一种可定制参考过程模型的自动构建方法
2017-04-07凌济民
凌济民 张 莉
(北京航空航天大学计算机学院 北京 100191) (lingjimin@buaa.edu.cn)
一种可定制参考过程模型的自动构建方法
凌济民 张 莉
(北京航空航天大学计算机学院 北京 100191) (lingjimin@buaa.edu.cn)
过程模型在企事业单位中的应用日益普遍.由于企业为每个特定业务需求单独开发过程模型是复杂并且高成本的工作,因此企业通常使用参考过程模型作为过程模型开发的基础,以有效降低成本并提高开发效率和质量.由于参考模型需要领域专家大量的领域分析和抽象建模工作,如何基于领域内已有的过程模型变体自动创建出初步的参考模型以辅助领域专家的工作成为有意义的研究问题.现有的参考模型构建方法存在输出模型复杂度较高或难以全面表达领域内多样推荐实践等问题.为了创建代表性和可读性更强的参考模型,基于相似过程片段聚合技术,提出了一种支持层次化子过程结构的可定制参考过程模型的自动构建方法,全面支持可定制参考模型中基础过程、变更可选项以及约束关系的自动构建.案例研究结果表明:该方法生成的参考模型具有良好的领域代表性和模型复杂度.
过程模型;过程变体;参考模型;可定制过程模型;过程片段
随着企业对过程重视程度的不断提高,过程模型在不同企事业单位中的使用变得日益普遍,企业通常通过建立过程模型分析和优化它们的业务流程[1].过程模型的开发包括活动及其关系的识别、选择建模工具和建模语言以及描述其他过程相关元素等大量工作.由于企业为每个特定业务需求单独开发过程模型是复杂并且高成本的工作,因此如何有效地裁剪和改编企业现有的过程模型以满足业务需求的变化是当前企业组织所需的重要能力之一.参考模型是描述特定领域内推荐实践的概念模型,因此在企业组织应对上述问题时被广泛应用.通过使用参考过程模型(reference process model)作为过程模型开发的基础可以有效降低成本并提高开发效率,模型的质量也因为最佳实践的重用得以保证[2].
传统的参考过程模型(以下简称为参考模型)通常基于经典的过程建模语言构建(例如由EPC语言描述的SAP R3参考模型),难以充分描述系统的可配置性和流程的可变性,领域内多样的推荐实践难以在单一的传统过程模型中体现,并且无法提供相应的决策支持或约束来引导用户对参考模型进行裁剪或修改.为了解决上述问题,现有研究通常引入配置[2-6]或定制[6-9]的概念扩展传统过程建模方法来建立参考模型.由于创建此类参考模型需要领域专家大量的领域分析和抽象建模工作,因此如何基于领域内已有的过程变体(process model variants)自动创建出初步的参考模型以辅助领域专家的建模工作成为有意义的研究问题.
目前针对参考模型自动构建的研究主要采用过程模型合并[10-11]以及过程变体挖掘技术[12-14],在一组过程变体的基础上归纳创建一个具有代表性的统一模型.过程模型合并技术通过将一组过程变体合并到一个可配置过程模型中,但是此类方法基于过程变体的两两合并,因此最终得到的过程模型的规模会随着过程变体数量的增加而迅速增长,并且过程模型不支持层次化的子过程结构,因此参考模型的复杂度较高;过程变体挖掘技术能够自动挖掘创建出一个与现有过程变体集合最接近的过程模型,但是此类方法仅支持构建传统非可配置定制的过程参考模型,因此难以全面表达领域内多样的推荐实践,从而降低了参考模型的领域代表性.
为了解决现有研究中存在的上述问题,本文提出了一种支持层次化子过程结构的可定制参考过程模型的自动构建方法.通过检测并聚合过程变体集合中相似的模型片段,将过程变体转化为具有子过程的层次化过程模型,并提出可定制过程模型的自动构建方法,逐层细化实现参考模型中的每一个子过程,进而生成完整的分层可定制的参考模型,最后基于一系列来自工业界的实际过程模型对所提出的方法进行了评估和讨论.
本文的贡献有2个方面:1)提出了基于相似过程片段检测和聚合的过程模型结构层次化方法,通过层次化结构提高复杂过程模型的可读性;2)提出了基于过程变体(或相似过程片段)集合的可定制过程模型(或子过程片段)的自动构建方法,实验评估表明该方法生成的参考模型能够具有较低的复杂度和良好的领域代表性.
1 背景和研究基础
1.1 过程变体的示例
由于建模目标和应用场景的不同,同一业务过程可能被描述为多个相似的业务过程模型,即过程变体.本节给出一组来自工业界的真实过程变体的示例,贯穿全文方法的阐述.这组过程变体来自于国内某专营机场贵宾服务与管理的企业(以下简称贵宾公司)的业务流程.该企业为不同类型的旅客提供不同但又相似的服务,例如政府贵宾、商务贵宾、商务嘉宾以及其他个人会员.此外,贵宾公司在全国各地拥有若干家成员子公司,它们的业务流程之间也具有一定的差异性.上述因素导致了过程变体广泛共存的现象,因此有效地构建参考模型有助于提高企业未来业务流程的规范性、可重用性和可扩展性.
本节涉及的过程模型示例描述了贵宾公司的服务预订接入流程,图1给出了其中3个经过简化的由BPMN建模语言描述的过程模型变体.为了便于清晰地展示模型结构,模型中具体的活动命名未在图中给出,示例模型包含的更多语义信息可以从在线链接①获取.服务预订请求可能来自于400服务电话、移动应用以及电话专线等.这些过程变体针对不同来源的预订请求以及不同类型的旅客描述了相应的预订接入流程.从图1可以看出,这些过程变体表达的业务流程是相似的,但它们在所包含的活动、活动的命名以及模型的结构等方面存在一定的差异,如何基于这些描述当前业务现状的过程变体自动地构建面向该领域的可定制参考过程模型并控制模型的复杂度是本文需要研究的关键问题.
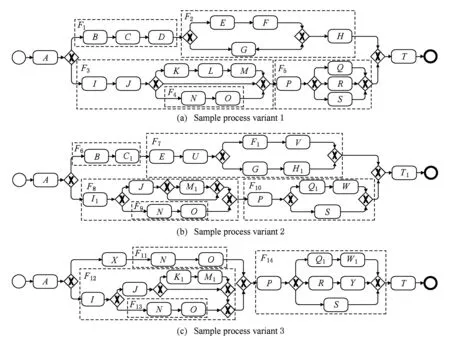
Fig. 1 A running example of process model variants图1 过程变体集的示例
1.2 过程模型和过程片段
目前在实践中已有多种过程建模语言用于描述业务过程,包括BPMN,EPC,UML活动图等.我们希望本文提出的方法能够应用于不同建模语言,因此本文将使用过程图(process graph)而非某种特定的建模语言来表示所有的过程模型(或过程片段),它由当前常见的过程建模语言的通用元素抽象而成.
定义1. 过程图.一个过程图是一个连通有向图,通过四元组G=(N,E,T,L)表示,其中:
1)N表示模型中所有节点的集合;
2)E⊆N×N表示连接节点之间有向边的集合;
3)T:N→t表示为节点分配的类型属性,例如考虑BPMN建模语言中的基本流对象,t∈{event,activity,gateway};
4)L:N→label表示为节点分配的命名标签,例如考虑BPMN建模语言中的基本元素,如果T(n)=event∨activity,则L(n)为该模型节点的名称;如果T(n)=gateway,则L(n)∈{XOR,AND,OR}.
由于本文需要建立包含层次化子过程结构的参考模型,因此我们需要将过程模型中的过程片段抽取为子过程.由于在过程模型中子过程是基于调用返回机制实现的,因此我们规定抽取的子过程为单入口单出口过程模型片段(single-entry-single-exit process fragment)[15],以下简称为过程片段.简单地说,过程片段就是过程图中由单一入口开始并且由单一出口结束的任何区域,利用环路等价算法[16]对过程图进行处理,可以在线性时间复杂度内将过程图层次化分解为一系列过程片段.
定义2. 过程片段.在一个过程图G=(N,E,T,L)中,一个过程片段F=(N′,E′,T′,L′)是G的一个非空子图,即N′⊆N且E′=E∩(N′×N′),并且满足:存在边e,e′∈E,使得E∩((NN′)×N′)={e}以及E∩(N′×(NN′))={e′}.其中e和e′分别称为过程片段F的入边和出边.
为了便于模型的展示,图1中的虚线框仅仅标识出了过程模型所包含的少部分过程片段.根据定义2可以注意到,过程片段可以相互重叠或嵌套,例如F1和F2可以组成一个更大的过程片段,而活动D和F2同样可以构成过程片段.因此在本文方法中,任何单入口单出口的区域都有可能被抽取为子过程活动.
1.3 可定制过程模型
为了描述过程模型的可变性,现有研究通常采用配置(configuration)[2-6]或定制(customization)[6-9]2种策略.可配置过程模型将所有已知的过程变体汇集到1个模型中描述,该模型包含了所有变体的行为,用户通过裁剪与业务需求无关的配置项得到所需的过程模型;而可定制过程模型包含1个基础过程(base process)和一系列变更可选项(change options),用户通过定制变更可选项并将其作用于基础过程上得到所需的过程模型.不难看出,可配置过程模型的建立需要预定义所有可能的过程变体,并且自身难以随着过程变体的增加或修改而演化,其灵活性相比可定制过程模型较差[17].本文采用可定制过程模型作为生成的参考模型的表示形式,下面给出本文所构建出的可定制参考过程模型的详细定义.
定义3. 可定制过程图.一个可定制过程图是一个四元组CG=(G,P,O,S),其中:
1)G表示基础过程对应的过程图G=(N,E,T,L);
2)P表示依附于基础过程G上位于节点前后的可定制点构成的集合,即P⊆N×{pre,post};
3)O表示变更可选项构成的集合,1个变更可选项包括一系列变更操作,包括3种:
① 插入操作insert(F,p1,p2,opt).将过程片段F按照opt方式插入可定制点p1和p2之间,其中opt∈{SEQ,AND,XOR,OR},SEQ表示直接插入p1和p2之间,AND表示插入F并使之与p1和p2之间现有的过程片段构成并行结构,XOR和OR的含义与AND同理.
② 删除操作delete(p1,p2,opt).将可定制点p1和p2之间包含的过程片段按照opt方式删除,其中opt∈{CON,DIS},CON表示删除过程片段后添加从p1到p2的控制流连接,而DIS表示不添加该控制流连接.
③ 修改操作modify(n,label).将节点n的命名标签修改为label.
4)S表示变更可选项之间约束关系构成的集合,包括蕴含(implies)和互斥(excludes)2种类型.变更可选项O1蕴含变更可选项O2表示,当选择O1时,O2也必需被选中,记作O1→O2; 变更可选项O1与变更可选项O2互斥表示O1与O2不能被同时选择,记作O1⊗O2.
定义4. 可定制参考过程模型.一个可定制参考过程模型是一个二元组CP=(CGC,M),其中:
1)CGC表示由各层次的可定制过程图所组成的集合;
2)M表示各个可定制过程图CG与子过程活动之间的映射关系.
为了便于理解上述定义,图2给出了1个基础过程及其相关的一组变更操作的示例,图2(a)所示的基础过程中包含了a,b,c,d,e共5个可定制点,图2(b)~(f)给出了基础过程经过插入、删除和修改变更操作后得到的过程模型.

Fig. 2 Examples of change operations in customizable process graph图2 可定制过程图的变更操作示例
2 可定制参考过程模型的自动构建方法
为了使构建出的参考模型支持层次化子过程结构,我们首先通过识别并聚合过程变体集合中相似的过程片段,将过程变体转化为支持子过程活动的过程模型.然后,提出可定制过程模型的自动构建算法,逐层细化实现参考模型中的每一个可定制过程图,最终生成完整的分层可定制的参考模型.上述研究内容的详细流程如图3所示,本节将对图中的各个步骤进行解释说明.

Fig. 3 Working procedure overview of the method to automatically build reference process model图3 参考模型的自动构建方法的工作流程概览
2.1 相似过程片段的聚合
为了识别并聚合过程变体集合中相似的过程片段,首先需要定义过程片段之间的相似性度量方法.由于过程片段也是由过程图表示,因此我们使用在过程模型相似性度量研究领域广泛应用的图编辑距离相似度[18]的方法度量过程片段之间的相似性.过程图之间的编辑距离是从一个图变换到另一个图所需的最少编辑操作的数量.编辑操作包括3类:插入(或删除)节点、插入(或删除)边以及替换节点.定义5给出了该度量的详细定义.

Sim(G1,G2,M)=1-avg(fsubn,fskipn,fskipe),
fskipn=|skipn|(|N1|+|N2|),
fskipe=|skipe|(|E1|+|E2|),

其中,fskipn表示插删节点占过程图中所有节点的比例;fskipe表示插删边占过程图中所有边的比例;fsubn表示替换节点的平均操作开销.
上述定义中的SimN(n1,n2)表示2个过程图中的2个节点之间的相似度值,取值范围为[0,1],使用文本相似度和上下文相似度相结合的方法进行度量,具体细节可以参考本文的前期工作[19].过程图G1和G2之间的图编辑距离相似度是所有节点对应关系M相应的Sim(G1,G2,M)中的最大值,记作SimG(G1,G2).由于寻找最佳映射关系M并计算SimG具有指数级复杂度,因此我们使用文献[20]中给出的一种改进的贪心算法计算该相似度值.
由此可以得到由过程片段两两之间相似度值构成的相似度矩阵.需要说明的是,由于将单个活动抽象为子过程活动是没有意义的,因此只包含单个节点的过程片段不出现在相似度矩阵中.此外,如果2个过程片段属于同一个过程变体并且它们之间存在重叠的节点,它们之间的相似度值记为0,因为它们之间相互重叠导致无法同时被抽取为子过程活动.最后,为了便于存储和数据处理,我们只需要在矩阵中记录不低于给定阈值δ的相似度值,其他不相似的过程片段之间的相似度值在矩阵中也记为0.例如给定阈值δ=0.5,图1示例过程变体中部分过程片段构成的相似度矩阵如表1所示:
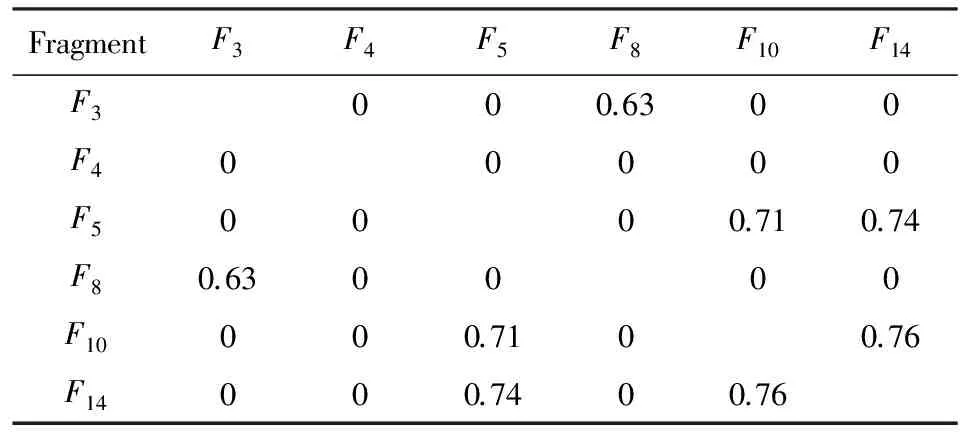
Table 1 Similarity Matrix of Process Fragments
随后需要基于相似度矩阵聚合相似的过程片段,我们认为一组过程片段能够被聚合,当其中任意元素两两相似,即在相似度矩阵中的对应值不为0.为了实现该目标,我们使用经典的层次聚类算法(hierarchical agglomerate clustering, HAC)[21]实现.HAC算法的基本思路是:1)将集合中每一个对象都视为1个簇(cluster);2)在每一次迭代中合并距离最短的2个簇,直至所有对象都包含在同一个簇中为止.
如何定义2个簇之间的距离是HAC算法的关键问题之一,通常有单链、全链和组平均3种策略.单链将距离定义为不同2个簇的2个最近点之间的距离;反之,全链则考虑最远点之间的距离;组平均则将距离定义为取自2个不同簇的所有点对邻近度的平均值.考虑到1个簇内任意过程片段两两相似的要求,本文选取全链策略以保证该目标的实现,即2个片段簇之间的相似度为取自不同簇的2个片段的相似度最小值.因此,本文将HAC算法实施如下:1)将每个过程片段都各自视作1个簇,然后合并2个相似度最高的簇形成1个新簇,在相似度矩阵中删除这2个簇,并按照全链策略计算新簇与其他簇的相似度,插入到相似度矩阵中;2)重复上述合并步骤直到相似度矩阵中不存在大于0的值结束,如算法1所示.在示例模型中,表1所示的相似度矩阵执行HAC算法后能够最终得到3个过程片段簇,即{F5,F10,F14},{F3,F8},{F4}.
算法1. 相似过程片段聚合算法.
输入:过程片段集合FragSet、片段相似度矩阵FragMx;
输出:过程片段簇集合ClusterSet.
① for eachFragSet中的过程片段Fido
② 添加过程片段Fi到片段簇Clusteri中;
③ 添加片段簇Clusteri到ClusterSet中;
④ end for
⑤ 初始化簇相似度矩阵ClusterMx;
⑥ while |ClusterSet|>1并且矩阵ClusterMx中的值不都为0 do
⑦ 从ClusterSet中选择相似度值最高的2个簇C1和C2;
⑧ 合并C1和C2至1个新簇CM;
⑨ 添加CM至ClusterSet,并从ClusterSet中删除C1和C2;
⑩ 计算CM与ClusterSet中其他簇的相似度,并更新ClusterMx;

2.2 可定制参考过程模型的构建
将过程变体中的相似过程片段聚合之后,为了逐层细化构建可定制参考模型,需要在每一层过程图中选择需要抽象为子过程的过程片段簇.由于过程片段簇之间可能存在相互重叠或嵌套(例如簇{F3,F8,F12}与簇{F4,F9,F11,F13}之间存在共有节点),为了将过程片段抽象为子过程活动,需要在该层过程图包含的过程片段簇中选择互不相交的簇,将它们加入未处理集合中供后续迭代,从而实现模型的逐层细化.为了使每个层次的过程图的可读性更高,我们尽可能地优先选择过程片段平均规模更大的簇.例如,考虑初始迭代的情况,即当前需要处理的是图1中的3个顶层过程图,最终选择的过程片段簇为:{F1,F6},{F2,F7},{F3,F8,F12},{F5,F10,F14},使用4个子过程活动分别替换上述4个簇包含的过程片段,然后将这4组片段的过程图加入到未处理集中,并进入顶层可定制过程图的构建流程,重复上述步骤直至不存在未处理的过程片段簇,从而得到最终的参考模型.
基于一组相似的过程图构建相应的可定制过程图主要包括3项工作:创建基础过程图、识别可定制点和变更可选项以及创建变更可选项之间的约束关系,下面我们对这3项工作进行详细说明.
2.2.1 创建基础过程图
为了使可定制过程图中的基础过程尽可能地具有代表性,可以采取4个策略[7]进行设计:领域专家定义标准过程、选择最频繁执行的变体、使用与各个变体平均距离最短的模型、采用所有过程变体的交集或并集.前2种策略需要人工建模或流程执行的数据,而取并集或交集的方法可能导致基础过程过于复杂或简单,从而降低基础过程的可读性或代表性,因此本文使用最短平均距离的策略自动地创建基础过程.
创建基础过程的步骤如下:
1) 首先在输入过程图集合中选择中心元素(与其他过程图之间的平均相似度最高者)作为初始的基础过程;
2) 搜索基础过程的近邻过程图(对基础过程图进行1次变更操作后得到),若存在比基础过程图更优(即与输入过程图的平均相似度更高)的邻近过程图,选择其中最优的1个替换当前的基础过程;
3) 重复步骤2)直至不能找到比当前基础过程更优的近邻过程图结束.
变更操作包括插入活动、删除活动以及重命名活动3类.任何在输入过程图中出现但不存在于当前基础过程中的活动允许被插入,活动可以被修改为其他输入过程图中与之匹配的相似命名,基础过程中的任何活动都允许被删除.

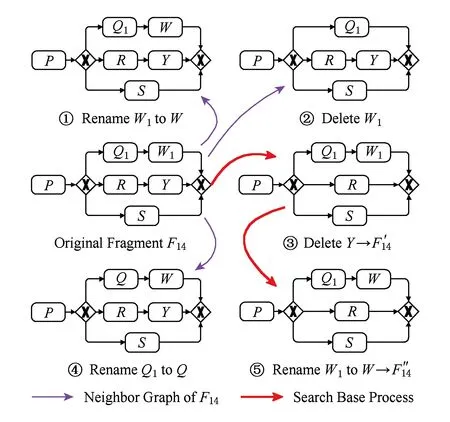
Fig. 4 Examples of change operations to F14图4 对过程片段F14的变更操作示例
2.2.2 创建可定制点和变更可选项
为了创建可定制点和变更可选项,需要识别基础过程G到各个过程图Gi之间的转换操作,如算法2所示,基础过程G到每一个过程图Gi的转换操作序列可以初始地视为1个变更可选项Optioni,具体的规则如下:
1) 若Gi中不存在与G中的活动Act匹配的活动,则向Points中添加可定制点Actpre和Actpost,并根据Act的上下文节点在Gi中的连通性判断删除Act后是否需要添加Actpre到Actpost的控制流连接,然后向变更可选项Optioni中添加删除操作delete(Actpre,Actpost,opt);
2) 若Gi中存在活动Act′与G中的活动Act匹配但命名存在差异,则向Optioni中添加修改操作modify(Act,Act′);
3) 若G中不存在与Gi中的活动Act匹配的活动,首先根据Act在Gi中的上下文节点确定其在G中的插入位置和操作方式,例如需要将Act按照opt方式插入到活动B和C之间,则向Points中添加可定制点Bpost和Cpre,并向Optioni中添加插入操作insert(Act,Bpost,Cpre,opt).
算法2. 可定制点和变更可选项构建算法.
输入:基础过程图G、过程图集合Variants;
输出:可定制点集Points、变更可选项集Options.
① 初始化集合Points和Options;
② for eachGi∈Variantsdo
③ 在Options中新增变更可选项Optioni;
④ for each活动Act∈Gdo
⑤ ifAct∉Gi并且Gi中不存在与Act相似匹配的活动then
⑥ 向Points中添加Actpre和Actpost;
⑦ 根据Act的上下文节点在Gi中的连通性判断删除操作方式opt;
⑧ 向Optioni中添加删除操作delete(Actpre,Actpost,opt);
⑨ else ifAct∉Gi并且Gi中存在与Act相似匹配的活动Act′ then
⑩ 向Optioni中添加修改操作modify(Act,Act′);







最后,我们针对创建出的可定制点和变更可选项进行一些优化.1)如果2个插入或删除操作对象可以组合成为1个过程片段,则将这2个操作合并为针对过程片段的操作,并删除过程片段内部相应的可定制点;2)由于1个相同的变更操作可能在多个变更可选项中出现,例如过程图G1和G2都可能包括从基础过程中删除活动Act的操作,因此我们针对变更可选项与变更操作之间的组合进行优化,将同时出现在完全相同的变更可选项中的变更操作组合到1个新的变更可选项中.图5给出了变更可选项优化的示例,可以看出,经过优化后的变更可选项能够去除重复出现的变更操作.

InitialChangeOptionsOption1:modify(Q1,Q)delete(Rpre,Rpost,DIS)modify(W,W1)Option2:insert(Y,Rpost,g2pre,SEQ)Option3:modify(W,W1)insert(Y,Rpost,g2pre,SEQ)NumChange→Options:3NumChangeOperations:6 OptimizedChangeOptionsOption1:modify(Q1,Q)delete(Rpre,Rpost,DIS)Option2:insert(Y,Rpost,g2pre,SEQ)Option3:modify(W,W1)Constraints:Option1→Option3Option1 Option2NumChange→Options:3NumChangeOperations:4

Fig. 5 Optimization to change options
图5 变更可选项优化
2.2.3 创建变更可选项之间的约束关系
在自动构建出基础过程以及可定制点和变更可选项之后,需要创建变更可选项之间存在的约束关系.约束关系包括蕴含和互斥2类,O1蕴含O2表示选择了变更可选项O1后也需要选择O2,而互斥关系则表示2个变更可选项不能同时选择.我们提出3条规则,通过两两比较变更可选项,检查它们对于每条规则的符合性来创建约束关系:
1) 为了避免操作冲突,若2个变更可选项包含针对同一个活动(或过程片段)的变更操作,则为这2个变更可选项之间建立互斥约束;
2) 若某变更可选项包含作用于可定制点p1和p2之间的变更操作,而p1或p2所依附的节点在另一变更可选项中被删除,则为这2个变更可选项之间建立互斥约束,例如图5中的Option1⊗Option2;
3) 在所有的初始变更可选项中,若当变更可选项O1中的变更操作出现时,变更可选项O2中的变更操作也会同时出现,则添加O1蕴含O2约束,例如图5中的Option1→Option3.将创建的基础过程图、可定制点、变更可选项以及约束关系组合起来即可得到最终的可定制过程图,例如图6给出了由示例模型中的过程片段簇{F5,F10,F14}创建的可定制过程图,其中包含了1个基础过程、5个可定制点、3个变更可选项以及2条互斥约束关系.

Fig. 6 Customizable process graph built from process fragment cluster {F5,F10,F14}图6 由过程片段簇{F5,F10,F14}创建的可定制过程图
3 评估与讨论
3.1 实验评估设置
本节重点评估并讨论本文方法构建出的可定制参考模型的复杂度和领域代表性以及本文方法的性能.我们选取来自贵宾公司的4组描述不同业务的过程变体作为评估的模型来源,这些模型是我们在与贵宾公司的前期合作中梳理并创建的,描述的业务包括预订接入控制、服务预订、现场服务以及财务结算,更多的模型详细信息如表2所示.
为了评估参考模型的复杂度,我们从模型规模以及配置选项数量2个角度,将使用本文方法构建出的可定制参考模型与现有方法进行对比,涵盖了过程模型合并以及过程变体挖掘等2类典型方法,具体地,评估中考虑的参考模型构建方法包括4种:
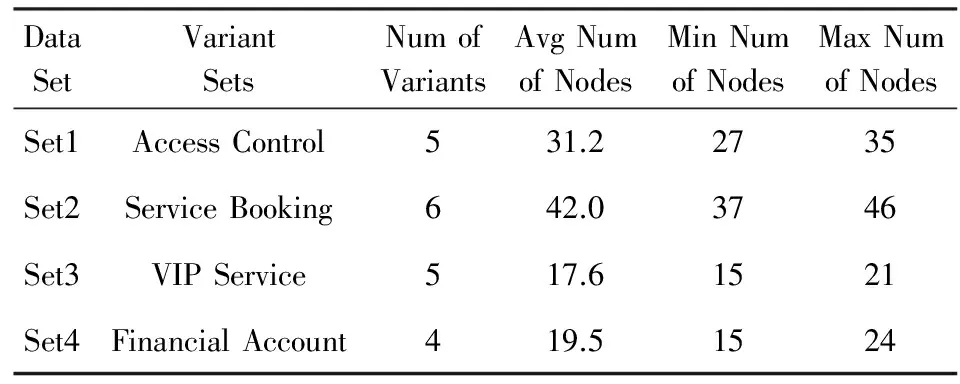
Table 2 Sets of Process Variants for Evaluation
1) 层次化的可定制过程模型(方法1).由本文方法构建出的可定制参考模型.
2) 非层次化的可定制过程模型(方法2).去除相似过程片段聚合与子过程逐层构建的迭代步骤,仅使用2.2节方法基于顶层过程变体集合构建出的单层的可定制参考模型.
3) 可配置过程模型(方法3).利用文献[10]中过程模型合并技术构建出的可配置参考模型.
本文所有实验程序使用Java实现,软件环境为Windows7 SP1,JDK 1.7,硬件环境为Inter Core i5-4590处理器,8 GB内存.
3.2 评估结果
分别使用上述4种方法针对选取的4组过程变体构建相应的参考模型,并统计了参考模型的规模(包含的节点总数或每层过程图包含节点的平均数量)和配置选项(可定制过程模型的变更可选项或可配置过程模型的可配置节点)的数量.各方法构建出的参考模型包含节点的总数量对比情况如图7所示.可以看出:方法3因为将配置选项以可配置节点的形式集成在单个过程图,因此它构建出的参考模型在4种对比方法中规模最大,影响了参考模型的可读性.方法1由于子过程结构的引入,增加了相应的子过程活动和子过程中的开始和结束节点,因此相比方法2和方法4的节点总数量较大,但分层的子过程结构能够提高复杂模型的可读性.

Fig. 7 Total number of nodes in reference models图7 参考模型节点总数量对比
方法1构建的参考模型中每层过程图包含的节点数量的统计信息如表3所示.可以看出,该方法构建出的参考模型每层过程图的规模较小,模型节点在各层过程图中分布相对平均,因此参考模型具有较好的层次化结构.
方法4构建出的参考模型与方法2构建出的参考模型的基础过程相似,但它不具有配置选项,只能表达单一的推荐流程实践,因此在参考模型的领域代表性方面不如方法1~3构建出的模型.方法1~3构建的参考模型的配置选项数量如图8所示.可以看出:方法2构建出的参考模型相比方法1和方法3具有较少的配置选项,即变更可选项,但由于此类模型不具有层次化子过程结构,基础过程的规模较大,并且变更操作集中在少量的变更可选项中,不利于未来参考模型的维护和演化.方法1将变更操作和变更可选项分散至各层过程图中,虽然变更可选项的总数量较多,但变更可选项包含变更操作的平均数量相比方法2明显降低,如表4所示.
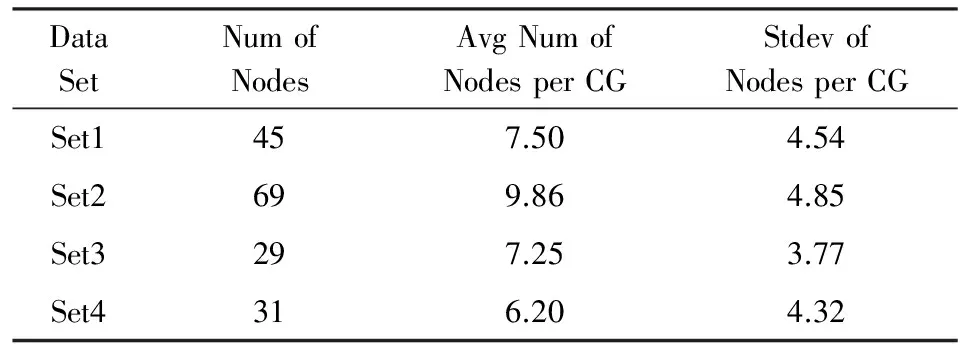
Table 3 Number of Nodes in Reference Models by Method 1
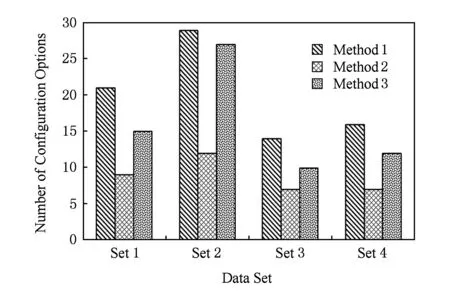
Fig. 8 Number of configuration options in reference models图8 参考模型的配置选项数量对比

DataSetMethod1Method2AvgNumofOptionsperCGAvgOperationsperOptionAvgOperationsperOptionSet13.51.714.67Set24.141.935.08Set33.51.644.29Set43.21.694.71
上述4种参考模型构建方法的性能对比情况如图9所示.可以看出,方法1和方法2的时间开销明显高于方法3和方法4,这是因为本文方法相比现有方法增加了层次化子过程的构建,变更可选项及其约束的生成等步骤,在性能上相比现有方法存在一定的劣势.尽管如此,本文方法能够在可接受的较短时间内构建层次化可定制参考模型,能够应用到参考模型辅助建模的实际工业场景中.
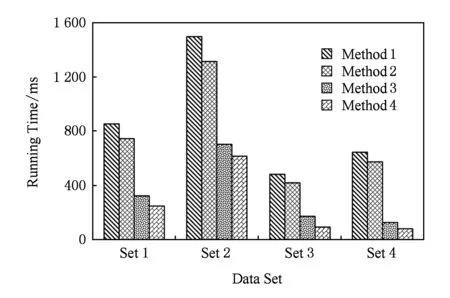
Fig. 9 Time efficiency of building reference models图9 各方法构建参考模型运行时间对比
3.3 讨 论
通过分析构建出的参考模型我们发现本文方法尚存在一定的局限性:
1) 本文构建的参考模型中的变更可选项不包含相应的条件说明,即指导用户应该在何种需求条件下选取该变更可选项,并且构建的约束关系存在于同层次过程的变更可选项之间,因此构建得到的初步模型仍需要领域专家进行调整或补足工作;
2) 在每次迭代选择需要抽象为子过程活动的过程片段簇时,本文使用的策略是优先选择过程片段平均规模更大的簇,这在一些特殊情况下可能导致参考模型的层次过多反而影响了模型的可读性,在未来需要考虑如何优化选择策略以权衡参考模型的层次数量和每层过程图的规模;
3) 目前抽取出的子过程活动采用数字ID的形式命名,未添加具体语义信息,可以研究针对过程片段的自动命名技术对构建的参考模型做进一步的改进;最后,本文方法在变更可选项的构建步骤中时间开销较大,在未来需要对可定制点和变更可选项构建算法的性能作进一步改进.
4 相关工作
本文研究的参考模型的自动构建技术与过程模型合并[10-11]以及过程变体挖掘技术[12-14]密切相关.Rosa等人[10]提出了一种满足行为保留、追踪性和可逆性3项需求的过程模型合并方法,能够在输出的可配置过程模型[2]中表达所有输入模型的行为,并且输出模型也能够派生出所有输入的过程变体.Gottschalk等人[11]提出了一种将2个EPC模型合并的方法,将输入模型转换为一种描述EPC活跃行为(active behavior)的中间形式实现模型的合并.上述方法简单地将多个输入模型到1个输出模型中,虽然能够表达领域内流程的变化性,但输出模型不支持层次化的子过程结构,复杂度会随着输入模型的增多而迅速上升,从而影响模型的可读性.
Li等人[12]以及Ardalani等人[13]提出了过程变体挖掘技术从给定的过程变体集合中发现最佳的参考模型.这些方法基于最短平均距离的机制重新创建参考模型或者改进现有的参考模型.不同于上述以过程变体集合作为输入的方法,Buijs等人[14]提出一种基于事件日志挖掘的参考模型改进方法提高参考模型包含的行为的质量.上述方法以构建“更接近”现有过程变体或事件日志的参考模型为目标,无需满足行为保留和可逆性等需求,因此输出模型的复杂度优于过程模型合并的方法,但是它们的输出模型仅支持传统建模语言描述,不支持配置定制机制描述参考模型的可变性,并且同样不支持层次化的子过程结构.
本文涉及的相似过程片段聚合的工作与过程匹配[19,22]、模型克隆检测[23-25]以及子图发现[26-27]等技术密切相关.本文的前期工作[19]以及Branco等人[22]重点考虑了过程片段的匹配问题.与本文采用的片段相似度算法不同的是,它们考虑了其他更多表征片段相似性的因素,例如过程片段中节点匹配关系的覆盖率、过程片段的上下文相似度等,但这些方法仅仅研究过程片段之间的两两匹配关系的建立而不是聚合相似的过程片段.在模型克隆检测方面,Dumas等人[23]提出一种名为RPSDAG的索引结构快速检测过程模型集合中的精确克隆,而Ekanayake等人[24]的方法能够支持过程模型库中近似克隆的检测,并利用该方法从事件日志中挖掘出一组具有子过程活动的相似过程模型变体[25],从而降低过程模型集合的冗余程度.此外,频繁子图挖掘[26]和子图同构[27]等技术与本文工作具有一定关联,但是它们的研究目标是发现图集合中多次出现的任意联通的子图而不是过程片段,因此不能满足本文层次化子过程抽取的需求.
5 结束语
为了创建领域代表性和可读性更强的参考模型,本文基于相似过程片段聚合技术,提出了一种支持层次化子过程结构的可定制参考过程模型的自动构建方法,并且案例评估表明该方法生成的参考模型具有良好的领域代表性和模型复杂度.未来的工作中,我们考虑引入更多新出现的相似性度量技术提高过程片段聚合准确性,并尝试扩展本文的方法以支持过程模型的数据和资源视角.此外,我们考虑将把本文方法应用于来自工业界更大规模的过程模型集合并通过用户实验等其他方式来进一步验证其有效性和效率.
[1]Dijkman R M, Rosa M, Reijers H A. Managing large collections of business process models: Current techniques and challenges[J]. Computers in Industry, 2012, 63(2): 91-97
[2]Rosemann M, Aalst W. A configurable reference modelling language[J]. Information Systems, 2007, 32(1): 1-23
[3]Rosa M, Dumas M, Hofstede A H M, et al. Configurable multi-perspective business process models[J]. Information Systems, 2011, 36(2): 313-340
[4]Huang Yiwang, He Keqing, Feng Zaiwen, et al. A colored C-net model based on RGPS and its application[J]. Journal of Computer Research and Development, 2014, 51(9): 2030-2045 (in Chinese)(黄贻望, 何克清, 冯在文, 等. 一种基于RGPS着色的C-net模型及其应用[J]. 计算机研究与发展, 2014, 51(9): 2030-2045)
[5]Murguzur A, Carlos X, Trujillo S, et al. Context-aware staged configuration of process variants@Runtime[G]LNCS 8484: Proc of the 26th Int Conf on Advanced Information Systems Engineering. Basel, Switzerland: Springer International Publishing, 2014: 241-255
[6]Döhring M, Reijers H A, Smirnov S. Configuration vs. adaptation for business process variant maintenance: An empirical study[J]. Information Systems, 2014, 39(1): 108-133
[7]Hallerbach A, Bauer T, Reichert M. Capturing variability in business process models: The Provop approach[J]. Journal of Software Maintenance and Evolution: Research and Practice, 2010, 22(67): 519-546
[8]Reinhartz I, Soffer P, Sturm A. Extending the adaptability of reference models[J]. IEEE Trans on Systems, Man and Cybernetics, Part A: Systems and Humans, 2010, 40(5): 1045-1056
[9]Kumar A, Yao W. Design and management of flexible process variants using templates and rules[J]. Computers in Industry, 2012, 63(2): 112-130
[10]Rosa M, Dumas M, Uba R. Business process model merging: An approach to business process consolidation[J]. ACM Trans on Software Engineering & Methodology, 2013, 22(2): Article No.11
[11]Gottschalk F, Aalst W, Jansen M H. Merging event-driven process chains[G]LNCS 5331: Proc of the 16th Int Conf on Cooperative Information Systems. Berlin: Springer, 2008: 418-426
[12]Li C, Reichert M, Wombacher A. Mining business process variants: Challenges, scenarios, algorithms[J]. Data & Knowledge Engineering, 2011, 70(5): 409-434
[13]Ardalani P, Houy C, Fettke P, et al. Towards a minimal cost of change approach for inductive reference model development [C]Proc of the 21st Euro Conf on Information Systems. Atlanta: AIS, 2013: No.127
[14]Buijs M, Rosa M, Reijers H A, et al. Improving business process models using observed behavior[G]LNBIP 162: Proc of the 2nd Int Symp on Process Discovery and Analysis. Berlin: Springer, 2013: 44-59
[15]Vanhatalo J, Volzer H, Leymann F. Faster and more focused control-flow analysis for business process models through SESE decomposition[G]LNCS 4749: Proc of the 5th Int Conf on Service-Oriented Computing. Berlin: Springer, 2007: 43-55
[16]Johnson R, Pearson D, Pingali K. The program structure tree: Computing control regions in linear time [C]Proc of the ACM SIGPLAN Conf on Programming Language Design and Implementation. New York: ACM, 1994: 171-185
[17]Qian L. Managing business process variability: Business brocess configuration vs. business process customization [D]. Eindhoven, Netherlands: Eindhoven University of Technology, 2013
[18]Dijkman R, Dumas M, Dongen B V, et al. Similarity of business process models: Metrics and evaluation[J]. Information Systems, 2011, 36(2): 498-516
[19]Ling Jimin, Zhang Li. Matching process model variants based on process structure tree[J]. Journal of Software, 2015, 26(3): 460-474 (in Chinese)(凌济民, 张莉. 基于过程结构树的过程模型变体匹配技术[J]. 软件学报, 2015, 26(3): 460-474)
[20]Yan Z, Dijkman R, Grefen P. Fast business process similarity search[J]. Distributed and Parallel Databases, 2012, 30(2): 105-144
[21]Aalst W. Process Mining: Discovery, Conformance and Enhancement of Business Processes[M]. Berlin: Springer, 2011
[22]Branco M, Troya J, Czarnecki K, et al. Matching business process workflows across abstraction levels[G]LNCS 7590: Proc of the 15th Int Conf on Model Driven Engineering Languages and Systems. Berlin: Springer, 2012: 626-641
[23]Dumas M, García-Bauelos L, Rosa M, et al. Fast detection of exact clones in business process model repositories[J]. Information Systems, 2013, 38(4): 619-633
[24]Ekanayake C, Dumas M, García-Bauelos L, et al. Approximate clone detection in repositories of business process models[G]LNCS 7481: Proc of the 10th Int Conf on Business Process Management. Berlin: Springer, 2012: 302-318
[25]Ekanayake C, Dumas M, García-Bauelos L, et al. Slice, mine and dice: Complexity-aware automated discovery of business process models[G]LNCS 8094: Proc of the 11th Int Conf on Business Process Management. Berlin: Springer, 2013: 49-64
[26]Jiang C, Coenen F, Zito M. A survey of frequent subgraph mining algorithms[J]. The Knowledge Engineering Review, 2013, 28(1): 75-105
[27]Skouradaki M, Goerlach K, Hahn M, et al. Application of sub-graph isomorphism to extract reoccurring structures from BPMN 2.0 process models [C]Proc of the 9th IEEE Symp on Service-Oriented System Engineering. Piscataway, NJ: IEEE, 2015: 11-20

Ling Jimin, born in 1989. PhD candidate at Beihang University. His main research interests include business process manage-ment, process modeling and analysis, and reference models.

Zhang Li, born in 1968. Professor and PhD supervisor at Beihang University. Senior member of CCF. Her main research interests include software architecture, software product line and business process modeling.
An Approach to Automatically Build Customizable Reference Process Models
Ling Jimin and Zhang Li
(SchoolofComputerScienceandEngineering,BeihangUniversity,Beijing100191)
Process models are becoming more and more widespread in contemporary organizations. It is a complex and high-cost work to develop individual process models for specific business requirements. The modeling procedure can be accelerated and cost-decreased by using reference process models as a basis for individual process models development, so reference process models are widely adopted by organizations. Because building reference process models requires a mass of modeling and analyzing work by domain experts, a major challenge has emerged that how to automatically build a preliminary reference model inductively based on the existing process variants to provide assistance to domain experts. The existing methods of building reference process models have some shortcomings, such as output reference models of most methods have high model complexity and reference models described by traditional process modeling language could not entirely represent various recommended practice in a specific domain. To build reference process models with high representativeness and understandability, this paper proposes an approach to automatically build customizable reference models which support hierarchical sub-process based on fragments clustering. The base model, change options and constraints in customized process models are fully supported to build automatically by our method. The evaluation results show that the generated reference models could achieve fine domain representativeness and model complexity.
process model; process variant; reference model; customizable process model; process fragments
2015-12-09;
2016-04-28
国家自然科学基金项目(61370058) This work was supported by the National Natural Science Foundation of China (61370058).
张莉(lily@buaa.edu.cn)
TP311.5
