基于术语提取的药品作用冲突自动检测模型
2016-12-19张顺香张世尧
张顺香,张世尧,王 银
(安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
基于术语提取的药品作用冲突自动检测模型
张顺香,张世尧,王 银
(安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
药品作用冲突自动检测是快速发现多种药物之间不良反应关系的信息检索技术,其可有效减轻医师和患者巨大的认知负担。药品作用冲突识别的核心任务是以药品信息为基本语义单元,分析并建立药品之间的冲突知识规则,实现药品之间冲突作用的深层次检测。提出的基于术语提取的药品作用冲突自动检测模型包括顺序递进的四个层次,即数据源的预处理、术语提取、药品冲突知识库的构建及药品作用冲突的自动检测。实验结果证明所提出的模型具有较高的准确度。
药品作用冲突;术语提取;冲突知识库;自动检测
药品冲突作用(Drug Interaction Conflict, DIC)是指两种或两种以上的药品同时服用时所可能发生的理化效应、拮抗等,其可能引起药品疗效下降或毒性增加,医学上称之谓为“配伍禁忌(Contraindications)”。现代临床使用的药品种类繁多,药品之间的相互作用千差万别,难免发生药品相互作用,要完全掌握药物之间的相互作用十分不易[1]。
非处方药中的复方制剂,都是选择作用彼此增强、相互抵销或减少不良反应的原则配伍组成[1]。对于处方药,《首都医药》杂志对北京市二级以上50家医院开药的的处方进行调查,结果存在明显相互作用的3类处方占94%[2]。这说明无论是医师[3],还是患者对了解药品的相互作用具有极其重要的意义。然而,药品种类纷繁复杂,人们对海量的药品数据无从下手,需要运用新的科技手段来减轻医师、患者的认知负担。
为解决这一问题,本文结合自然处理中的术语提取技术和数据库技术,提出了基于术语提取的药品作用冲突自动检测模型,以期帮助用户快速检测、发现给定药品之间是否存在作用冲突,使得人们可以智能地、合理地选取药品,达到健康用药的目的。模型框架分成四层,如图1所示。
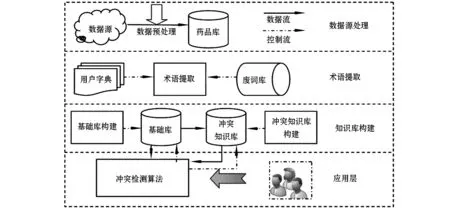
图1 药品作用冲突自动检测模型框架
1) 数据源预处理层:对数据源进行结构化处理,分析药品属性数据,面向药品作用冲突作用冲突检测简化药品数据结构;
2) 术语提取层:借助于NLPIR汉语分词系统,扩充用户字典和更新废词库,利用动态窗口分割方法进行药品成份术语和类别术语的提取;
3) 知识库构建层:在术语提取的基础上,设计并构建三个基础数据库:成分库、类别库和药品编码库;进一步挖掘药品作用冲突规则,构建冲突知识库。
4) 应用层:设计药品作用冲突检测算法,供用户进行药品冲突查询。冲突检测算法将查询冲突知识库,必要时结合基础实现冲突查询。
本文组织如下:第2节介绍介绍药品相互作用和术语提取的相关工作;第3节给出药品数据源处理及术语提取方法;第4节给出相关定义及知识库的构建方法;第5节介绍冲突检测算法;第6节给出模型的实验分析;第7节对本文进行总结。
1 相关工作
1) 药品相互作用。要做到合理用药,必须掌握药物之间的相互作用。面对种类繁多的药品,药品的相互作用速查表可供医师临床参考。文献[4]通过分子荧光互补实验,结合免疫荧光定位实验、免疫共沉淀等技术,分析并揭示了L-periaxin蛋白与Ezrin蛋白之间的互作方式。文献[5]分析不同结合物对药物的运载能力随环糊精数量的增加而增强。文献[6]对一些常用中药进行潜在药物相互作用研究,以预测其可能发生的药物相互作用,提供临床用药安全有效的重要途径。文献[7]对四物汤有效成分与模拟生物膜相互作用的影响进行深入研究。文献[8]利用电子医疗记录数据库进行药品相互作用的识别。
2) 术语提取。文献[9]针对锚文本和查询文本所存在的文本长度过短、语义信息不足等缺点,提出一种适用于各种类型网络数据及网络用户行为数据的领域数据提取方法。文献[10]利用自然语言处理技术过滤掉与术语无关的成分,对语句进行自然切割,为领域术语提取提供完整的候选数据集。文献[11]提出一种基于分离模型的中文关键词提取算法,根据关键单词提取和关键词串的不同特征进行关键词提取。NLPIR汉语分词系统可有效地实现中文分词、词性标注、命名实体识别、用户词典自定义等,为领域术语提取建立良好的基础。文献[12]利用NLPIR汉语分词系统,扩充用户词典,采用动态变化的窗口长度实现从中文课程中提取课程专业术语。
从研究现状来看,药品相互作用主要集中药品的成份、药理等本身研究,术语提取主要集中网络、课程文本的术语提取。
2 数据源处理-术语提取
数据源处理主要任务包含两个方面,一是对药品的说明书进行分析,对药品的主要属性进行提取和分析;二是根据分析的结果,利用中科院的开源中文分词系统,结合用户词典的扩充和废词库的更新,进行药品成分和类别等术语提取。
2.1 药品数据源属性分析
通常药品数据源的属性主要包括药品名称、成份、性状、作用类别、适应症、规格、用法用量、不良反应、禁忌、注意事项、药物相互作用、药理作用和生产企业等。根据药品这些常用属性,药品信息的数据结构Drug-DS可定义如下。
Struct Drug-DS
{char ID[20],name[20],element[100],
characteristics[30],role-categories[30],
indications[60],specifications[50],
usage-dosage[60],adverse-reactions[256],
contraindications[256],precautions[256];
drug-interaction[256],pharmacological-effect[256];
production-enterprises[60];}
通过大量药品说明书的研究发现,与分析药品冲突作用相关的属性主要有名称、成份、作用类别、药物相互作用。因此,基于药品属性的提取与分析角度,药品信息数据结构简化为
Struct simple-Drug-DS
{char ID[20];
char name[20];
char element[100];
char role-categories[30];
char drug-interaction[256];}
2.2 术语提取
根据药品数据源属性数据的分析结果,本文主要对药品的成份属性、类别属性和相互作用属性进行中文分词,并进行术语提取。下面以药品“双唑泰棉栓”为例,说明术语提取的过程。
1) 直接应用NLPIR汉语分词系统。NLPIR汉语分词系统中国科学院研究开发的,可用于网络搜索、 自然语言理解和文 本挖掘的技术开发的基础工具集。该系统可以使用用户的自定义字典来进行分词,并对词性进行了标注。本文首先利用分词工具对药品说明书中的相互作用和成分等进行分词,图2是对“双唑泰棉栓”的相互作用属性的分词结果。

1/m氯/n已/d定/v与/p肥皂/n、/wn碘化钾/n等/udeng有/vyou配/v伍/nr1禁忌/n。/wj与/p硼砂/n、/wn碳酸/n氢/ng盐/n、/wn碳酸盐/n、/wn氧化物/n、/wn枸/n橼/x酸/a盐/n、/wn磷酸盐/n和/cc硫酸盐/n也/d有/vyou配/v伍/nr1禁忌/n。…
图2 直接应用NLPIR分词结果
从图2可以发现,如果直接应用NLPIR汉语分词系统,分词系统使用默认的字典对结果进行分词,一些医学名词不能正确分割。例如“氯已定”这一成份术语被分割成三个独立的词“氯”,“已”和“定”。为此我们需要对NLPIR汉语分词系统的用户词典和废词库进行扩充和更新。
2) 扩充用户词典。进行用户词典的扩充最直接有效的办法是,从现有的医学词典中导入专业词汇,对分词工具中的用户词典进行扩充,并结合数据源的内容,进行人工分析,最终确定导入的医学词汇,保证导入用户词典的正确率。在对用户词典导入后,重新使用NLPIR汉语分词系统对“双唑泰棉栓”的相互作用属性进行分词,分词结果如图3所示。

1/m氯已定/n与/p肥皂/n、/wn碘化钾/n等/udeng有/vyou配伍禁忌/n。/wj与/p硼砂/n、/wn碳酸氢盐/n、/wn碳酸盐/n、/wn氧化物/n、/wn枸橼酸盐/n、/wn磷酸盐/n和/cc硫酸盐/n也/d有/vyou配伍禁忌/n。…
图3 扩充医学用户词典后分词结果
从图3可以看出,在进行用户词典扩充后,一些医学术语像“氯已定”,“碳酸氢盐”,“配伍禁忌”等被正确分割,而这也与实际相符合。但分词结果中仍然存在一些废词,为此需要进一步进行废词库更新。
3) 更新废词库。更新废词库的目的是将一些不需要的废词进行剔除,比如“作用”、“合用”“有”等,这些词没有实际意义,也不便于提取纯净的成份术语,更新废词库后的分词结果如图4所示。

氯已定/n肥皂/n碘化钾/n硼砂/n碳酸氢盐/n碳酸盐/n氧化物/n枸橼酸盐/n磷酸盐/n硫酸盐/n…
图4 扩充医学用户词典更新废词库后分词结果
3 构建冲突知识库
4.1 基本概念
定义1:药品成份库
在本模型中,药品成份库是指所有从n个药品说明书的成份(element)文本中提取的m个成份术语ele-Term所构成的集合,每个成份术语是表达药品的独立最小语义单元。每个成份术语在药品成份库中有唯一的编号ele-ID。从而,药品成份库DELib可描述为
DELib={(ele-IDi,ele-Termi)|
i=1,2,…,m} (1)
式中:ele-IDi表示药品成份库中的第i个成份的唯一编号;ele-Termi表示第i个成份的文本信息。
定义2:药品类别库
从药品的作用类别(categories)来看,每一种药品都有其所属的类别,药品类别库是指从所有药品说明书的作用类别中提取的k个类别术语cat-Term所构成的集合。每个药品类别术语在药品类别库中同样也有唯一的编号cat-ID。相应地,药品类别库DCLib可描述为
DCLib={(cat-IDi,cat-Termi)|
i=1,2,…,k} (2)
式中:cat-IDi表示药品类别库中的第i个类别的唯一编号;cat-Termi表示第i个类别的文本信息。
定义3:药品编码库
药品编码库包括每个药品的唯一编码、药品所有成份编码以及药品类别编码。药品编码库是基于药品成份库和药品类别库的定义基础上进行的,目的是便于快速查询每种药品所属的类别和可能包含的成份。对于n个药品,药品编码库DenLib可定义为
DenLib={(name-IDi,namei,ele-IDseti,cat-ID)} i=1,2,…,n,and ele-IDseti∈DElib,and cat-ID∈DClib
(3)
式中:name-IDi表示第i个药品的唯一编号;namei表示第i个药品的文本信息;ele-IDseti是第i个药品的所有成份编码的集合,cat-ID第i个药品所属类别的编号。
定义4:冲突类型
药品相互作用(Drug Interaction)是极其复杂的,它涉及到药品的理化性质、作用机理、体内过程、受体或作用部位效应,食物或环境污染物质对药品的影响;遗传基因以及药品对临床检查值的干扰等多方面因素。为了简化模型,只考虑药品之间的相互作用,不考虑药品与食物以及环境物质之间的相互作用。药品之间的相互作用分别包含物理化学的配伍禁忌、药代动力学的相互作用以及药效学的相互作用。概括起来,可以分为以下几种冲突类型:
①分解降效;②混浊或沉淀;③理化反应;④不相容;⑤拮抗作用;⑥毒性、不良反应增加;⑦稳定性降低; ⑧增强作用
Con-type={type-IDi|i=1,2,…,8}
(4)
式中:type-IDi表示第i种类型的冲突编码。
定义5:冲突规则
考察药品说明书的相互作用属性(Drug Interaction),从语义角度分析发现,主要有四种类型的冲突描述,即成份与成份、药品与成份、药品与类别和药品与药品之间存在不同类型的冲突。结合冲突类型的定义,冲突规则可描述为
Crule1={(ele-IDi,type-IDx,ele-IDj)}
(5)
Crule2={(name-IDi,type-IDx,ele-IDj)}
(6)
Crule3={(name-IDi,type-IDx,cat-IDj)}
(7)
Crule4={(name-IDi,type-IDx,name-IDj)}
(8)
式中:Crule1表示成份与成份的冲突规则;Crule2表示药品与成份的冲突规则;Crule3表示药品与类别的冲突规则;Crule4表示药品与药品的冲突规则;type-IDx表示某个冲突规则所属冲突类型。
每一种冲突规则均是一个三元组,即冲突前键、冲突类型和冲突后键。从冲突规则的定义可以看出,冲突前键可以是药品名和药品成份,冲突后键可以是药品类别、药品名、冲突成份。
定义这样四种类型的冲突规则基于一个基本思想:大多数非专业的用户只想查询某种药品和哪些药品存在冲突相互作用。同时,在实际应用中,前三种冲突规则可对第四种冲突规则Crule4进行完善和补充。
定义6:冲突知识库
冲突知识库由四种冲突表构成,与四种冲突规则相对应,每一种冲突表包含从药品相互作用属性提取出来的一种规则。从而冲突知识库CKLib可描述为
CKLib={(C-sheeti|i∈[1,4])}
(9)
C-sheet1={Crule1i|i=1,…,a}
(10)
C-sheet2={Crule2i|i=1,…,b}
(11)
C-sheet3={Crule3i|i=1,…,c}
(12)
C-sheet4={Crule4i|i=1,…,d}
(13)
式中:C-sheet1表示包含存储了总共a条Crule1(成份与成份冲突规则)的冲突表。C-sheet2、C-sheet3和C-sheet4冲突表和C-sheet1意义相同,不再赘述。
这里给出四种冲突表的一些具体实例,见表1、表2、表3、和表4。例如表1中第一行表示成份“氯已定”和成份“碘化钾”配伍会发生定义4中所说的第6种类型的冲突(不良反应增加);表2中的第一行表示药品“土霉素”和成份“甲硝唑”会发生发生第1种类型的冲突(降效,影响成分吸收);表3中的第一行表示药品“氟氯西林”和药品类别“氨基糖苷类”会发生第3种类型的冲突(理化反应);表4中的第9行药品“亚胺培南”和药品“乳酸钠”之间的冲突类型是第4种(不相容)。

表1 成份与成份C-sheet1冲突表
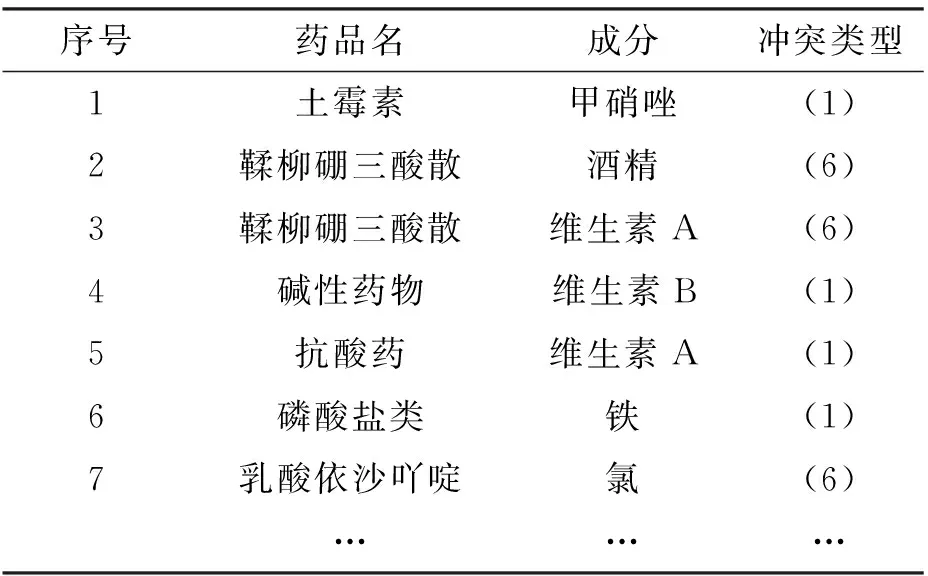
表2 药品与成份C-sheet2冲突表

表3 药品与类别C-sheet3冲突表

表4 药品与药品C-sheet4冲突表
4.2 冲突知识库构建算法
在冲突知识库构建之前,首先要进行基础数据库的构建,包括:
1) 药品成份库DELib的构建。扫描药品数据源,对每个药品成份属性的药品成份术语进行逐一提取,添加到DELib中,同时进行消除冗余和编码;
2) 药品类别库DCLib的构建。扫描药品数据源,对每个药品作用类别属性中的药品类别进行提取,添加到DCLib中,同时进行消除冗余和编码,提取完毕按照药品类别建立索引;
3) 药品编码库DenLib的构建。对每个药品编码,记录药品名称,查询药品成份库DELib完成药品成份编码的添加,查询药品类别库DCLib以标注药品所属的类别码。
在建立好等三个基础数据库后,即可进行冲突知识库的构建,冲突知识库构建算法见算法1。
算法1:冲突知识库构建算法
输入:药品的相互作用(Drug Interaction)文本
输出:根据获取的冲突规则加入相应的冲突表
1:i=1;
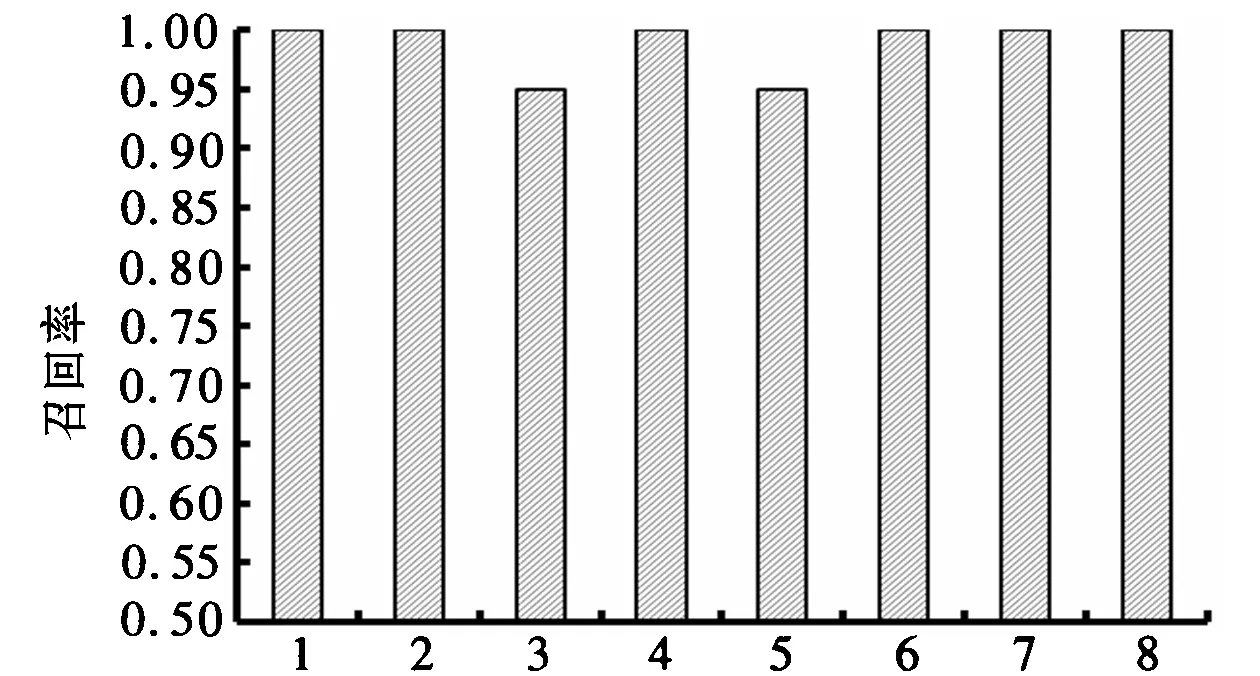
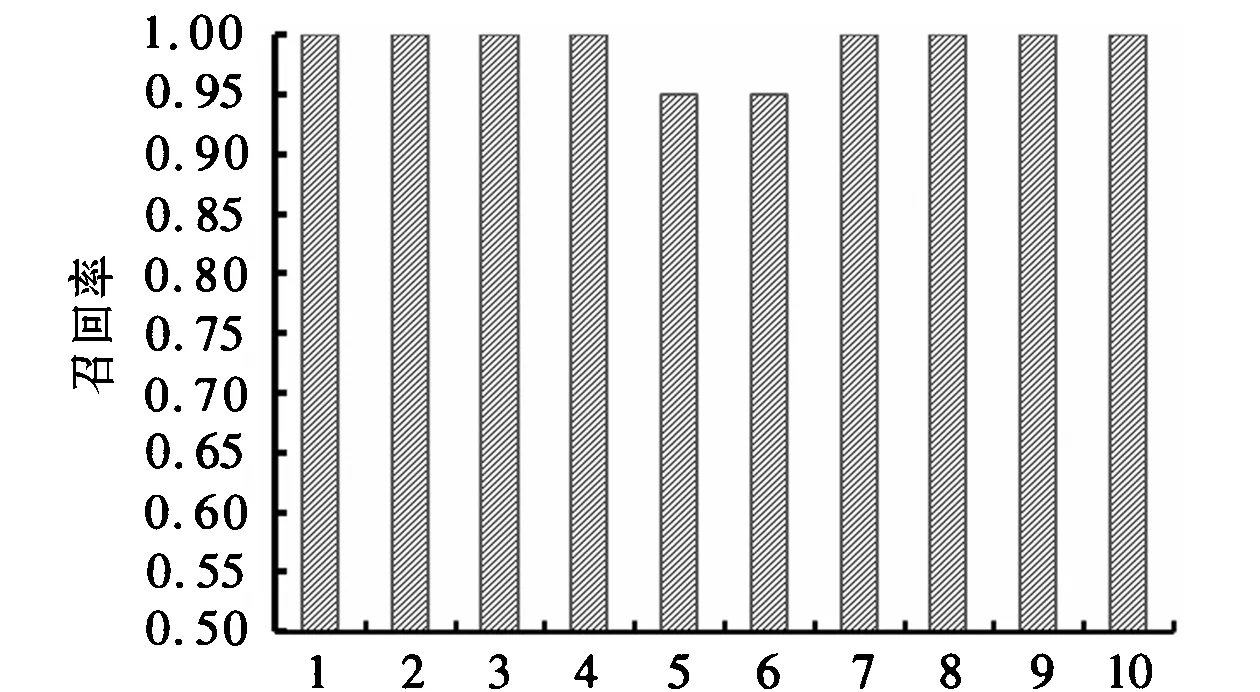
2: while (i 3: 取第i个药品的相互作用文本; 4:对该文本利用动态窗口分割方法进行逐条提取,获得冲突规则的前键、后键和冲突类型; 5:查询药品成份库DELib和药品编码库DenLib确定前键是药品成份还是药品名; 6:查询药品类别库DCLib、药品编码库DenLib和药品成份库DELib确定后键的类型; 7:if 前键是成份,后键也是成份,将该条冲突规则加入冲突表C-sheet1; 8:if 前键是药品,后键是成份,将该条冲突规则加入冲突表C-sheet2; 9:if 前键是药品,后键也是类别,将该条冲突规则加入冲突表C-sheet3; 10:if 前键是药品,后键也是药品,将该条冲突规则加入冲突表C-sheet4; 11:i++; 12:endwhile 在冲突知识库构建算法的执行过程中,需要查询三个基础数据库,即药品成份库DELib、药品类别库DCLib和药品编码库DenLib,为了提高查询速度,三个基础数据库提前建立索引。另外,在第6步查询后键类型时,考虑后键的数量,如果后键数量为较小(<=2),则查询优先次序为药品类别库DCLib、药品编码库DenLib和药品成份库DELib;反之查询的优先次序为药品成份库DELib、药品编码库DenLib和药品类别库DCLib。 冲突检测算法的设计是以用户的需求为前提。通常用户只关心某种药品和其他一种或几种药品是否存在配伍禁忌,而不是查看与某种药品存在冲突的所有药品列表。从认知角度来说,如果系统列出与某种药品存在冲突的所有列表,反而会到导致用户混乱。因此,冲突检测算法接受的输入是至少2种药品的名称,且以一个药品为主线,检查发现其他药品与该药品是否存在冲突。冲突检测算法的过程见算法2。 算法2:药品冲突检测算法 输入:药品name0和name1,…,namej 输出:与药品有冲突药品名称和冲突类型 1:i=0;Set=φ; 2:while (i≤j) 3:查询DenLib库,获取输入药品的name-IDi; 4:Set=Set∪name-IDi;i++; 5:endwhile 6:i=1;num=0; 7: while (i≤j) 8:以name-ID0为前键,以name-IDi为后键查询C-sheet4; 9:if存在符合条件的冲突规则 then 输出name0和namei以及冲突类型;num++;Set=Set-name-IDi 10:i++ 11:endwhile 12:if (num=j) goto 27; 13:while (Set≠φ) 14:从Set取一个name-IDi; 15:在药品编码库DenLib查询name-IDi的类别cat-IDi; 16:以name-ID0为前键,以cat-IDi为后键查询C-sheet3; 17:if存在冲突规则 then 输出name0和namei以及冲突类型;num++;Set=Set-name-IDi; 18:else在药品编码库DenLib查询name-IDi的成份ele-IDseti; 19:以name-ID0为前键,以ele-IDseti中的成份为后键查询C-sheet2; 20:if存在冲突规则 then 输出name0和namei以及冲突类型;num++;Set=Set-name-IDi; 21:else在药品编码库DenLib查询name-ID0的成份ele-IDsetx; 22:以ele-IDsetx中的成份为前键,以ele-IDseti中的成份为后键查询C-sheet1; 23:if存在冲突规则 then 输出name0和namei以及冲突类型;num++;Set=Set-name-IDi; 24:elseSet=Set-name-IDi; 25:endwhile; 26:输出冲突个数num; 27:end 冲突检测算法说明: 1) 第一个循环,即step2-step5,实现在DenLib库中快速查询输入药品name0编码name-ID0,查询name1,…,namej的编码name-IDi,并将之加入集合中。 2) 第二个循环,即step7-step11,实现在C-sheet4冲突表中快速查询name0与name1,…,namej的每个药品是否存在冲突。如果存在输出该冲突的前键、后键和冲突类型。 3) 第三个循环,即step13-step25。如果第二个循环已经发现j个冲突,则第三个将不再执行。相反,如果第二个循环发现冲突的个数小于j个,则需要执行该循环,依次查询C-sheet3、C-sheet2、C-sheet1,以期发现是否存在药品与药品类别、药品与药品成份、药品成份与药品成份等类型的冲突。如果存在,则以Crules4的输出该冲突, 并更新C-sheet4。 需要进一步说明的是: 采用多个措施提高算法的执行效率。包括DenLib库的索引技术、冲突知识库倒查(即依次查询C-sheet4、C-sheet3、C-sheet2、C-sheet1,如果满足查询要求算法提前结束);冲突知识库的自我更新机制。直接通过药品说明书建立的冲突表C-sheet4是不完整的,在用户查询使用的过程中,根据查询C-sheet3、C-sheet2、C-sheet1会逐渐发现一些新的药品与药品之间的冲突,来不断更新补充C-sheet4。 6.1 实验方法 为了验证药品作用冲突检测模型的效果,本文将从两个角度验证模型的准确性。 1) 从成份冲突角度进行药品冲突查询验证。选择一种药品成份ele-Term0及与其冲突的几种成份ele-Termi,计算包含成份ele-Termi的各种药品的召回率。 2) 从药品冲突的角度进行药品冲突查询验证。选择一类药品成份cat-Term0的多种药品namei,分别计算与namei药品存在冲突的各种药品的召回率。 6.2 实验分析 根据6.1节的实验方法,进行3组实验: 1) 第1组实验。选择的药品成份为双唑泰棉栓中“氯己定”,选择与该成份存在冲突的8种成份。分别计算包含每种冲突成份的所有药品的召回率,实验结果如图5所示。 8种药品冲突成份1. 碘化钾;2. 硼砂;3. 碳酸氢盐;4. 碳酸盐;5. 氧化物;6. 枸橼酸盐;7. 磷酸盐;8. 硫酸盐图5 包含冲突成份的药品召回率 2) 第2组实验。选择的药品类别为“青霉素类”,包含的10种药品。这10种药品中每一种药品存在冲突的所有药品的召回率,实验结果如图6所示。 10种药品冲突成份1. 青霉素钠;2. 阿洛西林;3. 阿莫西林;4. 美洛西林;5. 哌拉西林他唑巴坦;6. 呋布西林;7. 氟氯西林;8. 替卡西林克拉维酸钾;9. 亚胺培南;10. 美洛培南图6 与10种青霉素类药品有冲突的药品召回率 3) 第3组实验。选择的药品类别为“头孢菌素”,包含的12种药品。这12种药品中每一种药品存在冲突的所有药品的召回率,实验结果如图7所示。 12种药品冲突成份1. 头孢曲松钠;2. 头孢尼西;3. 头孢噻吩;4. 头孢噻肟;5. 头孢哌酮;6. 头孢甲肟;7. 头孢西丁钠;8. 头孢替安;9. 头孢硫脒;10. 头孢美唑;11. 头孢唑肟;12. 头孢吡肟图7 与12种头孢菌素类药品有冲突的药品召回率 从图5~图7可以看出,3组实验均保持较高的召回率(>0.95),即无论从成份冲突的角度进行药品冲突的查询,还是从药品冲突的角度进行药品冲突检测,基于术语提取的药品作用冲突检测模型均保持较高的召回率。 药品作用冲突检测可有效减轻医师和患者在面对海量医药数据环境下的巨大认知负担。基于术语提取的药品作用冲突检测模型是将自然语言处理和信息检索技术应用到医学领域中,便于用户智能、合理、健康地用药。本文主要贡献包括以下几个方面。 1) 有效进行了药品术语的提取。利用NLPIR汉语分词系统,结合动态窗口分割的术语提取方法,在扩充用户词典和更新废词库的基础上,实现了药品成份术语和类别术语的有效提取。 2) 成功构建了药品冲突知识库。在构建药品成份库、药品类别库和药品编码库的基础上,定义了8种类型的冲突类型和4种类型的冲突规则,进而提出了药品冲突知识库的构建算法。 3) 有效实现了药品冲突的检测。在药品冲突知识库构建的基础上,设计了药品冲突检测算法。算法采用倒查技术提高冲突检测过程的执行效率,同时,算法的执行能对冲突知识库进行更新和补充。 [1] 何红梅.药物相互作用速查表[M].北京:中国医药科技出版社, 2012:1-10. [2] 刘治军,付得兴,孙春华,等. 体内药物相互作用研究进展[J]. 药物不良反应杂志,2006:8(1):1-6. [3] L MILLER,KS PATER,S CORMAN.The role of clinical decision support in pharmacist response to drug-interaction alerts. Research in Social & Administrative Pharmacy, 2014, 11(3):480-486. [4] 彭婷婷,王慧, 石亚伟. 荧光双分子互补分析Ezrin与L-periaxin的互作模式[J]. 中国生物化学与分子生物学报, 2015, 31(1):38-46. [5] 秦飞, 姚鑫. 环糊精固载量不同的壳聚糖药物载体合成及性能[J]. 中国科学院大学学报, 2015, 32(1):51-56. [6] 叶林虎. 荷叶代谢性药物相互作用及体内成分研究[D].北京协和医学院,2014. [7] 张海鸣,闫寒,彭娟,等. 脂质体平衡透析-液质联用色谱法筛选四物汤药效物质的研究[J]. 药物分析杂志, 2014,34(12): 2 107-2 111. [8] P ZHANG,L DU,L WANG.A Mixture Dose—Response Model for Identifying High-Dimensional Drug Interaction Effects on Myopathy Using Electronic Medical Record Databases[J]. Cpt Pharmacometrics & Systems Pharmacology, 2015, 4(8):474-480. [9] 闫兴龙,刘奕群,方奇,等. 基于网络资源与用户行为信息的领域术语提取[J]. 软件学报, 2013, 24(9):2 089-2 100. [10] 李江华,时鹏,胡长军. 一种适用于复合术语的本体概念学习方法[J]. 计算机科学,2013, 40(5):168-172. [11] 罗准辰,王挺. 基于分离模型的中文关键词提取算法研究. 中文信息学报,2009,23(1):63-70. [12] SHUNXIANG ZHANG, YANYONG DU, KUI LU.A Dynamic Window Split-Based Approach for Extracting Professional Terms from Chinese Courses[J]. International Journal of Computational Science and Engineering, 2016,12(4):341-350. (责任编辑:李 丽) An Automatic Detection Model for Drug Interaction Conflict Based on Term Extraction ZHANG Shun-xiang, ZHANG Shi-yao ,WANG Yin (School of Computer Science and Engineering ,Anhui Univercity of Science and Technology,Huainan Anhui 232001,China) The automatic detection for Drug Interaction Conflict (DIC) is an information searching technology which can quickly find the conflict relationships among some drugs. It can effectively decrease the huge cognitive burden for some people such as physicians and patients etc. The main task of identifying DIC is analyzing and establishing the knowledge rules of conflict among drugs, and realizing the deep detection of DIC. The drug information is used as the basic semantic unit in this task. This paper proposed an automatic detection model for DIC which includes four progressive levels. That is, the preprocess of data source, term extraction, the construction of knowledge base of drug conflict and the automatic detection for DIC. Experimental results show that the proposed model is of high accuracy. crug interaction conflict; term extraction; knowledge base of drug conflict; automatic detection 安徽省教育厅自然科学基金资助项目(KJ2015A111);上海市信息安全综合管理技术研究重点实验室基金资助项目(AGK2013002) 张顺香(1970-),男,安徽无为人,副教授,博士,研究方向:语义Web,信息检索与信息提取。 TP391 A 1672-1098(2016)05-0046-085 冲突检测算法
6 实验

7 结论
