体系结构内可编程数据平面方法
2017-02-21马久跃余子濠包云岗孙凝晖
马久跃 余子濠 包云岗 孙凝晖
1(中国科学院计算技术研究所 北京 100190)2 (中国科学院大学 北京 100049)(baoyg@ict.ac.cn)
体系结构内可编程数据平面方法
马久跃1,2余子濠1,2包云岗1孙凝晖1
1(中国科学院计算技术研究所 北京 100190)2(中国科学院大学 北京 100049)(baoyg@ict.ac.cn)
随着互联网与云计算的发展,越来越多的应用被从本地迁移到云端,这些应用最终被运行在共享的数据中心.受到数据中心应用复杂并且需求多变特征的影响,传统体系结构中的部分硬件部件(如共享末级缓存、内存控制器、IO控制器等)固定功能的设计不能很好地满足这些混合多应用的场景需求.为满足这类应用场景的需求,计算机体系结构需要提供一种可编程硬件机制,使得硬件功能能够根据应用需求的变化进行调整.提出了一种可编程数据平面方法:通过在现有硬件部件中增加可编程处理器,使用执行固件代码的方式对硬件的请求进行处理,并通过更新数据平面处理器固件的方式实现硬件功能的扩展.该方法在FPGA原型系统中进行验证,其结果表明,该方法并没有给系统性能带来严重的影响,只使用有限的资源即可为硬件增加更为灵活的可编程能力,使其能够适应应用需求复杂多变的场景.
可编程;处理器;数据中心;服务器;服务质量
当前数据中心正面临着资源利用率与服务质量相冲突的挑战.使用虚拟化、容器等负载融合的方法将多个应用运行在同一服务器中,可以有效地提高服务器的资源利用率;但是在这一过程中,无管理的软硬件资源共享带来了不可预测的性能波动.为了保障延迟敏感型应用的服务质量,在共享的数据中心环境下,管理员或开发者通常会为这些应用独占或过量分配资源,造成了非常低的数据中心资源利用率,只有6%[1]~12%[2].
针对这种由于共享软硬资源竞争所带来的干扰问题,一些现有工作在软件层次,通过分析应用的竞争点,使用调度[3-6]、隔离[7-8]等方案尝试解决该问题.但由于数据中心中海量应用的特点,对海量的应用组合进行竞争点的判别与消除是不切实际的;同时由于数据中心应用不断变化的动态性特点,资源竞争点也是随时在发生变化,因此这些软件技术很难在通用数据中心发挥作用.另一些研究提出在硬件层次上实现资源隔离与划分(如末级缓存容量划分[9-13]、内存通道划分[14-15]等),但由于缺少统一的接口,这些工作通常只关注单一的资源,而没有考虑到资源之间的相关联;同时由于当前体系结构在共享硬件层次的应用语义信息缺失,使得其在硬件层次无法区分不同的应用需求,造成在硬件层次很难实现硬件资源的细粒度管理.
构建高效的数据中心需要一种软硬件协调的机制,而传统计算机体系结构所提供的指令集架构(ISA)抽象不能满足这一需求,正如白皮书《21st Century Computer Architecture》[16]中所指出的:我们需要一种高层接口将程序员或编译器信息封装并传递给下层硬件,以获得更好的性能或实现更多应用相关的功能.之前的工作PARD[17]提出了一种资源管理可编程体系结构,通过在计算机内部请求附加应用标签,在共享部件中实现应用区分;并通过控制平面对来自不同应用的请求进行不同的处理,实现在同一服务器上为不同应用提供区分化服务;同时提供集中式的资源管理平台,实现对不同部件的资源使用进行统一管理.但它使用的基于表的控制平面设计并不能很好地适应应用需求的变化,这种设计只提供了对硬件已有功能的配置,需要在硬件部件上静态实现这些功能并对外提供配置接口,且功能一旦实现无法根据应用的需求进行调整.
然而在实际场景中,应用会对底层的硬件不断提出不同的需求,如更换Cache控制器的缓存替换策略、更改内存控制器的地址映射方式与调度策略、为IO控制器增加数据加密或压缩的功能等.当前的这种静态的数据平面设计不能很好地满足这类需求,需要更换硬件才能实现,而这需要很长的周期,无法适应数据中心这种需要不断变化的场景.
在学术界中,已有一些研究通过在硬件上增加可编程机制,实现根据应用需求对硬件策略进行调整的功能.如体系结构领域已经提出在内存控制器[18-20]、Cache与一致性协议[21-24]上使用可编程逻辑来提供更灵活的功能,但这些只考虑了如何为单一应用提供更多的可编程支持,不能很好地在数据中心这种多应用场景下使用.在网络领域中也有工作提出在SDN数据平面上增加可编程逻辑的方案,以提高SDN数据平面的可编程性[25-28],通过数据平面的重编程,达到对更多数据包的检测与处理的目的.PARD的一个重要贡献是将网络概念引入计算机体系结构,本文希望将SDN数据平面中这种高级的可编程机制引入到计算机体系结构中,实现更灵活的控制.
综上,本文提出了一种体系结构内可编程数据平面架构,通过在硬件部件中增加处理器逻辑,使用执行固件代码的方式对硬件部件的请求进行处理,并通过更新数据平面处理器固件的方式实现数据平面功能的扩展,以增强计算机体系结构的可编程灵活度,使其能够适应更加复杂多变的数据中心应用场景.
1 研究背景与关键问题
1.1 PARD与区分化服务
PARD实现区分化服务(DiffServ)的关键机制是:1)使用标签区分应用;2)控制平面与数据平面分离,将请求处理与策略控制分离;3)集中式的策略管理与反馈机制.为实现以上3个关键机制,PARD体系结构由4个部分组成,如图1所示:
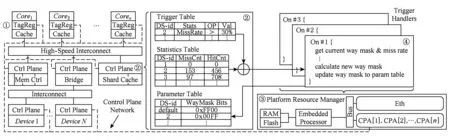
Fig. 1 PARD architecture overview[17]图1 PARD总体架构图[17]
① 标签机制.为了使硬件资源能够区分来自不同应用的请求,PARD为给每个应用分配一个区分服务标识符(DS-id),同时在CPU核心和IO设备等所有请求源中增加一个DS-id标签寄存器.这些寄存器用于给Cache访问请求、访存请求、DMA请求以及中断请求附加上标签.请求在发出源附加上DS-id标签后,这个标签将跟随请求在整个体系结构中传播.
② 可编程控制平面.为每个共享硬件资源增加一个可编程控制平面,以利用请求中所包含的DS-id标签实现区分化服务.当硬件接收到请求后,控制平面首先会根据请求的DS-id对其进行处理,并产生发送到下一级硬件的请求,同时将DS-id附加到新的请求上.由于不同硬件的行为差别很大,它们对DS-id的使用方式也不同,例如Cache使用DS-id实现容量划分,内存和IO控制器使用其实现带宽分配.PARD为不同的硬件部件提供了一个通用的控制平面结构,该控制平面结构包括3个由DS-id索引的控制表:参数表(parameter table),用于保存资源分配策略;统计表(statistics table),用于记录资源使用信息;用于存放性能触发条件的触发表(trigger table).除此之外,该控制平面还包括一个可编程接口和一个连接到集中式平台资源管理模块(PRM)的中断线.
③ 平台资源管理模块(PRM).与传统服务器中的IPMI[6]类似,PARD包含一个集中式平台资源管理模块来连接所有的控制平面和标签寄存器(参见图1中的虚线).PRM是一个包含处理器、内存、Flash存储、以太网适配器以及多个控制平面适配器(control plane adaptor, CPA)的嵌入式SoC系统.其上运行基于Linux的固件,将控制平面抽象为设备文件树,使用基于文件树的统一编程接口来访问控制平面,并为管理员提供了“Trigger→Action”编程方法来部署资源管理策略.
④ 可编程方法.为了方便管理员通过对控制平面进行编程来部署资源管理策略,PARD提供了一种“Trigger→Action”编程方法.如图2所示,对于一个DS-id,可以定义多个“Trigger→Action”规则,每个规则针对特定的硬件资源(如基于Cache缺失率等性能指标),并且被存放在触发表中;触发动作可以使用任何语言来编写,实现策略调整.这些规则被安装在PRM固件中,在PRM中可以对所有的控制平面进行管理,因此触发规则和动作可以被指定给不同的资源.例如,如果一个触发规则被设置为监控内存带宽,由于内存带宽的变化可能与Cache缺失率有关,因此它的动作可以定义为Cache容量调整,通过调整Cache容量来影响Cache缺失率,进一步反馈到内存带宽.数据中心管理员负责根据SLA为不同的资源管理策略预先定义一系列动作和触发规则,用户可根据他们的QoS需求选择适当的SLA.
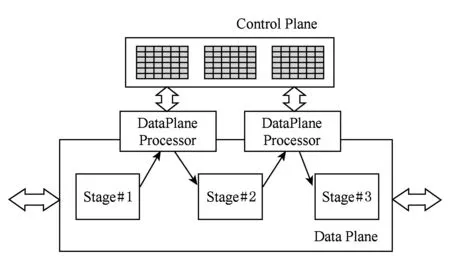
Fig. 2 Programmable data plane architecture图2 可编程数据平面架构
1.2 可编程数据平面抽象
在PARD中,计算机的硬件部件被抽象为数据平面与控制平面2部分,其中数据平面用于执行数据操作,而控制平面用于对数据平面的策略进行管理.以缓存控制器为例,数据平面中包含用缓存数据的DataArray与记录缓存内容的TagArray,以及替换策略的实现,其控制平面包含替换策略的参数、统计信息等;对于内存控制器而言,数据平面用于接收上层访存请求,并将其转换为内存地址,发送到内存阵列中,其控制平面用于控制地址映射与访存调度策略.从以上2个例子我们可以发现,PARD控制平面的可编程主要体现在其对数据平面所提供功能的控制,而数据平面所提供的功能在其设计完成后即已确定,如果需要增加额外的功能,则需要对数据平面重新进行设计,并对控制平面暴露相应的接口.因此,控制平面的可编程能力受到数据平面所能提供功能的限制.
另一方面,PARD中的“Trigger→Action”机制在响应时间上存在瓶颈:每当触发条件发生后,需要经过控制平面网络将该事件传递到PRM,由运行在PRM中的软件代码来更新策略,并通过控制平面网络写回到控制平面中.由于受到控制平面网络延迟以及PRM软件代码延迟的影响,该机制并不能达到特别高的响应速度;同时并非所有的触发条件发生后都需要在PRM进行全局处理,完全可以预定义一些动作,在控制平面本地完成处理.
为解决以上2个问题,本文提出的可编程数据平面架构如图2所示.在PARD中所提出的控制平面数据平面模型基础上,在数据平面中增加了多个可编程处理器,连接数据平面中其他的逻辑部分,并通过其中的固件代码对数据进行处理.控制平面依然使用3张控制表作为对外访问的接口,通过控制平面网络与集中式的平台资源管理模块通信.由于数据平面部件能够执行代码,因此可以使用软件代码来实现反馈调节,因此触发逻辑已经从控制平面中被移除.
要实现以上可编程数据平面架构,需要解决3个问题:1)如何为不同硬件部件的数据平面增加处理器逻辑;2)处理器如何设计,如何与控制平面进行通信;3)处理器逻辑如何编程.本文后续章节将针对以上3个问题进行分别阐述.
2 可编程数据平面
在讨论数据平面处理器设计前,我们首先以内存控制器和Cache控制器为例,讨论可编程数据平面的设计.
2.1 内存控制器
当前的处理器芯片通常会集成2~4个独立的内存控制器,每个控制器使用独立的内存通道.每个内存通道连接到多个可并行访问的rank,而每个rank又是由多个共享地址与数据总线的二维存储阵列(bank)组成.内存控制器的主要工作就是接收上游的读写请求,并将其转换为下游的DRAM命令,完成数据传输.以内存控制器作为数据平面,可以在地址映射和访存调度2个位置增加可编程功能.
1) 地址映射.地址映射分为2部分,首先是通过处理器的页表机制实现了从虚拟地址空间到物理地址空间的映射,虚拟化场景的出现在这一基础上又增加了扩展页表EPT机制,额外增加了一级虚拟机物理地址到主机物理地址的映射.之后是内存控制器将处理器的物理地址空间映射到DRAM阵列中,通常使用静态地址映射,通过某种固定的规则将物理地址空间映射到DRAM的bank,row,column中.
在PARD架构中,通过在内存控制器前增加MMU模块,通过映射表将不同应用标签的访存请求进行隔离.但这种方式只实现了一种固定的地址映射机制,即只能进行连续的大块地址分配,无法实现EPT等技术所支持的细粒度内存空间管理.为解决这一问题,可以将静态的MMU模块替换为一个处理器,能够在其中编写软件代码实现地址空间的映射.通过这种方式除了可以完成PARD中MMU的功能外,还可以实现更细粒度的空间管理,也可以实现现有虚拟化平台中常见的基于内容的内存空间压缩机制.除此之外,该处理器还可以通过对请求数据进行额外处理,以在硬件层面实现更复杂的如数据加密、敏感词过滤等高级功能.
2) 访存调度.在PARD的内存控制平面中,只实现了简单的基于优先级的访存调度,可以通过增加处理器的方式实现更为灵活的调度策略;同时也可以像PARDIS[18]工作一样,将处理器加入到内存控制器内部的请求调度模块中,根据不同应用的需求实现不同的DRAM调度策略.
2.2 Cache控制器
Cache控制器的功能是对到达的请求进行缓存操作,使用不同的替换策略对数据访问热度进行预测,以提高访存命中率和系统性能.其核心主要包括TagArray,DataArray和替换策略3个部分.以Cache控制器作为数据平面,可以在容量划分与替换策略2个角度增加可编程功能.
1) 容量划分.传统的Cache并没有提供容量划分功能,因此不同应用在共享Cache上运行会造成不同程度的干扰.Intel最新提出的CAT技术[29]在Cache上增加了按路的缓存容量划分机制.但按路划分并非适合所有的应用,可以通过使用处理器替换固定的SetWay映射方式,根据应用实现更为灵活的缓存容量划分方式.
2) 替换策略.与容量划分的需求类似,不同应用的访存模式不同,固定的缓存替换策略并不能很好地适应所有应用.因此使用处理器与软件替换策略,与PARD的应用区分机制结合,可以实现更为灵活高效的缓存.
3 数据平面处理器体系结构
由于数据平面处理器位于请求处理的关键路径上,为了保障系统的性能不受影响,需要从以下3个方面进行考虑:
1) 处理器需要执行一系列指令才能完成对请求的处理,因此处理器需要工作在比其所在硬件部件更高频率,以满足硬件部件的性能需求;
2) 处理器的固件代码执行需要确定性,因此不能使用cache结构,而是使用scratchpad memory代替;
3) 由于高频需求,因此处理器功能要尽可能简单,一些必需的复杂逻辑(如数据压缩与加密等)通过外部加速器的方式进行扩展.
基于以上需求,我们选择使用RISC作为数据平面处理器的基础架构,如图3所示.我们首先对传统RISC架构进行精简,只保留其基本功能,以保证其频率需求;同时增加scratchpad memory作为其指令与数据存储,增加请求缓存接口用于接入硬件设备中,增加控制平面接口用于连接控制平面.
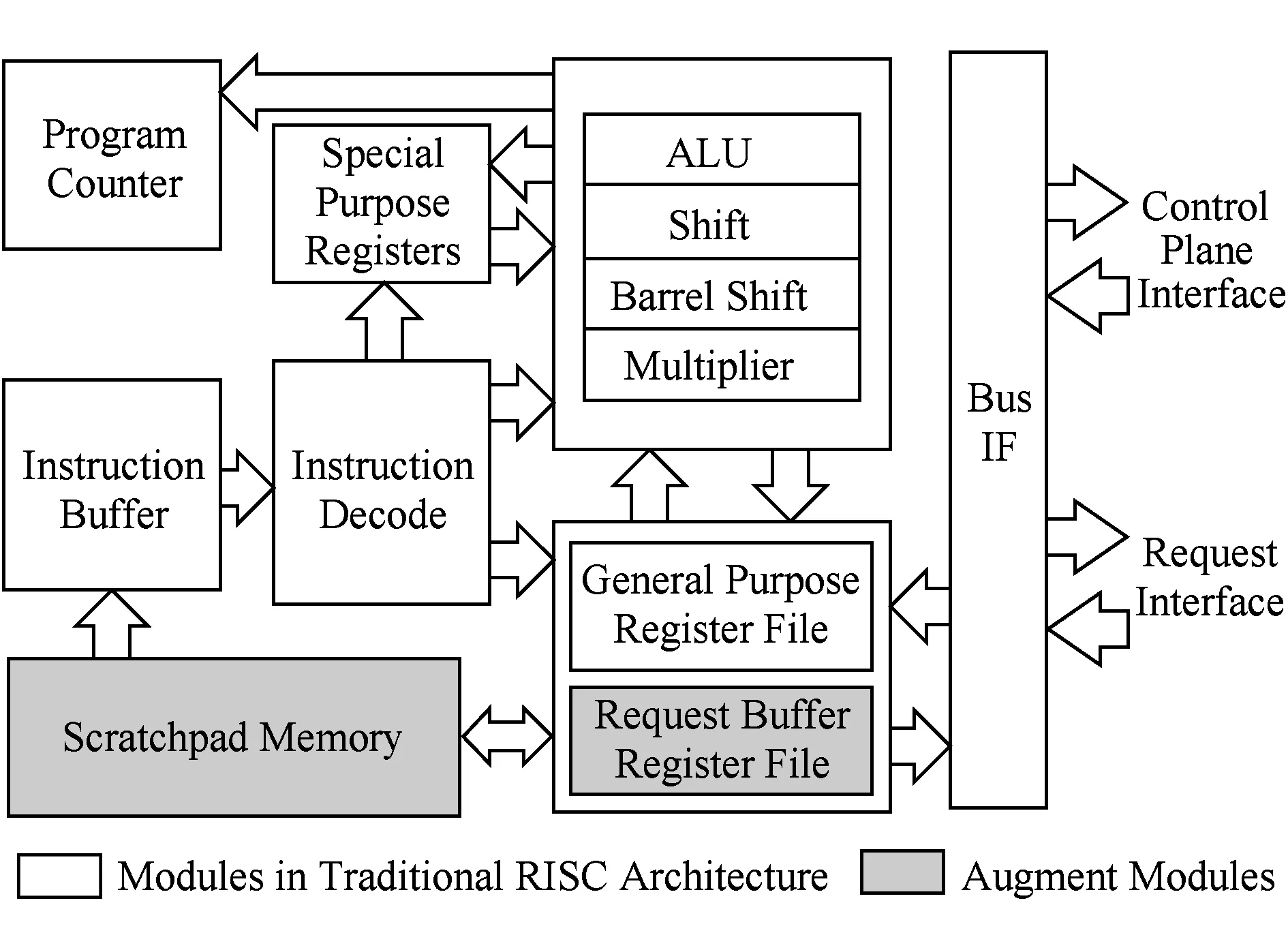
Fig. 3 Data plane processor block diagram图3 数据平面处理器结构图
从第2节可知,对于内存控制器与Cache,该处理器的主要工作包括:对请求进行调度、地址变换,对数据进行处理,生成控制信号(如Cache缓存与替换).要完成以上工作,该处理器需要具备基本的处理器功能外,还需要在数据类型、存储模型和指令上进行扩展.
3.1 数据类型
数据平面处理器中执行的算法代码大都只是对输入的请求进行处理,因此我们只有“无符号整数”和“请求”2种数据类型,如图4所示.无符号整数的长度与处理器的位宽相同,都被设置为其所属硬件的位宽,以节约请求处理时位宽转换的开销,保障请求处理的效率.
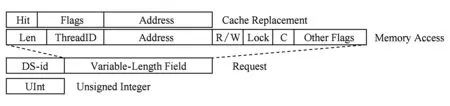
Fig. 4 Data types supported by the data plane processor图4 数据平面处理器支持的数据类型
“请求”是一个变长数据类型,其中包含了固定的16位应用标签(DS-id)以及变长的请求数据.以访存请求为例,其中包含请求地址、长度、线程号、读写类型、锁与缓存状态等其他一些标志位;对于Cache替换请求,其中包含了请求地址、HitMiss标记以及其他一些标志位等信息.图4给出了访存请求以及Cache替换请求类型的示例.数据平面处理器本身并不关心请求类型中具体每个位的意义,而只是将其做一个整体进行处理,对每个域的解析或修改由其运行的固件代码完成.
3.2 存储模型
数据平面处理器中程序员可见的存储结构包含寄存器、请求缓存、scratchpad memory、IO地址空间4部分.与传统的RISC架构相同,数据平面处理器包含32个通用寄存器(r0~r31),用于进行算数逻辑运算,其中r0是常数0;除此之外,增加了4个用于保存“请求”类型数据的请求寄存器(s0~s3),可以通过请求缓存操作指令(rbget和rbput,参见3.3节),将请求输入队列中的请求读取到该寄存器,或将该寄存器中的请求加入到请求输出队列中;请求寄存器不能直接参与算术逻辑计算,需要先将其部分数据读取到通用寄存器后才能执行计算;请求寄存器之间可以直接进行数据交换.处理器执行的固件代码与数据保存在scratchpad memory中,需要用户自行管理.控制平面被映射为数据平面处理器的外设,提供处理器的固件代码ROM以及处理器的对外接口.
3.3 指令集
数据平面处理器使用RISC标准的算数逻辑、控制流和访存指令,并在其基础上额外增加了请求缓存操作指令,如表1所示:

Table 1 Instruction Extension for Data Plane Processor
请求缓存分为2部分:1)输入缓存;2)输出缓存.其中输入缓存既可作为FIFO操作,也可基于DS-id进行内容寻址;输出缓存只能作为FIFO操作.用于请求缓存操作的指令如图5所示,指令rbput可以将指定请求寄存器中的请求添加到输出缓存队列末尾.指令rbget有2种使用方式:1)将输入缓存作为FIFO,取出队列头的请求到请求寄存器;2)通过DS-id对请求进行筛选,取出第1个满足应用标签的请求到请求寄存器.指令rbcp用于在请求寄存器之间传送数据.指令mfrb用于将请求寄存器中的部分数据传送到通用寄存器;指令mtrb与之相反,用于将通用寄存器的数据传送到请求寄存器指定的位置.
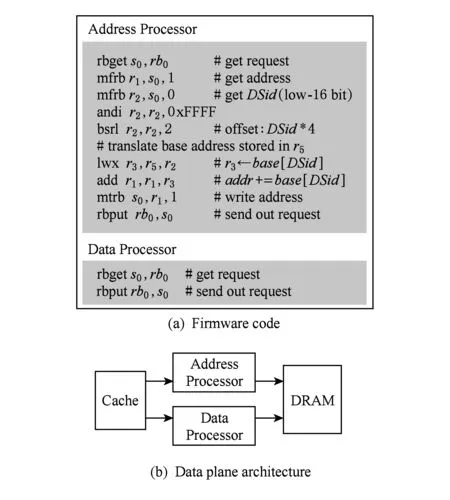
Fig. 5 Illustrative example of range address mapping图5 段式地址映射示例
3.4 固件代码示例
本节将以3段不同功能的固件代码为例,介绍数据平面处理器的编程方法.
3.4.1 内存地址映射
本示例用于实现PARD的内存控制器控制平面所提供的地址映射功能,该功能只需要对访存请求的地址进行修改,而请求的数据无需修改,我们将地址与数据分开由2个处理器进行处理,如图5所示.对于数据处理器,其固件代码只使用rbgetrbput指令对请求进行转发.地址处理器首先需要使用rbget指令获取当前请求到请求寄存器,并使用mfrb指令将其中的地址与DS-id读取到通用寄存器;而后通过查表的方式获得该请求对应的映射目的地址的基址,对请求地址进行变换,并使用mtrb指令将变换后的地址写回到请求寄存器;最后通过rbput指令将新的访存请求从处理器中送出,完成地址映射功能.
3.4.2 访存数据加密
本示例实现访存数据加密功能,由于数据加密操作通常需要耗费很长的时间,而且我们的数据平面处理器提供的指令集并不足以完成该操作.因此我们在外部实现了硬件AES加密模块,并通过请求接口将其连接到数据平面处理器上,该结构如图6所示.基于该结构,数据处理器只需要将数据发送到AES模块并等待其完成加密,将加密后的数据送出处理器即可.数据解密与加密过程类似,只需将数据发送到连接有解密模块的请求接口即可.
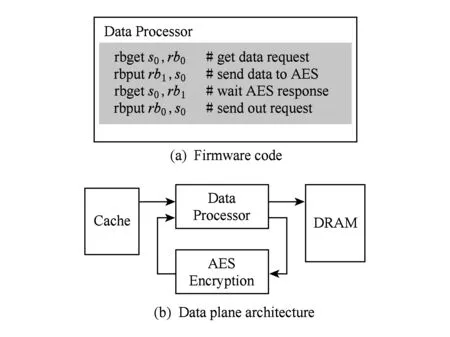
Fig. 6 Illustrative example of memory access encryption图6 访存数据加密示例
3.4.3 缓存替换策略
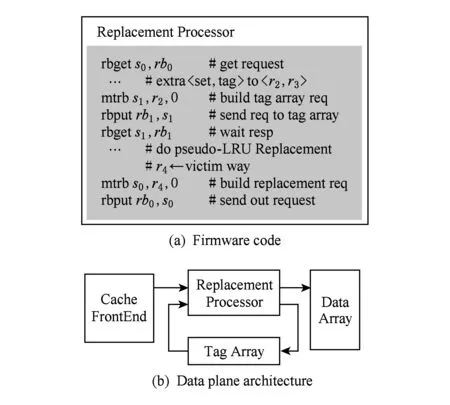
Fig. 7 Illustrative example of cache replacement policy图7 缓存替换策略示例
本示例实现缓存替换策略功能,使用可编程处理器替换Cache中原有的LRU模块,使用软件实现基于二叉树的伪LRU替换策略,如图7所示.处理器固件代码工作流程如下:1)处理器收到Cache前端的请求以及HitMiss信息,如果缓存命中则无需任何额外操作;2)对于缓存缺失的请求,首先从地址中解析出tag与set信息,并将解析后的set地址发送到TagArray,等待其返回该set的信息;3)根据TagArray返回的set信息以及内部的数据结构生成替换目标;4)将替换目标送出处理器.
4 原型实现
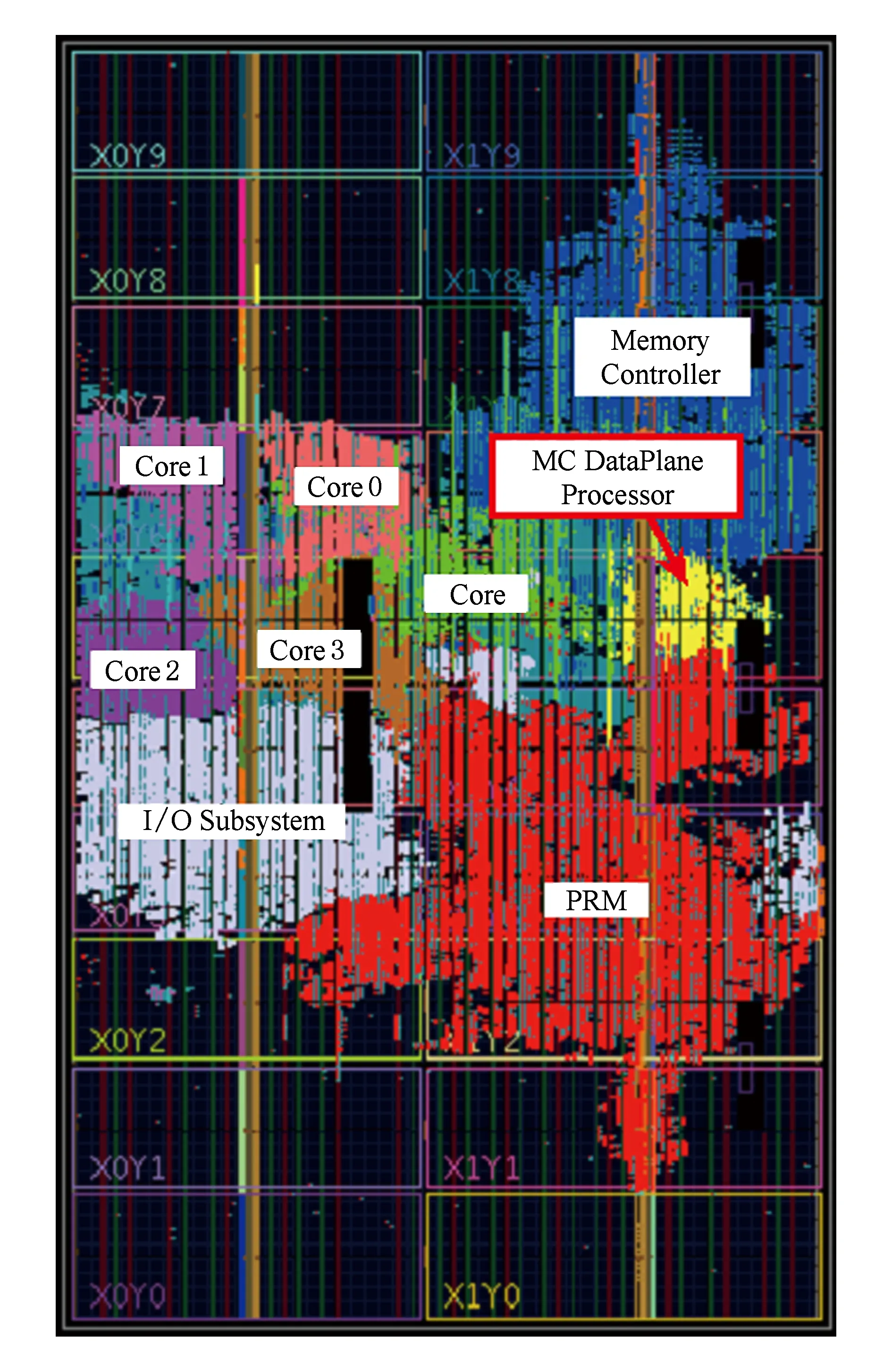
Fig. 8 Post placement&routing results (xc7vx690t device)图8 FPGA原型系统的布局布线结果(xc7vx690t设备)
为了验证可编程数据平面的思路,我们在Xilinx VC709(FPGA芯片型号为xc7vx690tffg1761-2)平台上搭建了一个PARD的原型系统,该原型系统使用4个MicroBlaze[30]作为处理器核,它们共享末级缓存和内存控制器,使用AXI总线实现互连,CPU与共享末级缓存工作在133 MHz频率,内存总线工作在100 MHz频率.系统的IO子系统包含2个以太网适配器和4个串口控制器;以太网适配器通过千兆光纤连接到外部交换机,4个串口控制器在FPGA内部连接到PRM的虚拟串口,通过虚拟PRM的虚拟串口与外部通信.PRM是基于MicroBlaze的SoC系统,使用I2C总线作为控制平面网络连接到所有的控制平面,通过以太网与串口与外部进行通讯.该原型系统布局布线后的结果如图8所示,其实现了PARD所描述的全硬件虚拟化功能,通过PRM中提供的固件将系统划分为4个独立的逻辑域,并可运行未修改的Linux操作系统.
我们修改了该原型系统的内存控制器部分,在其中增加了数据平面处理器(图8箭头所标识的区域),通过软件代码的方式实现内存地址映射功能.为简化实现,我们使用精简配置的MicroBlaze实现数据平面处理器的功能.
1) 将MicroBlaze配置为精简模式,去除所有与数据平面处理器无关的可选指令,如硬件FPU、乘法器除法器、扩展指令等;关闭MMU、Cache、中断异常等高级功能,只保留最基本的算术逻辑部分.通过精简配置,MicroBlaze系统的频率从133 MHz提高到了250 MHz.
2) 使用MicroBlaze提供的Stream Link接口作为数据平面处理器的请求接口.由于目前MicroBlaze的Stream Link接口是固定的32位AXIS接口,我们将多个Stream Link合并使用作为一个请求接口.
3) MicroBlaze提供putget指令实现对Stream Link的接口,通过合并多个put或get指令即可实现请求缓存指令rbput和rbget.如表2所示,“请求”类型的长度为12 B,我们使用3个MicroBlaze通用寄存器(r10~r12)作为请求寄存器,通过使用getput指令操作Stream Link接口fsl0~fsl2,实现rbget和rbput的功能.

Table 2 Request Buffer Instructions Implemented by MicroBlaze
对于该原型系统,另一个需要考虑的问题是如何对数据平面处理器的固件代码进行更新,以实现“可编程”的功能.对数据平面处理器固件代码更新可以分为兼容性更新与非兼容性更新.其中“兼容性”是指更新前后的代码是否对数据平面的功能产生更改;对于非兼容性更新,需要首先关闭系统中所有正在运行的逻辑域,并在数据平面处理器固件更新完成后重新启动逻辑域.对于兼容性更新,系统可实现无中断运行,但需要对数据平面处理器与硬件的接口处进行额外的处理,如图9所示,在收到更新固件命令后进入Drain状态,阻止请求继续发送到数据平面处理器,等待数据平面处理器处理完全部请求,并将请求队列排空后,使处理器进入Isolated隔离状态;之后完成对固件代码的更新,新的固件代码开始运行后,开始进行初始化操作,其中包括旧固件的状态数据迁移步骤;在所有的初始化操作完成后,处理器恢复到就绪状态,重新开始处理请求,至此完成数据平面处理器固件代码的兼容性更新操作.

Fig. 9 Compatible firmware update for data plane processor图9 数据平面处理器兼容性固件更新状态图
5 性能评估
通过使用可编程处理器来替代硬件逻辑,可以极大增强设备的可编程能力,但由于处理器位于硬件请求处理的关键路径,我们需要对其性能与资源开销进行评估,以确保其不会对系统性能与开销造成严重的影响.本节以内存控制器的可编程数据平面为例,对其可编程数据平面的资源开销进行分析;并通过stream与memcached两种应用负载来评估其对系统性能的影响;最后我们分析了可编程数据平面架构对PARD体系结构中“Trigger→Action”机制反馈时间的优化.
5.1 系统延迟
与硬件逻辑实现相比,可编程处理器在系统中引入了额外的开销,我们通过内存控制器上增加本文所提出的可编程数据平面架构,实现与PARD中相同的地址映射功能来验证该架构对系统延迟的影响.
系统延迟的大小与应用和固件功能相关,因此我们选择与硬件实现完全相同的地址映射功能,并使用内存带宽测试工具stream和内存键值存储应用memcached对系统的延迟进行评估.由于受到FPGA设备的限制,在我们的平台下MicroBlaze软核处理器最高只能工作在250 MHz的频率,我们选择了100 MHz150 MHz200 MHz250 MHz四种不同的频率对系统延迟进行了评估.
5.1.1 访存带宽
在PARD的控制平面设计中,实现地址映射的控制表并没有引入额外的延迟开销,其性能与直接访问内存控制器相同,受到MicroBlaze处理器性能的限制,我们能够得到25.1 MBps的访存带宽,如图10所示:

Fig. 10 Memory bandwidth of different processor configurations图10 访存带宽对比
由于地址映射功能只需要对请求地址进行操作而无需对数据进行修改,因此我们实现了一个简化版本的数据平面处理器(工作在100 MHz频率),该处理器只对地址请求进行处理,数据绕过处理器直接发送到内存控制器.在使用该设计后测得的访存带宽是21.5 MBps,与非处理器实现相比并没有特别明显的下降.
为了使数据平面处理器对访存数据也能够进行操作,我们将数据请求也发送到处理器进行处理,在100 MHz频率下测得的访存带宽出现了明显的下降,只有13 MBps.进一步提高数据平面处理器的工作频率,带宽基本呈线性上升,在150 MHz时能够得到15 MBps的访存带宽;在200 MHz时,访存带宽提高到了20 MBps;而在250 MHz时,访存带宽达到了22.5 MBps.由于受到FPGA硬件的限制,我们无法实现更高频率的数据平面处理器,但数据平面处理器的功能十分精简,如果使用ASIC工艺,可以得到更高的频率,因此其处理器的性能不会成为系统的瓶颈.
5.1.2 memcached 性能
访存带宽只能作为系统性能的一个评估指标,系统运行时的实际开销要与应用相关联.图11给出了memcached在同硬件配置下的性能变化,与访存带宽的结果类似,memcached的性能与数据平面处理器频率相关,当工作在100 MHz频率时,只能得到568RPS的性能,但如果处理器频率提升到250 MHz,其性能(618RPS)与使用控制表的方案(628RPS)基本接近.

Fig. 11 Performance of memcached benchmark图11 memcached性能
5.2 资源开销
可编程数据平面的资源开销主要在处理器逻辑及其使用的scratchpad memory两个方面.在通过配置精简后,MicroBlaze处理器所占用的资源量大大减少,其Slice(LUT和FF)占用只有完整配置的50%左右,scratchpad memory的容量由固件代码的大小决定,当前的实现中我们为其保留了32 KB的容量,在FPGA中占用了8个RAMB36资源.原型系统中主要的硬件部件与可编程数据平面占用的FPGA资源如表3所示.可以看到可编程数据平面在只占用有限的FPGA资源下,为硬件增加了更为灵活的可编程能力.
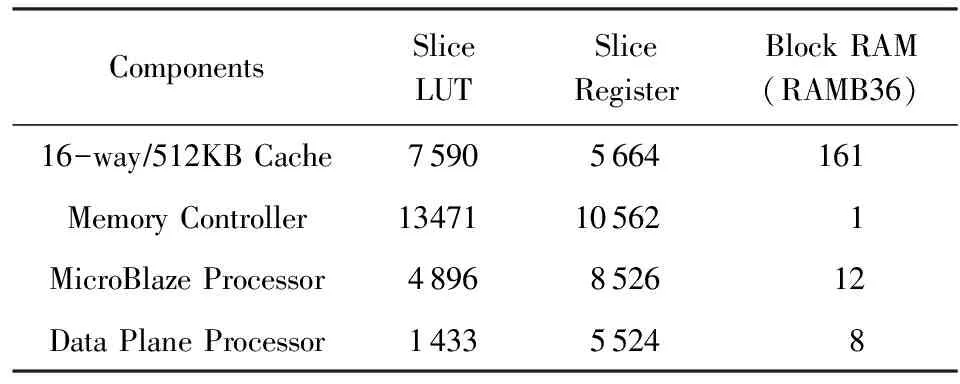
Table 3 Resource Consumption for xc7vx690t Device
5.3 反馈时间
在PARD体系结构基于表的控制平面设计中,“Trigger→Action”机制的反馈时间可以主要分为Trigger事件检测、控制平面网络传送事件消息、PRM处理事件以及控制平面网络传送Action的参数修改4个阶段.其中第1阶段由控制表硬件逻辑完成,可以在有限的时钟周期内完成.第2阶段和第4阶段由于需要使用控制平面网络传送数据,因此其响应时间与控制平面网络的速率相关.在我们目前的原型系统中,由于使用了I2C总线作为控制平面网络,其最高速率为1 Mbps,对于一个32 b的事件消息以及一组96 b的参数修改消息,至少需要128 μs完成数据传输,如果需要传输更多的消息则需要消耗更长的时间.第3阶段PRM处理中,需要经过控制平面驱动、内核、用户态3个层次进行处理,也需要消耗一定的时间.在采用可编程数据平面架构后,对Trigger事件的反馈调节代码可以直接在数据平面的固件代码中完成,消除了PARD原有设计中需要经过PRM进行统一处理的时间消耗,实现更快速的反馈响应.
6 总 结
本文展示了一种计算机体系结构内可编程数据平面架构,通过在计算机硬件设备中增加可编程处理器,通过可编程处理器的固件代码完成对硬件请求的处理,使硬件设备具备了更加灵活的可编程特性.我们的实验结果表明,这种可编程数据平面的设计并没有增加特别大的性能开销,可以用于在数据中心等需求不断变化的场景中,根据应用需要的变化调整硬件实现策略以达到最优效果.
[1]Kaplan J M, Forrest W, Kindler N. Revolutionizing data center energy efficiency[R]. New York: McKinsey & Company, 2008
[2]Goasduff L, Pettey C. Gartner says efficient data center design can lead to 300 percent capacity growth in 60 percent less space[OL]. 2010[2016-02-26]. http:www.gartner.comnewsroomid1472714
[3]Delimitrou C, Kozyrakis C. Paragon: QoS-aware scheduling for heterogeneous datacenters[C]Proc of the 18th Int Conf on Architectural Support for Programming Languages and Operating Systems (ASPLOS’13). New York: ACM, 2013: 77-88
[4]Delimitrou C, Kozyrakis C. Quasar: Resource-efficient and QoSaware cluster management[C]Proc of the 19th Int Conf on Architectural Support for Programming Languages and Operating Systems (ASPLOS’14). New York: ACM, 2014: 127-144
[5]Leverich J, Kozyrakis C. Reconciling high server utilization and sub-millisecond quality-of-service[C]Proc of the 2014 EuroSys Conf. New York: ACM, 2014: 4
[6]Mars J, Tang Lingjia, Hundt R, et al. Heterogeneity in “homogeneous” warehouse-scale computers: A performance opportunity[J]. Computer Architecture Letters, 2011, 10(2): 29-32
[7]Liu Lei, Cui Zehan, Xing Mingjie, et al. A software memory partition approach for eliminating bank-level interference in multicore systems[C]Proc of the 21st Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2012: 367-376
[8]Liu Lei, Li Yong, Cui Zehan, et al. Going vertical in memory management: Handling multiplicity by multi-policy[C]Proc of the 41st Annual Int Symp on Computer Architecture (ISCA’14). Piscataway, NJ: IEEE, 2014: 169-180
[9]Sanchez D, Kozyrakis C. The ZCache: Decoupling ways and associativity[C]Proc of the 43rd Annual IEEEACM Int Symp on Microarchitecture (MICRO’43). Los Alamitos, CA: IEEE Computer Society, 2010: 187-198
[10]Sanchez D, Kozyrakis C. Vantage: Scalable and efficient fine-grain cache partitioning[C]Proc of the 38th Annual Int Symp on Computer Architecture (ISCA’11). New York: ACM, 2011: 57-68
[11]Qureshi M K, Patt Y N. Utility-based cache partitioning: A low-overhead, high-performance, runtime mechanism to partition shared caches[C]Proc of the 39th Annual IEEEACM Int Symp on Microarchitecture (MICRO’39). Los Alamitos, CA: IEEE Computer Society, 2006: 423-432
[12]Kasture H, Sanchez D. Ubik: Efficient cache sharing with strict QoS for latency-critical workloads[C]Proc of the 19th Int Conf on Architectural Support for Programming Languages and Operating Systems (ASPLOS’14). New York: ACM, 2014: 729-742
[13]Jia Yaocang, Wu Chenggang, Zhang Zhaoqing. Program’s performance profiling optimization for guiding static cache partitioning[J]. Journal of Computer Research and Development, 2012, 49(1): 93-102 (in Chinese)(贾耀仓, 武成岗, 张兆庆. 指导cache静态划分的程序性能profiling优化技术[J]. 计算机研究与发展, 2012, 49(1): 93-102)
[14]Muralidhara S P, Subramanian L, Mutlu O, et al. Reducing memory interference in multicore systems via application-aware memory channel partitioning[C]Proc of the 44th Annual IEEEACM Int Symp on Microarchitecture (MICRO’44). New York: ACM, 2011: 374-385
[15]Jia Gangyong, Li Xi, Wan Jian, et al. A memory partition policy for mitigating contention[J]. Journal of Computer Research and Development, 2015, 52(11): 2599-2607 (in Chinese)(贾刚勇, 李曦, 万健, 等. 一种减少竞争的内存划分方法[J]. 计算机研究与发展, 2015, 52(11): 2599-2607)
[16]Computing Community Consortium (CCC). 21st century computer architecture: A community white paper[OL]. 2012[2016-02-26]. http:cra.orgcccdocsinit21stcentur yarchitecturewhitepaper.pdf
[17]Ma Jiuyue, Sui Xiufeng, Sun Ninghui, et al. Supporting differentiated services in computers via programmable architecture for resourcing-on-demand (PARD)[C]Proc of the 20th Int Conf on Architectural Support for Programming Languages and Operating Systems (ASPLOS’15). New York: ACM, 2015: 131-143
[18]Bojnordi M N, Ipek E. PARDIS: A programmable memory controller for the DDRx interfacing standards[C]Proc of the 39th Annual Int Symp on Computer Architecture (ISCA’12). Los Alamitos, CA: IEEE Computer Society, 2012: 13-24
[19]Martin J, Bernard C, Clermidy F, et al. A micropro-grammable memory controller for high-performance dataflow applications[C]Proc of European Solid-State Circuits Conf. Piscataway, NJ: IEEE, 2009: 348-351
[20]Kornaros G, Papaefstathiou I, Nikologiannis A, et al. A fully programmable memory management system optimizing queue handling at multi gigabit rates[C]Proc of the 40th Annual Design Automation Conf (DAC’ 03). New York: ACM, 2003: 54-59
[21]Kuskin J, Ofelt D, Heinrich M, et al. The stanford FLASH multiprocessor[C]Proc of the 21st Annual Int Symp on Computer Architecture (ISCA’94). Los Alamitos, CA: IEEE Computer Society, 1994: 302-313
[22]Reinhardt S K, Larus J R, Wood D A. Tempest and typhoon: User-level shared memory[C]Proc of the 21st Annual Int Symp on Computer Architecture (ISCA’94). Los Alamitos, CA: IEEE Computer Society, 1994: 325-336
[23]Carter J, Hsieh W, Stoller L, et al. Impulse: Building a smarter memory controller[C]Proc of the 5th Int Symp on High Performance Computer Architecture (HPCA’99). Los Alamitos, CA: IEEE Computer Society, 1999: 70-79
[24]Browne M, Aybay G, Nowatzyk A, et al. Design verification of the S3.mp cache coherent shared-memory system[J]. IEEE Trans on Computers, 1998, 47(1): 135-140
[25]Bosshart P, Daly D, Gibb G, et al. P4: Programming protocol-independent packet processors[J]. ACM SIGCOMM Computer Communication Review, 2014, 44(3): 87-95
[26]Song H. Protocol-oblivious forwarding: Unleash the power of SDN through a future-proof forwarding plane[C]Proc of the 2nd ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking (HotSDN’13). New York: ACM, 2013: 127-132
[27]Jeyakumar V, Alizadeh M, Kim C, et al. Tiny packet programs for low-latency network control and monitoring[C]Proc of the 12th ACM Workshop on Hot Topics in Networks (HotNets-XII). New York: ACM, 2013: 8
[28]Sivaraman A, Winstein K, Subramanian S, et al. No silver bullet: Extending SDN to the data plane[C]Proc of the 12th ACM Workshop on Hot Topics in Networks (HotNets-XII). New York: ACM, 2013: 19
[29]Intel Corporation. Improving real-time performance by utilizing cache allocation technology[OL]. 2015 [2016-02-26]. http:www.intel.comcontentdamwwwpublicusendocumentswhite-paperscache-allocation-technology-white-paper.pdf
[30]Xilinx Corporation. MicroBlaze soft processor core[OL]. 2015 [2016-02-26]. http:www.xilinx.comproductsdesign-toolsmicroblaze.html

Ma Jiuyue, born in 1988. PhD from the Institute of Computing Technology, Chinese Academy of Sciences. His main research interests include computer archi-tecture and operating system (majiuyue@ncic.ac.cn).

Yu Zihao, born in 1991. PhD candidate in the Institute of Computing Technology, Chinese Academy of Sciences. His main research interests include computer architecture and operating system (yuzihao@ict.ac.cn).

Bao Yungang, born in 1980. Professor and PhD supervisor. Member of CCF. His main research interests include computer architecture, operating system and system performance modeling and evaluation.

Sun Ninghui, born in 1968. Professor and PhD supervisor. His main research interests include computer architecture, high perfor-mance computing and distributed OS (snh@ict.ac.cn).
A Programmable Data Plane Design in Computer Architecture
Ma Jiuyue1,2, Yu Zihao1,2, Bao Yungang1, and Sun Ninghui1
1(InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing100190)2(UniversityofChineseAcademyofSciences,Beijing100049)
With the development of the Internet and cloud computing, more and more applications are migrated from local host to the cloud. In the cloud computing environment, these applications will finally be deployed to run in data centers, with the sharing of computer infrastructures. Influenced by the complexity and the variability of the applications running in data center, some fixed-function hardware components in traditional computer architecture, such as last-level cache, memory controller, IO controller, can not meet the requirements of deploying these application together in one data center. To adapt to these dynamic requirements, programmable hardware is needed from the view of computer architecture level, to make the function of computer hardware adaptable according to the application requirements. A programmable data plane design for computer architecture is presented, which brings programmability to hardware components by integrating programmable processors into the state-of-the-art hardware components, and let these new processors process hardware requests by firmware code. The functions of hardware components can be extended by updating firmware running on the processors. An FPGA prototype is implemented. Evaluation results show that the programmable data plane design brings flexible programmability to hardware by reasonable resource consumption, without introducing too much overhead to the original system performance. This makes it possible for the computer hardware to adapt to the dynamic requirement of application running in data centers.
programmable; processor; data center; server; quality of service (QoS)
2016-03-02;
2016-05-03
国家“九七三”重点基础研究发展计划基金项目(2011CB302500);国家自然科学基金项目(61420106013,61221062,61202062) This work was supported by the National Basic Research Program of China (973 Program) (2011CB302500) and the National Natural Science Foundation of China (61420106013, 61221062, 61202062).
TP303
