中文在线评论的用户性别判定研究*
2017-01-06胡龙茂
胡龙茂
(安徽财贸职业学院,安徽合肥230601)
中文在线评论的用户性别判定研究*
胡龙茂
(安徽财贸职业学院,安徽合肥230601)
该文旨在研究中文在线评论的用户性别判定问题,即根据用户的商品评论识别用户的性别.首先研究了在线评论中对用户性别起指示作用的信息,然后从用户名、商品描述和评论文本中抽取特征,分别采取独立特征、叠加特征及融合特征的方式构建最大熵分类器进行实验.实验结果表明,用户名+商品描述+评论文本的分类器准确率最高.
性别判定;中文在线评论;最大熵分类器
近年来,随着电子商务的飞速发展,越来越多的用户选择从网上购物,截止到2016年6月,我国网络购物用户规模达到4.48亿[1].在使用商品后,部分网购用户会在购物网站上发表评论信息,淘宝、京东和亚马逊上随之产生了海量的在线评论,这些评论包含了用户对商品或商品某些属性的意见,而不同类别的用户对商品及其属性的关注点也不相同,如果能够从评论中挖掘出用户的性别、年龄及职业等信息,则会对产品定制及差异化营销产生积极的影响.
文献[2]利用不同人群的博客用户在写作风格和内容上的显著差异,来确定一个未知用户的年龄和性别.文献[3]利用用户的tweet文本内容和用户资料中的全名、用户名及个人描述三个字段作为特征来判定用户的性别.文献[4]研究了美国的58 466 名Facebook用户的Facebook Likes数据,精确预测了一系列高度敏感的个人特征,包括:性取向、种族、宗教和政治观点、父母离异、年龄和性别等.文献[5]以用户名和微博文本作为特征,采用分类器融合的方法对中文微博用户的性别进行了判定.
除了对博客、微博用户进行信息提取研究外,也有少数学者对在线评论的用户信息提取展开了研究.文献[6]利用规则从Web评论中提取用户的性别.
本文研究了中文在线评论中对用户性别起指示作用的信息,在此基础上提出了从用户名、商品描述和评论文本抽取特征,采用最大熵模型判断用户性别的方法.实验结果表明,特征叠加的分类器有较高的准确率.
1 最大熵模型
最大熵模型就是符合已知事实的情况下,对未知事实不作概率上的假设,即未知的分布应该是均匀的.例如,假设用户的年龄分为四个阶段,已知所购商品中出现“美宝莲”的70%属于青年,而“美宝莲”在其余三个年龄段中的分布未知,则根据最大熵原则,各有10%的可能性属于其他三个年龄段.如果商品中没有出现“美宝莲”,则此用户都以相同的、25%的概率属于四个年龄段.
在自然语言处理任务中,通常使用条件最大熵模型.每个训练样例由实例x和其对应的类别y组成,fi(x,y)为表征训练样例的特征函数,则最大熵模型的公式如下:
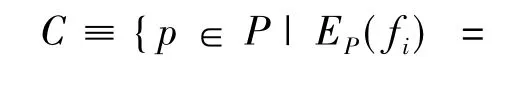
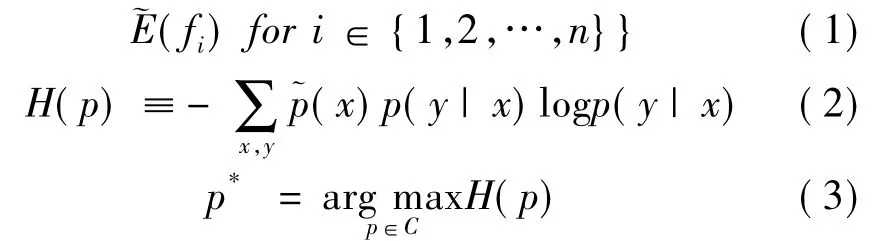
C为约束,要求所有特征的模型期望等于经验期望,即要求模型符合已知事实.通过拉格朗日乘法求解带约束的最优值,得到:
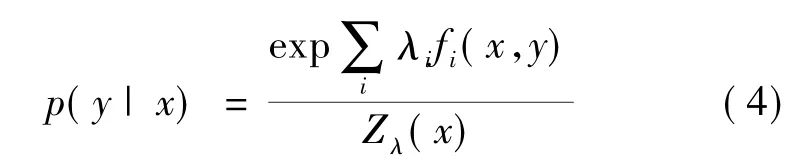
其中λi是特征权重,Zλ(x)为归一化因子,用于保证x属于各类别的概率和为1.
一般无法求出λi的解析解,可以采用GIS或IIS算法获得近似解.
最大熵模型的主要优点是能够在同一个框架中使用不同的特征,这些特征之间无需独立性假设,这显然比贝叶斯方法更符合事实.
2 语料描述
本文从亚马逊网站上抓取了某国产手机的评论共1068条,根据这些评论的用户URL继续抓取这些用户的所有评论,每个用户的评论由用户名、所购商品的描述和评论文本组成.由4人人工标注出这些评论用户的性别,只有3人及以上同时标注为男(或女),此用户才能确定为男(或女),不符合这个条件的评论被丢弃.最终得到可以确定性别的用户评论886个,其中男性658个,女性228个.
通过对评论语料的观察,可以从用户名、商品描述和评论文本中发现与性别相关的特征.
2.1 用户名特征分析
用户名有一定的性别指示作用.男性用户名的末尾往往有偏男性化的字,例如:杨海涛、孙旭辉、潘宇等.女性用户名的末尾也有类似的现象,如:刘婷婷、陈珍玫等.评论中也有部分用户名没有性别特征,如亚马逊卖家、sdu等.
2.2 商品描述特征分析
男女性用户对不同类别的商品感兴趣程度是不同的.男性往往对电子、电器感兴趣,而女性对服装、包、食品、化妆品更感兴趣.
例1:某男性用户所购商品,文本中每行代表一样商品(C52-m6.txt).
“荣耀畅玩4X Che1-CL20双卡双待全网通版4G智能手机移动/联通/电信4G/3G/2G(白色)...
Kindle Paperwhite电子书阅读器:300 ppi电子墨水触控屏、内置阅读灯、超长续航...
NuPro轻薄保护套(适用于第6代以及第7代Kindle Paperwhite电子书阅读器),经典黑...”
例2:某女性用户所购商品,文本中每行代表一样商品(C51-m566.txt).
“Greenleaf绿叶隔离防晒补水组合套装(防晒隔离乳冰肌露SPF 30PA+++60ml+复活草深层补水面膜贴25ml 6片)裸妆遮瑕防辐射补水(新老包装随机发货)...
Cetaphil丝塔芙洁面乳118m l(特卖)...
XSHOW圣雪兰洋甘菊花瓣初露150ml★韩国热卖温和爽肤水晒后修护...
荣耀畅玩4X Che2-UL00(2G RAM)联通高配版4G智能手机(白色)双卡双待...”
有些用户不但为自己购买商品,同时也给家人朋友购买商品,此时,所购商品中可能男、女性用品都存在.
例3:所购商品中同时包括男、女性用品.(C52 -m1124.txt)
“荣耀畅玩4X Che1-CL10双卡双待电信4G智能手机(白色)电信定制版FDD-LTE/TD-LTE/CDMA2000/GSM...
Braun德国博朗cruZer Z20电动剃须刀...
Donlim东菱全自动面包机XBM1028GP...
PUMA彪马 优雅时尚系列 女式 单肩包/斜挎包 黑 -黑70749010100...”
2.3 评论文本分析
男、女性评论的用词会有所区别,女性用词会有更多的语气词、感叹号等.
例4:某女性用户的评论文本.
“用了一年,内存总是不够,一般般咯
这个眼线笔一点也不好,真心的,晕妆,千万别买,后悔死了”
也有极少数评论文本中会明显地有指示性别的词语出现.
例5:某男性用户的某条评论,其中“老婆”指示了用户性别为男性.
“刚刚使用过,配置很方便,速度还不错,65Mb.有了这个,老婆就不再和我抢网络了.”
3 中文在线评论的用户性别判定
3.1 特征函数的选择
(1)用户名特征函数.微博用户的中文昵称大都与中文人名相似[7],而中文人名有较强的性别区分性[8].网购用户同微博用户一样,使用的都是网名,有一定的相似性,故对于中文用户名而言,可以使用名字的尾字作为特征进行区分.对于英文用户名而言,尾字的元、辅音对性别也有较强的区分性.特征模板如表1所示.
例如,由特征模板3可以得到一个特征函数:
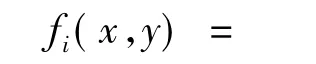


表1 用户名特征模板
(2)商品描述及评论文本的特征函数.根据用户所购商品的描述或评论文本来判定用户性别,实际上就是文本分类问题.定义D=(d1,d2,…,dn)是训练文档集,类别G=(g1,g2)为性别集合,W={w1,w2,…,wk}是训练文档集中特征词.最大熵模型的特征函数用如下公式表示[9]:
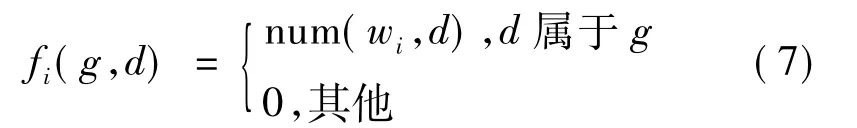
上式中num(wi,d)表示文档d中词wi出现的次数.
3.2 用户性别判定
用户性别判定的过程如图1所示.对于利用商品描述和评论文本判定性别,首先要进行文本预处理(文本分词、特征词选取),然后利用式(7)获得特征函数,最后用最大熵模型进行训练和判定.对于利用用户名判定性别而言,只需根据表1所示特征模型获得特征函数,然后用最大熵模型进行训练和判定.
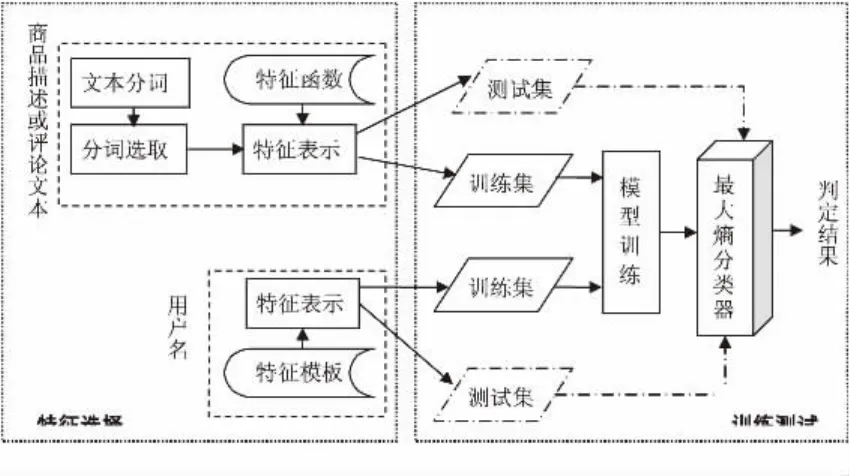
图1 中文在线评论的用户性别判定过程
4 实验及结果分析
4.1 实验设置
实验采用Python开发环境.本文借鉴墨尔本大学Steven Bird开发的自然语言工具包NLTK,用python语言实现了最大熵分类器.分词工具采用北京理工大学张华平博士开发的NLPIR汉语分词系统.从人工标注过的886篇评论语料中随机抽取80%作为训练集,其余20%作为测试集,使用准确率评价分类效果.
4.2 实验结果
分别采用用户名、商品描述、评论文本、用户名+商品描述、用户名+商品描述+评论文本构建分类器以及使用用户名、商品描述、评论文本三个基分类器的组合分类器,组合分类器采用贝叶斯积的方式融合基分类器.对于每种分类器,均进行五次实验,结果取五次实验的平均值.实验结果如表2所示.

表2 不同分类器的分类准确率
从表2的实验结果看,①仅使用用户名进行判定的准确率最低,这是由于用户的取名有很大的随意性,有些名字是数字,还有些注册时没取名,系统默认设为“亚马逊用户”,导致用户名的分辨效果较差.②仅使用商品描述进行判定的准确率接近最高准确率,比仅使用用户名高了10.3个百分点,说明商品描述有较强的性别分辨能力.③使用用户名+商品描述+评论文本叠加特征进行判定的准确率最高,达到了85.06%,可能是由于评论文本的一些性别指示词、男女性不同的用词习惯起了作用.④用户名、商品描述、评论文本的分类器组合的判定能力比较差,甚至不如单独的商品评论分类器,可能是因为准确率较低的用户名基分类器中的一些错误被传导到组合分类器.
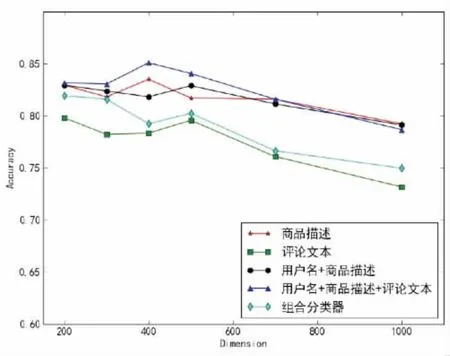
图2 不同特征数目下的分类准确率
图2给出了不同特征数目下的分类准确率.为方便统计,同时使用两种文本特征的分类器的特征数目取值是相同的,例如,特征数目为500的用户名+商品描述+评论文本分类器,指的是商品描述和评论文本的特征数目各取500.
从图2中可以看出:①各分类器的准确率在特征数为200到500之间取得最大值,超过500时,准确率逐渐降低.②评论文本分类器的准确率始终是最低的,组合分类器的准确率略高于评论文本分类器,用户名+商品描述+评论文本的准确率始终是最高的.
5 结语
[1]中国互联网络信息中心.中国互联网络发展状况统计报告(2016年7月)[EB/OL].http://www.cnnic.cn/gy wm/xwzx/rdxw/ 2016/201608/W020160803204144417902.pdf.
[2]Schler J,Koppel M,Argamon S,et al.Effects of Age and Gender on Blogging[C]//Proceddings of A AAI 06,2006.
[3]Burger J,Henderson J,Kim G,et al.Discriminating Gender on Twitter[C]//Proceddings of EMNLP 11,2011,1301-1309.
[4]Kosinskia M,Stillwella D,Graepelb T.Private traits and attributes are predictable from digital records of human behavior[J].Proceedings of the National Academy of Sciences,2010(15),5802-5805.
[5]王晶晶,李寿山,黄磊.中文微博用户性别分类方法研究[J].中文信息学报,2014,28(6):150-155.
[6]邱云飞,王雪,刘大有,等.基于Web评论的用户个人信息提取方法研究[J].计算机应用与软件,2012,29(5):44-47.
[7]安军辉.基于微博数据的微博用户性别判断研究[D].武汉:华中师范大学,2015.
[8]于江德,赵红丹,郑勃举,等.基于中文人名用字特征的性别判定方法[J].山东大学学报:工学版,2014(1):13-18.
[9]李荣陆,王建会,陈晓云,等.使用最大熵模型进行中文文本分类[J].计算机研究与发展,2005,42(1):94-101.
(责任编辑:王前)
TP18
A
1008-7974(2016)06-0069-04
10.13877/j.cnki.cn22-1284.2016.12.022
2016-09-08
安徽省高校自然科学研究重点项目(KJ2016A009)
胡龙茂,男,安徽太湖人,讲师.
