一种面向CASA的分布式数据存储策略
2016-12-26过汇卿乐嘉锦
过汇卿 王 梅 乐嘉锦
(东华大学计算机科学与技术学院 上海 201620)
一种面向CASA的分布式数据存储策略
过汇卿 王 梅 乐嘉锦
(东华大学计算机科学与技术学院 上海 201620)
随着天文设备的进步发展,对海量天文数据处理形成了新的挑战。为使当前主流的天文数据分析软件可以有效处理海量数据,提出一种适用于射电天文处理上层应用的分布式数据存储策略DDSS(Distributed Data Storage Strategy)。首先,设计分布式数据存储策略的系统框架。其次,设计混合分片列式存储方法,在保留列存储查询优势的同时提升了数据导入的速度。进一步,通过维护基于相对位置映射的元数据来快速读取包含大量数据的天文阵列数据,显著地提升了天文处理应用底层数据读写的吞吐量。最后,通过实验证明了该方法的有效性。
分布式 天文 阵列数据
0 引 言
伴随着信息爆炸,大数据时代已经走入各行各业,在诸如天文学、物理学、社会科学等行业中正源源不断的产生真正的海量大数据。然而,这些行业在解决大数据所带来数据读写与处理缓慢问题的方法却滞后于其数据产生的速度。在射电天文领域,随着射电望远镜设备的飞跃发展,望远镜所能观测和产生的数据量早已超出了当前主流的天文学数据处理软件的承载能力。为此,急需将计算机数据处理的前沿技术如列存储、分布式等应用到当前成熟的处理软件中,以应对海量天文数据所带来的挑战和冲击。
射电天文领域中,天文学家主要采用的数据处理软件有AIPS,AIPS++以及CASA等。其中,CASA[1]是当前主流的射电天文数据处理和分析软件。它由AIPS++发展而来,提供基于二维表的数据模型来处理和分析射电天文数据。CASA通过调用casacore[2]库中封装的原AIPS++处理程序,实现各种数据分析和处理。然而,由于casacore底层实现的限制,只可以单节点串行地处理数据,这使得CASA需要极高的单点硬件性能。并且由于其不具备扩展性,难以应对大数据流量下高效的数据读写需求。
另一方面,正如大部分科学数据,射电天文数据包含大量的阵列数据,近年来,针对以阵列(Array)为主要数据形式的科学数据库也得到了广泛的研究。如基于传统关系模型的阵列数据库SciDB[3,4]以及基于Hadoop的数据库SciHadoop[5,6]等。SciDB是一个针对科学数据的分布式数据库,其数据模型是基于多维的阵列,这样就打破了传统数据库固定表结构的限制,使其具备了对阵列进行的操作运算的功能。SciHadoop将科学家输入的基于阵列数据模型的逻辑查询语句转化为map/reduce程序进行执行。上述研究均对阵列数据的分布式存储和查询进行了研究,然而其并非针对射电天文数据处理,因此其查询难以满足天文领域对阵列数据的众多运算。若使用其提供的上层接口与天文软件对接,由于接口调用使得数据吞吐率低,影响了性能。
针对上述问题,本文提出了面向海量天文数据处理,适用于射电天文学数据分析软件CASA的分布式数据存储策略DDSS。DDSS通过重写CASA底层的文件存储管理模块,在不修改任何上层应用接口的情况下解决了其只支持集中式、串行的数据读写机制,实现了并行化读写数据和分布式存储数据。DDSS首先根据阵列数据类型与普通数据类型混合的特点,采用了行列混合分片的方法,分片时保证每个数据片段大小均匀,在不影响写入效率的同时保留了其读取某一属性的高效性。进一步,在写数据的同时,维护基于数据相对位置映射的元数据文件,以提高阵列数据读取时的效率。实验测评表明,所提策略在写数据与读数据的吞吐量都有了显著的提高,其数据写入性能提升了6.8倍,数据读取性能提升了3.4倍。同时也验证了阵列数据的大小并不会影响系统的性能,系统具有较好的可扩展性。
1 CASA简介
CASA是一个融合了射电天文数据图形化、数据分析、数据处理等功能的综合软件包,其内部的数据格式以CASA TABLE的二维表形式存在[7]。其按属性可以分为三种,分别是ArrayColumn(AC)、IndexColumn(IC)和ScalarColumn(SC)。ArrayColumn存放各种数据类型的阵列数据,IndexColumn和ScalarColumn存放普通类型的数据,类似传统数据库中的属性。在CASA TABLE中,大量的表数据往往集中在ArrayColumn中。如表1所示,表1为一张5列10 000行的CASA TABLE。其中前4列分别为int、int、float和double类型的普通数据,第五列为4×5的int型阵列数据。虽然ArrayColumn只有一列,但可计算出其占全表大小的80%。
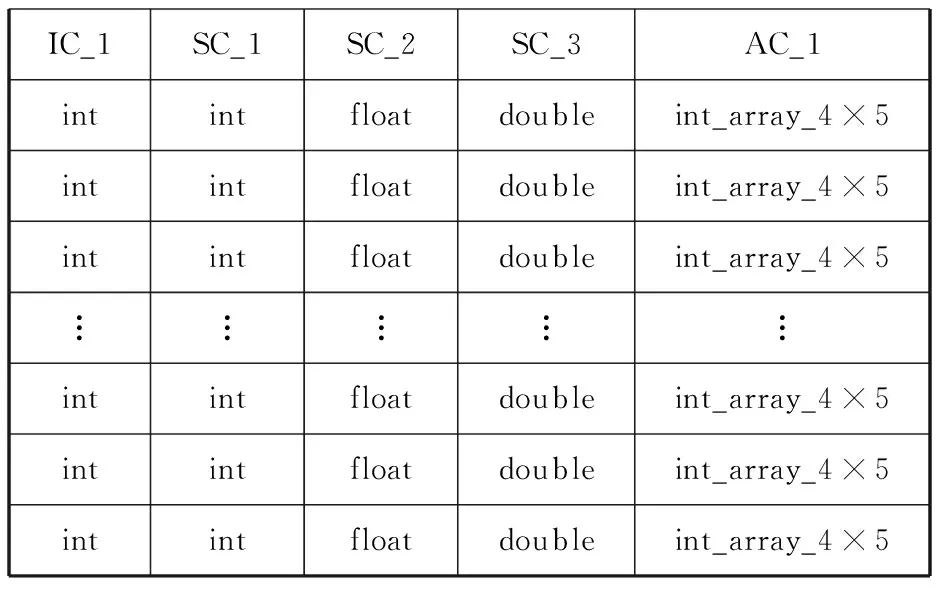
表1 CASA TABLE示例表
CASA提供了底层数据存储类StorageManager,使得其可以被二次开发来替换原始的数据读写方式,从而进行I/O优化。StorageManager是CASA核心库即casacore中负责数据读写的模块,其决定了数据的存储方式、位置、元数据信息等。目前,CASA中调用的StorageManager只支持集中式环境下串行的数据I/O,导致了I/O效率低下、无法扩展、硬件要求高等问题,已经难以满足当前海量射电天文数据的处理需求。
2 系统框架
为了无缝支持CASA系统,DDSS结合CASA环境编写而成,其与CASA以及casacore库的整体结构与数据流入流出过程如图1所示。图1中虚线框中即为的主要模块,包括数据划分模块、数据分配模块、重写后的CASA存储管理(DDSS_StMan)模块和数据流出的接口。系统的工作流程为:数据先经过划分,经数据分配模块分配到各个节点,各个节点的存储管理器DDSS_StMan负责数据的写入和读出。
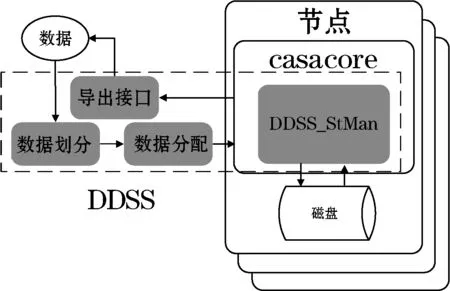
图1 DDSS框架图
形式化描述如下:
定义1CASA TABLE形式的数据集D={F1,F2,…,F|D|}。其中,Fi表示按照数据分片策略stfrag得到的数据片段,F1,F2,…,F|D|应满足F1∪F2∪…∪F|D|=D且Fi1∩Fi2=φ(i1≠i2,0≤i1,i2≤|D|)。
定义2节点集N={N1,N2,…,N|N|}。
其中,Nk表示系统中第k个存储节点。数据集D依照数据分配策略stallo分配到各个节点,每个节点Nk所得到的数据D_Nk可以表示为D_Nk=stallo(stfrag(D),N)。当上层需要数据时,各个节点同时通过存储管理器(DDSS_StMan)模块从磁盘中取出数据,转换成CASA TABLE的格式,完成过滤后流入导出接口。上层CASA应用可以直接调用各节点接口中的数据,完成其所需要的操作。
DDSS面向的是海量实时流入的CASA TABLE数据(如图1所示),因此无论是数据划分还是数据存储管理都必须考虑到以下问题:1) 数据对象是CASA TABLE,该数据以阵列类型数据为主,同时也包含普通数据类型;2) 尽可能提高并行执行度,来提供数据读写的效率。为此,本文将进一步详细介绍数据划分模块及重写后的CASA存储管理模块。而数据分配模块主要采用一致性哈希算法[8,9]完成数据分配[10],在此不再赘述。
3 混合分片列式存储策略
在CASA TABLE中,由于大部分数据量倾斜在ArrayColumn中,ArrayColumn往往会是所关注的焦点,在大量实际应用中,都需要对ArrayColumn中的阵列数据进行读取,此时列存储是十分适合这类场景的。然而,若采用直接的列存储,将数据垂直划分后用多进程分别写入不同列的方法,会使得某个进程需要写入大量的数据,而其他所有进程写入少量的数据,造成并行效率低的问题。因此,本文采用混合分片列式存储策略。
混合分片列式存储[11]是指在满足定义1的前提下将数据集D先进行水平划分,再进行垂直划分。其与行列混合存储的不同之处在于垂直划分后的数据片段F1,F2,…,F|D|分别根据属性名的不同,存于不同的文件之中。这样既解决了列存储在写入效率的不足,同时却保持了列存储的形式,可以发挥列存储在读取某单一属性如CASA TABLE中实际数据存放的ArrayColumn列效率高的优势。如图2所示,Table为一张8行三列的CASA TABLE,以三行为一个水平划分,按此划分通过下文的分配策略分配到每个节点,然后以列为单位,写进程分别将数据写入对应列名的文件中如tableIC_1、tableSC_1和AC_1中,从而实现了列存储。在分布式环境下,数据片段Fi根据分配策略stallo分配到满足定义2的节点集N。相同属性的数据片段Fi会
在各个节点被写入相同路径的文件中。当数据不断增加,以追加的方式的到来时,新的数据也会以追加的方式写入同一列名的文件夹中。
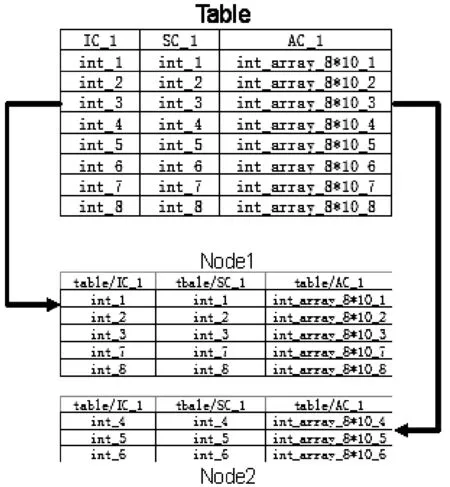
图2 数据表分片图
在进行数据分析,读取磁盘数据时,虽然每个节点储存列文件中的不同分片数据并不连续,但是单个分片内的数据是以顺序的方式存储中的。通常CASA TABLE中的数据会以时间或者天线频道排序,这样当天文学家需要某个时间段或者某个频道的阵列数据时,就只需要在某一个节点读取数据,节省了多节点元组重构和通信的网络开销。
4 数据存储管理器——DDSS_StMan
DDSS_StMan是DDSS中负责数据读写和管理的模块。由于casacore中原有的存储管理器(StorageManager)并不支持分布式环境。DDSS_StMan重写了StorageManager使其支持分布式与并行的环境,并且使用基于相对位置映射的元数据,加快阵列数据读取的速度。
4.1 支持分布式环境的DDSS_StMan
casacore中原有的存储管理器在设计时数据读写是单进程、串行处理的。同时,由于casacore库中全局的元数据文件以表为单位来创建,但在分布式环境下,我们对数据表进行划分,但casacore中的元数据信息却并不支持因数据表划分而再次划分元数据文件,这便在写数据时造成了元数据文件冲突。在DDSS _StMan为了支持分布式环境,在数据读写时提供了支持多进程的接口,并记录了各个节点数据的全局信息。于此同时其数据读写不再依靠casacore中所使用的元数据信息,以避免在分布式环境中所造成的各种元数据信息错误。当写入数据时,每个进程得到其划分后的数据之后,开始写入数据,并记录相关信息,完成基于相对位置映射的元数据。当读取数据时,不再从casacore库中所使用的元数据信息来寻找数据,而是通过之前维护的相对位置映射元数据来完成数据寻址,进行数据读取。
4.2 基于相对位置映射的元数据
在节点接收数据的水平分片后,将其垂直划分,根据之前的分配算法用相应的进程写入磁盘。在应用坏境中,进程需要读取ArrayColumn中的某一行或某几行。在列存储中,读取节点上单独列所有内容,是非常便捷的,但是当进行选择性读取的时候,往往需要从头遍历该列的数据文件,从而产生巨大的开销。传统的索引技术并不适用与阵列数据,而一些基于阵列数据的索引大多针对某一阵列内部数据。因此,本文提出了一种在写入阵列数据的同时,维护该列阵列各阵列相对位置的元数据信息,来快速定位该阵列在文件中的位置。如图3所示。每个ArrayColumn的阵列数据文件都会有一个对应的元数据文件,元数据文件中的指针与阵列数据文件中的阵列一一对应。当得到元数据文件中指针的位置时,便可以将位置信息映射到阵列数据文件中,再通过位置信息直接读取需要的阵列。DDSS中,使用行号作为元组重构的键值,元数据文件中也会记录相应的行号信息。
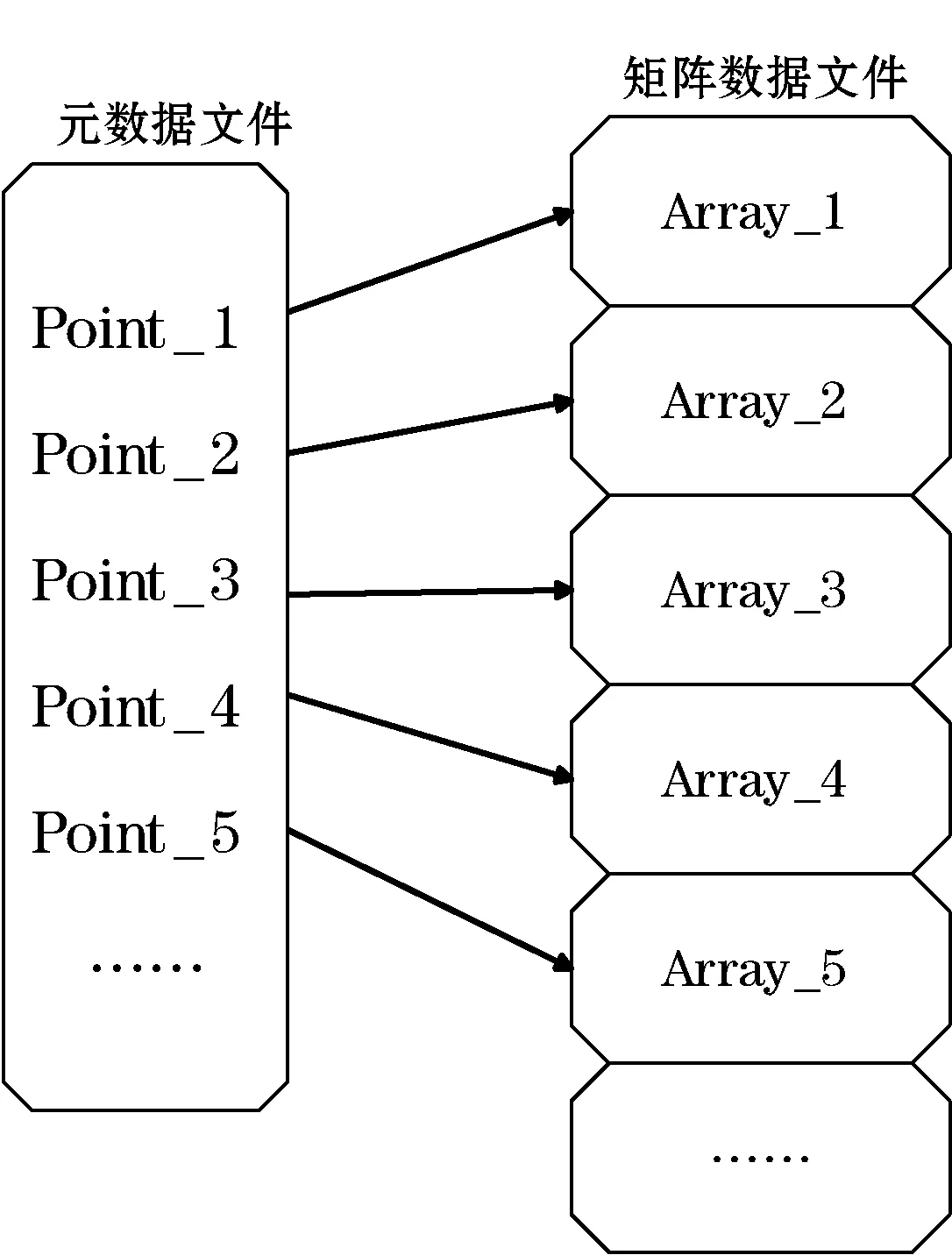
图3 指针与数据的相对位置映射图
实现上述的功能需要重写CASA存储管理器,尤其是修改其中的put与get函数。在put函数中需要添加写元数据文件的功能,而在get函数中需要先读取元数据文件,确认所需数据的实际地址映射。再根据映射关系map函数来确定实际数据的储存位置。最后,读取相应的阵列数据文件中所需要的阵列数据。
4.3 相对位置映射方法设计
ArrayColumn以列存储的方式,用字节流写入磁盘之中,设每个阵列大小为SA字节,总共写入k行,即k个阵列。同时,在元数据文件中写入指针,指针大小远远小于阵列大小,设指针大小为SP字节总共写入k行,即k个指针,其中SP< (1) 通过P_Pos的值,可以推导出对应阵列在阵列文件中的起始字节位置P_SB: P_PS=P_Pos×SA×k (2) 得到阵列起始位置P_SB后,在读取阵列文件时,使用lseek(filename,P_SB)函数直接从该阵列所在的位置读取SA个字节即可。 令式(1)与式(2)的计算函数为P_SB=Map(pki),基于运用基于位置映射的元数据来选取阵列数据的算法如下: 算法1:FindArray(int Row_id) 输入:元组重构的行号。 输出:该元组的阵列。 1readbuffer_meta[n];2readbuffer_array[m];3read(metadata,readbuffer_meta);4while(readbuffer_meta[i]!=NULL)5 if(Row_id==readbuffer_meta[i])6 pki==I;7 break;8 i++;9P_SB=Map(pki);10lseek(ArrayData,P_SB);11read(ArrayData,readbuffer_array);12returnreadbuffer_array; 该方法在传统的数据库中针对传统数据并没有任何效果,反而可能会影响读取效率,然而针对CASA TABLE中的ArrayColumn却非常适合。因为CASA TABLE中绝大部分数据量倾斜在ArrayColumn中,ArrayColumn中的一个阵列所占的存储空间往往可以达到MB级别。而元数据文件的总大小往往只有KB级别。在实验中发现,一个1 GB左右大小的数据文件所对应的元数据文件约为5 KB。鉴于这种情况,全扫描元数据文件所带来的开销几乎可以忽略不计,但却可以快速定位阵列数据文件中相应阵列的位置,避免了大量的阵列文件扫描的开销。 DDSS通过上述方法将数据取出,并依赖casacore完成部分节点内处理后传递至导出接口,上层即可直接运用接口中的数据,完成相应操作。 5.1 实验环境 实验采用centos 6.4(Final)和casacore-1.5.0作为软件环境。硬件采用2个服务器作为节点,每个服务器拥有2个4核的CPU(Intel Xeon CPU E5-2609 2.40 GHz),32 GB内存,和Broadcom NetXtreme BCM5750 千兆网卡。实验数据采用MWA[12]天文项目中数据,共23列,阵列型数据5列(即CASA TABLE中的ArrayColumn),阵列大小为4×384的浮点型数据,占整张表数据量的99.98%。同时,为了测试DDSS与casacore中标准存储模式在不同数据规模下的性能,将阵列型数据复制扩大,并且应实验需要,数据在内存中生成。 5.2 实验结果和分析 本文实验对比了CASA使用casacore库中标准的数据存储管理器模块(STANDARD)与CASA使用DDSS的I/O能力,验证两者的表现。每组实验运行3次,取平均结果。 实验一分别测试了标准情况下与DDSS在单机串行环境和多节点并行下,针对不同数据量的读写性能。图4(a)中的数据量为9.5 GB,比较了单节点串行环境下STANDARD与DDSS的读写性能。图4(b)中数据量为38 GB,比较了STANDARD与DDSS在单节点串行和多节点并行的读写能力,其中DDSS的并行环境为2个节点。每个阵列大小均约为1 MB。 图4 实验结果 结合图4分析可得,在串行环境下,无论数据量或大或小,DDSS的数据写入性能都率优于STANDARD,其随着数据量的增大,两者耗时的比例几乎不变,DDSS比STANDARD快1.2倍左右。但是在数据读取方面DDSS则比CASA在大量数据环境下有了显著的提升,单机和集群两种情况分别比STANDARD快了5.6倍和6.8倍,可见列存储和基于位置映射的读取数据方式是十分有效的。并且当数据量不断扩大时,DDSS的效果会更加优越。在分布式环境中,DDSS十分有效地提升了数据写入的速度,比STANDARD快了3.4倍。当数据量较小的情况下,本文方法读取数据的效果提升的较少,其原因是分布式环境下,每个节点得到的数据量减少,在数据量不大的情况下,效果并不十分显著。总结可得,通过分布式并行处理有效地减少了数据的读写时间。 实验二测试了阵列为1、2、4 MB时系统的读写数据时间。数据的总量为38 GB保持不变,每个实验按照阵列大小改变其记录条数。如图5所示,可以发现在数据总量不变的情况下,更改单个阵列的大小对系统的读写性能几乎没有影响,这说明DDSS可以灵活满足各种大小的阵列数据,适合各种天文场景的应用。 图5 DDSS应对不同大小阵列的吞吐量图 本文提出了适应主流射电天文软件CASA的底层分布式数据存储策略。在不改变任何上层应用层的条件下,使其支持分布式环境,将数据进行混合方片后采用列存储的方法,重写数据储存管理器并维护基于相对位置映射的元数据,提升CASA软件的底层I/O读写效率。最后通过一系列实验验证了所提方法DDSS的有效性。在未来的研究中,针对ArrayColumn和列存储,可以对阵列数据进行数据压缩,进一步提高读写效率。另外重点关注于进程安全问题,在保证并行效果的同时,完善其对进程安全的控制,提高系统的健壮性和可靠性。 [1] McMullin J P,Waters B,Young W,et al.CASA Architecture and Applications[C]//Astronomical Data Analysis Software and Systems XVI ASP Conference Series,2007,376:127. [2] Diepen G N J V.Casacore Table Data System and its use in the MeasurementSet[J].Astronomy and Computing,2015,12:174-180. [3] Zetics P,Jose S.Overview of sciDB:large scale array storage,processing and analysis[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data,2010,NY,USA:ACM,2010:963-968. [4] Yao Y,Bowen B,Dalya B,et al.SciDB for High-Performance Array-Structured Science Data at NERSC[J].Computing in Science & Engineering,2015,17(3):44-52. [5] Buck J,Watkins N,LeFevre J,et al.SciHadoop:array-based query processing in Hadoop[C]//Proceedings of International Conference for High Performance Computing,Networking,Storage and Analysis,2011,NY,USA:ACM,2011. [6] Buck J,Watkins N,Levin G,et al.SIDR:structure-aware intelligent data routing in Hadoop[C]//Proceedings of the International Conference on High Performance Computing,Networking,Storage and Analysis,2013,NY,USA:ACM,2013. [7] 危兵,王锋,邓辉,等.CASA混合编程技术分析与功能扩展研究[J].天文技术与研究,2014,11(1):46-53. [8] Hong T,Wu Ya,Cao B,et al.A dynamic data allocation method with improved load-balancing for cloud storage system[C]//Proceedings of the 31st AIAA International Communications Satellite Systems Conference (ICSSC),2013,Shanghai,China,2013:220-225. [9] 巴子言,吴军,马严.基于虚节点的一致性哈希算法的优化[J].软件,2014(12):26-29. [10] Eswaran K. Placement of records in a file and file allocation in a computer network[C]//Proceedings of IFIP Congress on Information Processing.Stockholm,Sweden,1974,304-307. [11] Floratou A,Patel J,Shekita E,et al.Column-oriented storage techniques for MapReduce[J].VLDB Endowment,2011,4(7):419-429. [12] Tingay S,Goeke R,Bowman J D,et al.The Murchison Widefield Array:The Square Kilometre Array Precursor at Low Radio Frequencies[J].Publications of the Astronomical Society of Australia,2012,30(30):109-121. A DISTRIBUTED DATA STORAGE STRATEGY FOR CASA Guo Huiqing Wang Mei Le Jiajin (SchoolofComputerScienceandTechnology,DonghuaUniversity,Shanghai201620,China) With the progress and development in astronomical equipments,to process massive astronomical data forms the new challenge.In order to make current mainstream astronomical data analysis software can effectively deal with massive data,we proposed a distributed data storage strategy (DDSS) applicable for radio astronomy to deal with upper application.First we designed the system framework of DDSS.Then we designed the hybrid method of partitioning and columnar storage,while preserving the advantage of column-store in data query,the speed of data import is promoted as well.Furthermore,by maintaining the relative position mapping-based metadata to quickly read astronomical array data containing large amount of data,the I/O throughput of astronomy when processing underlying data of applications is significantly improved.Finally,through experiment we testified the effectiveness of the proposed method. Distribution Astronomy Array data 2015-10-13。过汇卿,硕士生,主研领域:数据仓库和分布式技术。王梅,副教授。乐嘉锦,教授。 TP3 A 10.3969/j.issn.1000-386x.2016.11.007
5 实验与分析
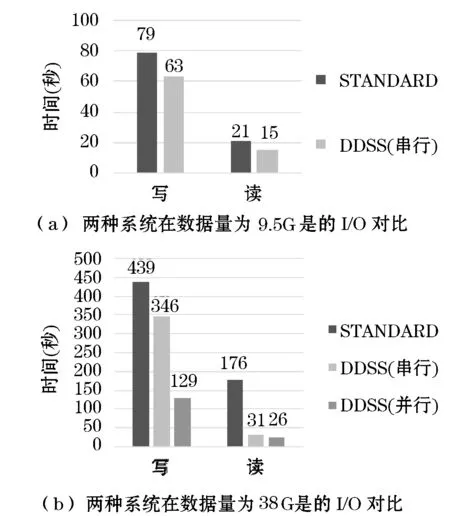
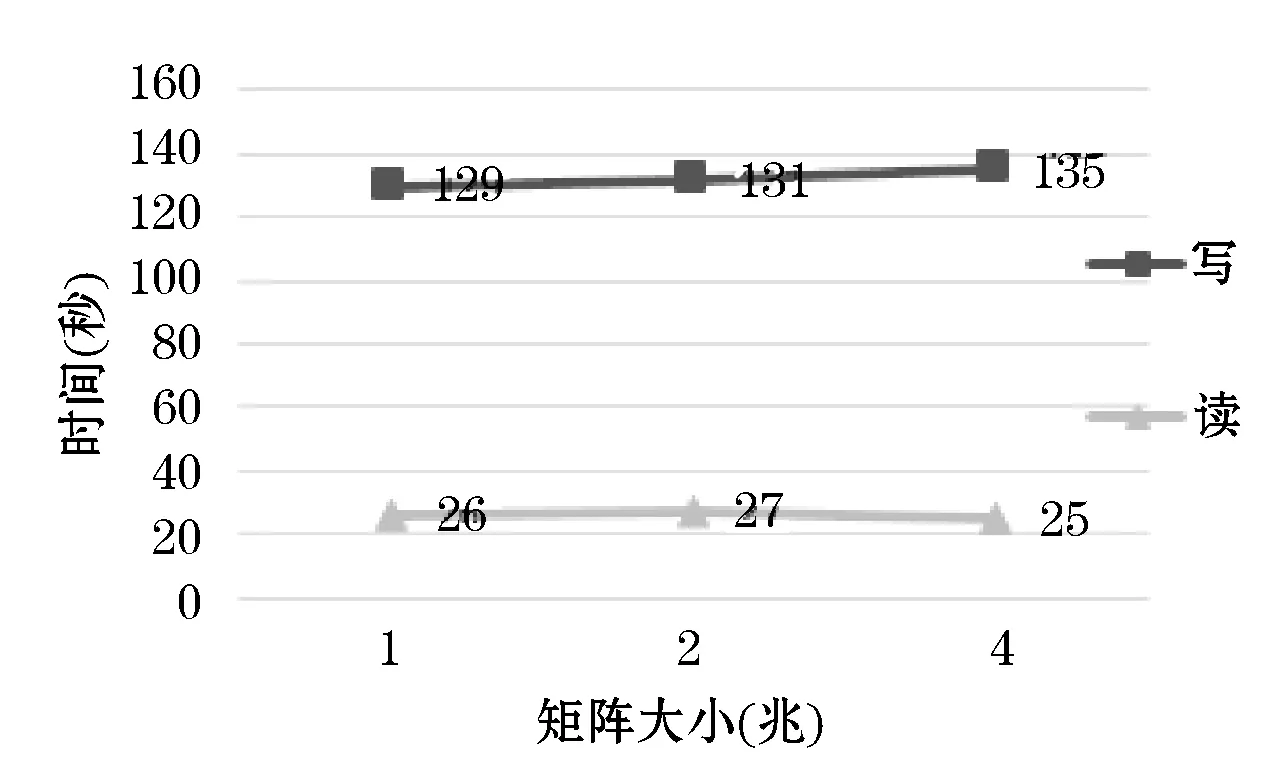
6 结 语
