基于混合HMM的文献元数据地名抽取方法研究*
2017-02-09杜秋霞王洪国邵增珍刘衍民
杜秋霞 王洪国 邵增珍 付 鑫 刘衍民
(1.山东师范大学信息科学与工程学院 济南 250014)(2.山东省物流优化与预测工程技术研究中心 济南 250014) (3.遵义师范学院数学与计算科学学院 遵义 563002)
基于混合HMM的文献元数据地名抽取方法研究*
杜秋霞1,2王洪国1,2邵增珍1,2付 鑫1,2刘衍民3
(1.山东师范大学信息科学与工程学院 济南 250014)(2.山东省物流优化与预测工程技术研究中心 济南 250014) (3.遵义师范学院数学与计算科学学院 遵义 563002)
论文从保护地名文化遗产的角度出发,提出了一种基于混合隐马尔科夫模型的地名抽取方法,从文献元数据中快速准确的提取地名。考虑到文本中上下文对状态的影响,并用传统Viterbi算法进行正序和逆序解码,通过两次解码使颗粒度较小的地名得到较好的识别和抽取。实验结果表明这种对于元数据的信息抽取模型能达到较好的效果。
信息抽取; 元数据; 地名抽取; 隐马尔科夫模型
Class Number TP391.1
1 引言
随着新型城镇化、信息化的快速发展,每年都有数以万记的新地名产生,同时有许多老地名不断消亡,近30年来,我国就有6万多个乡镇名称和40多万个村名称被废弃。据专家统计,人们日常使用的信息中约有80%与地理位置和空间分布有关,这些信息主要通过地名来量现。文献资料作为记录知识的一切载体,它可以记载历史地理的演变过程。文献资料中蕴含着丰富的地理空间信息,从中获取地理信息,已成为传统地理信息采集方式的有效补充。与一般电子文本不同,文献具有格式多样化、内容动态化等特点,计算机从海量的文本中发现少数的地名会浪费很多时间。故如何从非结构化的文献资料中将地名快速的自动化识别和提取,来反映自然环境和社会环境的地理空间信息,并确保信息真实可靠,具有重要的现实意义。
文献资料中蕴含的地理信息的抽取[1],属于自然语言处理中描述的命名实体识别的范畴。是通过分析地理名词之间的语义关联,通过模型建立,发现和填充与地理实体相关的空间位置、属性信息等。国内外对于地名提取方法的研究主要集中在规范化地名的自动识别[2],已达到较高的识别准确率,但是对那些粒度小的乡镇名和村名的识别和抽取研究成果较少。对于文献元数据[3~5]的研究则主要集中在对元数据的整体的抽取上,而对于元数据内部的信息研究关注较少。文献[6]利用本体的方法,对于每一个概念或关系的本体通过集合学习的模式从文本中抽取信息;文献[7]使用线程和同步将多个文件输入进行批处理,通过对句子进行语义分析,从原始文档中提取句子的关键词。文献[8]提出一种改进遗传退火(Hidden Markov Model,HMM)的Web抽取算法,并利用双序Viterbi解码,取得了较好的效果;文献[9]提出了基于改进二阶隐马尔科夫模型的文本信息抽取模型,并对Viterbi算法进行了改进,取得较好的识别效果;文献[10]通过分析文献中上下文和内容在文档中的关系,对文献中的关键词进行了抽取以方便文献的查找和。提出一种改进头脑风暴优化算法的隐马尔科夫模型。隐马尔科夫模型(Hidden Markov Model,HMM)是一种重要的文本信息抽取方法,由于其易于建立、适应性强等特点而备受研究者的关注。传统HMM模型及其衍生模型,虽然具有很好的抽取效果,但它们的共同点是只考虑某时刻的转移概率对前一个状态的依赖性,即前向依赖,较少考虑后向依赖,而现实情况是有些地名抽取时后词对前词的影响更大。基于此,本文提出一种基于混合HMM(Hybrid Hidden Markov Model,HHMM)的文本信息抽取方法,同时考虑当前状态受它前词和后词的双向混合影响,并利用Viterbi算法进行了验证。实验结果表明,混合隐马尔科夫模型可有效提高元数据中地名信息抽取的准确率,表现出了良好的性能。
2 相关模型和算法
2.1 隐马尔科夫模型
隐马尔科夫模型(Hidden Markov Model,HMM)(如图1)是一个二重马尔科夫随机过程,它包括具有状态转移概率的马尔科夫链和输出观测值的随机过程。其状态是不确定或不可见的,只有通过观测序列的随机过程才能表现出来。一个HMM包含两层:一个可观察层和一个隐藏层。可观察层是待识别的观察序列,隐藏层是一个马尔科夫过程,即一个有限状态机,其中每个状态转移都带有转移概率。
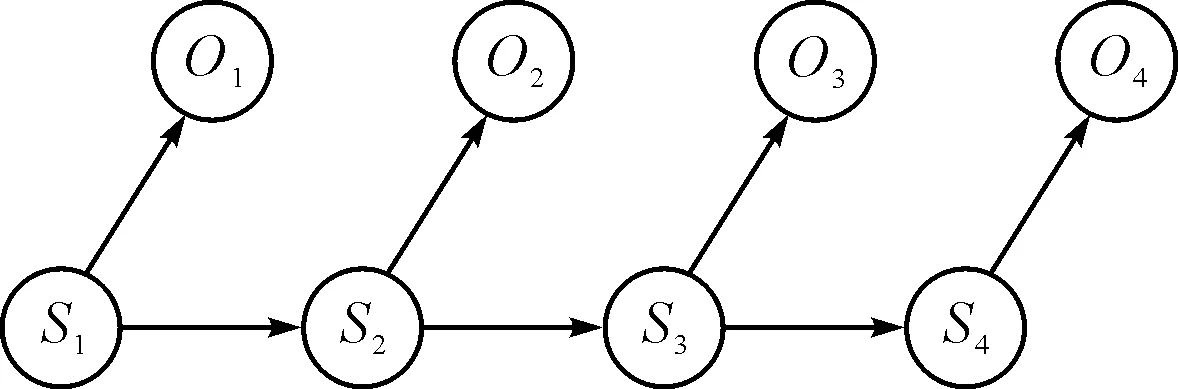
图1 隐马尔科夫模型
一个HMM可以看成一个五元组λ={S,K,Π,A,B},其中S={S1,S2,…,SN}表示模型中所有的状态,N代表状态的数目;K={K1,K2,…,KM}表示状态观察值的集合,M代表观察值的数目;Π={πi=P(q1=Si),1≤i≤N}为初始状态的集合。πi表示状态si作为初始状态的概率;A={aij=P(qt=Sj|qt-1=Si),1≤i,j≤N}为移概率矩阵,aij表示状态si转移到状态sj的概率;B={bi(k)=P(Ot=Kk|qt=Si),1≤i≤N,1≤k≤M}为发射概率矩阵,bi(k)表示在状态si下,Kk出现的概率。
2.2 混合隐马尔科夫模型(Hybrid Hidden Markov Model,HHMM)
传统隐马尔科夫模型仅考虑前一个词对后一个词的影响,而实际上对于文本而言,对于一个词的影响不只是前一个词,甚至一个命名实体和一句话中的其他所有词都有关系。鉴于这种情况,本文所提出的HHMM考虑了后一个状态对前一个状态的影响,因此本文的HHMM是由传统的HMM和逆序的HMM(Reverse Hidden Markov Model,RHMM)共同构成(如图2)。
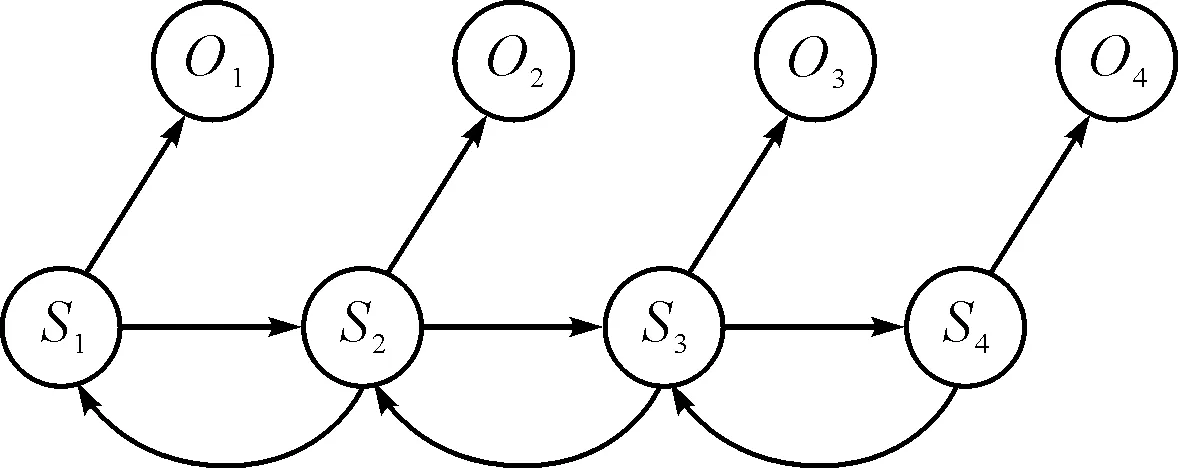
图2 混合隐马尔科夫模型
2.3 基于RHMM的改进解码算法(R-Viterbi)
对于一个特殊的HMM和一个相应的观察序列,在实际应用中经常希望能找到生成此序列最可能的隐藏序列状态。在命名实体识别中需要解决的问题就是如何为一个句子找到最合适的标记序列,即解码。常用的解码方法是Viterbi[11]算法,它属于动态规划算法,其思想是把问题分解,先解决最基本的子问题,再逐步外推寻找更好的子问题的最优解,在有限步后达到整个问题的最优解,即得到最优的命名实体标记序列[12~13]。算法的描述如下:
第一步:利用下式计算初始局部最优函数:
φ1(i)=πibi(y1) 1≤i≤N
θ1(i)=0
第二步:确定求解局部最优的递归函数的递归:
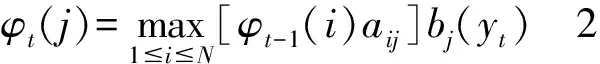
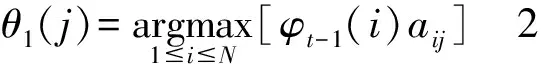
第三步:计算最后一个观察值的最佳状态:
第四步:回退以前观察值得最佳状态:
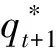
对于观察序列O=(O1,O2,…,OT),用Viterbi算法解码时,P(qi+1|q1,q2,…,qi)=P(qi+1|qi),即,O2的状态由O1的状态决定。针对逆序隐马尔科夫模型本文对传统解码算法(Viterbi算法)做了如下改进:
对于另一类观察序列O′=(OT,OT-1,…,O1),t+1时刻的状态qt+1由时刻t的状态qt所决定,即O1的状态由O2的状态决定。由此可以将观察序列为O′=(OT,OT-1,…,O1)的解码过程理解为:对观察序列O=(O1,O2,…,OT)的逆过程,t时刻的状态qt由t+1时刻的状态qt+1所决定,即P(qi|qi+1,qi+2,…,qi+n)=P(qi|qi+1),这体现了观察序列的后向依赖性。
3 基于HHMM的文献元数据的地名信息抽取
将以上算法用于文献元数据的地名信息抽取任务。本文所研究文献的元数据的基本格式为:{(Reference Type)、(Title)、(Author)、(Author Address)、(Journal)、(Year)、(Issue)、(Pages)、(Keywords)、(Abstract)、(ISBN/ISSN)、(Notes)、(Database Provider)}。
该元数据包括13个部分,其中包含地名的在(Title)、(Keywords)、(Abstract)这三部分中。由于(Keywords)部分的地名不包含语法语义,利用NLPIR汉语分词系统进行分词和标注后,对这部分的地名我们根据标注结果进行直接抽取。所以本文的研究重点是(Title)和(Abstract)部分。
3.1 数据预处理
本文分词工具选用的中科院NLPIR汉语分词系统(ICTCLAS2014),利用该系统对初始文本进行分词和标注,并对分词结果根据词性标注进行筛选,将每篇文本处理后的词汇集作为下一步处理的数据源。经过海量分词和后,元数据中(Keywords)部分的地名大部分可以被准确识别,但是由于(Title)和(Abstract)部分具有文本结构的复杂性,标注结果还存在以下一些问题:音译地名识别效果一般;颗粒度小的地名,如岛砣、宁木特乡等难以被识别。而这些不能准确标注的地名,对研究已经消失的地名和对地名遗产的保护具有非常重要的意义,因此本文对文献元数据进行了二次标注(人工标注),以保证得到较好的标注文本。
3.2 地名信息抽取
中文地名自动识别是通过对文本进行标记产生地名识别的结果。对于每个词模型给出判断其是或不是一个地名的概率。为了给文本信息抽取建立一个HMM,必须首先决定模型应该包含多少个状态,以及状态间如何转移。一个合理的初始模型是每一类使用一个状态,并且允许任何一个状态到另外一个状态的转移(一个完全连接模型)。文本中的地名不止与其前一个词有关系,与其后边的词也有关系,因此本文分别用文本的正序列和逆序列建立隐马尔科夫模型。本文的地名抽取过程分为模型训练和对测试文本的解码两部分,具体如图3所示。
3.2.1 模型建立
为方便计算和去除噪音数据,本文在人工标注时做了以下修改:在做地名识别二次标注时,除了地名(ns)的其他名词都标为了n,其他动词(v)、形容词(a)等其他词同样为简化计算没再进行细分;除动词、名词、形容词等之外的其他词(如拟声词、标点符号等)都标为o,根据本文混合HMM模型的训练过程如下:
第一步:初始化HMM,确定模型的状态数,初始化模型的参数。本文的状态集为对每个词的标记为:n(物名)、ns(地名)、t(时间词)、v(动词)、a(形容词)、r(代词)、m(数词)、d(副词)、p(介词)、u(助词)、o(其他词);
第二步:正序扫描文本,依据排版格式、分隔符等信息将标记好的文献元数据转换为由分组构成的序列,每一分组都用上一步的标记符号进行状态标记;
第三步:训练模型,以分组为单位,应用ML[14]算法计算HMM参数λ=(A,B,π);
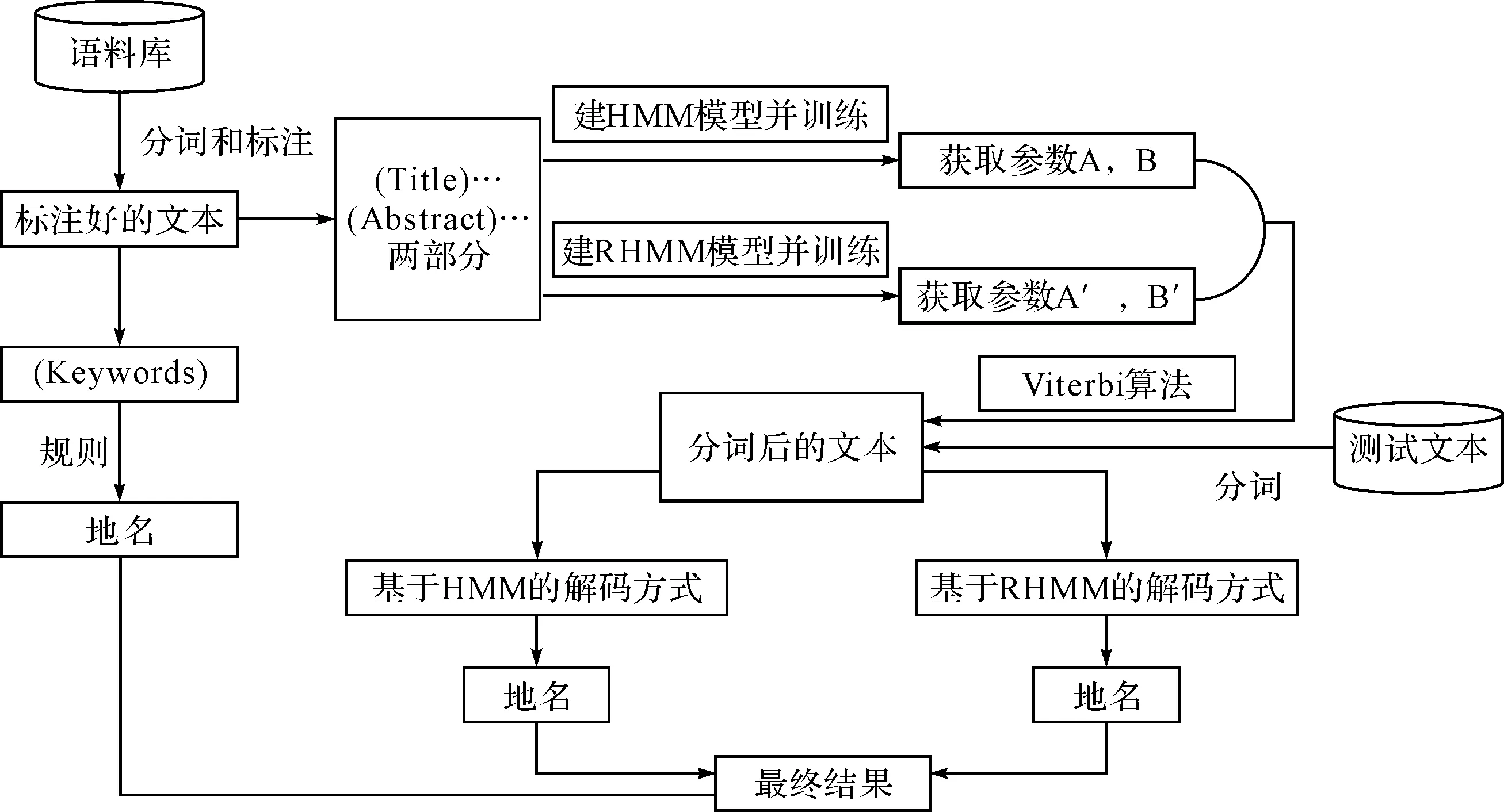
图3 抽取过程
第四步:初始化RHMM,确定模型的状态数,初始化模型的参数,这里的状态集和第一步中的相同;
第五步:逆序扫描文本,方法和第二步相同;
第六步:训练模型,以分组为单位,应用ML算法计算RHMM参数λ=(A′,B′,π)。
3.2.2 解码过程
为方便计算,本文假设测试文本中的词只与词语所在的一句话有关系。首先对测试文本按标点符号“,”、“。”、“!”、“?”进行切分,这样测试文本就变为单个句子;然后给这些句子进行分词后求出其最佳的标注序列;最后把标为ns(即地名)的词输出,完成整个抽取过程。算法描述具体如下:
第一步:训练样本预处理。扫描文本,利用逗号、句号、问号、感叹号(括号、引号内的逗号除外)、三个以上的空格等分隔符信息将文本序列切分成文本分块序列;
第二步:计算正序文本的最大概率路径。结合训练部分输出的HMM模型参数λ=(A,B,π),利用Viterbi算法计算;
第三步:回溯查找最大概率路径上HMM的状态标记序列,将标记为ns的词输出。
第四步:计算逆序文本的最大概率路径。结合训练部分输出的RHMM模型参数λ=(A′,B′,π),利用R-Viterbi算法计算;
第五步:回溯查找最大概率路径上RHMM的状态标记序列,将标记为ns的词输出;
第六步:取第三步和第五步输出结果的并集,输出最终结果。
3.3 算法复杂性分析
本文的算法复杂性分析分为模型的训练和解码两部分,对于HMM的训练部分的算法复杂度分析,即模型训练问题,是指给定观察序列,产生出这些参数的模型λ=(A,B,π)以满足某种最优化准则,使观察序列的概率P(O|λ)最大。直接解决方式具有指数级的计算复杂性(2T*NT,T是观察序列的长度,N是状态的个数),这样复杂性特别大,为了有效地解决该问题通常使用后向算法解决。定义后向概率βt(i)=P(O1O2…Ot,qt=Si|λ),后向算法描述如下:
第一步:初始化:
βT(i)=1 1≤i≤N
第二步:归纳计算:
1≤t≤T-1,1≤i≤N
第三步:求最终和:
由以上步骤可以看出:计算某时刻在某个状态下的后向变量需要看后一时刻的n个状态,此时,时间复杂度为O(n),每个时刻又有n个状态,此时时间复杂度为n×O(n)=O(n2),又有T个时刻,所以时间复杂度为T×O(n2)=O(n2×T),因为本文所考虑的为一阶隐马尔科夫模型,所以算法复杂度为O(n2)。
对于解码过程中,Viterbi算法的第一步初始概率是在训练模型中已经训练出的,是个固定的值,所以第一步的算法复杂度是O(1),以后的每一步计算的复杂度都和相邻两个状态si和si+1各自的节点数ni和ni+1的乘积成正比,即O(ni·ni+1)。在隐马尔科夫模型中节点最多的状态有n个节点,也就是说在Viterbi算法整个网格的宽度为n,每一步的复杂度不超过O(n2)。所以整个算法的复杂度为O(n2)。
4 实验及结果分析
本文实验是在MyEclipse开发环境下用Java语言进行开发。数据集选择从CNKI文献库中搜集到的鸟类研究文献包含环境科学与资源利用、生物学、蚕蜂与野生动物保护等学科中的文献元数据信息共2000条。为更好地评估算法的有效性,从2000条数据中选出1000条作为训练数据。首先用ICTCLAS开源系统进行初次标注,并把关键字部分的地名进行输出,然后对(Title)和(Keywords}部分的内容进行人工标注,最终的标注结果为如下格式:
“(/o Title/o )/o :/o 烟台/ns 的/u 十一种/m 山东省/ns 鸟类/n 新/a 记录/n
(/o Abstract/o )/o :/o 烟台市/ns 鸟类/n 资源/n 普查/v 从/p 1983年/t 5月/t 开始/v ,/o 至/p 1985年/t 6月/t 结束/v 。/o 通过/p 普查/v 共/d 鉴定/v 鸟类/n 标本/n 3000/m 余号/m ,/o 查出/v 烟台市/ns 鸟类/n 19目/m 、/o 50/m 科/n 、/o 276种/m (/o 含/v 亚种/n 4种/m )/o 。/o 其中/r 发现/v 山东/ns 鸟类/n 新/a 记录/n 11种/m ,/o 现/t 分述/v 如下/v :/o 1/m 、/o 中/b 白鹭/n 1984年/t 4月/t 2日/t 在/p 长岛县/ns 大黑山/ns 首次/m 采得/v 一只/m 雌鸟/n 。/o ”
统计这1000条文本数据中词性之间的转移概率和词性对应每个词的发射概率,即HMM模型中的参数A、B。经统计发现文本中转移概率,任何词到其他词(o)所占的比例都较大,而标记为o的这些词中大部分为标点等,对地名的抽取影响不大,所以本文对除o外的其他十个状态转移概率做了归一化处理,使每个状态对应的转移概率之和为1。
利用Viterbi算法对1000条测试数据进行抽取,测试数据为分词后的文本,利用空格作为间隔符,测试文本格式如下:
“( Title ) : 东港市 白鹭 繁殖群 生境 调查 及 保护
( Abstract ) : 辽宁省 东港市 以 白鹭 为主 的 鹭类 繁殖群 的 数量 、 种类 在 人工 湿地 中 群 居 之 多 在 省内 实属 罕见 。 对 该 区域 内 白鹭 等 鹭类 的 生境 条件 调查 发现 , 丰富 的 植被 、 水域 、 食物 条件 为 白鹭 提供 了 留存 条件 。 由于 没有 健全 的 保护 措施 , 保护 力度 不够 , 造成 因 受 环境 、 人为 等 干扰 使 白鹭 生存 环境 受到 破坏 , 导致 数量 减少 , 因此 建立 东港市 白鹭 自然保护区 是 必要 的 , 经 论证 也 是 可行 的 。”
目的为从以上文本中抽取地名,由于对文本元数据进行地名信息抽取算法目前还没有准确的客观评价指标,为评价本文算法的有效性,本文通过人工标注从1000篇文献中共标出地名5775个,然后再用本文的方法进行抽取。抽取结果如表1,这里用三个常用评价标准:召回率(R)、准确率(P)和F1值(召回率和准确率的调和平均数)来进行评价算法的性能,c代表地名总数,m代表抽取到的地名总数,n代表抽取正确的地名,t代表抽取错误的地名。则有下式:

表1 抽取结果
由上表可以计算出利用传统HMM方法的召回率为77.6%,准确率为88.2%,F1值为82.6%。利用HHMM方法的召回率为85.9%,准确率为89.1%,F1值为87.5%。用图表示如图4所示。
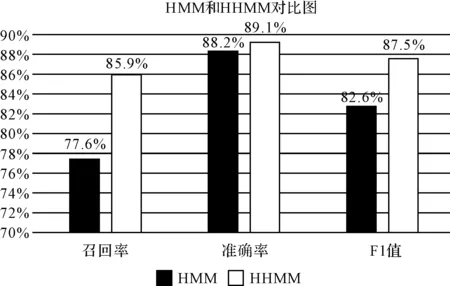
图4 基于HMM和HHMM的对比图
从上图可以看出,用基于HHMM的方法在召回率和F1值上比传统HMM有显著增高,准确率升高幅度不大,但也有所提高。所以整体来看,本文的方法是有效的。但是从表1来看,HHMM中抽取错误的地名也有所增加,这是因为HHMM是取传统HMM和RHMM的并集,所以抽取完成后错误的地名会有所增加,同时也说明本文的方法在对抽取正确的地名有较高的有效性和实用性。
5 结语
本文从保护地名文化遗产的角度出发,考虑到文献所独具的特点,从文献元数据中快速的将文献中所蕴含的地名信息抽取出来。在模型建立上,考虑到文本中地名前词和后词对地名的影响,提出了一种基于混合隐马尔科夫模型的地名抽取方法;在解码方法上,采用传统Viterbi算法进行正序和逆序解码,从文献元数据中抽取地名;在抽取效果上,通过两次标注训练混合隐马尔科夫模型,使那些颗粒度较小的镇名和村名得到较好的抽取效果。但是从保护地名遗产的角度来看,本文仅是对元数据中的地名进行了较为细致的抽取,但对于哪些是已经消失或新增的地名哪些是现有的地名没有准确分类;另外,每个地名都有它的时间特征,这样便于发现消失和新增地名的变化过程。所以下一步的工作中,将加入地名数据库,利用地名数据库来发现消失和新增的地名,并对地名加入时间特征进行抽取。
[1] Piskorski J, Yangarber R. Information extraction: Past, present and future[C]//Multi-source, Multilingual Information Extraction and Summarization. Berlin Heidelberg: Springer-Verlag,2013:23-49.
[2] 张晓艳,王挺,陈火旺.命名实体识别研究[J].计算机科学,2005,4:44-48. ZHANG Xiaoyan, WANG Ting, CHEN Huowang. Named entity recognition[J]. Computer Science,2005,4:44-48.
[3] Chen F, Chiu P, Lim S. Topic Modeling of Document Metadata for Visualizing Collaborations over Time[C]//Proceedings of the 21st International Conference on Intelligent User Interfaces. ACM,2016:108-117.
[4] Frank J R, Kornai A. Methods of systems using geographic meta-metadata in information retrieval and document displays: U.S. Patent 9,286,404[P]. 2016-3-15.
[5] Hoenich D A, Hunt D W, Logan W K, et al. Document Processing System And Method For Associating Metadata With A Physical Document While Maintaining The Integrity Of Its Content: U.S. Patent 20,160,063,365[P]. 2016-3-3.
[6] Gutierrez F. A Hybrid Approach for Ontology-based Information Extraction[J]. 2016.
[7] Motwani D, Saxena A S. Multiple Document Summarization Using Text-Based Keyword Extraction[C]//Proceedings of Fifth International Conference on Soft Computing for Problem Solving. Springer Singapore,2016:187-197.
[8] 李荣,冯丽萍,王鸿斌.基于改进遗传退火HMM的Web信息抽取研究[J].计算机应用与软件,2014,4:40-44. LI Rong, FENG Liping, WANG Hongbin. Extraction based on improved genetic annealing HMM Web Information[J]. Computer Applications and Software,2014,4:40-44.
[9] Ling L J T J X. Research on Information Extraction Based on Second-Order HMM[J]. 2011.
[10] Kavila S D, Rani D F. Information Extraction from Research Papers Based on Statistical Methods[C]//Proceedings of the Second International Conference on Computer and Communication Technologies. Springer India,2016:573-580.
[11] Viterbi A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm[J]. IEEE Transactions on Information Theory,1967,13.
[12] 刘芳,赵铁军,于浩,等.基于统计的汉语组块分析[J].中文信息学报,2000,6:28-32,39. LIU Fang, ZHAO Tiejun, YU Hao, et al. Based on statistical analysis of Chinese Chunk[J]. Chinese Information Technology,2000,6:28-32,39.
[13] 白栓虎.基于统计的汉语语料库词性自动标注方法的研究与实现[D].北京:清华大学,1992. BAI Shuanhu. Research and implementation of automatic annotation method based on statistics of Chinese speech corpus[D]. Beijing: Tsinghua University,1992.
[14] Seymore K, McCallum A, Rosenfeld R. Learning hidden Markov model structure for information extraction[C]//AAAI-99 Workshop on Machine Learning for Information Extraction,1999:37-42.
Place Name Extraction Method of Literature Metadata Based on the Hybrid HMM
DU Qiuxia1,2WANG Hongguo1,2SHAO Zengzhen1,2FU Xin1,2LIU Yanmin3
(1. School of Information Science and Engineering, Shandong Normal University, Jinan 250014) (2. Shandong Provincial Logistics Optimization and Predictive Engineering Technology Research Center, Jinan 250014) (3. School of Mathematics and Computational Science, Zunyi Normal College, Zunyi 563002)
From the perspective of the protection of the cultural heritage of place names, this paper proposes a method of place name extraction based on the hybrid Hidden Markov Model,fast and accurate place names extraction from literature metadata. Considering the influence of the context on the state in the text, the traditional and reverse Viterbi algorithms are used to decode, and the place names with small particle size can be well recognized and extracted by decoding twice. Experimental results show that the information extraction model of metadata can achieve good results.
information extraction, metadata, place name extraction, HMM
2016年7月11日,
2016年8月29日
国家自然科学基金(编号:71461027);山东省科技发展计划项目(编号:2014GGH201022);山东省经信委软科学计划项目(编号:2015EI010);遵义市创新人才团队(编号:遵市科合(2015)38号);贵州省优秀青年科技人才培养对象专项资金(编号:黔科合人字[2015]06)资助。
杜秋霞,女,硕士研究生,研究方向:信息抽取。王洪国,男,教授,博士生导师,研究方向:电子政务,物流优化等。邵增珍,男,博士后,副教授,硕士生导师,研究方向:智能计算,智能物流,大数据分析等。付鑫,男,硕士研究生,研究方向:信息抽取。刘衍民,男,博士后,教授,研究方向:优化理论及智能算法。
TP391.1
10.3969/j.issn.1672-9722.2017.01.022
