基于术语同义关系的文档相似度研究
2017-03-14张锡忠徐建民
张锡忠,徐建民
(1.保定市教育考试院 信息处,河北 保定 071000; 2.河北大学 计算机科学与技术学院,河北 保定 071002)
基于术语同义关系的文档相似度研究
张锡忠1,徐建民2
(1.保定市教育考试院 信息处,河北 保定 071000; 2.河北大学 计算机科学与技术学院,河北 保定 071002)
基于向量空间的文档相似度算法假设特征元素间关系为正交,当2篇文档采用了具有相近语义的不同术语描述时,该方法不能准确反映二者的相似性.针对这种情况,文章利用词语的同义关系,在给出术语与术语组相似度、术语组和术语组间相似度的概念及算法的基础上,给出一种基于词语相似关系的文档相似度计算方法.实验采用科技文献类文档和新闻报道类文档作为测试集合,比较新方法和向量空间算法的分类性能,结果显示新方法可提高文档分类的准确性.
同义词;词语相似度;文档相似度
文本相似度作为数据挖掘的一个热点,在互联网搜索引擎、智能问答、机器翻译、信息检索和社区发现等方面有着广泛的应用[1-2],主要包括文档之间相似度,短语和篇章之间相似度,短语和文章段落之间相似度等.传统的文档之间相似度的计算方法主要包括基于向量空间模型方法[3],基于集合运算模型方法[4],基于文档结构方法[5]和基于引文图方法[6]等.基于空间向量的方法和基于集合运算的方法都假设特征元素之间的关系是正交的,过分依赖于文档特征之间交集的大小[6].基于文档结构的方法和基于引文图方法主要用于结构化文档、科研论文等特殊文本,偏重研究文档之间结构的相似程度,没有合理考虑文档之间的语义联系.
在自然语言文档中,人们往往用不同的词来表达同样的意思,造成2篇含义相近的文档其特征词并不相同.文本文档的特征项主要是术语,术语之间的同义关系实际上隐含了文档之间的语义联系.合理利用术语之间的这些关系可以提高信息系统的性能[7].本文给出了一个文档语义相似度的定义,提出一种利用词语间的同义关系计算文本文档语义相似度的方法,并实验验证了该方法的有效性.
1 基本概念
1.1 文档标引
文本文档一般可以用一组术语来标引,最常用的文本标引方法为TF-IDF方法[8],其中TF (term frequency)是对一个词语局部重要性的度量,用该词语在某一文本中出现的频率表示,频率越大,则该词语对于这篇文本的表示贡献越大;为防止TF偏向长的文本,一般地采用归一化的方法.
(1)
其中,nij是词语ti在文本dj中的出现次数,而分母则是在文本dj中所有词的出现次数之和.
IDF(inverse document frequency)为倒排文本频率,其理论依据为包含词语ti的文档数越少,则该词的辨别力越强,即权重越大.IDF的计算公式为
(2)
其中,N表示文本集的大小,ni表示含有词语ti的文本数.
一种常用的TF-IDF公式为
(3)
T表示文本dj包含的词语总数,T=∑knkj.
1.2 同义词及其度量
同义词概念属于语言学的范畴,在语言学领域,多数学者认为同义词包括2类[9-10]:1)2个词表达的意思完全相同;2)2个词表达的意思有所类似,但又不完全相同.依据辞海提供的书面解释,同义词可定义为:意义相同或者相近的词,其中意义相同地词为等义词,意义相近的词定义为近义词.
信息检索领域的同义词并不完全等同于上述语言学中的同义词.信息检索中的同义词是指在检索过程中能够相互替换的表达相同或者相近概念的词语,并不考虑这些词语携带的感情色彩.检索中,2个同义词的同义程度经常采用二者的相似程度衡量.
词语相似度是一个主观性较强的概念,脱离具体应用谈词语相似度存在弊端,只有在具体的应用环境中词语相似度的概念才比较明确.本文采用文献[11]给出的词语相似度定义.
定义1 词语相似度:词语相似度是用来衡量2个词语在查询中或文档中意义相符程度的度量.词语相似度是一个数值,取值范围为[0,1],词语t1和t2的相似度记为Sim(t1,t2).
词语相似度指标用于度量2个词语相似的程度.理论上,如果t1和t2是同一个词语,则二者的相似度为1,如果t1和t2是2个意义完全不同的词语,则二者的相似度为0,故词语相似度的取值范围为[0,1].
词语相似度的计算方法主要有2类,其一是使用同义词词典或词汇分类体系,利用词语之间的概念距离来计算词语相似度,其二是利用大规模的语料库进行统计的方法.目前常用的同义词词典主要有英语的《wordnet》,中文的《同义词词林》和《Hownet》(知网)[12].
2 基于术语同义关系的文档相似度计算
类似于词语相似度的定义,可以定义一个词语和一组词语之间的相似度.
定义2 术语t和术语组T=(t1,t2,…,tk)之间的相似度定义为术语t和T中每一个术语之间的相似度之和的平均值,记为
(4)
一个词语和一组术语之间的相似度表示了该术语和一组术语之间整体的语义同义关系.
利用术语t和术语组T=(t1,t2,…,tk)相似度的概念,进一步可以定义2组术语之间的相似度.
定义3 2组术语之间的相似度定义为2个集合包含术语两两之间术语相似度之和的平均值,记为
(5)
文本文档是由一组特征词来标引的,这组标引词不仅表示了文档的特征,也表示了文档的语义,因此可以用这组标引词之间的语义相似程度来计算2个文档之间的语义相似程度,但是,一篇文档的不同标引词具有不同的权重,也就是说它们对一篇文档语义表示的贡献度是不同的,文档的语义相似度计算应考虑其标引词的权重.
本文将不考虑文档标引词权重,仅仅使用2组标引词之间相似度表示的文档相似度称作文档的简单语义相似度.
定义4 文档di和dj的简单语义相似度,假定2个文档di和dj的标引词集合分别为di=(ti1,ti2,tim)和dj=(tj1,tj2,…,tjm),则文档di和dj的简单语义相似度定义为
(6)
由文档标示知识可知,若术语tij和术语tik(j≠k)在文档di中的权重不同,其对di标引所起到的贡献也不同,于是在计算文本相似度时的贡献也不同.
定义5 文档di和dj的语义相似度,设2个文档di=(ti1,ti2,…,tim)和dj=(tj1,tj2,…,tjm)的权重分别为wi=(wi1,wi2,…,wim)和wj=(wj1,wj2,…,wjm),则文档di和dj的语义相似度定义为
(7)
其中α为调节系数.
3 实验及评价
3.1 测试集合
测试集包括2大类文档,分别是科技文献类(A类)和新闻报道类(B类),其中科技文献类包括2个子类:信息检索类和软件工程类,共30篇科技文献.新闻报道类包括3个子类:治安类、母婴类和航天类,共36篇新闻报道.实验分别采用传统向量空间模型和文章提出的基于术语同义关系的文档语义相似度计算任意2篇文档的相似度,对二者计算的准确率进行比较.
3.2 词语同义度的获得
实验首先对测试集中所有文档向量化,每个文档取权重最大的前50个特征词表示,然后将所有特征词两两组成术语对,用刘群提出的算法计算术语对的相似度,并人工去除不合语义的结果,最终获得术语的相似度.
3.3 实验结果

图1为采用A类文档作为测试集合时,依据传统向量空间方法和文章提出的方法对435对文档在不同阈值下计算分类的准确性,绘制出分类准确性曲线图.从图1可以看出,在科技文献类文档的应用环境中,新方法的性能明显优于旧方法,准确率最大可以提高9.518%.

图1 科技文献类性能比较

图2 新闻报道类性能比较
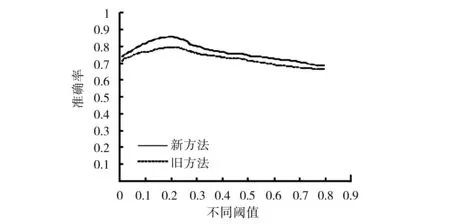
图3 完整测试集性能比较
图2为在新闻报道类测试集中,新方法和旧方法分类准确性的对比曲线,新方法的性能优于旧方法,但提高幅度低于科技文献类文档,其原因是新闻报道类文档一般比较短,出现同义词的可能性低于较长的科技文献类文档.在整个测试集合中,分别运用旧方法和新方法在不同阈值下对2 145对文档进行分类,依据分类的准确性绘制出如图3所示的性能比较图.
综上,不管在科技文献类文档的应用环境中,还是在新闻报道类文档的应用环境中,或者是混合类文档的应用环境中,新方法均可在一定程度上提高文档分类的准确性.表1为3种应用环境下,新方法分类准确性的最大提高值.
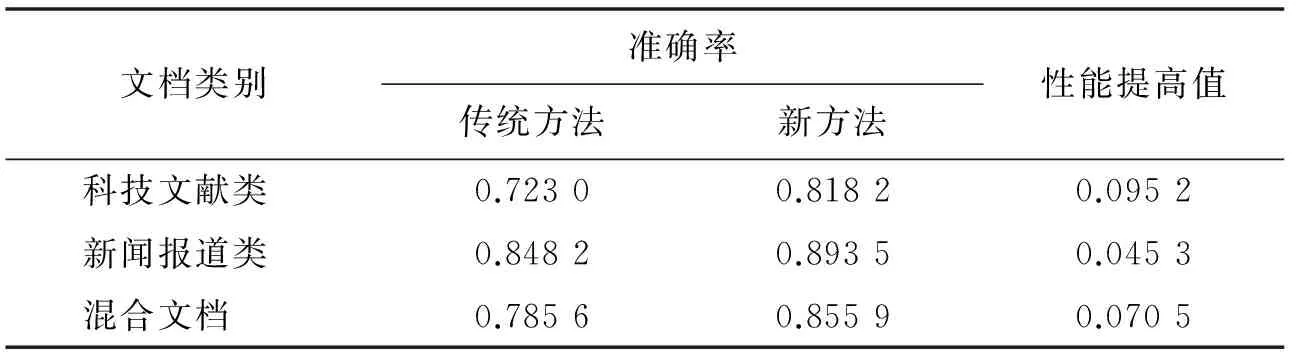
表1 不同类文档下的最大性能提高值
4 结束语
文章将同义关系应用于文档的相似度计算,提出融合同义关系的文档语义相似度计算方法,实验验证了该方法对文档分类的有效性.在未来的研究中,将寻找更为规范的测试集合,进一步对新方法进行验证.语义信息是提高文档分类准确性的重要途径,除同义信息外,将针对特定类型文本,挖掘其他语义信息,进一步提高现有文本分类系统的分类性能.
[1] 孙润志.基于语义理解的文本相似度计算研究与实现 [D].沈阳:中国科学院沈阳计算技术研究所,2015. SUN R Z.Research and implementation of text similarity computing based on semantic understanding [D].Shenyang :Shenyang Institute of Computing Technology,Chinese Academy of Sciences,2015.
[2] 杨长春,徐小松,叶施仁,等.基于文本相似度的微博网络水军发现算法[J].微电子学与计算机,2014,31(3):82-85. YANG C C,XU X S,YE S R,et al.A method to find water armies in weibo based on text similarity[J].MICROELECTRONICS & COMPUTER,2014,31(3):82-85.
[3] 谭静.基于向量空间模型的文本相似度算法研究 [D].成都:西南石油大学,2015.
[4] RICARDO BAEZA-YATES,BARTHIER RIBEIRO-NETO.Mordern informtion retrieval[M].北京:机械工业出版社,2004:24-38.
[5] 赵宁宁,梁意文.综合结构和内容的XML文档相似度计算方法 [J].微电子学与计算机,2016,33(4):69-72.DOI:10.19304/j.cnki.issn1000-7180.2016.04.015. ZHAO N N, LIANG Y W. Combining structure and content similaritiesmeasure for XML document[J].Microelectronics & Computer,2016,33(4):69-72.DOI:10.19304/j.cnki.issn1000-7180.2016.04.015.
[6] 万昊,谭宗颖,鲁晶晶,等.2001~2014年引文分析领域发展演化综述 [J].图书情报工作,2015,59 (6) :120-136.DOI:10.13266/j.issn.0252-3116.2015.06.018.DOI:10. 13266 / j. issn. 0252 - 3116. 2015. 06. 018.
[7] CAMPOS L M de,FERNáNDEZ-LUNA J M,HUET J F.Clustering terms in the Bayesian network retrieval model:a new approach with two term-layers[J].Applied Soft Computing,2004,4(2):149-158.DOI:http://dx.doi.org/10.1016/j.asoc.2003.11.003.
[8] 牛萍,黄德根.TF-IDF与规则相结合的中文关键词自动抽取研究 [J].小型微型计算机系统,2016,37(4):711-715. NIU P,HUANG D G.TF-IDF and rules based automatic extraction of chinese keywords [J].Journal of Chinese Computer Systems,2016,37(4):711-715.
[9] 张为泰.基于词向量模型特征空间优化的同义词扩展研究与应用 [D].北京:北京邮电大学,2015.
[10] 刘怀亮,杜坤,秦春秀.基于知网语义相似度的中文文本分类研究 [J].现代图书情报技术,2015,2:39-45.
[11] 徐建民.基于术语关系的贝叶斯网络信息检索模型扩展研究[D].天津:天津大学,2007. XU J M.Research of Using term-relationships to extend Bayesian network retrieval models[D].Tianjin:Tianjin University,2007.
[12] 陈宏朝,李飞,朱新华,等.基于路径与深度的同义词词林词语相似度计算 [J].中文信息学报, 2016,30(5):80-88. CHEN H C,LI F,ZHU X H,et al.A path and depth-based approach to word semantic similarity calcalation in CiLin[J].Journal of Chinese Information Processing,2016,30(5):80-88.
(责任编辑:孟素兰)
Research on document similarity based on terms synonymous relationship
ZHANG Xizhong1,XU Jianmin2
(1.Institute of Information Technology,Baoding Education Examinations Authority,Baoding 071000,China;2.School of Computer Science and Technology,Hebei University,Baoding 071002,China)
Because vector space model (VSM) assumes that terms in different documents is orthogonal,when different documents are described by different terms,VSM can’t accurately reflect the similarity between them.For this problem,based on giving definition and computing method of similarity between two terms set,this paper gives a quantification method to calculate similarity between two documents.Our experiments adopt science and technology literature documents and news stories to test the classification accuracy of VSM and the new method,results indicate that the new method can improve classification accuracy.
synonymous;similarity between two terms;similarity between two documents
10.3969/j.issn.1000-1565.2017.01.016
2016-10-10
河北省自然科学基金资助项目(F2015201142);河北省社会科学基金资助项目(HB15SH064)
张锡忠(1966—),男,河北衡水人,保定市教育考试院高级工程师,主要从事信息管理、管理信息系统研究. E-mail:13903223288@139.com
徐建民(1966—),男,河北馆陶人,河北大学教授,博士,主要从事为信息检索、不确定信息处理. E-mail:hbuxjm@hbu.edu.cn
G353;TP393
A
1000-1565(2017)01-0108-05
