一种混合算法在学习历程数据分析中的应用研究*
2017-01-06刘建炜张艳红
张 颖,刘建炜,张艳红
(1.福州建筑工程职业中专学校计算机教研室,福建福州350013; 2.福建幼儿师范高等专科学校人文科学系,福建福州350013)
一种混合算法在学习历程数据分析中的应用研究*
张 颖1,刘建炜2,张艳红1
(1.福州建筑工程职业中专学校计算机教研室,福建福州350013; 2.福建幼儿师范高等专科学校人文科学系,福建福州350013)
该文尝试混合运用K-means、ID3等算法,并加以改进,得出了一种混合改进算法.在实际应用中,它能够高效的对学生的学习历程数据进行深入的分析与挖掘,最终发现在海量的学习历程数据中蕴藏的有价值的信息,并以此为职业院校的人才培养与决策提供数据支持.
算法;预测;K-means;ID3
在教育信息化浪潮中,职业院校大量的关于学生学习历程的原始数据沉积了下来,它涉及到学生日常学习、生活的方方面面.这类数据是学校办学过程中积累的最宝贵的财富之一,大数据对学校教育教学改革与人才培养可起到支持作用.本文通过混合运用多种数据挖掘算法,对学校的海量学生学习历程数据进行分析研究,并得到在这类数据中蕴藏的有价值的知识和规则.进而运用这些知识规则,尝试对在校生的德育行为进行预测,进而为学生工作者、校领导的工作开展与决策提供数据支持.[1-2]
1 本文所采用的行为分析算法研究
1.1 K-means聚类算法及改进
通常采用分类、聚类、关联规则等算法对学生学习历程数据进行分析.在数据分析过程中,特别关注两类现象,一类是“群体”现象,另一类是“离群”现象.而K-means聚类算法可以进行聚类运算,同时也可以根据算法寻找到孤立数据.但是,通过样本数据的测试发现,传统的K-means聚类算法在学生学习历程数据的分析中存在运行效率与准确度较低的现象.[3]而影响该算法准确性的关键之一是集合中心点的选择计算,结合领域知识,根据学生群体的学习历程数据特征,创建特定的中心点选择算法,以此对学生学习历程数据的分析过程中所使用的K-means聚类算法进行改进,以适应学习历程数据分析的具体情况.该算法的核心思想如下:
定义一:集合Pij(pi1,pi2,pi3,…pin),其中i表示样本点,j表示维度.则集合Pij的中心点计算方式如下[4-5]:
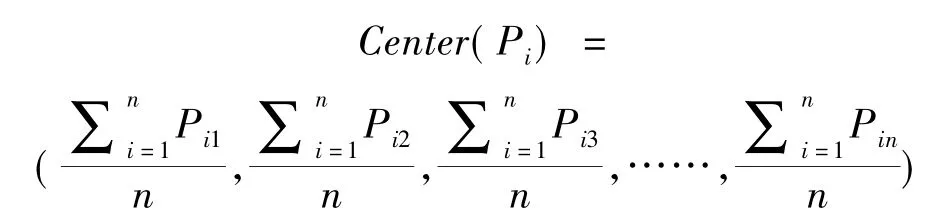
步骤1:根据定义一计算出传统K-means算法所得出的集合{Pi}的中心点Center(Pi);[6-8]
步骤2:双中心点计算,根据步骤1计算出的中心点,计算出离该点最近与最远的两个点作为双中心,分别记为Max(Pi)、Min(Pi),且置n=2;
步骤3:判断用户输入k>n是否成立:如果不成立则算法退出,并且把n作为中心点数进行聚类划分;如果成立,则计算中心点集合的中心位置Center(Ci),并计算出距离该位置最远的数据作为下一个聚类中心,且设置n=n+1;
步骤4:重复执行步骤3,直到算法退出.
1.2 ID3决策树算法及改进
ID3算法是一种常用的基于信息熵的分类算法,通过递归计算出分类树.但是在对学生学习历程数据的计算过程中,由于递归重复计算导致运算效率低下,计算成本较高.传统的解决方式是简化熵计算的方式,即应用泰勒公式和麦克劳林公式进行降维处理,从而降低ID3算法的时间复杂度.[9-11]
公式1:

通过应用上述公式ID3算法的计算效率有所提高,但该改进算法在学习历程数据分析过程中的效果并不理想.根据学生学习历程数据的特点,这类数据中有很多数据项具有强关联关系,由此课题组尝试引入Apriori关联规则算法,通过对原始数据进行关联规则清洗:对参与计算的数据进行强关联规则计算,从中发现它们之间的强关联关系,并以此为依据进行数据属性的约减,从而约减参与ID3分类计算的数据规模,进而有效提高计算效率.
2 基于K-means、ID3等算法的学生行为预测数据挖掘
样本数据来自于历年来学校学生沉积的学习历程数据,有教学管理、心理测评、德育考评等方面的数据来源,初始数据如下表1所示:

表1 学生月度情况一览表
表1说明:户籍={城关=1、农村=2};…;处分情况={无处分=1,警告/记过=2,留校察看= 3、开除=4}.
2.1 基于K-means改进算法的学生学习历程数据的分析
为了分析学生的心理因素对德育行为的影响,课题组将心理测评与德育积分作为研究分析对象,把K值置为4,即分为四类,分别为:优秀、良好、中等、差.根据改进后的K-Means算法计算结果如表2所示:

表2 各分组情况
各分组的学生人数占比,如表3:
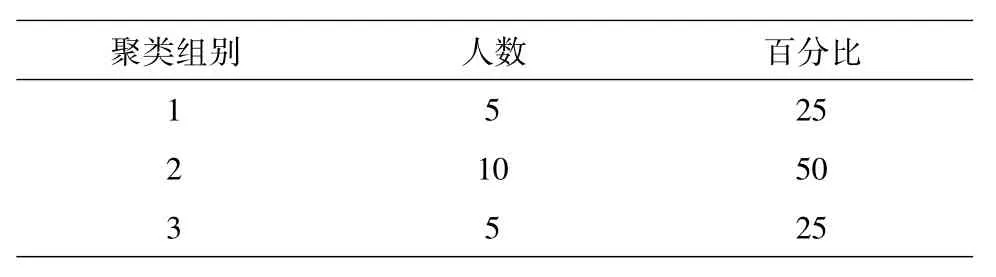
表3 各分组人数所占百分比
二维坐标数据分布示意图如图1:

图1 心理与德育积分分析示意图
同时,我们从数据样本中抽取具有代表性的若干字段进行分类汇总,如表4:
应用K-means算法的分析结果,得到以下信息:第一组的学生属于学习中等的学生,但是他们的综合表现良好,出勤率高、课堂表现优异、学习态度端正、积极参与集体活动等,且大部分属于粘液质的气质类型;第二组同学平时表现一般,但成绩较为突出,这是一个值得深入研究的现象.而让我们更为关注的是系统检测出的离群信息,学生6:该学生即为我们传统上说的问题学生,例如学习态度不端正,爱出小差,与同学关系紧张,参加集体活动很消极、较为孤立,学习成绩也是不理想.这类学生的数据是我们关注的重点,需要进一步深入挖掘的对象,通过下面的进一步挖掘,以期得出这类学生更有价值的信息,为学生工作者及相关领导提供更为有效的决策支持.

表4 按分组进行字段分类汇总表
2.2 基于ID3改进算法的学生德育行为数据分析为了对上述得出的感兴趣的数据进行进一步分析挖掘,继续抽取学生的学习历程数据进行分析研究,经过二次数据清洗得到数据如表5(部分).

表5 学生信息表C
(1)ID3算法计算过程演练.表5是采集样本数据集R,一共选取了8个字段进行计算,“处分”字段是作为分类算法的标识字段.在进行ID3分类算法计算之前,应用Apriori算法对源数据进行关联规则数据挖掘,从而挖掘出符合要求的强关联属性集.并以此为依据,对这类属性进行属性约减得到数据集R',然后再应用ID3分类算法对R'进行分类计算,以此提高分类计算的效率.具体演算步骤如下:
步骤1:对参与演算的源数据集合C(表5数据)进行清洗,设置Apriori算法计算相关参数:最小支持度α=4,最小置信度β=0.8,计算得到以下强关联规则:
1{活动情况、心理状态}=>{气质类型} 置信度=83.33%
2{活动情况、气质类型}=>{心理状态} 置信度=71.43%
3{气质类型、心理状态}=>{活动情况} 置信度=71.43%
4{心理状态、气质类型}=>{活动情况} 置信度=100%
5{缺勤情况、气质类型}=>{户籍性质} 置信度=100%
6{户籍性质、气质类型}=>{缺勤情况} 置信度=83.33%
根据上述得出的强关联规则,筛选出可以约减的属性为:“活动、户籍”,因为这两个属性可以分别由“气质、心理”与“气质、缺勤”所替代,故可以约减这两个属性,得到集合C',如表6所示:

表6 新数据集合C'
步骤2:应用ID3分类算法对新得到的数据集合C'进行分类计算:设定“处分”作为分类标识字段,则有K=20、m=4;K表示为集合C'的记录数,此处共计20条记录,故K=20;m表示为属性取值数量,此处“处分”的值域为{无处分、警告记过、留校察看、开除}合计有4种类型,故m=4.
步骤3:计算信息熵,首先根据m=4设定“处分”属性值为“无处分”的类记为C1;“处分”属性值为“警告记过”的类记为C2;“处分”属性值为“留校察看”的类记为C3;“处分”属性值为“开除”的类记为C4.则,C1=5,C2=3,C3=3,C4=9,且有:P1= 5/20,P2=3/20,P3=3/20,P4=9/20,对于C'的期望值计算如下:
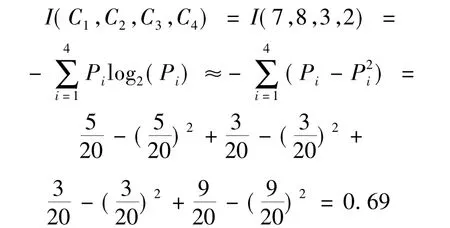
步骤4:依次计算其余属性的熵值,先计算“学习”属性的熵,对于“学习=优”的类别标号,有:C11=5,C21=0,C31=0,C41=0;则有:P11=5/5,P21=0,P31=0,P41=0,计算熵值如下:
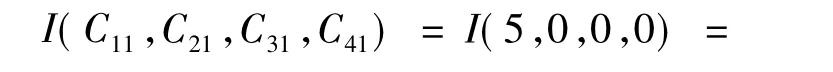
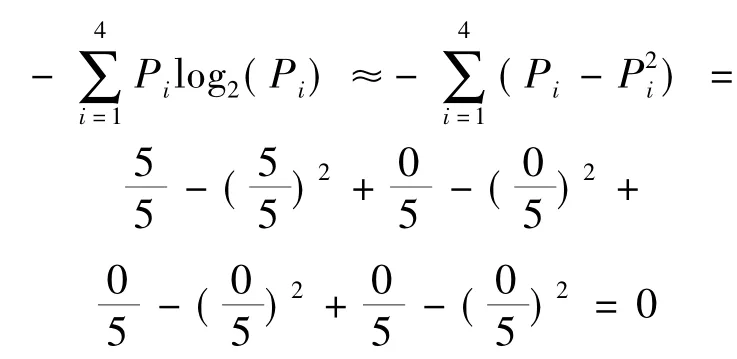
再计算“学习=良”的情况,有:C12=1,C22= 2,C32=0,C45=0;则有:P12=1/3,P22=2/3,P32=0,P42=0,计算熵值如下:
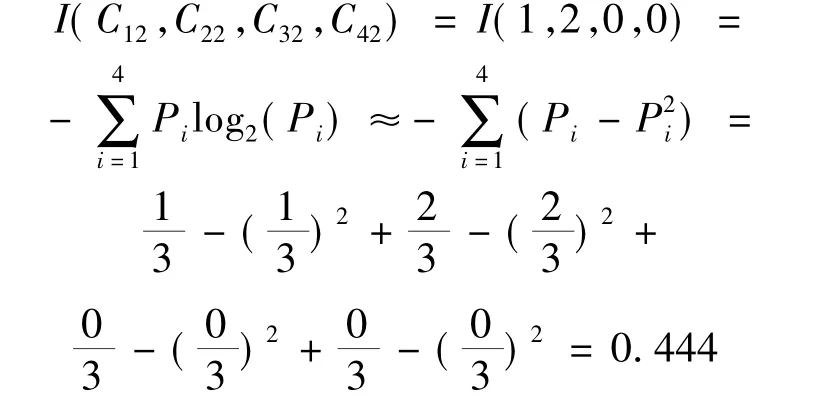
再计算“学习=中”的情况,有:C13=0,C23= 1,C33=1,C43=1;则有:P12=0,P22=1/3,P32= 1/3,P42=1/3,计算熵值如下:
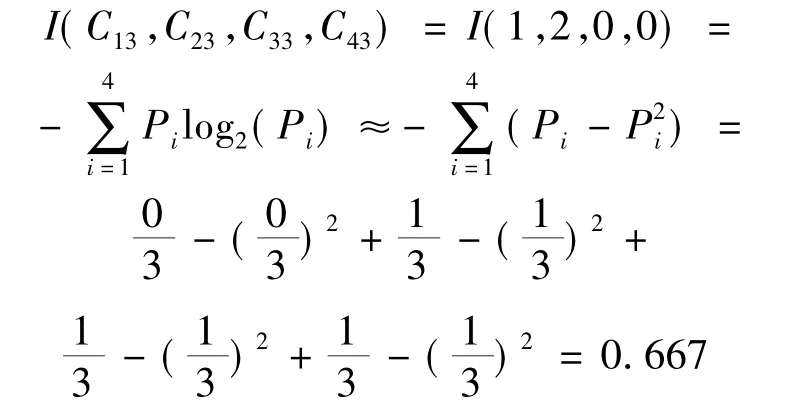
最后计算“学习=差”的情况,有:C14=1,C24=5,C34=2,C44=1;则有:P12=1/9,P22=5/9,P32=2/9,P42=1/9,计算熵值如下:

综合以上计算结果,设定以“学习”字段进行分组划分,其期望值结果计算如下:
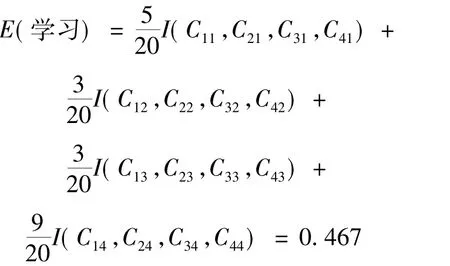
即可以计算出“学习”字段的期望值:
Gain(学习成绩)=I(C1,C2,C3,C4)-E(学习成绩)=0.2230
重复执行公式4,分别计算出“德育、缺勤、心理、气质”等属性的期望值,结果如下:
Gain(德育)=I(C1,C2,C3,C4)-E(德育)= 0.2645
Gain(缺勤)=I(C1,C2,C3,C4)-E(缺勤)= 0.0345
Gain(心理)=I(C1,C2,C3,C4)-E(心理)= 0.1005
Gain(气质)=I(C1,C2,C3,C4)-E(气质)= 0.1085
步骤5:根据步骤4计算出了数据集合C'所有属性的期望值,其中得出Gain(德育)的期望值最大,以此作为分类划分的依据,并创建决策树,并进行相应的标记.得出本次计算以“德育”字段作为分类测试的字段,创建决策树节点,并计算出以此为节点的其他分支.
步骤6:对步骤5生成的相应分支,重复步骤1 ~5的相关操作,直到整个决策树的生成.
本次对数据集合C的计算,生成的完整决策树,如下图2所示:
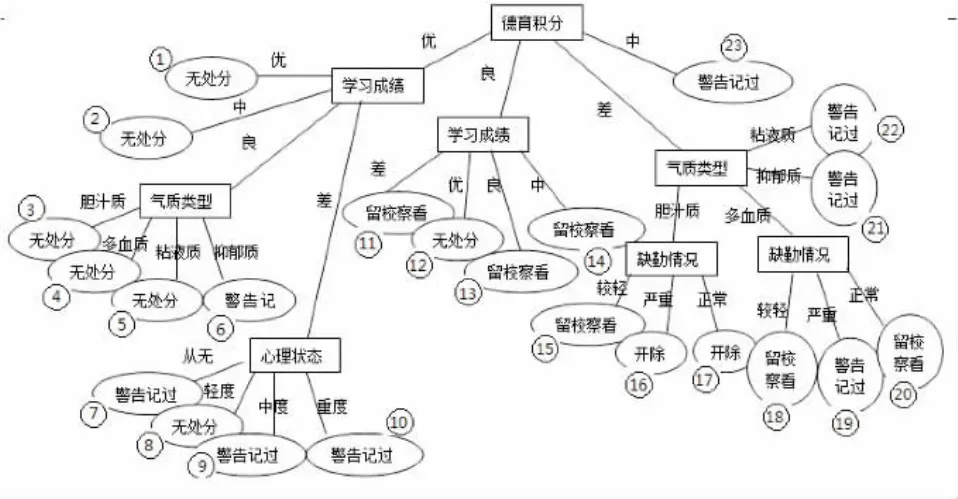
图2 完全决策树
应用“IF…THEN…”表达式可以抽取出图2决策树所包含的知识,即可得到以下的规则:
① IF德育积分=“优”AND学习成绩=“优”THEN处分情况=“无处分”;
② IF德育积分=“优”AND学习成绩=“中”THEN处分情况=“无处分”;
③ IF德育积分=“优”AND学习成绩=“良”AND气质类型=“胆汁质”THEN处分情况=“无处分”;
④ IF德育积分=“优”AND学习成绩=“良”AND气质类型=“多血质”THEN处分情况=“无处分”;
⑤ IF德育积分=“优”AND学习成绩=“良”AND气质类型=“粘液质”THEN处分情况=“无处分”;
⑥ IF德育积分=“优”AND学习成绩=“良”AND气质类型=“抑郁质”THEN处分情况=“警告记过”;
⑦ IF德育积分=“优”AND学习成绩=“差”AND心理状态=“从无”THEN处分情况=“警告记过”;
⑧ IF德育积分=“优”AND学习成绩=“差”AND心理状态=“轻度”THEN处分情况=“无处分”;
⑨ IF德育积分=“优”AND学习成绩=“差”AND心理状态=“中度”THEN处分情况=“警告记过”;
⑩ IF德育积分=“优”AND学习成绩=“差”AND心理状态=“重度”THEN处分情况=“警告记过”;
⑪ IF德育积分=“良”AND学习成绩=“优”THEN处分情况=“无处分”;
⑫ IF德育积分=“良”AND学习成绩=“良”THEN处分情况=“留校察看”;
⑬ IF德育积分=“良”AND学习成绩=“中”THEN处分情况=“留校察看”;
⑭ IF德育积分=“良”AND学习成绩=“差”THEN处分情况=“留校察看”;
⑮ IF德育积分=“中”THEN处分情况=“警告记过”;
⑯ IF德育积分=“差”AND气质类型=“胆汁质”AND缺勤情况=“较轻”THEN处分情况=“留校察看”;
⑰ IF德育积分=“差”AND气质类型=“胆汁质”AND缺勤情况=“严重”THEN处分情况=“开除”;
⑱ IF德育积分=“差”AND气质类型=“胆汁质”AND缺勤情况=“正常”THEN处分情况=“开除”;
⑲ IF德育积分=“差”AND气质类型=“多血质”AND缺勤情况=“正常”THEN处分情况=“留校察看”;
⑳ IF德育积分=“差”AND气质类型=“多血质”AND缺勤情况=“较轻”THEN处分情况=“留校察看”;
㉑ IF德育积分=“差”AND气质类型=“多血质”AND缺勤情况=“严重”THEN处分情况=“警告记过”;
㉒ IF德育积分=“差”AND气质类型=“粘液质”THEN处分情况=“警告记过”;
㉓ IF德育积分=“差”AND气质类型=“抑郁质”THEN处分情况=“警告记过”.
(2)规则分析与应用.知识1:通过分析规则①②③④⑤⑥可以得出以下有用的知识结论,即学习成绩在中等以上且德育成绩优秀的学生受到的学校处分较少,这部分学生占了在校学生的绝大多数,属于中坚力量,充分表明了学生的在校表现与学生取得的学校成绩呈正态分布的实际情况.
知识2:通过分析规则⑦⑧⑨⑩发现在学习成绩较差的学生中,心理状态是影响学生在校德育表现的重要影响因素.例如,有部分心理表现为重度、中度的学生在校德育表现较差,有出现违纪受到处分的记录.
知识3:通过分析规则⑪⑫⑬⑭发现,这部分学生群体德育表现中等,但有一些违纪记录.这类学生如果能够加以引导,让其专注于学习,将大幅降低这类学生德育违纪相关事件发生的概率.
知识4:通过分析规则⑮⑯⑰⑱⑲⑳㉑㉒㉓发现,这部分学生属于学生工作者较为头疼的“后进生”.根据数据分析结果表明,这类学生较为冲动,属于典型的胆汁质性格特质的学生较多.上述通过聚类算法挖掘出的离群学生就是出自这类学生,这类学生应当成为学生工作者重点关注与预防的对象.
3 系统实现
通过应用上述改进的K-means、ID3算法,并实验验证了其有效性及效率的提升,最终实现了系统的开发与应用.系统共分为数据采集模块、数据预处理模块、规则挖掘模块、离群分析模块、规则生成模块等5大部分组成.如图3~图5展示了系统的部分功能模块.
4 总结
图3 数据预处理模块
通过对学生学习历程数据进行聚类分析,有效地发现离群信息,并通过分类算法对学生的行为进行分析和预测.实验结果显示,改进后的算法提高了决策树算法的分类效率,分类效果良好.同时,根据分类结果生成的规则知识,在一定程度上能够有效地对学生行为分析及预测,在学生管理工作中具有重要的指导意义.
图4 离群信息发现
图5 生成的决策树
[1]余辉,吕扬生.数据挖掘技术在生物医学领域的应用[J].国外医学.生物医学工程分册,2003,26(2):54-59.
[2]王轩.数据挖掘热点和研究方向浅析[J].黑龙江科技信息,2012(27):105.
[3]高尚,杨静宁.一种新的基于例子群算法的聚类方法[J].南京航空航天大学学报,2006,(B07):62-65.
[4]崔丹丹.K-Means聚类算法的研究与改进[D].合肥:安徽大学,2012.
[5]黄继超.K-Means算法若干改进和应用[D].长沙:中南大学,2012:22-29.
[6]ZhouTao,Lu Huiling.Clustering algorithm research advances on data mining[J].Computer Engineering and Applications,2012(12).
[7]陆声链,林士敏.基于距离的孤立点检测研究[J].计算机工程与应用,2004,40(33):73-75.
[8]李金宗.模式识别导论[M].北京:高等教育出版社,1994: 294-356.
[9]何化玲.基于ID3决策树算法的改进研究[D].郑州:华北水利水电学院,2011.
[10]姜晗,贾涑.基于聚类的孤立点检测算法[J].计算机与现代,2012(11):37-39.
[11](印度)MARGARETHDUNHAM.数据挖掘教程[M].郭崇慧,田凤占,晓明等译.北京:清华大学出版社,2005.
(责任编辑:王前)
TP274
A
1008-7974(2016)06-0010-06
10.13877/j.cnki.cn22-1284.2016.12.004
2016-06-23
福建省教育厅科技A类项目(JA15735)
张颖,女,福建南平人,讲师.
