基于AdaBoost分类器的实时交通事故预测
2017-04-17胡震波朱新山
张 军,胡震波,朱新山
(天津大学 电气与自动化工程学院,天津 300072)
(*通信作者电子邮箱xszhu126@126.com)
基于AdaBoost分类器的实时交通事故预测
张 军,胡震波,朱新山*
(天津大学 电气与自动化工程学院,天津 300072)
(*通信作者电子邮箱xszhu126@126.com)
传统的道路交通事故预测是对交通事故次数及其造成的损失的历史趋势进行预测,针对其不能反映交通事故与实时交通特性关系、不能有效地预防事故发生的问题,提出一种基于AdaBoost分类器的交通事故实时预测的方法。首先,将交通道路划分为正常、危险两种交通状态,利用实时采集的交通流数据作为特征变量对不同的状态进行表征,将事故的实时预测问题转化为分类问题;然后,采用Parzen窗非参数估计的方法对两种状态在不同时间尺度下候选交通流特征的概率密度函数(PDF)进行估计,利用基于概率分布的可分性判据分析估计的密度函数,选择合适的特征变量及时间尺度,确定样本数据;最后,根据样本数据训练AdaBoost分类器对不同的交通状态进行分类识别。实验结果表明,采用交通流特性的标准差特征对测试样本分类的正确率比平均值特征高7.9%,更能反映不同交通状态的差别,获得更好的分类结果。
智能交通;事故预测;分类器;交通流特性;Parzen窗;可分性判据
0 引言
随着我国经济与社会的快速发展,交通道路不断扩建,汽车保有量也在持续增长,导致道路交通事故发生频率及伤亡情况也在增长。交通事故预测是道路交通安全研究的一项重要内容,它能探究道路交通事故的发生规律,帮助控制交通安全,制定合理的交通安全对策。
国外已经有很多学者在研究基于实时检测数据的交通事故预测。文献[1-3]最初采用了概率神经网络(Probabilistic Neural Network, PNN)模型、分类树等方法来计算发生事故的概率,近几年他们又采用了贝叶斯理论、logistic回归等方法来处理高速公路上实时交通数据,以此来预测事故的发生。国外相关的研究还包括Hossain等[4]采用逻辑回归模型以及贝叶斯网络对高速路进行事故实时预测;Xu等[5-6]采用K-means聚类等方法对不同交通状态特征变量进行研究等。
目前国内的研究多是对交通事故未来的形势,包括每年事故次数、伤亡人数等进行估计和推测,而针对交通事故实时预测的研究较少。林震等[7]用车速的标准差作为特征变量进行事故预测,建立了最小风险贝叶斯预测模型。秦小虎等[8]提出基于贝叶斯法则的学习算法,通过计算条件概率来计算事故发生概率。Lv等[9-10]利用基于欧氏距离的特征选择方法选择特征变量,采用C-means和k近邻法对事故进行实时预测。这些研究都由于国内获得交通流数据、事故数据的困难较大,采用仿真实验去验证方法的有效性,不能够真实考虑到国内实时采集的交通数据的特性,本文中采用北京2014年10月份的交通流数据以及交通事故数据,从能够实时采集的交通流数据中提取合适特征,设计分类器识别危险交通状态,从而预测事故的发生。
1 道路交通事故实时预测原理
本文将交通状态分为3种类型:危险状态、正常状态、过渡状态,如图1所示。正常交通状态(ω1)表示交通状况稳定,不会发生事故;危险交通状态(ω2)表示交通状况不稳定,并且不稳定的程度从T-α时刻开始逐渐增长,直到T时刻发生事故;过渡状态(ω3)表示事故发生之后危险交通状态恢复到正常交通状态前的交通状态。

图1 交通状态划分
文献[1-3]的研究已经证明,不同的交通状态可以采用一定时间段内的交通数据进行表征,本文通过较为稳定的道路信息以及能够实时采集的交通流数据对ω1以及ω2进行表征,不同交通状态的特征向量记作:
xi={Ti,Li,Ci,Wi,Fi}T;i=1,2,…,N
(1)
其中:T表示样本数据记录时间;L表示样本数据记录地点,本文中采用该位置的经纬度来表示;C表示记录时间的平均气温;W表示记录时间的天气状况,包括晴、雨、雾等;F表示实时采集的交通流特性,包括特定时间尺度Δt内的速度(s)、占有率(o)、车流量(v),N为样本数量。
这样交通事故的实时预测转化为对不同交通状态的分类问题,通过分类器h(x)对某一时刻i的特征向量xi进行分类来实现对该时刻交通事故的实时预测:
(2)
当判定x属于ω2即危险交通状态时,则可采取合理的措施预防事故的发生。基于分类器的交通事故实时预测过程如图2所示。
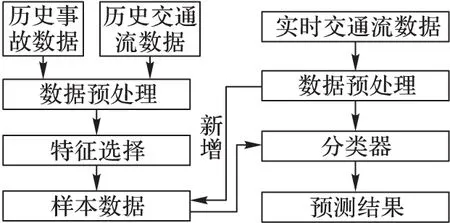
图2 实时交通事故预测过程
具体步骤为:1)采集交通事故数据以及相应的交通流数据,进行数据预处理;2)选择合适的特征变量获得样本数据。3)根据样本数据设计分类器,将分类器应用到实际中,根据实时数据识别交通状态,从而预测事故。同时,在实际应用当中,随着事故数据的增多,可以动态调整特征变量并且训练新的分类器以便提高预测的准确性。
2 交通数据准备及处理
对于交通状态分类器的设计,收集的数据有两类:一类是交通流数据,为了能够在实时预测中稳定收集数据,采用固定型检测器采集的交通流数据;一类是交通事故数据。这两类数据在预测系统中,起着不同的作用。在设计分类器阶段,两类数据均要用到。在应用分类器时,需要的是交通流数据。
2.1 数据采集及预处理
本文中采用北京二环路上2014年10月16日到10月26日的交通流数据以及该时间段内交通事故数据进行分类器的设计。由于环境影响、检测设备故障等原因,这些数据存在一些问题,例如记录的数据丢失、数据时间点顺序错误、数据精度产生偏差等。
在实际交通流数据的采集过程中,同样会出现错误或异常,因此在应用交通流数据之前,需要对这些数据进行预处理,以保证数据的准确性,预处理主要包括如下。
1)设定参数的合理范围以及精度,对不符合条件的数据进行修正。例如,平均速度的合理范围一般在0和地点限制速度的1.3或1.5倍之间,时间占有率的合理范围是0到100%。
2)检验每组交通流数据的记录时间,正确数据应当从0到719,删除重复数据,对乱序数据重新排序修正。
3)对缺失数据以及其他异常数据进行填补,如果只有个别数据存在问题,则利用其相邻数据平均值进行填充,如果一段时间内存在问题,则利用同期的历史数据平均值进行填充。
另外,由于天气状况数据不是数值型数据,因此需要先将该数据进行数值化,对应处理如表1所示。
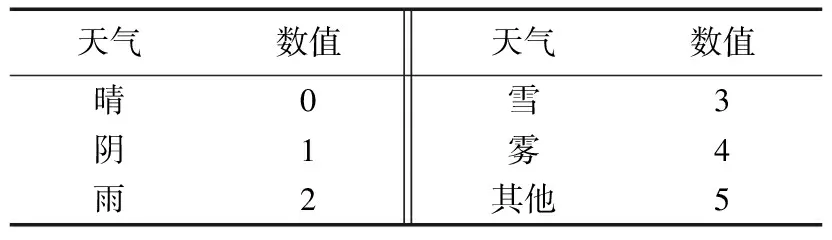
表1 天气状况数值化
2.2 交通状态特征选择
特征变量对区分正常交通状态和危险交通状态有很大的影响。特征变量如果选取合适,就比较容易对两种交通状态进行分类,而且效果很好;如果选取不好,设计分类器将会很困难。时间及地点特征是确定包含的,特征选择的重点在于交通流数据的选择,综合考虑已有数据及前人对交通流特性的研究,选取速度、占有率、车流量的平均值与标准差6个变量作为候选特征。另外,时间尺度Δt对于分类器设计也有影响,Δt的最优值也应当使两类交通状态样本差别最大。
2.2.1 特征选择原理
首先要确定特征选择的准则,即特征的可分性判据,从概念上是希望能够最有利于区分两种状态,因此利用分类器的错误率作为准则是最直接的想法,对于交通状态分类问题,分类器在分类时将决策区域分为正常交通状态Φ1、危险交通状态Φ2两部分,一维特征情况下,如图3所示,Φ1为(-∞,t),Φ2为(t,+∞)。
P(ω1)、P(ω2)为交通状态的先验概率,样本在Φ1中属于危险交通状态的概率即第一类错误率为:
(3)
样本在Φ2中属于正常交通状态的概率即第二类错误率为:
(4)
再考虑各自的分布就是平均错误率:

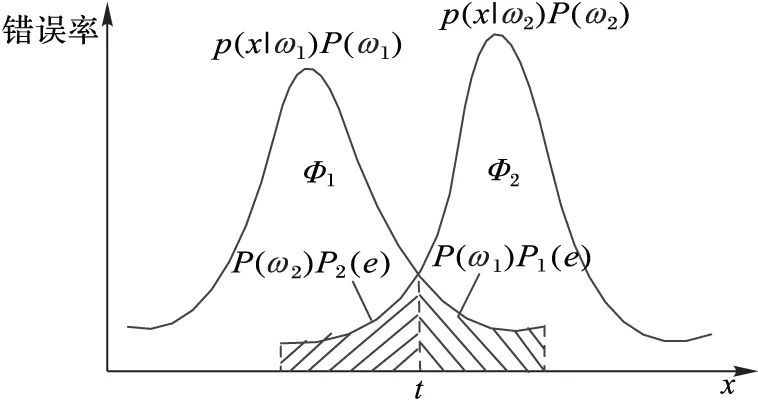
图3 错误率
从错误率计算过程可知,该准则在交通事故实时预测中不太可行,因为两类交通状态样本的概率密度函数未知,计算错误率就非常困难,因此要采用一套与错误率有关系但又便于计算的准则。
概率密度函数与错误率关系密切,因此可采用基于概率分布的可分性判据,通过分析交通状态特征分布密度的交叠程度来分析其可分性。联合概率密度函数未知,不能够计算出错误率,但可采用Parzen窗法对每一维候选特征的概率密度函数进行估计,然后通过分析不同类交通状态同一特征的交叠程度来选择特征,具体步骤如图4所示。
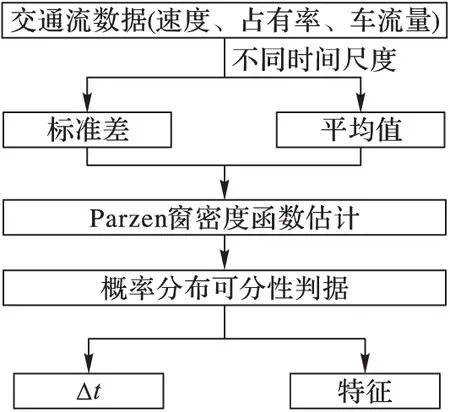
图4 特征选择
2.2.2Parzen窗密度函数估计
由于对不同类交通状态样本的分布没有充分的了解,无法事先给出密度函数的形式。为了能够利用基于概率分布的可分性判据,需要先采用非参数估计方法对不同类的交通状态每一维特征的概率密度函数进行估计。Parzen窗法即核概率密度函数估计方法由于具有很好的效果而被广泛使用,当样本数据N→∞时,该方法估计的概率密度函数收敛到真实的概率分布[11]。本文采用最常用的高斯窗,一维情况下高斯窗[12]表达式为:
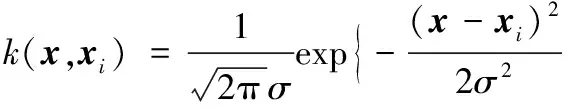
(6)
利用高斯窗对不同交通状态6个候选特征变量分别进行估计,则可得到不同特征的概率密度函数。另外,在不同Δt下对于候选特征值计算的结果是不同的,因此对不同Δt也要重新估计其概率密度函数。最终估计得到的概率密度函数为:
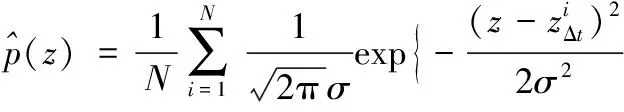
(7)
其中:zΔt代表不同Δt下速度、占有率、车流量的标准差或平均值特征。因为是按照正常交通状态ω1和危险交通状态ω2分别进行估计,最终得到的结果也可以表示为类条件密度p(z|ω1),p(z|ω2)。
2.2.3 基于概率分布的可分性判据
基于概率分布的可分性判据就是要根据正常交通状态ω1和危险交通状态ω2的概率分布之间的交叠程度来分析在某一特征下两类交通状态的可分程度。若所有使p(z|ω2)≠0的点都有p(z|ω1)=0,则两类交通状态完全可分;若对所有特征都有p(z|ω1)=p(z|ω2),则两类完全不可分。
交叠程度可用p(z|ω1)、p(z|ω2)之间的距离来度量,任何距离函数如果满足非负、两类完全不交叠时取最大值和两类分布密度相同时取零这几个条件,都可以作为类分离性的概率距离度量。
概率概率密度函数的似然比对于分类是一个重要的度量,人们在似然比的基础上定义了以下的散度[13]作为度量:
(8)
本文采用散度度量作为概率距离的度量,JD越大,则可分性越好。利用式(8)对不同Δt下6个特征的类条件密度分别进行计算,纵向对比可确定适合的时间尺度,横向对比可确定哪些特征在选定Δt下更能反映不同交通状态的差异。
3 AdaBoost分类器设计
特征变量选择完成后,就确定了样本数据,就可以训练分类器对两类交通状态进行分类。将正常交通状态标记为0,危险交通状态标记为1,选择AdaBoost分类器对交通状态进行分类,该方法基本思想是针对不同的训练集训练多个弱分类器,然后将这些分类器组合起来,构成一个最终的强分类器[14]。这种方法不需要精确了解样本空间分布,能够自适应调整弱学习算法的错误率。
本文中采用的弱分类器是分类和回归决策树(ClassificationAndRegressionTree,CART),在训练弱分类器的过程中,在每次弱学习后都重新调整样本空间分布,更新所有样本的权重,把被正确分类的样本权重降低,而增加被错误分类的样本权重。最终分类的结果是弱分类器的加权组合,权值代表该弱分类器的性能[15]。具体流程如下。
1)初始化训练样本的权重:
ωi=1/N;i=1,2,…,N
(9)
2)对第m次迭代,利用加权后的样本构造弱分类器fm(x),分类并计算分类错误率em,令
cm=lb ((1-em)/em)
(10)
3)更新样本的权值,令
ωi=ωiexp[cml(yi≠fm(xi))]
(11)
归一化使
(12)
其中:
(13)
4)重复执行2)~3)步直到m达到最大迭代次数M。
5)由M组弱分类器组合得到强分类器h(x),对于待分类样本x,分类器的输出为:
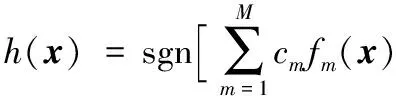
(14)
训练好分类器之后就可以对实时的样本数据进行分类,决策规则如式(2)所示,若某一时刻被决策为危险交通状态,则可采取合适的措施预防事故的发生。
在实际应用中,随着交通数据的累积,可以对最新采集的数据处理,更新分类器,实现动态调整,提高分类的准确性。
4 实验及结果
4.1 数据准备
本文中采用的是北京二环路上2014年10月16日到10月26日的交通流数据,有118个固定检测器,每2min记录一次;交通事故数据包括北京全市范围内事故发生时间及地点。
经过数据预处理,地点匹配等处理后得到412组危险交通状态数据及393组正常交通状态数据,每组数据包含事故时间、地点、平均气温、天气情况及该地点驶入驶出4个方向的交通流数据,危险交通状态数据包括事故发生时及前20min内(后文中确定具体的Δt)的交通流数据,正常交通状态数据是事故发生前50 min时(前人研究证明事故前50 min的交通状态与事故关系很小)及前20 min内的交通流数据。
在未进行特征选择前,每组样本包含时间,地点坐标、平均气温、天气状况、事故地点四个方向上22 min内的速度、占有率、车流量数据,共137维特征。归一化处理后,从两类数据中分别挑选250组数据共500组数据作为训练样本,剩余305组作为测试样本。
4.2 特征选择
采用Parzen窗估计方法对候选特征进行概率条件密度估计,然后通过对比不同类交通状态特征类条件密度的散度距离来确定合适的时间尺度及特征。
候选的交通流特征中包含驶入驶出4个方向,每个方向上包含有6个变量,另外,预选的数据中包含从2 min到22 min共10个时间尺度,对两类交通状态分别进行估计,共进行480次,然后计算不同类交通状态的散度距离,如表2所示。
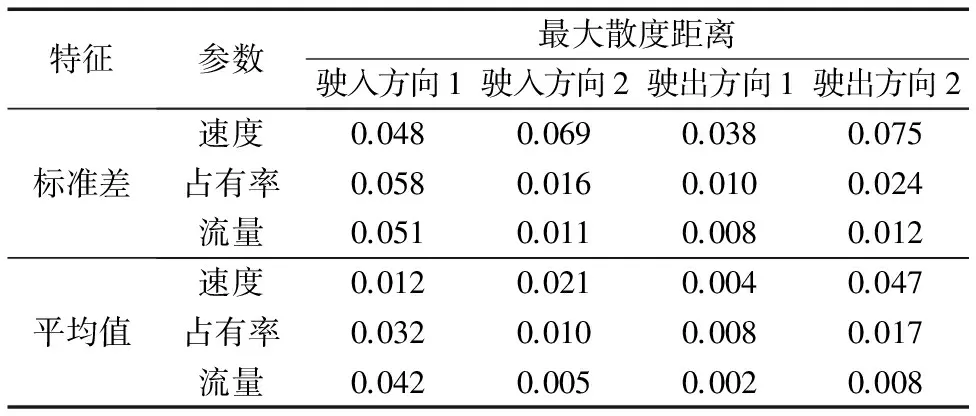
表2 不同特征最大散度距离
通过对比得知速度、占有率、车流量的标准差特征的散度距离比平均值的更高,表明交通流数据平均值在不同交通状态下差异性较小,并不能准确反映不同交通状态的特性,因此选择标准差特征作为特征变量,标准差特征估计结果,如图5所示。
通过图5中趋势可知,对于时间尺度,4个方向上速度、占有率、车流量的选择并不相同:Δt1={2,2,2},Δt2={2,8,6},Δt3={2,2,4},Δt4={2,2,2}。
对训练样本及测试样本分别按照上述结果提取数据,并计算标准差特征,使得样本特征均为时间、经纬度坐标、平均气温、天气状况、4个方向上速度、占有率、车流量的标准差,共17维特征。
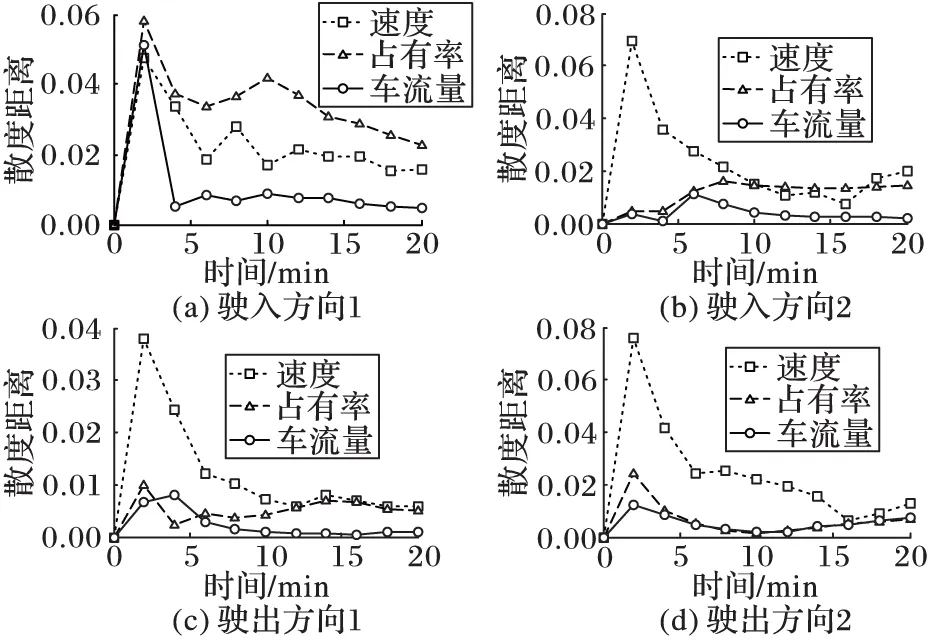
图5 不同时间尺度标准差特征散度距离
4.3 分类结果
训练AdaBoost分类器,对测试样本进行分类,测试样本中ω1的样本数量为143组,ω2样本数量为162组,分类结果如表3所示。
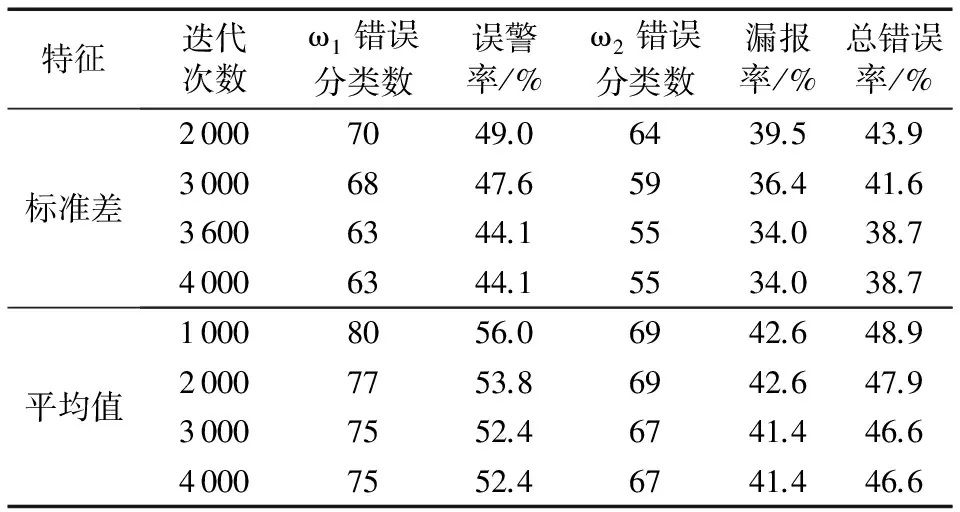
表3 本文方法的分类结果
从表3中可知,随着分类器最大迭代次数的变化,分类结果也不相同,对于平均值特征,当迭代次数为3 000时已经收敛,而对于标准差特征,迭代到3 600时达到收敛,且分类结果较平均值特征要好一些,因此对于特征的选取是正确的。分类效果最好时,危险交通状态的分类正确率为66%,而正常交通状态的正确率为55.9%,总正确率比平均值特征的正确率高7.9%。
国内的相关研究中文献[9]中预测精度最高,准确率为70%,利用文献[9]中方法对本文数据进行处理,结果如表4所示。
对比表3和表4可知,本文方法的分类结果要优于文献[9]中的方法,且文献[9]方法用于分类时出现了误警率增加而漏报率下降的情况,说明该方法并没有选取到合适的特征。
训练数据的增加,训练分类器时迭代次数的增加,都会引起训练时间的增加,但训练好分类器后,单个测试样本分类结果的输出时间很短,实验中305个测试样本的输出时间平均为15.236s,单个样本为49ms,因此在交通事故预测的实际应用中,可提前利用可随时更新的历史数据训练分类器,预测时只需将计算后的实时采集的交通流等数据输入到分类器中,就可以快速得到预测结果,从而实现事故的实时预测。
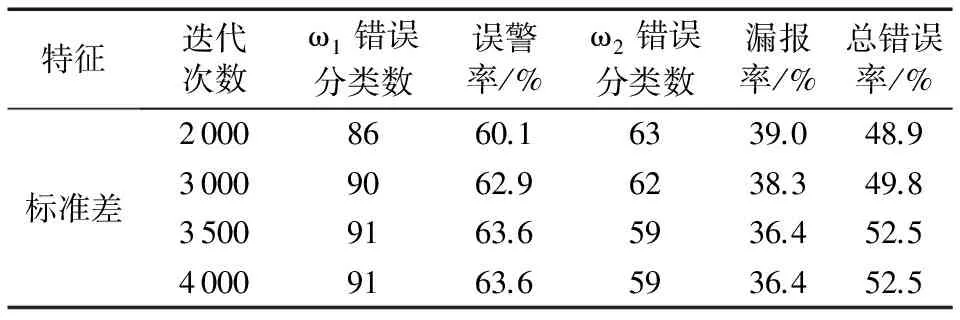
表4 文献[9]方法分类结果
5 结语
本文通过对北京二环上实时采集的交通流数据以及相同时间段内记录的交通事故数据进行处理,利用分类的方法对实时的交通事故进行预测,重点分析了能够表征不同交通状态的交通流特性,结果表明在事故地点不同方向上不同时间尺度上的速度、占有率以及车流量特征对交通事故发生的影响不同,且标准差特征要比平均值特征更加能反映不同交通状态的差异,分类的正确性也要更高。
从实验结果可知,通过分类来预测事故的发生是可行的,并且特征变量的选择至关重要,下一步将对交通状态更多的影响因素进行分析,将更多的特征加入到交通状态特征变量中,更好地提高分类预测的准确性。
)
[1]WANGL,ABDEL-ATYM.Predictingcrashesonexpresswayrampswithreal-timetrafficandweatherdata[C]//TRB2015:ProceedingsoftheTransportationResearchBoard94thAnnualMeeting.Washington,DC:TransportationResearchBoardBusinessOffice, 2015: 32-38.
[2]WANGL,ABDEL-ATYM.Real-timecrashpredictionforexpresswayweavingsegments[J].TransportationResearchPartC, 2015, 61: 1-10.
[3]YUR,ABDEL-ATYM.Utilizingsupportvectormachineinreal-timecrashriskevaluation[J].AccidentAnalysisandPrevention, 2013, 51: 252-259.
[4]HOSSAINM,MUROMACHIY.ABayesiannetworkbasedframeworkforreal-timecrashpredictiononthebasicfreewaysegmentsofurbanexpressways[J].AccidentAnalysisandPrevention, 2012, 45(1): 373-381.
[5]XUC,LIUP,WANGW,etal.Evaluationoftheimpactsoftrafficstatesoncrashrisksonfreeways[J].AccidentAnalysisandPrevention, 2012, 47: 162-171.
[6]XUC,ANDREWPT,WANGW,etal.Predictingcrashlikelihoodandseverityonfreewayswithreal-timeloopdetectordata[J].AccidentAnalysisandPrevention, 2013, 57: 30-39.
[7] 林震,杨浩.基于车速的交通事故贝叶斯预测[J].中国安全科学学报,2003,13(2):34-36.(LINZ,YANGH.Bayesianpredictionoftrafficaccidentbasedonvehiclespeed[J].ChinaSafetyScienceJournal, 2003, 13(2): 34-36.)
[8] 秦小虎,刘利,张颖.一种基于贝叶斯网络模型的交通事故预测方法[J].计算机仿真,2005,22(11):230-232.(QINXH,LIUL,ZHANGY.AtrafficaccidentpredictionmethodbasedonBayesiannetworkmodel[J].ComputerSimulation, 2005, 22(11): 230-232.)
[9]LVYS,TANGSM.Real-timehighwaytrafficaccidentpredictionbasedonthek-nearest neighbor method [C]// ICMTMA 2009: Proceedings of the 2009 International Conference on Measuring Technology and Mechatronics Automation.Piscataway, NJ: IEEE, 2009: 547-550.
[10] LV Y S, TANG S M.Real-time highway accident prediction based on support vector machines [C]// CCDC’09: Proceedings of the 2009 Chinese Control and Decision Conference.Piscataway, NJ: IEEE, 2009: 4403-4407.
[11] 贺邓超,张宏军,郝文宁.基于Parzen窗条件互信息计算的特征选择方法[J].计算机应用研究,2015,32(5):1387-1390.(HE D C, ZHANG H J, HAO W N.Feature selection based on conditional mutual information computation with Parzen window [J].Application Research of Computers, 2015, 32(5): 1387-1390.)
[12] 张宏稷,杨健,李延.基于条件熵和Parzen窗的极化SAR舰船检测[J].清华大学学报(自然科学版),2012,52(12):1693-1697.(ZHANG H J, YANG J, LI Y.Ship detection in polarimetric SAR images based on the conditional entropy and Parzen windows [J].Journal of Tsinghua University (Science and Technology), 2012, 52(12): 1693-1697.)
[13] 张学工.模式识别[M].3版.北京:清华大学出版社,2010:146-150.(ZHANG X G.Pattern Recognition [M].3rd ed.Beijing: Tsinghua University Press, 2010: 146-150.)
[14] 曹莹,苗启广,刘家辰.AdaBoost算法研究进展与展望[J].自动化学报,2013,39(6):745-758.(CAO Y, MIAO Q G, LIU J C.Advance and prospects of AdaBoost algorithm [J].Acta Automatica Sinica, 2013, 39(6): 745-758.)
[15] 贾润莹,李静,王刚.基于AdaBoost和遗传算法的硬盘故障预测模型优化及选择[J].计算机研究与发展,2014,51(增刊):148-154.(JIA R Y, LI J, WANG G.Optimization and choice of hard drive failure prediction models based on AdaBoost and genetic algorithm [J].Journal of Computer Research and Development, 2014, 51(Suppl.): 148-154.)
ZHANG Jun, born in 1964, M.S., associate professor.His research interests include intelligent transportation, image processing.
HU Zhenbo, born in 1992, M.S.candidate.His research interests include intelligent transportation, image processing.
ZHU Xinshan, born in 1977, Ph.D., associate professor, His research interests include machine learning.
Real-time traffic accident prediction based on AdaBoost classifier
ZHANG Jun, HU Zhenbo, ZHU Xinshan*
(SchoolofElectricalandAutomationEngineering,TianjinUniversity,Tianjin300072,China)
The traditional road traffic accident forecast mainly uses the historical data, including the number and the loss of traffic accidents, to predict the future trend, however, the traditional method can not reflect the relationship between the traffic accident and real-time traffic characteristics, and it also can not prevent accidents effectively.In order to solve the problems above, a real-time traffic accident prediction method based on AdaBoost classifier was proposed.Firstly, the road traffic states were divided into normal conditions and dangerous conditions, and the real-time collection of traffic flow data was used as the characteristic variable to characterize the different states, so the real-time prediction problem could be converted to a classification problem.Secondly, the Probability Density Function (PDF) of traffic flow characteristics under the two conditions in different time scales were estimated by Parzen window nonparametric estimation method, and the estimated density function was analyzed by the separability criterion based on probability distribution, then the sample data with appropriate characteristic variable and time scale could be determined.Finally, the AdaBoost classifier was trained to classify different traffic conditions.The experimental results show that the correct ratio by using standard deviation of traffic flow characteristics to classify test samples is 7.9% higher than that by using average value.The former can reflect the differences of different traffic states better, and also get better classification results.
intelligent transportation; accident prediction; classifier; traffic flow characteristic; Parzen window; separability criterion
2016-07-20;
2016-09-12。
张军(1964—),男,天津人,副教授,硕士,主要研究方向:智能交通、图像处理; 胡震波(1992—),男,山西忻州人,硕士研究生,主要研究方向:智能交通、图像处理; 朱新山(1977—),男,辽宁新民人,副教授,博士,主要研究方向:机器学习。
1001-9081(2017)01-0284-05
10.11772/j.issn.1001-9081.2017.01.0284
TP391.4
A
