天体物理成团研究中的非规则访存优化*
2017-01-18司雨蒙韦建文文敏华林新华
郝 赫,司雨蒙,韦建文,文敏华,林新华,2+
1.上海交通大学 高性能计算中心,上海 200240
2.NVIDIA Technology Center Asia Pacific,Singapore 999002
天体物理成团研究中的非规则访存优化*
郝 赫1,司雨蒙1,韦建文1,文敏华1,林新华1,2+
1.上海交通大学 高性能计算中心,上海 200240
2.NVIDIA Technology Center Asia Pacific,Singapore 999002
HAO He,SI Yumeng,WEI Jianwen,et al.Optimizing irregular memory access in astrophysical clustering studies.Journal of Frontiers of Computer Science and Technology,2017,11(1):80-90.
HGGF(halo-based galaxy group finder)算法实现了基于暗物质晕的星系找群,在研究宇宙大尺度结构及宇宙的演化等领域中占有至关重要的地位。但由于数据规模的增长,急需对HGGF算法进行优化,以缩短运行时间。经分析,算法的热点部分耗时受到非规则访存的严重影响,因此针对算法的结构和非规则访存模型,提出了数据预排序方法,并分析了该方法如何影响访存过程。在此基础上,利用数据对齐、循环分解进一步优化访存效率,利用负载均衡和互斥变量私有化的方法提高了OpenMP的并行效率,最终将HGGF应用使用12线程加速11.6倍,同时取得了更好的可扩展性。主要有三点贡献:(1)分析了HGGF算法的非规则访存问题;(2)提出并分析了数据预排序方法;(3)使用数据对齐、循环分解、负载均衡、互斥变量私有化方法提高了HGGF应用的并行性能。
天体物理成团;非规则访存优化;数据预排序;并行计算
1 引言
随着天文观测能力的不断提高,天文数据急剧增加,其中星系的观测总量已经达到109量级。面对来自大型数字巡天计划的海量数据,如何从数据中迅速准确地提取所需要的内容,直接影响着天文学的发展和研究进程。其中,如何将可观测的星系和理论中不可见的暗物质晕联系起来,是天体物理研究中的重要难题之一[1]。天文学家利用计算机设计出多种Group-Finding算法来寻找同一暗物质晕中的星系。FOF(friends-of-friends)是Group-Finding算法中最早的算法之一[2],对于理解宇宙的结构和演化具有重大意义。HGGF(halo-based galaxy group finder)算法由FOF算法演变而来,虽然同样是对星系进行分类,但是HGGF算法是依赖暗物质晕的性质,能实现对某些孤立的星系和暗物质晕的联接[3]。HGGF算法还将亮度、红移距离、暗晕质量等性质共同作为筛选的依据,相比仅依靠距离的算法更有实际意义和准确性。
星系成团类算法基本步骤是预先指定星系中心,根据连接长度[4]逐个将星系样本分配到某一星系群,再反复迭代直到收敛,使用的数据结构多为基于指针的图或树,如FOF算法即基于K-D树[5]实现。虽然整体框架基本相同,但是HGGF算法使用数组替代指针作为主要数据结构,而在天文学或分子动力学的N体模拟问题中,粒子间的位置和连接关系往往非常复杂,使用数组的存储效率更高[6]。在HGGF算法的核心部分,由于连接体积和索引数组[7]的存在,主数组的访问顺序被彻底打乱,因此将HGGF算法的访存方式视为非规则访存。非规则访存算法通常表现出极少的数据局部性和数据重用,大量的动态非连续存储访问以及细粒度的同步或通讯[8],在现代处理器基于缓存的架构下,缓存的利用效率会对程序的性能起决定性作用。而非规则访存算法由于访问地址不连续,甚至是随机访问,缓存内的数据不能得到高效利用,加上CPU和内存之间的速度差异,即使CPU计算能力很强,也不能获得好的性能。
随着异构计算的发展,在科学计算或是工程计算中加速卡的使用已经非常普遍。人们尝试将HGGF应用移植到Intel公司的MIC(many integrated core)上,但是由于处理器的性能相比CPU差距较大[9],HGGF算法没有在MIC上取得理想的性能,需要进一步优化。
数据预取是通过优化局部性改善访存性能的常见方法。数据预取包括硬件预取和软件预取,硬件预取一般由编译器自动执行,而软件预取需要在代码中插入明显的预取指令[10]。我们使用了两种软件预取方法,但效果一般。经过进一步分析算法结构,发现主数组访存顺序同时受到连接体积和索引数组影响,因此采用了按转换坐标对输入数据预排序的方法,明显改善了数据局部性,减少了缓存未命中的次数,在单核上加速超过2倍。同时,利用OpenMP在单节点上实现了HGGF算法中筛选星系过程的多线程并行,并且从负载均衡、同步开销等方面对算法进一步优化,最终在12线程上获得11.6倍的加速,在将数据规模扩大16倍后,获得15倍加速。
综上,本文主要有以下三点贡献:
(1)分析了HGGF算法的非规则访存问题;
(2)提出并分析了数据预排序方法;
(3)使用传统方法提高了HGGF应用的并行性能。
本文组织结构如下:第2章介绍相关工作;第3章介绍HGGF算法及其访存模型;第4章详细介绍优化方法;第5章是实验环境及结果分析;最后总结全文,并提出下一步工作。
2 相关工作
目前,星系成团研究中对并行计算的使用还比较有限,现有工作局限在对FOF算法[11]、HOP算法[12]的研究中。文献[11]介绍了卡内基梅隆大学的Gibson等人利用Hadoop集群对超大天文数据集分解处理的DiscFinder方法。DiscFinder基于初始版本的FOF算法,通过Hadoop和MapReduce实现数据并行。文献[12]介绍了西北大学的Liu等人为HOP算法设计的并行方案。他们通过对K-D树进行域分解,利用MPI(message passing interface)实现了多节点多核的并行加速。HGGF算法与FOF算法和HOP算法相比计算精度更高,与实际观测数据更接近,在星系成团研究中的地位已得到广泛认可[13-14],但计算过程更复杂,数据依赖更多,尚未有文献对其模拟运算性能进行研究。HGGF算法利用OpenMP共享内存实现的多任务并行效率较低,并且算法中数据互相依赖造成外层循环难以拆分,本文并未如文献[12]采用多节点MPI并行,而是在深入分析算法结构后,针对访存问题和共享变量等问题给出多种优化方法,在单节点多核环境下获得很好的效果。
由于访存延迟常常严重影响程序性能,至今已有多种方法通过改善数据局部性优化访存性能,如缓存分块[15]、单指令多数据(single instruction multiple data,SIMD)[16]、预取技术等。本文所述方法既包括如数据对齐、循环分解等在文献[9,17]中记载的方法,也有针对算法特定结构提出的数据预排序方法。主数组-索引数组结构在N体模拟问题中应用广泛。文献[7]介绍的非规则访存模型中包含主数组-索引数组结构,其中提出的数据重排方法基于Inspector-Executor机制[18],通过在程序内插入预处理函数动态调整数据顺序。这种方法虽然更灵活,但由于大规模数值模拟计算中循环迭代次数太多,节省的时间不足以抵消Inspector函数的耗时。
本文所述数据预排序方法在计算前的预处理阶段根据索引数组特点重排输入数据,与文献[7]不同,对迭代次数多的大规模计算加速更明显,同时还区别于文献[19-20]中记载的直接排序方法,可应用于结构更复杂的访存模式。
3 HGGF算法及其非规则访存模型
3.1HGGF算法
本节将对算法的核心部分,同时也是程序热点部分(占总运行时间超过90%)进行详细介绍。
3.1.1 连接体积
文献[4]首次提出了连接体积的概念。每个星系在筛选时,本应遍历空间中所有其他星系,但若两星系间距超过特定阈值,根据经验它们不可能属于同一类,没有互相计算的必要。图1为星系分布的二维空间抽象图,每个点代表一个星系。图中有效半径外与圆心位置的星系肯定不同群,因此在后面的筛选过程中,只需计算球体(扩展到正方体)内的样本。
初始化连接体积的伪代码如下:

前面说的有效半径不是实际的空间距离,而是将三维空间转换成以L为边长的正方体(简称L空间)后按比例换算出的数值。式(1)中,x、y、z分别代表利用输入数据中星系的极坐标求得的直角坐标;x′、y′、z′为直角坐标经过放缩平移到L空间(0<x′,y′,z′<L)内的值,L′为经验常数。式(2)中,x″、y″、z″为x′、y′、z′的取整,函数Func的值为Volume数组的下标(后面统称为转换坐标),并且可以保证仅当x″、y″、z″都相等时,Func的值才会相等。由于x″、y″、z″为原浮点数坐标的取整,误差可能导致不同星系转换坐标相同,此时,Linklist数组会以类似链表的方式逐一记录下转换坐标相等的星系编号,若未与其他星系相同,由Volume数组记录星系编号。
Fig.1 Valid radius ofLspace图1 L空间内的有效半径

经过以上步骤,Volume和Linklist两个数组记录了所有的星系编号。进入筛选过程前,需要先确定有效半径内包含了哪些星系。本文将以当前星系为中心(多次迭代后为星系群的中心),二倍有效半径为边长(如图1虚线框)的正方体称为连接体积,则连接体积必然包含所有有效半径内的星系。建立索引数组时,按递增顺序筛选连接体积内的所有整数点,若该点的Func函数值刚好等于某一星系的转换坐标,则将Volume中的星系编号加入索引数组,伪代码如下:
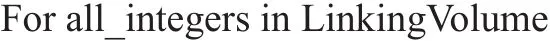
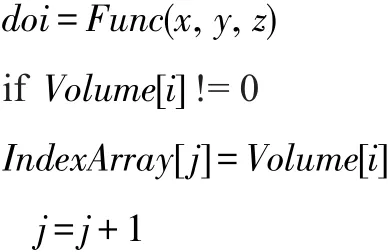
扫描结束后,连接体积内所有星系的编号都存入了索引数组。
3.1.2 遍历筛选星系
建立索引数组后进入筛选星系的过程,筛选的对象是连接体积内的星系,即索引数组和对应Linklist中存储的星系编号。判断星系是否同类的条件为式(3),Dist1为红移距离,Dist2为空间距离,p1、p2、p3、p4和r、x、y、z分别代表被筛选星系和中心星系的坐标。每次筛选过程需要两次判断,若红移距离不符合要求,则跳转到下一个星系,若满足条件,再判断空间距离,如果两个条件同时满足,则记录下该星系编号。此外,在每次筛选结束后会查看对应Linklist数组中是否存有其他星系。
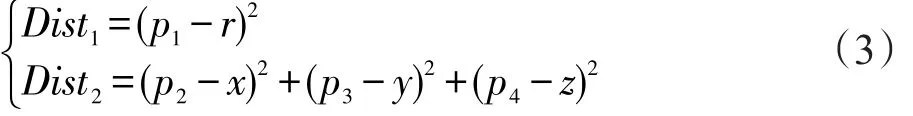
3.2 非规则访存模型
HGGF算法的非规则访存模型为二重循环,外层循环为当前分类数,随着星系成团的过程,星团数目会不断减少,两个内层循环分别对应上一小节建立索引数组和遍历筛选星系的过程。第一个内层循环建立的索引数组用作第二个内层循环中主数组的下标,每个外层循环索引数组根据当前星系编号对应更新,包含新的要筛选的星系。访存模型伪代码如下:

因为编译时主数组下标即索引数组的值不能立即获取,所以访存的顺序完全由索引数组决定,且连接体积内的星系离散分布在所有样本星系中。以最小输入数据为例,样本数为639 359个星系,则索引数组index的值不规则分布于区间1~639 359。主数组读取数据时,会按一个缓存行的大小(64 B)读入,即16个相邻的数组元素,但受索引数组的影响,访问地址不连续,需要的数组元素很难位于同一数据块中,这会严重影响缓存性能。因此,可将这种访存模式归为非规则访存。
4 优化方法
优化之前,使用VTune[21]测试出热点函数每行代码的具体耗时以及硬件性能计数器的数据。结果显示筛选星系过程耗时占热点函数的95%以上,因此优化工作主要针对这部分展开。
对于非规则访存问题,软件预取是优化局部性最常见的方法。由于没有明显性能提升,只简要介绍软件预取方法:通过插入具体预取指令,编译器可提前将数据读入缓存,并利用流水线上其他任务覆盖这部分开销。本文尝试了两种:
(1)使用#pragma prefetch指示编译器进行预取;
(2)使用intrinsic代码_mm_prefetch将数组元素预取到指定缓存。
从profile结果看,数据被成功预取,但开销不仅没有被覆盖,还和优化前一样。分析原因是需要预取的计算任务简单,流水线不能覆盖时间更长的访存开销[22]。
4.1 非规则访存优化
4.1.1 数据预排序
通过分析连接体积算法的原理可以发现,循环内主数组元素的访问顺序由索引数组决定,而索引数组作为Volume数组的子集,存储了当前星系有效半径内的所有星系编号(除转换坐标相等的星系由Linklist数组存储)。因为遍历连接体积时是按转换坐标从小到大的顺序,所以索引数组中星系编号的存储位置同样应该按转换坐标从小到大排列。设想一下,如果能让输入数据在程序开始前按同样顺序排好,则通过遍历连接体积内整数点得到的索引数组,其中的星系编号很可能已经是连续的,即1~639 359中的任意一个连续区间,但不包含转换坐标相等的星系。
原输入数据中星系的性质与转换坐标并没有直接关系,也没有与转换坐标顺序一致或相似的一列数据,因此只有通过对输入数据进行预处理,才能达到使输入数据按转换坐标有序的目的,这个预处理过程称之为数据预排序。从优化的思路来看,数据预排序与Inspector-Executor有一定相似之处,两种方法都是通过改变数据的分布来优化访存性能,但前者是在程序运行前通过预处理输入数据改变数据局部性,而Inspector-Executor是通过在程序中插入数据重排函数,动态改变数据的分布。
下面介绍数据预排序的具体操作方法。如图2,首先利用与原程序相同的算法求出所有星系的转换坐标,然后将得到的值按原输入数据顺序添加到文件中(原输入数据中没有转换坐标那一列,相当于给每个星系增加一个新的性质),再按转换坐标从小到大对输入文件按行排序,并作为新的输入文件,整个过程并不需要修改源程序的代码。

Fig.2 Procedure of data pre-sorting图2 数据预排序步骤
图3是数据预排序前后索引数组分配的抽象图,可看出预排序前,各星系编号被随机分配到索引数组中,这样读取数据时,由于星系编号差别很大,导致每次读入的一行数据中可能只有一个有效数据。预排序后,由于星系编号已经按转换坐标排序,会按顺序被分配到索引数组中,使得每次读入缓存的数据块中的全部数组元素都是本次循环或下个循环要被使用的数据。图4是数据预排序前后索引数组(阴影部分)及Linklist数组(突出部分)存储的星系编号,因为遍历的顺序类似于深度优先搜索,所以预排序后数组内星系编号可视为完全连续。虽然主数组-索引数组的结构未变,但是数据局部性已经彻底得到改善。

Fig.3 Distribution of index array图3 索引数组分配

Fig.4 Change of index and Linklist array图4 索引数组及Linklist数组变化
相比访存延迟的巨大额外开销,数据预排序本身的开销可以被抵消掉,而且仅通过一次预排序,可以为之后多次模拟实验节省时间,显然是可以接受的。
4.1.2 数据对齐
筛选星系过程的主数组是二维数组,记录了星系的全部16个性质,并且声明在内存的相邻位置,但是计算过程中只访问到16个元素中的前4个(三维坐标、红移距离),这会影响数据读取的效率。如图5(a)是数据未对齐时最好的情况,即一次将4个数组元素全部读入,但是浪费了后面的12个单元。图5(b)则是最差的情况,4个元素由于前端未对齐被分开,此时需要访问两次内存才能取出全部4个元素。图5(c)是使用数据对齐,并且将数组分开声明的情况,再配合数据预排序,一次可同时读入4组有效数据,比之前最差的情况效率提高8倍。
Fig.5 Data alignment图5 数据对齐
数据对齐方法:首先确保数组的起始地址对齐,使用可以将普通的内存分配和释放改写为对齐的intrinsic原语,即将malloc()改为_mm_malloc(),free()改为_mm_free(),由于刚好被16整除,不需要考虑后端对齐。
4.1.3 循环分解
由于CPU缓存空间有限,循环中无关数据过多可能使原本应保留在缓存中的数据被挤出,而换入的数据若再被换出,会形成恶性循环,导致有效数据总是不能保留在缓存中。如果将没有依赖关系的计算拆开,分成两个或多个循环,不仅可以提高各部分对缓存的利用效率,还可以分别展开进一步优化。
4.2 OpenMP并行效率优化
本文使用OpenMP对筛选星系过程实现并行,但在12线程上只加速不到4倍,因此使用了以下方法进一步优化算法。
4.2.1 负载均衡
为避免各线程任务分配不均,可利用OpenMP制导语句选项nowait或schedule实现任务的动态分配。加入选项后,编译器会根据各线程的执行情况动态分配任务,先执行完的线程会被分配新的任务。两种方法对HGGF算法的效果基本相同。
4.2.2 互斥变量私有化
因为程序中的部分操作和变量在迭代过程中只能串行执行或由多线程共享,所以需要使用锁机制避免该部分程序因为多线程并行出现读写冲突。OpenMP中实现互斥最常见的方法是使用指导选项#ompcritical或#ompatomic。添加指导选项后,同一时间只能有一个线程对互斥区进行访问。需要特别指出,atomic比critical虽然在性能上会有小幅提升,但由于atomic选项只能作用于简单语句,当互斥区内指令比较复杂时,可能造成结果错误。
虽然指导选项使用便捷,但线程间只能互相等待,严重影响程序并行效率。HGGF算法中互斥区内指令的作用是计数及记录星系编号,线程执行的先后顺序不影响最终结果。利用这个特点,将线程序号与数组下标结合,为每个线程单独声明一组变量,使得原来需要互斥访问的共享变量可以被各线程私有和同步读写,实现了线程间的完全并行。伪代码如下:

4.3 MIC移植介绍
MIC采用传统x86架构,拥有数十个精简核心,提供高度并行的计算能力,支持现有程序的平滑移植。MIC有灵活的编程模式,既可以用作协处理器,也可以作为独立的节点,Native和Offload是两种比较常见的模式[23]。但是,MIC并不总是能提供好的性能,其CPU核心不支持乱序执行,复杂算法在MIC上的表现一般。与传统多核CPU相比,MIC的SIMD和缓存对算法更敏感,访存密集或访存不规则的程序受到的影响更加严重。
为了进一步验证文中优化方法的有效性,以及探索未来程序向众核平台移植的可能性,在MIC的Natvie模式下测试了HGGF应用,仅比较并行部分的耗时,即使开启全部60个核上的60/120/180/240个线程,并行性能仍落后于CPU。
要在MIC上获得好的性能,往往需要从多方面进行优化。受到算法限制,缓存分块、单指令多数据等技术并不适用于HGGF算法。但考虑到同样是x86架构,前面介绍的优化方法应该也适用于MIC。因此本文将同样的优化方法应用在MIC的程序中,取得了与CPU上接近的加速比。
5 实验环境及结果分析
5.1 实验环境
5.1.1 数据集
原始HGGF算法已经在单线程机器上验证并使用过。其使用的输入数据是基于P3M算法得到的仿真数据[24],输出数据正确性可由2度视场星系红移巡天计划(2-degree Field Galaxy Redshift Survey,2dFGRS)和斯隆巡天计划(Sloan Digital Sky Survey,SDSS)数据验证。在本次并行化的升级算法中,将和原来的单线程结果相互比较验证。
5.1.2 软硬件环境
实验的硬件环境如表1所示,软件环境如表2所示。

Table 1 Hardware表1 硬件环境

Table 2 Software表2 软件环境
5.2 结果分析
5.2.1 非规则访存优化
为了验证数据预排序对访存性能的影响,利用VTune测出了程序单核运行时的各级缓存丢失率。从表3中可以看出,使用该方法后,各级缓存丢失率均有明显下降。这说明数据预排序已经改善了局部性,使得CPU每次都能读取更多的有效数据,与本文的分析基本一致。

Table 3 Cache miss rate during pre-sorting表3 预排序前后缓存丢失对比 %
确认了预排序方法的作用后,又在多线程上测试了程序的运行时间。如图6,单独使用预排序方法时(红色线),单线程上的加速效果最明显,有1.9倍加速,而使用全部12个线程后,仅有1.2倍加速。原因是使用多核并行后,每个核有独立的一、二级缓存,等效于每次循环可将更多数据读入缓存,削弱了数据预排序的效果。此外,数据对齐和缓存分解方法是已有记载的优化方法,不仅针对单一访存模型,无需在此详细分析。使用全部3种非规则访存优化方法(蓝色线)的运行时间,相比仅使用预排序方法有1.2倍加速,在不同核数上加速效果基本相同。因为核数增多后,数据预排序加速效果减弱,所以设计了使用更大数据集的实验。如图7,数据规模从1到16倍,预排序的加速比从1.2倍增加到1.6倍。原因是随着数据规模扩大,缓存容量再次不足,数据预排序的效果逐渐回升,证明其弱可扩展性较好。

Fig.6 Strong scalability of memory optimization图6 访存优化强可扩展性
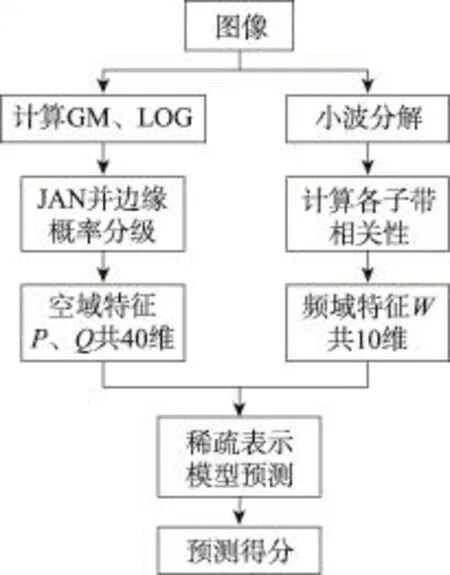
Fig.7 Weak scalability of data pre-sorting图7 数据预排序弱可扩展性

Fig.8 Strong scalability of OpenMP optimization图8 OpenMP并行优化强可扩展性
5.2.2 OpenMP并行效率优化
如图8,分别测试了负载均衡(红色线)和互斥变量私有化(蓝色线)两种方法的运行时间。可以看出负载均衡对性能的提升并不明显,只有5%左右,说明原算法线程任务分配已经比较均匀。而互斥变量私有化随着使用核数的增加加速效果越来越明显,12线程直接加速2倍,这也说明原算法中互斥区的存在严重影响了线程的并行。
最后来看一下综合所有优化方法的加速效果及可扩展性。如表4,优化后12线程的加速比为11.6倍,相比优化前仅有3.9倍的加速有了大幅提高。而优化后整个程序(不仅Kernel部分)的加速比也达到8倍。图9显示了程序经整体优化后弱可扩展性良好。
5.2.3 MIC优化结果
本文分别测试了使用数据预排序方法和全部优化方法在MIC上的运行时间。如图10,仅使用数据预排序时,最多加速1.4倍,但不同线程数的加速效果相差不大,主要是因为在MIC上每个核最多可开启4个线程,虽然线程数不同,但是使用的核数都是60个,所以并未改变缓存的容量,就不会对数据预排序的效果产生影响。使用全部优化方法后,最多在240个线程上加速2.2倍,主要原因是线程越多,互斥变量私有化方法的效果越明显。

Table 4 Speedup of all optimizations表4 所有优化方法加速情况

Fig.9 Weak scalability of final optimization图9 最终优化弱可扩展性
Fig.10 Result on MIC图10 MIC测试结果
6 总结与下一步工作
本文通过对天文应用Halo-based Galaxy Group Finder进行分析与优化,归纳出算法核心部分的非规则访存模型,并对该类型问题使用数据预排序方法优化访存性能,取得了不错的优化结果。还分析了数据预排序方法对该非规则访存模型产生影响的原因,为类似的访存问题提供了新的优化思路和方法。在数据预排序的基础上,使用了几种传统优化方法:(1)使用数据对齐、循环分解优化访存性能;(2)使用负载均衡、互斥变量私有化提高算法的并行效率。综合上述方法,在单节点12个线程上对HGGF应用加速11.6倍,并且随着数据规模的扩大,加速效果更加明显。将HGGF应用以本地模式移植到MIC卡上,并测试了性能,验证了本文优化方法的有效性。综上,本文的优化成果对于HGGF应用涉及的天文学问题的研究将有很大帮助,也为相似访存类型应用提供了更多优化途径。
在下一步工作中,将继续通过优化算法改善其数据局部性和可扩展性,并利用多节点(MPI)或异构平台(CPU+GPU,CPU+MIC)进行加速。
致谢感谢上海交通大学高性能计算中心提供的实验环境。感谢上海交通大学物理与天文系杨小虎教授在程序优化过程中的悉心指导,以及对本文的修改意见。
[1]Yang Xiaohu,Mo H J,van den Bosch F C,et al.A halobased galaxy group finder:calibration and application to the 2dFGRS[J].Monthly Notices of the Royal Astronomical Society,2005,356(4):1293-1307.
[2]Huchra J P,Geller M J.Groups of galaxies:I-nearby groups [J].TheAstrophysical Journal,1982,257:423-437.
[3]Yang Xiaohu,Mo H J,van den Bosch F C,et al.Galaxy groups in the SDSS DR4.I.the catalog and basic properties [J].TheAstrophysical Journal,2007,671(1):153.
[4]Eke V R,Baugh C M,Cole S,et al.Galaxy groups in the2dFGRS:the group-finding algorithm and the 2PIGG catalogue[J].Monthly Notices of the Royal Astronomical Society,2004,348(3):866-878.
[5]Shevtov M,Soupikov A,Kapustin A.Highly parallel fast KD-tree construction for interactive ray tracing of dynamic scenes[J].Computer Graphics Forum,2007,26(3):395-404.
[6]Badawy A H,Aggarwal A,Yeung D,et al.The efficacy of software prefetching and locality optimizations on future memory systems[J].Journal of Instruction-Level Parallelism,2004,6(7).
[7]Lin Yuan,Padua D.Analysis of irregular single-indexed array accesses and its applications in compiler optimizations [C]//LNCS 1781:Proceedings of the 2000 Joint European Conferences on Theory and Practice of Software,Berlin, Mar 25-Apr 2,2000.Berlin,Heidelberg:Springer,2000: 202-218.
[8]Hennessy J L,Patterson D A.Computer architecture:a quantitative approach[M].San Francisco,USA:Morgan Kaufmann Publishers Inc,2011.
[9]Lin Xinhua,Li Shuo,Zhao Jiaming,et al.Node-level memory access optimization on Intel Knights Corner[J].Computer Science,2015,42(11):37-42.
[10]Gornish E H,Granston E D,Veidenbaum A V.Compilerdirected data prefetching in multiprocessors with memory hierarchies[C]//Proceedings of the 25th International Conference on Supercomputing Anniversary Volume,Tucson, USA,May 31-Jun 4,2011.New York:ACM,2014:128-142.
[11]Fu Bin,Ren Kai,Lopez J,et al.DiscFinder:a data-intensive scalable cluster finder for astrophysics[C]//Proceedings of the 19th International Conference on High Performance Distributed Computing,Chicago,USA,Jun 20-25,2010. New York:ACM,2010:348-351.
[12]Liu Ying,Liao Weikeng,Choudhary A.Design and evaluation of a parallel HOP clustering algorithm for cosmological simulation[C]//Proceedings of the 17th International Parallel and Distributed Processing Symposium,Nice,France,Apr 22-26,2003.Piscataway,USA:IEEE,2003:82.
[13]Faltenbacher A,Li Cheng,Mao Shude,et al.Three different types of galaxy alignment within dark matter halos[J]. TheAstrophysical Journal Letters,2007,662(2):L71-L74.
[14]Yang Xiaohu,Mo H J,van den Bosch F C.Galaxy groups in the SDSS DR4.II.halo occupation statistics[J].The Astrophysical Journal,2008,676(1):248-261.
[15]Nishtala R,Vuduc R W,Demmel J W,et al.When cache blocking of sparse matrix vector multiply works and why [J].Applicable Algebra in Engineering,Communication and Computing,2007,18(3):297-311.
[16]Knobe K,Lukas J D,Steele G L.Data optimization:allocation of arrays to reduce communication on SIMD machines [J].Journal of Parallel and Distributed Computing,1990,8 (2):102-118.
[17]Hager G,Wellein G.Introduction to high performance computing for scientists and engineers[M].Boca Raton,USA: CRC Press,Inc,2010.
[18]Arenaz M,Tourino J,Doallo R.An inspector-executor algorithm for irregular assignment parallelization[C]//LNCS 3358:Proceedings of the 2nd International Symposium on Parallel and Distributed Processing and Applications,Hong Kong,China,Dec 13-15,2004.Berlin,Heidelberg:Springer, 2005:4-15.
[19]Oh G H,Kim J M,Kang W H,et al.Reducing cache misses in hash join probing phase by pre-sorting strategy[C]//Proceedings of the 2012 SIGMOD International Conference on Management of Data,Scottsdale,USA,May 20-24,2012. New York:ACM,2012:864-864.
[20]Abouzied A,Abadi D J,Silberschatz A.Invisible loading: access-driven data transfer from raw files into database systems[C]//Proceedings of the 16th International Conference on Extending Database Technology,Genoa,Italy,Mar 18-22,2013.New York:ACM,2013:1-10.
[21]Wang P.How to use Vtune amplifier XE 2013 on Intel Xeon Phi coprocessor[R/OL].Intel Corporation(2012)[2015-10-19].https://software.intel.com/zh-cn/blogs/2012/11/05/vtuneamplifier-xe-2013-intel-xeon-phi-coprocessor?language=it. [22]Lee J,Kim H,Vuduc R W.When prefetching works,when it doesn’t,and why[J].ACM Transactions on Architecture and Code Optimization,2012,9(1):2.
[23]Jeffers J,Reinders J.Intel Xeon Phi coprocessor high performance programming[M].Beijing:Posts and Telecom Press,2014.
[24]Jing Y P,Suto Y.Triaxial modeling of halo density profiles with high-resolutionN-body simulations[J].The Astrophysical Journal,2002,574(2):538-553.
附中文参考文献:
[9]林新华,李硕,赵嘉明,等.Intel Knights Corner的结点级内存访问优化[J].计算机科学,2015,42(11):37-42.
[23]Jeffers J,Reinders J.Intel Xeon Phi协处理器高性能编程指南[M].北京:人民邮电出版社,2014.

HAO He was born in 1989.He is an M.S.candidate at Shanghai Jiao Tong University.His research interest is high performance computing.
郝赫(1989—),男,辽宁锦州人,上海交通大学硕士研究生,主要研究领域为高性能计算。

SI Yumeng was born in 1992.He is an M.S.candidate at Shanghai Jiao Tong University.His research interest is high performance computing.
司雨蒙(1992—),男,山西晋城人,上海交通大学硕士研究生,主要研究领域为高性能计算。

WEI Jianwen was born in 1986.He is an assistant engineer at the Center for High Performance Computing of Shanghai Jiao Tong University.His research interest is high performance computing.
韦建文(1986—),男,广西百色人,上海交通大学高性能计算中心助理工程师,主要研究领域为高性能计算。

WEN Minhua was born in 1988.He is an assistant engineer at the Center for High Performance Computing of Shanghai Jiao Tong University.His research interest is high performance computing.
文敏华(1988—),男,江西会昌人,上海交通大学高性能计算中心助理工程师,主要研究领域为高性能计算。

LIN Xinhua was born in 1979.He is the vice director at the Center for High Performance Computing of Shanghai Jiao Tong University.His research interests include computer architecture and code optimization.
林新华(1979—),男,浙江绍兴人,上海交通大学高性能计算中心副主任,主要研究领域为体系结构,代码优化。
Optimizing Irregular MemoryAccess inAstrophysical Clustering Studies*
HAO He1,SI Yumeng1,WEI Jianwen1,WEN Minhua1,LIN Xinhua1,2+
1.Center for High Performance Computing,Shanghai Jiao Tong University,Shanghai 200240,China
2.NVIDIATechnology CenterAsia Pacific,Singapore 999002
+Corresponding author:E-mail:james@sjtu.edu.cn
Halo-based galaxy group finder(HGGF)tries to find galaxies in the same dark matter halo which is not directly visible.It plays a very important role in the research of large-scale structure of the universe.However,because of the growth of data scale,it’s extremely necessary to increase the running speed by optimizing the group finder coding algorithm.After a thorough investigation on the original HGGF code,it is found that the kernel part of the algorithm is seriously affected by the irregular memory access.This paper proposes a specific data pre-sorting approach and analyzes how it affects the process of memory access according to the structure of the algorithm and the irregular memory access pattern.Moreover,this paper uses data alignment and loop fission to optimize the memory access as well as improving the efficiency of OpenMP with load balance and mutex privatization.Eventually the HGGF application gets 11.6 times speedup on 12 threads,and gets better weak scalability.The following is the original contributions:(1)Analyze the irregular memory access of the HGGF application;(2)Propose and analyze the data pre-sorting;(3)Improve the parallel performance of HGGF application with another four approaches including data alignment,loop fission,load balance and mutex privatization.
A
:TP391
10.3778/j.issn.1673-9418.1512078
*The National High Technology Research and Development Program of China under Grant No.2014AA01A302(国家高技术研究发展计划(863计划));the Project of Japan Society for the Promotion of Science RONPAKU Fellowship(日本学术振兴会项目).
Received 2015-11,Accepted 2016-01.
CNKI网络优先出版:2016-01-07,http://www.cnki.net/kcms/detail/11.5602.TP.20160107.1540.008.html
Key words:astrophysical clustering studies;optimizing irregular memory access;data pre-sorting;parallel computing
