基于聚类技术的网络学习行为数据分析研究
2017-05-19陈萍
陈萍
(广东青年职业学院计算机工程系,广东广州 510507)
基于聚类技术的网络学习行为数据分析研究
陈萍
(广东青年职业学院计算机工程系,广东广州 510507)
在“互联网+”时代,网络学习已经成为学校教育教学的重要组成部分。文章选取某高职院校《计算机应用基础》网络课程为分析对象,运用聚类技术对高职院校学生在线学习行为进行数据分析,建立学生特征分类模型,为教师优化教学提供决策参考、为学生推送学习建议,以提高网络教学的效果。
聚类技术;网络学习行为;计算机应用基础;数据分析
1 引言
随着移动互联网、云计算、大数据为特征的新一代信息技术的快速发展,学生获取知识的方式也与时俱进,结合在线学习和面授教学的混合式学习方式正在高职院校日益兴起。作为一名高职教师,作者积极参与学院的网络教学资源建设,运用网络信息技术手段进行教学。同时,在教学实践中产生了一些困惑:学生的考试成绩与其在线学习行为、特征是否有关联呢?什么样的学习行为是有效的?教师该如何优化网络课程,为学生提供更具有个性化的教学服务?同时,发现学院的教学管理信息系统、网络自主学习平台积累了大量的教学数据,比如学生的基本信息、登陆数据、闯关学习、测试及学习交流等数据。因此,希望借助聚类技术等数据挖掘方法,对学生在线学习数据进行分析,探索问题的答案。
2 聚类技术挖掘和K-means聚类算法
2.1 基本概念
数据挖掘(Data Mining)是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的,但又潜在有用的信息和知识的过程[1]。近年来,信息化引领着教育模式不断创新,在线学习系统、智能手机应用、社交网络、MOOC课程等提供了大量的数据,教育数据挖掘及分析也成为教育领域的热点。
聚类分析是数据挖掘应用的主要技术之一,可作为发现数据分布和模式的独立工具。例如,在保健业,聚类分析腰椎间盘突出患者有哪些不良的生活习惯,可以帮助预防和保健;在证券业,可以聚类分析客户的投资热点板块。聚类分析属于动态分类的方法,分类的数目是未知的,把数据集分为若干不同类别,使同类数据尽可能相似,异类数据尽可能相异。
2.2 K-means聚类算法
聚类分析包含许多算法,其中基于距离的方法最直观,划分聚类算法就是其中的一种,划分聚类算法中最常用的方法是K-means聚类算法,其他许多方法都是在此基础上演变的。聚类算法K-means是一种被广泛应用于科学研究的经典算法,许多统计分析工具软件包都使用它来进行聚类分析。算法的核心思想是通过迭代,把数据集划分为聚类性能最优的不同类别。算法主要步骤如下:
(1)在包含m个数据对象的数据集中,任意选p个作为聚类中心的初始点。
(2)计算每个数据对象与聚类中心初始点的距离,并把它划分到距离最近的初始点所表示的类别中。
(3)重新计算每个有变化聚类的均值。
(4)循环执行(2)到(3)直到每个聚类比较稳定,即误差平方和标准函数的值为最优。
(5)输出聚类的最终结果。
3 学生网络学习行为的聚类分析
3.1 确定挖掘目标
近几年,高职院校的《计算机应用基础》课程普遍采用“网络自主学习平台+线下课堂教学”的混合式教学模式,课堂教学的学时大量缩减。作为公共必修课,学院往往要求非计算机专业学生要通过计算机I级考证,而学生个体之间存在较大的差异性,因此,要提高考证通过率,教师要引导学生有效地进行网络自主学习。
已有研究,网络学习行为与网络学习效果有密切相关[2]。因此,通过网络学习平台获取学生的学习行为数据,应用聚类技术,建立学习者特征模型,有利于教师掌握学生的学习特征,从而优化教学策略。
3.2 数据采集
本研究选取某高职院校《计算机应用基础》网络自主学习平台2015级新生的数据作为数据源,保存为excel格式,格式如表1所示;选取由广东省高等学校教学考试管理中心提供的学生期末考证成绩表,保存为excel格式,如表2所示。
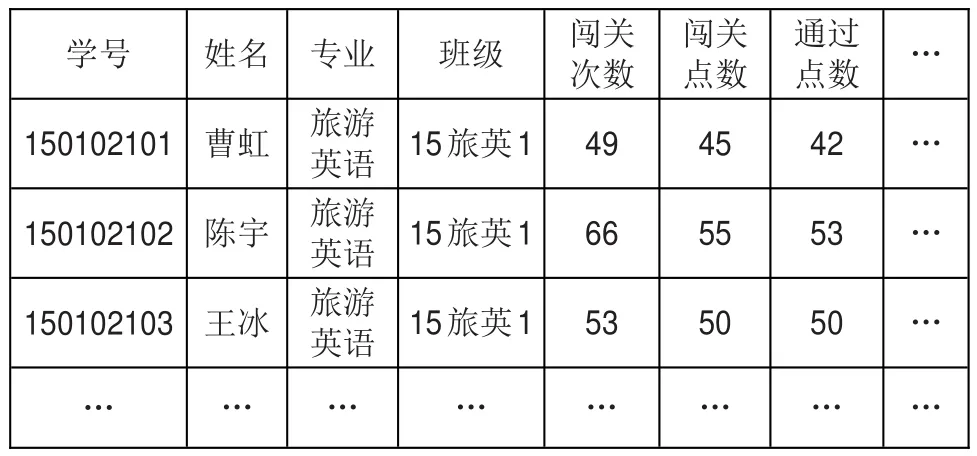
表1 自主学习情况表
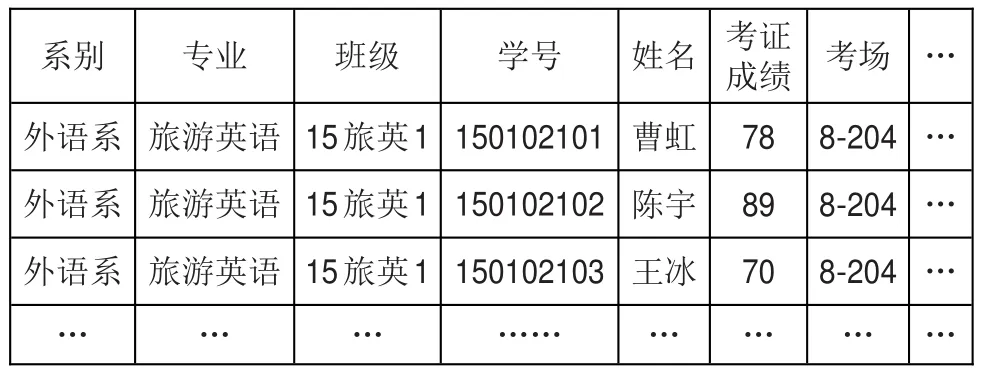
表2 考证成绩表
3.3 数据预处理
根据原始数据表,采用Microsoft SQL Server 2008建立数据库。数据表包括:
(1)自主学习情况表(study_student),该数据表主要包含的字段有student_ID(学号)、name(姓名)、major(专业)、class(班级)、cgcs(闯关次数)、cgds(闯关点数)、passds(通过点数)等信息。
(2)考证成绩表(score_student),该数据表主要包含的字段有department(系别)、major(专业)、class(班级)、student_ID(学号)、kzcj(考证成绩)等信息。
为了有效挖掘,需要对以上数据表进行数据清理,避免出现包含噪声、不完整、不一致的数据。例如采用忽略元组法将缺考、休学、退学、转学学生的相应记录删除;个别学生由于某些原因,没有正确录入分数的,把分数补录正确。通过数据预处理,采集到1359条有效数据记录。
根据聚类分析挖掘需要,把自主学习情况表(study_student)和考证成绩表(score_student)结合生成一张新的数据表,并根据经验选择网络学习行为,将对分析影响较小的一些冗余字段(如姓名、考试时间、考场、系别等)和意义相似的重复字段(如闯关点数)删除,得到挖掘目标数据表。kmeans聚类算法不适合处理离散型属性,因此数据集采用连续性描述属性,建立挖掘模型结构如表3所示。
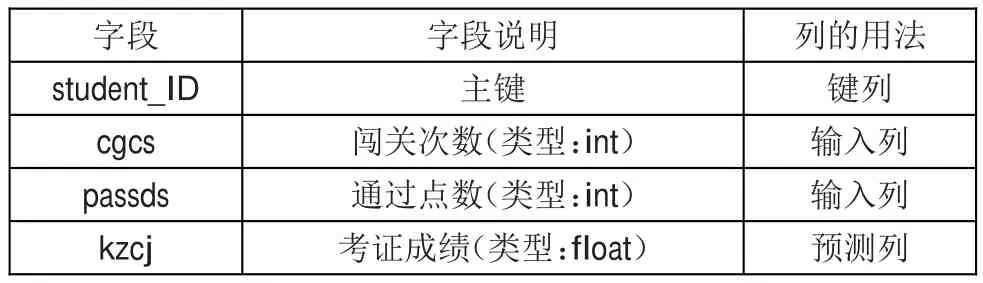
表3 学生网络学习行为聚类分析的建模数据结构
3.4 聚类分析的应用
采用Microsoft SQL Server 2008 Analysis Service(SSAS)的K-means算法进行挖掘,算法运行的硬件平台:Intel Core I3-3220、4G内存,软件平台:Windows7、SQL Server 2008。将考证成绩(kzcj)作为主要预测对象,闯关次数(cgcs)和通过点数(passds)作为输入对象,建立聚类挖掘模型。
用K-means聚类算法进行数据挖掘,得到网络学习行为的主要分类,如图1所示。在分类剖面图中,每个分类属性以及属性的分布显而易见,列标题处显示各分类的统计数据。菱形图显示连续属性,表示每个分类的平均偏差和标准偏差。在7个分类中,学生人数最多的是分类1、分类2、分类3。分类1中网络学习行为cgcs和passds的值适中,分类2中cgcs和passds的值较大,分类4中cgcs和passds的值偏低。

图1 聚类挖掘分类剖面图
3.5 聚类挖掘结果分析
通过分析学生网络学习行为分类剖面图,归纳出以下几种存在显著差异的网络学习行为特征:
A类:学习积极型。此类的典型代表是分类2,人数较多;学生在学习方面积极追求上进,闯关次数和通过点数非常高,考证成绩优良。分类2的特征表现为:闯关次数(cgcs)的值介于89到135之间,平均值为112.01;通过点数(passds)的值介于80到93之间,平均值是88.6;考证平均成绩为81.23分。
B类:学习中等型。此类的典型代表是分类1,人数最多;学生在学习方面表现一般,各项指标适中,考证成绩也一般。分类1的特征表现为:闯关次数(cgcs)的值介于36到76之间,平均值为55.69;通过点数(passds)的值介于27到64之间,平均值为45.59;考证平均成绩为72.07分。
C类:学习危机型。此类的典型代表是分类5和分类6,学生的闯关次数和通过点数偏低,学习效率偏低,考试不及格率偏高。分类5的特征表现为:闯关次数(cgcs)的值介于13到33之间,平均值为23.1;通过点数(passds)的值介于9到26之间,平均值为17.71;考证平均成绩为64.43分,考试不及格率较高,达到40.24%。分类6的考试不及格率次高,达到33.9%,具体特征为:闯关次数(cgcs)的值介于28到41之间,平均值为34.62;通过点数(passds)的值介于24到32之间,平均值为28.25;考证平均成绩为66.65分。
D类:学习消极型。此类的典型代表是分类4,学生学习积极性非常低,闯关次数和通过点数非常低,考试成绩不及格可能性最高,达到70.95%。具体特征表现为:闯关次数(cgcs)的值介于0到17之间,平均值为8.89;通过点数(passds)的值介于0到12之间,平均值是6.11;考证平均成绩为52.52分。
通过学生网络学习行为特征的分析,教师可及时发现学生学习上的问题并“因材施教”。
(1)针对A类层次学生,给予高度的赞扬,向他们推荐一些与专业结合的,注重能力和技能的培养的综合实训案例,甚至推荐拓展学习课程,比如计算机二级课程办公软件高级、Photoshop图像处理等。
(2)针对B类层次学生,找准切入点,适当给予激励。中等生往往有“比上不足,比下有余”的心理,教师要善于发现他们身上的闪光点,也是激励他们进取的切入点,引导学生进行自主学习与协作学习,注重实践动手能力的提高。教师可提供反应学科前沿的相关案例,激发学生思考;提供综合能力测试题,鼓励他们多做多练,争取稳中有提升和突破。
(3)针对C类层次学生,要增强他们的危机意识,避免考试不及格。教师需要定期检查和督促他们的学习进度,向他们推荐一些重点知识点,提供重点习题、重点复习资料,传授学习方法与技巧,争取提高考试通过率。
(4)针对D类层次学生,给予严肃的批评教育,并提供课程导学资料、基础练习和复习资料,安排优秀学生给予“一对一”学习帮扶,帮助学生逐步建立学习的自信心。
通过观察四类学生特征,可以预见:加强网络自主学习、加强知识点的在线闯关测试对学生考证所起的积极作用较大。
有学者指出:网络课程结构体系相对完整,学生网上学习时间和次数就会增长[3]。因此,教师要优化网络平台的学习资源,设计分层次学习资源,以满足不同层次学生的学习需求;跟踪学科动态,增强课程的吸引力,提高学生学习兴趣;设计计算机水平摸底考试,帮助学生认识自己的信息技术起点水平,制定学习目标和计划,选择合适的学习方法,有计划地自主学习;激励学生争当积极型学习分子,及时发现和解决疑惑知识点,切忌临考抱佛脚。
4 结语
本文采用了聚类分析方法对学生网络学习行为进行分析,让教师更深入地了解学生,为“因材施教”提供决策参考,辅助修正学生不良的网络学习行为,向学生推荐好的网络学习策略、学习资源。数据挖掘的方法很多,在实际应用中,还可以用其他方法或者多种方法结合起来进行分析研究。实践表明,对大量的数据进行挖掘和分析,可以帮助我们更好地提升网络教学效果。
[1]Han,M Kamber.Data Mining:Concepts and Techniques[M].San Mateo,CA:Morgan Kaufmann,2001.
[2]傅钢善,王改花.基于数据挖掘的网络学习行为与学习效果研究[J].电化教育研究,2014(9):53.
[3]孙莹,程华,万浩.基于数据挖掘的远程学习者网上学习行为研究[J].中国远程教育,2008(5):44-47.
Analysis of Network Learning Behavior Data Based on Clustering Technology
Chen Ping
(Guangdong Youth Vocational College,Guangzhou 510507,Guangdong)
tract】 In the era of"Internet+",online learning has become an important part of school education.This paper takes the course of Foundation of Computer Application as the analysis object;uses the clustering technology to analyze the online learning behavior data of higher vocational college students;establishes the classification model of student characteristics,to provide decision-making reference for teachers and learning advice for students,to improve the effect of network teaching.
words】 clustering technology;network learning behavior;foundation of computer application;data analysis
TP311
A
1008-6609(2017)04-0031-03
陈萍(1976-),女,广东湛江人,硕士,讲师,研究方向为数据库应用、计算机教育等。
广东青年职业学院校级科研项目,项目编号:Y B 201401。
