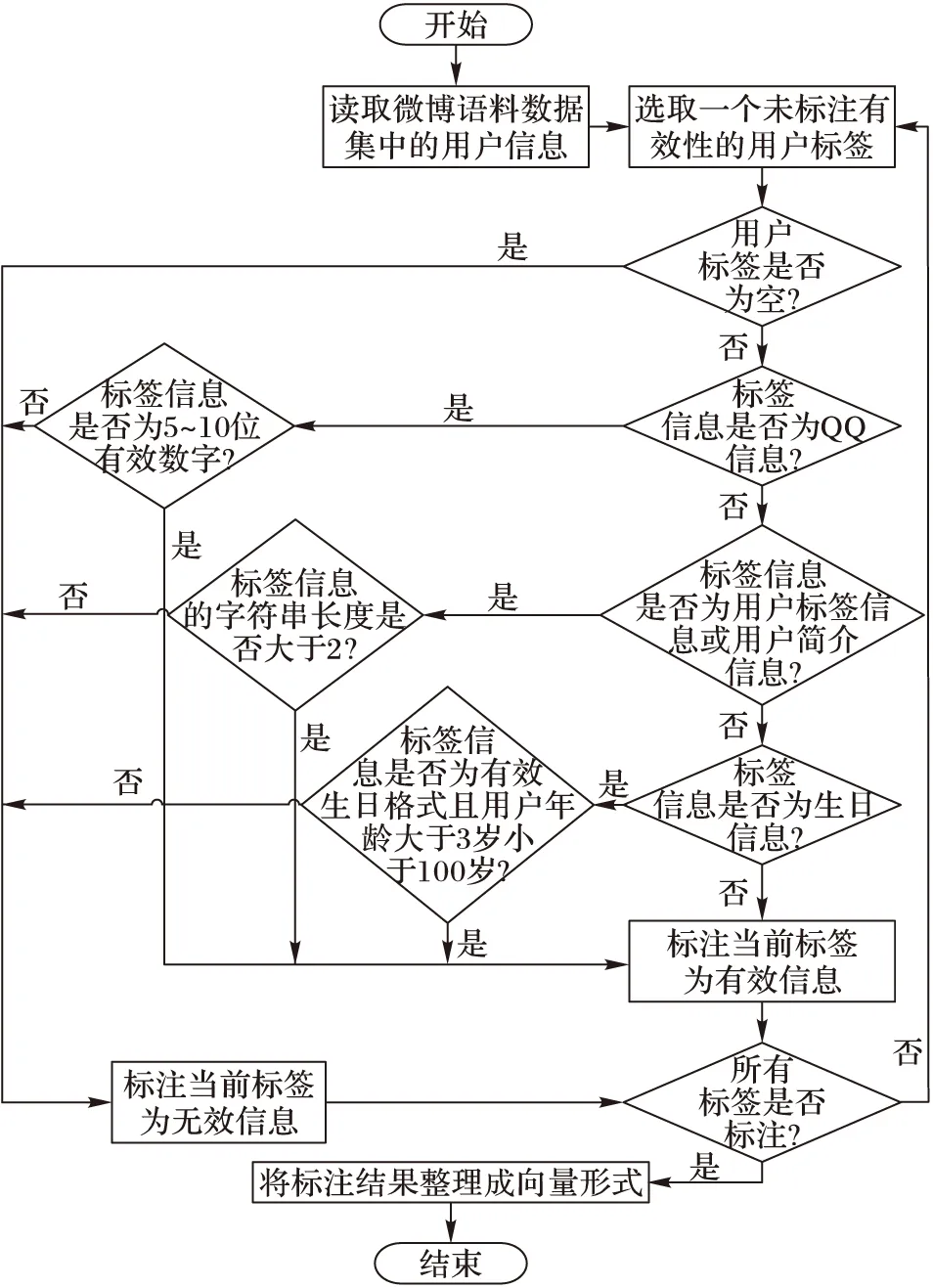
图1 用户向量模型构建算法流程
定义1 用户资料完整度为用户注册微博平台账号时主观意愿上向公众公开的个人基本信息标签所占所有信息标签的比例。
通过计算向量A的稀疏度来确定用户资料完整度(UserInfo Integrity, UI),如式(2)所示:
(2)
其中:UI(u)表示用户资料完整度函数,n是用户资料向量A的总维度。
2.1.2 用户行为信息
从用户行为信息出发,本文考虑用户发布或转发微博中非链接域比率、内容多样性、微博活跃度和时间活跃度这四个特征。
1)非链接域比率。
通常情况下,每条微博文本都较为简短,一些广告用户通常会选用“在微博消息中添加链接”的方式发布广告推广、产品营销等垃圾微博信息。Al-Khalifa等[12]通过对Twitter的分析,考虑文本中是否含有链接这一特性。本文用“不含URL(UniformResoureLocator)微博比”来描述用户微博中不含有链接的微博占比(NoURLRate,NR),如式(3)所示:
(3)
其中:NR(u)表示用户u发布的所有微博中不含链接的微博比例;Num(u)表示用户u的微博总数;函数Url(i)表示用户u发布微博中第i条微博中是否包含链接,若包含链接返回值为1,反之返回值为0。
2)內容多样性。
微博用户中既有正常用户也有僵尸用户。正常用户的微博内容富含用户个人色彩,语言表达形式多样;僵尸用户是指那些虚假账号,一般通过人为控制、自动转发特定信息的账号,目的性较强,发布的微博大多具有针对性。通过对广告用户、垃圾用户等一些有目的性的微博用户的分析,本文发现,这类用户发布的微博内容在一段时间内比较集中,通常具有目的性。特别是广告用户,他们发布的微博内容重复率特别高。这类用户发布的微博内容去重之后,有效字数较少。为了更好地区分正常用户与垃圾用户或者有目的性的用户,本文认为,从微博用户发布的历史微博内容出发,考虑微博短文本的特性、微博内容有效字数,在一定程度上能反映微博用户的差异性,进而对微博用户的可信度进行分析。
基于微博文本的特性,以字为最小单位,计算微博用户内容的多样性(ContentDiversity,ConD),如式(4)所示:
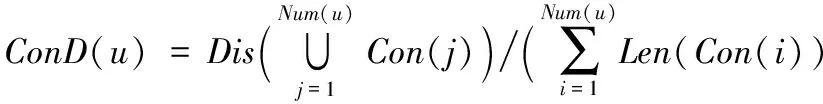
(4)
其中:ConD(u)表示微博用户内容的多样性,Con(i)表示微博用户第i条微博的内容,Num(u)表示用户u的微博总数,Len(m)表示微博文本m的长度,Dis(C)表示微博文本集C去重后的字数。
3)微博活跃度。
该指标指的是用户在更新微博、转发微博的活跃程度。微博活跃度越高,说明该微博用户经常借助微博互动行为,与其他用户实现信息共享。一方面表明该用户所发布的微博、评论等具有比较强的传播能力,另一方面也说明该用户的可信度比较高,其他用户对其信任程度也较高。
定义2 用户微博活跃度(ActivityDegree,AD)为微博用户在一定时间内,通过发布或者转发微博,与他人进行微博信息共享的频率,如式(5)所示:
(5)
其中:AD(u)表示用户微博活跃度,NumT(u)表示用户u在时间T内的原创微博总数,ReblogT(u)表示用户u在时间T内的转发关注者的微博总数,AttT(u)表示用户u在时间粒度T内的关注者数,常数T为时间粒度量,γ为用户原创微博数的权重,δ为用户转发微博数的权重。
例如:用户A有5个关注者,在一段时间内原创微博10条,转发微博5条;用户B有100个关注者,在相同时间内原创微博11条,转发微博4条。可以看出,用户A与他人进行信息共享频率比用户B的高。
4)时间活跃度。
定义3 时间活跃度(TimeActivityDegree,TD)是对用户发布的最近N条微博消息跨越的天数的度量。对于正常用户而言,这一特征值较低,而对于突然活跃的用户,例如当某一话题在微博流行时,这些用户会通过当前热门话题来博得其他用户的关注,这些用户的该特征值较高,如式(6)所示:
(6)
其中:TD(u)表示用户时间活跃度值,Num(u)表示用户u的微博总数,Date(i)表示第i条微博发布的日期,Day(register)表示微博账号注册的天数。
2.1.3 用户交互信息
1)微博传播力度。
定义4 微博传播力度(SpreadDegree,SD)是指微博用户发布的原创微博中,被粉丝认可进而进行的转发、评论、回复、点赞等互动行为的次数。一定程度上,用户传播力度反映了该用户对关系网络中的其他用户的影响力的大小。用户传播力度越高,用户发布的微博获取的关注也就越多,参与的人数也会增加,用户的影响力也越高,如式(8)所示:
(7)
SD(u)=(eμ×Total(u)-1)/(eμ×Total(u)+1)
(8)
其中:SD(u)表示微博传播力度,Num(u)表示用户原创微博数,Thu(i)表示用户u的第i条微博被点赞的次数、Eval(i)表示用户u的第i条微博被评论的次数、Rep(i)表示用户u的第i条微博被回复的次数、Tran(i)表示用户u的第i条微博被转发的次数,Fans(u)表示用户的粉丝数。
2)用户有效交际广度。
在用户关系网络中,微博用户间通过关注成为彼此的粉丝。粉丝表明他人对用户的关注,以期望得到用户的微博行为信息,并将成为微博传播的带动者。拥有越多粉丝的用户,与粉丝之间的交互能力越强,在粉丝中的影响力越高,用户的可信度越高。在中文微博中,有的用户为了追求高粉丝数,于是出现了一种特殊的“互粉”现象,即用户关注了其他某个用户,同时也希望该用户关注自己。
定义5 针对这种特色现象,本文通过对纯粉丝数和互粉数加权求和来统计用户有效交际广度(CommunicateDegree,ComD),如式(9)所示:
(9)
其中:ComD(u)表示用户有效交际广度;Pfans(u)表示用户纯粉丝数,Mfans(u)表示用户互粉数,Fans(u)表示用户粉丝数,且Fans(u)=Pfans(u)+Mfans(u);Att(u)表示用户关注数,γ为用户纯粉丝数的权重系数,δ为用户互粉数的权重系数。
2.1.4 用户自评价可信度模型的构建
基于以上3方面7个指标特征,应用层次分析法(AnalyticHierarchyProcess,AHP)[13]进行指标权重系数的评价,进而度量用户自评价可信度。
层次分析法是把复杂的多因素决策问题分解为多个层次上的子因素间相互比较和权重计算问题。它是美国运筹学家Saaty教授提出的一种多准则、单目标决策方法,是对定性事件作定量分析的一种灵活、适应性强、相当有效的方法。应用层次分析方法进行权重系数评价主要包括三部分。
1)层次结构模型的创建。
层次分析法的基本结构包括三层,分别是目标层、指标准则层以及方案层,如图2所示。
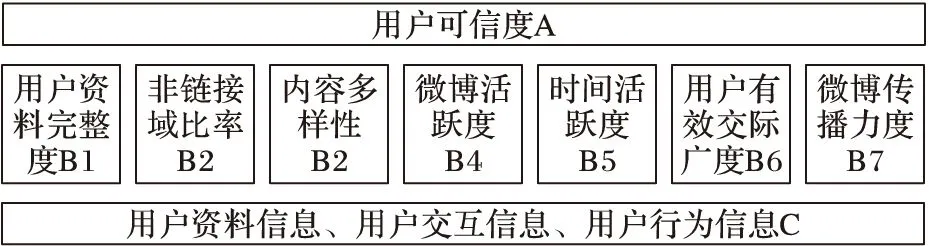
图2 层次结构模型
其中,第一层表示此次的目的是计算用户的可信度,第二层表示存在7个指标来影响目标选取的准则层,第三层表示用户信息的方案层。
2)模型比较矩阵的构建。
根据层次结构模型,相对于计算用户可信度,比较准则层中的各个指标的相对性,得出的比较矩阵如表1所示。
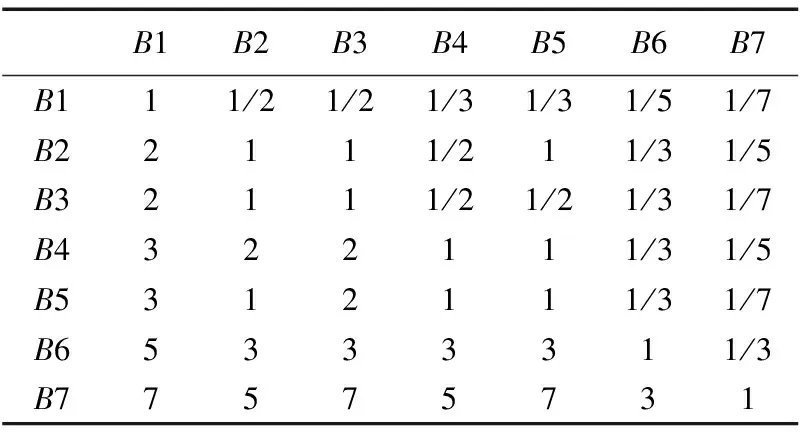
表1 模型比较矩阵
3)权值向量的构建。
构建向量μ用以表示各个指标的权重系数,如式(10)所示:
μ=(μ1,μ2,…,μi)
(10)
根据比较矩阵,获取各个指标间的相对重要程度,进而得到权值向量:
μ=(0.037 3,0.068 7,0.059 9,0.099 7,0.085 7,0.201 7,0.447 5)
本文自评价(Self Evaluate, SE)度量模型的量化计算方法,如式(11)所示:
SE(u)=(UI(u),NR(U),ConD(u),AD(u),TD(u),SD(u),ComD(u))×(μT)
(11)
其中:SE(u)表示用户u的自评价可信度值。
2.2 用户可信度评价模型
上节中,利用用户自评价模型来描述微博用户的可信度,但是从某种程度上来说基于自评价的可信度模型是可以被“灌水”的。为了尽可能避免这种情况,本文对用户之间的关联关系进行了分析,进而评价用户可信度对其他用户的可信度造成的影响。
2.2.1 微博关系网络模型
作为以用户为核心的微博社交网络,微博用户之间可以彼此任意关注对方,这种“关注”与“被关注”的关联关系形成了有向图,也就形成了一个巨大的用户关系网络,如图3所示。
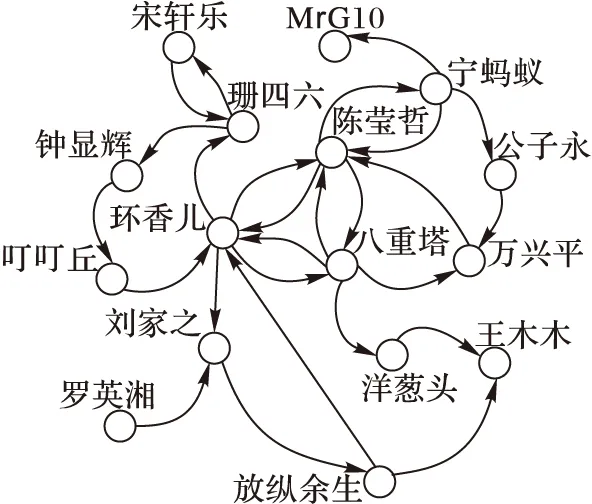
图3 用户关系网络
2.2.2 基于User-Rank的用户可信度网络评价模型
PageRank是一种评价网页的相关性以及重要性程度的算法,常常被用来衡量网页之间链接指向的权威性。
从拓扑结构来说,微博用户关系网络与网页之间的链接关系具有相似性,因此,PageRank算法对微博用户在用户传播关系网络中的评估有一定的借鉴意义。假设微博用户A和用户B拥有相同的粉丝数,并且所有粉丝的PageRank值相同,通过PageRank算法计算,用户A和用户B可信度值是相等的。由于微博中存在互粉现象,在粉丝数相同的情况下,拥有较多互粉的用户的可信度值计算存在一定的偏差,因此,本文在对用户可信度计算时,把粉丝分为通过互粉建立关系和通过纯粉建立关系两类用户,在计算用户可信度值时,在用户关系之间引入权值,对PageRank算法进行改造,提出User-Rank用户可信度评价算法,使其更加适用于微博关系网络中用户的可信度度量。
User-Rank算法分为两个步骤。首先利用用户自评价模型,得到每个微博用户自评价可信度值。然后以用户自评价值作为输入,基于用户关联关系,计算用户可信度值(UserCredibility,UC),如式(12)所示:

(12)
(13)
(14)
(15)
式(12)中,UC(i)表示用户i的可信度评价值,Wm(k)表示用户的互粉用户k的可信度值,Wp(j)表示用户的纯粉用户j的可信度值,f表示阻尼系数,由式(15)得到。
3 实验结果与分析
本文的实验数据来自新浪微博。采集信息包括微博用户资料信息、微博文本信息、微博用户关系信息三方面的信息。微博用户资料信息包括用户id、简介、标签、认证信息、粉丝数、关注数、互粉数等基本信息。微博文本信息包括微博文本内容、点赞次数、评论数、转发数、@用户等信息。微博用户关系信息包括微博用户id、用户关注数、关注者id列表。基于新浪微博的应用程序编程接口(ApplicationProgrammingInterface,API),信息采集如下:
1)爬取微博种子用户信息。
从某一用户出发,爬取用户的粉丝列表,以这些粉丝作为种子用户。
2)获取用户关注关系信息。
从种子用户出发,逐层爬取并记录用户之间的关注关系信息(每个单向关注作为一条记录)。
3)获取微博用户语料。
从用户关注关系出发,统计关注关系中所有的微博用户,选取关注关系较为理想的微博用户,进而爬取微博用户的所有信息。其中本文选取微博文本的时间跨度为2014年10月-2016年4月,数据规模统计如表2所示。

表2 数据规模
3.1 实验结果
在测试数据集上,通过对用户信息的预处理,统计用户可信度评价的各个指标,部分结果如表3所示。其中,表中的用户指标是通过式(2)~(9)所得。为了减小各个指标的波动性,本文进行归一化处理,使指标的范围在[0-1]。表3中的用户对应的可信度评价值如表4所示。表5列出利用本研究方法得到的用户可信度排名和微博风云榜[14]给出的2016年4月9号微博用户排名中共同用户对比的Top10结果。
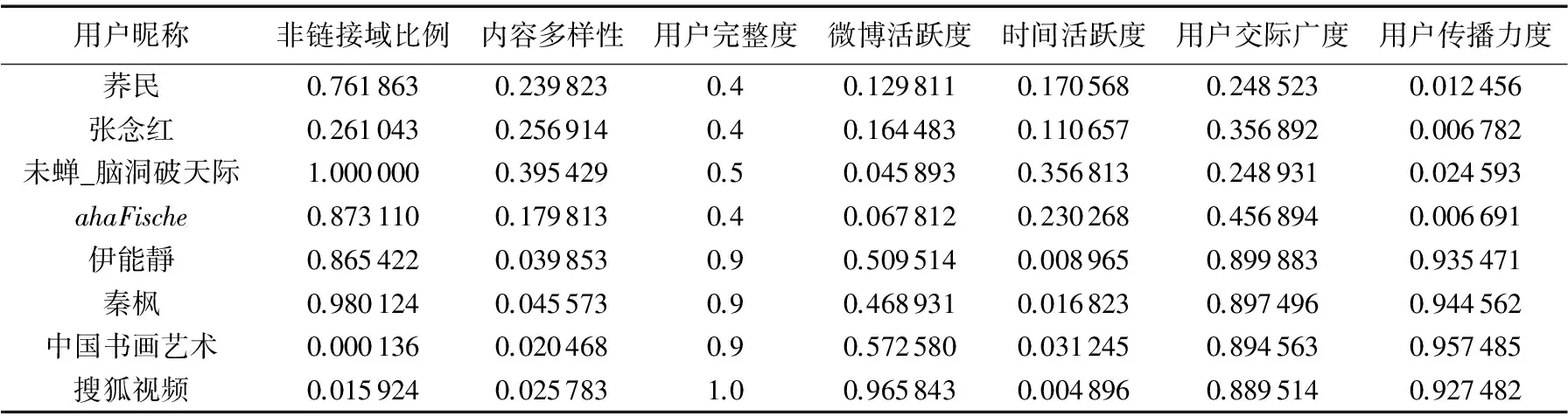
表3 部分用户信息的对应指标
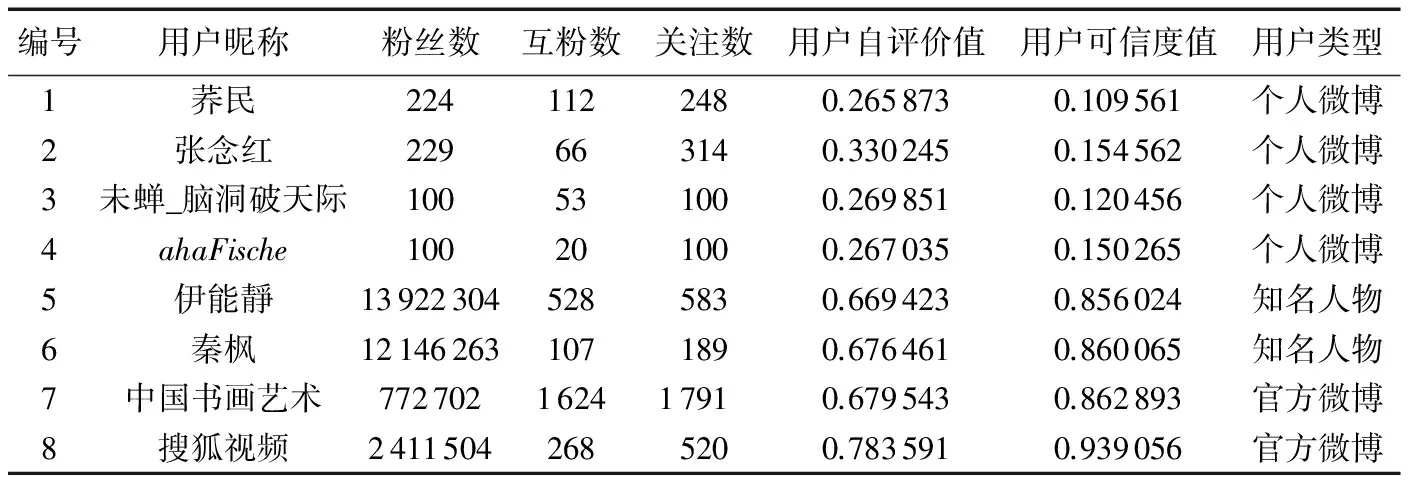
表4 部分用户可信度评价值
3.2 模型分析
从表4中可以看出:知名人物、娱乐明星以及官方认证机构的微博用户可信度值一般较高;而对于普通的个人微博用户来说,其可信度值一般较低。
通过对表3和表4的综合分析可以看出:对于一般用户来说,其用户完整度一般都不高,说明用户的基本信息不全;微博活跃度不高和时间活跃度较大,说明了用户近期大都没有发布或转发微博的行为;用户的关注数与粉丝数较少,在一定程度上决定其交际广度和传播力度较低;正是由于普通的个人微博基本信息不全,并且其在微博信息网络中没有什么活跃性,那么微博用户的可信度值必然较低。而对于知名人物的微博来说,由于其具有大量的粉丝,其发布的信息可以迅速地在微博关系网络中得到其他用户的响应,所以其可信度一般都较高。因此,模型的计算结果符合人们对不同类别的用户群体的可信度认知,也符合本文计算用户可信度得出的一般性结论。
对表4中记录1和2、5和6、7和8两两比较,不难看出,在不考虑用户关系网络情况下,用户粉丝较多的用户,其自评价值相应地也较高。针对微博用户关系网络中用户之间双向指向的关联关系,本文在用户关系之间引入权值,对表4中记录1和2、3和4、5和6两两比较,可以看出在考虑互粉对用户可信度影响后,在粉丝数相同或差不多的情况下,拥有较多的互粉的用户的可信度值较低,这是因为新浪微博中存在互粉现象,在对用户粉丝数统计时,是存在“灌水”的可能性,所以在不考虑互粉影响下,用户自评价的可信度模型的评价值不合理。这也证明了本文引入的用户可信度评价模型,在一定程度上避免了用户的可信度排名不合理的问题。
从表5可以看出,通过本文计算的用户可信度排名具有一定的合理性。通过对比,可以看出,本文对用户可信度的排名与微博风云榜给出的微博用户的排名在趋势上是一致的。然而模型的构建均是针对用户历史数据的计算,因此这个模型数值只能在一段时间内有效。
4 结语
本文主要研究了微博用户可信度的问题。首先提取用户的资料信息、交互信息和行为信息的7种特征,来度量用户自评价可信度;随后结合用户关系网络和用户自评价可信度,提出了一种基于关系网络中用户权值分配的User-Rank用户可信度评价方法。结合真实微博用户数据进行相关实验,结果表明,本文提出的用户可信度评价方法,不仅考虑了用户本身各类信息特征,而且综合考虑关系网络中其他用户的可信度对该用户的可信度度量的影响,为用户可信度分析提供高性能评价方法。
在接下来的研究工作中,将从以下两个方面进一步改进算法。
1) 探索其他因素对微博用户可信度评价特征的影响。例如。对微博转发、评论特征统计时,考虑与传播学理论相结合,挖掘微博被转发、评论的原因,对特征进一步综合分析。
2) 进一步探究可信度分析方法。通过综合评估分析各个指标对用户可信度的影响,合理权衡对应的阈值,实现对用户可信度更有效的度量。
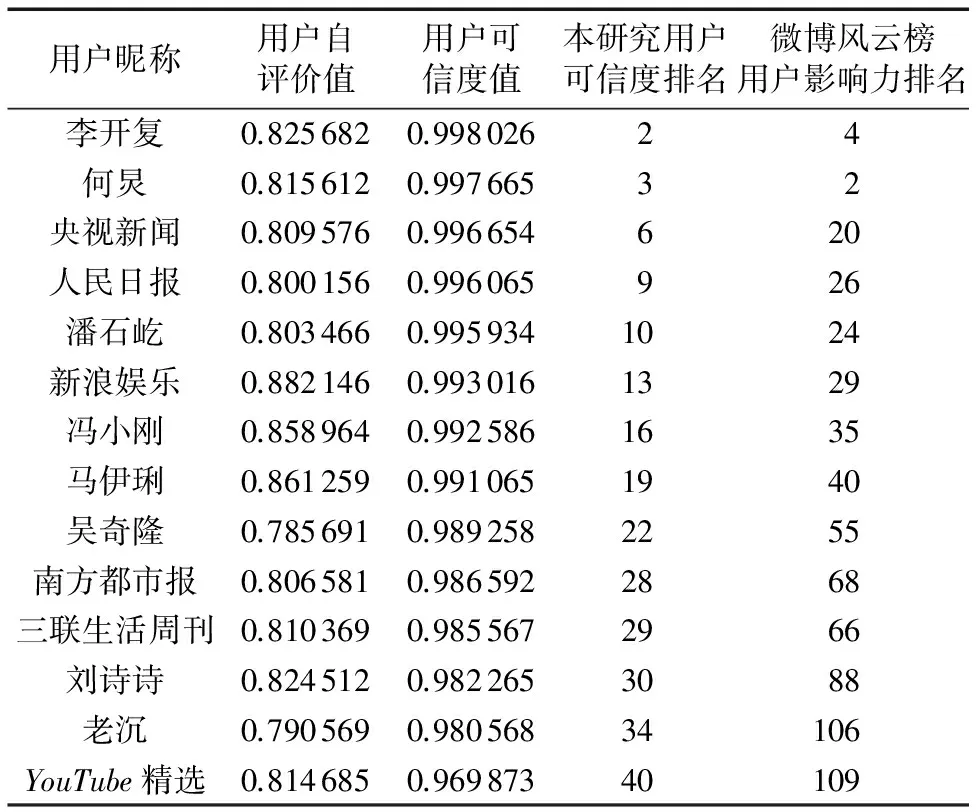
表5 用户可信度排名
)
[1] 中国互联网络信息中心.2015年中国社交应用用户行为研究报告[EB/OL].[2016- 04- 08].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/sqbg/201604/P020160722551429454480.pdf.(ChinaInternetNetworkInformationCenter.Chinasocialapplicationuserbehaviorresearchreport2015 [EB/OL]. [2016- 04- 08].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/sqbg/201604/P020160722551429454480.pdf.)
[2] 新华网舆情监测分析中心.2015年上半年全国政务新媒体综合影响力报告[EB/OL].[2015- 08- 18].http://news.xinhuanet.com/yuqing/128137211_14399521067501n.doc. (XinhuaPublicOpinionMonitoringandAnalysisCenter.Reportonthecomprehensiveinfluenceofthenationalgovernmentnewmediainthefirsthalfof2015 [EB/OL]. [2015- 08- 18].http://news.xinhuanet.com/yuqing/128137211_14399521067501n.doc.)
[3] 蒋盛益,陈东沂,庞观松,等.微博信息可信度分析研究综述[J].图书情报工作,2013,57(12):136-142.(JIANGSY,CHENDY,PANGGS,etal.ResearchreviewofinformationcredibilityanalysisonMicroblog[J].LibraryandInformationService, 2013, 57(12): 136-142.)
[4] 文坤梅,徐帅,李瑞轩,等.微博及中文微博信息处理研究综述[J].中文信息学报,2012,26(6):27-37.(WENKM,XUS,LIRX,etal.SurveyofMicroblogandChineseMicrobloginformationprocessing[J].JournalofChineseInformationProcessing, 2012, 26(6): 27-37.)
[5] 张成.社交网络中的用户行为特征分析与挖掘[D].北京:北京邮电大学,2014:15-46.(ZHANGC.Characteranalysisandminingofuserbehaviorinonlinesocialnetwork[D].Beijing:BeijingUniversityofPostsandTelecommunications, 2014: 15-46.)
[6] 徐恪,张赛,陈昊,等.在线社会网络的测量与分析[J].计算机学报,2014,37(1):165-188.(XUK,ZHANGS,CHENH,etal.Measurementandanalysisofonlinesocialnetworks[J].ChineseJournalofComputers, 2014, 37(1): 165-188.)
[7]CHAM,HADDADIH,BENEVENUTOF,etal.Measuringuserinfluenceintwitter:themillionfollowerfallacy[C]//ICWSM2010:Proceedingsofthe4thInternationalAAAIConferenceonWeblogsandSocialMedia.MenloPark,CA:AAAIPress, 2010:10-17.
[8]BAKSHYE,HOFMANJM,MASONWA,etal.Everyone’saninfluencer:quantifyinginfluenceontwitter[C]//WSDM2011:Proceedingsofthe4thACMInternationalConferenceonWebSearchandDataMining.NewYork:ACM, 2011: 65-74.
[9]CASTILLOC,MENDOZAM,POBLETEB.Informationcredibilityontwitter[C]//Proceedingsofthe20thInternationalConferenceonWorldWideWeb.NewYork:ACM, 2011: 675-684.
[10] 毛佳昕,刘奕群,张敏,等.基于用户行为的微博用户社会影响力分析[J].计算机学报,2014,37(4):791-800.(MAOJX,LIUYQ,ZHANGM,etal.SocialinfluenceanalysisforMicro-bloguserbasedonuserbehavior[J].ChineseJournalofComputers, 2014, 37(4): 791-800.)
[11] 张绍武,尹杰,林鸿飞,等.基于用户分析的微博用户影响力度量模型[J].中文信息学报,2015,29(4):59-66.(ZHANGSW,YINJ,LINHF,etal.AMicro-bloguserinfluentialmodelbasedonuseranalysis[J].JournalofChineseInformationProcessing, 2015, 29(4): 59-66.)
[12]AL-KHALIFAHS,AL-EIDANRM.Anexperimentalsystemformeasuringthecredibilityofnewscontentintwitter[J].InternationalJournalofWebInformationSystems, 2011, 7(2): 130-151.
[13]SAATYTL.Howtomakeadecision:theanalytichierarchyprocess[J].EuropeanJournalofOperationalResearch, 1990, 48(1): 9-26.
[14] 微风云.微风云榜[EB/OL].[2016- 04- 09].http://www.tfengyun.com/rankings.php.(TFENGYUN.MicroChart[EB/OL]. [2016- 04- 09].http://www.tfengyun.com/rankings.php.)
ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61370139),theProjectofConstructionofInnovativeTeamsandTeacherCareerDevelopmentforUniversitiesandCollegesUnderBeijingMunicipality(IDHT20130519).
LI Fumin, born in 1990, M. S. candidate. His research interests include Chinese information processing, data mining.
TONG Lingling, born in 1984, Ph. D., senior engineer. Her research interests include multimedia content analysis and coding, natural language processing.
DU Cuilan, born in 1966. Her research interests include network information security, natural language processing.
LI Yangxi, born in 1982, Ph. D.candidate, senior engineer. His research interests include machine learning, data mining.
ZHANG Yangsen, born in 1962, Ph. D., professor. His research interests include Chinese information processing, artificial intelligence, Web content security.
Weibo users credibility evaluation based on user relationships
LI Fumin1, TONG Lingling2*, DU Cuilan2, LI Yangxi2, ZHANG Yangsen1
(1.InstituteofIntelligenceInformationProcessing,BeijingInformationScienceandTechnologyUniversity,Beijing100192,China; 2.NationalComputerNetworkEmergencyResponseTechnicalTeam/CoordinationCenterofChina,Beijing100190,China)
With the deepening of Weibo research, credibility evaluation of Weibo users has become a research hotspot. Aiming at the problem of Weibo users’ credibility evaluation, a user confidence analysis method based on association was proposed. Taking Sina Weibo as the research object, firstly, seven characteristics of the user from three aspects: user information, interactive information and behavior information were analyzed, and the user self-evaluation credibility was got by using Analytic Hierarchy Process (AHP). Then, by using the user self-evaluation as the base point, the user relationship network as the carrier, and the potential users’ evaluation relationship among the users, was improved the PageRank algorithm, and the user credibility evaluation model called User-Rank was proposed. The proposed model was used to evaluate comprehensively credibility of users by other users in relational network. Experiments on large scale Weibo real data show that the proposed method can obtain good evaluation results of user credibility.
user self-evaluation; relationship network; user credibility; user relationships; Analytic Hierarchy Process (AHP); PageRank
2016- 09- 30;
2016- 10- 20。
国家自然科学基金资助项目(61370139);北京市属高等学校创新团队建设与教师职业发展计划项目(IDHT20130519)。
李付民(1990—),男,河南商丘人,硕士研究生,CCF会员,主要研究方向:中文信息处理、数据挖掘; 佟玲玲(1984—),女,辽宁阜新人,高级工程师,博士,主要研究方向:多媒体内容分析与编码、自然语言处理; 杜翠兰(1966—),女,湖北武汉人,主要研究方向:网络信息安全、自然语言处理; 李扬曦(1982—),男,甘肃兰州人,高级工程师,博士研究生,主要研究方向:机器学习、数据挖掘; 张仰森(1962—),男,山西临猗人,教授,博士,CCF高级会员,主要研究方向:中文信息处理、人工智能、Web内容安全。
1001- 9081(2017)03- 0654- 06
10.11772/j.issn.1001- 9081.2017.03.654
TP393.092
A
