基于LDA与评价对象的微博观点摘要
2017-04-07朱艳辉张永平徐叶强
朱艳辉, 张永平, 杜 锐, 徐叶强
(1.湖南工业大学 计算机学院 湖南 株洲 421001; 2.广州索答信息科技有限公司 广东 广州 510663)
基于LDA与评价对象的微博观点摘要
朱艳辉1, 张永平1, 杜 锐2, 徐叶强2
(1.湖南工业大学 计算机学院 湖南 株洲 421001; 2.广州索答信息科技有限公司 广东 广州 510663)
针对微博话题观点摘要问题,提出一种基于LDA与评价对象相结合的微博观点摘要方法.首先,利用LDA模型得到话题的词分布矩阵和文档的话题分布矩阵,把两个矩阵的乘积作为各个词在句子中的权重分布矩阵,再利用词频与词权重分布矩阵的乘积作为词的重要度;然后,通过词的词性标注规则从句子中选择候选评价对象,再计算句子中候选评价对象的稳定性;最后,把句子中所有词的重要度与句子中所有候选评价对象的稳定性的总和作为句子权重,并从大到小排序,再进行观点句识别,并去除相似性较大的句子,抽取前20个句子作为话题观点摘要.实验结果表明,此方法可以有效地抽取微博观点摘要.
微博观点摘要; LDA; 评价对象
0 引言
随着互联网的飞速发展,越来越多的用户喜欢在网络中发表自己对某些事件的看法.微博作为重要的自媒体平台,是用户对热点事件发表评论和表达观点的主要途径,因此,研究如何快速准确地获取热点微博话题的观点摘要具有重要意义.自动摘要的抽取方法主要分为两大类:抽取式(extractive)和理解式(abstractive)[1].目前基于抽取式的文摘是主流方法.文献[2]在对文档进行聚类的基础上,加入句子位置、长度等特征对句子进行权重计算,从而抽取出权重较高的句子作为摘要.文献[3-5]基于LDA模型中主题的概率分布和句子的概率分布来计算句子的主题相似性,并结合句子长度、位置等特征抽取文档摘要.
以上方法都在文摘研究上取得一定效果,但是针对微博话题形成的文本,长度、位置等特征并不能取得很好的效果;且微博文本带有一定的观点性,抽取出具有观点性的句子作为摘要更合适.因此,本文提出了一种基于LDA和评价对象相结合的微博观点摘要抽取方法,以微博几个话题下的评论作为研究对象,把某个话题下的评论每20条一组作为一个文档.首先,根据LDA模型得到话题的词分布矩阵和文档的话题分布矩阵,并把这两个矩阵相乘,得到各个词在句子中的权重分布矩阵,词的权重分布矩阵再与词频相乘得到词的重要度;然后,通过词的词性标注规则从句子中抽取候选评价对象,随后计算句子中候选评价对象的稳定性;最后,计算出一个句子中所有词的重要度,再计算出句子中所有候选评价对象的稳定性,把两个结果的和作为句子的权重,按权重从大到小对句子进行排序,并判断句子的观点倾向,抽取具有观点性的前20个句子作为观点摘要.
1 基于LDA的词重要度矩阵计算
LDA(latent Dirichlet allocation)是一种概率主题模型,通过使用联合分布来计算在给定观测变量下隐藏变量的条件分布的概率模型,其中观测变量为词的集合,隐藏变量为主题.在已知语料和话题个数的情况下,可以通过LDA模型计算出话题的词分布矩阵和文档的话题分布矩阵,因此,我们通过这两个分布矩阵的乘积来定义句子中词权重分布矩阵,并把这个矩阵与词频向量相乘,所得结果作为词的重要度矩阵.
根据LDA的定义,文档生成过程中对应的观测变量和隐藏变量的联合分布为
(1)

在LDA模型中,最重要的就是文档的主题分布概率θd和主题的词分布概率βK,这两个参数在给定语料和已知话题K的情况下可以用Gibbs sampling[6]公式训练得到,算法如下:
Step 1 随机初始化,对语料中每篇文档的每个词w,随机赋一个topic编号z;
Step 2 重新扫描语料库,对每个词w,按照Gibbs sampling公式重新采样它的topic,在语料中进行更新;
Step 3 重复以上语料库的重新采样过程直到Gibbs sampling收敛;
Step 4 统计语料库话题下词的分布矩阵,该矩阵就是LDA的模型.
在得到话题的词分布矩阵之后,可以计算出相应的文档的话题分布矩阵.
根据LDA的概念,一篇文档的话题分布概率为
(2)
其中:Tj为第j个话题;Di为文档i,则文档的话题分布矩阵为
(3)
同理,话题下的词分布概率为
(4)
其中:Tj为第j个话题;Wk为词k,则话题的词分布矩阵为
(5)
把矩阵X和Y相乘则可以得到词在句子中的权重分布度矩阵,记为Z.虽然Z已经体现了句子中词的重要度,但微博语料中一个文档由约20个评价句组成,词频较高的词往往是讨论热点,所以计算文档的词频向量f,则所有词组成的重要度矩阵可以表示为
(6)
通过公式(6)就可以算出一个句子的重要度了.
2 评价对象稳定性计算
在微博语料中,一个话题下句子所讨论的对象越多,则表达的内容也就越多,句子在文档中权重也就越大,基于此思想,我们通过词性规则抽取句子中的词组作为候选评价对象,然后分别计算各个候选评价对象的稳定性,最后计算句子中候选评价对象的稳定性之和.
2.1 候选评价对象的抽取

表1 词性规则(部分)
根据句子中词语的词性标注出现的规则对候选评价对象进行抽取,规则选用文献[7]所总结的30组规则,部分规则见表1.
2.2 候选评价对象的稳定性计算
定义1 评价对象object通常是由多个词(w1w2…wn)组成,用各个词之间的紧密耦合程度,来衡量object的稳定性.本文采用公式(7)来计算评价对象的稳定性:
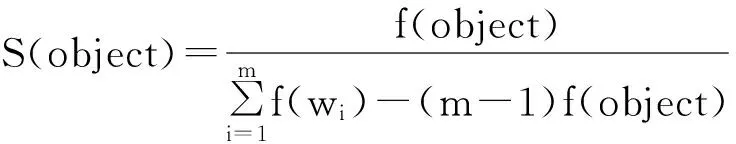
(7)
其中:object表示某个候选评价对象;f(object)表示object在文档中出现的频率;f(wi)表示组成object的词wi在文档中出现的频率;m表示组成该object的词个数;S(object)表示评价对象的稳定性.若S(object)的值越接近1,则object是一个评价对象的概率就越大.
则句子中所有候选评价对象之和为

(8)
其中:n表示句子中候选评价对象的个数;S(objecti)表示第i个候选评价对象的稳定性.
3 微博观点摘要抽取
根据公式(6)和(8),则一个句子的权重计算公式为
Weight(sentence)=WeightLDA(sentence)+Weightobject(sentence),
(9)
通过公式(9)计算出话题下每个句子的权重后对句子进行观点识别,具体步骤是:首先,选用知网[8]的情感词典和评价观点词典合并去重,得到观点词库8 746个,采用文献[9]的方法对词典进行扩建,最后得到观点词14 064个;然后,判断句子中是否包含观点词;最后,把包含观点词的句子按照句子权重从大到小排序,并选出前40个句子.
在经过了观点句识别之后,句子按照权重从大到小排序.这些排序的句子中有可能出现前几个句子所描述的意思相近,这就需要对这些句子进行相似性排除.本文的句子相似性排除算法如下:
Step 1 选择权重最高的句子并抽取候选评价对象;
Step 2 将剩下的所有句子也抽取出各自的候选评价对象;
Step 3 把各个句子的候选评价对象与Step 1中的候选评价对象进行对比,若相同的个数越多,则惩罚越大,计算公式为
(10)
其中:m是句子中候选评价对象相同的个数,并且m≤10,若m>10,则s=0;
Step 4 根据公式(10)把句子进行重新排序,从40个观点句中选择前20个句子作为微博摘要.
4 实验结果与分析
4.1 实验语料及评价指标
本文采用COAE2016任务1发布的10个微博话题语料,每个话题由约20个文档组成,每个文档由约20个评论句组成.
评价指标采用COAE2016任务1制定的评价指标[9],该评价指标采用评测工具ROUGE,广泛应用于DUC(document understanding conference)的摘要评测任务中,挑选其中的3个指标:R_1、R_2、R_SU4,每个指标又分别有召回率、准确率和F值,分别为:R_1_R、R_1_P、R_1_F、R_2_R、R_2_P、R_2_F、R_SU4_R、R_SU4_P和R_SU4_F共9个指标.
R_N的计算公式为

(11)
在本次实验中N的取值为1和2,即R_1和R_2.在公式(11)中,S表示候选摘要组成的集合;n表示n-gram的长度;referenceSummaries是候选摘要;Countmatch(gramn)表示同时出现在一篇候选摘要和参考摘要的n-gram个数;Count(gramn)表示参考摘要中n-gram的个数.
R_SU4的计算公式为

(12)
其中:skip2(A,B)表示候选摘要A与参考摘要B的skip-bigram匹配次数;C(m,2)的计算公式为
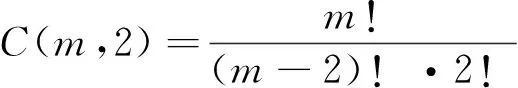
(13)
其中:m表示skip-bigram的最长跳跃距离,COAE2016任务1选择的跳跃距离为4.
4.2 语料预处理
预处理过程为:先用文献[5]的方法对语料进行分词标注,然后过滤停用词、符号、网址等噪声,最后建立词袋模型.
4.3 实验结果
本文共做了两组实验,一组是本文提出的方法,另一组是文献[3]的方法.实验结果见表2和表3.
表2中,topic ID从1~10分别是:“58同城”、“起亚K5”、“捷豹XFL”、“盗墓笔记”、“封神演义”、“郭德纲”、“iphone7”、“梅西退出国家队”、“姚明”和“支付宝”.
从表2可以看出,本文方法在各个话题中的结果都比文献[3]要好很多,特别在话题“封神演义”中,本文方法的R_1_P值达到0.447 37,在话题“姚明”中,本文方法的R_1_R、R_1_P和R_1_F值分别是0.412 44、0.343 70和0.374 95.表3的平均结果中,本文方法都优于文献[3].实验结果表明,本文方法可以有效识别出微博话题下的观点摘要.
5 总结
本文以COAE2016任务1提供的微博话题语料进行研究,提出了一种基于LDA和评价对象的微博话题观点摘要抽取方法.实验结果表明,将评价对象作为特征加入文本摘要中能提高实验效果,但本文的不足在于对句子相似性的排除不是很理想,这也是今后我们努力的方向.
[1] XU Y D. Multi-document automatic summarization technique based on information fusion[J]. Chinese journal of computers, 2007, 30(11):2048-2054.
[2] 林立, 胡侠, 朱俊彦. 基于谱聚类的多文档摘要新方法[J]. 计算机工程, 2010, 36(22):64-65.
[3] 吴登能, 袁贞明, 李星星. 基于组合特征LDA的文档自动摘要算法[J].计算机科学与应用, 2013,3(2):145-148.
[4] BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. Journal of machine learning research, 2003(3):993-1022.
[5] 于江德, 王希杰, 樊孝忠. 基于最大熵模型的词位标注汉语分词[J]. 郑州大学学报(理学版),2011,43(1):70-74.
[6] SHONKWILER R W, MENDIVIL F. Introduction to monte carlo methods[M].New York:Springer, 2011.
[7] 徐叶强, 朱艳辉, 王文华,等. 中文产品评论中评价对象的识别研究[J]. 计算机工程, 2012, 38(20):140-143.
[8] 中国知网. 《知网》情感分析词语集:Beta版 [EB/OL].(2007-10-22)[2016-11-01].http://www.keenage.com.
[9] 杜锐, 朱艳辉, 鲁琳,等. 基于SVM的中文微博观点句识别算法[J]. 湖南工业大学学报(自然科学版),2013, 27(2):89-93.
(责任编辑:王浩毅)
Micro-blog View Summary Based on LDA and Evaluation Object
ZHU Yanhui1, ZHANG Yongping1, DU Rui2, XU Yeqiang2
(1.SchoolofComputerScience,HunanUniversityofTechnology,Zhuzhou421001,China;2.SUMMBA,Guangzhou510663,China)
A micro-blog view summarization method based on LDA and evaluation object was proposed for micro-blog topic. Firstly, the importance of words was calculated by multiplying word frequency and word weight matrix of each word, and the weight matrix was calculated by multiplying the doc-topic matrix and the topic-word matrix which obtained from LDA model.Secondly, the cadidate evaluation objects were extracted before the stability of a candidate object was calculated by a defined formula; Finally, the topic summary was extracted from the sentences which had more evaluation objects and high score of word weight. This method was proved to be effective with experiments.
view summarization; LDA; evaluation object
2016-11-10
国家自然科学基金项目(61402165);国家社会科学基金项目(12BYY045);湖南省教育厅重点项目(15A049).
朱艳辉(1968—),女,湖南湘潭人,教授,主要从事自然语言处理研究,E-mail: swayhzhu@163.com;通讯作者:张永平(1989—),男,贵州遵义人,硕士研究生,主要从事自然语言处理研究,E-mail:780235260@qq.com.
TP391.4
A
1671-6841(2017)01-0045-05
10.13705/j.issn.1671-6841.2016333
