基于停留时间的语义行为模式挖掘
2017-02-21郭黎敏郭皓明徐怀野魏闫艳王之欣
郭黎敏 高 需 武 斌 郭皓明 徐怀野 魏闫艳 王之欣 焉 丽 田 霂
1(北京工业大学 北京 100124)2(中国科学院软件研究所 北京 100190)3 (中国科学院大学 北京 100049)(guolimin@bjut.edu.cn)
基于停留时间的语义行为模式挖掘
郭黎敏1高 需2,3武 斌2郭皓明2徐怀野2魏闫艳2王之欣2焉 丽2田 霂2
1(北京工业大学 北京 100124)2(中国科学院软件研究所 北京 100190)3(中国科学院大学 北京 100049)(guolimin@bjut.edu.cn)
移动对象的语义行为模式挖掘是当前移动对象研究中关注的热点,有益于诸多应用场景,如朋友推荐系统、轨迹破案领域和个性化服务等.目前语义行为模式挖掘方法没有考虑移动对象在停留点的停留时间,不能准确地分辨出移动对象之间的不同行为模式.为了解决上述问题,提出了一种基于停留时间的语义行为模式挖掘(discovering common behavior using staying duration on semantic trajectory, DSTra)方法,首先挖掘每个移动对象的频繁语义行为模式,然后定义语义行为模式之间的相似性度量方法,最后采用层次聚类的方法对移动对象进行聚类,找出具有相似行为模式的移动对象群体.实验结果表明:该方法不仅具有合理性和有效性,同时还具有较高的准确率和较好的效率.
语义轨迹;停留时间;语义行为模式;模式相似度;移动对象聚类
随着移动便携设备的广泛普及以及无线通信技术和全球定位技术的飞速发展,移动对象可以方便地获取其位置信息并对移动轨迹进行存储管理.移动轨迹本身的价值使得各种基于位置的服务越来越受到国内外研究学者的关注,移动对象的轨迹模式挖掘是其中最受关注的热点问题之一.本文研究了移动对象的语义行为模式挖掘方法,即在移动对象语义轨迹的基础上,找出具有相似行为模式的移动对象群体.
事实上,移动对象轨迹记录了人们在现实世界中的活动,而这些活动在一定程度上反映了其生活方式或行为习惯,因此通过对轨迹数据进行分析,挖掘出移动对象的行为模式,发现移动对象之间相关性具有重要的研究价值与广泛的应用领域.如在朋友推荐系统中,通过用户分享的轨迹数据,发现用户的生活方式、兴趣爱好等,推荐趣味相投的朋友;在轨迹破案领域,分析犯罪行为遗留的轨迹信息,结合对嫌疑人的关联分析,查找案件的同伙关系人,并发现嫌疑人的移动模式及其规律,预测其发展走向,协助案件侦破;在个性化服务中,帮助服务供应商了解用户的生活规律,预测用户的行驶路径,实现商品或路径推荐.可以说,移动对象的轨迹模式挖掘技术已经得到了人们日益广泛的重视.
移动对象的轨迹模式挖掘可以分为两大类:基于地理信息的轨迹模式挖掘和基于语义信息的轨迹模式挖掘.其中,前者主要关注轨迹的位置特征,如轨迹形状、行驶方向、速度等;后者则主要关注轨迹的语义信息.在基于地理信息的轨迹模式挖掘方法中,位置越靠近并且形状越相似的轨迹被认为越相似.如图1所示,仅从轨迹的位置特征考虑,MO1与MO2最相似,因为MO1与MO2的轨迹距离最接近并且形状最相似.然而,基于地理位置的相似性度量缺乏语义信息,并不能挖掘移动对象的移动模式.在基于语义信息的轨迹模式挖掘方法中,语义轨迹对移动对象行驶路径中的地理位置标注上了语义信息,图1中语义层的轨迹是地理层中的移动轨迹对应的语义轨迹.然而,现有的基于语义信息的轨迹模式挖掘方法没有考虑移动对象在每个停留点的停留时间.例如,在图1中MO1和MO3具有相同的移动模式:家→饭店→公司→饭店,但是实际上MO1与MO3并不相似,因为MO1在饭店工作,去公司送外卖后再返回饭店,而MO3在饭店吃完早餐后去公司上班,并再次返回饭店吃午饭.因此,现有的基于语义的方法不能准确地分辨出移动对象之间不同的生活方式.
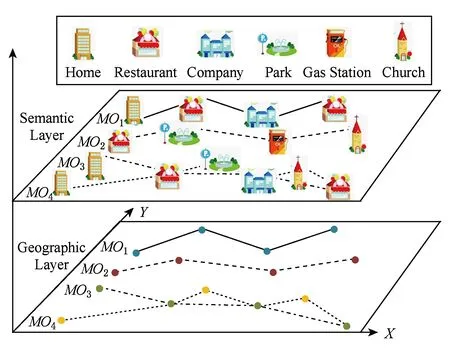
Fig. 1 Geographic and semantic trajectories图1 地理信息轨迹和语义信息轨迹
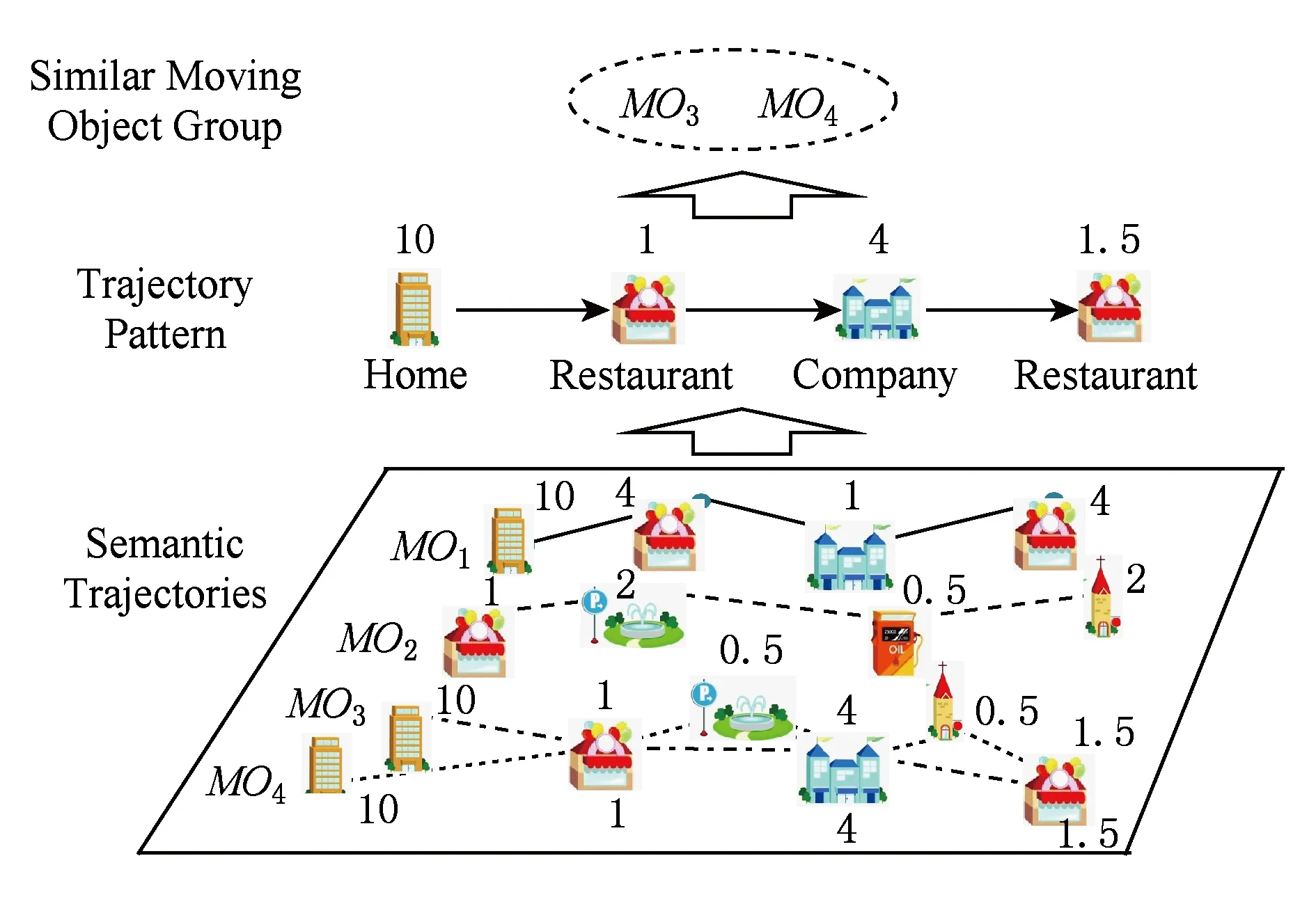
Fig. 2 User behaviors with staying durations图2 基于停留时间的语义行为模式挖掘
通过上述分析可以看出,在轨迹模式挖掘技术方面,目前缺乏一种能够处理移动对象停留时间的高准确性的轨迹模式挖掘方法.为了解决上述问题,本文提出了一种基于停留时间的语义行为模式挖掘(discovering common behavior using staying duration on semantic trajectory, DSTra)方法.DSTra具备2种优势:1)能够提高不同语义行为模式之间的区分度;2)能够发现具有相似生活方式或行为习惯的移动对象群体.在图2中,如果考虑每个停留点的停留时间,就能容易地区分出图1中MO1与MO3具有不同的行为模式.由于MO1与MO3在公司和饭店的不同停留时间体现了其不同的意图,因此可以分辨出MO1与MO3具有不同的行为模式.由此可以从图2中挖掘出语义行为模式 (家,10)→(饭店,1)→(公司,4)→(饭店,1.5),并逐步找出具有相似行为模式的移动对象聚类{MO3,MO4}.
DSTra的基本思路是:在一系列移动对象的语义轨迹集合中,1)挖掘出每个移动对象的基于停留时间的频繁语义行为模式;2)基于停留时间给出了语义行为模式之间的相似性度量方法;3)通过模式之间的相似性,采用层次聚类的方法对移动对象聚类,每一个聚类代表具有一系列相似语义行为模式的移动对象集合,也就是具有相似生活方式、行为习惯的移动对象集合.归纳总结本文的主要贡献有5点:
1) 定义了基于停留时间的语义行为模式;
2) 提出了一种基于停留时间的语义行为模式挖掘算法;
3) 提出了一种基于停留时间的语义行为模式相似性度量方法;
4) 提出了一种基于模式相似性的移动对象聚类算法;
5) 验证了DSTra方法在挖掘语义行为模式时的有效性、高准确性及高效性.
1 相关工作
本节首先介绍了轨迹相似性度量方法,然后概述了现有的轨迹模式挖掘技术.
轨迹相似性度量方法主要分为两大类:基于地理信息的相似性度量和基于语义信息的相似性度量.
基于地理信息的相似性度量关注的是轨迹的位置特征,早期的研究主要是基于欧氏距离的度量方法,其中最具代表性的有DTW[1],EDR[2],LCSS[3].此外,针对轨迹模式之间的相似性度量也进行了相关的研究[4-7],文献[4]研究了基于线索的轨迹相似性.文献[5]提出了3种距离度量方法;基于语义信息的相似性度量主要关注的是轨迹的语义特征,文献[8-11]对语义轨迹进行了研究,语义轨迹被定义为一系列时空位置与相应停留点的集合,如此不仅能抽取位置信息还能挖掘语义信息.另外,研究学者在语义轨迹相似性领域也进行了相关的讨论和研究[12-16].这些文献中,首先将轨迹转换为语义轨迹,然后通过移动对象之间的相似性进行用户推荐.文献[15]依据用户之间轨迹模式的相似性定义用户之间的相似性.文献[13-14]通过层次树状结构计算相似性.文献[16]结合了位置及语义特征预测用户未来的位置.
基于地理信息的相似性度量方法只能处理轨迹的位置信息,而基于语义信息的相似性度量方法不能处理轨迹中的停留时间,因此现有的相似性度量方法不能解决基于停留时间的轨迹相似性问题.
现有的轨迹模式挖掘方法可以分为2大类:轨迹模式挖掘和轨迹聚类.
轨迹模式挖掘研究的是移动对象的运动模式,早期的研究主要关注的是轨迹的时空属性[17-20],其基本思想是通过序列模式挖掘找出频繁轨迹模式.由于这些方法没有考虑停留时间对轨迹模式的影响,因此不能有效地区分不同的轨迹模式.
轨迹聚类的目标在于挖掘具有相同运动模式的移动对象集合[21-26].除此之外,另一类研究的目标在于找出移动对象集合的公共路径,文献[5]将每条轨迹划分为一系列子轨迹,然后基于距离函数进行聚类.文献[27]在轨迹划分和聚类的过程中同时考虑了时间和空间因素.
上述轨迹模式挖掘方法从移动对象的个体或群体的角度出发进行研究,但是既不能挖掘移动对象的公共行为模式,也不能处理语义轨迹.为了解决上述问题,本文提出了一种基于停留时间的语义行为模式挖掘方法.
2 问题定义
本节以语义轨迹为基础,首先给出了语义行为模式的相关问题定义,然后介绍了DSTra方法的系统架构.
为便于叙述,表1给出了本文的符号描述表.
定义1. 语义点.语义点A定义为
A=(A,t),
其中,A是移动对象的停留点,t是移动对象在A的停留时间.
定义2. 语义轨迹.语义轨迹S是一组移动对象语义点的有序序列,定义为
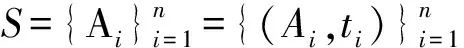
.
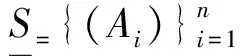
不失一般性,我们使用字母表示移动对象的停留点,表2为某一移动对象的语义轨迹集合实例.

Table 2 An Example of Semantic Trajectory Dataset
定义3. 语义轨迹等价.给定停留阈值δt,语义轨迹S1与S2等价定义为S1≅S2,当且仅当满足条件:

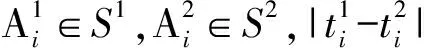
其中,条件2对相应2个语义点之间的停留时间进行了约束,即停留时间比例差受限于δt.
定义4. 语义行为模式.语义行为模式P是一组相似语义轨迹的共同模式,定义为

为了更好地描述语义行为模式挖掘,我们定义了语义行为模式与语义轨迹之间的匹配关系.
定义5. 模式匹配.给定语义行为模式P和语义轨迹S,S匹配P定义为SP,当且仅当S存在子序列SP,使得SP≅P.
移动对象的行为语义提取即从语义轨迹集合中挖掘出频繁语义行为模式.
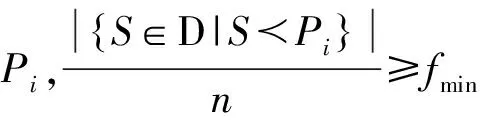
以表2为例,假设δt=0.5,fmin=0.5,依据定义6,{(a,10),(b,0.5),(c,4),(b,1.5)}是一个语义行为模式.然而任意形如{(a,10),(b,t),(c,4),(b,1.5)}(t∈[0.5,1])的行为模式都满足条件.因此,我们采用平均停留时间来表示行为模式中的停留时间.
问题描述:给定语义轨迹集合D、最小支持度fmin和停留阈值δt,移动对象的语义行为模式挖掘步骤如下:1)依据fmin和δt,从D中进行行为语义提取,找出所有语义行为模式的集合P;2)度量P中模式之间的相似度;3)在相似度的基础上,依据移动对象的相似生活方式、行为习惯等进行聚类.
由此,我们提出了一种语义行为模式的挖掘方法——基于停留时间的语义行为模式挖掘DSTra.DSTra的系统结构如图3所示,可以分为3部分:1)语义行为模式挖掘(semantic trajectory pattern mining,STPM);2)模式相似性度量(pattern similarity, P-Similarity);3)基于模式相似性的移动对象聚类(similarity-based user clustering, SU-Clustering).
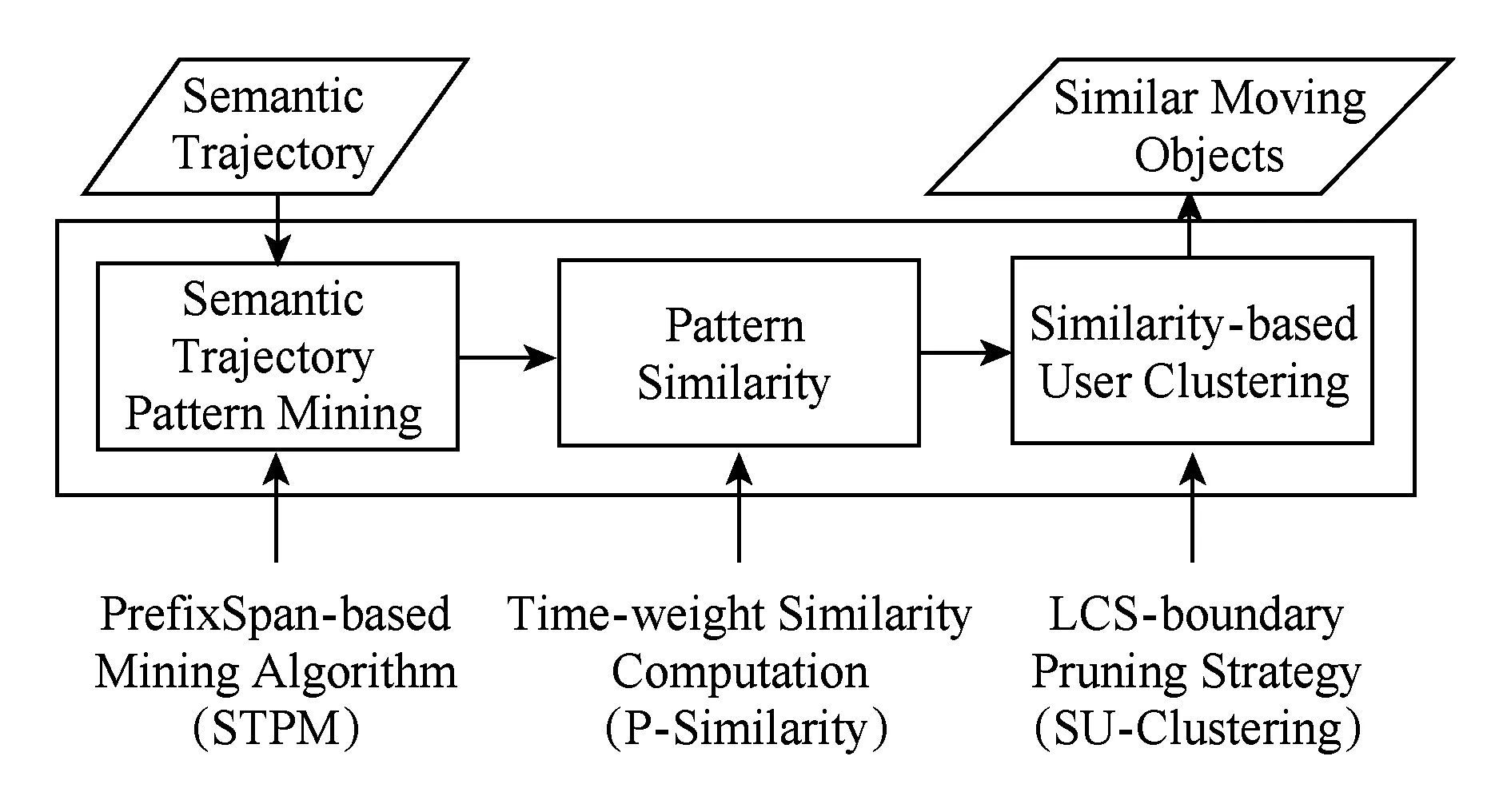
Fig. 3 System overview of DSTra图3 DSTra的系统结构
图3中,1)提出了基于停留时间的语义行为模式挖掘算法,并对每个移动对象进行了行为语义抽取;2)设计了基于时间权重的语义行为模式相似度度量方法;3)在模式相似性的基础上,采用剪枝策略进行层次聚类,找出所有具有相似行为模式的移动对象群体.
3 基于停留时间的语义行为模式挖掘算法
本节首先给出了相关数据结构,然后详细介绍了语义行为模式挖掘算法STPM.
在语义行为模式挖掘之前,首先要将原始轨迹转换为语义轨迹,相关研究较为丰富[7],鉴于篇幅所限,在此处不再详述;然后针对每一个移动对象,提取其主要的语义行为模式集合.
在PrefixSpan算法的基础上,我们提出了基于停留时间的语义行为模式挖掘算法STPM.STPM与PrefixSpan的不同之处在于投影数据库的构建,对于α,PrefixSpan中α-投影数据库是由第1次出现的α为前缀的子序列构成,而STPM中并不总以第1次出现的α为前缀.我们采用类似文献[28]中的数据结构来构建α-投影数据库.
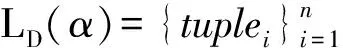
tuple=sid,pos,t,proj,
其中,sid是语义轨迹在D中的标识号;pos是α中最后一个停留点在语义轨迹中的位置;t是在α中最后一个停留点的停留时间;proj是pos位置上以α为前缀的子序列.
表3为表2中语义轨迹集合的b-投影数据库.

Table 3 b -projected Database
STPM算法的伪代码如算法1所示.STPM是深度优先递归算法,递归地扩展语义行为模式,以及试探其是否满足频繁语义行为模式的条件,并通过不断构建投影数据库有效降低支持度及停留时间计算的时间复杂度.
算法1. STPM算法.
输入:语义轨迹集合D、最小支持度fmin、停留阈值δt、语义行为模式P;
输出:频繁语义行为模式集合P.
②S1←Frequent(LD(P));
③ forβinS1do
⑤P′←P⊕β;*P后扩展β*
⑥ LD(P)←∅;
⑧ fortpin LD(P) do
⑨S←D(tp.sid);
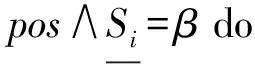



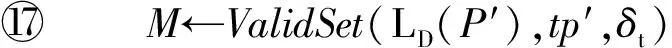
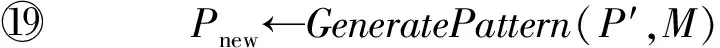
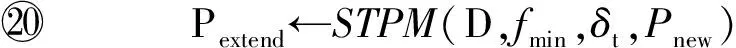





R=[tp′.t,tp′.t1-δt].
函数ValidSet()最终返回LD(P′)中停留时间在R范围内的项集M.


函数GeneratePattern()最终返回语义行为模式P′=P⊕(β,tβ).
在表3中,假设δt=0.5,tp′=3,4,1.5,∅,则等价停留时间R=[1.5,3],等价项集M={3,4,1.5,∅,4,6,1.5,∅},停留点b的平均停留时间tb=(1.5+1.5)2=1.5.
4 语义行为模式相似性
本节介绍了语义行为模式之间的相似性度量方法.
从直觉上来说,语义行为模式之间的相似性与其之间的公共子串相关,因此我们采用公共子串来度量模式之间的相似性.
定义8. 最长公共子串.给定2个语义行为模式P1和P2,P1与P2的最长公共子串LCS满足条件:
1)LCSP1∧LCSP2;
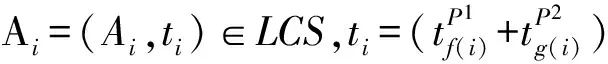
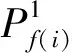
为了突出停留时间对语义行为模式的影响,我们给出了时间权值的定义.
定义9. 时间权值.给定语义行为模式P1,P2及其最长公共子串LCS,对于Ai∈LCS,Ai的时间权值定义为

定义10. 语义行为模式相似度.给定语义行为模式P1,P2及其最长公共子串LCS,P1与P2之间的相似度定义为
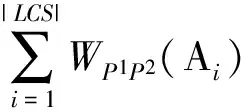
其中Ai∈LCS.
假设δt=0.5,给定2个语义行为模式P={(a,10),(b,1),(c,4)} 和Q={(a,10),(b,0.5),(d,0.5),(c,4)},那么P与Q的最长公共子串为LCS(P,Q)=(a,10),(b,0.75),(c,4).表4给出了LCS的时间权值,因此P,Q之间的相似度为Sim(P,Q)=(13+14)×(1+0.5+1)=1.46.
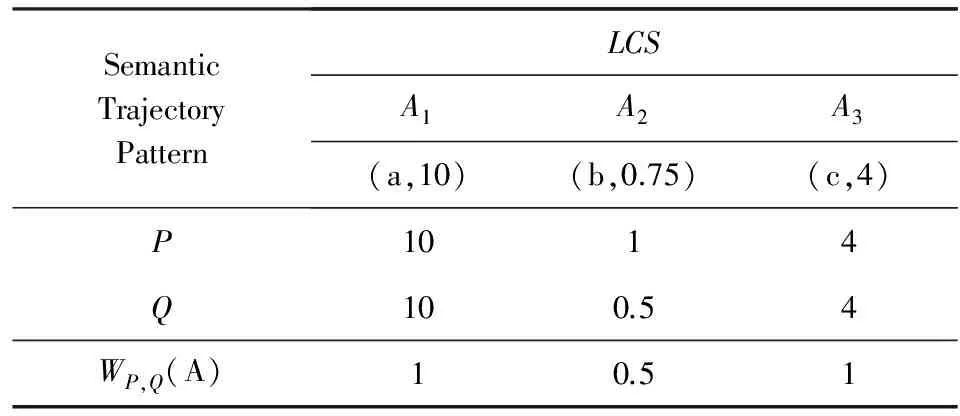
Table 4 An Example of Time-Weight
动态规划是寻找最长公共子串最有效的方法,动态规划方法采用二维数组标识中间计算结果,避免了重复计算而提高了效率.我们修改了文献[29]中的算法,采用矩阵SM保存最长公共子串计算过程中语义行为模式之间的时间权值.给定语义行为模式P,Q,SM[i,j]的计算公式定义为
SM[i,j]=
(1)

算法2. P-Similarity算法.
输入:语义行为模式P和Q、停留阈值δt;
输出:相似度Sim.
① fori=0 to |P| do
②SM[i,0].count←0,SM[i,0].t←0;
③ end for
④ forj=0 to |Q| do
⑤SM[0,j].count←0,SM[0,j].t←0;
⑥ end for
⑦ fori=1 to |P| do
⑧ forj=1 to |Q| do
⑨ ifPi≅Qjw.r.tδtthen
⑩SM[i,j].count←SM[i-1,j-1]+wi j;


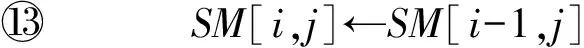

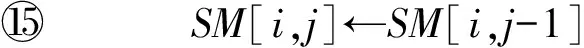

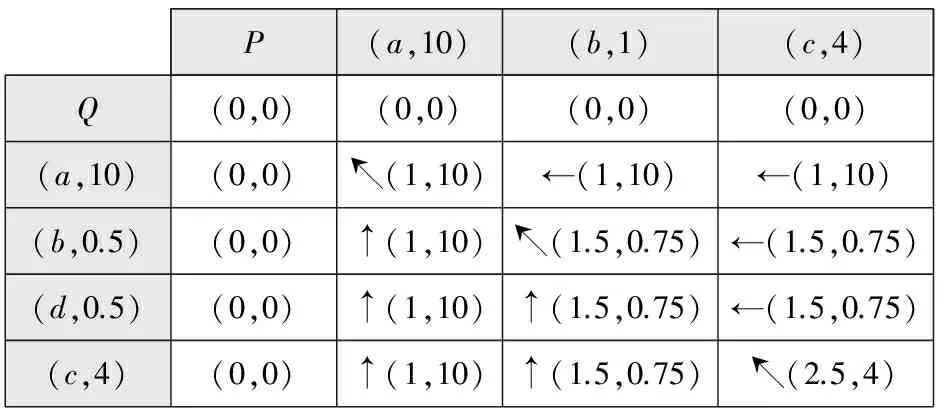
P(a,10)(b,1)(c,4)Q(0,0)(0,0)(0,0)(0,0)(a,10)(0,0)↖(1,10)←(1,10)←(1,10)(b,0.5)(0,0)↑(1,10)↖(1.5,0.75)←(1.5,0.75)(d,0.5)(0,0)↑(1,10)↑(1.5,0.75)←(1.5,0.75)(c,4)(0,0)↑(1,10)↑(1.5,0.75)↖(2.5,4)

Fig. 4 An example of P-Similarity
图4 P-Similarity算法实例
5 基于模式相似性的移动对象聚类
本节介绍了如何在语义行为模式相似性的基础上找出具有相似行为模式的移动对象集合,并提出了基于模式相似性的移动对象聚类算法SU-Clustering,然后在此基础上介绍了SU-Clustering的优化算法.
由于基于密度的聚类算法可能引入噪声点,因此我们采用了层次聚类的方法.为了保证移动对象聚类的有效性,限定同一聚类中语义行为模式之间的最长公共子串长度不能小于长度阈值δlen.
算法3. SU-Clustering算法.

输出:移动对象聚类集合MO.
①MO←∅;
② fori=1 ton-1 do
③ forj=i+1 tondo
⑤Sim[i,j],Lcs[i,j]←P-Similarity(ci.P,cj.P);
⑥ end for
⑦ end for
⑩FindSimPattern(Sim,Lcs,δlen);






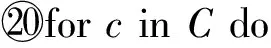
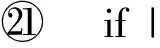
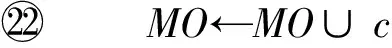
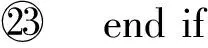
算法3中行⑧,函数FindSimPattern()返回满足一对最相似聚类cp,cq的条件:
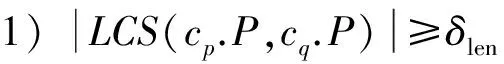
2)cp.U∩cq.U=∅.
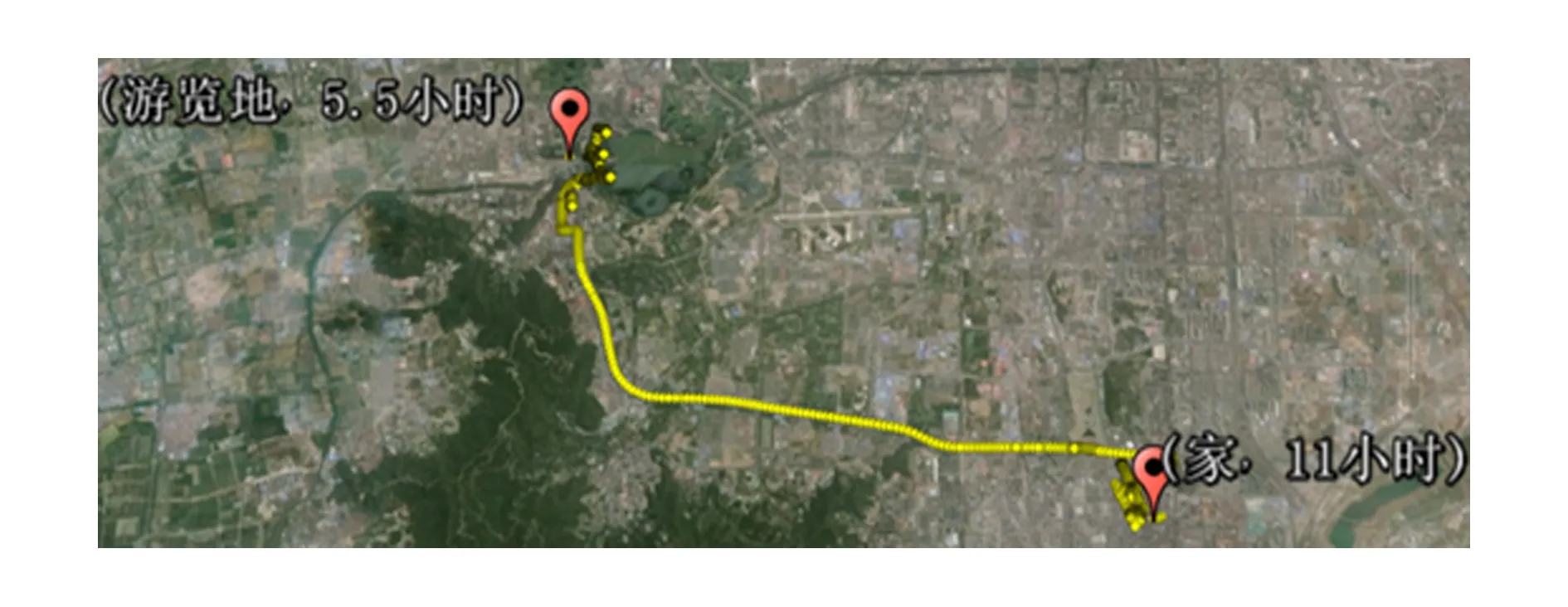
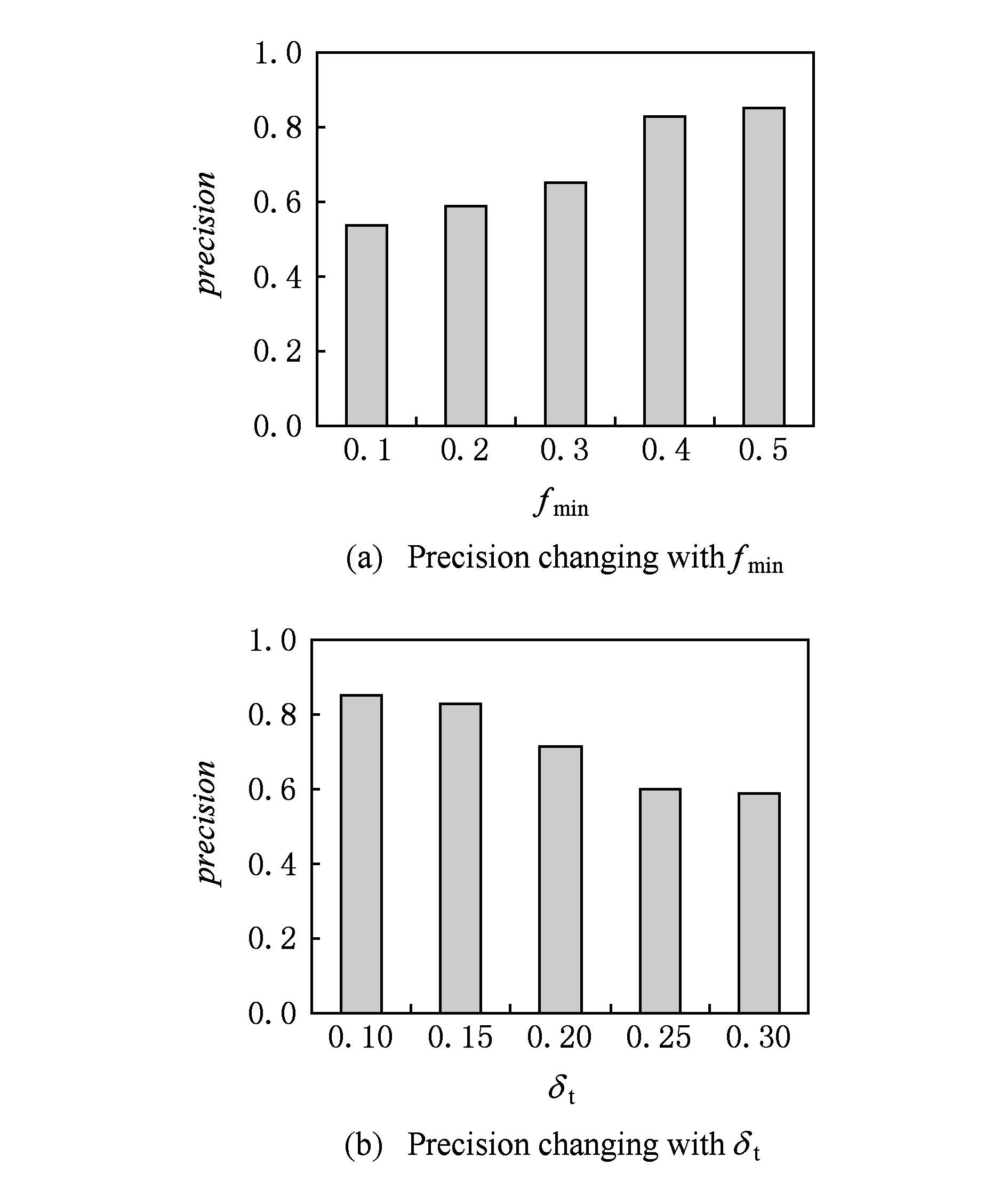
假设语义行为模式个数为n,语义行为模式的平均长度为m,迭代次数为n1,那么初始化矩阵Sim和矩阵Lcs的时间复杂度为O(n2m2),层次聚类的时间复杂度为O(n1nm2).因为n1 在每次迭代过程中,函数Adjust()需要调用n次函数P-Similarity()以更新矩阵Sim和矩阵Lcs,而这将带来较大的时间开销.为了避免不必要的计算,我们给出了剪枝策略性质1. 性质1. 假设给定语义行为模式P和Q,P与Q的最长公共子串长度的边界值等于P,Q之间等价的语义点个数,记作LCS-Boundary(P,Q). 利用性质1,我们能通过剪枝策略对函数Adjust()进行优化,优化后Adjust()算法如算法4: 算法4. Adjust算法. 输入:相似度矩阵Sim,最长公共子串矩阵Lcs,语义行为模式cp,cq,cnew,长度阈值δlen. ② 从Sim和Lcs中删除第p行和第q列; ④ fori=1 ton-1 do ⑤ ifLCS-Boundary(cnew.P,ci.P)≥δlenthen ⑥Sim[n,i],Lcs[n,i]←P-Similarity(cnew.P,ci.P); ⑦ end if ⑧ end for ⑨ return 假设语义行为模式个数为n,语义行为模式的平均长度为m,那么算法4的时间复杂度为O(nm2).虽然在最坏的情况下,算法4不能优化Adjust()算法,但在实验中我们发现优化后的聚类算法能大约提高50%的效率,因此剪枝策略可以有效地减少不必要的计算代价,提高效率. 本节实现了DSTra实验系统,并在真实数据集和模拟数据集的基础上,对语义行为模式的有效性、准确性以及效率进行了一系列实验验证. 实验所用的真实数据集来自GeoLife[30-32],GeoLife数据集是由微软亚洲研究院182名志愿者采集的9 462条GPS轨迹构成.实验所用的模拟数据由机器产生,我们模拟了一系列移动对象,并依据每个移动对象的行为习惯对其生成了一系列语义轨迹.为了真实模拟移动对象的语义轨迹,我们使用了2个参数控制移动对象的行为习惯:Npc和Pr.具体来说,我们将语义行为模式共分为Npc种类型,每一类语义行为模式描述移动对象的一类行为习惯或生活方式.对于每个移动对象,其中Pr比例的语义轨迹随机生成,剩下的语义轨迹依据Npc中的一部分行为模式生成.据此模拟的数据既具有一定的行为习惯又具有一定的灵活性,能较真实地还原移动对象的轨迹. 实验程序用C++编写,编译工具为GCC 4.4.6,优化选项为-O2.实验硬件平台处理器为Intel®Xeon®CPU E5-2630,主频为2.3 GHz,内存大小为4 GB;软件平台为CentOS release 6.2(Final).我们将从3个方面来分析DSTra的性能:1)语义行为模式挖掘的有效性;2)语义行为模式挖掘的准确率;3)语义行为模式挖掘的效率.表5给出了实验中的主要参数. Table 5 Experiment Settings 6.1 有效性验证 本节在真实数据集GeoLife的基础上验证了语义行为模式的有效性. 由于GeoLife数据集中的轨迹为GPS轨迹数据,因此不能在DSTra中直接使用,需要进行预处理.我们在处理中结合北京市POI数据库,首先从GeoLife数据集中挖掘出家、公司、超市、游览地、商场、车站、学校、公园、饭店几类具有代表性的访问点;然后以此为依据,将GPS轨迹转换为相应的语义轨迹;最后选择了周末节假日的语义轨迹以发现更有趣的生活方式. 为了显示停留时间对语义行为模式的影响,我们统计了语义轨迹中每个访问点的停留时间(假设志愿者关闭采集器后都在家中),并忽略了无法统计停留时间的语义轨迹.图5是115号志愿者(简称115号)的语义行为模式在Google Map中的展示.参数设置为:fmin=0.1,δt=0.2. Fig. 5 Semantic trajectory patterns of No.115图5 115号语义行为模式 图5(a)(b)是从115号的语义轨迹中抽取出的语义行为模式.可以看出,图5(a)(b)的轨迹位置并不相似,基于地理位置信息的轨迹模式挖掘方法不能发现用户的生活方式,而DSTra方法能有效地挖掘出语义行为模式(家,7.5 h)→(游览地,2.5 h)→(家,11 h),表示115号有周末出去游的生活习惯. 图6是73号志愿者(简称73号)的语义行为模式在Google Map中的展示.参数设置为:fmin=0.1,δt=0.2. Fig. 6 Semantic trajectory patterns of No.73图6 73号语义行为模式 图6是从73号的语义轨迹中抽取中的语义行为模式,即(游览地,5.5 h)→(家,11 h).可以看出,DSTra方法可以准确地区分出115号与73号2种不同的生活方式,其中115号偏向周末小游一趟,73号则偏向周末外出畅游,而没有考虑停留时间的轨迹模式挖掘方法却不能分辨出其中差别.由此,根据用户相似的生活习惯,DSTra可以将用户进行聚类,同一聚类内的用户具有相似生活方式或行为习惯. 6.2 准确性验证 本节模拟了100个移动对象,并依据每个移动对象的行为习惯各生成了1 000条语义轨迹,其中20%条语义轨迹随机生成,80%条语义轨迹依据20种行为习惯生成.为了更好地评估语义行为模式挖掘的准确率,我们给出了准确率的定义: 其中,ξcorrect是正确的语义行为模式个数,ξall是所有的语义行为模式个数.图7是准确率与最小支持度fmin以及停留阈值δt的关系,参数设置为:Nmo=100,Ntrj=1 000,Lpattern=6,Npc=20,Pr=0.2. 图7(a)显示随着最小支持度的增加,语义行为模式的准确率也随之增加,这是因为随着最小支持度的增加,挖掘出的语义行为模式更主流,相应地错误的模式也就随之减少,准确率增加.图7(b)显示语义行为模式的准确率随着停留阈值的增加而逐渐减少,由于停留阈值增加会导致不同模式的区分度降低,从而导致准确率下降. Fig. 7 Precision evaluation图7 准确性评估 6.3 效率验证 本节在模拟数据集的基础上验证了SU-Clustering及其优化算法Optimized-SUC的执行效率.图8是SU-Clustering与Optimized-SUC算法的效率评估,图8(a)中停留阈值δt=0.2,图8(b)中模式平均长度Lpattern=6,其他参数设置为:Nmo=100,Ntrj=1 000,fmin=0.2,δlen=3. Fig. 8 Runtime evaluation图8 效率评估 图8(a)为执行时间与模式平均长度的关系,随着模式平均长度的增加,SU-Clustering和Optimized-SUC的执行时间都逐渐增加,这是由于随着模式平均长度的增加,算法中最耗时的最长公共子串匹配的计算复杂度增加,从而导致效率下降.与此相似,图8(b)中SU-Clustering和Optimized-SUC的效率也随着停留阈值的增加而下降,因为最长公共子串匹配的时间复杂度也随着停留阈值增加而增加.除此之外,图8(a)(b)都显示,算法Optimized-SUC的性能明显优于算法SU-Clustering,充分表明Optimized-SUC中的剪枝策略具有显著的效果. 实验结果显示,本文提出的语义行为模式挖掘方法不仅具有合理性和有效性,同时还具有较高的准确率和较好的挖掘效率. 本文提出了一种语义行为模式挖掘方法,能够挖掘出具有相似行为习惯或生活方式的移动对象群体.为了提高不同语义行为模式之间的区分度,本文引入了停留时间的概念,并在此基础上提出了一种基于停留时间的语义行为模式挖掘方法DSTra.DSTra挖掘框架分为3部分:语义行为模式挖掘、模式相似性度量、基于模式相似性的移动对象聚类.DSTra方法具有广泛的应用前景.如在朋友推荐系统中,根据用户提供的日常行为轨迹,挖掘出每个用户的语义行为模式,利用模式相似性度量方法计算语义行为模式之间的相似性,最后基于模式相似性对用户进行聚类,发现具有相似生活方式或行为习惯的用户,并将聚类内的用户相互进行推荐.实验结果表明,DSTra方法不仅具有合理性和有效性,还能够准确并且有效地挖掘出语义行为模式. [1]Keogh E J. Exact indexing of dynamic time warping[C]Proc of VLDB’02. San Francisco: Morgan Kaufman, 2002: 406-417 [2]Chen L, Ozsu M, Oria V. Robust and fast similarity search for moving object trajectories[C]Proc of ACM SIGMOD’05. New York: ACM, 2005: 491-502 [3]Vlachos M, Hadjieleftheriou M, Gunopulos D, et al. Indexing multidimensional time-series[J]. VLDB Journal, 2006, 15(1): 1-20 [4]Hung C C, Peng W C, Lee W C. Clustering and aggregating clues of trajectories for mining trajectory patterns and routes[J]. VLDB Journal, 2015, 24(2): 169-192 [5]Lee J G, Han Jiawei, Whang K Y. Trajectory clustering: A partition-and-group framework[C]Proc of ACM SIGMOD’07. New York: ACM, 2007: 593-604 [6]Li Quannan, Zheng Yu, Xie Xing, et al. Mining user similarity based on location history[C]Proc of Sigspatial GIS’08. New York: ACM, 2008 [7]Zheng Yu, Zhang Lizhu, Ma Zhengxin, et al. Recommending friends and locations based on individual location history[J]. ACM Trans on the Web, 2011, 5(1): 1-44 [8]Parent C, Spaccapietra S, Renso C, et al. Semantic trajectories modeling and analysis[J]. ACM Computing Surveys, 2013, 45(4): No.42 [9]Yan Zhixian, Chakraborty D, Parent C, et al. SeMiTri: A framework for semantic annotation of heterogeneous trajectories[C]Proc of EDBT’11. New York: ACM, 2011: 259-270 [10]Spaccapietra S, Parent C. Adding meaning to your steps[C]Proc of ER’11. Berlin: Springer, 2011: 13-31 [11]Alvares L O, Bogorny V, Kuijpers B, et al. Towards semantic trajectory knowledge discovery[EBOL]. 2007[2015-06-21]. https:uhdspace.uhasselt.bedspacebitstream194218321towards.pdf [12]Liu Hechen, Schneider M. Similarity measurement of moving object trajectories[C]Proc of IWGS’12. New York: ACM, 2012: 19-22 [13]Zheng Yu, Zhang Lizhu, Xie Xing, et al. Mining interesting locations and travel sequences from GPS trajectories[C]Proc of WWW’09. New York: ACM, 2009: 791-800 [14]Zheng Yu, Xie Xing. Learning travel recommendations from user-generated GPS traces[J]. ACM Trans on Intelligent Systems and Technology, 2011, 2(1): No.2 [15]Ying J J C, Lu E H C, Lee W C, et al. Mining user similarity from semantic trajectories[C]Proc of LBSN’10. New York: ACM, 2010: 19-26 [16]Ying J C, Chen H S, Lin K W, et al. Semantic trajectory-based high utility item recommendation system[J]. Expert Systems with Applications, 2014, 41: 4762-4776 [17]Zhu Feixiang. Mining ship spatial trajectory patterns from AIS database for maritime surveillance[C]Proc of ICEMMS’11. Piscataway, NJ: IEEE, 2011: 772-775 [18]Smouse P E, Focardi S, Moorcroft P R, et al. Stochastic modeling of animal movement[J]. Philosophical Trans of the Royal Society of London-Series B: Biological Sciences, 2010, 365(1550): 2201-2211 [19]Li Zhenhui, Ji Ming, Lee J G, et al. MoveMine: Mining moving object databases[C]Proc of ACM SIGMOD’10. New York: ACM, 2010: 1203-1206 [20]Tsai H P, Yang D N, Chen M S. Mining group movement patterns for tracking moving objects efficiently[J]. IEEE Trans on Knowledge and Data Engineering, 2011, 23(2): 266-281 [21]Zheng Kai, Zheng Yu, Yuan N J. On discovery of gathering patterns from trajectories[C]Proc of ICDE’13. Piscataway, NJ: IEEE, 2013: 242-253 [22]Guo Limin, Huang Guangyan, Ding Zhiming. Efficient detection of emergency event from moving object data streams[C]Proc of DASFAA’14. Berlin: Springer, 2014: 422-437 [23]Jeung Hoyoung, Shen Hengtao, Zhou Xiaofang. Convoy queries in spatio-temporal databases[C]Proc of ICDE’08. Piscataway, NJ: IEEE, 2008: 1457-1459 [24]Al-Naymat G, Chawla S, Gudmundsson J. Dimensionality reduction for long duration and complex spatio-temporal queries[C]Proc of SAC’07. New York: ACM, 2007: 393-397 [25]Li Zhenhui, Ding Bolin, Han Jiawei, et al. Swarm: Mining relaxed temporal moving object clusters[J]. Proceedings of the VLDB Endowment, 2010, 3(1): 723-734 [26]Tang L A, Zheng Yu. On discovery of traveling companions from streaming trajectories[C]Proc of ICDE’12. Piscataway, NJ: IEEE, 2012: 186-197 [27]Wu H R, Yeh M Y, Chen M S. Profiling moving objects by dividing and clustering trajectories spatiotemporally[C]Proc of TKDE’12. Piscataway, NJ: IEEE, 2012: 2615-2628 [28]Srikant R, Agrawal R. Mining sequential patterns: Generalizations and performance improvements[C]Proc of the 5th Int Conf on Extending Database Technology. Piscataway, NJ: IEEE, 1996: 3-17 [29]Bergroth L, Hakonen H, Raita T. A survey of longest common subsequence algorithms[C]Proc of SPIRE’00. Piscataway, NJ: IEEE, 2000: 39-48 [30]Zheng Yu, Zhang Lizhu, Xie Xing, et al. Mining interesting locations and travel sequences from GPS trajectories[C]Proc of Int Conf on World Wild Web (WWW 2009). New York: ACM, 2009: 791-800 [31]Zheng Yu, Li Quannan, Chen Yukun, et al. Understanding mobility based on GPS data[C]Proc of ACM Conf on Ubiquitous Computing(UbiComp 2008). New York: ACM, 2008: 312-321 [32]Zheng Yu, Xie Xing, Ma Weiying. GeoLife: A collaborative social networking service among user, location and trajectory[J]. IEEE Data Engineering Bulletin, 2010, 33(2): 32-40 Guo Limin, born in 1984. PhD and lecturer in Beijing University of Technology. Her main research interests include database research and implementation, spatial-temporal data mining, storage, query and analysis of big data, etc. Gao Xu, born in 1980. PhD candidate and lecturer in the Institute of Software, Chinese Academy of Sciences. His main research interests include database and knowledge base systems, and spatial-temporal database. Wu Bin, born in 1982. PhD and research fellow in the Institute of Software, Chinese Academy of Sciences. His main research interests include massive data management and multidimensional data analysis. Guo Haoming, born in 1978. PhD and senior engineer in the Institute of Software, Chinese Academy of Sciences. His main research interests include massive data management and multidimensional data analysis. Xu Huaiye, born in 1987. Master and engineer in the Institute of Software, Chinese Academy of Sciences. His main research interests include massive data management and multidimensional data analysis. Wei Yanyan, born in 1990. Master and assistant engineer in the Institute of Software, Chinese Academy of Sciences. Her main research interests include massive data management and multidimensional data analysis. Wang Zhixin, born in 1989. Master and assistant engineer in the Institute of Software, Chinese Academy of Sciences. Her main research interests include massive data management and multidimensional data analysis. Yan Li, born in 1990. Master and assistant engineer in the Institute of Software, Chinese Academy of Sciences. Her main research interests include networked control system. Tian Mu, born in 1989. Master and assistant engineer in the Institute of Software, Chinese Academy of Sciences. His main research interest includes networked control system. Discovering Common Behavior Using Staying Duration on Semantic Trajectory Guo Limin1, Gao Xu2,3, Wu Bin2, Guo Haoming2, Xu Huaiye2, Wei Yanyan2, Wang Zhixin2, Yan Li2, and Tian Mu2 1(BeijingUniversityofTechnology,Beijing100124)2(InstituteofSoftware,ChineseAcademyofSciences,Beijing100190)3(UniversityofChineseAcademyofSciences,Beijing100049) With the advancement of mobile computing technology and the widespread use of GPS-enabled mobile devices, research on semantic trajectories has attracted a lot of attentions in recent years, and the semantic trajectory pattern mining is one of the most important issues. Most existing methods discover the similar behavior of moving objects through the analysis of sequences of stops. However, these methods have not considered the duration of staying on a stop which affects the accuracy to distinguish different behavior patterns. In order to solve the problem, this paper proposes a novel approach for discovering common behavior using staying duration on semantic trajectory (DSTra) which can easily differentiate trajectory patterns. DSTra can be used to detect the group that has similar lifestyle, habit or behavior patterns. Semantic trajectory patterns of each moving object are mined firstly. Then, the time-weight based pattern similarity measurement is designed. After that, a hierarchical clustering method with pruning strategy is proposed, where each cluster represents the common behavior patterns from moving objects. Finally, experiments on both real-world dataset and synthetic dataset demonstrate the effectiveness, precision and efficiency of DSTra. semantic trajectory; staying duration; semantic trajectory pattern; pattern similarity; moving object clustering 2015-09-01; 2016-11-04 国家自然科学基金项目(61402449,91546111,91646201);中国科学院重点部署项目(KGZD-EW-102-3-3);北京市教委重点项目(KZ201610005009);北京工业大学“17内涵发展定额——引进人才科研启动费” This work was supported by the National Natural Science Foundation of China (61402449, 91546111, 91646201), the Key Deployment Project of the Chinese Academy of Sciences (KGZD-EW-102-3-3), the Key Project of Beijing Municipal Education Commission (KZ201610005009), and the Connotation Development 2017—Introducing the Talents Scientific Research Foundation of Beijing University of Technology. TP311
6 实验结果与分析
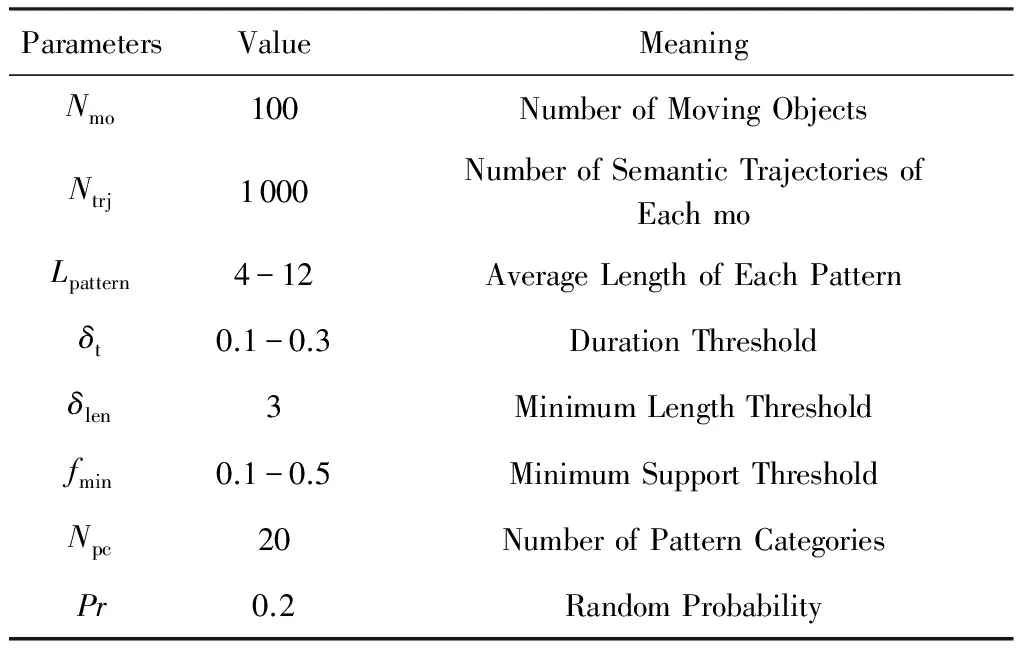
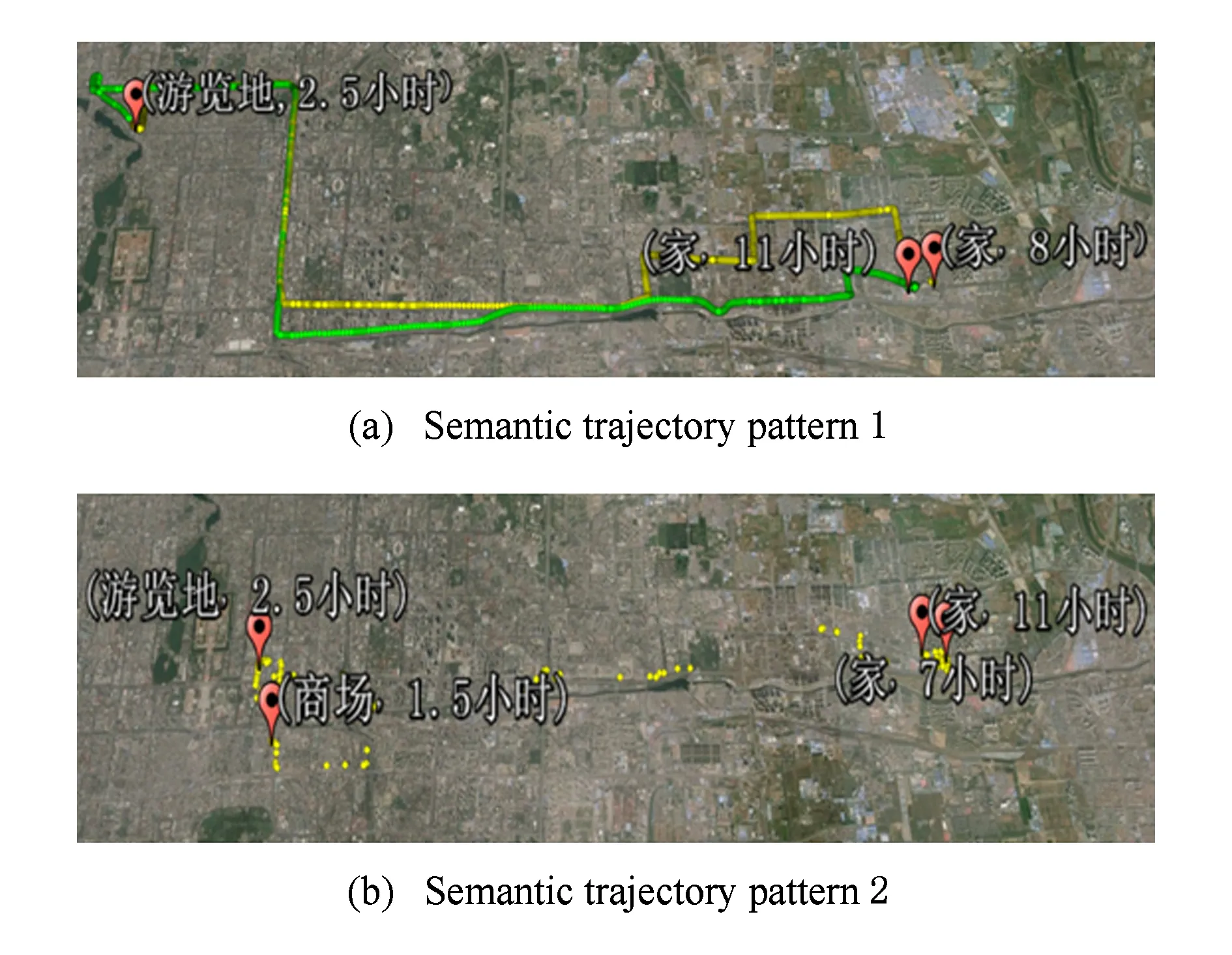
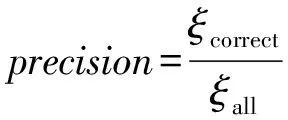

7 结 论









