基于相似性分析的时间序列异常检测方法
2017-05-22孙焱,林意
孙 焱,林 意
江南大学 数字媒体学院,江苏 无锡 214000
基于相似性分析的时间序列异常检测方法
孙 焱,林 意
江南大学 数字媒体学院,江苏 无锡 214000
时间序列数据是按照时间顺序在不同的时间点采集的数据,反映了某一对象随时间的变化状态和程度。由于时间序列的海量性及复杂性,我们采用频域表示时间序列,并以此为基础提出了基于相似性分析的时间序列异常检测方法。将动态模式匹配距离作为衡量相似性的指标,计算每一个模式同其余各模式之间的相似性,据此确定异常状态。该方法大大降低了数据搜索复杂度,提高了系统效率与准确度。
时间序列;相似性分析;动态模式匹配;异常检测
近年来伴随着社会经济的高速发展以及科学技术的巨大进步,计算机技术也获得了巨大的进步。随着信息时代的到来,人类社会对于外界信息的依赖变得越来越重要同时也产生了海量的信息数据。另一方面这些数据的产生速度可以用惊人来形容,只需要短短一年甚至几个月整个人类社会的信息量就可以增长一倍。而采用哪种有效手段管理并挖掘出这些海量数据中所隐藏的规律与知识则成为了当代研究者们所关注的热点话题,因此数据挖掘技术在当代社得越来越重要。
时间序列作为一种广泛存在于医学、工程、商业以及自然科学等领域数据库中的常见数据形式,近年来得到了研究人员越来越多的关注[1]。对其进行相关性分析并在此基础上进一步进行数据搜索匹配成为了数据挖掘的重要步骤。时间序列异常是指在数据集中某一数据偏离大部分数据,其数值特性已经超出了随机偏差的范围,而更有可能是由不同机制产生的[2-4]。为了能够有效检测出时间序列数据中的异常数据,本文提出了基于相似性分析的时间序列异常检测方法。首先通过建立合适的时间序列模型来抽象化数据,降低搜索复杂度,便于检索;随后通过一个滑动的窗口平滑处理时间序列,计算其和其他模式的相似度以确定其是否异常。
本文的结构安排如下:首先给出了时间序列模型对数据进行抽象化处理,随后介绍对时间序列进行相似性度量的各类方案,紧接着提出了时间序列异常检测的方案,最后通过仿真实验来验证分析该方案的可行性。
1 时间序列的模型
因为时间序列一般都是高维数的,假如直接要在原始的数据中进行数据挖掘需要付出高昂的代价,其复杂性高效率低下,也会降低算法的准确性和可靠性。针对这个问题,必须采用合适的抽象方法对时间序列进行抽象建模,以达到简化数据模型,去除冗余,搭建出符合要求的数据库索引的目的[5-7]。虽然直接采用传统时间序列分析方法理论上同样可以解决相似性分析的问题,但是实际运用时间复杂度。因此,必须能够建立一个合适的数据模型,以同时具有 高鲁棒性和低复杂度的优中效果差,因为相似性度量的计算依赖于时间序列的表示方式,这会大大影响计算过程的点,这会大大提高数据索引的效率。
在这里我们采用频域表示法,由于离散傅里叶变换DFT开头的几个系数表现突出,能够保留信号的绝大部分能量,因此可以只留存DFT头几个系数而直接删除其余系数同时保留下了数据的大部分特征来达到数据压缩的目的,这样做也保留了原始时间序列的基本特性[8]。


DFT变换同时对原始时间序列中的局部极大值与局部极小值都进行了数据平滑,这样做使得数据的部分重要信息丢失。除此之外DFT还对序列的平稳性有着较高的要求,其对于非平稳的序列并不适用。而且DFT变换以相同长度的系数来度量所有长度的时间序列,降低了方法的合理性。因此,在此基础上我们提出使用滑动窗口的简单平滑方法,不但可以去除噪声,也较为真实地反映出数据的实际特性。具体操作如下:
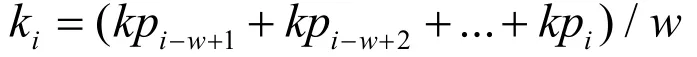
2 时间序列的相似性度量
2.1 Minkowski距离
欧几里得距离是平时最常用的一种距离计算方式。假定长度为n的时间序列看作是一个n维欧式空间中的点,它的坐标点则对应着时间序列在各个时间点的取值,则两条长度为n的时间序列之间的欧氏距离就是这个n维空间中两点的距离[9-11]。其可以作如下描述:

Minkowski距离作为相似性度量距离,其是欧氏距离的推广,如下定义:

当p=2时,Minkowski距离就成为了欧式距离,而在p=1时则变成了曼哈顿距离;当p趋于无穷大时则称为最大距离。由于Minkowski距离同样满足非负性即所有值不小于零、对称性以及距离三角不等式,所以该距离也能够作为一种度量距离。
正是由于Minkowski距离具有满足三角不等式的特性,所以在基于索引进行数据查询时,能够根据这一特性将其作为索引距离,快速过滤某些不符合索引条件的节点,从而提高索引速度。
Minkowski距离应用于数据索引的相似性度量时具有诸多优点,其简单直观,计算简便,具有非常高的可扩展性,同样可以应用于数据地查询以及聚类等方面。然而Minkowski距离应用在时间序列数据挖掘时却不具备很好的可靠性,其对于时间序列自身的噪声以及波动不具备很好的鲁棒性,相似的时间序列也会存在着多种变形,例如振幅平移与伸缩、线性飘逸、不连续、时间轴伸缩等等。
2.2 动态模式匹配距离
虽然Minkowski距离计算简便,在索引查询以及聚类领域有很优秀大表现,但是其对于时间序列的时间轴弯曲以及伸缩并不友好。所以为了能够更好的进行时间序列的相似性分析,这一节提出使用动态模式匹配距离,同传统距离所不同的是,动态模式匹配距离并不是根据两个目标点之间的距离进行计算,而是通过模式匹配进行。这样做一方面是因为模式的定义较为灵活,同时因为时间序列的模式一般远远小于序列的长度,这样可以降低计算的数据量,提高算法效率。模式之间的距离使用加权欧氏距离进行定义:
假定给定两个模式p1=(l1,k1)和p2=(l2,k2),其中l和k分别表示模式的长度与斜率,则两个模式之间的距离可以如下定义:

在以上定义中,分母的作用是将长度和斜率这两个不同的量纲进行统一,而取最小值则是为了能够突出短模式的重要性。

公式中d(px1,py1)表示的是px1与py1之间的模式距离,而P(X)-px1和P(Y)-py1分别表示P(X)和P(Y)去除了第一个元素后的序列。
从上述公式可以看出,模式是由他的长度和斜率这两个特征表示。由于模式的长度与时间序列的振幅大小无关,而其斜率则体现了时间序列振幅的相对大小,所以所提的动态模式匹配距离可以克服时间序列的振幅平移与伸缩变换。除此以外,因为采用了模式的动态匹配方法,可以实现时间序列在时间轴上的伸缩和弯曲。
动态模式匹配距离可以使用累积距离矩阵的方法进行计算,这样的话其时间复杂度就为O(mn/uv),这其中的m和n分别表示两个时间序列的长度,而u和v则表示模式的平均长度。由此可见,如果模式的平均长度越长的话,动态模式匹配的时间复杂度就越低。进一步可以看出,采用动态模式匹配距离的计算方法要远远优于Minkowski距离计算。
3 时间序列的异常检测
3.1 时间序列的异常模式
异常可以简单理解为在一个时间序列数据集中,其某一个数据点的值与其他数据点值存在非常明显的差别,超出了随机产生的可能,有可能是因为不同的机制而产生的,这一类数据就称为异常。如图中就是一种直观的异常模式。其中的点3,4,5,6,7单独来看时,其值与整体数据而言并没有什么差异,然而当这些数据在时间上连续出现时就形成了整个时间序列中的异常数据。

图1 时间序列异常Fig.1 The abnormal time series
3.2 K-近邻原理
某一点p的k-近邻距离(k-dist(p))可以如下定义[12-14]:假定k是一个正整数,D则是一个数据点的集合,而p为改数据集中的一个点,p点的k-近邻距离应当满足以下两个条件:
(1)数据集D中至少有k个数据点(p点除外),这些数据点到p点距离不大于k-dist(p)。
(2)数据集D中至多有k-1个数据点(p点除外),这些点到p点的距离小于k-dist(p)。
如图所示,当k=4时,点p的k-近邻距离k-dist(p)=d(p,u),d(p,u)即表示点p到u的距离。
在数据集D中,点p到点t的k-近邻可达距离r-dist(p,t)可以定义为:

点q的k-局部可达密度l rd(q)可以定义为:
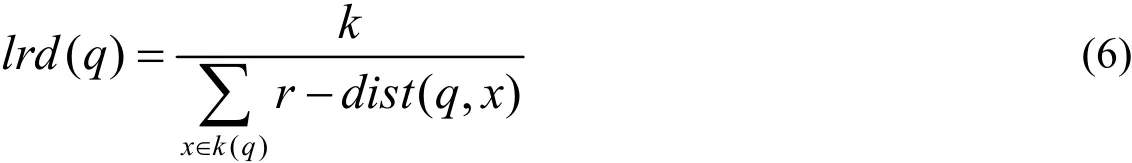
以上公式中,k(q)表示q点的近邻范围,由局部密度的定义方式,可以看出该密度反应的是点q周围的数据点分布情况,如果密度越高表示在数据集中类似于点q的点越多,同时也表明点q是异常数据的概率也越小。
数据集D中,点q的局部异常系数LOF(q)可以如下定义:

如上公式所示,如果局部异常系数越大则表明q点的局部范围内数据点较为稀疏,则其为异常点的可能性也就越大[15,16]。
3.3 基于相似性分析的异常检测算法
基于相似性分析的异常检测算法不是直接对比目标两个点,而是采用2.2节中提出的动态模式匹配距离,将两个模式进行比较。由于模式的数据量远远小于原始数据量,这样就极大地降低了需要检测的数据量,降低了算法的复杂度。同时也对噪声进行了过滤。并且使用这种方式计算出的异常是一个目标范围而不再是单单的某一个数据点,这极大地提高了算法的鲁棒性与合理性而且也更加符合实际。
该方法的流程图如图所示,第一步将目标时间序列进行频域抽象化表示,形成模式化后的序列数据;第二步计算每一个模式同其余模式之间的模式距离分析其相似性,计算k-近邻距离,紧接着根据公式6和公式7计算出每一个模式的局部密度以及局部异常因子;最后选取具有较大局部异常因子的模式判定为异常模式。

图2 时间序列异常检测流程Fig.2 The detection process of abnormal time series
4 实验结果与分析
4.1 方法验证
这部分我们对所设计的方法进行仿真验证,采用dell便携机作为仿真主机,频率2.27 GHz,内存4 G,基于MATLAB进行仿真分析。验证分为两个部分,分别是对该方法的可行性以及可靠性进行测试。可行性测试的方法是通过MATLAB仿真对一系列随机产生的数据进行模式距离计算后计算出每一个点的局部异常系数,并输出异常数据。

图3 可行性验证结果图Fig.3 The verification results for feasibility
如图所示,对产生的一系列时间序列模式化后计算出了每一个数据点的拒不异常系数,并将其直观地用圆的半径表示,半径越大则该点的异常系数越大,其为异常模式的可能性也就越大。设置合适的阈值之后就可以通过比较判别出异常模式,如图中黑色圆所示。
随后我们对该方法的可靠性进行验证,探讨其在不同数据量下的检测准确性与时间消耗。

图4 不同数据量下准确度(%)Fig.4 The detection accuracy on different data

图5 不同数据量下检测时间Fig.5 The detection time on different data
如图4所示为改方法在不同数据量下的准确度,可以看出随着检测数据量的不断增加,该方法虽然准确度有所下降但是依然保持着非常高的准确性。从图5中可以看出,随着数据量的增多,方案的检测时间迅速增加,表明该方法对于算法的复杂度优化方面还存在着缺陷。综上所述,该方法可以有效对于时间序列的异常进行检测,并且在大数据量下依然具有非常高的准确性,但是其时间消耗方面需要进一步优化。
4.2 方案不足
该方法基于相似性的分析设计了时间序列异常检测的方法,虽然可以有效完成异常检测的目标,但是也存在着一些不足之处:
(1)对于时间序列的模式化还有着其他许多更优秀的方法,而不单单是频域表示,如分段线性表示法等,可以采用其他抽象方法进行对比仿真。
(2)虽然动态模式匹配距离获得了很高的准确性,但是其算法的速度依然有待提高,可以对其进行进一步的优化。
5 结论
本文基于相似性分析,结合局部密度计算数据点的数据密度设计了基于相似性分析的时间序列异常检测方法。提出了动态模式匹配距离,使用模式而不是空间中的两个点进行距离计算,模式的距离就直观反映了每一个模式与其余模式之间的相似性,该距离很好的克服了时间序列振幅平移、时间伸缩等困难,采用频域表示法模式化时间序列极大地降低了数据量,提高了算法效率。同时结合局部密度计算算法有效检测了每一个目标数据的异常情况。总结而言,该方法不但可以有效检测出异常数据,而且极大地降低了数据量提高了算法效率,同时可以克服时间序列的伸缩等缺陷,具有很好的扩展性。
[1]陈海燕,刘晨晖,孙 博.时间序列数据挖掘的相似性度量综述[J].控制与决策,2017,2(1):1-11
[2]陈 然.基于相似性分析的时间序列异常检测研究[D].重庆:西南交通大学,2011:30-33
[3]肖 辉.时间序列的相似性查询与异常检测[D].上海:复旦大学,2005:33-40
[4]曹文平,熊启军,罗 颖,等.基于相关性分析的时间序列异常检测方法[J].信息系统工程,2012,22(10):131-132
[5]闫明月.时间序列相似性与预测算法研究及其应用[D].北京:北京交通大学,2014:18-30
[6]李 权,周兴社.一种新的多变量时间序列数据异常检测方法[J].时间频率学报,2011,34(2):154-158
[7]唐 亮.时间序列挖掘和相似性查找技术的研究[D].上海:上海师范大学,2004:18-20
[8]方加果.基于相似性分析的时间序列数据挖掘算法研究[D].杭州:浙江大学,2011:33-35
[9]杨永强.基于相似性分析的时间序列数据挖掘研究[D].重庆:西南交通大学,2007:22-25
[10]曾海泉.时间序列挖掘与相似性查找技术研究[D].上海:复旦大学,2003:20-30
[11]冯 钧,陈焕霖,唐志贤,等.一种基于 DTW 的新型股市时间序列相似性度量方法[J].数据采集与处理,2015,30(1):99-105
[12]张 军.基于时间序列相似性的数据挖掘方法研究[D].南京:东南大学,2006:33-39
[13]邱均平,王菲菲.时间序列相似性查询与索引方法研究[C].中国索引学会年会暨学术研讨会,2009:4-8
[14]门连生,卫婧菲,李 中.基于形态相似距离的时间序列相似性度量[J].计算机工程与应用,2015,51(4):120-122
[15]刘 杰.时间序列相似性查询的研究与应用[D].北京:北方工业大学,2016
[16]刘永志.基于两点的时间序列相似性研究[J].盐城工学院学报:自然科学版,2014,27(4):1-4
The Detection Method onAbnormal Time Series on account of Similarity Analysis
SUN Yan,LIN Yi
School of Digital Media/Jiangnan University,Wuxi 214000,China
Time series data are collected at different time points according to the time order to reflect an objective variation states and contents with time.This paper took frequency domain to express the time series in consideration of the magnanimity and complexity of time series and propose the detection method on abnormal time series on account of similarity analysis to take a dynamic pattern matching distance as a index to calculate the similarity between every model and others hereby to ensure the abnormal state.This method could greatly reduce the complexity in data search and improve the efficiency and accuracy of the system.
Time series;similarity analysis;dynamic pattern matching;abnormal detection
TP39
:A
:1000-2324(2017)02-0287-06
10.3969/j.issn.1000-2324.2017.02.026
2016-08-23
:2016-10-02
孙 焱(1992-),男,研究生.研究方向:时间序列数据挖掘.E-mail:thierry14henry12@163.com
