基于树干解析的高山松天然林单木木材生物量生长模型
2017-03-31魏安超熊河先闾妍宇欧光龙
魏安超,熊河先,胥 辉,李 超,闾妍宇,张 博,冷 燕,欧光龙
(西南林业大学西南地区生物多样性保育国家林业局重点实验室,云南 昆明 650224)
基于树干解析的高山松天然林单木木材生物量生长模型
魏安超,熊河先,胥 辉,李 超,闾妍宇,张 博,冷 燕,欧光龙
(西南林业大学西南地区生物多样性保育国家林业局重点实验室,云南 昆明 650224)
以云南省香格里拉市两块典型样地内的10株高山松样木为研究对象,基于树干解析测定和计算其单木木材生物量生长及木材生物量生长率,采用非线性混合效应模型技术,分别考虑了样地效应和样木效应,将所有不同随机参数组合的模型进行拟合并分析模型的方差和协方差结构,构建其生物量生长及生物量生长率混合效应模型。结果表明:考虑样地效应、样木效应作为随机效应的单水平混合效应模型和两水平混合效应模型均提高了模型的拟合精度,其中考虑两水平随机效应的混合效应模型具有最佳的拟合表现,具有最低的AIC和BIC值。考虑两水平混合效应在生物量生长量及生物量生长率模型构建中预估精度最高,分别达93.05%和89.83%;考虑样木效应的混合效应模型次之,分别为88.34%和88.74%;考虑样地效应的混合模型预估精度均最低,分别为83.99%和67.27%;而一般回归模型的预估精度仅87.00%和87.11%。
木材生物量生长;生物量生长率;非线性混合效应模型;树干解析;高山松
森林生物量是森林生态系统结构中最基本的特征之一,占全球陆地植被生物量的85%以上,是研究森林生态系统能量和物质循环的基础[1-2]。近年来,关于森林生物量的研究中,树干生物量在森林生物量中占有绝对的主体地位。杜虎等[1]对马尾松、杉木、桉树人工林生物量进行研究时发现,树干木材生物量所占比重最大。然而,森林的生长周期长、长期定位监测比较困难等特点往往造成森林经营管理水平相对比较滞后[3],单木生长模型的构建往往是解决这一问题的有效途径。生长模型是以个体树木的生长信息为基础,模拟林分内不同年龄的树木生长变化过程[4]。
以往建立的生物量与林龄的方程大多假定误差是服从独立同分布的,忽略了个体或群体之间存在的序列相关性及差异性[5]。而混合效应模型方法在一定程度上解决了以上不足,既可以反映总体的平均变化趋势,又可以提供数据方差、协方差等多种信息来反映个体之间的差异[6],被大量应用到林业研究中。陈东升等[7]基于Richards模型构建了不同种间落叶松林树高生长非线性混合模型;肖锐等[8]利用两水平混合模型对杂种落叶松树高和胸径生长进行了拟合;李春明[6]基于Richards变式模型和Logistic模型,利用SAS软件进行了不同区组的杉木林(Cunninghamia lanceolata)优势木平均高生长过程模拟;欧光龙等[9]以幂函数模型为基础,构建了考虑区域效应的更高精度的林分生物量混合效应模型。以上研究都得到了相同结论,混合效应模型较传统回归模型不仅表现出更优的拟合和预估精度,而且能很好地表达数据间误差分布情况。但是目前关于生物量生长模型构建大多为传统理论生长模型,采用非线性混合效应模型的少有报道。与基于空间替代时间的生物量生长测定方法相比,树干解析可以说明单株木材生物量的生长差异,准确反映单木生物量生长的差异,从而使混合效应模型可以有效地应用分析单木木材生物量由样木效应及样地效应引起的生长差异。
高山松(Pinus densata)是云南松与油松的天然杂交种,主要分布于我国青藏高原东南边缘海拔2 800~3 500 m的阳坡地带[10]。本研究选取香格里拉市小中甸和洛吉两块样地作为试验区,以高山松天然林为研究对象,基于树干解析的方法获得树干生物量生长数据,分别考虑单木效应和样地效应,采用非线性混合效应模型的方法建立高山松天然林单木木材生物量生长模型及生物量生长率模型,并对混合效应模型与传统模型拟合结果进行检验比较,为模拟高山松天然林单木木材生物量的动态变化以及生物量的准确估算提供参考依据。
1 研究区概况与研究方法
1.1 研究区概况
香格里拉市位于云南省西北部,地理坐标为99°20′~100°19′E、26°52′~28°52′N。全市地形总趋势西北高、东南低。东与四川省的稻城县、木里县相连,东南和南部与丽江市的玉龙县隔江相望,西与维西县、德钦县以金沙江为界,北与四川省的得荣县、乡城县接壤。香格里拉市东、南、西三面被金沙江环绕,是两省七县的结合部。植被森林覆盖率为89%,其中针叶林占59%、阔叶林占15.6%、灌木林占18%、草地和其他作物占3.7%[11]。本研究选择小中甸镇(Site I)、洛吉乡(Site II)作为研究位点(图1)。
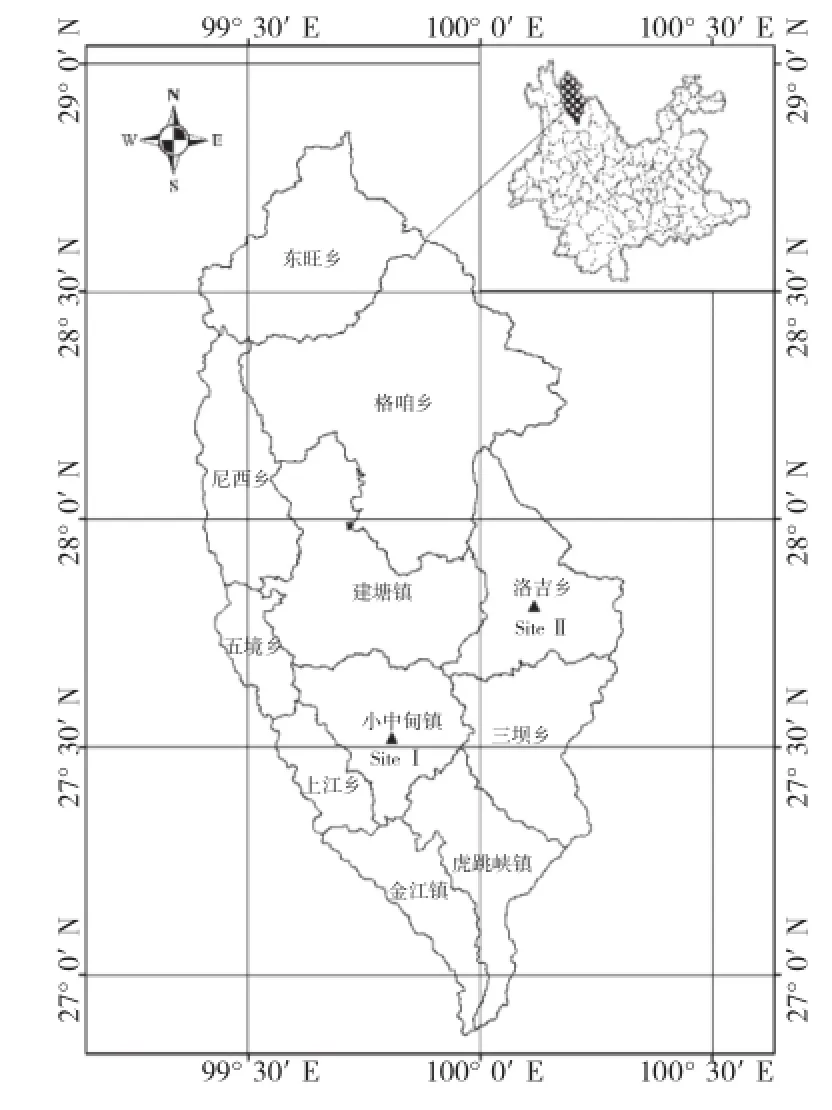
图1 研究区位置示意
1.2 数据调查及整理
分别在香格里拉市小中甸镇和洛吉乡选择一块样地,样地面积为0.09 hm2。在样地内各选择5株树干通直圆满、无明显病虫害、梢头完整的高山松作为样木,编号分别为X1、X2、X3、X4、X5、L1、L2、L3、L4、L5,伐倒前准确测量基部位置、胸径,并在树干上标明南北方向[12]。伐倒后,从0 m处开始以2 m为区分段截取圆盘并记录圆盘基本信息。将圆盘抛光后查数年轮,测量并记录带皮直径、去皮直径。以5年为区分年龄,测量部位圆心距后对圆盘取样并称量鲜重。将样品带回实验室,置于105℃烘箱内烘至恒重,计算含水率,从而得到生物量。生物量生长率采用普雷斯勒式方法计算。
随机选择8株样木数据,其中小中甸和洛吉各4株作为建模数据,剩余2株作为检验样本,样木基本情况见表1。
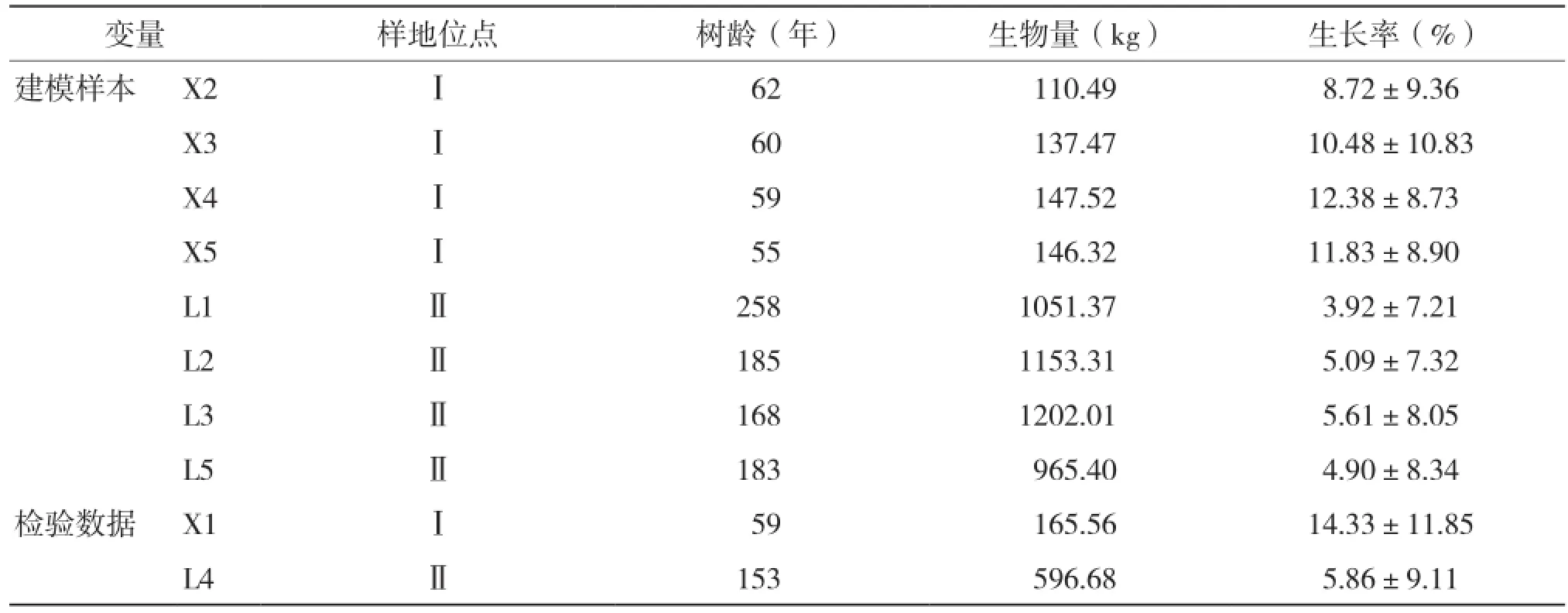
表1 样木基本情况
1.3 数据分析
1.3.1 基本模型选型 (1)生物量生长基本模型选择。本研究采用Logistic变式[6]作为基础模型对生物量生长进行模拟,其模型如下:
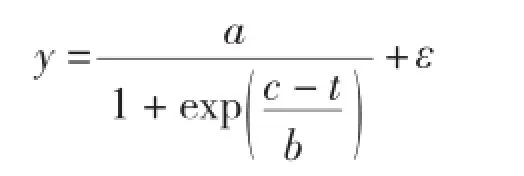
式中,y为单木木材生物量(kg);a、b、c分别为模型中未知参数;t为树龄;ε为误差项。
(2)生物量生长率基本模型选择。本研究所采用的生物量生长率与年龄的关系基本模型[13]为:

式中,y为生物量生长率;a、b为未知参数;t为树龄;ε为误差项。
1.3.2 混合效应模型构建 在构建混合模型之前,需要确定以下3个结构[14]:(1)混合参数选择。在模型中,一般依赖于研究数据确定参数是固定效应还是混合效应。Pinheiro等[15]建议如果模型能收敛,首先应把模型中所有参数看成是混合参数,然后将不同随机参数组合的模型进行拟合,利用AIC、BIC、logLik等统计量指标对模型的拟合优度进行比较,选择模拟精度较高的形式作为最终拟合模型。
首先,我国茶染工艺在普通大众中的认知程度较低。虽然茶及茶文化在我国具有悠久的历史,饮茶和品茶在国人的日常生活中也比较常见,但对于茶染工艺及茶染服饰产品的关注程度就比较低。目前关于茶染工艺的研究大多集中在高校和茶文化爱好者组织,远离普通大众的生活,违背了艺术演变发展的逻辑。
(2)组间方差协方差结构(D)。组间方差协方差结构也被称为随机效应方差协方差结构,反映了组间之间的变化性,也是模型模拟中误差的主要来源。当随机效应参数的参数个数大于1时应考虑组间方差-协方差结构,本文以广义正定矩阵(General Positive-Definite Matrix,Symm)考虑组间方差-协方差结构。以包括两个随机参数的方差协方差结构为例,其结构如下:

(3)组内方差协方差结构(R)。组内方差协方差结构也称为随机误差效应方差协方差结构。为了确定组内的方差协方差结构,必须解决自相关结构和异方差的问题。本研究所使用的生长数据是与时间相关的,存在异方差问题,因此在模拟过程中要考虑样地内的方差协方差结构。常用的描述R矩阵[16]的具体表达式为:
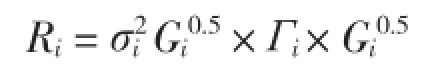
式中,Ri是样地内方差协方差矩阵是未知的样地i的残差方差;Gi为描述样地内误差方差的异质性的对角矩阵,Гi是描述误差效应自相关结构矩阵。
本研究采用的方差结构有幂函数(Power)和指数函数(Exp)两种形式。协方差结构有一阶自回归矩阵〔AR(1)〕、连续一阶自回归矩阵〔CAR(1)〕、复合对称结构〔CompSymm()〕等3种矩阵结构作为模型的协方差结构参与模型拟合。
使用R 3.2.5软件car模块的nls函数和nlme模块的nlme函数,用限制极大似然法(REML)进行建模。
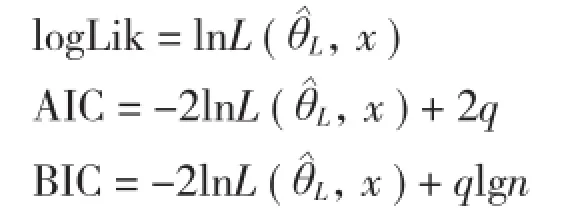
(2)独立性样本检验。模型独立性检验采用建模时为使用的独立样本数据,对所确定模型的预测性能进行综合评价。选取总相对误差(Sumrelative error,SRE)、平均相对误差(Mean relative error,MRE)、绝对平均相对误差(Absolute mean relative error,AMRE)和预估精度(Prediction precision,PP)4个指标进行检验并比较评价模型的预测能力[17]。
2 结果与分析
2.1 单木生物量生长混合效应模型构建
2.1.1 基于单水平生物量生长混合效应模型构建 从表2可以看出,当考虑样木效应时,将a、c参数作为混合参数时表现最优;仅考虑样地效应时,将a参数作为混合参数时表现最优。
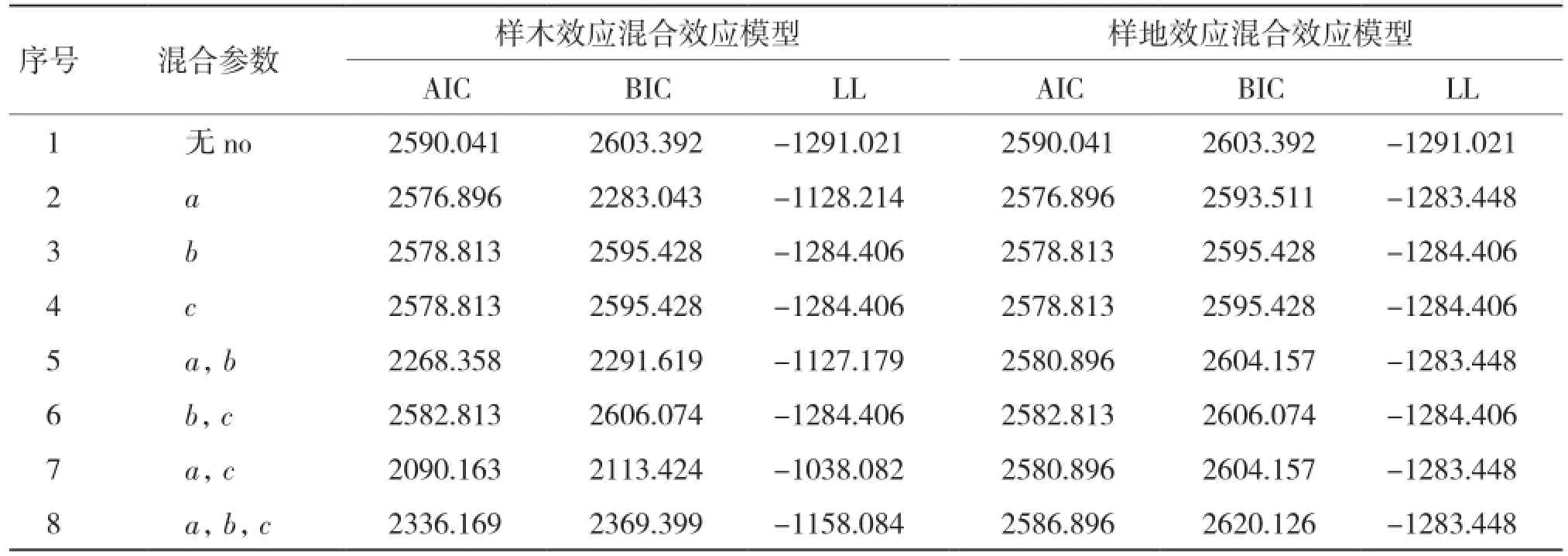
表2 生物量生长单水平混合效应模型参数比较
混合模型在参数效应确定后,还必须确定误差的异质性和相关性。从表3可以看出,在混合效应模型中考虑方差结构时,指数函数和幂函数的方差结构均提高了模型的拟合精度,且考虑指数函数(Exp)的模型拟合精度最高;考虑3种协方差结构时,3种协方差结构均能收敛,且考虑AR(1)结构时模型提高精度最高。同时考虑方差协方差结构时,均不能收敛。
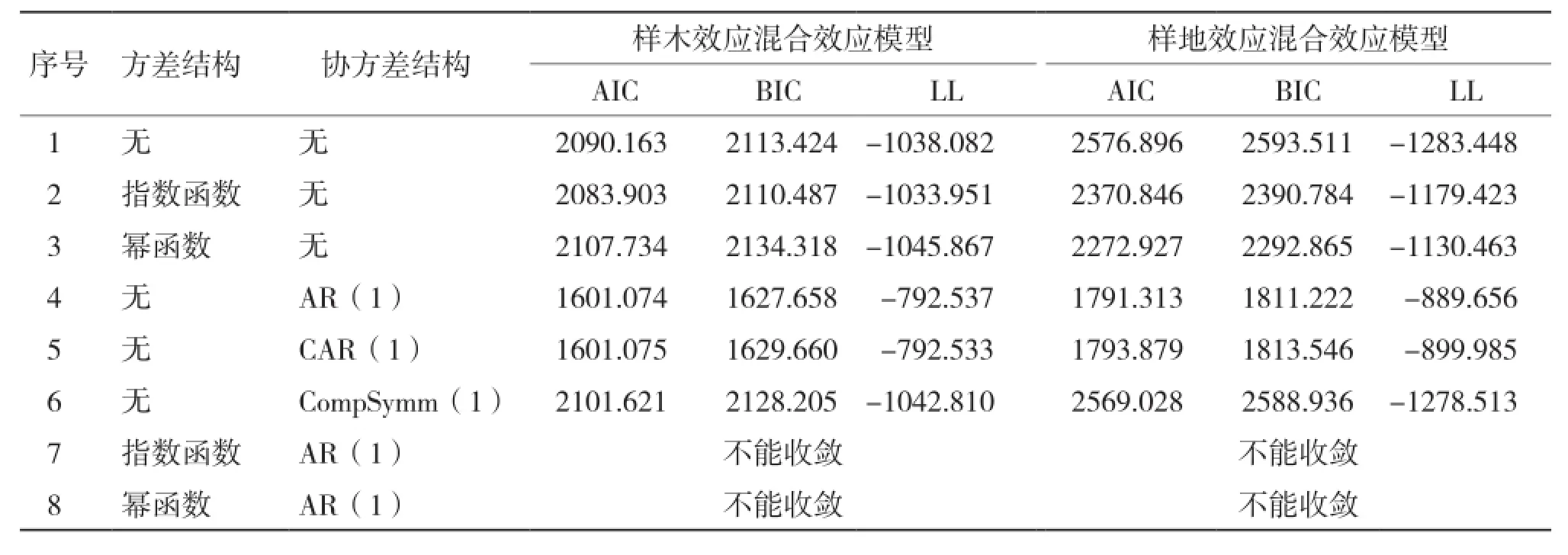
表3 考虑组内方差协方差结构的单水平混合效应模型比较
2.1.2 基于单木和样地二水平生物量生长混合效应模型构建 能收敛的随机效应参数组合有38种,选出7种拟合表现较好的组合列入表4。由表4可知,当样木效应以a为混合参数,且样地效应以b、c为混合参数时(序号2),模型表现最优,故将该模型作为基础混合效应模型。
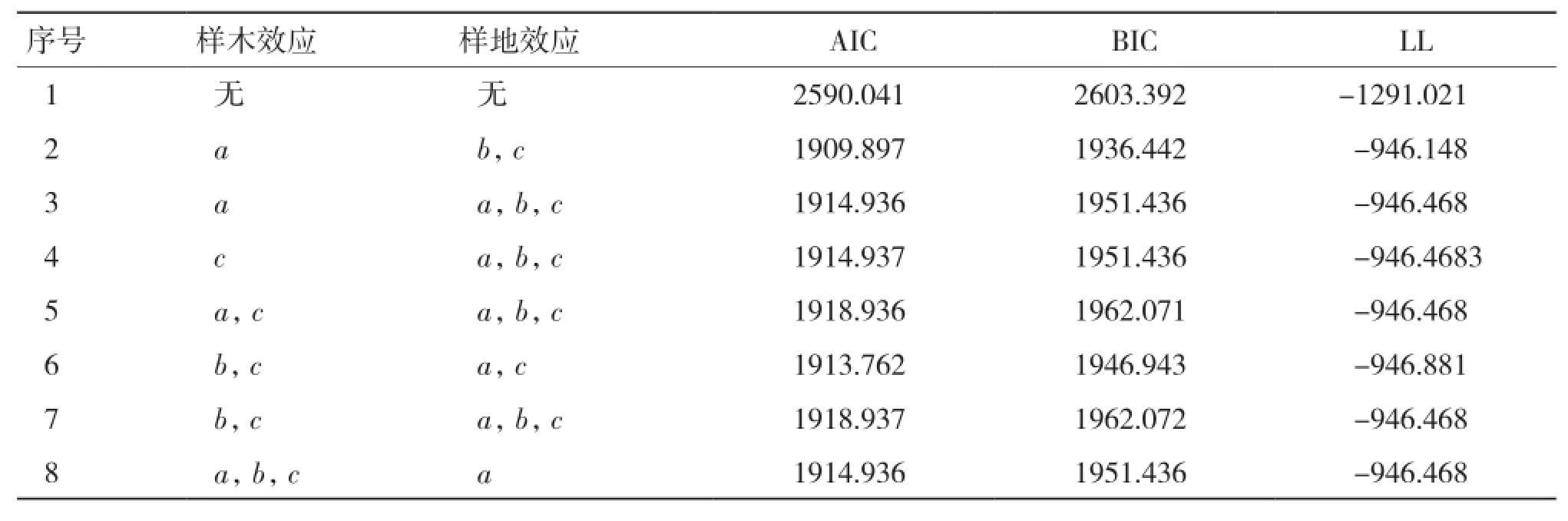
表4 两水平生物量生长模型混合参数比较
从表5可以看出,单独考虑幂函数和指数函数的方差结构模型拟合精度均不及原模型;考虑时间自相关序列的协方差结构均不能收敛;综合考虑组内方差协方差结构时,模型的拟合精度比单独考虑方差、协方差结构的精度要高,其中同时考虑幂函数方差结构(Power)和AR(1)时间自相关协方差结构时模型具有最好的拟合表现(序号7)。
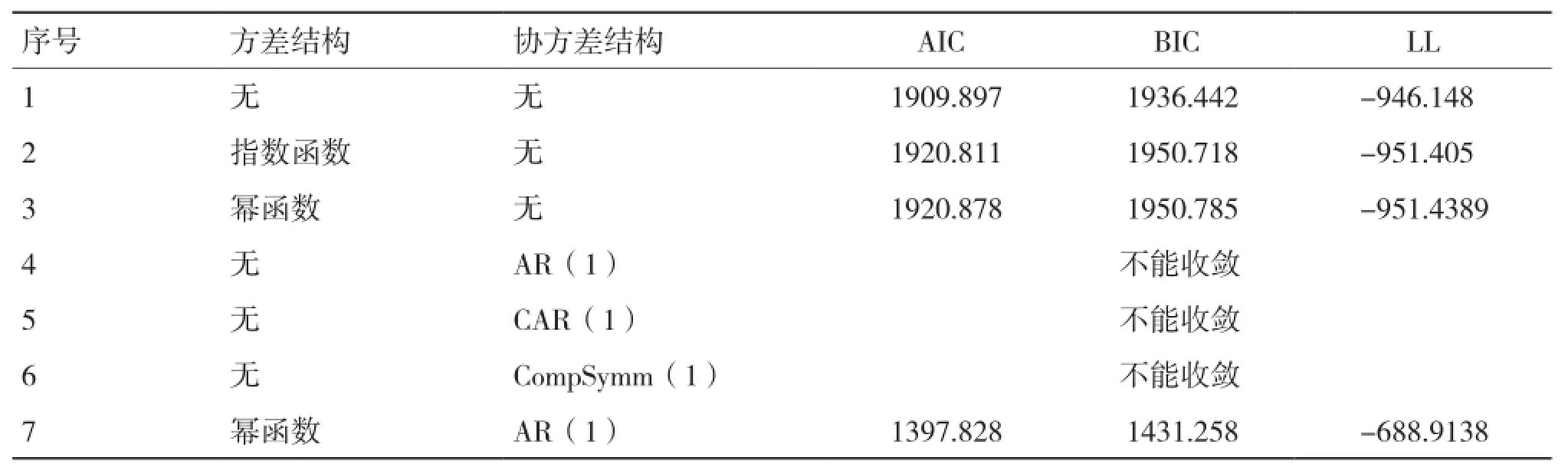
表5 不同两水平生物生长量混合模型比较
2.2 单木生物量生长率混合效应模型构建
2.2.1 基于单水平生物量生长率混合效应模型构建 从表6可以看出,在考虑样木效应时,将a、b参数作为混合参数时表现最优;在考虑样地效应时,将a参数作为混合参数时表现最优。
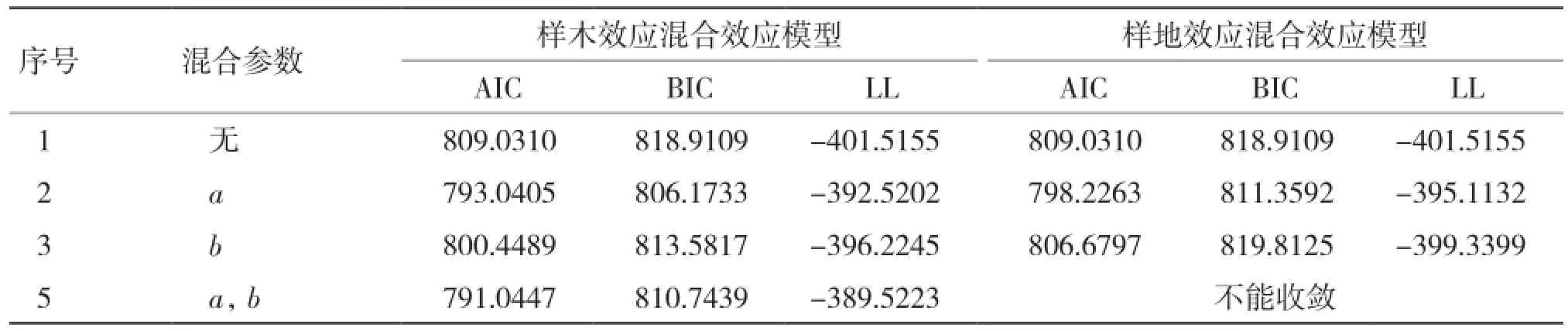
表6 生物量生长率单水平混合效应模型参数比较
由表7可知,在考虑样木效应时,指数函数和幂函数的方差结构均提高了模型的拟合精度,且考虑幂函数(Power)的模型拟合精度最高;考虑3种协方差结构时,考虑AR(1)结构和CAR(1)时模型拟合精度相同且均能提高;综合考虑方差协方差结构时,均不能收敛。在考虑样地效应时,指数函数和幂函数的方差结构均提高了模型的拟合精度,且考虑幂函数(Power)的模型拟合精度最高;考虑3种协方差结构时,3种协方差结构均能收敛,其中考虑AR(1)结构和CAR(1)时模型拟合精度均能提高;综合考虑方差协方差结构时,均能提高模型的拟合精度,其中同时考虑幂函数结构(Power)和CAR(1)模型拟合精度最优。
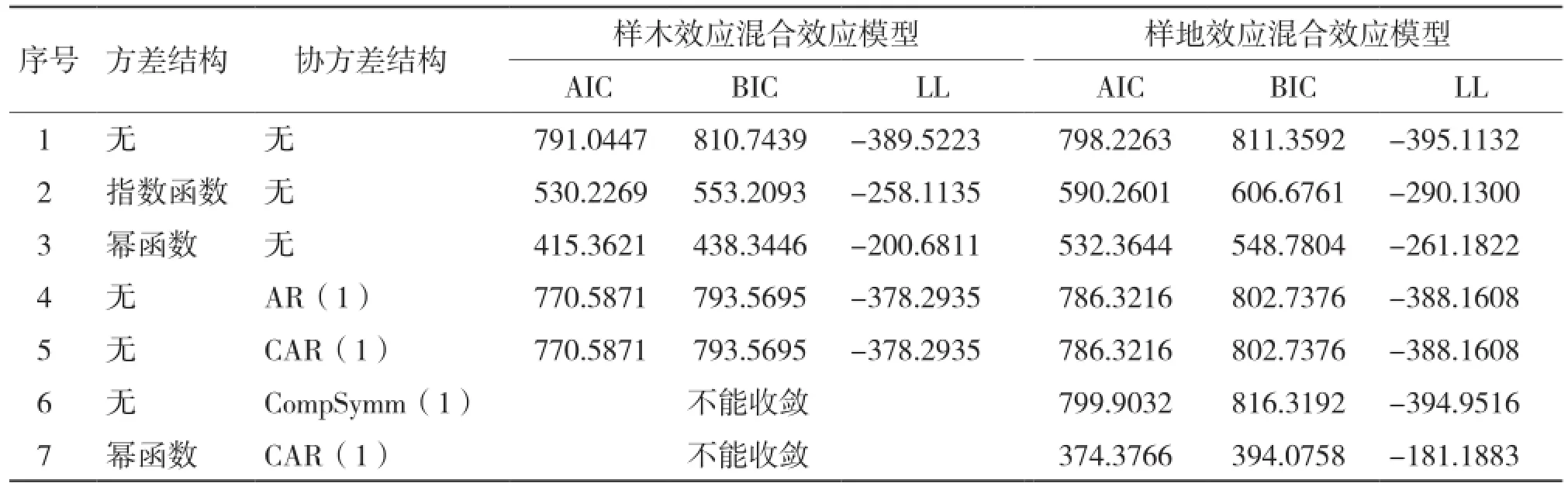
表7 考虑组内方差协方差结构的单水平混合效应模型比较
2.2.2 基于单木和样地二水平生物量生长率混合效应模型构建 由表8可知,当样木效应以a为混合参数,且样地效应以b为混合参数时(序号3),模型表现最优,故将该模型作为基础混合效应模型。
从表9可以看出,单独考虑幂函数和指数函数的方差结构模型拟合精度均优于原模型;单独考虑三种的协方差结构均不能收敛;综合考虑组内方差协方差结构时,以同时考虑幂函数方差结构(Power)和AR(1)时间自相关协方差结构时模型具有最好的拟合表现(序号7)。
2.3 模型评价与检验
2.3.1 模型拟合指标分析 从表10可以看出,混合效应模型的拟合指标均优于一般回归模型。就生物量生长量混合效应模型而言,考虑两水平混合效应模型最好,考虑样木效应混合模型次之,考虑样地效应混合模型最差。就生物量生长率混合效应模型而言,考虑两水平混合效应模型最好,考虑样地效应混合模型次之,考虑样木效应混合模型最差。
2.3.2 模型独立性检验分析 从表11可以看出,混合效应模型中除考虑样地效应的生物量及生物量生长率模型外,其余混合效应模型均较一般回归模型有更高的预估精度,其中考虑两水平混合效应在生物量生长及生物量生长率模型构建中预估精度最高,分别达93.05%和89.83%;考虑样木效应的混合效应模型次之,分别达88.34%和88.74%;而考虑样地效应的混合模型预估精度较低,分别是83.99%和67.27%。就生物量生长模型而言,仅考虑样木效应时总相对误差和平均相对误差最小;考虑两水平效应时,平均相对误差绝对值最小。对于生物量生长率模型,考虑两水平效应时,总相对误差最小;仅考虑样地效应时,平均相对误差最小;一般模型的平均相对误差绝对值最小。
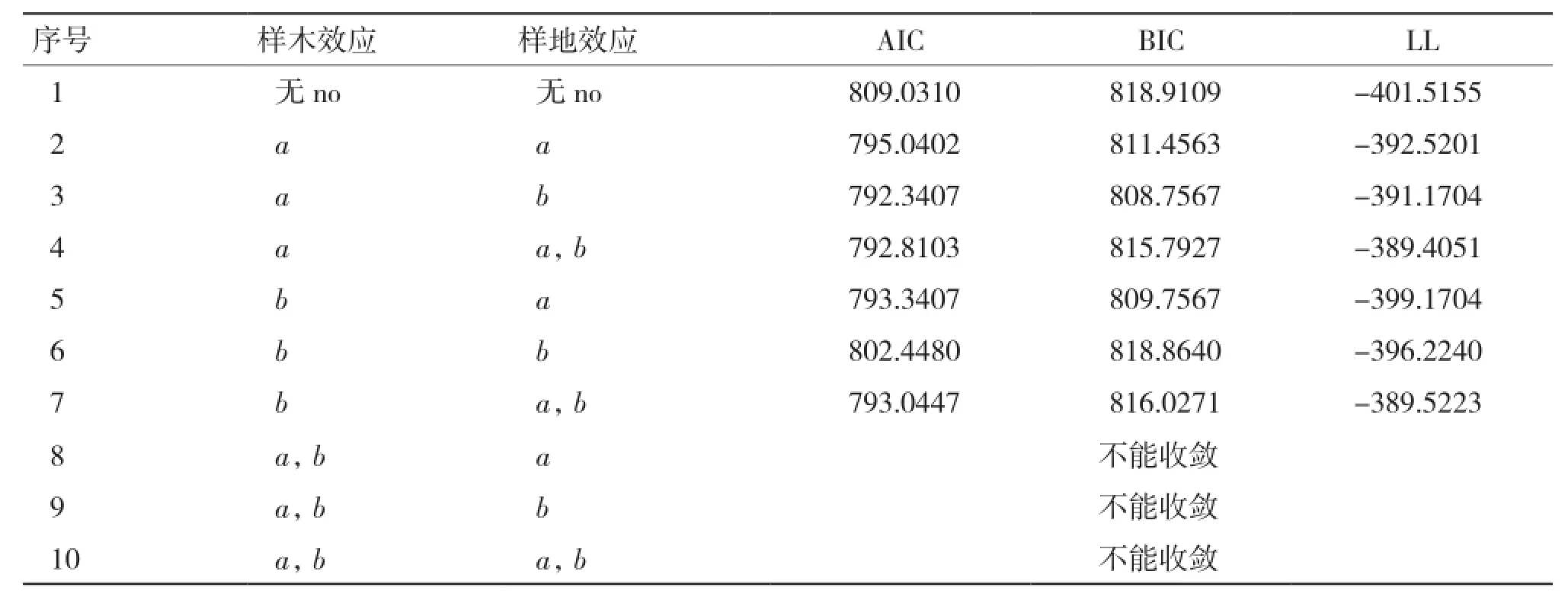
表8 两水平生物量生长率模型混合参数比较

表9 不同两水平生物量生长率混合模型比较
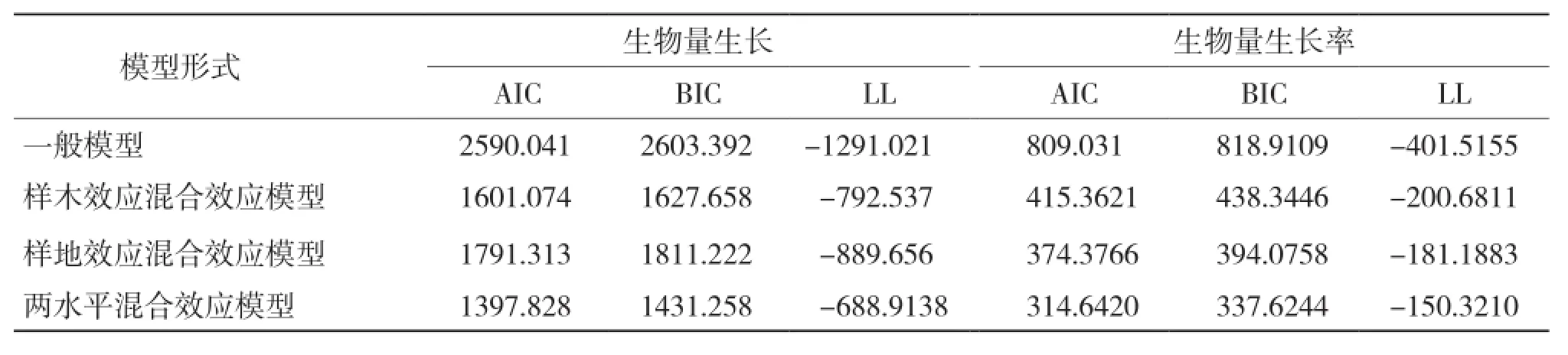
表10 模型拟合指标比较
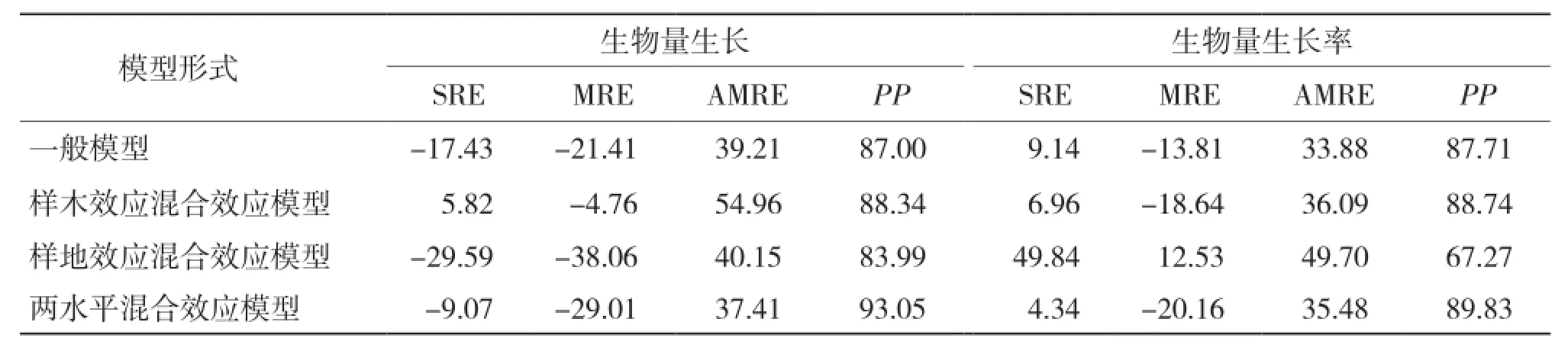
表11 生物量生长模型检验结果比较
2.3.3 模型拟合结果 生物量生长及生物量生长率生长模型的拟合结果分别见表12、表13。

表12 生物量生长混合效应模型拟合结果

表13 生物量生长率混合效应模型拟合结果
3 结论与讨论
本研究采用非线性混合模型的方法,分别建立了高山松单木木材生物量及生物量生长率与年龄关系的模型。考虑了样地效应和样木效应的随机效应,将所有不同随机参数组合的模型进行拟合。当对生物量-树龄关系进行拟合,考虑样木效应时,a、c同时作为混合参数模型拟合最好,由于Logistic方程中a参数表示y的上渐近值,c参数表征内禀生长率,可见,林木木材生物量生长的内禀生长率及理论最大值会随林木个体差异而产生明显差异;而考虑样地效应时,a参数作为混合参数模型拟合最好,即不同立地条件的样地会对树木木材生物量生长的最大值产生较大影响[18]。此外,小中甸镇样地Ⅰ和洛吉乡样地Ⅱ分别为60年的成熟林和200年的过熟林,林分年龄和林木平均大小差异较大,可见林分生长状态也是影响树木木材生物量生长的重要因素;同时考虑样地及样木效应时,样木效应以a为混合参数,样地效应以b、c为混合参数时模型拟合最好。当对生物量生长率-年龄关系进行拟合,考虑样木效应时,a、b同时作为混合参数模型拟合最好;考虑样地效应时,a参数作为混合参数模型拟合最好;同时考虑样地及样木效应时,样木效应以a为混合参数,样地效应以b为混合参数时模型拟合最好。可见,非线性混合效应模型的估计精度比传统的回归模型精度明显提高,但是在单木木材生物量生长及生物量生长率模型中,并非所有参数均作为混合参数的模型具有最优的拟合精度,增加随机效应参数的个数并非会绝对增加混合效应模型的预估精度,其原因可能是由于混合参数个数的增加计算难度也随之增加,因此模型精度反而降低[5]。
从模型拟合结果看,混合效应模型的拟合精度都比一般回归模型的拟合精度高,且两水平的混合效应模型具有最优的拟合表现,这与符利勇等[19]和李耀翔等[20]的结论一致。考虑样木效应比考虑样地效应混合效应模型的拟合精度更高,这与王春红[21]关于红松人工林枝条生长研究得出的结论相符,同时也说明在拟合混合效应模型时,样地之间差异较小,误差主要来源于不同树木之间的差异。从模型的预估精度来看,除考虑样地效应的单木木材生物量及生物量生长率模型外,其余混合效应模型均较一般回归模型有更高的预估精度,其中两水平的生物量生长及生物量生长率混合效应模型的预估精度最高,分别达到93.05%和89.83%;单独考虑样木效应的模型预估精度次之,分别是88.34%和88.74%;单独考虑样地效应的模型预估精度最低,分别是83.99%和67.27%,且低于一般回归模型的87.00%和87.11%。可见,具有较好拟合效果的模型未必会具有更高的预估精度,这与欧光龙[22]对思茅松生物量模型拟合中的结果一致。
本研究采用的广义正定矩阵(General Positive-Definite Matrix)结构考虑组间方差-协方差结构,而在混合效应模型中,组间方差协方差结构还有多种结构,如对角正定矩阵(Diag)、多重身份正定矩阵(Ident)、无结构(UN)、复合对称(CS)等,这些仍需进一步深入研究。
[1] 杜虎,曾馥平,王克林,等. 中国南方3种主要人工林生物量和生产力的动态变化[J]. 生态学报,2014,34(10):2712-2724.
[2] 郭兆迪,胡会峰,李品,等. 1977~2008年中国森林生物量碳汇的时空变化[J]. 中国科学:生命科学,2013(5):421-431.
[3] 刘平,王玉涛,杨帆. 基于单木生长模型的森林动态模拟系统研究进展[J]. 世界林业研究,2011,24(5):25-30.
[4] 邓红兵,郝占庆. 红松单木高生长模型的研究[J]. 生态学杂志,1999(3):19-22.
[5] 李春明,张会儒. 利用非线性混合模型模拟杉木林优势木平均高[J]. 林业科学,2010,46(3):89-95.
[6] 李春明. 混合效应模型在森林生长模型中的应用[J]. 林业科学,2009,45(4):131-138.
[7] 陈东升,孙晓梅,李凤日. 基于混合模型的落叶松树高生长模型[J]. 东北林业大学学报,2013(10):60-64.
[8] 肖锐,陈东升,李凤日,等. 基于两水平混合模型的杂种落叶松胸径和树高生长模拟[J]. 东北林业大学学报,2015(5):33-37.
[9] 欧光龙,胥辉,王俊峰,等. 思茅松天然林林分生物量混合效应模型构建[J]. 北京林业大学学报,2015(3):101-110.
[10] 沈志强,卢杰,华敏,等. 西藏色季拉山高山松种群点格局分析[J]. 西北农林科技大学学报(自然科学版),2016,44(5):73-81.
[11] 岳彩荣,唐瑶,徐天蜀,等. 香格里拉县植被净初级生产力遥感估算[J]. 中南林业科技大学学报,2014(7):90-98.
[12] 孟宪宇. 测树学[M]. 第3版. 北京:中国林业出版社,2006.
[13] 刘炳英,厉保志,王允寿,等. 5树种材积生长率与年龄的关系[J]. 山东林业科技,1991(S1):24-26.
[14] Fang Z,Bailey R L. Nonlinear Mixed Effects Modeling for slash pine dominant height growth following intensive silvicultural treatments[J].Forest Science,2001,47(47):287-300.
[15] Pinheiro J C,Bates D M. Mixed Effects Models in S and S-plus[M]. New York:Springer Verlag,2000.
[16] Davidian M,Gallant A R. The Nonlinear Mixed Effects Model with a Smooth Random Effects Density[J]. Biometric,1993,80:475-488.
[17] 胥辉. 一种生物量模型构建的新方法[J]. 西北农林科技大学学报(自然科学版),2001,29(3):35-40.
[18] 段爱国,张建国,童书振. 6种生长方程在杉木人工林林分直径结构上的应用[J]. 林业科学研究,2003,16(4):423-429.
[19] 符利勇,唐守正,张会儒,等. 基于多水平非线性混合效应蒙古栎林单木断面积模型[J]. 林业科学研究,2015,28(1):23-31.
[20] 李耀翔,姜立春. 基于2层次线性混合模型的落叶松木材密度模拟[J]. 林业科学,2013,49(7):91-98.
[21] 王春红. 基于非线性混合模型的红松人工林枝条生长[J]. 应用生态学报,2013,24(7):1945-1952..
[22] 欧光龙. 气候变化背景下思茅松天然林生物量模型构建[D]. 哈尔滨:东北林业大学,2014.
(责任编辑 张辉玲)
Construction of individual wood biomass growth models for Pinus densata natural forests based on stem analysis
WEI An-chao,XIONG He-xian,XU Hui,LI Chao,LYU Yan-yu,ZHANG Bo,LENG Yan,OU Guang-long
(Key Laboratory of State Forest Administration for Biodiversity Conservation in Southwest China,Southwest Forestry University,Kunming 650224,China)
Taking 10 Pinus densata sampling trees at two plots located in Shangri-La city of Yunnan province as the research object,we measured and calculated single wood biomass growth and wood biomass growth rates based on stem analysis. Considering random effect of the plot effect and tree effect,the biomass growth and growth rate models were constructed by nonlinear mixed effect model technology,and all the different random parameter combinations were fitted and the variance and covariance structures of the models were analyzed. The results showed that,considering random effect of plot effect and tree effect model as the single-level mixed effect model and two-level mixed effect model,the fitting precision of the models was improved,especially two-level mixed effect model had the best fitting performance with the lowest values for AIC and BIC. Both biomass growth and growth rates two-level mixed effect models had the highest prediction accuracy,and the values reached 93.05% and 89.83%;the secondbest ones were the mixed effect model considering the random effect of tree effect,and the prediction accuracies were 88.34% and 88.74%,respectively;the prediction accuracies of models considering the plot effect were 83.99% and 67.27%,respectively;and the prediction accuracies of ordinary models were 87.00% and 87.11%,respectively.
wood biomass growth;biomass growth rate;nonlinear mixed model;stem analysis;Pinus densata
S758.2
A
1004-874X(2017)01-0066-10
2016-10-11
国家林业公益性行业科研专项(2014040309);西南林业大学云南省重点学科(林学)项目;国家自然科学基金(31560209)
魏安超(1991-),男,在读硕士生,E-mail:weianchao@foxmail.com
欧光龙(1983-),男,博士,副教授,E-mail:olg2007621@126.com
魏安超,熊河先,胥辉,等. 基于树干解析的高山松天然林单木木材生物量生长模型[J].广东农业科学,2017,44(1):66-75.
