基于HMM 的维吾尔语词性标注研究
2017-04-22李萍杨勇赛买提艾力任鸽
李萍,杨勇,赛买提·艾力,任鸽
(新疆师范大学计算机科学技术学院,乌鲁木齐 830054)
基于HMM 的维吾尔语词性标注研究
李萍,杨勇,赛买提·艾力,任鸽
(新疆师范大学计算机科学技术学院,乌鲁木齐 830054)
在维吾尔语与汉语的机器翻译的研究中,词性标注起到很大的作用,词性标注也是自然语言处理的基础性工作。介绍基于隐马尔可夫模型的词性标注算法和词性标注器Citar,并且将Citar标注器应用到维吾尔语上进行词性标注。为了能对维吾尔语进行词性标注,在在布朗词性标注集的基础上,定义一套适用于维吾尔语的词性标注集,采用基于隐马尔可夫模型的方法,对部分维吾尔语进行词性标注实验,经过实验表明,Citar标注器能准确对维吾尔语进行词性标注,从而表明此标注器适用于维吾尔语。
机器翻译;词性标注;隐马尔可夫模型;词性标注集;维吾尔语
0 引言
词性标注[1-3]是自然语言处理的基础,其中机器翻译[4-5]、信息抽取[6-7]、信息检索、信息识别等的研究都要在词性标注的研究基础上。词性标注是将句子中的词语标记上词性属性,词性标注的难点在于一个词在不同的语境环境可能有不同的属性,另外对于未登录词的处理也是词性标注中的一大难点。汉语中的词性标记还涉及一个分词问题,先要对句子进行分词,而像英语、维语这类的语言,其词与词之间存在空格,相比于汉语的词性标记,这类语言的词性标注相对容易些。
维吾尔语是阿尔泰语系,所有的词语由32个字母构成,但是每个字母有不同的变形,在构成不同的词语的时候其字形不一样,这种变形加大了维吾尔语词性标注的难度。词性标注的难点主要是对兼类词和未登录词的处理。目前对于维吾尔语词性标注的研究主要是集中于两个方面,一个方面是维吾尔语词性标注集的研究与设计,第二个方面是词性标注算法在维吾尔语上的应用。文献[8]主要研究的是基于词典的词性标注,构建了《现代维语电子词典》用于维吾尔语的词性标注,使用的标注集是小标记集。文献[9]使用了最大熵模型对维吾尔语进行了词性标记,并且标记的时候结合了维吾尔语的词缀作为标记特征。文献[10]将三阶隐马尔可夫模型运用到了维吾尔语的词性标注,并且改进了Viterbi算法。文献[11]使用感知器训练算法和Viterbi算法对维吾尔语进行了词性标注,同样在标注时结合了词的特征。对维吾尔语的自动化标注目前使用的标注集大部分是新疆大学多语种信息技术实验室制定的,也有部分研究是专门关于标记集的制定。本文采用的以布朗语料库制定的词性标记集为基础并结合了维吾尔语的词性特征筛选出来,使得基于隐马尔科夫模型标注器Citar适用于维吾尔语的词性标注。
1 基于HMM 的词性标注算法
隐马尔科夫模型是由五元组μ=(S,O,A,B,π)构成的,S为模型中的隐含状态集合,在词性标注问题中对应的是词性,O为模型中的观察状态,在词性标注问题中对应的是单词,π为初始化状态概率矩阵,A为隐含状态转移概率矩阵,B为观察状态转移概率矩阵。
为了对大量维吾尔语词语进行标注,需要先得到一个合适的隐马尔科夫模型。本文采用Citar标注器对维吾尔语进行模型的训练以及词性的标注。由于Citar标注器适应的是英文,在应用方面有相应的区别。在训练之前首先要确定维吾尔语的标记集,由于在词性标注问题上,大部分的标记集都是由布朗语料库中的标记集演变而来,因此根据Brown语料库的87个标记集[12-13]以及大众维语里出现的词性[14],筛选出用于维吾尔语词性标注的标记集如表1所示,这里只针对常见的维吾尔语词性确定了标记集,还有待进一步完善。

表1 维吾尔语词性标记集
采用此标记集对部分语料的人工标注结果如图1所示。
2 实验
2.1 模型训练
本文使用了维吾尔语日常用语的1000句进行人工标注,根据人工词性标注的实验数据进行模型训练,通过实验数据的训练,可以得到两个模型文件lexicon和ngrams,其中lexicon模型文件主要是统计词型和词性标记的组合在训练集合中出现的次数,ngrams模型文件主要是一元词性和二元词性在训练集中的出现次数。模型训练的命令为:”./citar-train../../corups/w4.txt lexicon ngrams”,生成的模型文件如图2和图3所示:

图1 维吾尔语词性标注人工标注结果
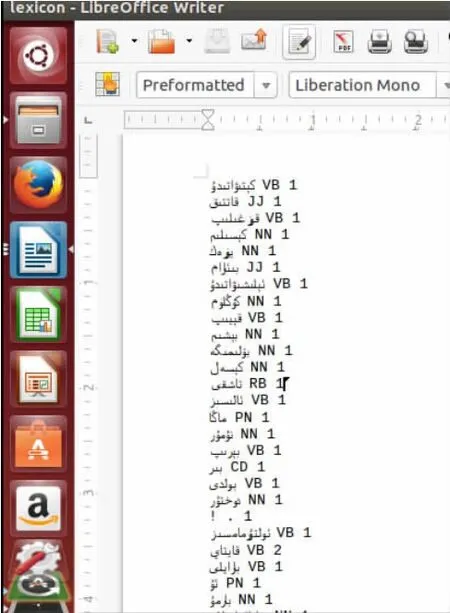
图2 lexicon
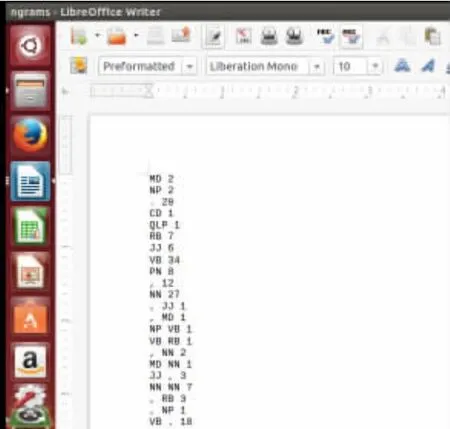
图3 ngrams
2.2 词性标注

图4 词性标注结果
3 结语
结合维吾尔语的特点,为了能高效对维吾尔语进行词性标注,本文提出了将基于HMM的Citar标注器应用于维吾尔语中进行词性标注。在布朗词性标注集的基础上,提取出了维吾尔语常用的词性标注集,通过实验表明,Citar标注器非常适用于维吾尔语的词性标注,这也为以后的研究奠定了基础。不足的是维吾尔语词性标注集不是很齐全,另外由于维吾尔语的书写规则,使得词性标注的应用存在困难,另外模型训练时人工标注语料较少,真正对词性进行标注时测试数据集较少,下一步工作就是获取更多的人工标注语料,在大规模的测试集上进行实验,并对结果进行评测。
[1]陈莉.基于HMM的柯尔克孜语基本词性标注研究[D].新疆大学,2013.
[2]王海波,祖漪清,力提甫,等.基于功能词缀串的维吾尔语词性标注方法[J].中文信息学报,2013,27(5):179-183.
[3]洪铭材,张阔,唐杰,等.基于条件随机场(CRFs)的中文词性标注方法[J].计算机科学,2006,33(10):148-151.
[4]刘群.统计机器翻译综述[J].中文信息学报,2003,17(4):1-12.
[5]杨攀,李淼,张建.基于短语统计翻译的汉维机器翻译系统[J].计算机应用,2009,29(07):2022-2025.
[6]李保利,陈玉忠.信息抽取研究综述[J].计算机工程与应用,2003,39(10):1-5.
[7]李萍,朱建波,周立新,廖彬.基于快速构建模板的购物信息抽取方法[J].计算机应用,2014,34(3):733-737.
[8]玉素甫·艾白都拉,阿布都热依木·沙力.现代维语语料库的词类标注研究.民族语文,2005(4):63-66.
[9]帕里旦·吐尔逊,艾山·吾买尔尔,吐尔根·依布拉音,等.基于最大熵的维吾尔语词性标注模型:第三届全国少数民族青年自然语言信息处理、第二届全国多语言知识库建设联合学术研讨会[Z].乌鲁木齐:201017-20.
[10]陈鹏.隐马尔可夫模型在维吾尔语词性标注中的应用[J].电脑知识与技术(学术交流),2006(4):127-128.
[11]卡哈尔江·阿比的热西提帕提古力·依马木买合木提·买买提吐尔根·依布拉音.基于感知器算法的维吾尔语词性标注研究[J].中文信息学报.2014,28(5).
[12]Eric Atwell.Automatic Mapping Among Lexico-Grammatical Annotation Models[eb/ol].[2015-9-29].http://www.scs.leeds.ac.uk/ccalas/ tagsets/brown.html.
[13]Brants T.TnT:a Statistical Part-of-Speech Tagger[C].Proceedings of the Sixth Conference on Applied Natural Language Processing. Association for Computational Linguistics,2000:224-231.
[14]马德元,塔西普拉提,乌买尔.大众维语[M].新疆:新疆大学出版社,1997:1-100.
Research on Uyghur Part-of-Speech Tagging Model Based on Hidden Markov Model
LI Ping,YANG Yong,SAI Mai Ti·Ai Li,REN Ge
(College of Computer Science and Technology,Xinjiang Normal University,Urumqi 830054)
The part-of-speech tagging plays a very important role in the research on machine translation in Uyghur and Chinese.The part-ofspeech tagging is the groundwork for natural language processing.Introduces the part-of-speech tagging algorithm based on HMM and the part-of-speech tools named Citar,improves Citar in order to make the part-of-speech tagging tools apply to the Uyghur.On the basis of brown part-of-speech tagging sets,defines part-of-speech tagging sets used in the Uyghur for the part-of-speech tagging of Uyghur. Uses the method based on hidden Markov model,carried out the part of speech tagging experiment.The experiment result show that Citar has a good result on the part-for-speech tagging of Uyghur and the label machine is suitable for the Uyghur.
Machine Translation;Part-of-Speech Tagging;HMM;Part-of-Speech Tagging Sets;Uyghur
1007-1423(2017)07-0011-04
10.3969/j.issn.1007-1423.2017.07.003
李萍(1989-),女,湖南株洲人,讲师,硕士,研究方向为自然语言处理、信息检索、信息抽取
杨勇(1979-),男,陕西汉中人,副教授,博士,研究方向为自然语言处理
赛买提·艾力(1983-),男,新疆乌鲁木齐人,讲师,硕士,研究方向为自然语言处理
任鸽(1986-),女,新疆乌鲁木齐人,讲师,硕士,研究方向为自然语言处理
2016-12-22
2017-02-10
新疆师范大学优秀青年教师科研启动基金项目(No.XJNU201420)
