分类精确性指数Entropy在潜剖面分析中的表现:一项蒙特卡罗模拟研究*
2017-02-01王孟成邓俏文毕向阳叶浩生杨文登
王孟成 邓俏文 毕向阳 叶浩生 杨文登
(1广州大学心理系; 2广州大学心理测量与潜变量建模研究中心; 3广东省未成年人心理健康与教育认知神经科学实验室,广州 510006) (4中国政法大学社会学院, 北京 102249)
1 引言
以结构方程模型为代表的潜变量建模方法在心理学和社会科学各领域得到了广泛的应用(侯杰泰, 温忠麟, 成子娟, 2004; 王孟成, 2014)。然而在传统的结构方程模型中, 研究的样本通常假设来自同质性(Homogeneity)群体, 但这一假设在很多情况下并不成立。不同质群体的结构方程建模可以使用多组分析(Multiple-Group Analysis)或多指标多因模型(MIMIC) (侯杰泰等, 2004)。不过这种处理的前提是存在明确的分组变量, 最多见的分组变量如性别、种族和宗教信仰等。但更多时候, 往往很难找到客观的外显分组变量, 最常见的例子就是心理疾病的诊断(e.g., Helzer, Kraemer, & Krueger, 2006;Widiger & Samuel, 2005; Zachar & Kendler, 2007)。目前的心理疾病诊断通常以患者满足某种疾病最低的症状数目为确诊依据即采用类型(Categorical)标准将个体分为异常和正常。然而实证研究的结果通常并不支持这种诊断划分(e.g., Widiger, Livesley,& Clark, 2009), 即心理疾病不是有或无的类别。在不存在明确的分组变量的情况下, 不同质群体(即异质群体)的划分是隐蔽的、潜在的, 因此需要通过基于模型的方法对潜在分组进行估计。
在统计学上, 为了处理潜在分组问题, 研究者提出了多种统计模型, 比如Taxometric分析法(Meehl,1995; Ruscio, Haslam, & Ruscio, 2006)和潜类别/潜剖面分析(McLachlan & Peel, 2000)。由于Taxometric方法在处理存在两个以上的潜在群体方面存在很大的局限性(Lubke & Miller, 2015; Lubke & Tueller,2010), 潜类别/潜剖面分析是目前将人群分成不同潜在组最流行的方法(McClintock, Dale, Laumann,& Waite, 2016; Mokros et al., 2015; 王孟成, 毕向阳, 叶浩生, 2014)。
潜类别分析(Latent Class Analysis, LCA)或潜类别模型(Latent Class Model, LCM)是通过个体在观测变量上的反应模式将其划分成不同的潜类别组, 与聚类分析在功能上类似, 只是LCA是基于模型的聚类方法, 因此也称作潜聚类分析(latent cluster analysis)。潜类别模型主要处理分类的观测变量, 如果观测变量是连续指标时则称作潜剖面分析(Latent Profile Analysis, LPA)。近年来LPA/LCA在心理学、预防医学、精神病学、市场营销、组织管理等诸多领域逐渐流行(e.g., Carragher, Adamson,Bunting, & McCann, 2009; Lanza, Rhoades, Greenberg,Cox, & The Family Life Project Key Investigators,2011; McClintock et al., 2016; Wang & Hanges, 2011;张洁婷, 焦璨, 张敏强, 2010)。例如, Carragher等(2009)在12,180个全美代表性样本中应用潜类别分析将抑郁症状划分成4个类别:严重抑郁组(Severely Depressed, 40.9%)、躯体症状组(Psychosomatic,30.6%)、认知情感组(Cognitive-Emotional, 10.2%)和健康组(Non-depressed, 18.3%)。
LPA/LCA作为潜在分组的统计方法其分类精确性是应用研究者关注的焦点, 目前绝大多数LPA/LCA均报告分类精确性指标(e.g., McClintock et al., 2016; Pastor, Barron, Miller, & Davis, 2007;Vannucci, Tanofsky-Kraff, Crosby et al., 2013), 因此深入分析分类精确性在不同条件下的表现将是评价 LPA/LCA作为潜分类分析法有效性和适切性的重要议题, 同时也将为实际使用者提供应用参考。由于心理学研究中的变量通常为连续型变量, 所以本研究主要考察潜剖面分析的分类精确性。
1.1 潜剖面分析
潜剖面分析通过类别的潜变量即潜在剖面变量来解释连续外显指标间的关联, 使外显指标间的关联通过潜在类别变量来估计, 进而维持其局部独立性的统计方法。连续指标的方差被分解为类别/剖面间和类别/剖面内方差。例如, 第k
个剖面的第i
个指标的方差可以分解为(Lazarsfeld & Henry,1968):


1.2 分类精确性指标及其影响因素
1.2.1 分类精确性指标Entropy
LPA/LCA作为潜在聚类的分析方法, 其分类精确性是考查建模有效性的重要指标, 也是研究的主要兴趣。例如, 在临床诊断上, 根据LPA/LCA的结果将不同患者归入不同的临床分组, 分类的精确性将会影响诊断的有效性。在LPA/LCA模型中, 通常使用 Entropy作为分类精确性的指标, 取值范围在0~1之间, 越接近1表明分类越精确。其计算公式如下:

P
为估计第i
个个体属于第k
个类别的后验概率,n
为样本量。P
可通过如下贝叶斯后验概率获得:

N
是基于模型估计的类别潜变量, 与实际的类别潜变量C
并不完全一致(完全一致时不存在分类误差), 因此存在如下分类不确定率:


N
c是根据N
将个体分配到C
的数量。1.2.2 Entropy指数的变式
由于Entropy容易受剖面间类别距离和剖面内方差的影响(e.g., Lubke & Muthén, 2007; Muthén,2004), 文献中还提出了三种基于Entropy指数的变式, 分别为规范化Entropy指数(Normalized Entropy Criterion, NEC; Celeux & Soromenho, 1996)、分类似然指数(Classification Likelihood Criterion, CLC;Biernacki & Govaert, 1997)和综合似然指数(Integrated Completed Likelihood Criterion, ICL-BIC; Biernacki,Celeux, & Govaert, 2000)。由于本研究不考虑总体同质(潜类别数k
= 1)的情况, 所以我们不考虑纳入NEC作为评价分类精确性的指标。CLC和ICL_BIC的公式分别如下:
样本校正的ICL_BIC, SaICL_BIC的公式如下:

p
为模型估计的参数量,LL
为对数似然统计量,N
为样本量。1.2.3 Entropy的影响因素
Entropy作为分类精确性的标准化衡量指数,凡是影响潜类别分类精确性的因素均会对其产生影响, 其中最重要的影响因素是潜类别间距(Latent Class Separation)和类别内方差(e.g., Lubke & Muthén,2007; Muthén, 2004)。
潜类别间距是指潜类别间差异的大小, 反映在项目反应概率或均值上, 表现为不同类别个体间在所有观测指标上存在显著的差别(Collins & Lanza,2009)。潜类别间距越大, 对于来自任一潜类别的个体来说, 将其划分到所属类别的精确性越高。如果两个类别间的差异不明显, 即潜类别间距小, 将个体精确地划分到所属类别就越困难。因此, 潜类别间距的大小是影响分类精确性的重要因素, 也是影响潜类别个数保留的重要变量(Lubke & Neale, 2006)。
对分类精确性有影响的另一个因素是类别内方差。在潜类别间距相同的情况下, 特定类别分布的方差越大, 两个分布之间重叠的部分越大, 将个体划分到特定类别组就越困难。类别分布的方差越小, 两个分布之间重叠的部分越小, 将个体划分到特定类别组就越容易。由于在此模拟研究中, 通过固定方差法来统一潜变量的单位, 所以本研究不考查类别内方差对分类精确性的影响。
1.3 先前研究的不足与本研究目的
尽管Entropy是衡量分类精确性最常用的指标,然而令人遗憾地是, 在方法学文献中考查该指数表现的研究非常少。据我们所知当前仅有一项研究考查了Entropy与分类精确性的关系(Lubke & Muthén,2007), 其他研究只考查Entropy作为确定潜类别数目的评价指标时的表现(e.g., Peugh & Fan, 2013;Tein, Coxe, & Cham, 2013)。
Lubke和 Muthén (2007)的模拟研究在考查样本量、潜类别间距、协变量和模型复杂性等因素对因子混合模型(factor mixture model)的参数估计和分类精确性的影响时, 发现当Entropy < 0.60时相当于超过20%的个体存在分类错误; Entropy≥0.80表明分类准确率超过90%。这一结果是否能推广到研究设定因素之外的情况呢?另外, 在他们的研究中还存在如下几个方面的不足。首先, 该研究考查的样本量范围有限, 仅考查了N
= 300时的情况。在本研究之前的预实验中, 我们发现样本量与Entropy呈负相关, 即样本量越大 Entropy值越小,所以扩大样本量范围对全面了解Entropy的表现具有重要意义。另外, 她们的研究只考查了存在2个潜在类别组即k
= 2的情况, 然而在实际研究中,潜类别数量通常多于2个。最后, 上述关于Entropy的临界值是在考虑协变量的情况下获得的, 在很多应用研究中并未涉及协变量, 所以在其他条件下这些值是否适用有待进一步分析。最近, Peugh和 Fan (2013)的模拟研究考查了Entropy及其三种变式(CLC、NEC、ICL_BIC)在确定潜剖面类别个数中的表现, 但没有考查这些指数与分类精确性的关系。本研究将在上述两个研究的基础上, 进一步考察 Entropy及相关变式在不同样本量、潜类别数目、类别距离和指标个数等因素在不同水平组合条件下的表现。
2 模拟研究
2.1 模拟设计
(1) 样本量
样本量是多变量模型考虑的重要因素之一。在先前针对 LPA/LCA的模拟研究中, 样本量主要集中在100~3000的范围内(e.g., Nylund, Asparouhov,& Muthén, 2007; Peugh & Fan, 2013; Tein et al.,2013; Yang, 2006)。考虑到考查更小样本量的重要性(Paxton, Curran, Bollen, Kirby, & Chen, 2001), 特别是临床应用研究(Kyriakopoulos et al., 2015)的样本量通常不大; 同时为了更全面揭示样本量对分类精确性的影响(Lubke & Muthén, 2007), 本研究主要考查以下5个样本量:50, 100, 500, 1000, 3000。
(2) 类别距离
类别距离是影响分类精确性最重要的因素, 马氏距离(Mahalanobis Distance, MD)常被用来衡量潜类别间的距离。MD测量两个随机向量X
(x
,x
,…,x
)和Y
(y
,y
,…,y
)之间的距离, 其中X
与Y
有着相同的分布和协方差矩阵S
。与之前的相关研究一致(e.g., Lubke & Muthén, 2007; Peugh & Fan, 2013),本研究采用马氏距离来衡量潜类别间的距离, 公式如下(j
表示元素或变量个数):
本研究选择了 3个水平的类别距离, 分别为0.5、1.2和 3, 涵盖了从小到较大的类别距离范围(Lubke & Neale, 2006; Peugh & Fan, 2013)。正态分布的方差固定为 1, 具体的指标均值和马氏距离的关系呈现在表1中。其中, 类别数为3时对应的马氏距离的均值等于类别数为5时对应的马氏距离的潜类别1-3的均值。
(3) 指标数

(4) 类别数目
另外一个考虑的变量是类别数。在模拟研究中,研究 3个潜类别数的情况比较多(e.g., Lubke &Neale, 2006; Peugh & Fan, 2013; Tein et al., 2013;Tofighi & Enders, 2008)。另外, 在多数应用研究中通常发现3~5个潜在类别或剖面(e.g., Pastor et al.,2007; Vannucci et al., 2013; Wade, Crosby, & Martin,2006), 所以本研究考虑3和5个类别的情况。
2.2 研究假设
本研究主要通过蒙特卡洛模拟(Monte Carlo simulation, MC)来考查分类精确性指标Entropy受上述因素及其组合影响的情况; 另外我们想通过模拟上述条件下的 Entropy值, 为应用研究者提供合理的临界值。基于以上文献回顾, 我们提出如下研究假设:首先, 由于 Entropy是衡量分类精确性的指标, 所以 Entropy应该与分类精确率之间具有强的正相关(Lubke & Muthén, 2007)。其次, 我们希望通过此研究验证Lubke和Muthén (2007)的发现, 即Entropy < 0.60时相当于超过20%的个体存在分类错误; Entropy≥0.80表明分类准确率超过90%。第三, 在预实验中, 我们发现 Entropy随样本量的增加而减小, 在此研究中, 我们预计会出现同样的结果。最后, 基于其他混合模型(Mixture model)的研究结果(e.g., Lubke & Neale, 2006; Tein et al., 2013;Wurpts & Geiser, 2014), 本研究还假设指标数和类别距离对分类精确性有正向的影响作用。
2.3 数据生成与分析
本研究包含以下 120种组合:5个样本量(50,100, 500, 1000, 3000)´3 类别距离(0.5, 1.2, 3)´4 指标数(4, 8, 12, 20)´2潜类别数(3, 5)。总体参数的设定情况为:类别内指标之间不相关; 指标正态分布方差为 1, 均值由对应的马氏距离决定(如表 1所示)。分析模型的统计量与总体参数一致, 即拟合的是真模型。由于本研究的目的并非检验某一参数估计的统计功效问题, 受重复次数影响较大的参数覆盖率并非此次研究的焦点(Kim, 2012), 所以参考前人模拟研究中的重复次数(e.g., Lubke & Neale,2006; Tein et al., 2013), 我们将每种组合设定为重复100次。本研究中所有数据的生成与分析均采用Mplus
7.4 实现(Muthén & Muthén, 1998–2015)。
表1 马氏距离(MD)与指标均值(指标数=4)

图1 k=3指标数=4 (左图)和指标数=20 (右图)时Entropy和分类错误率随类别距离(MD)和样本量的变化情况(两图的图例相同)

图2 k=5指标数=4 (左图)和指标数=20 (右图)时Entropy和分类错误率随类别距离(MD)和样本量的变化情况(两图的图例相同)
2.4 评价指标
本研究的评价指标主要有:Entropy及其变式、分类精确率和分类错误率(Asparouhov & Muthén,2014)。Entropy通过Mplus
直接输出获得。分类精确率是通过对每个类别的平均后验概率值求和再除以类别数得到, 具体做法是通过平均类别概率矩阵中的斜对角线上的分类确定性概率值获得。另外,通过平均所有q
值获得分类错误率。3 结果
研究发现, Entropy与3个类别模型的分类精确率相关系数为0.94, 与5个类别模型的分类精确率相关系数为0.95 (p
s < 0.001)。类别数为3时, Entropy< 0.64相当于超过20%的个体存在分类错误; Entropy≥ 0.76表明分类准确率超过90%。类别数为5时,Entropy < 0.68相当于超过30%的个体存在分类错误; Entropy > 0.84表明分类准确率超过90%。当类别数为3指标数相同时, Entropy与样本量的关系, 虽然不是单调递减的形式, 但总体呈下降趋势, 分类错误率随样本量的增大总体呈上升趋势。当类别距离达到3时, Entropy明显高于其他类别距离下的结果, 分类错误率明显小于其他类别距离下的结果(以4和20个指标为例, 见图1)。随样本量的增大, 大类别距离的优势更加明显。多指标数的情况下, 大样本量更容易体现类别距离对Entropy和分类错误率的影响。类别数为5的模拟中呈现同样的结果(见图 2)。小样本的情况下(N
=50~100), Entropy总体上随指标数的增多而增大,逐渐接近1, 分类错误率逐渐接近0 (见表2)。整体来说, 在各种条件下CLC、ICL_BIC与样本校正的ICL_BIC变化趋势一致, 都随着样本量的增大而增大, 且类别距离越大, CLC、ICL_BIC与样本校正的ICL_BIC值越大, 但跨类别距离之间的差异没有Entropy明显(以类别数 = 3指标数为4和类别数 = 5指标数 = 20的CLC为例, 见图3和图4)。随着指标数的增多, CLC、ICL_BIC与样本校正的ICL_BIC之间变化的差异越来越小。
4 讨论
近年来 LPA/LCA在心理学等社会科学领域逐渐流行, 研究者通常选择报告 Entropy作为分类精确性的衡量指标, 然而在方法学文献中, 缺少考察Entropy在不同条件下表现的研究, 因此有必要探明 Entropy在不同条件下的表现。据此, 本研究系统考察了样本量、类别距离、指标数和类别数对Entropy及相关指数影响的情况。
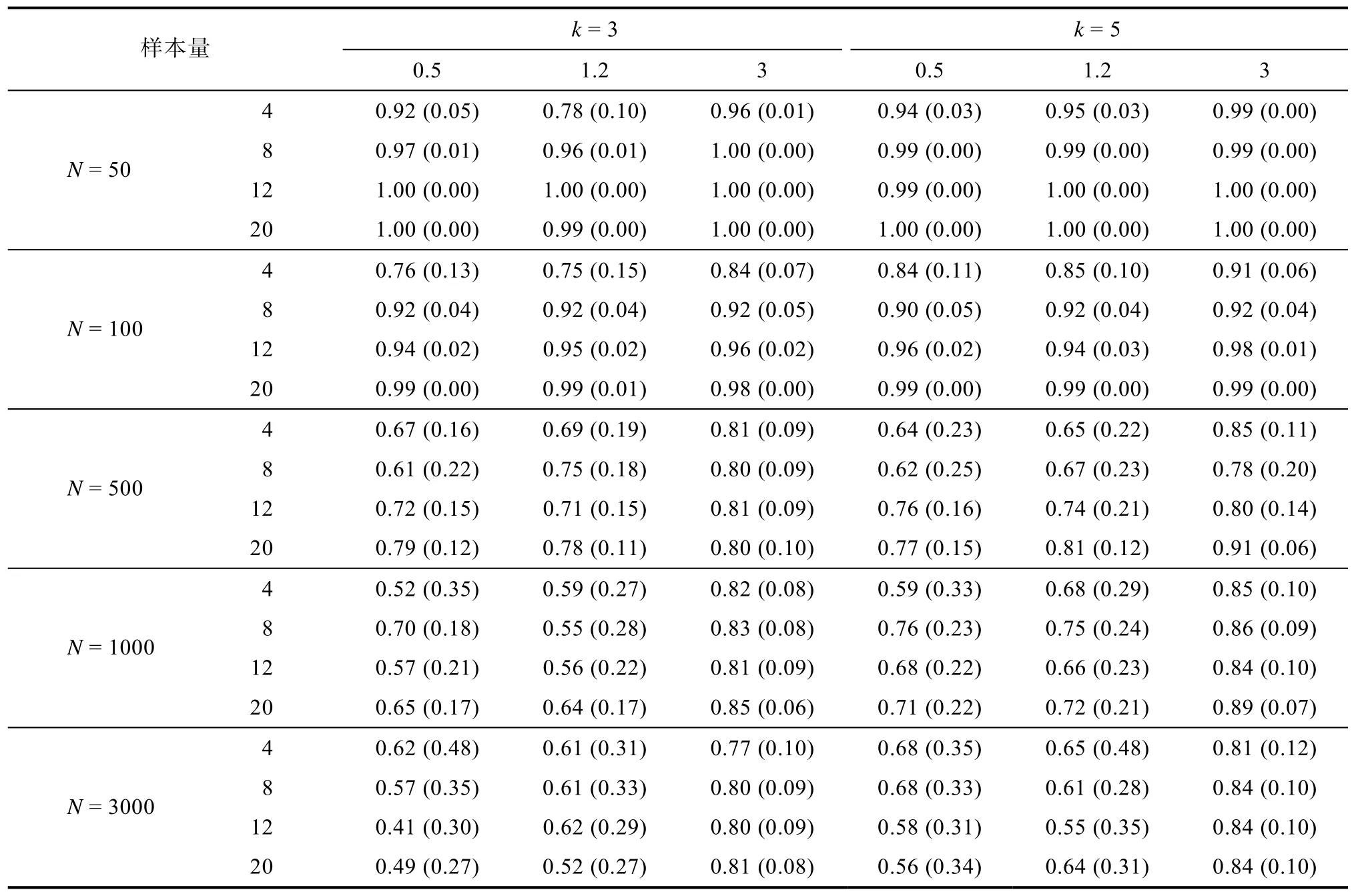
表2 不同样本量和类别数目下Entropy值及对应错误率

图3 k=3指标数=4 CLC随样本量和类别距离的变化情况

图4 k=5指标数=20 CLC随样本量和类别距离的变化情况
4.1 样本量和指标数对Entropy的影响
正如我们预实验发现的那样, 样本量越大, 分类精确性越差。尽管Tein及其同事(2013)主要研究在什么条件下以及采用什么样的评价指标有利于正确选择潜剖面模型的类别数, 但从他们拟合真模型(k
= 5)的结果可以发现, 样本量越大(N
= 250,500, 1000), Entropy的值越小。Lubke和Neale (2006)的研究中也发现大样本量的情况下, 更倾向于高估类别数。在 Lubke和 Muthén (2007)的研究中没有直接考查 LPA模型中指标数的变化对分类精确性影响的情况。尽管有研究发现指标数越多(指标数 = 6,10, 15), Entropy的结果越好(N
= 250, 500, 1000;Tein et al., 2013), 但本研究发现这一规律只适用于小样本的情况(N
= 50~100)。随着样本量的增大, 先是8个指标数的情况出现与这一结果的不一致现象,然后到 12个指标的组合情况。即中等以上的样本(在本研究中为N
≥ 500)与指标数交互影响分类精确性的表现, 所以不能忽略样本量的影响而单纯通过增多指标数来获得好的分类精确性。4.2 类别距离对Entropy的影响
类别距离是对模型分类精确性影响最大的因素(Lubke & Muthén, 2007; Lubke & Neale, 2006)。Lubke 和 Muthén (2007)发现, 较大的类别距离(MD= 1 vs. 1.5)可以得到更高的Entropy。Tein等(2013)也发现类似的结论(类别距离用 Cohen’d
表示, 分别为0.2, 0.5, 0.8, 1.5)。但本研究发现类别距离对分类精确性的影响依然受样本量的影响。小样本情况下(N
= 50~100), 类别距离越大, 分类精确性越好。但是对于更大的类别距离(MD = 3), Entropy明显高于其他类别距离下的结果, 分类错误率明显小于其他类别距离下的结果, 且具有跨样本量的一致性。随着样本量的增大, 类别距离为3的优势更加明显。当类别数较多的时候(本研究中k
= 5), 大类别距离(MD = 3)的作用更明显, 尤其是在指标数少或样本量大的条件下。显然, 要得到好的分类精确性, 且不用担心样本量的影响, 类别距离最好达到 3。另外, 尽管类别距离对 Entropy的变式 CLC、ICL_BIC、SaICL_BIC也有一定的影响, 但从这些变式的指数中可以发现类别距离对他们的影响比较小, 这主要是因为这些指标考虑了模型复杂程度,特别是公式包含对数似然值, 使得各因素对Entropy的影响被稀释了。因此, 在LPA/LCA分析中采用Entropy衡量精确性比其变式更灵敏。4.3 Entropy受多个因素影响很难确定唯一临界值
尽管 Entropy值与分类精确性高相关, 但其值随类别数、样本量和指标数的变化而变化, 很难确定唯一的临界值,这一结果与前人研究类似(Lubke& Muthén, 2007)。Entropy与分类精确率呈高相关,说明Entropy是个不错的衡量分类精确性的指标。同时Entropy作为一个单独的分类精确性指标比分类错误率更加方便, 正因为如此 Entropy在不同条件下的表现更具有实践意义。尽管Lubke和Muthén(2007,k
= 2)考虑协变量后的研究结果表明:Entropy < 0.60时相当于超过20%的个体存在分类错误; Entropy≥0.80表明分类准确率超过90%。但我们的研究发现, 类别数为 3的时候, Entropy <0.64时相当于超过 20%的个体存在分类错误,Entropy≥0.76时表明分类准确率超过 90%; 类别数为5时, Entropy < 0.68时相当于超过30%的个体存在分类错误, Entropy > 0.84时表明分类准确率超过 90%。本研究中的 3个类别(k
= 3)时的结果与Lubke和Muthén (2007) 2个类别(k
= 2)时的结果相近, 当类别数达到 5的时候, 差异比较大。由此可见, Entropy的表现不仅受协变量的影响, 还受类别数的影响。因此, 在选择哪个临界值作为 Entropy分类精确性的衡量指数时, 我们不仅要考虑有没有协变量的影响, 还要根据不同的类别数进行抉择。4.4 不足与展望
本模拟研究的不足主要有以下几个方面:首先,与其他模拟研究一样, 本研究的发现能否应用于模拟之外的模型。例如, 研究只考虑3和5个潜类别的情况, 对于其他潜类别的数量的研究不一定适用。其次, 我们主要考察的是 LPA, 以后的研究可以探索本研究的结果能否推广到其他混合模型。第三, 在当前仅有的一项考查了 Entropy与分类精确性的关系(Lubke & Muthén, 2007)的研究中, 违反局部独立性假设时Entropy分类精确性的问题并没有被探究。而在有些情况下, 局部独立性假设很难满足。将来的研究可以探究违反局部独立性时Entropy的表现。第四, 本研究考查的LPA模型并没有考虑协变量的情况, 将来的研究可以对协变量的影响进行系统考查。最后, 我们拟合的是真模型,在实践中可能存在高估或低估类别数的情况, 因此在误设模型下, Entropy的表现也是未来研究的一个重要议题。
5 结论与建议
总的来说, 本研究首次系统地研究了样本量、类别距离、指标数和类别数对分类精确性指标Entropy在LPA中的表现。随着LPA/LCA这些处理潜变量的统计模型的广泛应用, 本研究的结果对应用研究者而言有很大的参考价值。
基于本研究的发现, 下面总结了几点结论和为应用研究者建议。
(1) 由于 Entropy受多种因素影响, 实践中的模型各不相同, 因此不存在绝对的临界值。但当实际的模型与我们模拟的条件类似时可以参考表2和网络版附表1-2的Entropy值及对应的错误率。
(2) 其他条件不变的情况下, 样本量越大Entropy的值越小, 分类精确性越差。因此从分类精确性的角度来说, 样本量并非越多越好, 小样本进行LPA分析是可行。另外, 当小样本(N
=50~100)时,指标数越多Entropy的结果越好。因此, 实践中处理小样本时可以通过增加指标数来提高分类精确性。(3) 尽管本研究发现类别距离对分类精确性影响最大, 但实际分析之前是不知道分类距离的, 所以在实践中尽可能的抽取有代表性的样本并尽可能的扩大群体异质性。
致谢:
本文作者衷心感谢三位匿名评审专家对本文提出的修改意见和建议。感谢澳洲国立大学寿懿赟博士帮助修改英文摘要。Asparouhov, T., & Muthén, B. (2014). Auxiliary variables in mixture modeling: Three-step approaches using Mplus.Structural Equation Modeling: A Multidisciplinary Journal,21
, 329–341.Biernacki, C., Celeux, G., & Govaert, G. (2000). Assessing a mixture model for clustering with the integrated completed likelihood.IEEE Transactions on Pattern Analysis & Machine Intelligence, 22
, 719–725.Biernacki, C., & Govaert, G. (1997).Using the classification likelihood to choose the number of clusters
.Computing Science and Statistics
, 29, 451–457.Carragher, N., Adamson, G., Bunting, B., & McCann, S. (2009).Subtypes of depression in a nationally representative sample.Journal of Affective Disorders, 113
, 88–99.Celeux, G., & Soromenho, G. (1996). An entropy criterion for assessing the number of clusters in a mixture model.Journal of Classification
,13
, 195–212.Collins, L. M., & Lanza, S. T. (2009).Latent class and latent transition analysis: With applications in the social, behavioral,and health sciences
. London: John Wiley & Sons, Inc.Helzer, J. E., Kraemer, H. C., & Krueger, R. F. (2006). The feasibility and need for dimensional psychiatric diagnoses.Psychological Medicine, 36
, 1671–1680.Hou, J. T., Wen, Z. L., & Cheng, Z. J. (2004).Structural equation model and its applications.
Beijing: Education Science Press.[侯杰泰, 温忠麟, 成子娟. (2004).结构方程模型及其应用
.北京: 教育科学出版社.]Kim, S. Y. (2012). Sample size requirements in single- and multiphase growth mixture models: A Monte Carlo simulation study.Structural Equation Modeling, 19
, 457–476.Kyriakopoulos, M., Stringaris, A., Manolesou, S., Radobuljac,M. D., Jacobs, B., Reichenberg, A., … Frangou, S. (2015).Determination of psychosis-related clinical profiles in children with autism spectrum disorders using latent class analysis.European Child & Adolescent Psychiatry, 24
, 301–307.Lanza, S. T., Rhoades, B. L., Greenberg, M. T., Cox, M., &The Family Life Project Key Investigators. (2011). Modeling multiple risks during infancy to predict quality of the caregiving environment: Contributions of a person-centered approach.Infant Behavior and Development, 34
, 390–406.Lazarsfeld, P. F., & Henry, N. W. (1968).Latent structure analysis
. Boston: Houghton Mifflin.Lubke, G. H., & Miller, P. J. (2015). Does nature have joints worth carving? A discussion of taxometrics, model-based clustering and latent variable mixture modeling.Psychological Medicine, 45
, 705–715.Lubke, G., & Muthén, B. O. (2007). Performance of factor mixture models as a function of model size, covariate effects,and class-specific parameters.Structural Equation Modeling,14
, 26–47.Lubke, G., & Neale, M. C. (2006). Distinguishing between latent classes and continuous factors: Resolution by maximum likelihood?Multivariate Behavioral Research, 41
, 499– 532.Lubke, G. H., & Tueller, S. (2010). Latent class detection and class assignment: A comparison of the MAXEIG taxometric procedure and factor mixture modeling approaches.Structural Equation Modeling, 17
, 605–628.Marsh, H. W., Hau, K. T., & Wen, Z. L. (2004). In search of golden rules: Comment on hypothesis-testing approaches to setting cutoff values for fit indexes and dangers in overgeneralizing Hu and Bentler’s (1999) findings.Structural Equation Modeling, 11
, 320–341.McLachlan, G. J., & Peel, D. (2000).Finite mixture models.
New York, NY: Wiley.McClintock, M. K., Dale, W., Laumann, E. O., & Waite, L.(2016). Empirical redefinition of comprehensive health and well-being in the older adults of the United States.Proceedings of the National Academy of Sciences of the United States of America, 113
, E3071–E3080.Meehl, P. E. (1995). Bootstraps taxometrics: Solving the classification problem in psychopathology.American Psychologist, 50
, 266–275.Mokros, A., Hare, R. D., Neumann, C. S., Santtila, P., Habermeyer,E., & Nitschke, J. (2015). Variants of psychopathy in adult male offenders: A latent profile analysis.Journal of Abnormal Psychology, 124
, 372–386.Muthén, B. (2004). Latent variable analysis: growth mixture modeling and related techniques for longitudinal data. In D.Kaplan (Eds.),The SAGE handbook of quantitative methodology for the social sciences
(pp. 345–368).
Thousand Oaks, CA:Sage Publications.Muthén, L. K., & Muthén, B. O. (1998–2015).Mplus user’s guide (7.4 Ed.)
. Los Angeles, CA: Muthén & Muthén.Nylund, K. L., Asparouhov, T., & Muthén, B. O. (2007).Deciding on the number of classes in latent class analysis and growth mixture modeling: A Monte Carlo simulation study.Structural Equation Modeling, 14
, 535–569.Pastor, D. A., Barron, K. E., Miller, B. J., & Davis, S. L.(2007). A latent profile analysis of college students’achievement goal orientation.Contemporary Educational Psychology, 32
, 8–47.Paxton, P., Curran, P. J., Bollen, K. A., Kirby, J., & Chen, F. N.(2001). Monte Carlo experiments: Design and implementation.Structural Equation Modeling, 8
, 287–312.Peugh, J., & Fan, X. T. (2013). Modeling unobserved heterogeneity using latent profile analysis: A Monte Carlo simulation.Structural Equation Modeling, 20
, 616–639.Ruscio, J., Haslam, N., & Ruscio, A. M. (2006).Introduction to the taxometric method: A practical guide.
London: Routledge.Sterba, S. K. (2013). Understanding linkages among mixture models.Multivariate Behavioral Research, 48
, 775–815.Tein, J. Y., Coxe, S., & Cham, H. (2013). Statistical power to detect the correct number of classes in latent profile analysis.Structural Equation Modeling, 20
, 640–657.Tofighi, D., & Enders, C. K. (2008). Identifying the correct number of classes in growth mixture models. In G. R.Hancock & K. M. Samuelsen (Eds.),Advances in latent variable mixture models
(pp. 317–341). Greenwich, CT:Information Age Pub.Vannucci, A., Tanofsky-Kraff, M., Crosby, R. D., Ranzenhofer,L. M., Shomaker, L. B., Field, S. E., ... & Yanovski, J. A.(2013). Latent profile analysis to determine the typology of disinhibited eating behaviors in children and adolescents.Journal of Consulting and Clinical Psychology, 81
, 494–507.Wade, T. D., Crosby, R. D., & Martin, N. G. (2006). Use of latent profile analysis to identify eating disorder phenotypes in an adult Australian twin cohort.Archives of General Psychiatry, 63
, 1377–1384.Wang, M. C. (2014).Latent variable modeling with Mplus
.Chongqing: Chongqing University Press.[王孟成. (2014).潜变量建模与Mplus应用
. 重庆: 重庆大学出版社.]Wang, M. C., Bi, X. Y., & Ye, H. S. (2014). Growth mixture modeling: A method for describing specific class growth trajectory.Social Studies, 29
, 220–241.[王孟成, 毕向阳, 叶浩生. (2014). 增长混合模型——分析不同类别个体发展趋势.社会学研究, 29
, 220–241.]Wang, M., & Hanges, P. J. (2011). Latent class procedures:Applications to organizational research.Organizational Research Methods, 14
, 24–31.Widiger, T. A., Livesley, W. J., & Clark, L. A. (2009). An integrative dimensional classification of personality disorder.Psychological Assessment, 21
, 243–255.Widiger, T. A., & Samuel, D. B. (2005). Diagnostic categories or dimensions? A question for the diagnostic and statistical manual of mental disorders—fifth edition.Journal of Abnormal Psychology, 114
, 494–504.Wurpts, I. C., & Geiser, C. (2014). Is adding more indicators to a latent class analysis beneficial or detrimental? Results of a Monte-Carlo study.Frontiers in Psychology, 5
, 920.Yang, C. C. (2006). Evaluating latent class analysis models in qualitative phenotype identification.Computational Statistics& Data Analysis, 50
, 1090–1104.Zachar, P., & Kendler, K. S. (2007). Psychiatric disorders: a conceptual taxonomy.American Journal of Psychiatry, 164
,557–565.Zhang, J. T., Jiao, C., & Zhang, M. Q. (2010). Application of latent class analysis in psychological research.Advances in Psychological Science, 18
, 1991–1998.[张洁婷, 焦璨, 张敏强. (2010). 潜在类别分析技术在心理学研究中的应用.心理科学进展, 18
, 1991–1998.]附录:
数据生成与分析的Mplus
语句(指标数=4, 类别数=3,类别距离=0.5, 样本量=50)

