基于聚类和梯度选择的网络协作学习分组算法
2016-12-26马艳云
马艳云,袁 健
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于聚类和梯度选择的网络协作学习分组算法
马艳云,袁 健
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于网络协作学习具备便捷、海量资源共享和不受时空约束的优势,但其学习效果易受学习者分组的影响;分组越科学合理,整体学习效果则越理想,反之亦然。文中根据网络协作学习者的个性化特征和协作特征,在引入团队协作学习量表解决学生协作能力判断的前提下,提出基于学习者特征聚类和协作特征梯度选择的GSDBK-means分组算法对学习者进行分组,以期达到提高网络协作学习效果的目的。经实验证明,GSDBK-means分组算法较于其他分组策略能产生更科学合理的分组结果,从而取得更好的学习效果。
分组算法;协作学习;聚类;梯度选择
伴随着网络学习和协作学习的发展,网络协作学习成为一种有效的学习模式[1],其既可针对在校学生进行基于网络的协作学习,又可使处于不同年龄、时间和地点的人们开展协作学习成为可能。通过在网络上进行协作学习,解决了传统网络学习产生的“孤独”学习者的问题,也解决了课堂协作学习找不到合适小组成员和资源的窘境。由于对协作前的准备——分组缺乏有效的技术支持[2],而协作学习的核心是分组,这意味着协作分组的优劣对于协作学习起着关键性的作用。
1 研究现状
目前网络协作学习分组主要在相关理论上进行研究,对于网络协作学习分组算法的研究不多。胡慧[3]等基于蚁群算法根据学习者个性化特征进行同质分组;但蚁群算法搜索时间过长,大部分的时间都耗费在算法中解的构造,求解时间有待进一步的优化;Chen Long[4]等基于遗传算法根据学习者特征进行异质分组;遗传算法易造成局部最优,当学习者特征维数较多时难以进行处理和优化,算法的时间性能也得不到保证。刘均[5]采用层次聚类方法 AGNES根据学习者认知水平进行同质分组。层次聚类方法相对于K-means算法,层次聚类簇的数目难以确定。唐杰[6]根据学习者特征采用K-means算法进行目标聚类、异质聚类、差异性聚类对于学习者进行异质分组;K-means算法初始中心点的选取对于算法时间性能具有较大影响。
本文基于协作学习理论[7]、建构主义理论[8],加入协作学习的群体特征,利用改进的聚类算法结合梯度选择提出了基于聚类和梯度选择的网络协作学习分组算法(Density-Based Improved K-Means With Gradient Select Grouping Algorithm, GSDBK-means)。通过基于密度选取聚类中心点的方法改进K-means算法,对于学习者的特征属性进行聚类,再引入团队学习能力量表[9]判断学习者的协作能力,解决首次协作学习成员群体特征属性值为0的情况。最后基于梯度选择根据学习者的协作能力对于聚类后的每个簇进行分组。
2 网络协作学习分组模型
在基于网络协作学习的环境中,分组模型是为用户提供更好服务的强有力机制[10],如图1所示,学习者要进行合适的分组,需要获得学习者重要的特征参数。根据分组模型,学习者在注册时将个人基本信息存入学习者档案,通过登录操作进一步完善相关信息存入学习者档案中。本文采用学习偏好、知识水平、认知水平作为学生的个性化特征,协作能力作为协作特征在学生登录后进行特征测量。对于协作特征采用学生自测和伙伴互测两种方式进行测量。所有的个性化特征和协作特征均将存储在学习者特征库中,作为网络协作学习分组的依据。
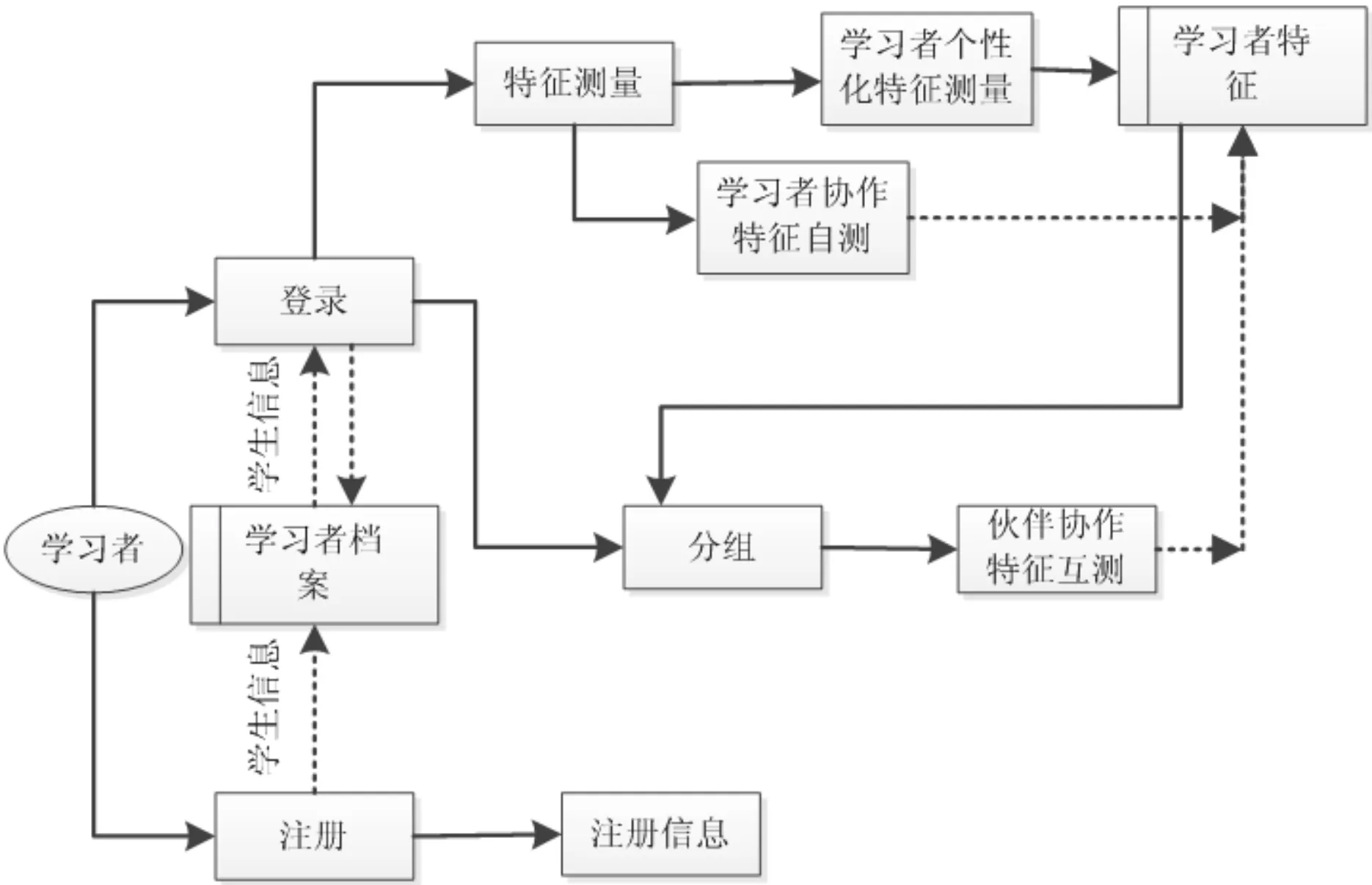
图1 网络协作学习分组模型
根据学习者的特征量化值,将N个学习者基于学习者特征相似性和协作能力差异性进行分组,使其既满足分组原则又能保证小组内人数均匀[11]。本文所需的相关变量及计算方式如下:
变量 1对象间距离 dist(i,j)。对象之间的距离dist(i,j)使用欧式距离来表示
(1)
式中,d表示数据的纬度;ik、jk表示学习者i,j对应的第K个特征;
变量 2 邻域半径Eps。定义对象的邻域半径Eps
(2)
其中,i和j表示对象;d表示学习者的特征维度;n表示学习者的个数;
变量 3Eps邻域NEps(p)。数据对象p的Eps邻域NEps(p)定义为
NEps(p)={q∈S|dist(p,q)≤Eps}
(3)
其中 ,S∈Rd为d维实空间上的数据集 , dist(p,q) 表示S中对象p和q之间的距离;
变量 4邻域密度ρ(p)。为对象p的邻域NEps(p)内所包含的对象个数,即ρ(p)=|NEps(p)|;
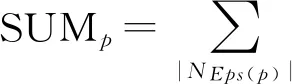
变量 6核心点Mp。对于任意对象p∈S,在P的邻域NEps(p)内,Mp定义为
(4)
3 GSDBK-means分组算法
3.1 数据标准化
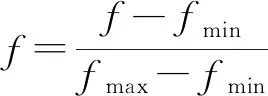
3.2 算法描述及流程图
网络协作学习强调的是通过网络让学习者以小组形式参与学习,最大化个人学习成果。如何生成高效而有意义的协作小组,是网络协作学习的关键。本文考虑将学习者个性化特征相似的学习者分在一个小组,使其对学习有共同的兴趣,让协作能力相异的学习者分在一个小组,确保小组成员可互帮互助,增加小组凝聚力。根据Feichtner和Davis的调查中显示,小组成员在4~7个人时为小组的最佳学习人数[14]。本文采用选择对象邻域高密度[15]的学习者作为K-means的中心点来改进学习者基于个性化特征相似聚类,对于聚类后的每个簇基于“组间同质,组内异质”,即组间协作能力相似,组内协作能力有差异的梯度选择算法进行分组。具体GSDBK-means分组算法和分组流程,由图2进行表示。GSDBK-means分组算法步骤:
步骤1 初始化参数。对于n个对象,p∈s,s={s1,s2,…,sn},分别通过标准化公式将数据量化,设置聚类的最大迭代次数time;
步骤2 计算对象的邻域密度。根据对象的个性化特征按照式(2)计算聚类对象的邻域半径Eps,以每个对象为中心,Eps为邻域半径,得到每个对象的NEps(p),以及每个邻域内的对象个数|NEps(p)|,即对象在这个邻域内的密度ρ(p);
步骤3 计算密度核心点。根据式(4)计算对象的M点,并将这一邻域内的对象全部从待聚类的对象中全部剔除。对剩余的对象按照式(4)进行迭代计算,直至得到k个核心点为止;
步骤4 选取初始中心点。根据密度法计算出的k个核心点,作为K-means聚类的初始聚类中心;
步骤5 计算个性化特征相似度。根据(1)式计算每个对象到聚类中心的距离dist(i,p),将对象分到与其距离最小的簇中;
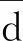
步骤7 按照协作特征进行分层。分别计算每个簇的大小size,并按照协作能力进行排序,再根据0~size/n,(size/n+1)~size/n×(n-1),size/n×(n-1)~size分成高、中、低3个梯度;
步骤8 根据协作特征按照梯度选择进行分组。根据协作能力基本呈现正态分布的排列情况,从高、中、低3个梯度的对象中按照有序选取的方法对应顺序选取1,n-2,1共n个对象组成小组;当某个聚类结果总人数不是n的倍数时,则将剩余的对象加入其最适合的小组中。
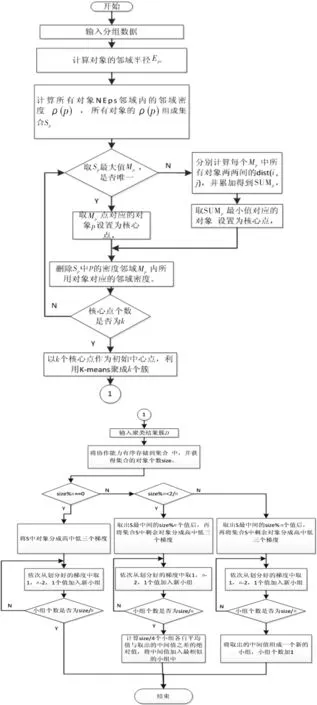
图2 分组算法流程图
4 实验设计与分析
4.1 实验设置
为了证实本文分组算法的有效性,对于上海理工大学英语学科一位老师所带的4个平行班级200名大一新生设计基于不同分组策略进行网上辅助学习的对比实验,并以他们的期末成绩作为学习效果评判依据。首先,对于第1个班级采取不分组的方式进行学习,第2个班级采取学生随机分组的方式进行学习,第3个班级基于本文所提到的学生个性化特征(学习偏好、知识水平、认知水平)进行个性化分组,最后一个班级,在考虑学生个性化特征的基础上利用团队学习能力量表,加上学生的协作特征——协作能力,基于GSDBK-means进行分组学习。
其次,设置小组人数为4人。第3个小组采取基于密度改进的K-means进行分组,设置聚类簇数K=4,迭代次数为1 000,聚类后从每个聚类中随机抽取4人组成一组;第4个小组同样设置聚类簇数K=4,迭代次数为1 000。
4.2 实验分析
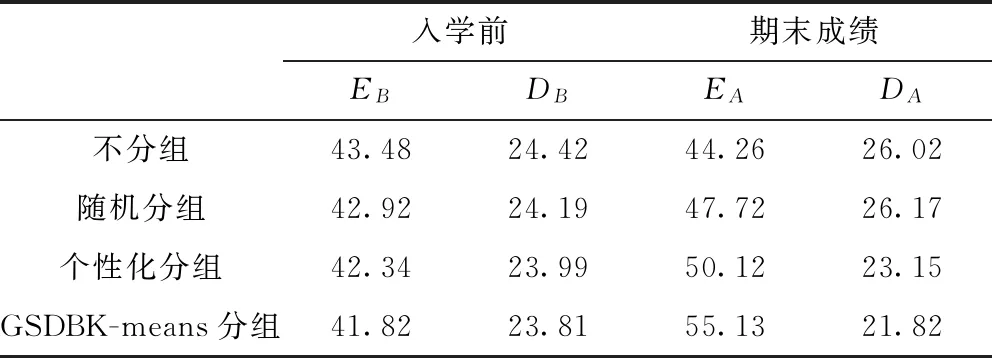
表1 采取不同分组策略的学习效果对比
从表1中可看出,基于分组的协作学习效率相较于不分组的学习效率高;对比随机分组和个性化分组,增加协作特征的GSDBK-means分组学习的学生成绩平均值 增幅较大,表征组内学生成绩分散程度的 大幅度降低,这表示基于GSDBK-means分组的协作学习能进一步的提高学生成绩的平均水平,缩小学生之间的差距,使学生之间协作互助,知识共享的高效学习得到了较好的体现。
5 结束语
通过分析学习者协作学习的各要素,建立了网络协作学习的分组模型。在此基础上,通过GSDBK-means算法将学习者个人特征相似、协作能力有差异的学生组成一个协作小组,同时又保证了各小组间差异较小,便于组间竞争,这便是符合当下流行的“组间同质,组内异质”分组原则。最后根据英语学科学生分组对比学习,证明将学习偏好、知识水平、认知能力相近,协作能力相异的学习者分在一组能促进学习者之间更充分、有效地交互进而提高学习效率。针对不同的教学目标,设计者也可考虑不同的学习者特征。本文仅对网络协作学习提供智能化分组奠定了基础,对于网络协作学习的学习者流动性等特性还需对分组进一步改进。
[1] 王永固,李克东.主题式网络协作学习模型及其案例研究[J].中国电化教育,2008 (2):46-51.
[2] Li Li,Luo Xiangfeng.Automatic student grouping method for foreign language learning[C].Beijing:10th International Conference on Semantics、Knowledge and Grids (SKG),2014.
[3] 胡慧.基于改进蚁群算法的协作学习分组研究[J].计算机工程与应用,2014,50(13):137-141.
[4] Chen Long,Yang Qinghong.A group division method based on collaborative learning elements[C].Changsha:26th Chinese Control and Decision Conference,2014.
[5] 刘均,李人厚,郑庆华.一种面向个性化协同学习的任务生成方法[J].软件学报,2006, 17(1):79-85.
[6] 唐杰,李浩君,邱飞岳.mCSCL环境下协作分组的伙伴模型研究[J].中国远程教育:综合版,2012(3):48-51.
[7] 琳达·哈拉西姆,肖俊洪.协作学习理论与实践——在线教育质量的根本保证[J].中国远程教育:综合版,2015(8):5-16.
[8] 李静,赵伟.基于建构主义学习理论基础上的现代远程教育[J].电化教育研究, 2003(5):37-40.
[9] 陈国权.复杂变化环境下人的学习能力:概念、模型、测量及影响[J].中国管理科学,2008,16(1):147-157.
[10] 刘菊香.基于模糊理论的网上协作学习学生分组系统的研究与实现[D].上海:华东师范大学,2006.
[11] Pang Yulei,Raymond Mugno,Xue Xiaozhen,et al.Constructing collab-orative learning groups with maximum diversity requirements[C].Hualien: IEEE 15th International Conference on Advanced Learning Technologies,2014.
[12] 陈林林.移动学习中学习者偏好模型研究[D].武汉:华中师范大学,2013.
[13] 孙家振,朱玉全,周李威,等.基于模糊规则的学习者认知水平估算方法[J].计算机应用研究,2014,31(9):2652-2655.
[14] 李洁.CSCL中协作小组分组系统的设计与开发研究[D].广州:华南师范大学,2005.
[15] Xia L N,Jing J W.SA-DBSCAN:A self-adaptive density-based clustering algorithm[J].Journal of the Graduate School of the Chinese Academy of Sciences,2009,26(4):530-538.
Based on GSDBK-means Grouping Algorithm Reseach for Networked Collaborative Learning
MA Yanyun,YUAN Jian
(School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
Based on network collaborative learning with convenient, massive resources sharing and not subject to the restriction of time and space advantage, but its learning results susceptible to study the impact of packet; packet more scientific and reasonable, learning effect is more ideal, and vice versa. This paper according to the collaborative network learners personalized features and the characteristics of collaboration, in the introduction of team cooperation learning scale to solve student’s cooperative ability judgment premise proposed to learners in grouping learning based on gradient feature clustering and collaborative feature selection GSDBK-means grouping algorithm, in order to improve the network collaborative learning effect. The experimental results show that the GSDBK-means grouping algorithm can produce more scientific and reasonable grouping results compared with other grouping strategies, which can obtain better learning results.
grouping algorithm; collaborative learning; clustering; gradient selection
10.16180/j.cnki.issn1007-7820.2016.12.025
2016- 02- 05
马艳云(1992-),女,硕士研究生。研究方向:网络学习。袁健(1971-),女,副教授,硕士生导师。研究方向:云计算安全与大数据管理等。
TP301.6
A
1007-7820(2016)12-089-04
