基于Logistic回归和随机森林算法的2型糖尿病并发视网膜病变风险预测及对比研究
2017-01-05曹文哲应俊陈广飞周丹
曹文哲,应俊,陈广飞,周丹
中国人民解放军总医院 a. 生物医学工程研究室;b. 医务部,北京 100853
基于Logistic回归和随机森林算法的2型糖尿病并发视网膜病变风险预测及对比研究
曹文哲a,应俊a,陈广飞a,周丹b
中国人民解放军总医院 a. 生物医学工程研究室;b. 医务部,北京 100853
目的应用随机森林算法和Logistic回归算法,分析2型糖尿病并发视网膜病变的关联因素并构建风险预测模型。方法采用2011~2013年中国人民解放军总医院2型糖尿病住院患者的电子病历信息,主要利用其中的糖尿病诊断数据、糖尿病糖化数据以及糖尿病生化检查数据,应用Logistic回归和随机森林算法,根据ROC曲线下面积比较两种模型的预测效果。结果在随机森林模型的39个变量重要性评分中,糖化血红蛋白、空腹血糖、尿素、肌酐、尿酸、年龄、冠心病和慢性肾病得分较高且具有临床意义,Logistic回归模型最终纳入性别、血糖控制情况(糖化血红蛋白浓度)、慢性肾病、冠心病、心梗和癌症6个因素,ROC曲线下面积提示随机森林模型预测效果优于Logistic回归模型。结论本次研究随机森林算法分析结果给出了各个因素指标的重要性评分,为2型糖尿病并发视网膜病变的早期诊断以及优化诊断流程提供了一定的依据。
2型糖尿病;视网膜病变;关联因素;风险预测;随机森林算法;Logistic回归算法
0 引言
糖尿病及其并发症现已成为世界范围内的重要公共健康问题,且糖尿病发病率非常高,几乎达到流行病的比例[1]。糖尿病并发视网膜病变,也称糖尿病眼病,是糖尿病性微血管病变中最重要的表现,也是糖尿病患者常见的并发症之一。糖尿病并发视网膜病变在10年期以上的糖尿病患者中患病率高达80%[2],是全球中老年人视力丧失的主要原因[3],一项Meta分析结果[4]显示在中国糖尿病患者中糖尿病并发视网膜病变的患病率为23%。糖尿病并发视网膜病变是劳动年龄人口(20~64岁)致盲的主要因素[5],有研究[6-7]提示40岁以下患糖尿病的人群中视网膜病变的发病率为33.3%,是40岁以上患病人群的2倍(15.6%),具有早期隐蔽性、慢性进展性、不可逆性的特点,按照疾病的发展进程可以分为2型6期,其中1~3期为单纯型视网膜病变,4~6期为增殖型视网膜病变,因此针对糖尿病并发视网膜病变做好早期预防是很必要的。
近年来,大数据分析与数据挖掘逐渐引起关注,尤其是在医疗卫生领域,数据挖掘的运用极其广泛。本研究采用了基于机器学习理论的随机森林模型和基于流行病学研究设计的Logistic回归模型,分析2型糖尿病并发视网膜病变的关联因素并建立风险预测模型,通过ROC曲线下的面积(Area Under Curve,AUC)比较两种风险预测模型的优劣,以期为内分泌科临床实践中糖尿病患者并发视网膜病变的风险评估提供数据指导,尽早发现病情,确定诊断方案,开展临床治疗。
1 方法
1.1 数据标准化与合并
选取中国人民解放军总医院内分泌科2011~2013年住院患者的糖尿病诊断、糖化以及生化检查数据。其中3种数据分属于独立的表格,并对其进行整合得到可用于统计分析的数据集。数据整合的步骤如下:① 根据首次诊断信息提取2型糖尿病并发视网膜病变以及无视网膜病变的2型糖尿病患者信息;② 根据患者就诊ID以及诊断时间从糖化检查以及生化检查表中提取距离诊断时间最近的一次患者检查信息;③ 从糖化、生化实验室检查中的诊断信息中提取出合并症的信息,包括高血压、血脂异常、肾病、肿瘤、大血管病变、周围神经病变、心梗、脑梗、冠心病。有关提取的变量信息见表1。
表1 变量信息表类别变量名中文描述人口学信息Sex性别
Age年龄
诊断信息Diagnosis2型糖尿病并发视网膜病变
Hyperten高血压
Hyperlip血脂异常
Kidney Dis肾病
Cancer肿瘤
Macroangiopathy大血管病变
PNP周围神经病变
Myocadinf心梗
Cerebralinf脑梗
Guanxinbing冠心病糖化HbA1c糖化血红蛋白生化ALT谷丙转氨酶
AST谷草转氨酶
TP血清总蛋白
ALB血清蛋白
TBIL总胆红素
DBIL直接胆红素
ALP 碱性磷酸酶
Urea 尿素
GGT γ-谷胺酰转肽酶
Cre肌酐
GLU_blood血糖
TG 甘油三酯
S_UA尿酸
TCHO 总胆固醇
CK 肌酸激酶
LDH 乳酸脱氢酶
Ca 钙
Na 钠
K 钾
Cl 氯
P 磷
Mg 镁
Lipase 酯酶
HDL_C 高密度脂蛋白胆固醇Fe 铁
UIBC 不饱和铁结合力
1.2 随机森林模型
1.2.1 随机森林基本原理
随机森林由Breiman[8]在2001年提出,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
1.2.2 随机森林算法
随机森林中的每一棵分类树为二叉树,其生成遵循自顶向下的递归分裂原则,即从根节点开始依次对训练集进行划分;在二叉树中,根节点包含全部训练数据,按照节点不纯度最小原则,分裂为左节点和右节点,它们分别包含训练数据的一个子集,按照同样的规则节点继续分裂,直到满足分支停止规则而停止生长。若节点n上的分类数据全部来自于同一类别,点的不纯度I(n)=0。不纯度度量方法是Gini准则,即假设P(ωj)是节点n上属于ωj类样本个数占训练样本总数的频率,则Gini准则表示为:(1)
具体算法过程如下:
(1)N表示原始训练集样本个数,mall用来表示变量的数目。
(2)应用bootstrap法有放回地随机抽取k个新的自助样本集,并由此构建k棵决策树,每次未被抽到的样本组成了k个袋外数据(Out-of-Bag,OOB)。
(3)每个自助样本集用于建立一棵决策树,在每一棵树的每个节点处随机抽取mtry个变量(mtry<mall),然后在中选择一个最具有分类能力的变量,变量分类的阈值通过检查每一个分类点确定。
(4)每棵树最大限度地生长,不做任何修剪。
(5)将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果视树分类器的投票多少而定。
在随机森林构建过程中,自助样本集用于每一个树分类器的形成,每次抽样生成的OOB被用来预测分类的正确率,对每次预测结果进行汇总得到错误率的OOB估计,然后评估组合分类器判别的正确率。此外,在随机森林中,所应用的自助样本集从原始的训练样本集中随机选取,每一棵树所应用的变量也是从所有变量mall中随机选取,两次随机过程使得随机森林具有较稳定的错误率,同时应用袋外数据来衡量分类器的性能。
随机森林中最重要的参数是mtry,Svetnik等[9]通过试验证实是一种较好的选择。随机森林中另外两个重要的参数是构建分类树的个数ntree和叶节点nodesize的大小,本研究采用ntree=500和nodesize=1进行研究。
1.2.3 变量重要性评分
变量重要性评分用于评价变量对于结局发生的影响,变量的重要性评分越高,则表明该变量越有能力对结局变量进行分类。设原始样本含量为N,各影响因素变量分别为x1,x2,…,xm。应用bootstrap法有放回地随机抽取b个新的自助样本,并由此形成b个分类树,每次未被抽到的样本则组成b个袋外数据[10]。袋外数据作为测试样本可以用来评估各个变量在分类中的重要性,具体实现过程如下:
(1)用自助样本形成每一个树分类器,同时对相应的OOB进行分类,得到b个自助样本的OOB中每一个样品的投票分数,记为rate1,rate2,...,rateb。
(2)将变量xi的数值在b个OOB样本中的顺序随机改变,形成新的OOB测试样本,然后用已建立的随机森林对新的OOB进行分类,根据判别正确的样品数得到每一个样本的投票分数,所得结果用矩阵表示为
(2)
(3)用rate1,rate2,...,rateb与矩阵(2)对应的第i行向量相减,求和平均后再除以标准误得变量xi的重要性评分,即(3) 1.3 Logistic回归模型
基于大样本数据库应用流行病学研究设计,采用等样本量病例对照研究,将数据库中全部2型糖尿病并发视网膜病变患者作为病例组,采用简单随机抽样法在全部非2型糖尿病并发视网膜病变患者中抽取与病例组等样本量的对照组。结合文献资料、专家经验和临床知识选取研究因素。采用SPSS 21软件对数据进行统计学分析,利用卡方检验分析不同因素与2型糖尿病并发视网膜病变的关联性,检验水准α=0.05。应用Logistic回归分析法建立2型糖尿病并发视网膜病变关联因素模型,自变量筛选采用以似然比检验为依据的前向步进法(Forward: LR),以P<0.05为纳入标准,P>0.1为剔除标准。
2 结果
2.1 随机森林模型结果
本研究应用随机森林方法对2型糖尿病与2型糖尿病并发视网膜病变进行分类预测,算法通过R软件实现。根据2型糖尿病患者的基本信息(年龄、性别)以及实验室检查信息建立随机森林预测模型对2型糖尿病与2型糖尿病并发视网膜病变进行分类预测研究。糖尿病数据中的检查信息存在一些数值缺失,本研究利用随机森林方法内嵌的临近估计填补方法对其进行填补。
为了准确地评价随机森林分类模型的效果,本研究将经过预处理的样本分析数据随机分成两部分,其中3/4为训练样本,1/4为测试样本,按此方法随机组成100个训练集和100个测试集,分别利用训练集建立预测模型,然后利用测试集对模型进行效果评价。对模型的评估侧重于模型本身的精度、准确度、效果、效率等,主要采用错误率(Err. rate)、灵敏度(Sen)、特异度(Spe)和AUC 4种评价指标,其中灵敏度和特异度是按照概率0.5为判别阈值预测分类的评价结果,AUC是综合评价的结果。
在随机森林模型的建立过程中,随机森林方法能够给出模型中每个变量的重要性评分,结果见图1。可以看出糖尿病相关指标如HbA1c、GLU_blood得分较高,肾功能检查指标如Urea、Cr、UA等也对分类起一定的作用,除此以外,年龄、合并冠心病以及肾病也对模型分类有一定贡献。
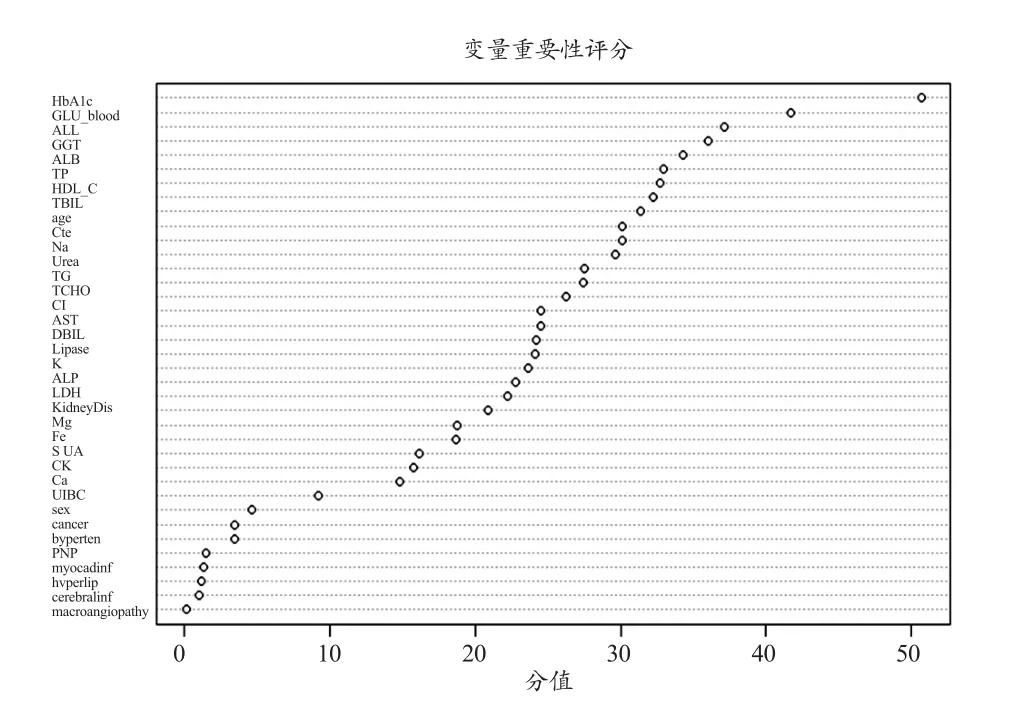
图1 随机森林变量重要性评分
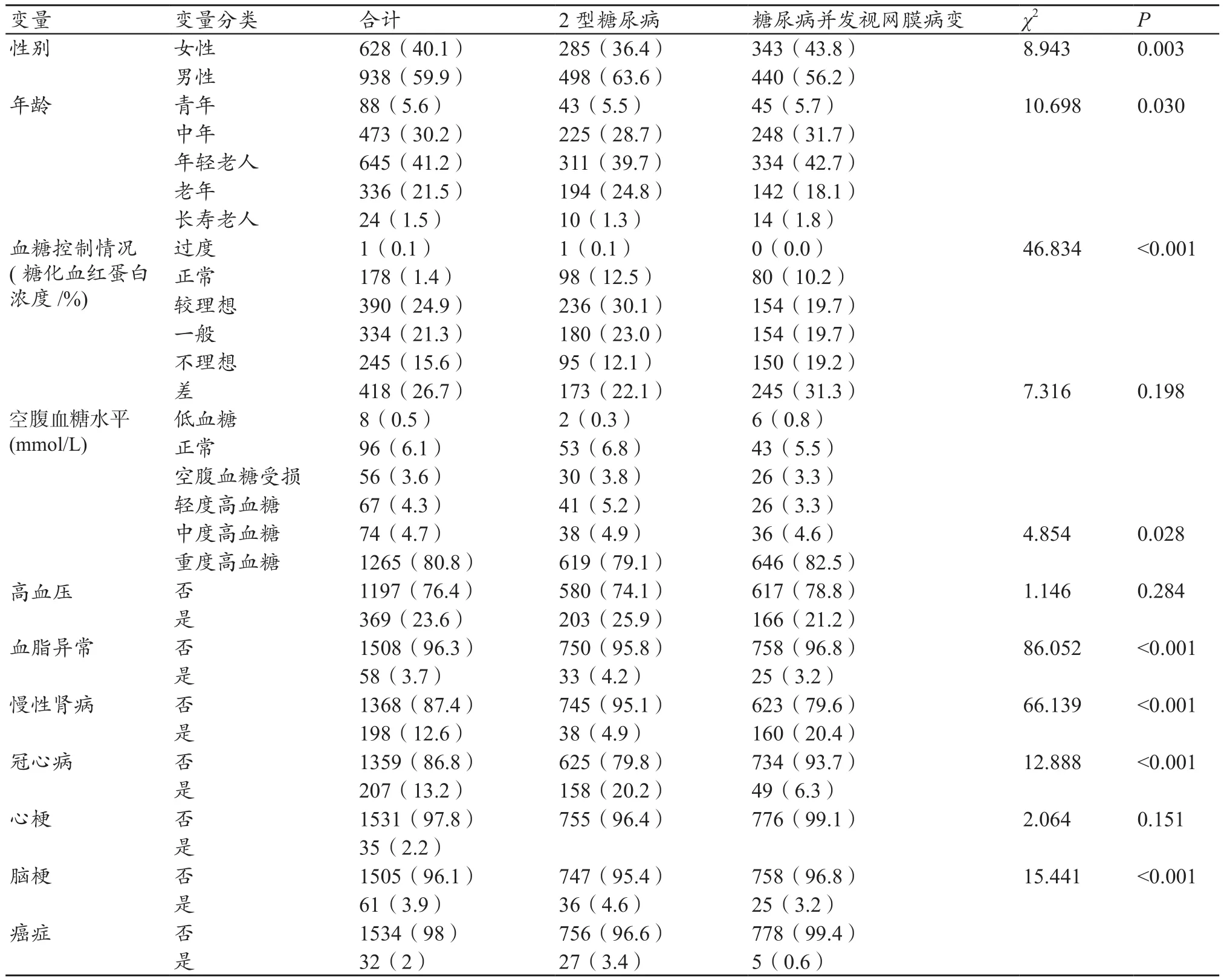
表2 基本情况及卡方检验结果,n(%)
2.2 Logistic回归模型结果
最终纳入研究的样本共1566例(病例组和对照组各783例),其中女性占40.1%,平均年龄为(64.2±13.0)岁,其中60~74岁的年轻老人占41.2%,血糖控制情况差或不理想者(糖化血红蛋白浓度>8%)占42.3%,血糖重度升高者(空腹血糖浓度≥11.1 mmol/L)占80.8%,高血压患者占23.6%,血脂异常者占3.7%,慢性肾病患者占12.6%,冠心病患者占13.2%,心梗患者占2.2%,脑梗患者占3.9%,癌症患者占2.0%,各分类变量基本情况及卡方检验结果见表2,其变量赋值可见表3。
单因素分析结果显示,糖尿病并发视网膜病变的关联因素包括性别、年龄、血糖控制情况(糖化血红蛋白浓度)、高血压、慢性肾病、冠心病、心梗和癌症,见表2。其中,女性、90岁以上老年人、血糖控制情况不理想(糖化血红蛋白浓度8%~9%)、未患高血压、患有慢性肾病、未患冠心病、未患心梗及未患癌症的糖尿病患者视网膜病变的发生率较高。
Logistic回归模型因变量及各自变量赋值,见表3。最终纳入Logistic回归模型的关联因素包括性别、血糖控制情况(糖化血红蛋白浓度)、慢性肾病、冠心病、心梗和癌症,见表4。其中,男性与女性相比,糖尿病并发视网膜病变风险减少29%(OR=0.71);血糖控制情况每恶化一个水平,糖尿病并发视网膜病变风险增加30%(OR=1.30);慢性肾病患者糖尿病并发视网膜病变风险增加4.48倍(OR=5.48);冠心病患者、心梗患者和癌症患者的糖尿病并发视网膜病变风险则分别减少68%(OR=0.32)、63%(OR=0.37)和82%(OR=0.18)。

表3 Logistic回归模型变量赋值
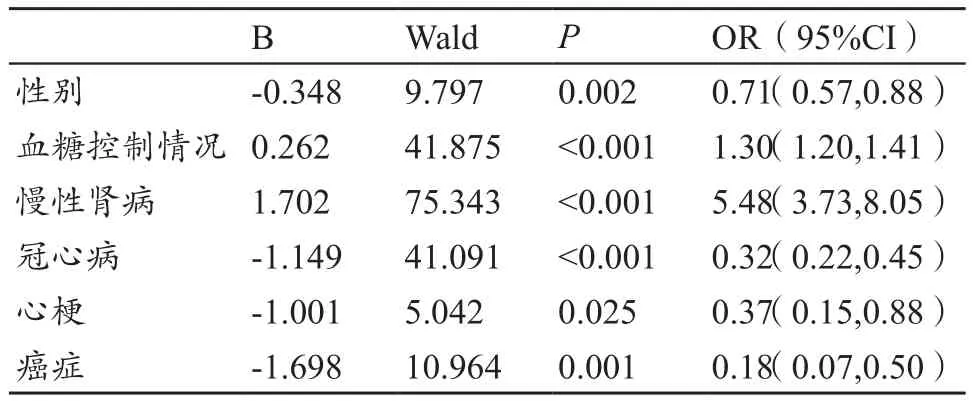
表4 糖尿病并发视网膜病变关联因素的Logistic模型
2.3 两种模型结果的比较
表5中给出了随机森林模型与Logistic回归模型预测的结果,其中随机森林是对100个测试数据集预测的结果,包括各评价指标的均值和标准差。可以看出随机森林模型在各个评价指标结果中都要优于Logistic回归模型。两种模型预测效果的ROC曲线见图2,在检验水平α=0.05下对两种模型作差异性检验,得P=0.0019,由此可见随机森林模型综合预测效果要优于Logistic回归模型。
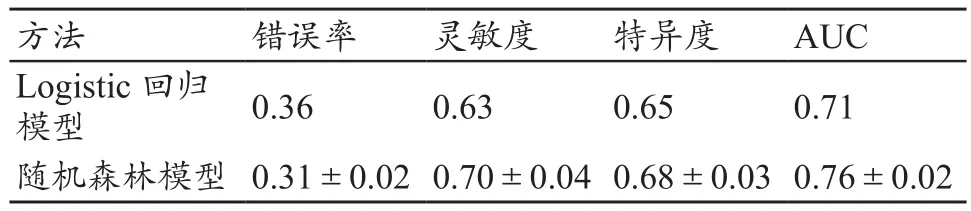
表5 随机森林模型与Logistic回归模型预测结果比较
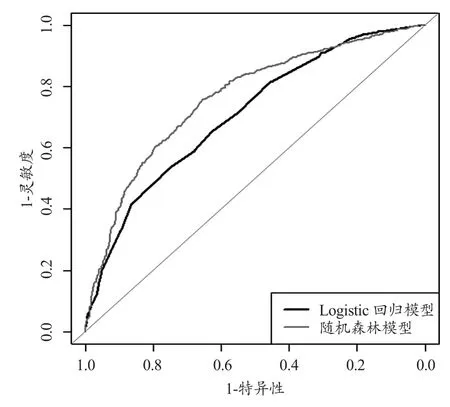
图2 Logistic回归与随机森林的ROC曲线
3 讨论
在进行数据整理时发现数据本身存在着变量缺失和变量数据缺失的问题,如已知的2型糖尿病并发视网膜病变重要风险因素糖尿病病程变量缺失,生化检查结果变量有较多的缺失数据,这些都造成了后续模型拟合时在准确度和精密度上存在一定误差[11-12]。
既往研究表明2型糖尿病并发视网膜病变的发生发展与糖尿病病程、高血压、高血糖、血脂异常、慢性肾病及相关实验室检查指标等多种因素有关[13-16]。本文研究的Logistic分析结果显示,慢性肾病与糖化血红蛋白浓度是2型糖尿病并发视网膜病变的危险因素。慢性肾病与2型糖尿病并发视网膜病变的关联性较为明确,临床上认为糖尿病并发视网膜病变与慢性肾病具有相似的病理基础,即微血管病变和微循环障碍,本研究中慢性肾病患者发生糖尿病并发视网膜病变的风险增加近5倍,验证了慢性病肾病与糖尿病并发视网膜病变的关联性。许多研究进一步指出,反映慢性肾病程度的尿白蛋白是与糖尿病并发视网膜病变高度相关的独立危险因素[17-18]。血糖控制情况是糖尿病并发视网膜病变的另一重要影响因素。与多数研究结果相同,本研究中糖化血红蛋白浓度的升高增加了2型糖尿病并发视网膜病变的风险,但空腹血糖值与2型糖尿病并发视网膜病变在本次研究中未表现出关联性。其原因可能是空腹血糖值仅反映一次测量的血糖水平,而糖化血红蛋白可反映近3个月的血糖水平,能更好地反映平时血糖控制情况,与2型糖尿病并发视网膜病变的关联性更显著[19]。本研究中冠心病、心梗和癌症与2型糖尿病并发视网膜病变也具有关联性,但其对2型糖尿病并发视网膜病变的保护作用与临床机制和相关研究不符,可能的原因是研究资料中存在共线性,或样本中冠心病、心梗和癌症的病例数太少导致参数估计不可靠。本研究发现糖尿病并发视网膜病变的另一关联因素是性别,女性比男性糖尿病患者并发视网膜病变的风险大。性别在有关2型糖尿病并发视网膜病变关联因素的现有研究中较少涉及,其关联程度和影响作用有待进一步的流行病学研究或大数据分析验证。此外,既往研究中2型糖尿病并发视网膜病变传统的危险因素高血压和血脂异常在本研究中均未被纳入多因素模型,可能是样本中高血压和血脂异常的病例数太少导致(样本总量中高血压患者占23.6%,血脂异常仅占3.7%)。
本次研究,随机森林算法分析结果给出了各个因素指标的重要性评分,为2型糖尿病并发视网膜病变的早期诊断以及优化诊断流程提供了一定的依据,但是在变量重要性评分中实验室检查结果变量的表现普遍优于诊断结果变量,产生此现象主要是由于诊断结果变量在数据集中出现频率较低,此种偏移在Logistic回归分析中也产生了不利的影响。随机森林算法分析结果筛选出了一些现在医学机制上尚无法解释的变量,这可为以后的研究提供方向,但值得注意的是这些无法解释的变量可能是由于数据集本身的样本量限制及自变量间的相关性导致[20-21]。与Logistic回归相比,随机森林算法通过大量随机选择样本的方法平衡了样本误差的影响,对由此产生的大量不同测试数据进行分类综合评价,较仅以单个测试样本进行拟合的Logistic回归的结果更为可靠,但其对影响因素的解释较为模糊,无法给出影响因素相对危险度的估计以及作用的方向性。
[1] Sun JK,Cavallerano JD,Silva PS.Future promise of and potential pitfalls for automated detection of diabetic retinopathy[J].JAMA Ophthalmol,2015,17:1-2.
[2] Kertes PJ,Johnson TM.Evidence Based Eye Care[M]. Philadelphia,PA:Lippincott Williams & Wilkins,2007.
[3] Ting DS,Cheung GC,Wong TY.Diabetic retinopathy: global prevalence,major risk factors,screening practices and public health challenges: a review[J].Clin Experiment Ophthalmol, 2015,43(9):1-4.
[4] Liu L,Wu X,Liu L,et al.Prevalence of diabetic retinopathy in mainland China: a meta-analysis[J].PLoS One,2012,7(9):e45264.
[5] Engelgau MM,Geiss LS,Saaddine JB,et al.The evolving diabetes burden in the United States[J].Ann Intern Med,2004,140(11): 945-950.
[6] Raman R,Vaitheeswaran K,Vinita K,et al.Is prevalence of retinopathy related to the age of onset of diabetes?Sankara Nethralaya Diabetic Retinopath Epidemiology and Molecular Genetic Report No.5[J].Ophthalmic Res,2011,45(1):36-41.
[7] Chatziralli IP,Sergentanis TN,Keryttopoulos P,et al.Risk factors associated with diabetic retinopathy in patients with diabetes mellitus type 2[J].BMC Res Notes,2010,3:153.
[8] Breiman L.Random forests[J].Machine Learning,2001,45 (1):5-32.
[9] Svetnik V,Liaw A,Tong C,et al.Random forest:A classification and regression tool for compound classification and QSAR modeling[J].J Chem Inf Comput Sci,2003,43(6):1947-1958.
[10] Díaz-Uriarte R,Alvarez de Andrés S.Gene selection and classification of microarray data using random forest[J].BMCBioinformatics,2006,7:3.
[11] Abougalambou SS,Abougalambou AS.Risk factors associated with diabetic retinopathy among type 2 diabetes patients at teaching hospital in Malaysia[J].Diabetes Metab Syndr,2015,9(2): 98-103.
[12] Jee D,Lee WK,Kang S.Prevalence and risk factors for diabetic retinopathy: the Korea National Health and Nutrition Examination Survey 2008-2011[J].Invest Ophthalmol Vis Sci,2013,54(10):6827-6833.
[13] Dowse GK,Humphrey AR,Collins VR,et al.Prevalence and risk factors for diabetic retinopathy in the multiethnic population of Mauritius[J].Am J Epidemiol,1998,147(5):448-457.
[14] Ronald K,Barbara EK,Scot EM,et al.The Wisconsin epidemiologic study of diabetic retinopathy.II.Prevalence and risk of diabetic retinopathy when age at diagnosis is less than 30 years[J].Arch Ophthalmol,1984,102(4):520-526.
[15] McKay R,McCarty CA,Taylor HR.Diabetic retinopathy in Victoria,Australia:the Visual Impairment Project[J].Br J
Ophthalmol,2000,84(8):865-870.
[16] Varma R,Macias GL,Torres M,et al.Biologic risk factors associated with diabetic retinopathy:the Los Angeles Latino Eye Study[J].Ophthalmology,2007,114(7):1332-1340.
[17] Pontuch P,Vozár J,Potocký M,et al.Relationship between retinopathy,and autonomic neuropathy in patients with type 1 diabetes[J].J Diabet Complications,1990,4(4):188-192.
[18] Savage S,Estacio RO,Jeffers B,et al.Urinary albumin excretion as a predictor of diabetic retinopathy,neuropathy,and cardiovascular disease in NIDDM[J].Diabetes Care,1996,19(11):1243-1248.
[19] 伍春荣,马志中,胡莲娜,等.糖尿病视网膜病变相关因素的因子分析[J].国际眼科杂志,2007,7(4):1056-1059.
[20] Nicodemus KK,Malley JD,Strobl C,et al.The behaviour of random forest permutation-based variable importance measures under predictor correlation[J].BMC Bioinformatics,2010,11:110.
[21] Strobl C,Boulesteix AL,Zeileis A,et al.Bias in random forest variable importance measures:ilustrations,sources and a solution[J].BMC Bioinformatics,2007,8:25.
Risk Prediction and Comparitive Research of Type 2 Diabetes Mellitus Complicated with Retinopathy based on Logistic Regression and
Random Forest Algorithm
CAO Wen-zhea, YING Juna, CHEN Guang-feia, ZHOU Danb
a.Department of Biomedical Engineering; b.Department of Medical Management, General Hospital of PLA, Beijing 100853, China
ObjectiveTo analyze the relevant factors of type 2 diabetes mellitus complicated with retinopathy and to construct the risk prediction model based on machine learning, the random forest algorithm, and the Logistic regression algorithm based on the epidemiological design.MethodsTo analyze the data from the electronic medical record of patients with type 2 diabetes mellitus complicated with retinopathy in the General Hospital of PLA during 2011-2013. The main focus was on the diagnostic data of diabetes mellitus, the glycosylated data, and biochemical examination data. The prediction effect of the two models were compared with the Logistic regression algorithm and random forest algorithm according the area under the ROC curve.ResultsAmong the 39 variables in the the random forest models, blood glucose control (HbAlc), fasting glucose, urea, creatinine, uric acid, age, coronary heart disease (CHD), and chronic kidney disease (CKD) had higher scores and were of significant clinical explanations. The Logistic regression model finally in corporated six factors: sex, HbAlc, CKD, CHD, myocardial infarction, and cancer. The area under the ROC curve showed that the prediction effect of the random forest model was better than the Logistic regression Model.ConclusionThe research provided grading of the significance of different variable, which to a certain extent provides guidance for the early diagnosis of type 2 diabetes mellitus complicated with retinopathy and the optimization of clinical diagnosis flow.
type 2 diabetes mellitus; retinopathy; correlative factor; risk prediction; random forestalgorithm; Logistic regressionalgorithm
TN957.51
A
10.3969/j.issn.1674-1633.2016.03.006
1674-1633(2016)03-0033-06
2016-01-15
国家自然科学基金( 61501518)。通信作者:周丹,教授,博士生导师。
邮箱:zd99@vip.sohu.com
