基于密度聚类算法的学术资源热点发现方法研究
2017-01-11孙艳超邹盼盼陈德军
赵 楠,刘 振,孙艳超,邹盼盼,陈德军
(1.中国船舶重工集团公司第七二二研究所,湖北 武汉 430205;2.武汉理工大学 信息工程学院,湖北 武汉 430070)
基于密度聚类算法的学术资源热点发现方法研究
赵 楠1,刘 振1,孙艳超1,邹盼盼2,陈德军2
(1.中国船舶重工集团公司第七二二研究所,湖北 武汉 430205;2.武汉理工大学 信息工程学院,湖北 武汉 430070)
针对学术会议产生的爆炸式学术资源共享下用户如何快速准确地获取当前研究热点的问题,提出了一种改进的基于密度的聚类算法DBSCAN,实现学术资源热点的自动发现,即通过合并具有明显关系的关键词以缩减特征项,以及解决公共资源对象邻域的重复获取问题,从而在一定程度上提高聚类的准确率和时间效率。结果表明,上述方法能够快速准确地发现当前相关领域的研究热点,有助于了解当前各学科的研究热点,并对传播学术成果具有重要意义。
热点发现;向量空间模型;密度聚类算法
20世纪70年代以来,随着中国经济的持续增长和社会的不断进步,科学研究也取得了飞速发展,各种学术会议如雨后春笋般持续增多,为推动我国经济发展和社会进步发挥了重要作用。然而,当用户面对各类学术会议产生的大量学术共享资源时,想要快速获取当前的研究热点并掌握相关领域的发展趋势却非常困难。显而易见,通过人工整理分析获取研究热点的方式,对于如今海量信息资源来说无疑是事倍功半甚至是极其低效的。所以,亟需通过高效的文本聚类技术将海量的学术资源信息分成若干有意义的类簇,实现资源热点的自动发现,从而使用户无需自行搜索分析就可以准确了解到当前的研究热点。
近年来,国内外学者对该问题进行了大量研究,取得了丰硕的成果[1-6]。传统的热点话题发现通常采用基于增量K-Means算法和凝聚层次聚类算法。基于划分的聚类方法虽然时间效率高但是不能处理噪声,且需要人为地事先确定分类结果个数,即输入参数k,这对于未知资源的聚类是不现实的;基于层次的聚类方法虽然不需要人为地事先确定分类结果个数,但是一旦某对象被划分为某一类就不能更改,这对于聚类质量有一定的影响;基于密度的聚类方法可以发现各种不同形状的类簇、不需事先确定分类结果个数并且能够识别噪声,是综合性能较好的聚类方法。针对学术会议资源的特点,笔者提出了一种基于密度的文本聚类方法实现资源热点的自动发现,即采用向量空间模型来结构化资源文本;然后通过改进的DBSCAN聚类方法自动发现资源热点,即通过合并具有明显包含关系的特征词以及解决公共资源对象邻域的重复获取问题,从而在一定程度上提高聚类的准确率和时间效率。
1 基于时间效率的DBSCAN算法改进
1.1 文本表示模型(VSM)
20世纪60年代末由SALTON等提出的向量空间模型(vector space model,VSM),搭建了自然语言与数学模型之间相互转换的桥梁。其基本思想为:忽略词语之间的相关性,用向量代表文本。只考虑语料统计,不考虑语义影响,简化了文本中关键词的相互关系,从而能够以向量之间的距离来判断文本与文本之间相似与否。向量空间模型能够应用在信息检索、文本分类等领域[7-10]。建立向量空间模型的基本过程为:不考虑特征项在文本中的出现顺序以及相互之间的关系,从而文本被表示成若干个独立的特征项集合。用此集合构造出一个高维空间,该空间的维即为各个特征项,那么文本就可以用此空间中的向量表示。而特征项对于文本的重要程度即为特征项权重,该权重即为文本特征向量的值,然后通过计算文本向量之间的余弦相似度来判断文本是否相似。向量空间模型将文本数据转变成可计算的结构化数据,从而通过计算向量之间的相似度解决文本之间的相似性问题。
1.2 基于密度的聚类方法(DBSCAN)
DBSCAN(density based spatial clustering of applications with noices)是一种经典的基于密度的聚类算法。当在给定半径Eps的区域内对象数目超过密度阈值MinPts,就合并到相近的类中,从而实现密度相似的对象聚类。在DBSCAN算法中,定义数据集合D中的对象p和q之间的距离函数为dist(p,q)。
DBSCAN算法的目的是发现密度相连对象的最大集合。DBSCAN算法的步骤为:首先扫描输入对象集合,判断每个输入对象是否为核心对象,并找到核心对象的Eps邻域NEps(p)中直接密度可达集合;通过对核心对象的所有直接密度可达对象进行密度可达对象的合并,从而找到密度相连对象的最大集合,实现基于密度的对象聚类。
1.3 基于时间效率的DBSCAN算法改进
从DBSCAN算法可知,其聚类过程需要遍历对象集中每个对象的Eps邻域,从而保证每个对象都被标记为某类。而在实际情况中很多对象的Eps邻域都相互交叉,即某个对象同时存在于几个对象的Eps邻域中,如图1所示[11]。
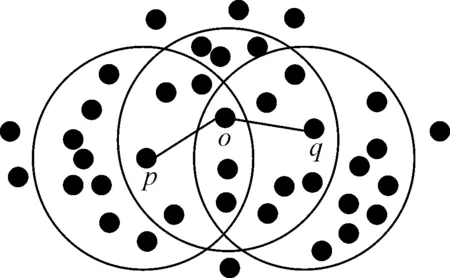
图1 邻域交叉的核心对象
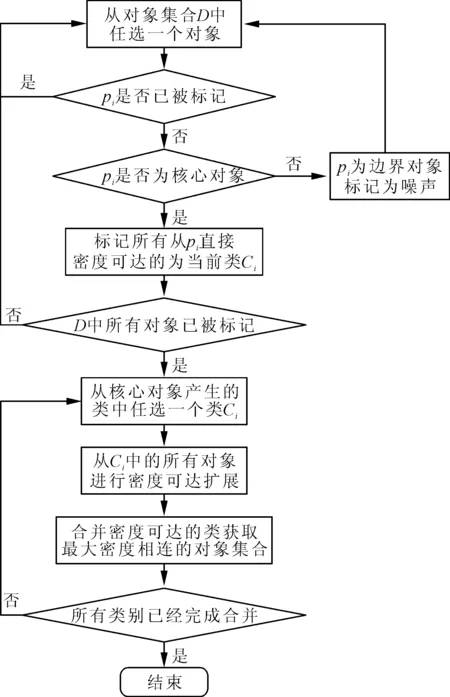
图2 改进的DBSCAN算法流程图
在图1中,对象p、o和q都是核心对象,而这3个对象的Eps邻域相互之间都要交叉,存在一些公共对象。笔者将针对公共对象的邻域重复获取问题对DBSCAN聚类算法进行改进。具体思路为:在获取对象集中各个对象的Eps邻域前,先判断此对象是否已被标记为某个对象Eps邻域中的对象,如果有则获取该对象的Eps邻域,否则判断下一个对象,以此来避免对公共对象重复获取其Eps邻域,从而减少获取次数和时间。改进的DBSCAN算法流程图如图2所示。
2 基于改进DBSCAN学术资源热点发现
由改进的DBSCAN算法可知,需要先将学术会议共享资源文本表示成向量空间模型,然后进行基于文本相似度的密度聚类,从而获取资源热点。笔者将资源按学科类别分别聚类,这样在一定程度上降低了语义的干扰,同时大大缩小聚类的规模,提高了聚类的时间效率。资源聚类过程如图3所示。
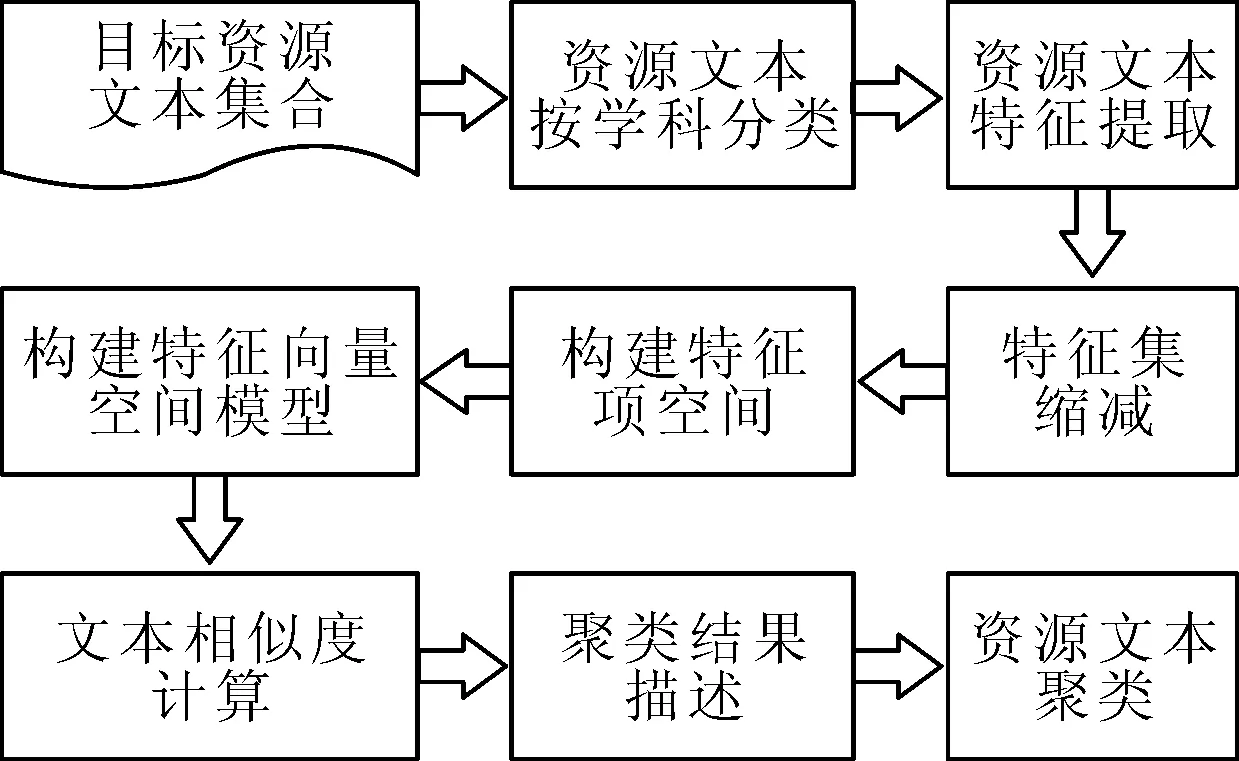
图3 资源聚类过程
(1)资源文本按学科分类:将目标资源文本集合按学科进行分类后,在某学科下进行相应的资源聚类,这种“先分类再聚类”在一定程度上提高了聚类的准确性和时间效率。
(2)文本特征提取:每个资源都有相应的标题、关键字和摘要等信息,这些信息都是作者细心提炼而成的,能够反映出对应资源的主要思想。而其中每个资源的关键字最为精炼重要,因此选取关键字作为资源的特征项。
(3)特征集缩减:根据关键字选取的特征项数目会随着资源数目的增加而不断增加,因此需要对获取的特征集进行缩减,取特征项在所有资源文本中出现次数较多的前n个组成特征集。n值需要根据目标资源的个数进行适当选取,因为当n过大时,会引入冗余,使聚类准确性不够;而当n过小时,包含的特征信息不够,不能很好地区分不同的类。与此同时,删减掉无意义的、词频较低的关键词外,还需对具有明显包含关系的关键词进行合并,从而在一定程度上提高聚类结果的准确率。
(4)构建特征项空间:根据缩减后的特征集建立特征项空间(T1,T2,…,Tn)。
(5)构建特征向量空间模型:计算特征项空间中各个特征项Tk(1≤k≤n)对于各个文本的重要程度(即权重Wk(1≤k≤n)),从而建立向量空间模型。目标资源文本用向量空间模型表示为D(T1,T2,…,Tn)。其中,D为目标资源文本;Tk(1≤k≤n)为划分D的多个独立特征项。然后根据TF-IDF方法确定特征项Tk的权重Wk。
TF-IDF是一种应用广泛的权重计算方法,其综合考虑了特征项在笔者文本以及所有文本中的词频。也就是说,某特征项在笔者文本中越常出现,其重要性就越大,即与权重结果成正比;而包含某特征项的文本数量越多,其区分文本的能力就越低,即对某个文本的重要性就越小,从而与权重结果成反比。TF-IDF的具体计算公式为:
TF-IDF(Tk,D)=
(1)
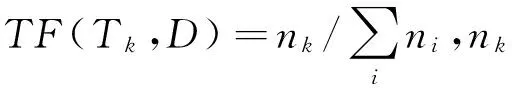
笔者用Wk表示Tk的权重(1≤k≤n),则文本D的向量表示为:
D=D(W1,W2,…,Wn)
(2)
(6)文本相似度计算:文本D1和D2之间的文本相似度Sim(D1,D2)通过向量之间的夹角余弦来衡量:
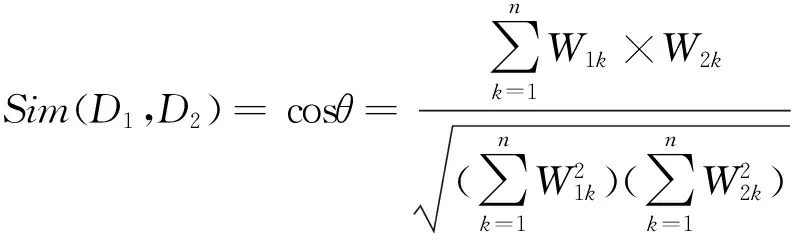
(8)聚类结果描述:将聚为一类的资源文本中具有最大词频的两个特征值合成聚类结果,即发现的热点名称。
3 基于DBSCAN的资源热点发现验证
将某届会议的所有文献资源作为测试样本,通过对比人工分类结果与实验聚类结果,从而验证聚类算法的有效性。测试样本中共有392个文献资源,通过人工的方式分为5大热点:有限元分析、数值模拟、神经网络与遗传算法、建模、模糊PID与基线波动。
评价聚类效果的常用指标为查准率和召回率,前者表示聚类结果中确实属于某类别的对象与此类别的聚类结果中对象总数之比,后者表示确实属于某类别的所有对象中,聚类得出相同判断的对象所占的比例(亦称查全率)。
DBSCAN算法中通常取MinPts=4,Eps的值在0~1之间(归一化后的相似度),笔者取为0.8,即文本之间的相似度大于等于0.8时可归为一类。特征项空间的维数可根据实验确定一个合适的值,笔者设置为15。
先对经过一般的特征词缩减(未合并具有包含关系的特征词)后的资源文本进行聚类,具体结果如表1所示。
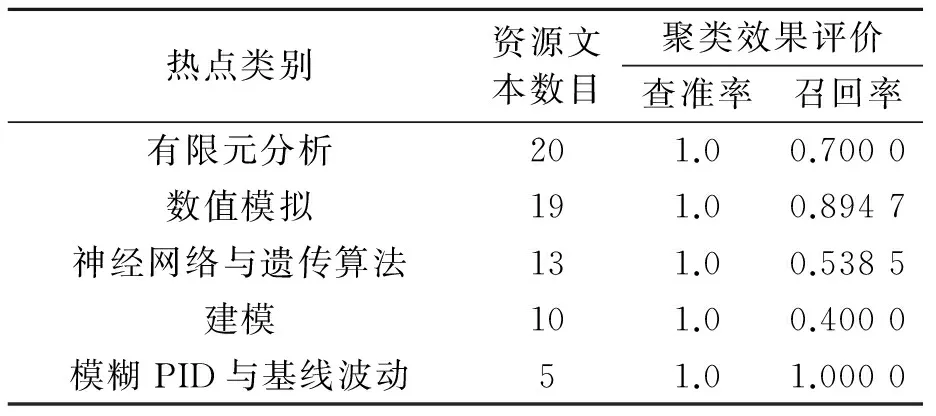
表1 基于密度聚类的资源热点发现结果
由表1可知,某些类别的召回率比较低,通过分析人工分类结果和聚类结果可知,某些特征词之间存在包含关系,实际上可以归为一类,而聚类算法却将其作为独立的特征词处理,以“神经网络与遗传算法”为例,某些文本中相关的关键词有“BP神经网络”、“人工神经网络”、“混合遗传算法”和“改进遗传算法”等,拥有这些关键词的文本也应该归为“神经网络与遗传算法”这一类。因此,笔者将对基于密度聚类的资源热点发现方法中“特征项缩减”这一部分进行改进,即除了删减掉无意义的、词频较低的关键词外,还对具有明显包含关系的关键词进行合并,从而提高聚类的准确率。合并具有包含关系特征词后的基于密度聚类的资源热点发现结果,如表2所示。
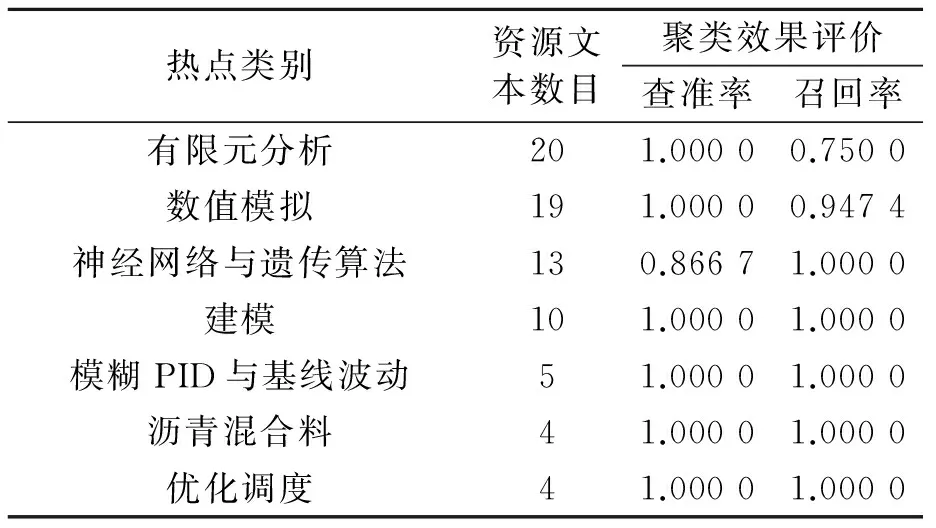
表2 合并具有包含关系特征词后的资源热点发现结果
由表2可知,热点类别的召回率都有了一定的提升;还发现“神经网络、遗传算法”热点的查准率有所下降,这是因为合并具有包含关系的关键词时不可避免地引入了其他有效的关键词,但是其召回率大大提高,因此该方法总体上还是有效的。除此之外,改进方法还产生了新的热点类别,这是因此合并具有包含关系的关键词后,使得某些对象集合满足设定的密度阈值,从而产生新的热点类。
笔者将验证基于时间效率改进的DBSCAN算法,即解决DBSCAN聚类算法中公共对象的邻域重复获取问题,改进前后的算法聚类结果相同,而改进前后的算法时间对比结果如图4所示。由图4可知,在保证聚类准确性的前提下,改进后的聚类时间因避免公共对象邻域的重复获取而缩短,并且随着资源文本数量的增加而越发明显。因此,基于时间效率的算法改进对于平台上大量资源文本的聚类是很有意义的。
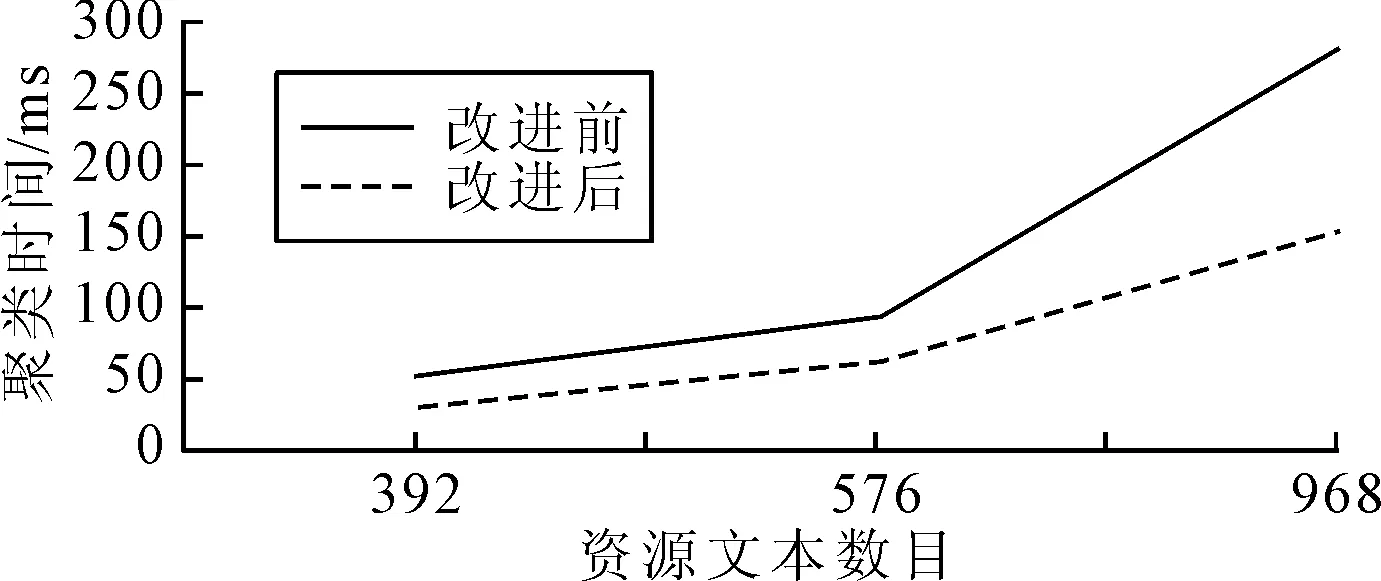
图4 DBSCAN算法改进前后的聚类时间对比图
通过上述的聚类效果评价和聚类时间结果可知,改进后的基于密度的聚类方法能够快速有效地自动发现资源热点,并且通过基于学科分类后再聚类、基于合并具有包含关系的特征项缩减以及解决DBSCAN聚类算法中公共对象的邻域重复获取问题,可以在一定程度上保证了聚类的准确性和时间效率。
4 结论
笔者针对学术会议产生的各类爆炸式信息资源,提出了一种基于资源关键字的资源聚类方法,实现了资源热点的自动发现,使学术会议共享资源的用户无需自行搜索分析就能快速了解相关领域的研究热点,提高了会议学术资源共享平台的使用价值和友好性。但上述DBSCAN算法中输入的参数都是通过多次实验选取的,如何快速确定适宜有效的参数将是下一步研究的问题。
[1] 韩晨靖.基于标题特征值密度聚类以及相似度计算的热点发现研究[D].成都:电子科技大学,2013.
[2] POULIQUEN B, STEINBERGER R, IGNAT C, et al. Multilingual and cross-lingual news topic tracking[C]∥International Conference on Computational Linguistics Ralf.[S.l.]:[s.n.], 2004:20-23.
[3] 郭建永,蔡永,甄艳霞.基于文本聚类技术的主题发现[J]. 计算机工程与设计,2008,29(6):1426-1428.
[4] 李若鹏,李翔,林祥,等.基于DK算法的互联网热点主动发现研究与实现[J].计算机技术与发展,2008,18(9):1-4.
[5] 罗云.互联网海量信息中热点信息主题的自动发现[D].广州:华南理工大学,2013.
[6] 唐远华.Web新闻热点信息的自动发现及展示[D].广州:华南理工大学,2012.
[7] 陈飞宏.基于向量空间模型的中文文本相似度算法研究[D].成都:电子科技大学,2011.
[8] 郭庆琳,李艳梅,唐琦.基于向量空间模型的文本相似度计算的研究[J].计算机应用研究,2008,25(11):3256-3258.
[9] ZHANG G H, ODBAL. Sentence alignment for web page text based on vector space model[C]∥International Conference on Computer Science and Information Processing.[S.l.]:[s.n.], 2012:167-170.
[10] LIANG X, WANG D, HUANG M. Improved sentence similarity algorithm based on vector space model and its application in question answering system[C]∥IEEE International Conference on Intelligent Computing & Intelligent Systems.[S.l.]: IEEE, 2010:368-371.
[11] 李双庆,慕升弟.一种改进的DBSCAN算法及其应用[J].计算机工程与应用,2014,50(8):72-76.
ZHAO Nan:Engineer;China Shipbuilding Industry Corporation 722 Research Institute,Wuhan 430205,China.
Research on Academic Resources Hotspot Detection Based on Density Clustering Algorithm
ZHAONan,LIUZhen,SUNYanchao,ZOUPanpan,CHENDejun
In view of the explosive sharing of scholarly resources and how to get the current research hotspots quickly and accurately, it proposed an improved density-based clustering algorithm DBSCAN, to achieve the automatic discovery of academic resources hot spots. This algorithm can detect the academic resources hotspots automatically by combining keywords with obvious relationship to reduce feature items and it also can solve the problem that public resources object neighborhood's repeated acquisition, which can improve the accuracy and time efficiency to a certain degree. The results show that this method can detect the research hotspots in current related fields accurately and quickly. It helps to understand the current research hotspots of various disciplines, and dissemination of academic achievements of great significance.
hotspot detection; vector space model; density clustering algorithm
2095-3852(2016)06-0721-05
A
2016-07-07.
TP391
10.3963/j.issn.2095-3852.2016.06.017
收稿日期:赵楠(1987-),女,山东泰安人,中国船舶重工集团公司第七二二研究所工程师.
