数据清洗下的改进半监督聚类入侵检测算法研究
2017-05-09周志平陈晓洁
周志平,陈晓洁
(龙岩学院信息工程学院,福建龙岩364000)
数据清洗下的改进半监督聚类入侵检测算法研究
周志平,陈晓洁
(龙岩学院信息工程学院,福建龙岩364000)
针对半监督聚类算法易受噪点的影响,提出一种基于数据清洗的改进半监督聚类算法DCSC。将噪点从数据集中提取出来另行分析。从数据清洗处理后的数据集中抽取若干正常与异常样本分别计算作为初始样本辅助K-Means算法进行聚类。实验结果表明,与现有相关算法相比,该算法具有检测未知攻击的能力,且具有更高的攻击检测率以及更低的误报率。
数据清洗;半监督聚类;入侵检测
计算机网络已融入到人类社会的方方面面,随着网络的快速发展,网络攻击技术和手段也日趋复杂多样,网络安全问题日渐突出。入侵检测是指通过分析网络或者系统中的数据,发现是否存在异常并生产报警信息的过程。入侵检测作为一种有效的网络安全防御技术,引起国内外学者的广泛关注。传统的入侵检测系统(intrusion detection system,IDS)采用模式匹配的方法,从网络或者系统的数据中提取特征并与攻击特征库中的攻击特征进行匹配来识别入侵行为。随着网络技术的发展,基于专家提供的攻击特征库构建越来越困难,使得这种方法存在大量的错报或虚报的情况,并且对于未定义的新型攻击特征无法检测。将数据挖掘技术引入入侵检测中[1],可以大大改善入侵检测系统建模过程中人为以及不定因素的影响。
在入侵检测系统中常用的数据挖掘算法有时序算法、决策树算法、神经网络算法、聚类分析算法等。基于聚类分析的入侵检测是一种无监督的异常检测技术,该方法对无标签的数据集进行操作,将相似的数据样本划分到一个类中,相异的数据样本划分到不同的类中。理想状况下,通过聚类算法,将正常数据与异常数据划分到不同的类中。为了提高聚类算法的检测率,降低误报率,可将半监督学习的思想引入到入侵检测中。半监督学习是近几年来在机器学习领域发展的一种新方法,它综合利用有标签和无标签样本进行学习。将半监督聚类分析引入入侵检测,利用少量的标有正常与异常标签的数据样本对数据集进行约束,辅助聚类算法,减少错报虚报,提高算法的效率。由于数据来源不一,可能存在不同模式的描述,甚至存在矛盾。因此,在数据集成的过程中对数据进行清洗,以消除相似,重复或是异常的数据是非常必要的[2]。本文提出基于数据清洗的半监督聚类算法(data cleaning based semi-supervised clustering algorithm, DCSC),将数据集进行降噪处理,可以改善噪点对于聚类过程的影响,并分别抽取若干正常与异常样本进行初始化,引导后续的聚类过程。
1 相关工作
1.1 K-means算法
K-means算法是一种最常用的基于划分的聚类方法,将目标数据划分为K个类,样本与样本之间的距离采用欧氏距离计算。该算法是基于目标函数的聚类算法,其目标函数为,其中μl为第l个类的质心。该算法的优点是简单,能够高效的处理大型数据,缺点是对初始值K以及随机数敏感,对噪点和孤立点非常敏感,易陷入局部最优解。
算法描述:
输入:聚类数目k。
输出:误差平方和(sum of squared errors,SSE);聚类中各类样本数目。
算法步骤:
Step 1随机选择k个样本作为初始簇质心并进行标准化处理;
Step 2根据簇中对象的平均值,将每个对象赋给最类似的簇;
Step 3更新簇的平均值;
Step 4重复Step 2,Step 3直到重新分配不再变化。
1.2 基于距离的半监督聚类算法
半监督聚类算法[3]是指在数据集中选取若干seed样本作为带有标签的数据样本,以辅助聚类过程,使得聚类结果的精确度更高。文献[4]提出了两种基于距离的半监督聚类算法:Seeded K-Means和Constrained K-Means。两者的差别在于前者的样本标签仅用于初始化,而不参与后续的聚类过程;后者的标签样本在聚类步骤中维持不变,只有非标签样本进行聚类。该算法的初始化如下:
2 基于数据清洗的半监督聚类算法
由于在半监督聚类算法中,seed样本可能混入噪点,而噪点数据对于IDS来说很有可能是未知攻击,并且聚类算法对噪点以及孤立点相当敏感,从而造成IDS性能的不稳定以及检测率的降低。为了降低噪点对半监督聚类算法的影响,检测出未知攻击,提高IDS的检测率,本文提出对数据样本预降噪的方法。采用密度聚类算法进行数据清洗,抽取出噪点由管理员进行进一步分析,将剩余的样本进行聚类,以保持半监督聚类算法的稳定性。
2.1 数据清洗方法
DBSCAN(density-based spatial clustering of applicationswith noise)是一个比较具有代表性的基于密度的聚类方法,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有噪点的空间数据集发现任意形状的聚类,常用于基于孤立点的聚类分析方法。该算法将不满足密度分布的点视为噪点数据,将其抽取出来以降低噪点数据对聚类的影响。提出数据清洗的方法旨在于抽取出DBSCAN排除的噪点数据,而不关心DBSCAN的聚类结果。
2.2 算法描述
将数据样本由DBSCAN进行数据清洗后,从剩余数据样本中抽取若干正常与异常样本,作为半监督聚类的seed样本,分别计算质心用于后续的聚类算法初始化。算法描述如下:
输入:聚类数目k;抽取正常样本的比率NorRatio;抽取异常样本比率AttRatio;seed总数目numSeeds;正常seed数目numNormalSeeds;KDD99样本D={d1,d2,…,dn};有标签的正常样本;有标签的异常样本
输出:聚类样本数;SSE;聚类中各类样本数目。
算法步骤:
Step 1初始化,采用DBScan密度聚类算法对数据集进行分析,抽取出噪点另行分析并从数据集中将其删除;
Step 4采用K-means算法对数据集进行聚类,并分析算法结果。
3 实验结果分析
3.1 实验平台与数据集
实验使用的是数据挖掘软件平台weka-3-5,数据集使用的是KDD CUP 99[5]。由于数据集过于庞大,本实验是在10%的子集(kddcup.data_10_percent.gz)中随机抽取1/25。具体数据如下表1及表2所示。

表1 数据清洗前各类样本数目Table 1 Number of samples before data cleaning

表2 数据清洗后各类样本数目Table 2 Number of samples after data cleaning
为验证算法的稳定度,本实验引入KDD CUP 99数据集中经过纠正标签的数据集corrected.gz并抽取1/30进行测试,具体数目如表3所示。

表3 corrected数据集Table 3 Corrected data set
3.2 性能评价指标
为了评价聚类算法在入侵检测中的性能,我们引入聚类及入侵检测相关统计量:误差平方和(SSE,sum of squared errors)表示各聚类中样本的相似度,Centroidi为第i个聚类的质心,该值越低表示聚类的效果越好;检测率(DR,detection rate),该值越高表示入侵检测算法的效果越好;误报率(FPR,false positive rate),该值越低表示入侵检测算法的效果越好。

3.3 聚类结果
数据集中采用DBSCAN聚类算法进行数据清洗。经过处理,抽取227条噪点样本,剩余12 124条样本进行半监督聚类分析。其中227条的噪点样本中,有180条是异常样本,经过与corrected.gz数据集对比,其中有13条为未知攻击,降噪效率为85.02%。将剩余的数据集继续进行聚类实验。
表4为在抽取的数据清洗后样本的聚类的情况。表5为抽取的corrected.gz样本聚类情况。
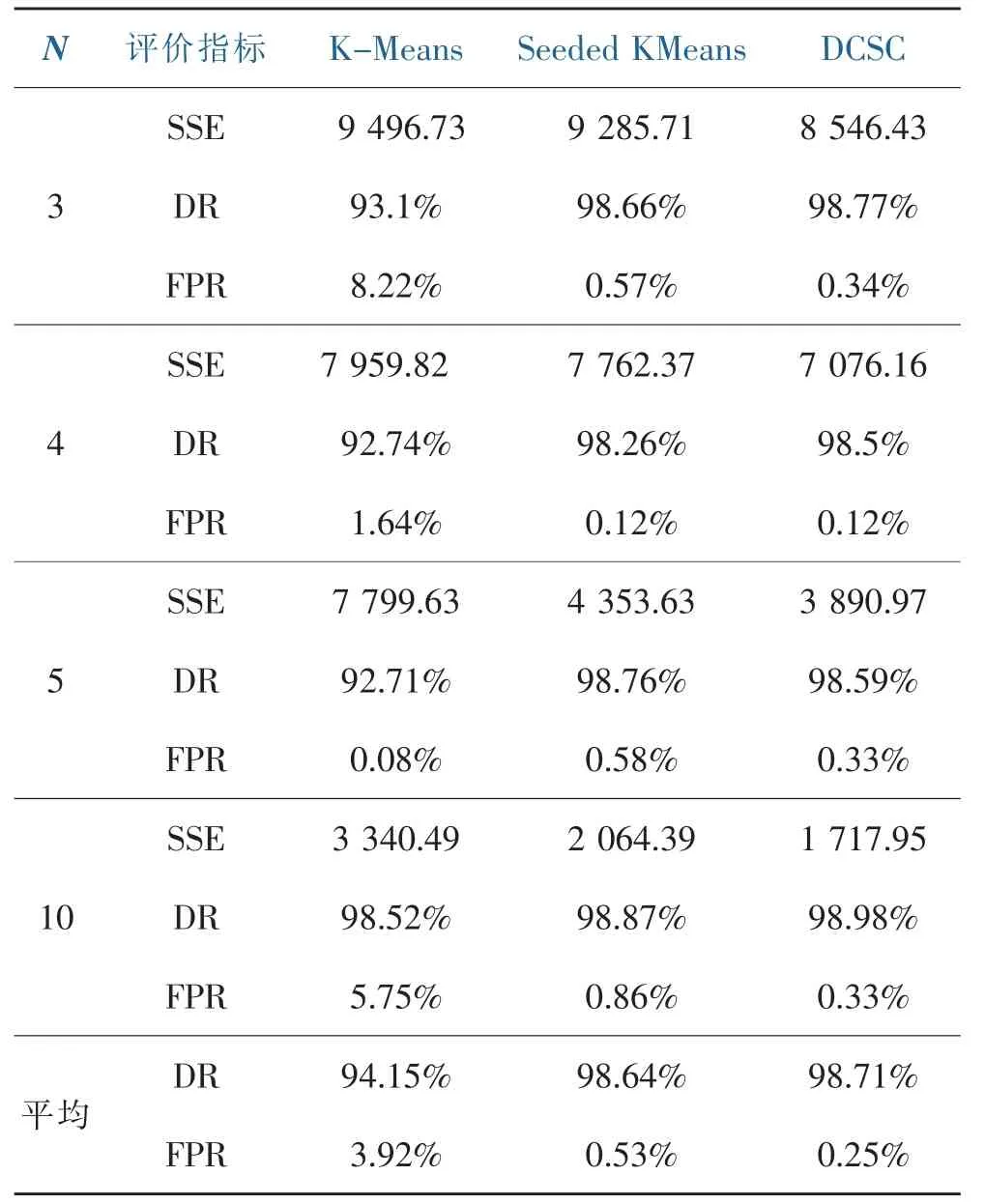
表4 kdd cup数据集聚类结果比较Table 4 Comparison of clustering results of kdd cup data set
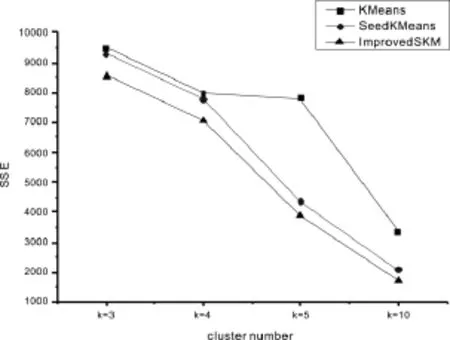
图1 kdd cup数据集各算法SSE比较Figure 1 Comparison of each algorithm’s SSE of kdd cup data set

图2 kdd cup数据集各算法DP比较Figure 2 Comparison of each algorithm’s DP of kdd cup data set

表5 corretced数据集聚类结果比较Table 5 Comparison of clustering results of corrected data set

图3 corrected数据集各算法FPR值比较Figure3 Comparison ofeach algorithm’sFPRofcorrected data set
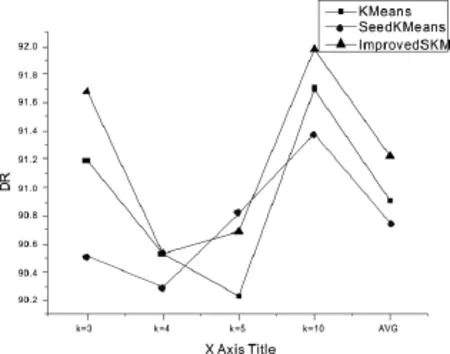
图4 corrected数据集各算法DR值比较Figure 4 Comparison ofeach algorithm’s DR of corrected data set
由实验结果可知,改进的半监督聚类算法在各数据集中都具有较高的效率,由于corrected数据集没有进行数据清洗,在seed中混入了噪点,因此seeded K Means算法的效率较不稳定。
4 小结
基于数据清洗的改进半监督聚类算法,通过将数据集进行降噪处理既可以降低噪点对半监督聚类算法效率的影响,又可以由噪点中分析出未知攻击,这对于入侵检测系统应对攻击手法不断更新,病毒特征不断改变具有重要的意义。实验结果表明本文提出的改进算法具有较高的效率以及良好的数据集适应度。
[1]LASKOV P,DUSSEL P.Learning intrusion detection:su-pervised or un-supervised[C].Image Analysis and Processing,Proc.of 13th ICIAPConference,2005:50-57.
[2]冯登国,张敏,李昊.大数据安全与隐私保护[J].计算机学报,2014,37(1):246-258
[3]ZHU X.Semi-supervised learning literature survey[R].University ofWisconsin-Madison Technical Report 1530,Computer Sciences,2005.
[4]BASU S,BANERJEE A.Semi-supervised Clustering by Seeding[C].Proceedings of the 19th International Conference on Machine Learning,2002:19-26.
[5]KDD CUP 99 data[R/OL].(2008-03-28)[2016-04-25]http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html.
(责任编辑:叶丽娜)
A Data Cleaning Based on Im proved Sem i-supervised Clustering Algorithm for Intrusion Detection System
ZHOU Zhiping,CHEN Xiaojie
(School of Information engineering,LongYan University,Longyan,Fujian 364000)
A data cleaning based improved semi-supervised clustering algorithm is proposed in this paper in order to overcome the problem for semi-supervised clustering algorithm noise sensitivity.Noise sample in the data setswill be extracted for further analysis.From the data cleaned data sets,we collect sampleswhich are labled normal and abnormal,then calculate them respectively to support the initialization phase of K-Means clustering algorithm.Experimental results show that proposed clustering algorithm has the ability to detect unknown attacks,and has a higher attack detection rate and lower false positive rate.
data cleaning;semi-supervised clustering;intrusion detection
TP393
A
1674-2109(2017)03-0067-05
2016-05-02
龙岩学院青年教师攀登项目(LQ2013008,LQ2014001)。
周志平(1985-),男,汉族,讲师,主要从事计算机网络、网络安全的研究。
