基于启发式规则的SPARQL本体查询
2017-01-18谭立威邵志清张欢欢蒋宇一胡芳槐
谭立威, 邵志清, 张欢欢, 蒋宇一, 胡芳槐
(华东理工大学信息科学与工程学院,上海 200237)
基于启发式规则的SPARQL本体查询
谭立威, 邵志清, 张欢欢, 蒋宇一, 胡芳槐
(华东理工大学信息科学与工程学院,上海 200237)
提出了基于启发式规则的SPARQL查询。用语言技术平台(LTP)解析出问句的依存分析树(DPT),然后对问句集的依存分析树进行统计和分析,总结出用于查询三元组抽取的启发式规则,利用这些规则去掉无意义的查询三元组,合并和重组意义不完整的查询三元组。查询三元组经过类映射、实例映射和属性映射得到本体三元组,形成SPARQL查询。用户在B/S结构的查询界面中提交中文自然语言问句,得到中间结果和问句结果。实验结果表明了该方法的有效性。
自然语言问句; 依存分析树; 三元组映射; SPARQL查询
本体能清楚地表示某一领域的分类(类和属性)和存储大量的知识(实例和实例关系),通过共享和交换知识在语义网中起着关键作用[1]。然而,为了查询本体内的知识,人们需要了解本体和本体查询语言,对普通用户显然不友好。由于问答系统的输入是更为自然的日常语言的问句,并且有能力直接返回针对用户提问的答案[2],因此结合本体和问答系统功能的基于本体的问答系统、问答模型或查询接口得到了越来越多的关注。
基于本体的自然语言查询关键在于自然语言问句到本体查询语言的转换。文献[3] 简单地使用语言技术平台(LTP)解析中文问句得到依存分析树,再根据本体元数据和经验找出词语间的映射关系得到本体三元组,效率较低。文献[4-5]中先生成查询三元组然后生成本体三元组。AquaLog在扩展性和方便程度上优于PANTO,但只支持23类问题。PANTO比AquaLog支持更多问题,但缺少AquaLog的其他特性[6]。选择不同的自然语言处理平台使得上述3种方法所处理的数据结构有所不同,PANTO利用Stanford Parser[7]解析问句得到的句法树作为算法的输入,AquaLog利用GATE[8]标注过后的问句作为算法输入,标注内容包括:动词的时态和名词的类别等。
本文提出了基于启发式规则的SPARQL本体查询,利用LTP解析问句生成依存分析树,提出了6条启发式规则用于从依存分析树中抽取查询三元组,提高了查询三元组的抽取效率。用户只需在B/S结构的查询界面提交中文自然语言问句,便能从本体库中检索出答案。为了便于验证和改进本文方法,中间结果即问句的查询三元组和本体三元组也作为查询结果的一部分返回给用户。
1 自然语言映射为SPARQL查询的一般步骤及分析
自然语言映射为SPARQL查询的一般步骤如图1所示,可概括如下:
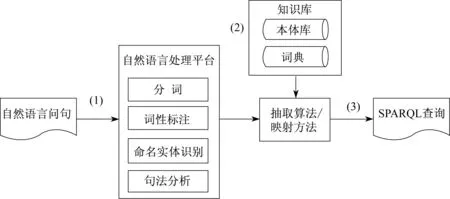
图1 自然语言问句映射为SPARQL查询的一般步骤Fig.1 General steps of mapping natural language question to SPARQL query
(1)利用自然语言处理平台对问句进行分词、词性标注、命名实体识别和句法分析等工作后得到问句的组件(命名实体、疑问焦点等)。
(2)构建本体库和词典。
(3)使用映射方法或抽取算法结合知识库和问句组件中得到SPARQL查询。
分析发现,在第3步抽取算法中,从问句中抽取查询三元组时,可用启发式规则来提高查询三元组的抽取效率,从而有利于提高整个映射过程的效率。
本文在一般步骤的基础上使用LTP的依存句法分析功能分析问句,得到问句的依存分析树,然后对问句集的依存分析树的标注关系进行统计和分析得到用于抽取查询三元组的启发式规则,通过这些规则和查询三元组抽取算法去掉了无意义的查询三元组,合并和重组了意义不完整的查询三元组。再利用本体库和字典,把查询三元组映射为本体三元组,最终形成SPARQL查询,整个流程如图2所示。本文在一般步骤的基础上作了如下改进:

图2 本文的自然语言问句映射为SPARQL查询的步骤Fig.2 This paper’s steps of mapping natural language question to SPARQL query
(1)对问句集的依存分析树的标注关系进行统计和分析,由此提出用于抽取查询三元组的启发式规则。
(2)设计查询三元组抽取算法并结合抽取规则从依存分析树中抽取查询三元组,然后经过类、实例和属性的映射得到本体三元组,组合后得到SPARQL查询。
(3)开发B/S结构系统提供用户查询界面,用户提交自然语言问句后,系统自动把问句映射为SPARQL查询,然后在本体库上执行,最终得到答案。
2 依存分析树及统计和分析
2.1 依存分析树
依存分析树由LTP解析问句后得到,它是查询三元组抽取算法的输入。LTP是一个处理中文的集成平台,拥有一系列自然语言处理模块,包括词法分析(分词、词性标注和命名实体识别)、句法分析和可视化工具等模块[9]。
本文的依存分析树(又称为依存结构树)不同于句法树,是利用LTP提供的WEB API对语句进行依存句法分析后生成,且以标注关系为边、词语为节点的有序树。句法树是依据上下文无关文法表示句子句法结构的有根节点的有序树[10],依存分析树识别了句子中的“主谓宾”、“定状补”这些语法成分,并分析了各成分之间的关系[11]。有序树是一棵有根节点的树,且树中每个节点的孩子节点的顺序是固定的。LTP依存句法标注关系有14种,如表1[11]所示。
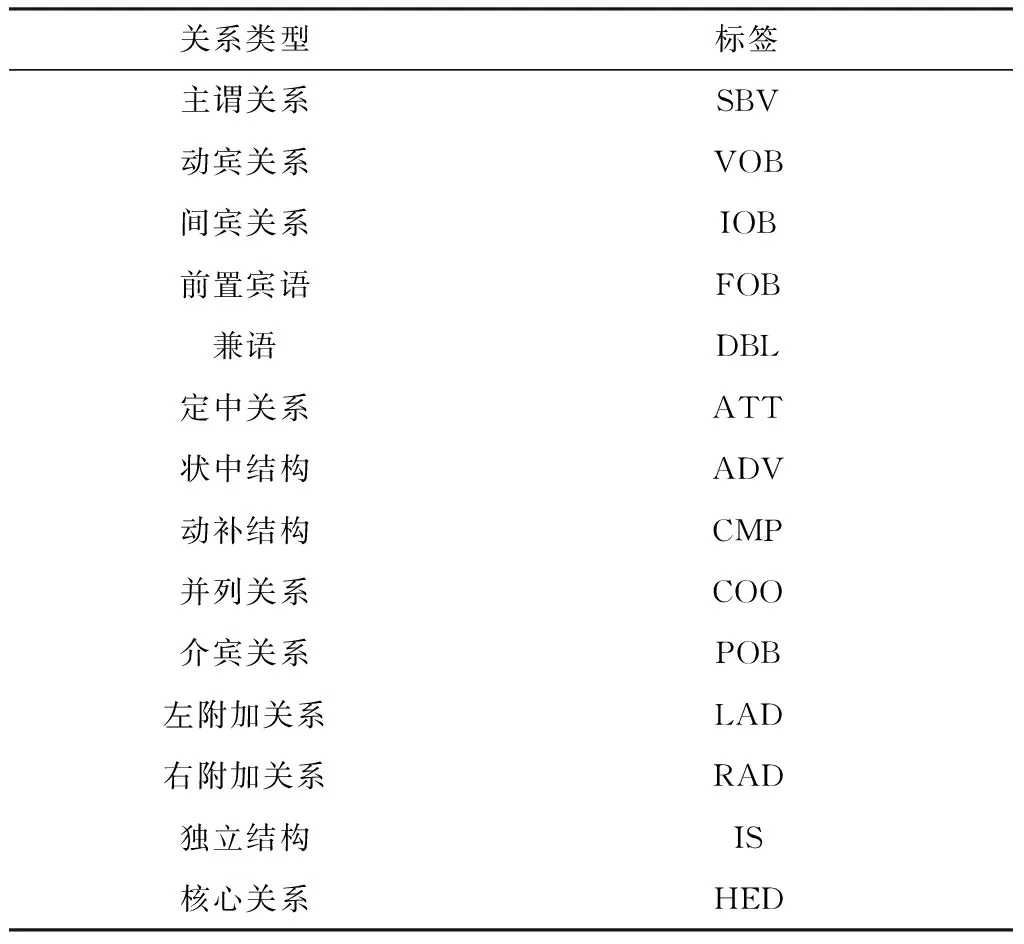
表1 LTP依存句法标注关系Table 1 LTP dependency relationships
例如:“阿里巴巴网络技术有限公司”经LTP分析后得到该句子的依存分析树,如图3(a)所示;图3(b)是该依存分析树对应的直观树形图。图3(a)中,节点“Root ”经弧“HED”指向单词“有限公司”,表示“有限公司”是核心单词,是这棵树实际上的根节点,简称为根单词,“Root”起头节点的作用。“有限公司”经弧“ATT”指向单词“阿里巴巴”,表示“阿里巴巴”和“有限公司”是定中关系。图3中其他关系可类推。
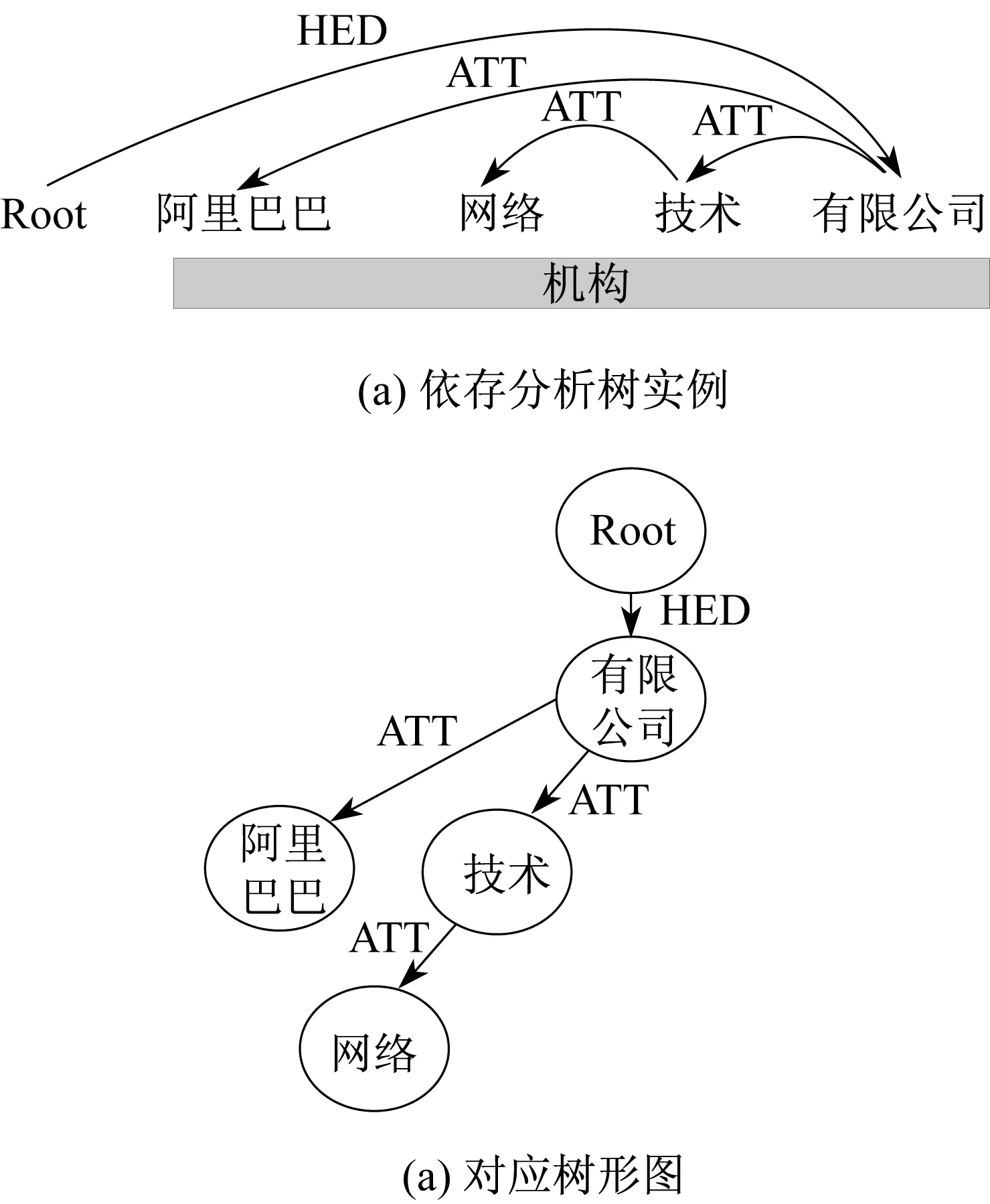
图3 依存分析树和对应的树形图示例Fig.3 ADPT and its tree structure
2.2 问句标注关系的统计和分析
以往的基于LTP的SPARQL本体查询方法缺乏对问句的标注关系的统计和分析,如文献[3,12]。问句的依存分析树中的标注关系体现了各词语间的依赖关系,是各个词语如何组成查询三元组的依据。除HED关系外,每一个标注关系都是一个候选查询三元组。基于标注关系的统计和分析有助于生成启发式规则,从而去掉无意义的查询三元组,合并和重组意义不完整的查询三元组,提高抽取查询三元组的效率。本文提出当查询三元组能独立地映射为本体三元组时,则认为该查询三元组是意义完整的。
查询三元组的形式为:<主语部分,谓语部分,宾语部分>,简写为<主语,谓语,宾语>。查询三元中3个部分的内容都是依存分析树中的单词,它的谓语可以为空,谓语为空时填入null,或者填入主语和宾语之间的标注关系。
哈工大信息检索研究中心语言技术平台中的问答系统问题集[13]包含机构、概念、人物等类别的问句,这些类别的问句能够与百度百科中的词条对应起来,而百度百科是本文实验系统的数据源之一,因此本文采用该问题集,对该问题集的标注关系进行统计和分析。调用LTP的WEB API的依存句法分析功能解析问题集中的629个问句,得到它们的依存分析树,然后统计各标注关系,并按照各标注关系出现的频率降序排列,排前10位的标注关系柱的状图如图4所示。
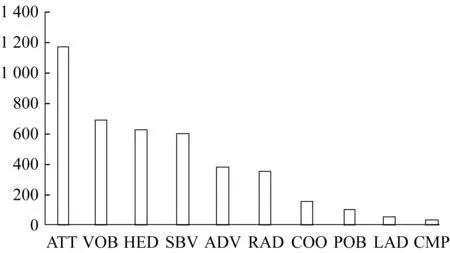
图4 特定问句标注关系的频率统计Fig.4 Frequency of certain dependency relationships
从图4可以看出,中文问句标注关系中出现频率最高的依次是定中关系(ATT)、动宾关系(VOB)、核心关系(HED)、主谓关系(SBV)、状中结构(ADV)和右附加关系(RAD),这6个标注关系是中文问句的主要标注关系,需要重点处理。6个标注关系转换成查询三元组的具体分析如下:
(1)ATT标注关系,简称为ATT关系,其他标注关系采用同样的方式进行简称。ATT关系修饰名词,起限定名词的作用,因此可直接抽取为查询三元组。当命名实体或行业名词被LTP解析成多个ATT关系时需要合并这些ATT关系成一个单词以表示一个整体。
(2)同一个动词对应的一对SBV关系和VOB关系分别转换成查询三元组时,缺少主语或宾语,意义不完整,这样的一对关系需要合并从而得到包含主谓宾意义完整的查询三元组。
(3)HED关系标识出查询三元组抽取的起始单词是哪个单词,对查询三元组的抽取无其他意义。
(4)RAD关系出现的频次高是因为助词“的”和各个名词构成的RAD关系在问句中频繁出现,这类关系所表达的含义隐含在各名词的ATT关系中,可直接去掉。比如在问句“公司的创始人是谁”经LTP解析后得到标注关系:<的,RAD,公司>和<公司,ATT,创始人>等标注关系。右附加关系<的,RAD,公司>的含义已隐含在定中关系<公司,ATT,创始人>中,因此可以直接去掉。
(5)ADV关系修饰形容词或动词,在本文的问题集中,ADV关系主要修饰形容词,表示程度、范围等,视情况决定是否要映射为查询三元组,这是因为ADV关系所描述的程度或范围等信息,本体库中常常没有与之直接对应的属性,也难以量化。
3 查询三元组的抽取规则与抽取算法
3.1 抽取规则与抽取算法
基于2.2节的分析,提出6条从依存分析树中抽取查询三元组的抽取规则如下:
(1)命名实体名词和行业名词在问句中表示一个整体概念,因此提出抽取规则:合并依存分析树中被拆分为多个单词的命名实体名词和行业名词。
(2)根据2.2节的分析(4)提出用于去掉无意义组合的抽取规则:去掉首单词为助词“的”的RAD关系。
(3)根据2.2节的分析(1)和本节抽取规则(1),提出抽取规则:当满足本节规则(1)且ATT关系对应的首尾单词都是名词时,一个ATT关系对应一个查询三元组。
(4)根据2.2节分析(2)提出合并意义不完整的查询三元组的抽取规则:一对SBV关系和VOB关系合并为一个查询三元组,简称为SBV-VOB查询三元组。
(5)当本节规则(4)中的SBV-VOB查询三元组修饰名词时,需要拆分SBV-VOB查询三元组再和被修饰的名词组成新查询三元组,因此提出用于重组查询三元组的抽取规则:当SBV-VOB查询三元组的谓语(动词)和某一名词存在ATT关系时,拆分SBV-VOB查询三元组,然后和ATT关系组成新查询三元组。
(6)依据就近原则,和疑问单词(比如:谁,哪里)在同一查询三元组内的主语或宾语为疑问焦点,得到以下抽取规则:查询三元组的主语或宾语为疑问单词时,对应的宾语或主语为疑问焦点。
抽取规则中,首单词为标注关系到达的单词,对应查询三元组的主语。尾单词为标注关系出发的单词,对应查询三元组的宾语,如图3中的标注关系<网络,ATT,技术>,“网络”是首单词,“技术”是尾单词,起连接作用的弧是ATT关系。
抽取算法描述如下:
输入:问句依存分析树
输出:问句查询三元组
(1)执行抽取规则(1)和规则(2)。
(2)根据HED关系找到依存分析树的根单词并把它作为参数传入第(3)步。
(3)传入的单词作为父单词,检索其孩子单词,若孩子单词为空则此趟遍历结束;否则,根据所有孩子单词和父单词的词性与标注关系抽取查询三元组。
(4)将第(3)步中的孩子单词作为参数传入第(3)步,递归处理孩子单词。
3.2 抽取规则与抽取算法的应用
以问句“阿里巴巴网络技术有限公司的创始人是谁”为例说明抽取规则的作用和抽取算法的执行过程。该问句的依存分析树如图5所示,其中阴影部分为LTP命名实体识别功能模块识别出来的机构实体。
第1步,合并机构实体名词“阿里巴巴网络技术有限公司”,去掉首单词为助词“的”的RAD关系<的,RAD,阿里巴巴网络技术有限公司>。
第2步,确定根单词为单词“是”,把该单词作为参数传入算法的第3步。
第3步,“是”的孩子单词非空,根据抽取规则(4),抽取出SBV-VOB查询三元组:
<创始人,是,谁>
第4步,“创始人”和“谁”分别作为参数传入第3步。
执行算法的第3步,“创始人”是传入参数,根据抽取规则(3),抽取出查询三元组:
<阿里巴巴网络技术有限公司,ATT,创始人>
执行算法的第4步,“阿里巴巴网络技术有限公司”传入第3步,该单词已无孩子单词,此趟遍历结束。
执行算法的第3步,“谁”是传入参数,它的孩子单词为空,此趟遍历结束,整个遍历随之结束。
例句的依存分析树中的7个标注关系(HED关系除外)对应7个候选查询三元组,抽取过程不是简单的依赖经验而是利用抽取算法和抽取规则去除了1个RAD关系、合并了3个ATT关系和1对SBV-VOB关系,提高了抽取效率,最后生成2个查询三元组。
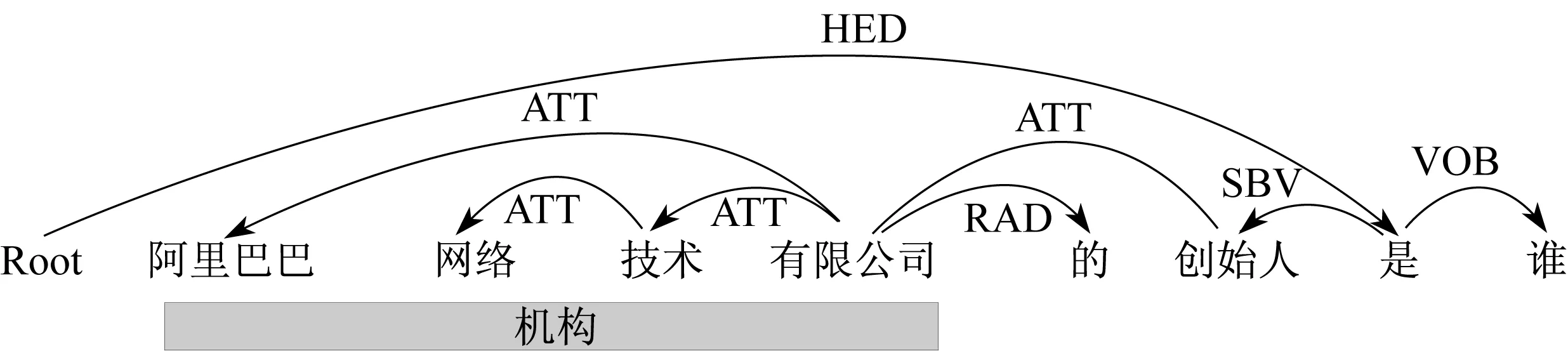
图5 “阿里巴巴网络技术有限公司的创始人是谁”的依存分析树Fig.5 DPT of question “a li ba ba wang luo ji shu you xian gong si de chuang shi ren shi shui”
4 映射本体三元组
4.1 SPARQL和词典
SPARQL[14]是一种RDF(Resource Description Framework)[15]查询语言,可以检索和操作RDF格式的数据。RDF是有向的、含标签的图数据格式,也是以三元组的形式表示和存储数据:<主语,谓语,宾语>。例如,通过三元组<谁,创作,红高粱>来表示问句“谁创作了《红高粱》”。RDF三元组可构成本体库,然后通过SPARQL语句查询本体库内的RDF数据。SPARQL的语法类似SQL,使用“SELECT”语句包含查询变量,“FROM”语句指出具体查询哪一个本体库,设置默认本体库后可省略“FROM”语句。“WHERE”语句块表示与查询变量相关的约束条件,约束条件也是通过三元组的形式表示。查询变量可以出现在三元组中任何一个位置上。上述问句可简单地映射为SPARQL查询语句:
PREFIX:
SELECT ?author
WHERE { ?author :created “红高粱”.}
为了实现查询三元组到SPARQL查询的映射需要借助词典。词典主要包括3部分:本体实体、通用词典、用户词典[16]。本体实体包含类(概念)、属性(关系)和实例(个体)。通用词典可以使用中文WordNet[17]和维基百科。用户词典是对通用词典的补充,补充新名词、术语等。例如:本体实体中包含词语“公司”,它对应的本体类“:Company”,即存在一条映射规则:<公司, :Company>。在通用词典中“公司”和“企业”是近义词,因此,结合本体实体和通用词典便可以推出新的映射规则:<企业,:Company>。问句“饿了么的网址”,经LTP解析后,机构名词“饿了么”会被解析为两个标注关系<了,RAD,饿>和<么,RAD,饿>,当“饿了么”作为机构名词加入用户词典后,便可以在抽取查询三元组和映射本体三元组时正确地识别为一个整体。
4.2 映射本体三元组
本体三元组也是通过三元组的形式表示:<主语,谓语,宾语>,但三元组内的主谓宾是本体元素:本体实体、查询变量和本体格式数据。每个查询三元组映射为本体三元组都需要3个步骤:映射主语、映射宾语、映射谓语。先映射主语和宾语再映射谓语。映射谓语时,谓语非空时根据主语、谓语和宾语映射谓语,谓语为空时则根据主语和宾语及它们之间的标注关系映射谓语。查询三元组映射为本体三元组有3类映射:类映射、实例映射和属性映射。
例如:3.2节中第1个生成的查询三元组<创始人,是,谁>在映射为本体三元组时,第1步映射主语 “创始人”,它对应本体类“:Person”,进行类映射,通过以下本体三元组描述该类映射:
?person rdf:type :Person
第2步映射宾语“谁”,它是疑问词,根据抽取规则(6)确定与它对应的主语“创始人”是疑问焦点,疑问词本身不需要做映射,从而也不需要进行第3步谓语映射,第1个查询三元组的映射结束。
类似的,3.2节中第2个查询三元组<阿里巴巴网络技术有限公司,ATT,创始人>映射为本体三元组时,第1步映射主语“阿里巴巴网络技术有限公司”,它对应本体实例,进行实例映射。该实例对应本体类“:Company”。实例名称为“阿里巴巴网络技术有限公司”,名称对应的本体属性为“:name”,“:name”的值即为实例名称。因此,通过以下两个本体三元组描述该实例映射:
?company rdf:type :Company
?company :name "阿里巴巴网络技术有限公司"
第2步映射宾语“创始人”,由图5可知,它和第1个查询三元组的主语是同一个词语且在之前的步骤中已经映射过,这里无须再映射。第3步映射谓语,ATT是主语和宾语之间的标注关系,说明谓语为空,主语是对应类“:Company”,宾语对应类“:Person”,根据类“:Company”和类“:Person”之间可能存在的属性和“创始人”的语义,把谓语映射为属性“:founder”,因此,通过以下本体三元组描述该属性映射:
?company :founder ?person.
本体三元组映射过程中需要的类(名)和属性(名)包含在本体库中。3.2节中的2个查询三元组按步骤,经过3类映射之后得到本体三元组,同时确定疑问焦点是“创始人”,因此SELECT语句中的查询变量设为“?person”,与生成的本体三元组组合后得到的SPARQL查询语句(查询结果为“马云”):
PREFIX rdf:http://www.w3.org/1999/02/22-rdf-syntax-ns#
PREFIX:http://cise.ecust.edu.cn/ontology#
SELECT ?person WHERE {
?person rdf:type :Person
?company rdf:type :Company.
?company :name "阿里巴巴网络技术有限公司".
?company :founder ?person.
}
5 实 验
实验使用本体编辑器Protégé5.0.0[18]设计本体库,采用Jena2.10.0[19]和Java程序向本体库中批量导入本体实例,使用SPARQL作为本体查询语言,利用LTP解析问句得到依存分析树。实验使用JSP和Tomcat6.0.39开发B/S结构系统方便用户提问,如图6。本体实例的数据源之一是百度百科词条,同时支持互动百科和中文维基百科,词条到本体实例的映射和本体库的构建,限于篇幅不再赘述。
文献[3]中的方法简单地利用了元数据和经验实现自然语言问句到SPARQL查询的转换,本文利用抽取算法和抽取规则去掉了无意义的查询三元组,合并和重组意义不完整的查询三元组,提高了抽取效率。以问句“北京经营电子商务的公司有哪些”为例,利用抽取算法和抽取规则去掉了一个RAD关系,合并了一个ATT关系和两对SBV-VOB关系,重组了一对SBV-VOB关系,问句的中间结果和答案如图6所示。该例句的处理过程类似3.2节的例句的处理过程。

图6 B/S结构查询界面Fig.6 Query interface based on B/S structure
实验主要针对经济本体、人物本体和城市本体这3个本体进行查询。实验数据如表2所示。
采用准确率评价本文方法,定义如下:
准确率=

表2 实验数据Table 2 Experimental data
实验中,对ATT关系、SBV关系和VOB关系的映射效果较好,对ADV关系的映射效果映射较差。因为ADV关系所描述范围和程度难以映射,例如问句:“哪些公司和华东理工大学比较近”,经LTP解析后得到ADV关系<比较,ADV,近>,如何定义“比较近”以及如何映射到本体库中都有待通过将来进一步的研究来解决。另一方面,由于本方法依赖LTP,当LTP解析依存分析树出现偏差时,后续的映射也出现错误。例如:“阿里巴巴网络技术有限公司的简称为什么”,目前为止,LTP都把“为什么”解析为疑问词,然而正确的解析是把“什么”解析为疑问词。
6 结束语
本文映射中文自然语言问句为SPARQL查询的方法,在一般步骤基础上,进一步对问句集的依存分析树进行统计和分析,提出了查询三元组抽取规则,设计并利用查询三元组抽取算法结合抽取规则从问句的依存分析树中抽取出查询三元组,提高了查询三元组的抽取效率。实验表明该方法的有效性。不过,该方法依赖于LTP,而LTP所生成的依存分析树存在偏差,针对这一情况我们将会研究人工修正和问句等价替换两种方法来处理这种情况。此外,本文主要分析处理了6种高频率的标注关系,其他标注关系也会在将来的工作中得到研究。
[1] CHANDRASEKARAN B,JOSEPHSON J R,BENJAMINS V R.What are ontologies,and why do we need them?[J].IEEE Intelligent Systems,1999,14(1):20-26.
[2] 孙昂,江铭虎,贺一帆,等.基于句法分析和答案分类的中文问答系统[J].电子学报,2008,36(5):833-839.
[3] CHANG Qingling,ZHOU Yuanchun,XU Shiting,etal.Research on ontology-based Chinese semantic retrieval model[C]// 2014 International Conference on Computational Science and Computational Intelligence (CSCI).USA:IEEE,2014:302-307.
[4] LOPEZ V,PASIN M,MOTTA E.AquaLog:An ontology-portable question answering system for the semantic Web[J].Lecture Notes in Computer Science,2005,3532:546-562.
[5] WANG Chong,XIONG Miao,ZHOU Qi,etal.PANTO:A portable natural language interface to ontologies[J].Lecture Notes in Computer Science,2007,4519:473-487.
[6] KARIM N,LATIF K,AHMED N,etal.Mapping natural language questions to SPARQL queries for job search[C]// 2013 IEEE Seventh International Conference on Semantic Computing.Irvine:IEEE,2013:150-153.
[7] KLEIN D,MANNING C D.Accurate unlexicalized parsing[C]// Proceedings of the 41st Annual Meeting on Association for Computational Linguistics.USA:ACM,2003:423-430.
[8] CUNNINGHAM H,MAYNARD D,BONTCHEVA K,etal.GATE:A framework and graphical development environment for robust NLP tools and applications[C]// Proceedings 40th Anniversary Meeting of the Association for Computational Linguistics (ACL).Philadelphia,USA:DBLP,2002:10-15.
[9] CHE Wanxiang,LI Zhenghua,LIU Ting.LTP:A Chinese language technology platform[C]// 23rd International Conference on Computational Linguistics.Beijing:DBLP,2010:13-16.
[10] Parsetree[EB/OL].[2015-07-20].https://en.wikipedia.org/wiki/Parse_tree.
[11] 语言技术平台[EB/OL].[2015-11-10].http://www.ltp-cloud.com/intro/.
[12] YIN Wenke,GE Weiyi,WANG Heng.CDQA:An ontology-based question answering system for Chinese delicacy[C]//2014 IEEE 3rd International Conference on Cloud Computing and Intelligence Systems (CCIS).Shenzhen:IEEE,2014:1-7.
[13] 刘挺.哈工大信息检索研究室对外共享语料库资源[EB/OL].[2015-09-22].http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm.
[14] PRUD’HOMMEAUX E,SEABORNE A.SPARQL query language for RDF[EB/OL].[1015-08-20].http://www.w3.org/TR/2008/REC-rdf-sparql-query-20080115/
[15] KLYNE G,CARROLL J J.Resource description framework (RDF):Concepts and abstract syntax[EB/OL].[2015-10-15].http://w3c.org/TR/rdf-concepts,2004.
[16] 张宗仁,杨天奇.基于自然语言理解的SPARQL本体查询[J].计算机应用,2010(12):3397-3400.
[17] 张俐,李晶皎,胡明涵,等.中文WordNet的研究及实现[J].东北大学学报(自然科学版),2004,24(4):327-329.
[18] Protégé[EB/OL].[2015-09-25].http://protege.stan-ford.edu/.
[19] Jena[EB/OL].[2015-10-20].http://jena.apache.org/documentation/ontology/.
SPARQL Ontology Query Based on Heuristic Rules
TAN Li-wei, SHAO Zhi-qing, ZHANG Huan-huan, JIANG Yu-yi, HU Fang-huai
(School of Information Science and Engineering,East China University of Science and Technology,Shanghai 200237,China)
This paper proposes an SPARQL ontology query based on heuristic rules.In the proposed method,LTP (Language Technology Platform) is utilized to parse a question to dependency parsing tree (DPT).Heuristic query triple extraction rules are formed according to the statistic and analysis of DPTs of question set.Query triple(s) are extracted accurately by deleting meaningless query triple(s) and recombining incomplete query triple(s) based on these rules.Query triple(s) are mapped to ontology triple(s) by means of three kinds of mapping:class mapping,instance mapping and property mapping.And then,SPARQL query is obtained.Intermediate results and answer will be presented to users when they submit a Chinese natural language question in the query interface.The experiment shows that the presented method is effective.
natural language question; dependency parsing tree; triple mapping; SPARQL query
1006-3080(2016)06-0851-07
10.14135/j.cnki.1006-3080.2016.06.016
2016-01-13
国家高技术研究发展“863”计划(2015AA020107)
谭立威(1988-),男,湖南郴州人,硕士生,主要研究方向为自然语言处理。E-mail:tanliweii@qq.com
邵志清,E-mail:zshao@ecust.edu.cn
TP39
A
