基于Q学习的管制员Agent学习行为研究
2017-01-03刘岳鹏林颖达
刘岳鹏,隋 东,林颖达
(南京航空航天大学 民航学院,南京 211106)
基于Q学习的管制员Agent学习行为研究
刘岳鹏,隋 东,林颖达
(南京航空航天大学 民航学院,南京 211106)
管制员Agent是空中交通运行仿真系统中的核心部分,为了提高其知识库的完备程度,做到空中交通的精确仿真,可以考虑将机器学习理论引入管制员Agent模型.研究了相关机器学习算法,提出管制员Agent的个体机器学习行为,选择Q学习算法对管制员Agent的学习行为进行建模,使管制员Agent能在空中交通运行仿真中取得最优策略,完善自身冲突解脱知识库的不足.仿真结果证明了管制员Agent学习行为的合理性.
交通运输规划与管理;行为建模;Q学习;多Agent系统
近年来,空中交通需求日益增长,而现有的空中交通管制保障能力有限,需求与供给的矛盾日益突出.无论是调整现有交通系统中的空域结构、航路航线等元素还是采用新技术新概念都需要事先做安全评估,查找潜在的危险因素[1].考虑到空中交通管理系统的复杂性,使用计算机软件来仿真空中交通管理系统成为了一种重要的研究手段.这种手段不仅可以减少对新技术新概念验证的成本,还可以对现有运行模式下所存在的潜在安全问题进行分析评估,具有非常重要的理论意义与研究价值.但是,由于空中交通管理系统的规模庞大,基于单机进行计算的集中式仿真难以胜任.针对此问题,分布式人工智能——多Agent系统技术被应用于空中交通运行仿真系统中[2].管制员Agent是整个仿真系统中的核心,它的任务是监视其所在扇区内的航空器Agent的活动并对其进行调配.随着空中交通运行仿真系统越来越智能化,传统的基于知识库的冲突调配方法较难满足系统的需要.因此,从仿真过程中获得经验以扩充其知识库是管制员Agent必不可少的能力.本问研究了相关机器学习算法,并在先验知识库的基础上,提出管制员Agent的个体机器学习算法,并选择Q学习算法对管制员Agent的学习行为进行建模,使管制员Agent能在空中交通运行仿真中对航空器Agent之间的冲突进行灵活调配,完善自身冲突探测与解脱知识库的不足,提升整个仿真系统的智能程度[3].
1 Q学习算法原理与模型
强化学习的主要思想是处于环境中的一个Agent可以感知环境状态,并且自身带有确定的动作集S,Agent根据当前环境的状态执行动作集A中的一个动作a,通过接受奖励或惩罚,由此决定当前状态应该执行哪种动作.在该学习系统中,存在预先制定好的奖励和惩罚措施,Agent每执行一个动作,系统都会对这个动作进行一个评价.最后,Agent会选择那些评价相对较高的动作并执行,经过大量训练样本的训练,最终能得到一套状态-动作映射关系,即策略π:S→A.

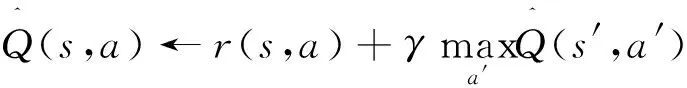
(1)
其中:r(s,a)为立即回报,γ为折算因子.
2 管制员Agent的学习行为实现

2.1 航空器Agent状态信息描述
Q学习解决的问题有如下特点:规模相对较小、环境状态和动作集是离散的.因此,如果环境状态和动作集是连续的,使用Q学习解决此类问题必然会出现“维数灾难”,学习的效率不能得到保证[6].由于管制员Agent所处的环境是连续的,因此在管制员Agent中实现Q学习行为,应将管制员Agent获取的航空器Agent的状态信息进行离散化.
航空器Agent有很多状态,在冲突探测与解脱时,主要判断的是航空器Agent的高度和速度.在程序设计中,构建State类,通过调用State类中的函数,可得到航空器Agent的部分状态值.其中,定义离散高度层数量40个,离散真空速数量20个,冲突类型分为同航迹、逆向航迹和交叉航迹3种,两个航空器Agent的上升/下降率按照上升、平飞和下降分为3个.其中,根据状态组合,共得到40×20×3×3×3=21 600种可能存在的状态.
2.2 航空器Agent高度离散化
航空器进行航路和航线飞行时,按照我国生效的巡航高度层配备方案所配备的巡航高度层飞行,根据飞行高度层的配备,可以将飞行高度进行离散化处理.根据真航线角建立东向飞行高度层数组和西向飞行高度层数组,共设置20个西向飞行高度层和20个东向飞行高度层,完成航空器Agent高度的离散化.
2.3 航空器Agent速度离散化
根据航空器在航路飞行时真空速的大小,本文将航空器Agent的真空速范围设定为110 ~300m/s.但实际的航空器的速度是个连续变量,并不利于Q学习算法的实现,因此根据实际管制规则,将速度步长设置为10 m/s.设置110 m/s为第1个真空速离散值,将真空速按照从小到大的顺序排列并编号0~19共20个离散真空速.以航空器Agent的真空速作为计算依据,与最小值110 m/s进行比较,即可得到当前真空速的编号,完成航空器Agent速度的离散化.
2.4 管制员Agent动作描述
管制员主要是通过调节速度和调节高度来对航空器之间的冲突进行调配,在此处,管制员Agent的主要动作为调节速度和调节高度.在动作定义过程中,主要分为保持速度、加速、减速、保持高度、上升高度和下降高度.在构建管制员Agent动作集时,建立Action类,包括15个静态变量.第0~4个变量为加速指令,其中,加速步长取10 m/s.第5~9个变量为减速指令,步长跟加速步长相同.其余变量分别定义为保持速度、保持高度、上升高度和下降高度.具体变量及含义如表1所示.
表1 管制员Agent的动作集定义

动作定义描述ATCAccelerateSpeedX加速(X×10)ATCDecelerateSpeedX减速(X×10)ATCMaintainSpeed保持速度ATCMaintainAltitude保持高度ATCAscendAltitude上升高度ATCDescendAltitude下降高度NumATCActions动作集中的动作总数量
2.5 回报的确定
状态和动作经过离散化后,整个仿真环境由连续状态和动作转化为离散化的状态和动作,已满足Q学习算法的使用条件.但是,Q函数中的各个变量还未确定.通过观察,在航空器Agent的状态改变时,对管制员Agent的动作即当前的管制指令进行评价,并优先选取评价较高的管制指令.
设定管制员Agent的每个动作初始Q值均为0.如果当前管制指令可以解决航空器Agent之间的冲突,则立即回报设置为正值,如果不能,则设置为负值.如前所述,管制指令只能执行一个,因此需要获得最优管制指令,还需要再评价一次Q值为正的管制指令.使用解脱时间t来进行衡量,其内部回报为:
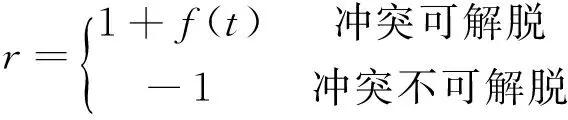
(2)
其中
(3)
2.6 具体学习行为实现方案
在确定了Q学习中的所有元素后,就可以用这些元素来实现管制员Agent的学习方案.
1)首先在程序中将所有Q值进行初始化;
2)管制员Agent获取航空器Agent信息后,将航空器Agent的信息通过State类中的函数进行离散化;
3)管制员Agent对动作集中的所有动作,根据能否解脱冲突和解脱冲突的代价对每一个管制指令进行评价,选取评价最高的一个动作作为最终输出的管制指令;
4)将航空器Agent的状态和指令绑定,进行Q值的更新,即迭代Q值.
3 仿真验证
3.1 仿真环境构建
基于Eclipse集成开发环境,欧盟开源项目JADE[7]开发框架,利用C#语言对ArcGIS Engine进行二次开发并构建仿真运行场景,并使用MySQL构建相关数据库,对空域、航路、机型、飞机性能数据进行管理,系统主界面如图1所示.
图1 仿真系统主控界面
航空器Agent的轨迹预测模型采用BADA 3.10[8]性能数据库,轨迹预测步长设置为Δt=4 s,与空管雷达刷新频率保持一致.
3.2 冲突场景构建
将冲突分为同航迹、逆向航迹和交叉航迹冲突,分别对不同种类的冲突进行冲突场景构建.以逆向航迹冲突为例,构造飞行计划,如表2、3所示,CXA1111从SASAN航路点飞行至P41航路点,起始高度600 m,巡航高度4 200 m.CXA2341从P41航路点飞行至SASAN航路点,起始高度600 m,巡航高度4 500 m.两架航班均处于A593航路飞行,两个航班均处于爬升状态并逆向飞行,如图2所示.
表2 逆向航迹冲突飞行计划

ID航班号机型计划时间起始航路点结束航路点飞行路径1CXA1111B73720131116160000SASANP41SASAN-P412CXA2341B73720131116160005P41SASANP41-SASAN
表3 飞行高度数据表
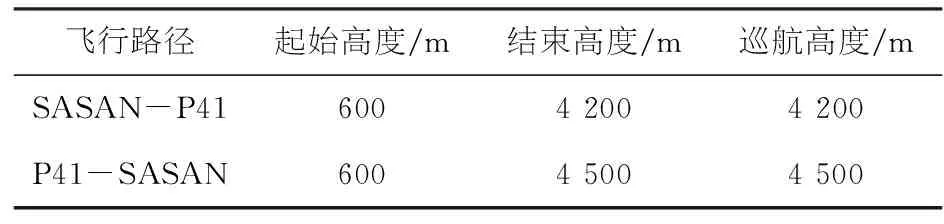
飞行路径起始高度/m结束高度/m巡航高度/mSASAN-P4160042004200P41-SASAN60045004500
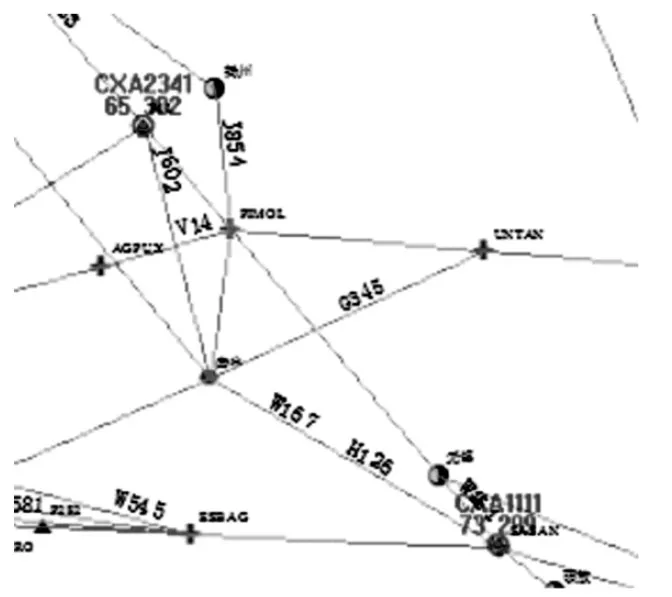
图2 两航空器Agent逆向航迹飞行
3.3 管制员Agent的学习行为验证
如前所述,航空器Agent的状态按照离散飞行
高度、离散飞行速度、冲突类型和航空器Agent的上升/下降率共分为五类.本文中只考虑两机之间的影响,因此取折算因子γ为0,即只考虑当前状态的影响,不考虑后续状态对当前的影响,因此对于每一个状态训练一次即可.在保证立即回报有界的情况下,Q函数可以确保是收敛的,并根据式(1)更新Q值.
管制员Agent根据状态-动作值自主进行决策,并得到状态-动作值最大的动作作为管制指令对航空器Agent之间的冲突进行调配.管制员Agent根据Q学习算法得出的结果如表4所示,管制员Agent可以将要调配的航空器Agent的状态进行离散化,得到离散的高度、速度、冲突类型以及上升下降率,并根据当前离散的状态对每个动作即管制指令进行评估,得到状态-动作值,即为该状态下每个动作的奖赏值.管制员Agent根据奖赏值的大小选择最优动作即当前状态下的最优管制指令,并将该状态的所有状态-动作值记录到Q表中,完成对该状态下的训练,并发送至航空器Agent进行冲突调配.
表4 逆向航迹冲突下的状态-动作值
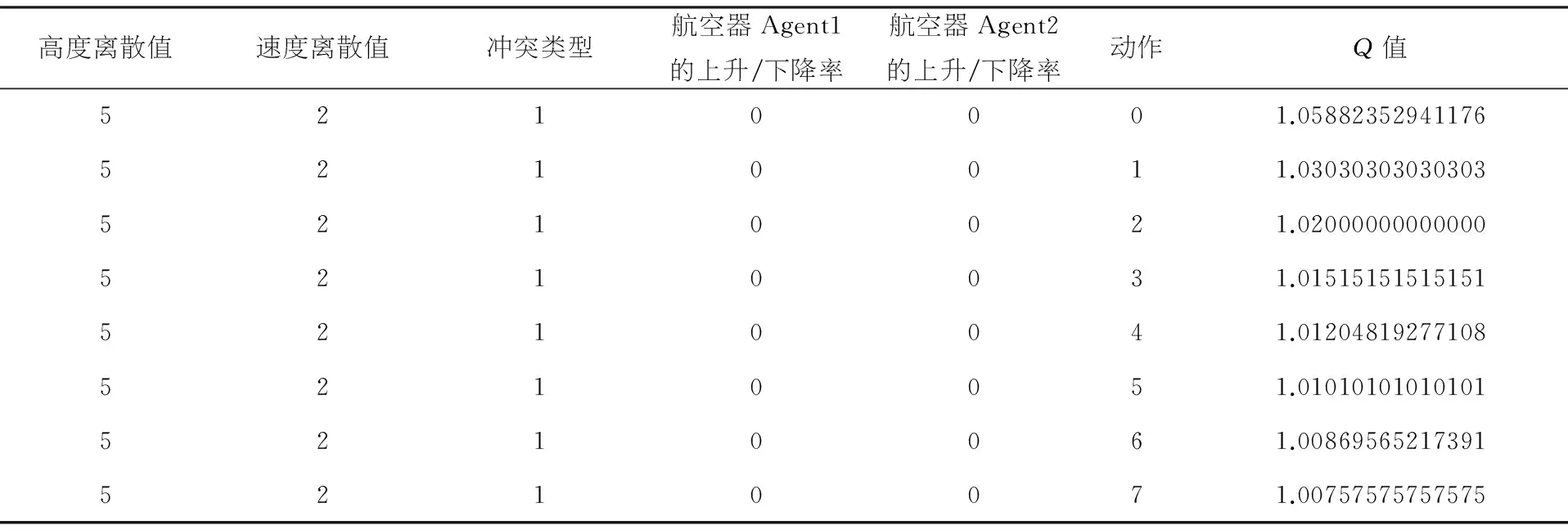
高度离散值速度离散值冲突类型航空器Agent1的上升/下降率航空器Agent2的上升/下降率动作Q值5210001.058823529411765210011.030303030303035210021.020000000000005210031.015151515151515210041.012048192771085210051.010101010101015210061.008695652173915210071.00757575757575
续表4
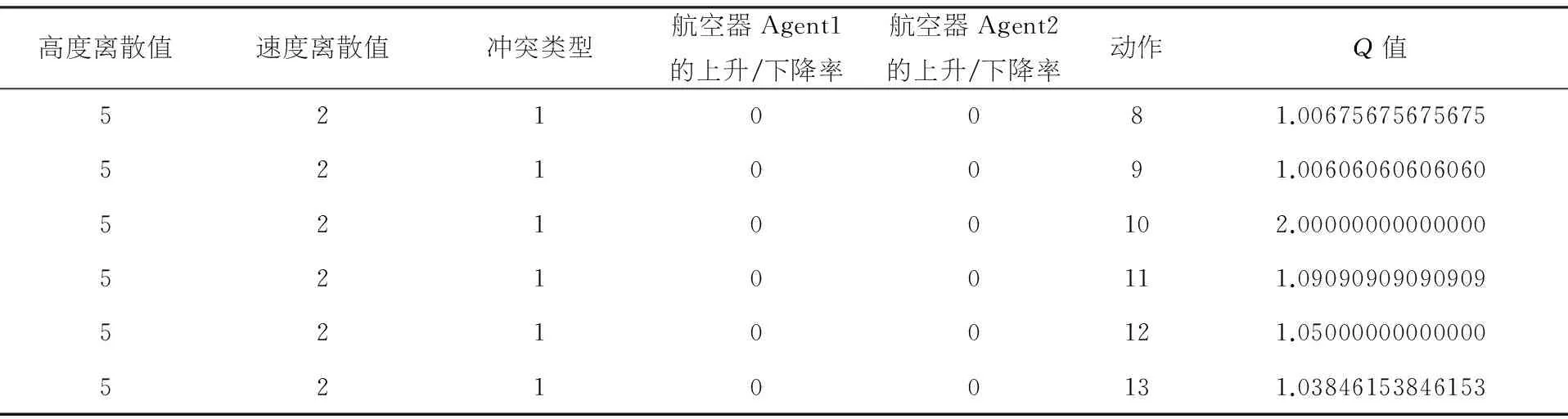
高度离散值速度离散值冲突类型航空器Agent1的上升/下降率航空器Agent2的上升/下降率动作Q值5210081.006756756756755210091.0060606060606052100102.0000000000000052100111.0909090909090952100121.0500000000000052100131.03846153846153
注:冲突类型0、1、2分别代表同航迹、逆向航迹和交叉航迹冲突;上升/下降率0、1、2分别代表上升、下降和平飞
从表4中可以看出,所有动作中动作10的Q值是所有动作中的最大值,因此动作10被选为最优管制指令进行输出.在动作集中定义动作10为保持当前速度,即对航空器Agent进行调速.从图3(B)中可以看出,CXA2341收到指令后即开始按当前速度飞行,而不是图3(A)中无管制指令情况下继续进行加速.从图4中可以看出,通过速度的减小而使航空器Agent的上升率减小,同样可以达到拉开垂直间隔并使冲突解脱的效果.图5将基于知识库的冲突解脱轨迹与基于Q学习算法的冲突解脱轨迹进行了对比,从图中可以看出两种指令分别进行了调高和调速,但均可以对冲突进行解脱.因此,一种冲突可能有不同的解脱方法,基于Q学习算法动态生成管制指令,可以对知识库进行完善.[9]

图3 航空器Agent的速度剖面对比

图4 CXA2341调速后两航空器Agent的垂直间隔修正空速/(m·s-1)t/s高度/m
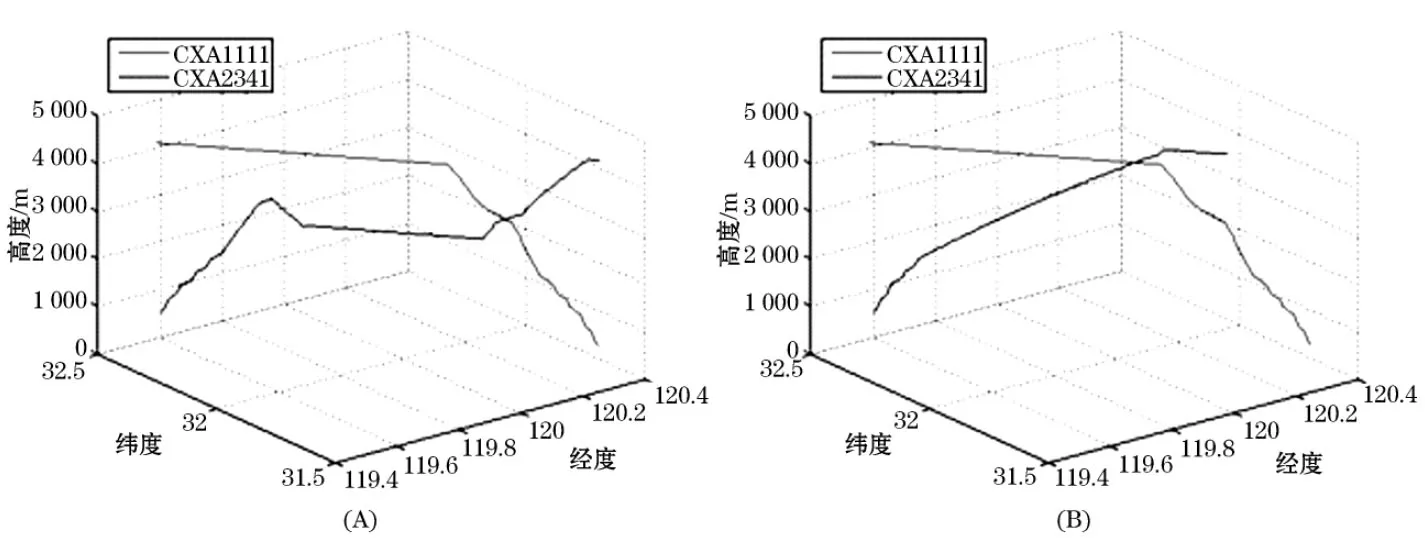
图5 基于知识库的冲突解脱与基于Q学习的冲突解脱三维轨迹对比
4 结 语
本文提出了管制员Agent的学习行为,使用Q学习算法实现管制员Agent的学习行为.首先将航空器Agent的状态参数和管制员Agent的动作进行离散化,使环境满足Q学习算法的要求.然后,通过确定Q学习算法中的回报、折算因子等参数,确定了Q值的更新方式,从而设计了管制员Agent的学习行为.最后,通过构建逆向冲突飞行计划验证了该学习行为的有效性.我国的空中交通正处于发展阶段,将机器学习技术应用于基于多Agent的空中交通运行仿真系统中,可为我国的扇区划设、跑道建设、航路设计以及航路网络优化等方面提供技术支持及工具,保证空中交通的安全运行.
[1] 王 超, 徐肖豪. 基于Agent的空中交通系统建模与仿真研究[J]. 计算机工程与应用, 2008, 44(31): 12-14.
[2] 刘成杰. 空中交通管制仿真分析——基于MAS的区域管制仿真[D]. 南京: 南京航空航天大学, 2013.
[3] 陈中祥. 基于BDI Agent的CGF主体行为建模理论与技术研究[D]. 武汉: 华中科技大学, 2004.
[4] POOLE D L, MACKWORTH A K. Artificial Intelligence: foundations of computational agents[M]. Cambridge University Press, 2010. 309-312.
[5] TZIORTZIOTIS N, TZIORTZIOTIS K, BLEKAS K. Play Ms. Pac-Man using an advanced reinforcement learning agent [M]. Artificial Intelligence: Methods and Applications. Springer International Publishing, 2014. 71-83.
[6] 王雪松, 朱美强, 程玉虎. 强化学习原理及其应用[M]. 北京: 科学出版社, 2014.
[7] BELLIFEMINE F L, CAIRE G, GREENWOOD D. Developing multi-agent systems with JADE [M]. [S.l.].John Wiley & Sons, 2007.
[8] NUIC A. User manual for the base of aircraft data (BADA) revision 3.10 [J]. Atmosphere, 2010, 2010: 001.
[9] 周雄飞,胡明华.基于RAMS仿真的扇区动态容量评估[J]. 哈尔滨商业大学学报:自然科学版,2016,32(5):626-630.
Research on learning behavior of air traffic controller based on Q-learning
LIU Yue-peng, SUI Dong, LIN Ying-da
(School of Civil Aviation, Nanjing University of Aeronautics & Astronautics, Nanjing 211106, China)
ATC Agent is the core part of an air traffic operation simulation system. In order to increase the degree of completeness of its knowledge base and achieve accurate simulation of air traffic, the machine learning theory was introduced into ATC Agent model. This paper studied the relevant machine learning algorithms and presented the individual learning behavior of ATC Agent. Then Q-learning algorithm wasselected to model the learning behavior of ATC Agent. Thus the ATC Agent was able to obtain the optimal strategy in the process of air traffic operation simulation and improve its knowledge base of conflict resolution.The simulation result proved the rationality of learning behavior of the ATC Agent.
transportation planning and management; behavior modeling; Q-learning; multi-Agentsystem
2016-01-14.
波音项目(1007-EBA14004);南京航空航天大学研究生创新基地(实验室)开放基金项目(kfjj20150702)
刘岳鹏(1989-),硕士,研究方向:空中交通智能化技术.
V355
A
1672-0946(2016)06-0763-06
