基于潜在特征的汽车评论要素挖掘
2017-03-21王钰刘复星赵帅刘贺
王钰+刘复星+赵帅+刘贺


摘要:互联网的迅速发展带来了网络中评论数据的大量增长,分析这些非结构化的文本数据的潜在价值对于整车企业在生产、营销、售后等环节具有重要的指导意义。汽车垂直网站内的评论数据海量且复杂,本文提出一种基于潜在特征的评论要素挖掘模型,对文本数据进行细粒度的挖掘,识别出文本的评论要素,即评价对象与评价词。在汽车之家评论语料进行的实验表明,本模型的预测准确率达到81%,具有良好的分类效果。
关键词:文本挖掘;评论要素;序列标注;潜在特征
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2016)33-0247-04
Abstract: The rapid development of the Internet has brought a lot of data growth in the network. The potential value of unstructured text data is of great significance to the production, marketing and after-sales. This paper presents a mining model of automobile reviews based on latent feature, which makes text data mining fine, and discerns the commenting essentials of text, namely review object and review word. The results of the experiments show that the prediction accuracy of this model is 81%, with good classification results.
Keywords: text mining, commenting essentials, sequence annotation, latent feature
1引言
隨着互联网和信息行业的发展,数据已经渗透到当今每个行业和业务职能领域,成为重要的生产因素,与此同时,汽车行业作为已有百年历史的传统产业,也在“互联网+”的时代趋势下进行着新一轮的产业革新。本文将对网络采集的汽车评论数据,利用文本挖掘技术进行分析。
当前,各汽车垂直网站中的评论数据多为文本数据,数据量大,结构复杂,并且包涵了众多无效信息。事实上,对于汽车评价数据的不同维度,人们更多关注其中真正有价值的部分,即一段评论的评论要素。现有的汽车评论要素识别方法考虑的特征有限,本文通过将评论要素挖掘建模为序列标注问题,综合考虑多个特征,提出基于潜在特征的挖掘模型识别评论要素。
2相关工作
2.1 评论要素概述
评论要素包括评价对象与评价词,评价对象是每一评论文本中的主题,评价词为评价对象所对应的描述。如在汽车的评论数据中,有:“外观沉稳大气,空间够宽敞,价格刚好在接受范围之内。”
该评论共有三个分句,主题分别为“外观”、“空间”、“价格”,即可作为该评论的三个评价对象,评价对象能够与各自对应的评价词构成<“外观”,“沉稳大气”>、<“空间”,“够宽敞”>、<“价格”,“刚好在接受范围之内”>的<评价对象,评价词>的二元组。本文的目标是提出一种基于潜在特征的模型,挖掘文本评论数据中的评论要素。
2.2 评论要素识别方法
2.2.1 基于规则的评论要素识别方法
在研究初期,评论要素的抽取主要是基于规则的方法,这些规则的制定通常需要借助包括中文分词、词性标注、命名实体识别、依存句法分析、语义角色标注在内的自然语言处理技术。
Hu和Liu[1]标注待分析文本中的名词,通过Apriori算法发现其中词频较高的为评价对象,再确定评价对象临近的形容词为其评价词。
Popescu和Etzioni[2]对算法进行了进一步地优化,通过定义句式结构标识词来计算名词短语与这些标识词间的互信息(PMI),PMI可以表示词间的共现关系,PMI较小则词间共现次数较低,即该名词短语为评价对象的可能性较低,过滤这些非评价对象的名词在一定程度上可以提升算法的准确度。
Blair-Goldensohn等[3]考虑了文本中频繁出现的名词短语,对文本的不同语句标以不同权重,统计这些名词短语的出现频率并对其进行权重排序,仅抽取权重较高的部分作为评价对象。
Scaffidi等[4]通过比较名词短语在待分析文本中出现的频率与在普通语料库出现的频率,识别真正有意义的评价对象。
基于规则的方法本质在于计算频率,虽然较为简单,但可以有效地识别出频繁细粒度评论要素;然而该方法过于依赖规则,具有一定的局限性,并且规则的覆盖范围难以掌握,评论要素的抽取效果在多种情况下难以保证全局最优。
2.2.2 基于机器学习的评论要素识别方法
基于机器学习的方法需要事先标注训练语料,但准确率高且泛化能力强。目前的主流算法包括条件随机场(CRF)和隐马尔可夫模型(Hidden Markov Model,HMM)。序列标注模型通常采用HMM,但HMM中存在两个假设:输出独立性假设和马尔可夫性假设。其中,输出独立性假设要求序列数据严格相互独立,而事实上大多数序列数据不能被表示成一系列独立事件。相较而言,CRF则无需非常严格的独立性假设,能够有效解决标注偏置的问题,而且可以灵活引入多种特征,所有特征进行全局归一化,最终实现更好的抽取效果。
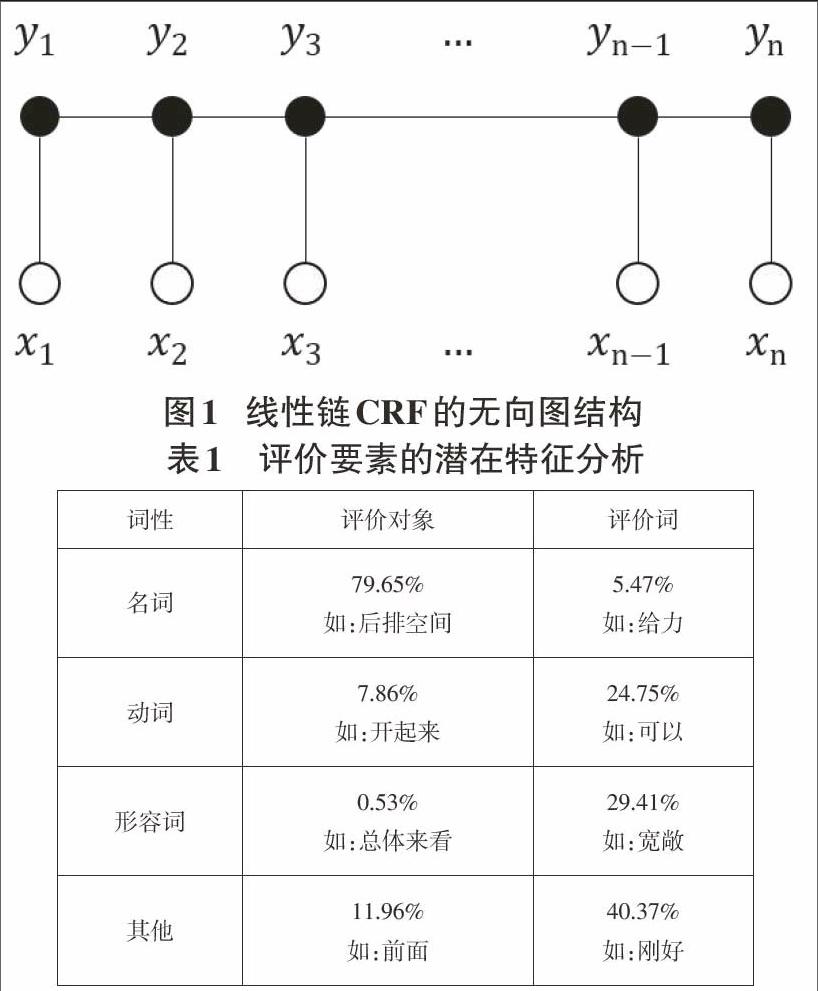
CRF是典型的判别式模型,线性链CRF模型如图1所示:
其中[X=x1,x2,…,xn]表示观察序列,[Y=y1,y2,…,yn]表示状态序列,通过训练模型可以得到状态序列的条件概率。在评价对象预测实例中,文本数据分词得到的[w1,w2,…,wn]作为观察序列输入CRF模型,输出对应的状态序列[l1,l2,…,ln],以B、I、O形式的标签表示。B为预测评论要素的开头部分,I为中间部分,O为其他部分。
Jakob和Gurevych[5]将评价对象抽取问题建模成序列标注问题,引入词性、依存句法、意见句等特征,在不同领域训练CRF模型,以得到更独立的训练结果。
徐冰[6] [7]等先后采用了N-gram、词性、词典特征及词、词性、上下文特征、位置特征、浅层句法特征对COAE2008评价对象抽取任务的语料进行抽取。
王中卿[8]等考虑了词、词性、依存关系等特征,最终在COAE2011评价搭配抽取任务中F值排位第一。
基于机器学习的方法在训练数据充足的情况下可以取得较好的结果,但训练数据所耗费的代价较大。本文设计了潜在特征来训练模型,在保证模型可靠性的原则上降低了训练成本。
3基于潜在特征的评论要素挖掘模型
3.1 评论要素的特征
3.1.1 序列特征
评论要素以序列形式排布在评论数据中,具有序列特征。如在评论文本“大排量好费油”中,包括评价对象“排量”及其評价词“大”与“好费油”。然而由于分词的不同,可分为“大排量/好费油”,“大排量好/费油”,不同的序列切分导致了不同的语义,因此,本文将评论要素的识别建模成一个序列标注问题。
3.1.2 语境特征
评论数据中的上下文形成语境,语境对评论要素的识别有重要影响。一方面,不同语境中相同的词可能在评价对象与评价词的识别中互相转换;另一方面,评价对象与评价词的关联关系对于同时识别评价对象和评价词有重要作用。如“空间大”中评价对象“空间”的语境是“大”,评价词“大”的语境是“空间”,当确定“大”是评价词时,很容易找到相应的评价对象“空间”。本文将利用语境特征同时识别评价对象与评价词。
3.1.3 语义特征
传统的评论要素识别方法通常定义较高频的名词和名词短语作为评价对象,定义其附近的形容词和形容词短语作为评价词[1] [2]。本文统计了汽车之家网站的1000条评价数据,分析得到词性与评价要素间的关系,如表1所示:
结果表明在评价对象中名词占比最高,达79.65%;评价词中动词占比24.75%,部分形容词短语被拆分成形容词与其他词性如副词,联合占比69.78%。由此可见词性一定程度上可以体现评论要素的语义特征,但不能仅依靠词性标注规则大概率地正确识别评论要素,因此本文引入了潜在特征这一概念,模型将利用潜在特征进行学习。除词性外,命名实体、语义角色、句法分析、情感分析等自然语言处理方法也常用来理解文本语义,本文将选取上述所有特征来共同描述评论要素的语义特征。
3.1.4 情感特征
评论数据中包含了用户的情感倾向,如好评词“给力”、“很好”、“不错”等,中评词“一般”、“可以”等,差评词“差”、“不好”等。在文本挖掘早期,研究者通过人工构建评价词词典来进行情感分析。虽然随着电子商务和社交网络的快速发展,新型评价词层出不穷,但早期研究仍为评价词的识别提供了有利的基础。本文将同时在模型和特征中考虑情感特性,抽取情感特征,并在模型中学习词汇的不同情感倾向。
3.2评论要素挖掘的定义
定义:给定一个产品的评论文本集合[D],其中[x=x1,x2,…,xn]为[D]中一个评论文本序列,[m]为文本长度,从所有可能的序列标注中选择最有可能的序列标注[y=y1,y2,…,ym],标注[y]中以TB开头以连续TI结尾的词或短语为评价对象[T],以PB开头以连续PI结尾的词或短语为评价词[P],识别其中[T]个评论表达的对象(评价对象)[T1,…,TT]和[P]个情感表达的词(评价词)[P1,…,PT]作为评论要素。
从解得的标签序列[y]中可以知道该评论文本是否包含评价对象或评价词。本文中以“TB”来代表产品评价对象的开头边界,“TI”来表示产品评价对象的内部,“PB”来代表产品评价词的开头边界,“PI”来表示产品评价词的内部,而其他背景词则标记为“O”,如表2所示:
3.3评论要素挖掘模型的结构
与多数序列标注模型一样,本节假设评论文本具有马尔可夫特性,即当前词只与当前词及前一个词相关。综合考虑评论要素中的序列特征、语境特征、语义特征、情感特征等,构建潜在特征层,提出基于潜在特征的评论要素识别模型,如图1所示:
1) 考虑评论要素的序列特征,将评论要素识别任务构建为序列识别模型,输入序列特征X,通过训练学习H层,并输出序列预测结果Y。
2) 考虑评论要素的语境特征,采用联合学习方式,同时学习和预测评价对象和评价词,构建当前词与前一个词间的语境变化特征函数,如图中[hi]与[xi-1]和[xi]所示。
3) 考虑评论要素的语义特征,抽取词性标注、句法分析、语义角色分析、实体识别等语义特征,通过潜在特征H层学习评论要素中不同类型的语义特征函数,如图中[hi+2]与[xi+2]所示。
4) 考虑评论要素的情感特征,抽取情感特征,并通过潜在状态H层学习评论要素中不同情感倾向的情感特征函数,如图中[hi+2]与[xi+2]所示。
5) 考虑评论要素潜在特征层与标注间的关系,根据评论要素中不同类型特征学习其中的映射关系,如图2中H与Y的关系所示。
本文模型在条件随机场模型的基础上,构建了潜在特征H层,同时考虑了细粒度的多种特征,及不同特征的潜在特征与动态组合特征。在真实数据集上的实验表明,所改进的模型经t检验具有较为显著的提高。
4 实验结果
4.1实验语料
本次实验采集了汽车之家网站的用户评论并加以整理,随机抽取2000条评论数据作为实验语料,进行特征选取及标签(TB、TI、PB、PI、O)标注。
4.2评价维度及评价指标
4.2.1 评价维度
本次实验共设6个评价维度,分别是:
1) 精细的评价对象;
2) 粗糙的评价对象;
3) 精细的评价词;
4) 粗糙的评价词;
5) 精细的评价对象+评价词;
6) 粗糙的评价对象+评价词。
其中“精细”的定义为标注结果与预测结果完全相同视为预测正确;“粗糙”定义为评价对象(评价词)不区分开头边界与内部,即标注结果与预测结果属同一类则视为预测正确。
4.2.2 评价指标
[tp]:预测出需求的评价维度并预测正确的数量;
[fp]:预测出需求的评价维度但预测错误的数量;
[tn]:没有预测出需求的评价维度但预测正确的数量;
[fn]:没有预测出需求的评价维度且预测错误的数量;
实际实验中对数据进行了五折交叉验证,即将标注数据五等分,以其中四份作为训练集,一份作为测试集进行交叉计算,平均五个[P],[R],[F1]值得到模型最終的[P],[R],[F1]值。这样的结果可以更为客观全面地检测模型的性能指标。
4.3 考虑不同特征对模型结果的影响
实验使用了基于三种不同特征的模型对评论预料进行要素挖掘,分别是本文提出的基于潜在特征方法的评论要素挖掘模型(记作WOMM_combine)、基于语义特征的评论要素挖掘模型(记作WOMM_baseline)、基于词语特征的评论要素挖掘模型(记作WOMM_word),模型结果分别如下表所示:
通过上表可见,在基于精细的评价对象、粗糙的评价对象、精细的评价词、粗糙的评价词、精细的评价对象+评价词、粗糙的评价对象+评级词六个评价维度的实验中,WOMM_word模型平均[F1]值为75%,WOMM_baseline模型平均[F1]值为79%,本文所提出的WOMM_combine模型的平均[F1]值为81%,高于基于词语特征的WOMM_word模型6%,高于基于语义特征的WOMM_baseline模型2%,并且在六个评价维度下的个[P],[R],[F1]值相较均有明显提高,表明潜在特征对于评论要素挖掘模型的准确率有所提升。
5 总结
本文针对网络采集的消费者评论数据,以文本挖掘的方法为基础,提出了基于潜在特征的评论要素挖掘模型,该模型对于预测文本数据标注具有良好的效果。在当前研究成果的基础上,下一步我们考虑利用向量方法对评价要素匹配及情感分析领域进行相关研究。
参考文献:
[1] Hu Minqing, Liu Bing. Mining and Summarizing Customer Reviews. In: Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2004. 168-177.
[2] Ana-Maria Popesc, Oren Etzioni. Extracting Product Features and Opinions from Reviews. In: Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT/ACL2005), 2005:339-346.
[3] Blair-Goldensohn Sasha, Hannan Kerry, and McDonald Ryan, etc. Building a sentiment summarizer for local service reviews. In: WWW Workshop on NLP in the Information Explosion Era, 2008. 14.
[4] Scaffidi Christopher, Bierhoff Kevin, and Chang Eric, etc. Red Opal: product-feature scoring from reviews. In: Proceedings of the 8th ACM conference on Electronic commerce. ACM, 2007. 182-191.
[5] Jakob N. and I. Gurevych. 2010. Extracting Opinion Targets in a Single and Cross-Domain Setting with Conditional Random Fields. In Proceedings of EMNLP-10. 1035-1045.
[6] 徐冰,王山雨. 句子级文本倾向性分析评测报告[C]//第二届中文倾向性分析评测会议(COAE2009)论文集,2009:69-73.
[7] 徐冰,赵铁军,王山雨,等. 基于浅层句法特征的评价对象抽取研究[J]. 自动化学报,2011(10):1241-1247.
[8] 王中卿,王荣洋,庞磊. Soda-SAM-OMS情感倾向性分析技术报告[C]//第三届中文倾向性分析评测会议(COAE2011)论文集,2011:25-32.
