基于改进SMOTE的小额贷款公司客户信用风险非均衡SVM分类
2016-12-27衣柏衡朱建军
衣柏衡,朱建军,李 杰
(南京航空航天大学经济与管理学院,江苏 南京 211106)
基于改进SMOTE的小额贷款公司客户信用风险非均衡SVM分类
衣柏衡,朱建军,李 杰
(南京航空航天大学经济与管理学院,江苏 南京 211106)
研究了小额贷款公司对客户进行信用风险评估时面临的问题,构建了信用风险评估指标体系,改进了支持向量机(Support Vector Machine, SVM)对非均衡样本分类时分类超平面偏移的不足。首先分析小额贷款公司业务区域性强、信用数据来源不规范、评价标准不一致等特点,给出用于客户信用风险评估的四个维度指标。针对传统SMOTE算法在处理非均衡数据时对全部少数类样本操作的问题,提出仅对错分样本人工合成的改进思想,给出具体算法步骤。将改进算法用于某小额贷款公司客户信用风险评估案例中,分类精确度较其他算法有所提升,表明该方法的可行性和有效性。
小额贷款;信用风险;支持向量机;非均衡数据;SMOTE
1 引言
小额贷款公司作为新兴的民间金融服务机构,在一定程度上解决了小微企业和低收入人群融资难问题,同时对“地下钱庄”这类非法借贷活动起到抑制作用[1-2]。相比于城市金融市场,国有银行、大型商业银行、农村合作信用社在农村和欠发达地区贷款业务的普及和推广仍有诸多障碍和滞后,而民营小额贷款公司的出现,与前者一同构成较为完善的金融体系层次,弥补了政策限制、信贷配给不平衡、管理成本高等缺点和不足,是促进社会金融组织体系多样化、健康化发展的有益尝试[3]。然而,小额贷款公司面临的信用风险有其行业特殊性[4]。除去企业本身的财务杠杆比率、短期债务比率、流动资金等因素,客户质量和其违约情况是小额贷款公司的主要风险来源[5]。目前,小额贷款公司用于风险评估的数据主观性较大,通常是审核人员与借款人面对面交流,加上从其他渠道侧面获得的借款人信息来综合评估风险,这些数据可能出现造假或辨识度不高的问题。最重要的是,在进行信用风险评估的过程中,经常面临评价标准不一致,输入数据维度高、复杂度高这类问题,传统的决策方法不足以抓住导致违约的关键因素,不能合理将评价指标组合并做出判断。此时,小额贷款公司需要使用新的评价模型和方法,针对性解决上述信用风险评估中的问题[6]。
许多学者在信用风险评估问题上做了大量工作并应用到不同的领域。张大斌等[7]建立了信用风险评价的差分进化自动聚类模型,并将其应用到我国上市公司信用风险评价中。陈庭强等[8]从信用风险持有者的心理和行为角度对信用风险传染过程进行了分析,通过引入信用风险传染的主体行为因素,建立了信用风险传染的网络模型。Moges等[9]从数据质量角度出发,通过对世界范围内的金融机构进行问卷调查,给出了数据质量的定义、测度,并结合信用风险数据库分析了评价数据质量的关键指标。在个人信贷风险评估方面,Verbraken等[10]提出基于期望利润最大化(Expected Maximum Profit, EMP)思想,在预期损失和收益间进行权衡,进而给出允许向客户放贷的阈值。Li Yongbin等[11]提出基于犹豫三角模糊数的多属性决策模型,并用于商业银行个人信用风险评估案例。Zhang Zhiwang等[12]提出融合核函数、模糊隶属度和罚函数的多准则优化分类器,以解决个人信用风险评估中非线性和不确定性等问题。
计算科学和机器学习的快速发展,催生了一批新的智能数据挖掘方法,其中基于结构风险最小化的SVM克服了传统分类器局部最优解、过拟合、维数灾难等缺点[13]。Harris[14]提出聚类SVM来降低传统方法处理高维信用数据的计算复杂度。然而在信用风险评估问题中,数据不均衡是影响SVM分类精度最主要的原因,分类超平面偏移现象严重[15]。为此,Bagging、boosting、SMOTE和一些组合算法被相继提出,来解决分类问题中的数据不均衡问题[16]。Chawla等[17]提出的SMOTE借助少数类样本及其邻域样本生成新数据,抗噪性能较好。但通常SMOTE与SVM结合是对全部少数类样本进行操作,而只有分类面附近的少量样本会影响最终结果[18]。文传军等[19]从SVM求解过程出发,对上述问题进行了分析。章少平等[20]提出采用KSMOTE对非平衡数据处理并用Bootstrap抽样来生成基SVM分类器,再通过投票机制得出最终结果。
总体来看,现有文献大多融合SMOTE与其他算法来解决非均衡分类问题,而较少从SVM角度分析SMOTE所合成样本对其分类面的影响。基于此,本文提出一种改进的SMOTE思想,对SMOTE算法进行迭代,且仅选择上一次迭代中被错分的样本作为下一次迭代的起始样本,直到少数类和多数类样本数量均衡或不再有少数类样本被错分,算法停止。在实证分析中,本文对小额贷款公司客户信用风险评估的各项指标加以分析,构建了4个维度16个指标的评价体系,并将本文模型应用到具有高不均衡率的真实借贷数据中,算法精度有所提高,违约样本能被较好识别。
2 基于改进SMOTE的SVM分类算法
为保证叙述的完整性,本节首先简要介绍支持向量机理论,具体可参阅文献[21];结合小额贷款公司客户信用风险评估的特点,分析支持向量机在处理非均衡数据分类问题中的缺陷;最后提出改进SMOTE的SVM分类算法,并给出具体算法流程。
2.1 现有方法及问题分析
给定训练集T={(x1,y1),(x2,y2),…,(xl,yl)}∈(n×)l,其中每个样本点(xi,yi)中xi∈n是包含n维属性的向量,yi={+1,-1}是对应的类别标签。支持向量机试图寻找n空间上的一个使分类边界最小的实数函数g(x)=(wT·x+b),以便用决策函数f(x)=sgn(g(x))推断任意新输入x对应的分类类别y。对于线性分类问题,求解最优分类超平面可表示为求解下列二次规划:
(1)
其中C>0为罚函数,ξi为允许数据点xi偏离的松弛变量。
为方便求解,构造拉格朗日函数:
(2)
对L关于w,b,ξ求极小,并将结果带回(2),可得到原问题(1)的对偶问题:
(3)
求解对偶问题(3)得到αi,进而推倒出w和b。
传统SVM分类算法大都基于数据集中正负类样本数量大致相同的假设,然而这一假设在很多现实应用领域并不成立。在信用风险评估中,无违约记录通常占绝大多数,只有极个别的用户出现违约。作为小额贷款公司,并不会过多关注无违约记录,相反希望能够准确识别出可能存在违约风险的客户,甚至在很多时候为了控制风险,宁愿将处于无违约风险边缘的客户划为违约风险客户。而传统SVM在处理非均衡数据分类问题,分类平面会向少数类偏移,即将更多的少数类样本错分为多数类,这样势必会增大小额贷款公司的放贷风险。
为方便说明问题,用matlab随机生成两类高斯样本,样本数分别为20个和200个,不均衡比例为10。一类样本中心为(1.5,1.5),另一类样本中心为(2.5,2.5),两类样本的方差均为0.5。用传统SVM进行分类,选用线性核函数,罚函数C取2,分类结果如图1所示:
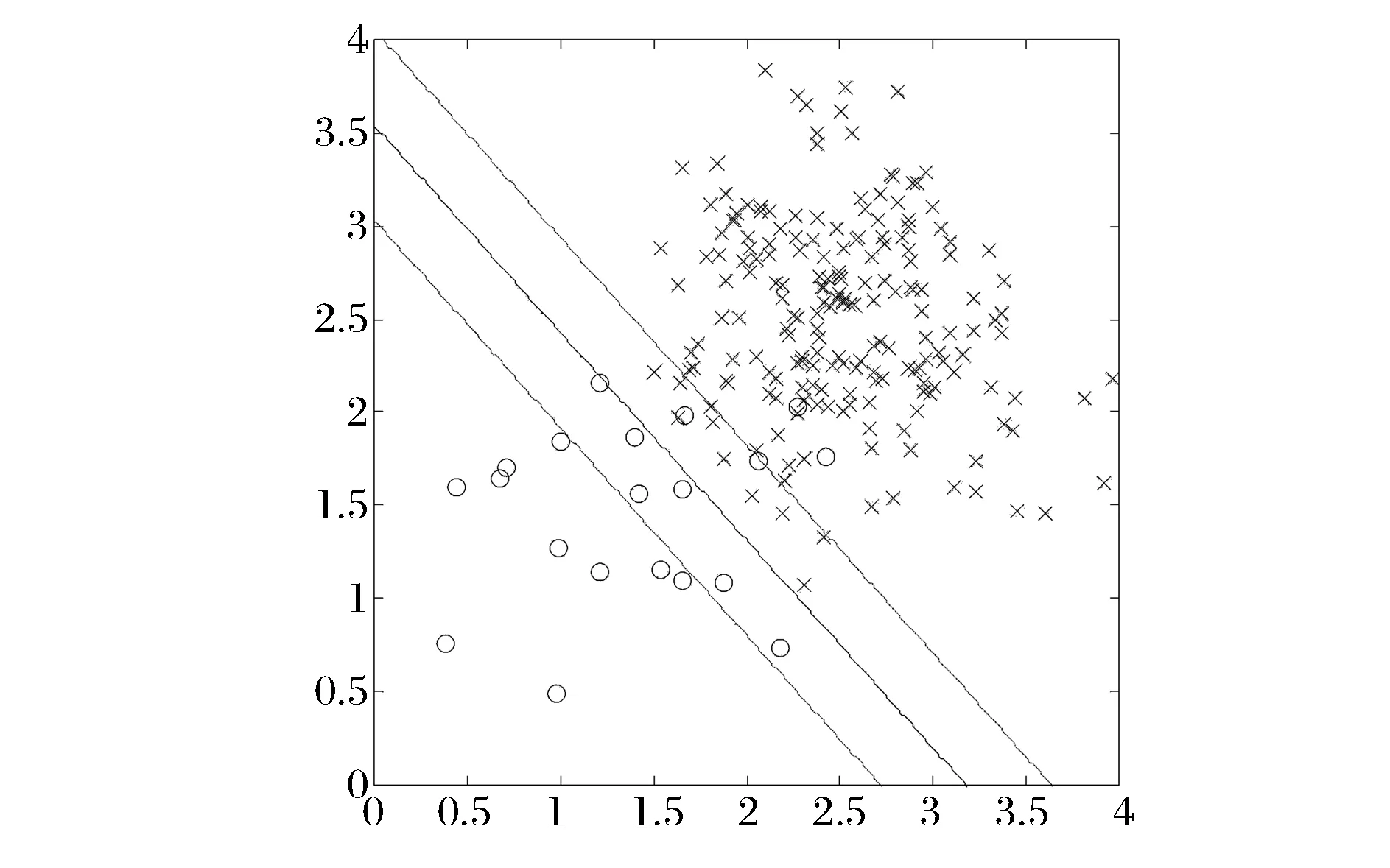
图1 传统SVM在非均衡数据中的分类效果
从图 1可明显看出,SVM的分类边界向少数类方向偏移,部分少数类样本被分类成多数类。这是由于传统SVM对两个类别的样本采用了相同的罚函数C,为了使SVM的目标函数最小化,分类平面需向密度较小的少数类样本移动以换取对多数类样本更少的错分惩罚。因此,为了提高少数类样本的识别精度,必须解决SVM算法在处理非均衡数据下的分类面偏移问题。
SMOTE算法由Chawla等人在2002年提出,通过人工合成少数类样本以达到与多数类样本的均衡。具体操作如下:首先找到少数类样本xi的k个邻近同类样本,在这k个样本中随机选取一个xj,通过下列公式合成新的样本:
xnew=xi+rand(0,1)×(xi-xj)
(4)
利用SMOTE算法生成新样本后,再对上述例子进行分类,结果如图2所示。相比图1,分类平面明显向多数类发生了偏移,但仍有部分原始少数类样本被错分为多数类。不难发现,SMOTE在原始数据包络里随机生成新样本,而影响SVM分类结果的只有分界面附近的样本,所以传统SMOTE算法生成的部分样本是没有实际意义的,因此需要对此加以改进。

图2 SMOTE-SVM在非均衡数据中的分类效果
2.2 基于改进SMOTE的非均衡数据SVM分类算法
针对上文涉及的问题,本节提出一种改进SMOTE的非均衡数据SVM分类算法。区别于传统SMOTE算法在所有少数类样本中随机生成新样本,本文算法关注影响分类面位置的错分样本,根据错分样本人工合成新样本,来提高这些关键样本在分类过程中的重要程度,具体算法设计如下:
1)设原始数据T={(x1,y1),(x2,y2),…,(xl,yl)}∈(n×)l中少数类为正类P,多数类为负类N,样本数量分别为nP和nN。
2)用原始SVM模型对T进行分类,并用原始数据T对模型进行验证,找出所有错分的少数类样本,生成集合P_mis。
3)判断P_mis是否为空集,若是,结束算法;若不是,令新集合S=T,进入下一步。
4)用SMOTE算法对P_mis中的所有样本人工合成一次,合成的新样本加入到集合S中。
5)用原始SVM模型对S进行分类,并用原始数据T对模型进行验证,找出所有错分的少数类样本,更新集合P_mis。
6)重复步骤4和步骤5,直到集合S中原始少数类样本数nP与合成样本数之和大于等于多数类样本数nN,算法终止。
利用本文算法对上文中的例子进行分类,结果如图3所示,分类平面继续向多数类移动,对少数类样本基本达到100%的识别精度,由此证明本文方法可以很好解决传统SVM和SMOTE算法的各自问题。
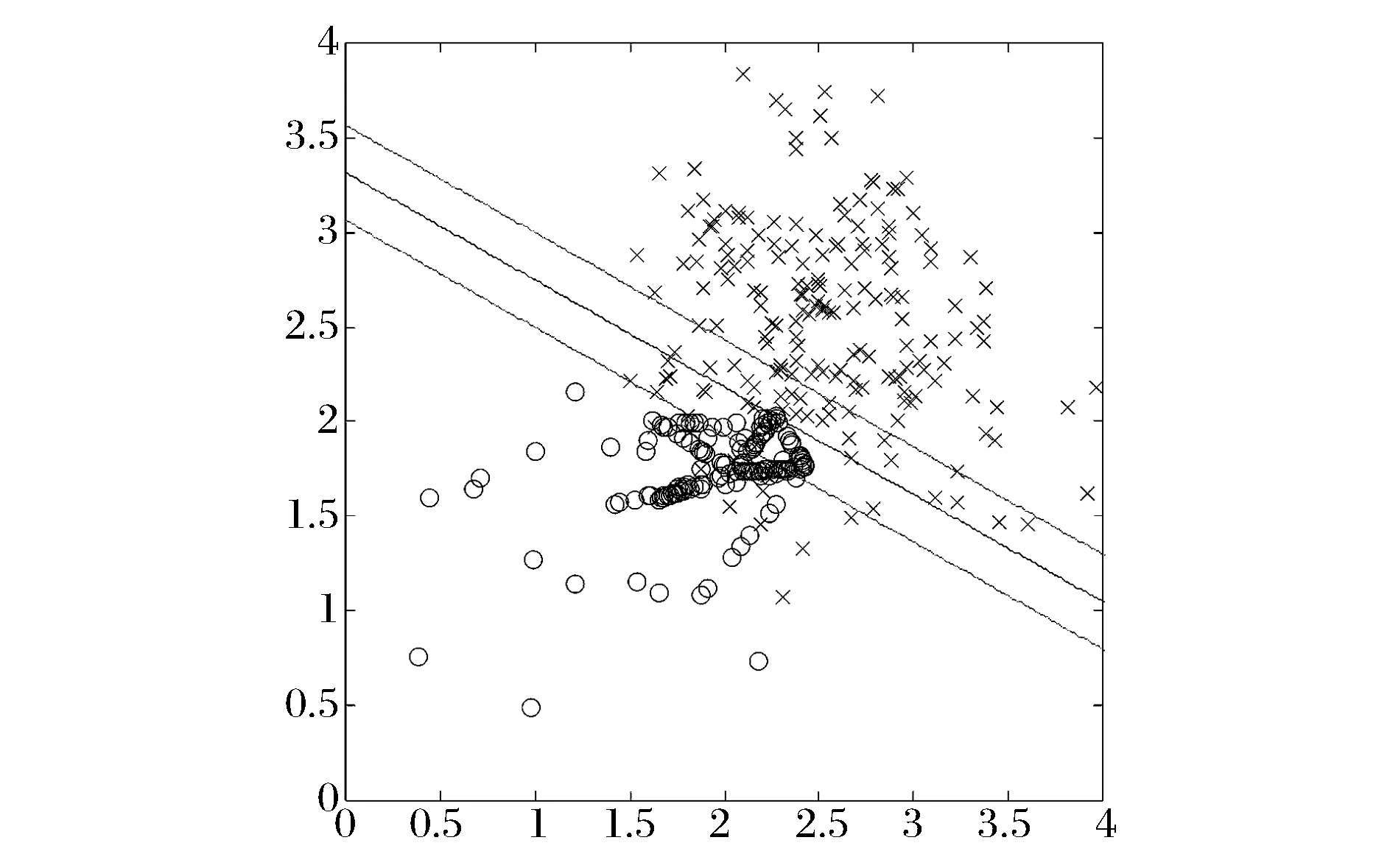
图3 本文方法在非均衡数据中的分类效果
3 案例分析
3.1 数据来源
为验证改进SMOTE的非均衡数据SVM分类算法在小额贷款公司客户信用风险评估中的效果,本文从某小额贷款公司采集393条借款记录作为实验原始数据,借款日期从2009年11月到2013年5月。这一区域中小企业和低收入人群占比较大,因此研究这一区域的小额贷款公司数据,能更加真实的反映出小额贷款行业面临的问题和风险。在数据集中,无违约记录369条,违约记录24条,不均衡比例为15.38,因此需要使用针对非均衡数据的分类方法进行风险评估。
3.2 信用风险评估指标构建
在信用风险评估中,指标的选取起到了关键作用。在小额贷款行业特征和公司实际运营基础上,要求审核人员充分挖掘借款人的经济、社会、信用等各方面信息,以确保规避风险的前提下为公司赢得最大收益。从国内外的文献研究来看,借款客户的信用风险评估指标体系主要集中在个人信息、信用信息、借款信息和担保信息四个维度,数据类型大多是数值型和类别型。
在四个维度中,个人信息包括年龄、性别、婚姻和文化程度四个指标,由于小额贷款公司的服务对象多为务农人员、个体工商户这类低文化水平客户,因此在对文化程度分类时按照小学、初中、高中、大专和本科及以上五个等级较为合适。信用信息则涵盖借款人在正规金融机构的历史信用记录、名下是否拥有住房、是否为本公司的历史借款客户、现有业务从业年限,这四个二级指标能反应出客户生活、工作、经济情况是否稳定,也是是否构成违约潜在风险的主要因素。另一方面,大额高息借款用于长时间的房地产开发,风险可能会大于小额低息借款用于短期家庭装修,因此从借款本身考虑,借款金额、用途、期限以及借款利息率作为风险评估的指标较为合适。最后,一旦客户出现违约,其抵押担保可冲抵部分违约损失,使小额贷款公司风险有效降低,其中是否有担保、是否有抵押品、抵押方式和抵押品是否足值四个较易获得数据被纳入信用风险评估的指标当中。由此,将小额贷款公司客户信用风险评估的指标在表1中列出。
3.3 精确度测量标准
对于均衡数据集,通常采用整体分类误差作为模型性能的评估指标,但对于非均衡数据集,整体误差难以反应分类器在少数类样本中的表现。举例说明,若训练集包括95%的多数类样本和5%的少数类样本,即使全部少数类样本被错分为多数类,整体的分类精度仍然在95%,而少数类的分类精度为0。为此,在非均衡数据实验中,许多学者提出使用G-mean和F-measure来评价分类器的性能。定义非均衡数据集中少数类为正类P,多数类为负类N;FN表示将正类错分成负类的样本数,FP表示将负类错分为正类的样本数,TN和TP分别表示负类和正类被正确分类的样本数。由此可以得到:
少数类样本查全率:
TPR=TP/(TP+FN)
(5)
多数类样本查全率:
TNR=TN/(TN+FP)
(6)
少数类样本查准率:
Precision=TP/(TP+FP)
(7)
综合G-mean:
(8)
少数类样本F-measure:
(9)

表1 小额贷款公司借款人信息
G-mean考虑了两类样本的分类性能,只有分类平面不发生偏移,两类样本都有较大的查全率时,G值才会较大。F-measure考虑了少数类的查全率和查准率,任何一个值的变化都能影响F的大小,因此能全面反映分类器对少数类样本的分类性能。

表2 SVM、SMOTE-SVM与本文方法的比较
3.4 结果及分析
本文采用LibSVM工具箱[22]在小额贷款公司客户信贷数据上进行实验,对比传统SVM和对全体少数类人工合成的SMOTE-SVM两种模型,验证本文方法的有效性。实验采用RBF核函数,罚函数C取10,gamma取1,由于SMOTE生成新数据的随机性,SMOTE-SVM和本文方法分别进行10次后取平均值,传统SVM不涉及生成样本,只需进行1次实验。由于个人信贷数据包含不同类别、不同范围的数据,因此首先需要对原始数据进行预处理,利用公式(10)将原始数据进行归一化,然后利用三种模型进行学习,最后用G-mean和F-measure衡量各方法的分类精确度,结果如表2所示。
(10)
其中k=1,2,…,n,i=1,2,…,l,xi(k)表示第i个借款人的第k个指标。
从三种方法的比较结果可以看出,由于未考虑非均衡样本的问题,传统SVM在三者中表现最差,G-mean和F-measure分别只有84.16%和82.93%。使用SMOTE算法生成新样本后,多数类和少数类样本达到一致,分类精度有了明显提升,G-mean和F-measure分别达到98.52%和83.57%。本文方法同时考虑了SVM和SMOTE-SVM方法的不足,对关键样本进行人工合成,实验精度有了进一步提升。其中,本文方法G-mean的最小值与SMOTE-SVM方法G-mean的最大值相同,而本文方法F-measure全部结果均大于SMOTE-SVM中的结果,充分说明本文方法在处理小额贷款公司客户信用风险评估案例中的有效性,数据非均衡情况得到了良好改善,即更多具有潜在违约风险的借款人被识别出来,小额贷款公司所面临的借款人违约风险大幅降低。
4 结语
本文以某小额贷款公司为例,分析了在对客户放贷前信用风险评估过程中涉及的诸多因素,制订了个人信息、信用信息、借款信息和担保信息四个维度下的评价指标体系。通过对传统SVM分类器的研究,指出其在处理非均衡数据时分类平面向少数类偏移的现象,同时说明在使用传统SMOTE算法对全体少数类样本进行人工合成时,没有考虑不同样本对分类平面具有不同的重要性。因此,提出一种改进SMOTE的SVM分类算法,考虑可以改变分类平面位置的错分样本,通过对这些样本使用SMOTE人工合成新样本,不仅使多数类和少数类样本数量得到均衡,而且让存在违约风险的少数类样本被反复学习,从而更好的识别不良借款人以降低小额贷款公司的借贷风险。本文方法在人造数据集和真实信用数据集的实验中均表现出较高的分类精度,优于传统SVM和SMOTE-SVM方法,说明本文方法具有较强的实用性。后续工作可在人工合成样本的同时,考虑噪声和野值点的影响,使非均衡数据的人工合成更为精确、合理。
[1] Armendariz B, Morduch J.The economics of microfinance[M]. 2nd, Cambridge, MA: MIT Press, 2010.
[2] 郑毓盛, 于点默. 小额贷款的理论、实践和危机[J]. 中国农村经济, 2013, (8): 88-95.
[3] Banerjee A, Chandrasekhar A G, Duflo E, et al. The diffusion of microfinance[J]. Science, 2013,341(6144).
[4] 庞素琳. 基于贷款风险损失比的农户信贷模型与应用[J]. 管理科学学报, 2012, 15(11): 11-22.
[5] Yang Jian, Zhou Yinggang. Credit risk spillovers among financial institutions around the global credit crisis: Firm-level evidence[J]. Management Science, 2013, 59(10): 2343-2359.
[6] Kruppa J, Schwarz A, Arminger G, et al. Consumer credit risk: Individual probability estimates using machine learning[J]. Expert Systems with Applications, 2013, 40(13):5125-5131.
[7] 张大斌, 周志刚, 许职, 等. 基于差分进化自动聚类的信用风险评价模型研究[J]. 中国管理科学, 2015, 23(4): 39-45.
[8] 陈庭强, 何建敏. 基于复杂网络的信用风险传染模型研究[J]. 中国管理科学, 2014, 22(11): 1-10.
[9] Moges H T, Dejaeger K, Lemahieu W, et al. A multidimensional analysis of data quality for credit risk management: New insights and challenges[J]. Information & Management, 2013, 50(1):43-58.
[10] Verbraken T, Bravo C, Weber R, et al. Development and application of consumer credit scoring models using profit-based classification measures[J]. European Journal of Operational Research, 2014, 238(2):505-513.
[11] Li Yongbin, Zhang Jianping. Approach to multiple attribute decision making with hesitant triangular fuzzy information and their application to customer credit risk assessment[J]. Journal of Intelligent & Fuzzy Systems, 2014, 26(6): 2853-2860.
[12] Zhang Zhiwang, Gao Guangxia, Shi Yong. Credit risk evaluation using multi-criteria optimization classifier with kernel, fuzzification and penalty factors[J]. European Journal of Operational Research, 2014, 237(1):335-348.
[13] Marqués A I, García V, Sánchez J S. A literature review on the application of evolutionary computing to credit scoring[J]. Journal of the Operational Research Society, 2013, 64(9):1384-1399.
[14] Harris T. Credit scoring using the clustered support vector machine[J]. Expert Systems with Applications, 2015, 42(2):741-750.
[15] Sun Zhongbin, Song Qinbao, Zhu Xiaoyan, et al. A novel ensemble method for classifying imbalanced data[J]. Pattern Recognition, 2015, 48(5): 1623-1637.
[16] Li Qiujie, Mao Yaobin.A review of boosting methods for imbalanced data classification[J]. Pattern Analysis and Applications, 2014, 17(4): 679-693.
[17] Chawla N V, Bowyer K W, Kegelmeyer W P. SMOTE: Synthetic Minority Over-sampling Technique[J]. Journal of Artificial Intelligence Research, 2002,16: 321-357.
[18] 陶新民, 郝思媛, 张冬雪,等. 基于样本特性欠取样的不均衡支持向量机[J]. 控制与决策, 2013, 28(7): 978-984.
[19] 文传军, 詹永照. 基于自调节分类面SVM的平衡不平衡数据分类[J]. 系统工程, 2009, 27(3): 110-114.
[20] 章少平, 梁雪春. 优化的支持向量机集成分类器在非平衡数据集分类中的应用[J]. 计算机应用, 2015, 35(5): 1306-1309.
[21] 邓乃杨, 田英杰. 支持向量机——理论、方法与拓展[M]. 北京: 科学出版社, 2009.
[22] Chang C C, Lin C J. LIBSVM: A library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011,2(3):1-27.
Imbalanced Data Classification on Micro-Credit Company Customer Credit Risk Assessment Using Improved SMOTE Support Vector Machine
YI Bai-heng, ZHU Jian-jun, LI Jie
(School of Economics and Management, Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China)
A great number of machine learning methods have been successfully applied for customer credit risk assessment cases, and support vector machine (SVM) is considered as an “off-the-shelf” supervised learning algorithm to solve classification problem by many researchers. Unfortunately, SVM fails to provide excellent enough classification performance when the data set is imbalanced, i.e., the accuracy of the majority class is usually much higher than that of the minority class due to the shifting of the hyper-plane. In most cases, people pay more attention on the minority class such as fault diagnosis and credit default. Thus, a Synthetic Minority Over-sampling Technique (SMOTE) is presented to deal with the imbalanced classification by generating new samples in the whole minority class. However, in the process of solving SVM by Sequential Minimal Optimization (SMO) algorithm, only those support vector samples xiwith the corresponding αi>0 can affect the position of the hyper-plane while the samples far from the hyper-plane have no influence on the final result. It is obvious that the classic SMOTE algorithm can generate more redundant samples which are far from the hyper-plane. In this article, an improved method for classic SMOTE algorithm is proposed that SMOTE is looped and only misclassified samples in the previous loop are selected to be processed in the next loop until the minority class outnumbers the majority class or all minority class samples are correctly classified. In the empirical study, a data set granted by a micro-credit company in Jiangsu Province is studied. The data set originates from a company that provides loans to local individuals and enterprises for the house condition improving, farm production expanding, business operating and so on. The customers’ information are analyzed according to the characteristics of micro-loan industry, and a credit risk assessment index system is suggested from four aspects with sixteen attributes in this paper. G-mean and F-measure score are used to evaluate the classification performance of the minority class, which is the accuracy of detecting default customers in this case. The results show high prediction accuracy of default customers, indicating the effectiveness of our method on credit risk assessment.
micro-credit; credit risk; support vector machine; imbalanced data; SMOTE
1003-207(2016)03-0024-07
10.16381/j.cnki.issn1003-207x.2016.03.004
2015-05-30;
2015-10-09
国家社会科学基金重点项目(14AZD049);国家自然科学基金资助项目(71171112,71401064);中央高校基本科研业务费专项资金资助(NS2014086);广义虚拟经济研究专项(GX2013-1017 (M))
简介:衣柏衡(1990-),男(汉族),天津人,南京航空航天大学经济与管理学院硕士研究生,研究方向:数据挖掘、系统分析与决策,E-mail: ysb900818@126.com.
F830.5;TP391
A
