基于聚类定量分析的微博舆情监测与预警
2017-04-25李立煊
文/李立煊
基于聚类定量分析的微博舆情监测与预警
文/李立煊
随着网络技术的发展和时代的进步,微博舆情逐渐进入大众的视野,微博舆情在一定程度反映了民情民意,因此,如何更好地对网络舆情进行引导和控制,并进行舆情的风险预警成为目前亟待解决的问题。本文以微博消息为研究对象,基于K-means算法完成对微博消息的聚类定量分析,找到所要分析的某类微博内容,进而在这类微博中找出微博消息意见领袖,提出微博意见领袖影响力评估算法,完成微博消息预警模块的实现,对微博舆情监测分析系统进行研究。
微博舆情 监测分析 K-means算法 聚类定量分析
网络舆情的重要性已经毋庸置疑,有关网络舆情管理与检测的研究也日趋成熟,有关网络舆情管理与监测的系统越来越多,微博舆情的分析平台也随之出现,不过多数是为政府和企业服务,其仅对有可能爆发的负面信息和重大事件进行监控,不对普通用户开放,而有关微博消息的分析软件不但费用昂贵而且只是对信息的已传播轨迹进行呈现和分析,既缺乏对微博消息未来走向的一个分析预测,也没有对微博消息传播范围广度的分级。
对于微博舆情的监测是要对微博内容进行聚类分析,所谓聚类,就是一个集群的集合。聚类的目的是找到对象组,进而通过数据分析确定对数据分析有用的群体。国内学者对微博聚类方法进行的研究,主要采用划分法、层次法、基于密度方法、网格方法、模型方法等,其中划分法作为一种主流的聚类分析方法进行初步分类,并采用不断迭代的方法优化分组方案,目前划分法大都采用定性分析方法,诸如Vlan等方法,对定量分析的方法尚未有文献提及。
一、微博消息的传播类型
1.微博消息传播的特点。微博消息的传播具有直接性、互动性以及突发性等特点,微博网络舆情的这三个典型特点,可以看出它与其他舆情传播存在着显著差别,而想要对微博舆情进行管理,必须很好的利用这三种特点。
2.微博用户状态。在调研文献时,病毒在传播的时候会出现三种用户状态:感染态、免疫态、易感染态。由于病毒传播与微博消息的传播相似性,假设一个用户发布一条消息后,他的粉丝用户都一定会看到这条消息,类比病毒传播的三种状态,将微博用户也分为三种状态:未知状态、转发状态、已知不传播状态(见图1)。

图1 微博用户状态图
3.微博意见领袖。微博意见领袖的粉丝数量通常为上万甚至几十万乃至上百万,成为微博平台上的明星,他们常通过与粉丝互动引导舆情导向。不过转发量并不是判断意见领袖影响力的唯一标准,粉丝数、转发率以及活跃程度均是评估意见领袖影响力的重要参考标准,通过对实验数据结果的总结,可以得出评估用户影响力的标准:粉丝数、转发率、历史转发率(该用户的活跃程度)。
4.微博传播模型。微博的传播模型具有很强的单向性,类似病毒的传播,病毒感染一台主机则这台主机进入感染态,而感染一台服务器,则访问这台服务器的所有主机都会了解这个病毒,或感染或免疫。微博中消息传播也是如此,普通用户相当于终端,而微博意见领袖则相当于服务器,区别在于,消息的接受是被动的,只要登录微博就能看到关注者的消息,而不像用户一样需要登录服务器。
对微博数据的抓取分析可以看到,微博中大V领袖的意见引导着大多数用户的意见。在微博信息传播初期,微博大V的加入会使消息传播呈现出爆炸式增长的趋势,随着传播时间的不断增长,微博大V的影响力逐渐衰弱,慢慢趋向于消失。
通过对数据分析可以发现,消息的传播广度与初始微博意见领袖加入的多少有一定关系,当单位时间内意见领袖的影响力达到了一个阈值M后,可以认为在之后的一段时间内,此消息的传播范围会有一个明显的增长。通过研究发现,消息成为热点有以下三种规律,每一种都会在热点的成长曲线中出现。对一个范围内的微博意见领袖进行监控,发现意见领袖对一条微博消息的转发比例达到10%时,可以认为此消息会有一个广泛的传播,会成为一个热点话题;通过对已知此消息但未转发的意见领袖的比例与已知此消息并转发的意见领袖所占比例的对比,可实现对未来的微博消息传播范围的判断;在单位时间内(设为1个小时)的消息传播量达到一个阈值M后,可以认为此消息传播进入爆发期,会出现较大增长,通过设置不同M值,可对未来的消息传播范围有一个大致的分级,不同级别表示预测此消息传播的最大广度。从趋势分析角度来说,以上三种规律无论应用哪一种均可以对消息传播趋势做一个分析,采用多种规律对趋势分析精度的提升也是有限的,而对一种规律分析的足够透彻已经可以达到一个接受的趋势分析的准确度了。
二、基于K-means算法的微博舆情监测分析系统
1.K-means算法概述。K-means在分群方法中视为一个最为简单并且有效率的方法,K-means表示依K个质心(means)做分群。K-means分群算法能在大量数据中找寻出最具代表的数据点并将其视为质心,也就是分群的中心点,而后以这些中心点为根据,计算其他数据点与其中心点之距离,例如在大量的资料中,找寻最具代表的K个数据点作为中心点(也就是质心),将其他数据点与K的中心点分别做距离运算,运算后可得知各个数据点与K个中心点的距离,将数据点与其计算出距离最近的中心点分为同一群,而这些距离较近的数据点,代表与中心点的相似度高,反之,距离较远的为较不相似的数据点,则不会被分为同一群。K-means还有另一个优势,可利用少数的数据点(大量数据中选出最具代表性的数据点)来代表大量资料,借此达到数据压缩效果。本研究主要探讨K-means分群的效果,以少数的数据点来代表特定类别之数据,降低数据的计算量以及避免噪声或是其他不良的影响(如图2)。

图2 K-means算法流程图
2.微博舆情监测分析系统设计流程。如图3所示,获得关键词或核心微博后,从数据库中获取微博相关数据。将微博内容与微博ID挂钩,用中文分词系统将微博内容进行分词,首先在数据库中新建一表项,用于存储分词后的文本内容;其次继续以微博ID为区分,将分词后的文本放入K-means算法中进行迭代聚类,选出关键词或核心微博所在类为相关微博类,删除数据库中其他无关微博;最后可筛选出符合微博意见领袖定义的用户,进入微博意见领袖影响力评估算法,分析出每个意见领袖的重要程度。以小时为单位,计算单位时间内的微博内容传播广度,设定不同等级阈值M,存在超过M值的时间段即可分析预测出消息未来走势,进而将意见领袖重要性在前10名的用户数据反馈数据库,将用户按时间顺序进行排序存储到数据库交给管理平台进行结果反馈,这就是整个数据分析系统的主要流程。

图3 微博舆情管理平台数据分析系统主要流程
三、微博舆情监测分析系统实现步骤
1.微博数据转化。向量空间模型广泛应用在信息检索的相关领域,例如在文件分类与文件分群。其方法是转换文件(或是查询语句,在本论文中为试题的关键词)到向量空间后,在此空间中比对查询条件与文件的相似度。字词频率的公式最早是由Rocchio于1971年所提出,他经过大量的统计分析后发现,文件中出现次数为中频率的字词,往往是整篇文件中的每一个不同的词项,在向量中只记录一个分量。重要的字词,或称为关键词(Keywords),其中包含以下关键内容。一是字词频率(Term Frequency,TF):表示在一篇文件中,某个字词出现的次数,目的是对一篇文件中出现次数为高频率的字词加权。二是文件频率(Document Frequency,DF):表示某个字词有在那几篇文件出现。三是反文件频率(Inverse Document Frequency,IDF):将上述的文件频率取倒数后乘上所有的文件总数,之后再取自然对数,目的是为了对一篇文件中出现次数为低频率的字词作加权。经过VSM分类的文本文档,可以看做粗略的分类,不过不够精确,所以需要后续的文本聚类的精确分类来确定所需要的微博消息。
2.K-means聚类分析算法流程。输入:聚类个数 k以及包含n个数据对象的数据集。输出:满足目标函数值最小的k个聚类算法流程:第一步从n个数据对象中任意选择k个对象作为初始聚类中心;第二步循环下述流程第三步到第四步,直到目标函数J取值不再变化;第三步根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并且根据最小距离重新对相应对象进行划分;第四步重新计算每个聚类的均值(中心对象)。
3.微博意见领袖重要性评估。从前文中可以知道,微博意见领袖在微博消息传播中具有重要作用,但对于影响力大小的衡量需要通过PageRank算法来进行评估。
对于意见领袖的影响力评估,通常采用两个指标进行评估。一是被转发量,被转发量通常指用户信息被他人转发的次数。二是粉丝数量,粉丝数量就是该用户吸收粉丝的数量。

图4 意见领袖用户传播率
为了评价微博大V对用户的影响力,以及覆盖的人群数量,本文通过以上的算法,对意见领袖累计覆盖率进行了统计,如图4所示,从图中可以看到,意见领袖的信息覆盖能力超过一般人群,本文的算法从定量角度上准确衡量微博大V对用户的影响力。
4.微博舆情预警模块。微博消息有两种传播模式,一种是常见媒体在用户中的传播,一种是微博大V的信息传播模式,图5就是两种方式的转发量时间曲线图,例子选择则是媒体模式选择的是南方周末“一名中国公民在波士顿爆炸案中遇难”的消息传播。微博达人模式选择的是“国学大师刘文典说过的一句话”,图6和图7选择的是传播量时间曲线图。其中南方周末微博消息在一天时间内的转发量为997,传播用户量接近500万,《南方周末》的粉丝数量就占了近450万,转发率非常低,但是传播范围广,依然是热点;而微博达人模式则不一样,转发量为724,最终传播用户量接近10万,在一定范围内也成为了热点,而它的传播时间图就和起点很高的《南方周末》图形很不一样,有着较高的转发率,虽然广度不及《南方周末》,但也形成热点话题。从两种模式的传播图形中可以看出,传统的媒体传播模式在开始的时候信息传播数量猛增,随后时间的增长很快趋近与稳定,而微博大V的传播模式中,信息刚开始传播数量缓慢增长,随着微博大V的加入,传播消息数量出现猛增,随着传播时间的继续增长,逐渐趋近于稳定。这两个图形很好的描述了两种模式的传播过程特性。

图5 转发量时间曲线图
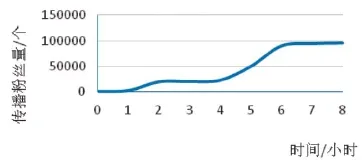
图6 微博达人模式图

图7 媒体模式传播图
四、小结
本文以微博消息为研究对象,基于K-means算法完成对微博消息的聚类定量分析,找到所要分析的某类微博内容,进而在这类微博中找出微博消息意见领袖,提出微博意见领袖影响力评估算法,完成微博消息预警模块的实现,对微博舆情监测分析系统进行研究。
作者系华中科技大学公共管理学院博士、韶关学院新闻与传播学讲师
[1]张洋,何楚杰,段俊文,杨春程.微博舆情热点分析系统设计研究[J].信息网络安全,2012(09).
[2]H Wang,P Yin,J Yao,JNK Liu.Text feature selection for sentiment classification of Chinese online reviews[J].Journal of Experimental & Theoretical Artificial Intelligence,2013(04).
[3]唐晓波,宋承伟.基于复杂网络的微博舆情分析[J].情报学报,2012(11).
[4]CS Park.Does Twitter motivate involvement in politics?Tweeting, opinion leadership,and political engagement[J].Computers in Human Behavior,2013(04).
[5]莫溢,刘盛华,刘悦,程学旗.一种相关话题微博信息的筛选规则学习算法[J].中文信息学报,2012(05).
[6]D Pelleg,AW Moore.X-means:Extending k-means with efficient estimation of the number of clusters[M].Seventeenth International Conference on Machine Learning,2000.
[7]李清,沈彤,关毅.面向大规模日志数据的聚类算法研究[J].智能计算机与应用,2012(05).
[8]肖宇,许炜,商召玺.微博用户区域影响力识别算法及分析[J].计算机科学,2012(09).
[9]杨春霞,胡丹婷,胡森.微博病毒传播模型研究[J].计算机工程,2012(15).
[10]李雯静,许鑫,陈正权.网络舆情指标体系设计与分析[J].情报科学,2009(07).
[11]高承实,荣星,陈越.微博舆情监测指标体系研究[J].情报杂志,2011(09).
[12]何黎,何跃,霍叶青.微博用户特征分析和核心用户挖掘[J].情报理论与实践,2011(11).
