关联规则及关键特征挖掘在临床透析时机选择中的应用
2017-04-13费海波
费海波,童 玲,李 智
(1.四川大学 电子信息学院, 四川 成都 610065;2.成都军区总医院 计算机网络管理中心,四川 成都 610083)
关联规则及关键特征挖掘在临床透析时机选择中的应用
费海波1,童 玲2,李 智1
(1.四川大学 电子信息学院, 四川 成都 610065;2.成都军区总医院 计算机网络管理中心,四川 成都 610083)
近年来,诸多学者利用数据挖掘技术进行了疾病发展趋势预测,合适的数据挖掘方法对获取有价值的数据信息尤为关键。然而,传统统计学方法不能得出具体指标与透析时机选择之间的相关规则,同时对综合性医院来说,选择合适的方法处理不同格式的原始数据较为困难。提出一种肾衰竭透析时机选择方法:利用信息增益从15个特征中选择出5大关键特征,根据提取的特征,利用K均值聚成3簇,在每一簇中运用Apriori算法,得到与透析时机选择有关的规则,并利用这些规则进行透析时机预测。实验结果表明,应用该算法能达到0.3以上的支持度和0.98以上的置信度。
信息增益;聚类;关联规则;透析时机
0 引言
终末期肾病(End Stage Renal Disease, ESRD)的治疗方法包括:包括血液透析、腹膜透析和肾移植[1-2],最常用的为透析方法。由于肾脏疾病的异质性和衰竭速度不同,因此需要建立一种准确的肾衰风险预测模型[3],帮助CKD患者得到更早期的个体化治疗。数据挖掘可以用来构建数据相关性模型,通过使用这些模型,不仅能得到数据的特征分布情况,还可以预测发展趋势。因此,数据挖掘可以为决策者、医生等提供科学的辅助决策。
透析时机选择[4-5]直接决定替代治疗的效果,日益受到学者们关注。近年来,已有学者利用数据挖掘的方法研究透析治疗过程。K R Lakshm等[6]对ANN、决策树和逻辑回归算法在肾透析存活能力中的性能作了比较,发现ANN性能最好,准确率为93.85%,但容易过拟合;N SRIRAAM等[7]提出了联合挖掘方法来进行肾衰竭参数估计,以改善肾透析病人的治疗,分类准确率会在50~97.7%之间变动,准确率波动较大;Yeh[8]利用决策树预测透析患者住院率,但决策树容易过拟合。本文提出了一种基于K均值和关联规则的慢性肾病透析时机预测方法,克服了过拟合局限,得到了透析时机预测规则,并实现了精准预测。
1 理论依据
1.1 透析时机选择预测流程
图1为透析时机选择预测流程。本研究采集成都某医院肾内科HIS系统数据,对数据进行预处理,首先去除血肌酐和尿素氮含有缺失值的患者;然后根据所选取的特征,去除特征值缺失值大于总样本15%的特征,其余缺失值用平均值替代;最后选出2 659个病人的实验室检查数据。其中包括透析患者1 202个,选取胱抑素c(CysC)、内生肌酐清除值(Ccr)、磷(P)、尿素氮(Bun)、钾(K)、钙(Ca)、白蛋白(Alb)、钠(Na)、性别(SEX)、舒张压(BH)、年龄(AGE)、收缩压(BL)、身高(HT)、肌酐(Scr)、体重(WT)作为特征,利用信息增益进行特征提取,将提取出的特征作为簇中心元素进行聚类,最后在每一簇中运用Apriori算法进行关联规则挖掘,得到与透析时机选择相关的规则。

图1 透析时机选择预测流程
1.2 信息增益
“信息熵”是度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为Pk(k=1,2,3,...,|y|),则D的信息熵定义为:
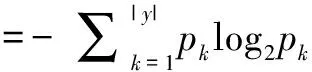
(1)
Ent(D)的值越小,则D的纯度越高。
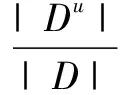
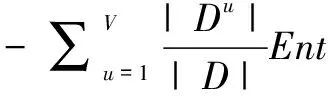
(2)
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,可用信息增益来进行特征选择[9]。

表1 样本部分数据

表2 信息增益值
1.3 K均值
本课题采用棋盘作为标定物体,棋盘是由不同黑白方块构成的平面格子。棋盘的标示点与其他标定物相比比较明显,处理起来也比较容易。将棋盘以不同的位置和角度放置,并采集相应图像,检测每组标定模板图像的角点,通过前面的几个步骤,得到多幅图像的角点数据后,可以调用OpenCV中的函数cvCalibrateCamera2()来进行摄像头的标定。由这个函数可以得到摄像头的内参数矩阵、畸变系数、旋转向量和平移向量。前两个构成摄像头的内参数,后两个构成了物体位置和方向的摄像头外参数。
首先根据设定的聚类簇数k,从样本集中随机选择k个样本作为初始均值向量,计算其余样本与各均值向量的距离,根据距离最近的均值向量确定样本集的簇标记,将样本划入相应的簇,然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值),不断重复这一过程直到后一轮迭代产生的结果与前一轮迭代相同才停止,得到最终的簇划分。

1.4 关联规则
关联规则挖掘过程:①找出所有频繁项集;②由频繁项集产生强关联规则。
最大频繁项集的生成是影响关联规则挖掘的关键问题。Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,使用频繁项集性质的先验知识,用逐层搜索的迭代方法来获得频繁项集。k-项集用于搜索 (k+1)-项集。首先,找出频繁1-项集的集合,记作L1。L1用于找频繁2-项集的集合L2,而L2用于找L3,如此下去,直到不能找到频繁k-项集。
Apriori性质:频繁项集的所有非空子集都必须也是频繁的。通过连接和剪枝两个过程来实现。
连接步:为找Lk,通过Lk-1与自己连接产生候选k-项集的集合,记作Ck。
剪枝步:Ck是Lk的超集,即它的成员可以是频繁的,也可以不是频繁的,但所有的频繁k-项集都包含在Ck中。扫描数据库,确定Ck中每个候选的计数,从而确定集都不可能是频繁k-项集的子集。因此,如果一个候选k-项集的(k-1)-子集不在Lk-1中,则该候选也不可能是频繁的,从而可以由Ck中删除[10]。
本文在关联规则挖掘前,首先对每一簇数据进行离散化,离散化间隔为10,将样本中每个特征的范围划分成10个区间。设置最低支持度为0.3,最低置信度为0.9。就簇1而言,通过计算肌酐、尿素氮、磷、胱抑素C、内生肌酐清除值、钠、钾等子集是否大于最低支持度值,将大于最低支持度值的特征设定为频繁1-项集的集合L1={Scr,Ccr,CysC,Bun,P,Na,K},然后利用L1找到频繁2-项集的集合L2={Scr∪Ccr,Scr∪Bun,...,Na∪K},直到不能找到满足最低支持度的频繁项集为止。簇2、簇3用同样的方法可以得到频繁项集。
2 实验分析
2.1 实验结果
对患者样本进行K均值聚类,最终聚类中心如表3所示,一共分为3簇,每个样本向量有5个元素,分别为肌酐、胱抑素C、内生肌酐清除值、尿素氮和磷。患者样本向量与各簇的聚类中心向量{853.3,4.7,27.6,28.1,2.1}、{227.5,3.5,36.2,12.1,1.3}、{85.6,1.2,76.6,5.9,1.2}中的某一簇聚类中心距离最小时,则归为相应的簇。最后得到簇1的样本有772条,占总样本的29%,簇2的样本有1346条,占总样本的51%,簇3的样本有541条,占总样本的20%。
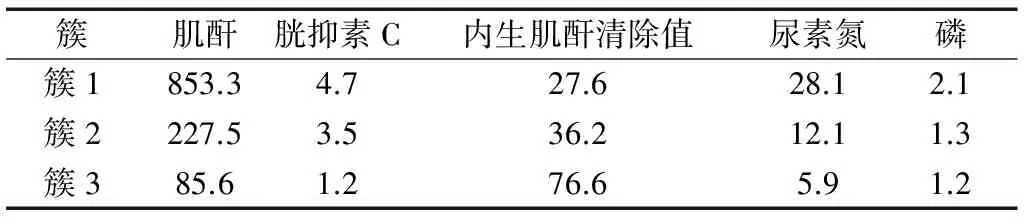
表3 最终聚类中心
利用关联规则算法,得到如表4所示的关联规则结果,第一列表示每条规则,第二列为该条规则所支持的样本数,最后一列表示该条规则的置信度。从表4可知,关联规则置信度均为100%,大于所设置的0.9,表明所得到的这些关联规则均为强规则,可以很好地说明肌酐、尿素氮与血液透析时机选择的强关联性。
2.2 实验总结
本研究使用k均值和Apriori确定与血液透析有关的特征和一些可能的规则。实验结果发现,当肌酐值在641-918.5(Scr=779.75±138.75)或者918.5-1196(Scr=1057.25±138.75)、尿素氮在21.97-30.33(Bun=26.15±4.18)范围内患者有较高的风险,应在此时合理选择透析。相反,肌酐值在45-207.2(Scr=126.1±81.1)、Ccr在58.46-68.86(Ccr=63.84±5.38)、Cysc在0.904-1.032(CysC=0.968±0.064)、P在1.02-1.26(P=1.14±0.12)、K在3.88-4.2(K=4.04±0.16)、Na在139.57-142.63(Na=141.1±1.53)、Bun在2.24-4.36(Bun=3.3±1.06)时有较低的风险。肾病学者明确表示,肌酐、尿素氮、内生肌酐清除率影响患者透析时机的合理性,胱抑素C和磷对患者透析时机选择的合理性影响目前不是很明确,需要更加深入的研究。通过与实际数据的对比,肌酐值在641~1 196范围内透析介入的概率是100%,尿素氮在21.97~30.33透析介入的概率是83%。
3 结语
正确把握透析时机可以缓解病人病情,提高治愈率。本研究将帮助医护人员找到一些关键特征预测病人透析时机。通过信息增益计算每个指标所包含的信息量确定最终选择的特征,并根据这些特征进行k均值聚类,最后对每一簇进行关联规则挖掘。最终结果可以辅助医护人员及时关注慢性肾病患者病情变化,一旦某个指标达到相应值时,患者就有较高的肾衰风险,选择合适的时机进行透析,从而达到更好的治疗效果。
[1] FRESENIUS MEDICAL CARE. ESRD patients in 2011 a global perspective[EB/OL].http:// www. vision-fmc.com/filesdownload/ESRD/ESRDPatientsin2011.pdf,2012-4-12/2016-3-24.
[2] ABBASI M, CHERTOW M G , HALL N Y. End stage renal disease[EB/OL].http://clinicaleviden ce.bmj.com, 2010-07-19/2016-3-24.
[3] JUSTIN B ECHOUFFO-TCHEUGUI, ANDRE P KENGNE. Risk models to predict chronic kidney disease and its progression: a systematic review[J]. PLOS Medicine,2012,9(11):1-18.
[4] NATIONAL KIDNEY FOUNDATION. Clinical practice guideline for hemodialysis adequacy[J]. Am J Kidney Dis,2015,66(5):884-930.
[5] NATIONAL KIDNEY FOUNDATION. Clinical practice guidelines and recommendations for peritoneal dialysis adequacy[J]. Am J Kidney Dis, 2006,48(suppl 1):S1-S322.
[6] K R LAKSHMI, Y NAGESH M VeeraKrishna, performance comparison of three data mining techniques for predicting kidney disease survivability[J].International Journal of Advances in Engineering & Technology, Mar.2014.
[7] N SRIRAAM, V NATASHA,H KAUR.Data mining approaches for kidney dialysis treatment[J]. Journal of Mechanics in Medicine and Biology, Volume 06, Issue 02. June 2010.
[8] J Y YEH, T,WU,C W TSAO.Using data mining techniques to predict hospitalization of hemodialysis patients[J].Decision Support Systems,2011,50(2):439-448.
[9] 周志华.机器学习[M].北京:清华大学出版社,2016.
[10] JAIWEI HAN,MICHELINE KAMBER, JIAN PEI. 数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2012.
(责任编辑:陈福时)
费海波(1990-),男,湖南衡阳人,四川大学电子信息学院硕士研究生,研究方向为医学数据挖掘;童玲(1979-),女,安徽合肥人,硕士,成都军区总医院计算机网络管理中心助理工程师,研究方向为医院信息管理、医疗数据分析;李智(1975-),男,四川成都人,博士,四川大学电子信息学院副教授、硕士生导师,研究方向为压缩感知、医学数据分析。
10.11907/rjdk.162784
TP319
A
1672-7800(2017)003-0118-03
