基于卷积神经网络的位置识别
2017-03-29王丽君于莲芝
王丽君,于莲芝
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于卷积神经网络的位置识别
王丽君,于莲芝
(上海理工大学 光电信息与计算机工程学院,上海 200093)
传统的移动机器人视觉位置识别算法,多是基于手工提取特征且易受环境影响。文中提出了一种基于卷积神经网络算法,根据深度学习框架Caffe优化了卷积神经网络的结构,从卷积神经网络每一层的输出中提取出图像描述符,进行动态环境中的位置识别。实验结果表明,该算法具有较高的鲁棒性与准确性。
视觉位置识别;卷积神经网络;动态环境
正确识别出已遍历过的位置是一个在移动机器人领域和计算机视觉领域均较为重要且具有挑战性的问题[1-5]。在移动机器人长距离导航中,由于天气情况的变化、季节变化、光照变化等的影响,同一个位置从外观上看起来可能会有较大的差异性。大多数位置识别系统都是根据在每一位置拍摄图片间的相似性做出判断,因此类似的外观变化会对系统的鲁棒性产生较大的不利影响。
目前关于动态环境中的位置识别算法大体可分为两个类别:(1)试图找到关于位置的具有条件不变性的描述符,例如具有尺度、旋转、和光照不变性的局部特征描述符;(2)通过训练学习来预测环境外观的变化[6-7]。其中最具代表性的为FAB-MAP[8]和SeqSLAM[9]。
最近一些研究机构已经证明了在目标分类或检测过程中,CNN的效果优于采用手动提取的特征的一些经典算法[10-11]。受到这些研究的启发,本文提出了一种基于CNN的位置识别算法,并与一些经典算法进行了比对。
1 实验模型
本研究采用了一个开源的深度学习框架Caffe[12]来提取基于CNN的图像特征。该模型是由一个场景为中心的,包含205个场景类别,250万幅图像的名为Places的数据集上训练得到的。将这个预先训练好的模型作为一个高效的全局图像描述符发生器,提取出基于CNN的全局图像描述符。重新构建后的CNN结构如图1所示。
该卷积神经网络模型主要由3种类型的层组成,其中包括5层卷积层(CONV1-CONV5),3层最大池化层和2层全连接层(FC6、FC7)。从输入图片上随机选取一个227×227的patch作为模型输入样本。第一个卷积层包括96个11×11的滤波器,卷积步长为4,激活函数的输出为96个55×55的特征图。CONV1、CONV2和CONV5之后分别连接着一个最大池化层,池化层的Kernel大小都是2,池化歩长为2。最大池化层对提取出来的图像特征进行了降维并且赋予相应的特征转换不变性[13]。同时,这也是一个通过融合低层局部信息来建立抽象表达的过程。这种抽象化在一个近邻窗口的局部进行。CONV3和CONV4之后没有连接池化层,卷积结果经过激活函数后直接作为下一个卷积层的输入。最后一个卷积层包含256个13×13的滤波器,每个滤波器与所有的输入MAP相连,卷积步长为1。接下来是两个全连接层,位于全连接层前面层的所有神经元与当前层的每一个神经元都是连接的。

图1 CNN模型
根据上述模型提取出CNN的各层特征后,接着对其进行标准化,公式为
(1)

2 实验及分析
本实验采用澳大利亚昆士兰科技大学机器人实验室用于视觉位置识别的公开数据集,具体描述如表1所示。

表1 数据集描述
第一组实验分别在数据集Nordland和St Lucia上将本文提出的基于CNN的算法和经典BRIEF-GIST[14]、WI-SURF[15]、FAB-MAP、SeqSLAM做了对比。实验结果如图2和图3所示。为了图像的直观清晰,图中只画出了本次实验中在CNN的7层输出中表现最好的一层,即CONV3作为代表层与其他算法的比对结果。后续实验中基于卷积神经网络各层输出特征的算法同样只采用在对应实验中效果最好的一层与其他经典算法对比。
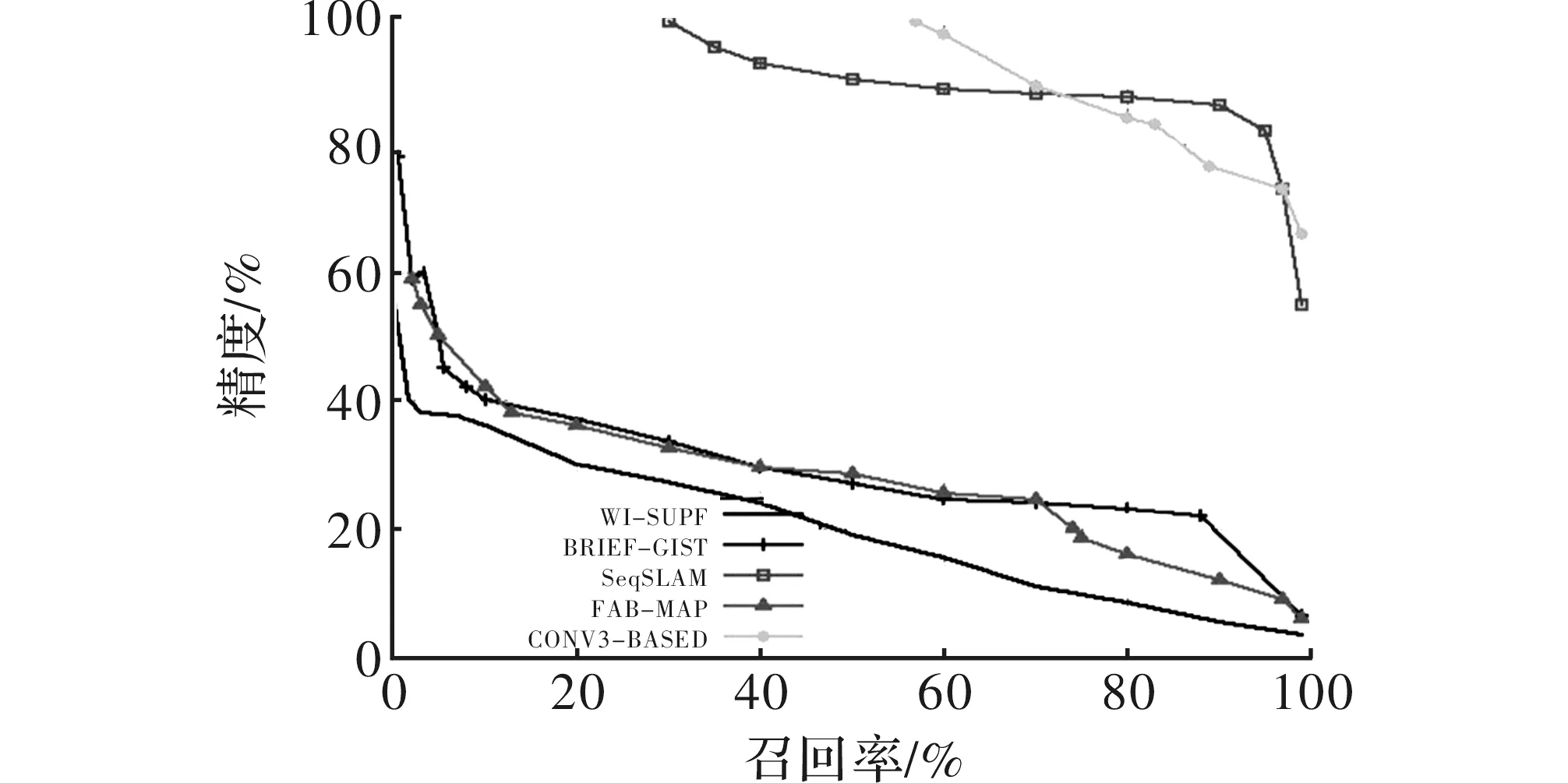
图2 不同算法在Nordland数据集上对比结果
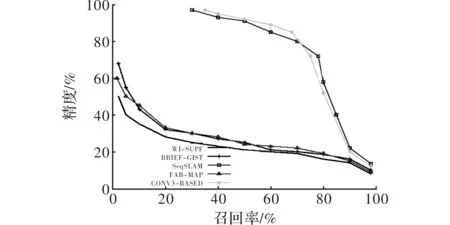
图3 不同算法在St Lucia 数据集上对比结果
如图2所示,采用基于CONV3特征的算法在精度和召回率方面都明显优于BRIEF-GIST、WI-SURF和FAB-MAP这些经典算法,而且,当精度高达98%时,CONV3的召回率接近57%,而SeqSLAM的召回率仅有30%。如图3所示,CONV3-BASED算法取得了与SeqSLAM相匹敌的效果,并明显优于其他3种对比算法。
第二组实验在两个包含视角变化的数据集Gardens Point和Pittsburgh上将基于CNN的算法和经典的对视角变化有较强鲁棒性的FAB-MAP算法进行了比对。实验结果如图4和图5所示。

图4 Gardens Point 数据集上对比实验结果
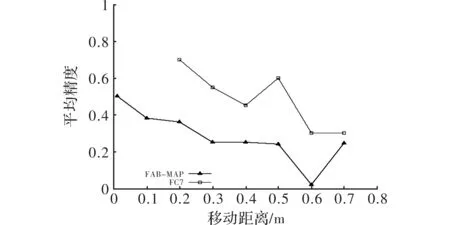
图5 Pittsburgh数据集上对比实验结果
如图4所示,在Gardens Point数据集上,当精度为96%时,FAB-MAP算法的召回率仅有14.7%,而基于FC7的算法的召回率为33%,效果优于FAB-MAP。如图5所示,在Pittsburgh数据集上,当摄像机镜头发生横向移动时,在横向移动距离相同的条件下,FC7算法的平均精度比FAB-MAP算法高约30%。
3 结束语
本文在4个公开的数据集上进行基于视觉的位置识别测试,实验结果表明,基于CONV3的算法对由于季节或光照变化引起的场景外观改变具有较好的鲁棒性,而在视角变化时,FC7的效果最好。这是随着卷积神经网络层数的递进,输入图像的表达会越抽象,就像传统的全局图像描述符对外观变化的鲁棒性较好,而局部图像描述符对视角变化的鲁棒性较好。今后,将继续深入研究如何将CNN与精度更高的图像相似性匹配算法相结合来进一步改善算法的性能。
[1] Sibley G, Mei C, Reid I,et al. Vast-scale outdoor navigation using adaptive relative bundle adjustment[J].Robot,2010,29(8):958-980.
[2] Konolige K, Agrawal M.Frame SLAM: from bundle adjustment to real-time visual mapping[J].IEEE Transactions on Robot,2008,24(5):1066-1077.
[3] Schindler G, Brown M, Szeliski R. City-scale location recognition[C].Roma: IEEE International Conference on Robotics and Automation,2007.
[4] Milford M, Wyeth G, Prasser D. RatSLAM: A hippocampal model for simultaneous localization and mapping[C].Australia: Conference on Robotics and Automation, 2004.
[5] Badino H,Huber D,Kanade T. Real-time topometric localization[C].Saint Paul: IEEE International Conference on Robotics and Automation (ICRA),2012.
[6] Milford M, Wyeth G.Persistent navigation and mapping using a biologically inspired SLAM system[J].The International Journal of Robotics Research,2010,29(5):1131-1153.
[7] Sünderhauf N,Neubert P,Protzel P. Are we there yet? challenging SeqSLAM on a 3000 km journey across all four seasons [C].Germany: IEEE International Conference on Robotics and Automation (ICRA),2013.
[8] Cummins M,Newman P.FAB-MAP: probabilistic localization and mapping in the space of appearance[J].The International Journal of Robotics Research,2008,27(6):647-665.
[9] Milford M,Wyeth G F.SeqSLAM:Visual route-based navigation for sunny summer days and stormy winter nights[C].Saint Paul:IEEE International Conference on Robotics and Automation (ICRA),2012.
[10] Wang Limin,Wang Zhe,Guo Sheng,et al. Better exploiting OS-CNNs for better event recognition in images[C].Santiago: IEEE International Conference on Computer Vision Workshop,2015.
[11] Tian Yonglong,Luo Ping,Wang Xiaogang,et al.Deep learning strong parts for pedestrian detection[C].Santiago:IEEE International Conference on Computer Vision,2015.
[12] Jia Y,Shelhamer E,Donahue J,et al.Caffe:an open source convolutional architecture for fast feature embedding [J]. Eprint Arxiv, 2014(3):675-678.
[13] 许可.卷积神经网络在图像识别上的应用的研究[D].杭州:浙江大学,2012.
[14] Sunderhauf N, Protzel P.BRIEF-gist-closing the loop by simple means[J].Robotics and Autonomous Systems,2011,69(2):1234-1241.
[15] Bay H,Ess A,Tuytelaars T,et al. Speeded-up robust features[J]. Computer Vision and Image Understanding,2008,110(3):346-359.
Visual Place Recognition Based on Convolutional Neural Networks
WANG Lijun,YU Lianzhi
(School of Optical-Electrical and Computer Engineering,University of Shanghai for Science and Technology, Shanghai 200093, China)
Most of the classic methods about visual place recognition for mobile robots are based on hand-crafted features and easily subject to the environment changes. In this paper, we proposed a Convolutional Neural Networks(CNN)based method, finetuned the CNN Architecture according to the Caffe frame and use descriptors obtained from the output of each CNN layer for place recognition in changing environments. The experimental results show the CNN based method perform well with good robustness and accurancy.
visual place recognition; convolutional neural networks; changing environments
2016- 03- 10
王丽君(1989-),女,硕士研究生。研究方向:机器视觉等。于莲芝(1966-),女,副教授,硕士生导师。研究方向:模式识别等。
10.16180/j.cnki.issn1007-7820.2017.01.029
TP391.4
A
1007-7820(2017)01-104-04
