基于稳态过程的多重分形Web日志仿真生成算法
2017-04-20彭行雄肖如良
彭行雄,肖如良
(1.福建师范大学 软件学院,福州 350117; 2.福建省公共服务大数据挖掘与应用工程技术研究中心,福州 350117)
(*通信作者电子邮箱xiaoruliang@163.com)
基于稳态过程的多重分形Web日志仿真生成算法
彭行雄1,2,肖如良1,2*
(1.福建师范大学 软件学院,福州 350117; 2.福建省公共服务大数据挖掘与应用工程技术研究中心,福州 350117)
(*通信作者电子邮箱xiaoruliang@163.com)
运行在服务器集群的软件系统需要Web日志的大规模数据集以满足性能测试的需求,但现有仿真生成算法因模型单一而无法满足要求。针对此问题,提出一种基于alpha稳态过程的多分形Web日志的仿真生成算法。首先,在长相关尺度(LRD)下采用alpha稳态过程来描述Web日志的自相似性;其次,在短相关尺度(RSD)下采用二项式b模型描述Web日志的多重分形性;最后,将长相关模型和短相关模型融合于改进的ON/OFF框架中。与单一的模型相比,新算法的参数物理意义明确,具有良好的自相似性和多分形性。实验结果表明,该算法能够较准确地模拟真实Web日志,可以有效地应用于Web日志大规模数据集的仿真生成。
稳态过程;多重分形;自相似;时间序列;日志分析;仿真生成
0 引言
在Web服务器性能测试中,分析Web日志特征对于服务器性能评测与决策有着重要意义。然而Web日志中包含用户隐私信息,企业及政府等机构极少愿意公开日志供研究人员使用;现有已公开的Web日志数据年代久远,其特征不符合当前大数据时代特征[1]。随着数据规模的增大,生成有代表性却不失一般性的大规模数据集是有困难的,而单一的传统仿真模型很难表现出多种复杂Web日志一般性特征。如何生成仿真且一般性可控的Web日志大规模数据集,是学术界的热点问题,也是本文研究的主题。
以ON/OFF模型[2]为代表的自相似模型,将自相似过程看成是无数用户数据源采用独立同分布形式叠加的结果,这种模型能对自相似现象给出明确的物理解释,但是在构造模型的过程中作了很多前提假设(如文件大小分布是重尾的[3],那么访问文件所需要的时间也是重尾的),且这些前提假设条件常常与实际情况不相符合,这使得流叠加模型难以对实际流量进行仿真。随着非线性动力学的发展,通过对Web日志序列的研究,发现其中含有丰富的非线性特性,因此逐渐开始采用计算智能的相关理论进行分析,其中以多分形小波模型(Multi-fractal Wavelet Model, MWM)[4]为代表的多重分形模型,通过将Web日志分为高频和低频,有效地揭示了突发性流量的局部较精细的本质特征。但是这类方法建立在重构相空间(Web日志模型的非线性特征量的提取及分析)的基础上,预测结果受相空间形状的影响,如果参数选取不合适,就有可能产生较大误差。
针对以上问题,本文提出一种模型融合算法:基于稳态过程的多重分形Web日志仿真生成算法(Multi-Fractal Web log simulation algorithm based on Stable process, MFWS)。MFWS将alpha稳态模型与二项式b模型融合,不仅能够更加准确地模拟Web日志的高斯性、非高斯性以及多分形性等特征,而且其参数的物理意义明确,能够很好地应用于不同Web服务器平台。
1 相关工作
为了有效地仿真生成Web日志,已经有很多相关的研究。当前模拟生成的方法主要是自相似方法和多重分形方法,具体如下:
1)在自相似方法中,通过模拟突发性特征来生成Web日志。其中,被不少研究者采用的ON/OFF模型[2]结构简单,具有明确物理意义,构造的每一个过程都能找到原型;然而在构造过程中作了一定假设,与实际流量不符,而且还忽略了很多细节。分形布朗运动(Fractional Brownian Motion, FBM)[5]模型虽然易于处理,参数简单,且能在高斯条件下描述自相似性,但是只适用于高斯分布情况,而且无法同时描述长相关尺度(Long Range Dependence, LRD)和短相关尺度(Short Range Dependence, SRD)[5]。M/G/∞排队模型[6]能够描述短相关性,但是需要在计算量和计算精度之间进行折中。分形自回归滑动平均(Fractional Auto-Regressive Integrated Moving Average, FARIMA)模型[7]虽然灵活,能够同时描述长相关性和短相关性,但过于复杂,仿真运算量太大,且对负载中的突发性缺乏表述。
2)在多重分形方法中,通过扩展单分形自相似过程来模拟小时间尺度的Web日志突发性特征。二项式b模型[8]首先用于存储系统的流量仿真。它通过偏差参数b来描述局部突发行为,将单位时间内的流量二项式分解来达到多分形的目的,有参数少、模型简单的优点。Hong等[9]推荐在一个相对较小的时间范围用二项式b模型合成流量,虽然提高了模拟的精度,但是没有在长时间范围生成流量。MWM模型[4]基于多分形小波理论对流量信号进行多尺度特性分析,通过设定限制方式,巧妙地避免了仿真流量出现负值的问题;但是在构造小波系数和尺度系数之间的随意乘法因子时,没有根据实际流量的概率密度特征进行分析,缺乏真实性,且难以调整。因此有研究者以一定规律来产生乘法因子,如文献[10]提出一种改进的MWM方法,提出一个β模型来初始化乘法因子提高仿真性能,但参数物理意义不足。
在以上各项工作中,构造模型的过程中采用最频繁的分布规律为重尾分布中的Pareto规律来作为分布原型。然而,无法确认流量数据是否真的符合Pareto分布。文献[11]指出随着网络媒体的多样化、缓存技术的提升,广延指数(StretchedExponential,SE)分布[11]能更加准确地描述Web日志特征,然而其参数却不容易确定,而且没有考虑流量的非高斯性。文献[12]在用户行为分形建模时发现Web日志符合alpha稳态[13],此外alpha稳态包含4个参数,每个均有相应的物理意义,这使得研究人员可以针对不同的应用环境很方便地转换流量模型。由于alpha稳态只存在特征函数,却没有具体的分布函数,这为仿真带来了困难。但是文献[13]中采用逼近法模拟alpha稳态得到了近似分布函数,这为alpha稳态的使用带来了方便。
综上所述,自相似方法和多重分形方法各有优缺点,本文借鉴这两类方法的优点,将流量序列分为长相关过程和短相关过程,考虑到Web日志的多样性,选择具有物理意义的模型进行构造;其中长相关过程采用alpha稳态来模拟Web日志自相似的高斯和非高斯特性,短相关过程采用二项式b模型来模拟Web日志的多重分形特征,在改进的ON/OFF模型的基础上提出一种模型融合算法——MFWS,以此达到提高Web日志仿真性能的目标。
2 理论基础
2.1 alpha稳态
文献[14]研究表明:对于不同的Web服务器,Web日志到达模型分为独立同分布和自相似性两种;而且,即使同样具有自相似性,有的Web日志具有高斯性,而有的Web日志体现出非高斯性。于是文献[14]发现用alpha稳态来描述Web日志特征更加合理。之所以alpha稳态具有准确的仿真性能,是因为相对于传统方法使用的幂律分布,alpha稳态更适合于描述Web日志。随着对大量数据的调查[11]发现,所谓的幂律仅仅适用于分布曲线的尾端部分(x轴远离原点位置)。另外文献[15]中利用美国真实税收情况估计出的收入分布曲线也表明:当取双对数坐标时,曲线尾端是直线,即幂律分布;当取半对数(y轴为对数)时,曲线顶端为直线,即指数分布。数学家Nolan[13]指出alpha稳态分布正好具备这种尾端趋近于幂律分布,而在头端(x轴靠近原点位置)偏离幂律、趋向于指数分布的性质。即:一个随机变量X被称为具有稳定分布,若存在参数0<α≤2,σ>0,-1≤β≤1,μ∈R,使得其特征函数E的形式如式(1)所示:
E[exp(iθX)]=
(1)
式中:sign(·)为符号函数。文献[14]发现:α表示分布中的突发程度,β表示分布的尾部变化情况。如果β≠0,说明alpha稳态的波峰是偏斜的:取负值表示alpha稳态的波峰偏向左尾部(left-tail);反之,取正值则表示alpha稳态的波峰偏向右尾部(right-tail)。因此参数α和β决定了alpha稳态的基本形状。σ表示分布的方差,μ表示分布的均值,j表示X的第j个特征。由式(1)可知,当α=2时,得式(2):
E[exp(iθX)]=exp(-σ2θ2+jμθ)
(2)
此时,alpha稳态的特征函数E退化为高斯特征函数。因此随着α取值的不同,alpha稳定过程可以表示高斯和非高斯情况下的随机过程。此外,alpha稳态包含4个参数,每个均具有相应的物理意义,这使得研究人员可以针对不同的应用环境很方便地转换仿真模型。虽然alpha稳态没有分布函数,但是可以使用Matlab软件中的stbl工具来进行模拟,这为模拟Web日志的到达模型提供了方便。
2.2 二项式b模型
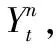
(3)
(4)
二项式b模型近似于“二八定律”:20%的操作中包含80%的数据。在二项式b模型中,如偏置参数b=0.8意味着在一个给定的时间间隔内,80%的流量只占时间间隔的一半(剩余20%占时间间隔的另一半)。然后这个过程反复递归,通过偏置参数b反映流量的局部突发行为,因此偏置参数b具有一定的物理意义。在实际中使偏置参数b为0.5到1之间的随机数,这样能增加分形的复杂性。
3 基于alpha稳态过程的用户到达模型
在选用alpha稳态过程作为Web日志建模依据之前,需要对实际的Web日志数据进行测量分析,以验证采用alpha稳态过程的合理性。对1995年美国国家航天航空局(NationalAeronauticsandSpaceAdministration,NASA)网站的八月份1 569 898条请求序列和MovieLens-1M的1 000 209条电影评分日志进行统计,图1表示用户到达数量与时间间隔关系Rel,横坐标为两个用户之间的时间间隔(100ms),纵坐标为时间间隔内到达的用户数量。可以看出大部分用户在很短时间间隔内到达,而少部分用户是相隔很长一段时间才能到达。对图1的横纵坐标取对数,这两个数据集的双对数曲线如图2所示,可以看出在双对数坐标下,Rel曲线头部(靠近坐标原点)为曲线,尾部(远离坐标原点)大致为直线;对图1的纵坐标取对数,其半对数曲线如图3所示,可以看出在半对数坐标下,Rel曲线头部大致为直线,尾部为曲线(当出现大量纵坐标值相等时,取其中点的横坐标值)。因此Rel是一种头部为指数分布,尾部为幂律分布的曲线,这是符合alpha稳态过程的[13]。
可以使用stbl工具的stblfit函数拟合此数据集参数,接着生成符合这两个参数模型的alpha稳态随机数集合,将此随机数集合与两个数据集用户到达模式累积概率分布进行比较,结果如图4所示。由图4可以发现alpha稳态与两个源数据集的累积概率分布差异不大,因此可以模拟基于alpha稳态过程的用户到达(UserArrivebasedonalphaStableprocess,UAS)模型获得alpha稳态过程的4个参数,如表1所示。
为了体现出参数的物理意义,图5(a)中NASA数据集的突发性更为均匀,图形平缓,而图5(b)中MovieLens-1M数据集的突发性更为集中,图形陡峭,因此NASA的α更大;其次两个数据集的概率密度分布曲线都向右偏,因此β>0。从图5的数据分布情况来看也不难解释两个数据集的方差σ和均值μ的差异性。

图1 不同数据集用户到达数量与时间间隔关系分布

图2 不同数据集用户到达数量与时间间隔关系双对数分布
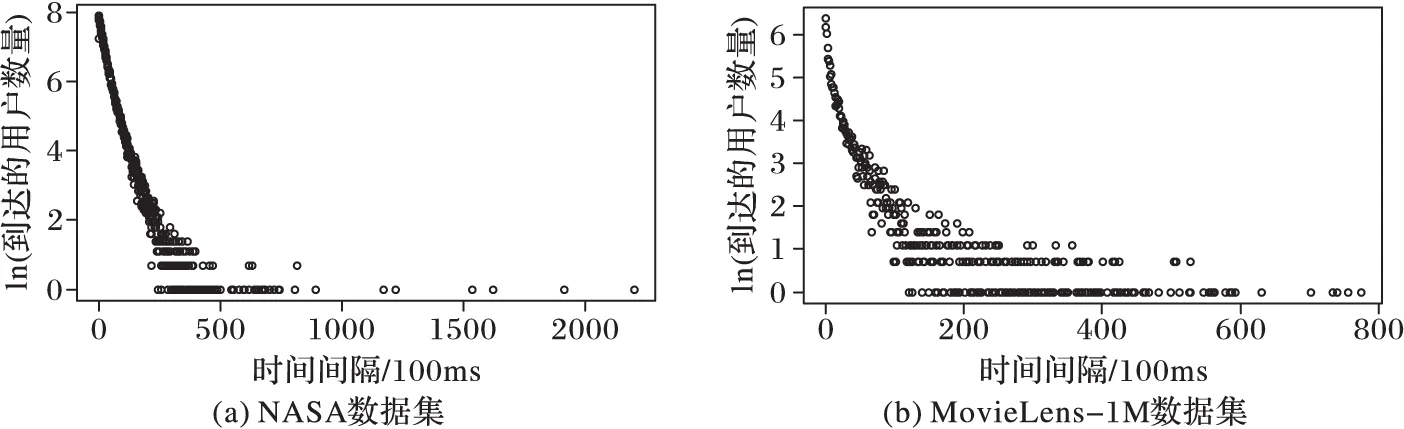
图3 不同数据集用户到达数量与时间间隔关系半对数分布
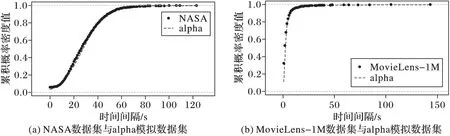
图4 原始数据集与alpha模拟数据集累积概率分布对比
表1alpha稳态过程的拟合参数
Tab.1Fittingparametersofthealphasteadystateprocess

数据集αβσμNASA1.790.9310.8328.40MovieLens⁃1M1.060.900.9311.49
图5 不同数据集用户到达模式分布情况
然后使用stbl工具的stblinv函数随机获取用户到达时间间隔序列ΔT={ΔT1, ΔT2,…, ΔTu,…, ΔTm},其中m表示有m个用户,用户u距离用户u-1的到达时间间隔为ΔTu。为了使ΔT更真实,改进ΔT如式(5)所示:
ΔT=ΔT/ln (1+Actu)
(5)
对于活跃度高的用户u,其ΔTu通常很小,这样会造成短时间内同一个用户频繁访问,因此给出对ΔT的惩罚因子1/ln(1+Actu),其中Actu表示用户u的流行度。
4 基于UAS的算法——MFWS
在单分形模型中,ON/OFF模型因其构造简单而受到广泛使用,然而其假设存在与真实流量不符合的现象,因此本文提出一种基于UAS的多重分形Web日志仿真算法——MFWS,改进ON/OFF模型如图6所示。
图6中Tu时刻表示某Web日志中某用户u到达(发生点击事件)的时刻,T(u+1)时刻表示用户u访问结束,下一个用户u+1到达的时刻,将两次用户到达时刻之间的时间间隔ΔTu称为用户间隔,也称为Web对象被动OFF时间。用户的一次点击行为引发服务器发送多个Web文件,第i个文件和第i+1个文件在传输的过程中由于网络延迟等[11]造成访问时间间隔Δti,也称为主动OFF时间。

图6 改进后的ON/OFF模型
根据第3章的方法可以使用alpha稳态分布生成用户间隔ΔT,对于文件间隔Δt,传统的做法是采用幂律分布来建立数学模型[16],然而在Web服务器端收集到的用户访问Web文件时间仅为Web服务器发送Web文件时间,却没有用户访问Web时间。不同的Web服务器性能也会导致这种数学模型缺乏一般性,同时也无法表现出Web日志的多重分形特性。在实际中,主动OFF时间比被动OFF时间小很多,属于小时间尺度,根据Hong等[9]的研究,本文认为同样也可以将二项式b模型用在小时间尺度的Web日志中。改进方法为在ON/OFF模型模拟文件间隔Δt时采用二项式b模型,具体做法如下:
对NASA网站数据进行分析发现,用户发出连续动作次数概率近似服从Zipf定律[16]。假设用户u的总请求序列是Sequ={sequ1,sequ2,…,sequi},其中rui为用户u访问的第i个Web文件,则第i个Web文件被访问的概率为p(rui)=iω,利用最小二乘法拟合可得ω=-0.924。这个结果与ω=-1 的Zipf 定律非常接近。由此可知在Web对象中,用户连续访问2个以上Web文件的概率低于60%,而用户连续访问16个以上Web文件的概率已经非常接近于0。文献[8]指出将时间ΔTu内的流量进行n次分离即是二项式分形,但实际中的n存在限制。根据二项式b模型的偏置参数b∈(0.5,1),不可能存在用户连续访问的16个文件都能独占一个时间区间,从而二项式分离次数0≤n≤4。
当确定用户u的连续访问序列长度s后,从Sequ中取出前s个Web文件,组成用户u当前连续访问序列Yu,随机选择二项式分离次数n,对每个用户到达时间间隔ΔTu以及连续访问的文件序列Yu,建立一棵高度为n+1的满二叉树Treeu,将ΔTu分为z=2n个相等区间,根据式(3)和(4)计算每个区间内的Web文件数量,先序遍历Treeu的叶子节点组成的时间序列Yu′={yu1′,yu2′,…,yut′,…,yuz′},其中yut′表示第t个时间区间内用户访问的Web文件数量,用户访问Web文件时间为ΔTu+t*ΔTu/z,则Yu′是用户u的一个含有多分形特性的Web对象。
基于以上分析,本文提出一种基于UAS的多重分形Web日志仿真算法——MFWS。该算法通过改进ON/OFF模型,利用alpha稳态过程模拟用户到达时间间隔ΔT,利用二项式b模型模拟用户连续访问Web文件时间间隔Δt,算法流程如下:
1)生成每个用户u的属性并形成集合U。
2)生成每个文件i的属性并形成集合I。
3)关联用户和文件形成原始请求序列Seq。
4)以alpha稳态拟合源数据集的用户到达模式,计算用户u的到达时间ΔT作为改进的ON/OFF模型的被动OFF时间。
5)将Seq变成用户请求序列Sequ,遍历u,记录算法开始时间currentTime。
6)判断是否收敛,是则算法结束;否则判断Sequ是否为空,为空转5),不为空则转7)。
7)找到连续访问个数s=1。
8)取出Sequ的前s个文件构成连续访问序列Y。
9)以二项式b模型分离Y为连续访问时间序列Y′,并以Y′的每个元素的Δt作为改进ON/OFF模型的主动OFF时间。
10)将序列Y′加入到用户的新访问序列Sequ′中。
11)从Sequ中删除前s个文件序列,转6)。
5 实验与结果分析
5.1 数据集
在生成Web日志之后需要观察模拟Web日志的仿真性能,采用真实数据集作为参照比对。实验采用NASA数据集以及MovieLens-1M电影评分数据集,其中NASA为31天采集的1 569 898条日志数据;MovieLens-1M为6 040个用户对3 952个电影的1 000 209条评分记录。
5.2 结果分析
5.2.1Hurst指数分析
由自相似性的定义[3]知,要验证生成的Web日志是否满足自相似过程,必须满足自相关函数r(m)(k)=r(k)~αk-β,0<β<1,H=2-2β且H∈(0.5,1)。其中α和β为自相关函数参数,H为Hurst指数。Hurst指数值越接近于1,说明Web日志具有较强的自相似性。考察真实数据集与模拟数据集的Hurst指数对比情况,按照不同时间间隔来获取不同时间尺度下的请求序列,最后用Hurst指数来估计各个不同时间尺度序列的自相似特性。将真实数据集的Hurst指数记为real_Hurst,将MFWS模拟数据集的Hurst指数记为MFWS_Hurst,将Web代理缓存生成器(WorkloadGenerationtoolforWebProxycaches,PWG)算法[16]模拟数据集的Hurst指数记为PWG_Hurst。如表2所示,可以发现对于每个真实数据集,随着时间尺度增大,real_Hurst在减小。这是因为随着时间尺度的增大,自相似系数r(k)的取值变少,在拟合的过程中,也就造成拟合效果不佳。
通过表2还可以看出,算法MFWS和PWG都有较好的自相似性(Hurst指数大于0.5),但是通过将这两个算法的Hurst指数值与真实数据的Hurst指数值对比,可以发现MFWS的Hurst指数与真实数据集更加接近,这是因为PWG算法采用的是幂律分布,在模拟不同类型数据集时不如alpha稳态分布合适,这说明MFWS具有更加良好的自相似性。
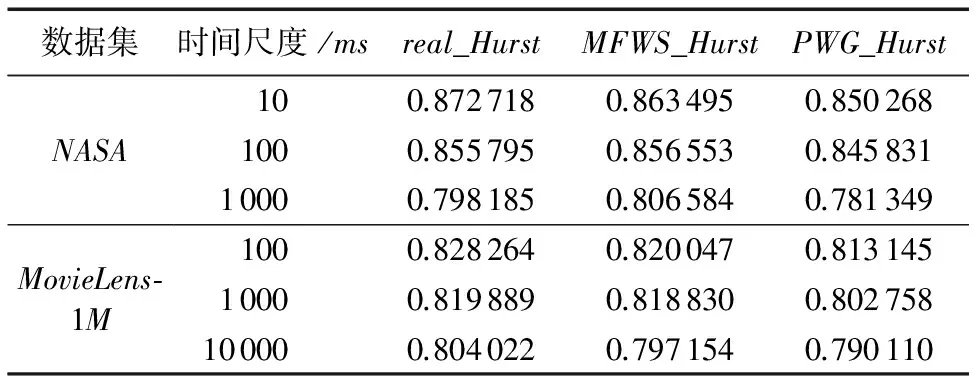
表2 不同时间尺度下的Hurst指数比较
5.2.2 分形谱评估
分形谱是Web日志模型在多重分形尺度上的本质体现,因而分形谱是衡量多重分形模型好坏的一项重要标准[17]。将两个真实数据集(real)和利用MWFS算法模拟产生的数据集(MWFS)的分形谱进行对比分析;另外,为了使实验更有说服力,将多分形小波算法的模拟数据集(MWM)也作为实验对比参照。α表示holder指数,f(α)表示奇异谱,以随机抽样的方式任意抽取这三个数据集中1 s内的Web日志,分形谱实验对比结果如图7所示。
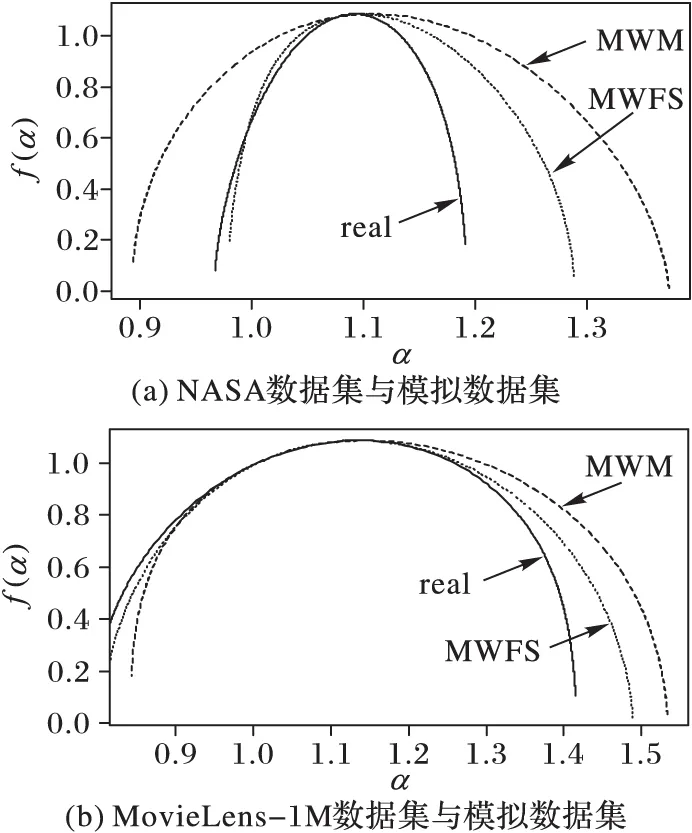
图7 真实数据集与模拟数据集分型谱对比
由图7可以看出,在α=1.1时,源数据集以及两种算法模拟的数据集的奇异谱非常相似,但是在α=1.1的两边,只有MWFS算法的模拟数据集更加接近于源数据集,说明MWFS算法在多分形谱描述上要优于MWM模型[16],与实际流量分形谱更为接近,能更准确地描述真实流量的多分形特性。
5.2.3 概率密度曲线的评估
分析数据集的用户到达模式概率密度分布,是为了验证仿真生成的数据集的用户到达模型是否符合实际数据集用户到达模式概率密度分布,体现MWFS算法的真实性。由图8可知,两个不同数据集的概率密度分布与仿真数据集的概率密度分布非常相似,说明仿真效果良好;其次,仿真数据具有很明显的重尾特征,这与真实情况相符。因此,MWFS算法仿真数据集符合原始数据集的用户到达模式特征。
通过对比真实数据集和模拟数据集的自相似特征、多分形特征和用户到达模式特征,可以发现MWFS算法具有较好的仿真性能,并且第3章中给出的各项参数物理意义明确,能够反映真实数据集特征。虽然MWFS算法仿真性能良好,但是由于采用的ON/OFF模型是一种流叠加模型,其时间复杂度也随着要生成的模拟数据集量级呈线性增长;另外,二项式b模型在创建和遍历二叉树时也会消耗大量时间。然而,MWFS得到的ΔT属于每个用户的固有属性,对每个用户的ΔT的多分形过程作为一次ON/OFF源,这为多个ON/OFF源的并发执行提供了可能,在运行时间上势必会有所减少。
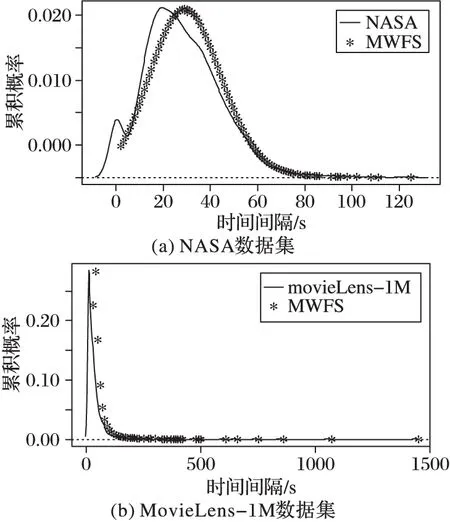
图8 不同数据集用户到达模式的概率密度分布
6 结语
自相似性和多分形性是Web日志仿真的关键,本文提出一种基于稳态过程的多分形Web日志仿真生成算法MWFS,它以alpha稳态模型代替幂律模型在大时间尺度下建立Web日志中的用户到达模型,同时以二项式b模型在小时间尺度下进行二项式分形,将这两个模型通过改进的ON/OFF模型进行融合。实验表明,MWFS算法同时具备良好的自相似性和多分形性;同时MWFS的各项参数物理意义明确,能够方便研究人员应用于不同的Web服务器上。如何实现并行化仿真生成是下一步要做的工作。
References)
[1] CALZAROSSA M C, MASSARI L, TESSERA D.Workload characterization: a survey revisited [J].ACM Computing Surveys, 2016, 48(3): Article No.48.
[2] CROVELLA M E, BESTAVROS A.Self-similarity in World Wide Web traffic: evidence and possible causes [J].IEEE/ACM Transactions on Networking, 1997, 5(6): 835-846.
[3] SARLA P, DOODIPALA M R, DINGARI M.Self-similarity analysis of Web users arrival pattern at selected Web centers [J].American Journal of Computational Mathematics, 2016, 6(1): 17-22.
[4] RIEDI R H, CROUSE M S, RIBEIRO V J, et al.A multifractal wavelet model with application to network traffic [J].IEEE Transactions on Information Theory, 1999, 45(3): 992-1018.
[5] 张雪媛,王永刚,张琼.基于分数布朗运动的自相似流量判别及生成方法[J].计算机应用,2013,33(4):947-949,963.(ZHANG X Y, WANG Y G, ZHANG Q.Self-similar traffic discrimination and generating methods based on fractal Brown motion [J].Journal of Computer Applications, 2013, 33(4): 947-949, 963.)
[6] GOMEZ M E, SANTONJA V.Analysis of self-similarity in I/O workload using structural modeling [C]// Proceedings of the 1999 7th International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems.Piscataway, NJ: IEEE, 1999: 234.
[7] LELAND W E, TAQQU M S, WILLINGER W, et al.On the self-similar nature of Ethernet traffic [C]// SIGCOMM’93: Proceedings of the 1993 Conference proceedings on Communications Architectures, Protocols and Applications.New York: ACM, 1993: 183-193.
[8] WANG M Z, MADHYASTHA T, CHAN N H, et al.Data mining meets performance evaluation: fast algorithms for modeling bursty traffic [C]// ICDE’02: Proceedings of the 18th International Conference on Data Engineering.Washington, DC: IEEE Computer Society, 2002: 507.
[9] HONG B, MADHYASTHA T M.The relevance of long-range dependence in disk traffic and implications for trace synthesis [C]// Proceedings of the 22nd IEEE / 13th NASA Goddard Conference on Mass Storage Systems and Technologies.Piscataway, NJ: IEEE, 2005: 316-326.
[10] WEN J, MA Y, LIU P, et al.Distributed multipliers in MWM for analyzing job arrival processes in massive HPC workload datasets [J].Future Generation Computer Systems, 2014, 37(7): 335-344.
[11] GUO L, TAN E, CHEN S, et al.The stretched exponential distribution of Internet media access patterns [C]// PODC’08: Proceedings of the Twenty-Seventh ACM Symposium on Principles of Distributed Computing.New York: ACM, 2008: 283-294.
[12] CHEN S, GHORBANI M, WANG Y Z, et al.Trace-based analysis and prediction of cloud computing user behavior using the fractal modeling technique [C]// Proceedings of the 2014 IEEE International Congress on Big Data (BigData Congress).Piscataway, NJ: IEEE, 2014: 733-739.
[13] NOLAN J P.Stable distributions: models for heavy tailed data [EB/OL].[2016- 01- 30].https://www.researchgate.net/publication/247635151_Stable_Distribution_Models_for_Heavy-Tailed_data.
[14] 邹强,程强.存储系统负载自相似性研究综述[J].计算机科学,2013,40(3):24-30.(ZOU Q, CHENG Q.Survey of studies on self-similarity in storage system workload [J].Computer Science, 2013, 40(3): 24-30.)
[16] BUSARI M, WILLIAMSON C.ProWGen: a synthetic workload generation tool for simulation evaluation of Web proxy caches [J].Computer Networks, 2002, 38(6): 779-794.
[17] THOMPSON J R, WILSON J R.Multifractal detrended fluctuation analysis: practical applications to financial time series [J].Mathematics and Computers in Simulation, 2016, 126(C): 63-88.
This work is partially supported by the Fujian Provincial Great Plan Project (2016H6007).
PENG Xingxiong, born in 1991, M.S.candidate.His research interests include machine learning.
XIAO Ruliang, born in 1966, Ph.D., professor.His research interests include software engineering, new technology of big data software.
Multi-fractal Web log simulation generation algorithm based on stable process
PENG Xingxiong1,2, XIAO Ruliang1,2*
(1.FacultyofSoftware,FujianNormalUniversity,FuzhouFujian350117,China; 2.FujianProvincialEngineeringResearchCenterofPublicServiceBigDataAnalysisandApplication,FuzhouFujian350117,China)
The software system running on the server cluster needs large-scale data sets of Web log to meet the performance test requirement, but the existing simulation generation algorithm cannot meet the requirements due to the single model.Aiming at this problem, a new multi-fractal Web log simulation generation algorithm based on alpha stable process was proposed.Firstly, the self-similarity of Web log was described by alpha stable process in Long Range Dependence (LRD).Secondly, the multi-fractal of Web log was described by binomial-bmodel in Short Range Dependence (SRD).Finally, the model of long range dependence and the model of short range dependence were integrated into the improved ON/OFF framework.Compared with the single model, the parameters of the proposed algorithm has clear physical meaning equipped with good performance of self-similarity and multi-fractal.The experimental results show that the proposed algorithm can accurately simulate the real Web log and be effectively applied in Web log simulation generation with large-scale data sets.
stable process; multi-fractal; self-similarity; time series; log analysis; simulation generation
2016- 06- 14;
2016- 08- 18。 基金项目:福建省高校产学合作项目(2016H6007)。
彭行雄(1991—),男,湖北孝感人,硕士研究生,主要研究方向:机器学习; 肖如良(1966—),男,湖南娄底人,教授,博士,CCF高级会员,主要研究方向:软件工程、大数据软件新技术。
1001- 9081(2017)02- 0587- 06
10.11772/j.issn.1001- 9081.2017.02.0587
TP
A
