基于Hadoop MapReduce的大规模雷电电磁传播数值仿真
2016-12-26林海铭
林 海 铭
(广东省建筑科学研究院集团股份有限公司 广东 广州 510500)
基于Hadoop MapReduce的大规模雷电电磁传播数值仿真
林 海 铭
(广东省建筑科学研究院集团股份有限公司 广东 广州 510500)
面对大规模雷电电磁问题,单机计算不能达到完全解决问题的程度,可以考虑利用新兴云计算技术来解决。提出基于Hadoop MapReduce框架的域分解时域有限差分并行算法,在6节点的Hadoop实验室集群上,对上海浦东某地区发生的大规模雷电电磁传播过程进行数值仿真,并测试不同计算子域所获得的加速比。计算结果显示,所提出的并行算法能有效地求解大规模雷电电磁传播问题,且计算模型越大、计算节点越多,加速比也大,在设定的计算环境下,最大加速比为2.4,受硬盘空间限制,最大计算规模为1 368万节点。
云计算 Hadoop MapReduce 雷电 有限差分法 并行计算
0 引 言
自2007年IBM正式提出云计算[1]的概念以来,许多学者、研究机构和IT公司都从不同角度定义了云计算。云计算是以虚拟化技术为基础,以网络为载体,以用户为主体,以IaaS、PaaS、SaaS服务为形式,整合大规模、可扩展的分布式资源进行协同工作的超级计算范式。云计算的基础设施架构在普通机器上,能够无缝地扩展到包含数千个节点的大规模集群上,扩展性好,最大限度地利用廉价计算资源。云计算通过普通机器的冗余获得高可用性,能够容忍节点失效。同时,用户通过即付即用方式使用云中心资源,可以避免在基础设备上的投资,也脱离技术与部署的复杂性。
云计算的兴起,为科学计算提供了新的工具,基于云计算的科学计算称为研究热点。Jakovits等[2]在Hadoop MapReduce框架上实现基于Monte Carlo的线性方程组求解,并跟Hadoop CG和Twister CG进行比较,结果显示Hadoop Monte Carlo的效率高于Hadoop CG,但低于Twister CG,同时随着Markov链的增加,Monte Carlo不容易收敛。Xuan等[3]在Hadoop框架顶层加了包含Dataflow DAG、Controllers、Resource Manager等数据流层,形成适合科学工作流的数据流驱动云模型SciFlow,整合了分子动力学MD程序GROMACS和前向流采样FFS算法,设计其基于数据流驱动的MapReduce实现。Yang等[4]提出基于MapReduce的图形算法Mapper-side Schimmy来实现神经网络仿真,用包含10万个神经元23亿个边的算例进行验证,此算法能提高性能64%,但MapReduce框架不适合迭代算法,在Hadoop顶层增加了适用于大规模图形处理的框架Giraph,性能提升了60%。Dalman等[5]在Amazon云平台上无缝集成了Hadoop MapReduce框架和生物医学工程的C-MFA框架,在Hadoop streaming接口上获得加速比17(64核),通过自定义数据类型和参数调优,加速比提高到48。Gu等[6]提出科学工作流SWF建模方法和XML数据管理模型XML-DMM,其中SWF建模负责数据的处理,XML-DMM确保了云环境中数据的一致性和分布式资源的利用率,并设计了Rollback、Break-Point和Release Resource三种动态执行机制来提高SWF的执行效率,在Hadoop平台上实现,并用计算大海表面温度SST的例子进行验证。Vijayakumar等[7]使用FASTA算法提出了生物信息学中的基因序列比对优化方法,并在Hadoop和Greenplum MPP 数据库组合的平台上实现,实验结果表明这种组合平台上的计算时间比Hadoop+PostgreSQL平均减少了48%。
空间雷电电磁传播问题具有计算/数据密集型的特性,随着计算规模和精度的不断提高,单机即使是高性能计算机已经不能完全求解问题,本文在云计算环境下实现有限差分法求解大规模电磁传播问题,具有重要的探索意义和实用价值。
1 Hadoop平台
Hadoop是一个应用最为广泛的开源MapReduce实现,通过廉价PC组建成具有强大数据处理能力的计算平台,每个PC提供本地计算和存储,通过高度抽象的编程模型实现分布式计算。Hadoop通过数据复制和局部重新计算实现错误容忍和失效恢复,而不是通过硬件的高可靠性,既能解决传统高性能计算中容错性不足的问题,也降低了基础设备的购置、维护费用。Hadoop平台包含HDFS、MapReduce、YARN、HBase、Hive、Pig等模块,用于计算的Hadoop平台主要包括分布式文件系统HDFS和并行计算框架MapReduce两部分。
1.1 HDFS
Hadoop的分布式文件系统HDFS采用Master/Slaver架构,典型的HDFS由一个NameNode和一定数目的DataNode组成。其中,NameNode是中心服务器,负责管理文件系统的Namespace并接受客户端对文件的访问;DataNode是数据存储节点,在Namenode的指挥下进行数据块的创建、删除和复制[8]。HDFS通过硬件的冗余和数据块的备份实现高容错性,通过流式访问实现高数据吞吐量,提供高传输带宽实现海量数据管理,要求每个时刻只能一个用户写入数据,实现数据的一致性。
1.2 MapReduce
MapReduce[8]是当前最为流行的分布式编程模型,用户只要根据自身需求实现Mapper和Reducer接口,就能自动并行化自己的应用程序。Mapper接口通过map()函数对输入进行映射操作。在各个工作节点上,map()函数获得一串由主节点分配的键值对(key/value)作为输入。对于一个key/value,在map()中进行相应的操作,可以产生一串key/value作为输出,这个过程的可以表示为map :: (key1; value1) to list(key2; value2)。Reducer接口通过reduce()函数对输入进行规约。reducer()函数获得一串key相同的键值对作为输入,规约成新的值作为输出,形式为reduce::(key2;list(value2)) to list(value3)。
2 FDTD并行化
2.1 Yee’s FDTD
在各向同性、时间无关的电磁空间中,电磁传播过程可用以下矢量方程表示:
(1)
(2)
其中,E为电场强度矢量,H为磁场强度矢量,ε为介电常数,μ为磁导率,σ为电导率。
通过Yee晶格把计算空间沿3个轴向划分成长方体小网格,将计算空间中的连续变量离散化,节点(i,j,k)处的电磁场分量如图1所示。

图1 Yee晶格
通过中心差分法并假设网格为方体(Δx=Δy=Δz=δ),式(1)和式(2)可离散为:
(3)
(4)
(5)
(6)
(7)
(8)
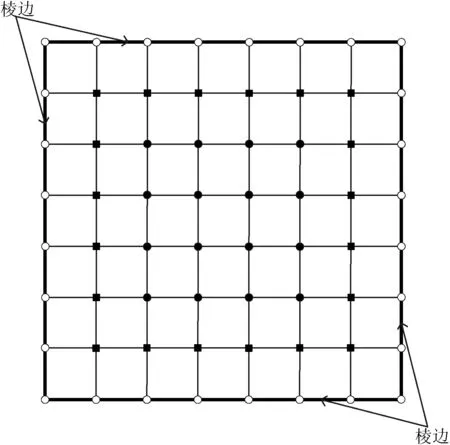
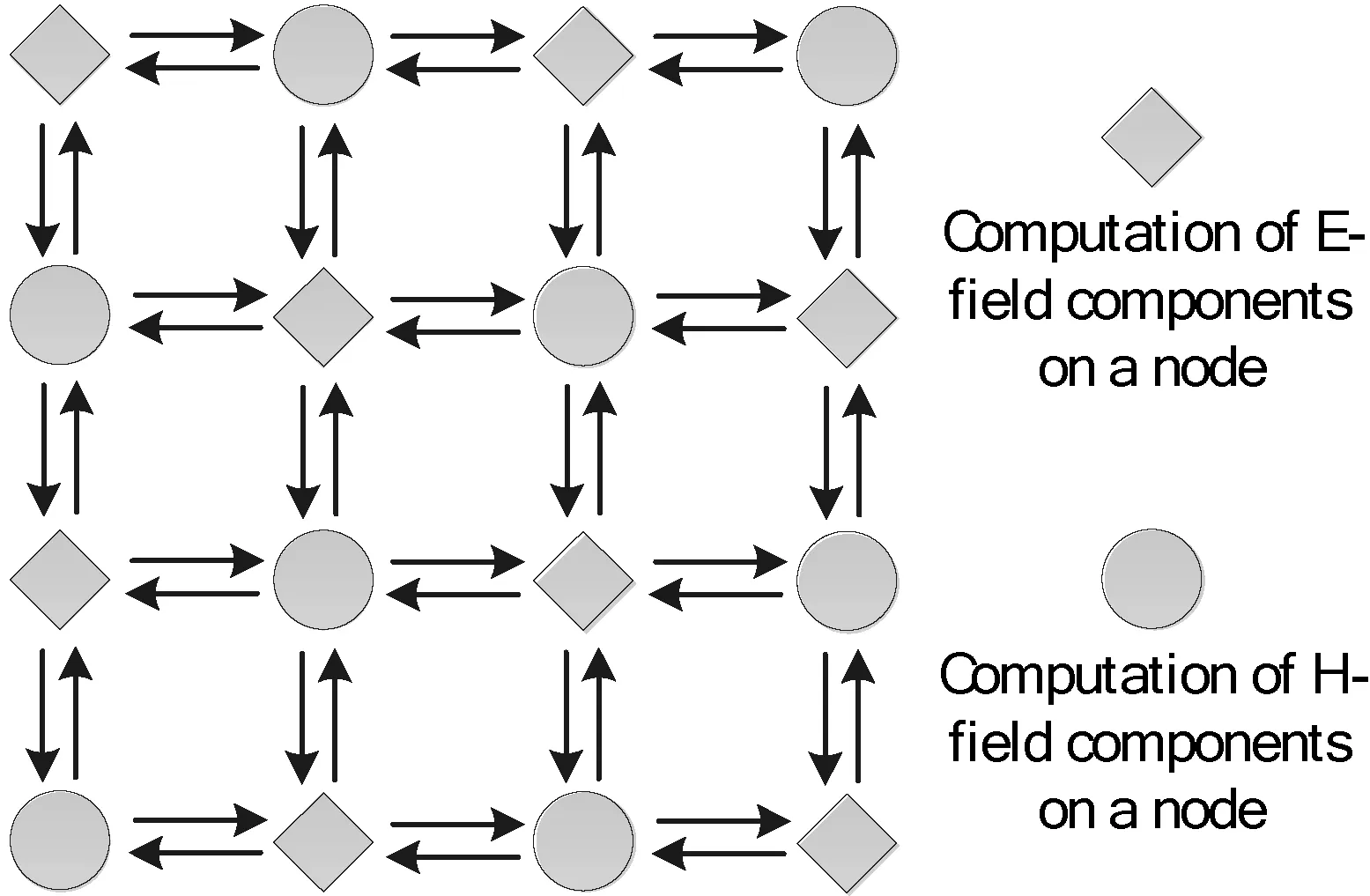
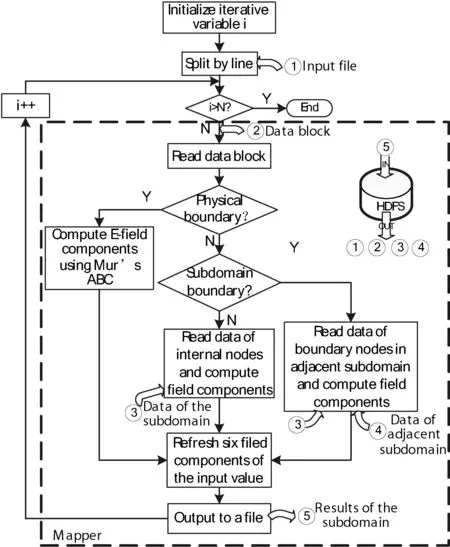
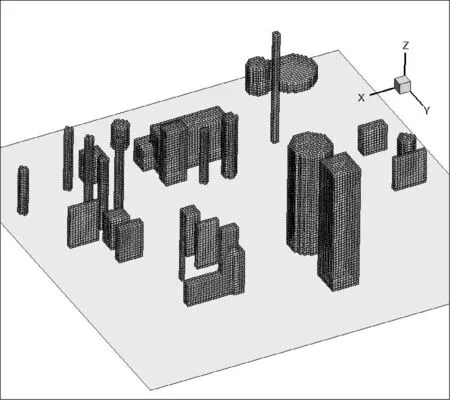
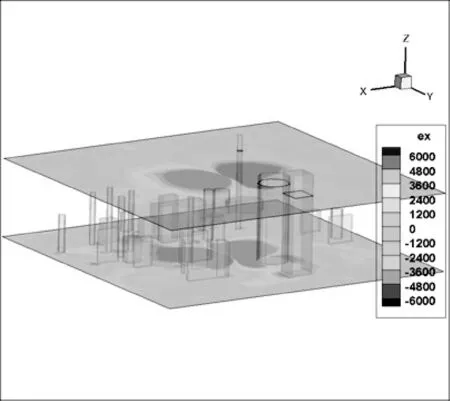
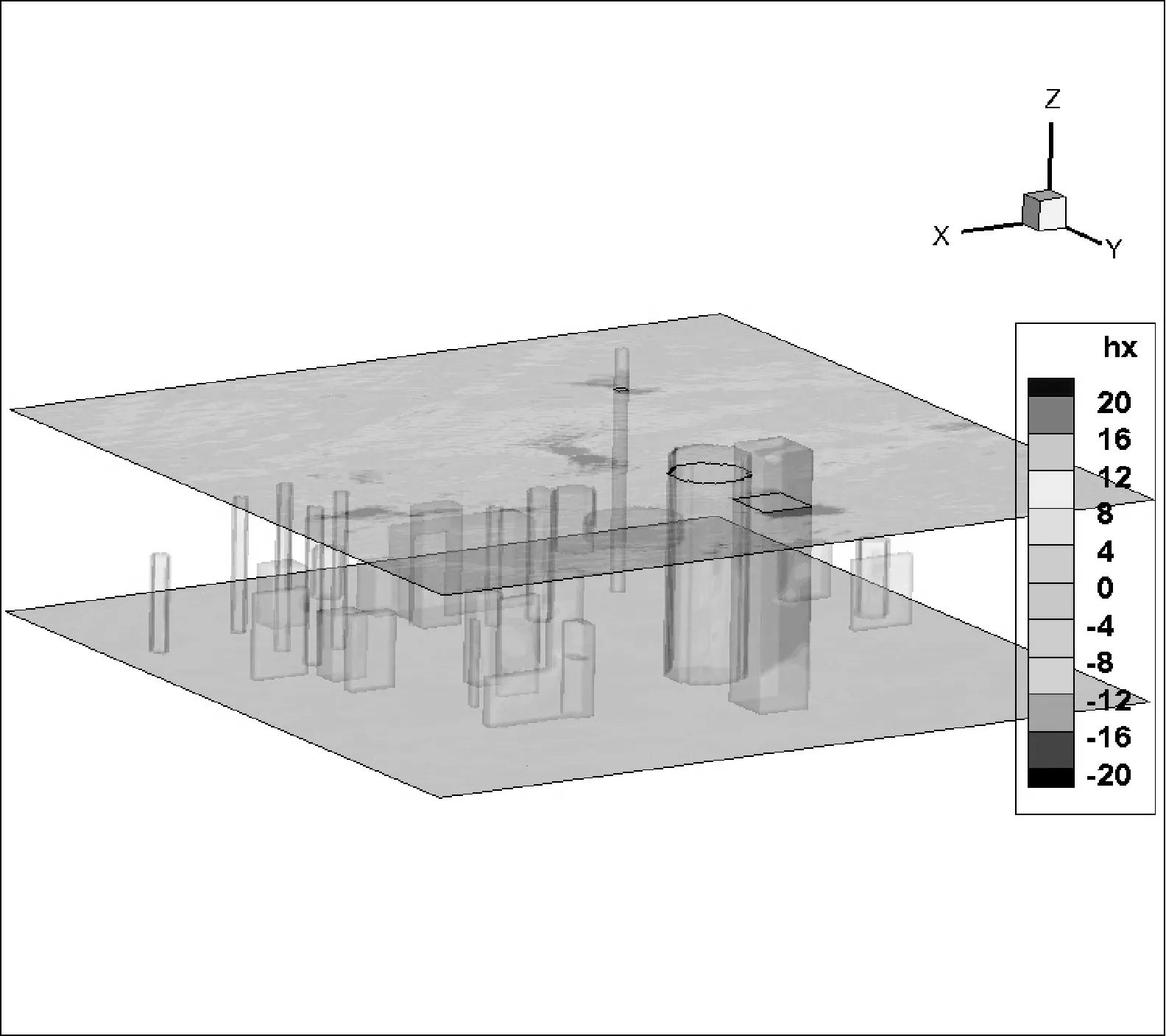
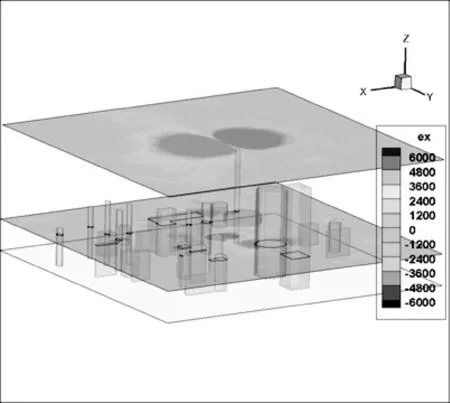
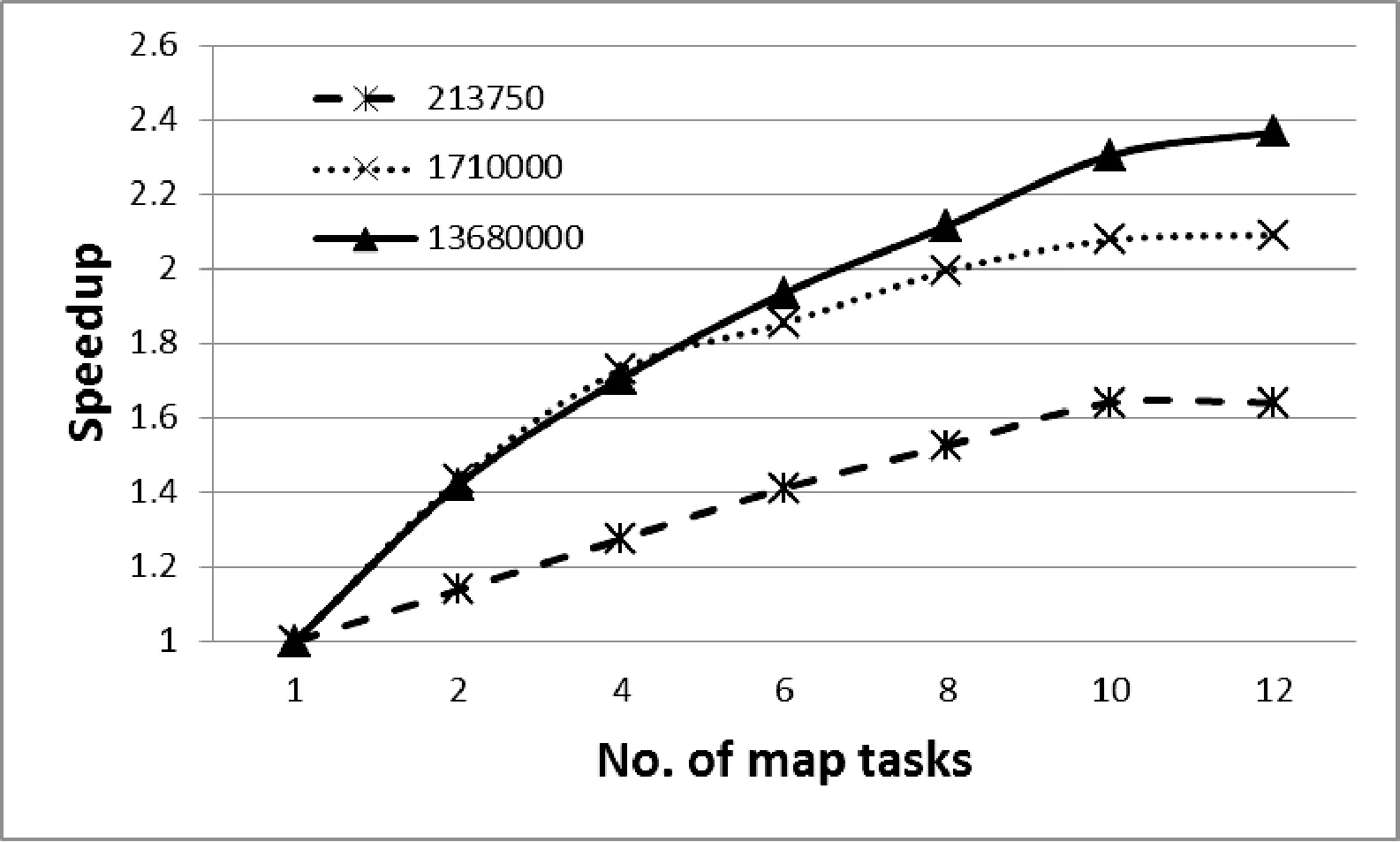
2.2 Mur边界条件
在一长方体(0 (9) (10) 图2中,P0为边界节点,Q0为P0相对的节点,P1、P2、P3、P4是P0相邻的节点,Q1、Q2、Q3、Q4为Q0相邻的节点,假设网格单元长度为δ,式(9)和式(10)可离散为: (11) fn(P3)+fn(P4)+fn(Q1)+fn(Q2)+fn(Q3)+fn(Q4)] (12) 图2 节点示意图 为保证FDTD的计算稳定性,对截断边界上网格节点(图3所示)做如下处理,可以避免对棱边及角顶点处网格节点(图中空心圆节点)的计算:与长方体棱边相邻的节点(图中方形节点)采用式(11)近似计算;内部节点(图中实心圆节点)则采用式(12)近似计算。 图3 边界节点处理示意图 2.3 DD-FDTD 根据迭代方程式(3)至式(8),得到FDTD算法的数据相关性图(图4)。每一网格点上的电磁计算都与相邻网格点存在数据相关联,但当把一个完整的计算域划分为若干个子区域时,子域边界处网格节点上的电磁计算用到临域边界处网格节点上的切向场量,存在数据依赖性,而子域内部网格节点上的电磁计算所需的数据都在本域内,与其他子域不存在数据依赖性,可以独立完成计算。 图4 数据相关性 DD-FDTD的基本原理如图5所示。在计算第N个时间步时,首先计算电场分量,根据式(8),计算子区域1内部网格节点的电场分量Ez所需的磁场分量Hx、Hy全在该区域中,能独立完成。但计算子域边界处网格节点的电场分量Ez所需的磁场分量Hy位于临域2边界处的网格节点上,开始计算Ez之前必须将上一时间步的磁场分量Hy从临域2传递到1中。计算磁场分量情况类似。 图5 DD-FDTD的基本原理 计算前,对计算网格进行分区,对计算节点进行编号,标记分块边界节点(不同于物理边界,物理边界通过节点编号判断),初始化电/磁场6个计算分量。网格节点信息存储到输入文件中,主要包括块编号、边界标记、节点编号、电磁场分量初始值等。 根据上述的FDTD算法基本理论及其域分解并行化技术,设计一个类DD_FDTDSolver实现基于MapReduce的DD-FDTD并行化。在DD-FDTD中,各个分块内部的计算都是独立的,只有边界节点上的计算需要用到相邻分块中的数据。因此,MapReduce过程只需要Mapper过程,每个Mapper负责一个分块的计算,不需要Combiner和Reducer对Mapper的结果进行归约。 在Mapper中,输入文件为上述的格式化文件,在Job的配置中用Hadoop的NLineInputFormat类设置输入格式,master将N行数据分配给一个Mapper,N的大小由属性mapreduce.input.lineinputformat.linespermap控制。在此N设置为每个分块里的数据量,从而实现每个Mapper独立计算一个分块,Mapper数为FDTD域分解的分块数。Mapper将所分配到的数据块以键值对的形式传给map()函数,作为其输入,其中“键”为该行数据在整个输入数据文件中的偏移量,“值”为一整行数据,即为一个网格节点信息数据。在每个迭代步中,每个节点上的电/磁场分量的计算所需的数据都是前边迭代步的计算结果。因此可以在setup()函数中,根据块编号从HDFS上的文件读取相应的相邻分块边界节点的结果数据和本块内部节点的结果数据,分别存储在数组A和数组B中。在map()函数中根据节点编号,判断是节点类别,若为物理边界节点,则利用式(11)和式(12)进行计算;若为分块边界节点,则从数组A获取临域边界节点数据根据迭代式(3)至式(8)进行计算。否则,从数组B中获取本块节点数据按照迭代式(3)至式(8)进行计算。最后更新“值”中的6个分量值,输出到HDFS上相应的文件中作为下一迭代步的输入数据。 Hadoop Job的基本配置参数可以采用系统默认的,而关键配置参数往往是通过启动命令进行传递给Job启动函数,在此需要通过启动命令配置的关键参数包括:输入数据文件路径、输出结果路径、行数Nline和分块数Nsplit。基于MapReduce框架DD-FDTD并行实现的算法流程如图6所示。 图6 基于MapReduce的DD-FDTD流程图 4.1 雷电电磁传播 以上海浦东某地区发生的雷电电磁传播过程为例,验证上述所提的算法。忽略小型建筑物,只对大型建筑物及长方体空间(1500 m×1500 m×750 m)内的空气介质进行建模,网格模型如图7所示(只显示建筑物的网格)。 图7 网格模型 将雷电流近似为线电流源进行加载,要在电磁场中添加线电流源,只需将下边子项加到式(8)的右边。 其中,I为线电流随时间变化的表达式,is,js为雷电流所在节点在x、y方向上的坐标。 本文采用IEEE推荐的8/20 μs双指函数波形雷电流模型,形式为: In(is,js,k)=I0(e-α(Δt·n-kδ/v)-e-β(Δt·n-kδ/v)) 其中,I0=23.3 kA,α=7.714×104,β=2.489×105,v=1.3×108m/s。雷电电磁场的频率范围就要集中在102~106Hz,计算时将频率设置为1 MHz,波长300 m,取Yee晶格大小δ=10 m,足以满足稳定性条件。计算域为1500 m×1500 m×750 m的长方体,由空气和建筑物构成,其中,空气的电磁参数为εr1=1、μr1=1、σ=0;假设建筑物各项同性,其电磁参数为εr2=6.0、μr2=1.13、σ=0.05 S/m。雷电流位于z=0平面的中心,在10 μs时达到峰值,此时x方向的电/磁场的云图如图8、图9(两截面分别在z=0 m和z=375 m处)和图10、图11(两截面分别在z=150 m和z=600 m处)所示。从截面图可以看出建筑物贯穿电磁场,引起电磁场传播不均匀,对电磁场起一定的屏蔽作用。 图8 Ex云图 图9 Hx云图 图10 Ex云图 图11 Hx云图 4.2 加速比 用三种不同尺寸的网格离散化计算域,得到三种不同规模的网格模型,分别由21 375、1 710 000、13 680 000个节点构成(受硬盘空间限制,不继续加密)。采用MATLAB将网格模型分为数目不等的计算子域并生成输入文件。在Hadoop实验集群(配置的最大map数为12)上测试其加速比,测试结果如图12所示。对于每一个网格模型,加速比随map数的增加而增加,但曲线的斜率随map数的增加逐渐减小,即加速比增长逐渐减缓。对于不同网格模型,网格模型的规模越大,获得更好的加速效率。对于同一个网格模型,map数的增加意味着Hadoop集群中更多的worker分配到计算任务参与计算,从而使得整体计算的并行度增大,获得更好的加速效果。但节点增加会引起数据读写和节点之间通信等方面的性能开销增加,而导致加速比的增长率变小。对于小模型,数据读写和节点之间通信等方面的开销所占的比重大于计算的开销,计算节点的增加提高了计算并行度,加速比增加,但节点处于未饱和状态并且未饱和状态越来越严重,增长速度下降比较快。对于大模型,数据读写和节点通信方面的开销比小模型的大,但其属于计算密集型,即计算方面的开销占绝大部分,计算模型规模的增大使得计算的开销在整体开销中所占的比重也增大,计算节点的增加加大了计算并行度,加速比增加,计算节点的状态随节点数的增加从超饱和状态向饱和状态、未饱和状态转变,加速比的增长速度逐渐变小。 图12 不同map任务下的加速比 本文设计了合适的数据结构,提出了基于MapReduce框架的DD-FDTD并行算法,并给出了详细的设计步骤和程序执行流程,最后通过上海某地区发生的雷电传播过程为数值实例,验证算法的并行性能。结果表明加速比随着计算节点的增加而增加,但当计算节点到达一定数量时,集群处于未饱和状态,加速比的增长速度下降;当集群规模与求解问题的计算量匹配时,集群处于饱和状态,系统的计算性能最佳;在本文所配置的6节点集群环境下,最大计算规模为1368万节点,最大的加速比为2.4。 [1] Armbrust Michael,Fox Armando,Griffith Rean,et al.A view of Cloud Computing[J].Commun.ACM,2010,53(4):50-58. [2] Pelle Jakovits,Ilja Kromonov,Satish Narayana Srirama.Monte Carlo Linear System Solver using MapReduce[C]//Proceedings of 2011 Fourth IEEE International Conference on Utility and Cloud Computing, Victoria, December 5-8, 2011.New York: IEEE,2011. [3] Xuan Pengfei,Zheng Yueli,Sarupria Sapna,et al.SciFlow:A Dataflow-driven Model Architecture for Scientific Computing Using Hadoop[C]//Proceedings of 2013 IEEE International Conference on Big Data, Silicon Valley, October 6-9, 2013.New York:IEEE,2013. [4] Yang Shuo,Spielman N D,Jackson J C,et al.Large-scale Neural Modeling in MapReduce and Giraph[C]//Proceedings of 2014 IEEE International Conference on Electro/Information Technology, Milwaukee,June 5-7, 2014.New York: IEEE,2014. [5] Tolga Dalmana,Tim Dörnemannb,Ernst Juhnke,et al.Cloud MapReduce for Monte Carlo Bootstrap Applied to Metabolic Flux Analysis[J].Future Generation Computer Systems,2013,29(2):582-590. [6] Gu R,Wu S,Dong H,et al.A Modeling Method of Scientific Workflow Based on Cloud Environment[C]//Proceedings of 2012 IEEE/ACIS 11th International Conference on Computer and Information Science,Shanghai, May 30-June 1, 2012.New York: IEEE,2012. [7] Vijayakumar S,Bhargavi A,Praseeda U,et al.Optimizing Sequence Alignment in Cloud Using Hadoop and MPP Database[C]//Proceedings of 2012 IEEE 5th International Conference on Cloud Computing, Honolulu, June 24-29,2012.New York:IEEE,2012. [8] Lam Chuck.Hadoop in action[M].New York,America: Manning Publications Co.,2010. NUMERICAL SIMULATION OF LARGE-SCALE LIGHTNING ELECTROMAGNETIC PROPAGATION BASED ON HADOOP MAPREDUCE Lin Haiming (GuangdongProvincialAcademyofBuildingResearchGroupCo.,Ltd.,Guangzhou510500,Guangdong,China) Single computer cannot reach the extent of completely solving the problem of large-scale lightning electromagnetic propagation simulation, but it may consider to use emerging cloud computation technology as the solution. This paper proposes a Hadoop MapReduce frame-based parallel algorithm of domain decomposition finite difference time domain (DD-FDTD). On a 6-nodes Hadoop laboratory cluster we carried out numerical simulation on the large-scale lightning electromagnetic propagation process occurred in an area in Pudong District, Shanghai, and tested the speedup ratios obtained in different computational sub-domains. It is shown by computational results that the proposed parallel algorithm can calculate the electromagnetic propagation of large-scale lightning effectively, and the speedup ratio increases along with the augment in computation model and the number of computational nodes, and the maximum speedup ratio is about 2.4 under the computation environment introduced in the paper. With the limitation of the capability of hard disk, the maximum computation scale is 13.68 million nodes. Cloud computing Hadoop MapReduce Lightning FDTD Parallel computing 2015-09-07。林海铭,助理工程师,主研领域:计算机仿真,大规模计算。 TP3 A 10.3969/j.issn.1000-386x.2016.11.016

3 基于MapReduce的DD-FDTD
4 算例验证

5 结 语
