计算机图形处理器加速的光学航空影像正射校正
2016-12-19全吉成王宏伟
全吉成,王 平,王宏伟
(空军航空大学 航空航天情报系,吉林 长春 130022)
计算机图形处理器加速的光学航空影像正射校正
全吉成,王 平*,王宏伟
(空军航空大学 航空航天情报系,吉林 长春 130022)
提出了计算机图形处理器(GPU)加速的光学航空影像正射校正并行算法,以满足获取光学航空影像对实时性的要求并提高对海量影像数据在CPU上串行正射校正的效率。介绍了光学影像正射校正算法原理以及正射校正算法的并行化处理。为减少GPU执行的计算负载,引入“有效像素区域”概念,设计了改进的GPU并行校正算法。通过配置选择以及存储器访问优化进一步提高了算法的执行效率。最后,分析了GPU并行算法的精度,并验证了噪声干扰对算法的影响。实验结果表明,优化的改进GPU并行算法显著提高了正射校正的速度,影像大小为5 000×5 000时,加速比最高可达CPU串行算法的223倍以上。虽然GPU单精度计算和噪声干扰会使影像校正精度有所下降,但尚在误差允许范围之内。该算法能够快速实现光学航空影像的正射校正,校正后的影像满足实际应用需要。
航空影像;正射校正;计算机图形处理器(GPU);并行算法;有效像素区域
1 引 言
在应急救灾,军事侦察以及环境监测等应用领域,航空摄影为及时、准确地获取数据信息发挥着重要的作用。在影像成像过程中,由于受地形起伏,地球曲率等因素的影响,原始影像各像素将产生不同程度的几何畸变,因此需要对航空影像进行正射校正。随着航空光学影像分辨率和数据量的增加,针对单个像元的正射校正计算量也急剧增多,导致传统的串行处理难以满足影像实时处理的要求[1]。
近年来,计算机图形处理器(Graphics Processing Unit,GPU)以超过摩尔定律的速度在不断更新,在通用计算领域已取得了长足发展[2]。2007年,NVIDIA公司提出了统一设备计算架构(Compute Unified Device Architecture, CUDA)[3]。作为一种新的编程模型,CUDA采用了类C语言的软件开发环境。CUDA核心具有单指令多数据流的特性,用来加速的算法涉及领域[4-7]非常广泛,其中包括一些图形图像处理算法的加速。例如国外学者将图像处理器应用到加速图像去噪[8]和可视化[9]算法中;国内,李仕等利用图像处理器加速实现模糊视频图像的实时恢复[10]、航空成像的位移补偿[11]以及航空斜视成像异速像移的实时恢复[12]等算法。
目前,不少学者[13-14]将GPU引入到影像的正射校正中,大大加快了影像处理的速度。文献[15]利用GPU加速了航拍影像数据的正射校正,达到了实时处理。但该方法采用了OpenGL传统编程方式,实现比较复杂。文献[16]利用CUDA并行处理几何校正,实现了UAV拍摄影像数据的快速处理,与CPU性能相比,加速比最大可达12倍以上。文献[3]使用了“层次性分块”策略设计了CPU和GPU协同处理的正射校正模式,通过配置优化和存储层次性访问提高了校正效率,处理时间压缩至了5 s以内。
为了快速实现影像的正射校正,本文采用划分“有效数据区域”的方法来减少计算量,并且针对GPU架构特点进行性能优化,充分利用GPU强大的并行处理和浮点运算能力,提高影像几何校正的效率。
2 正射校正算法原理及其并行化
2.1 正射校正算法原理
根据成像时设备记录的摄影参数,基于共线方程建立影像坐标与地物坐标之间的对应关系,进而对影像进行正射校正。其中共线方程分为正解和反解形式[17],分别为:
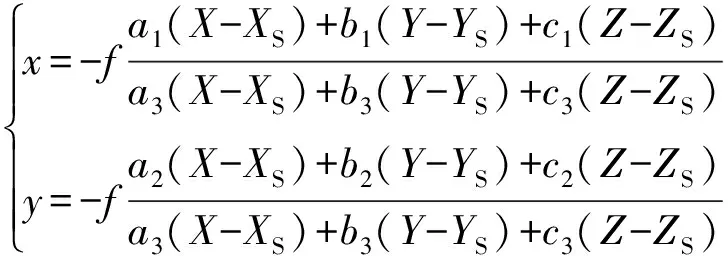
(1)
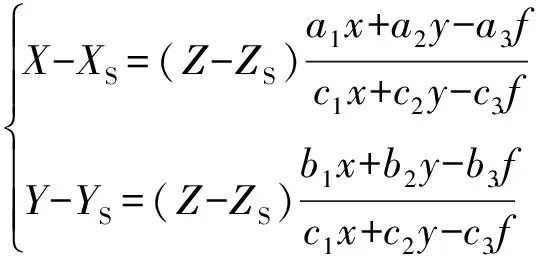
(2)
式中:(x,y)为像点在像平面坐标系中的坐标,(X,Y,Z)为对应地面点在物空间坐标系中的坐标,(XS,YS,ZS)为摄站在物空间坐标系中的坐标,(ai,bi,ci)为图像的外方位元素确定的旋转矩阵的9个元素(3个为独立元素)。
以投影中心为原点,x,y轴与像平面坐标系的x,y轴平行,z轴与主光轴重合,建立像空间坐标系,以大地空间直角坐标系作为物空间坐标系。利用摄影参数以及大地测量相关公式计算物像坐标系之间的旋转矩阵,代入共线方程中。将原始影像4个角点的坐标,代入式(2),求得原始影像在物空间坐标系中的覆盖范围,即纠正后影像的范围。然后利用正射校正的间接法方案,对纠正后影像的每个像素代入式(1)求得对应像点在像空间坐标系中坐标,同时,在原始影像上进行灰度值内插并赋予纠正影像空间的像素[18]。
2.2 正射校正算法的并行化
正射校正算法是对图像中单个像素的操作,物像空间坐标的转换以及灰度值内插、赋值都是逐个像素完成的,且各个像素之间没有相关性,计算量大,因此非常适合映射到GPU中进行处理。
GPU中的线程是按照线程网格和线程块的形式进行组织的。常规的GPU正射校正并行化一般将整个纠正后的影像映射到线程网格上,再将纠正后影像逻辑分块,使每一块与线程块的大小一致,保证线程块的每个线程对影像分块中的每一个像素进行处理[3],如图1所示。
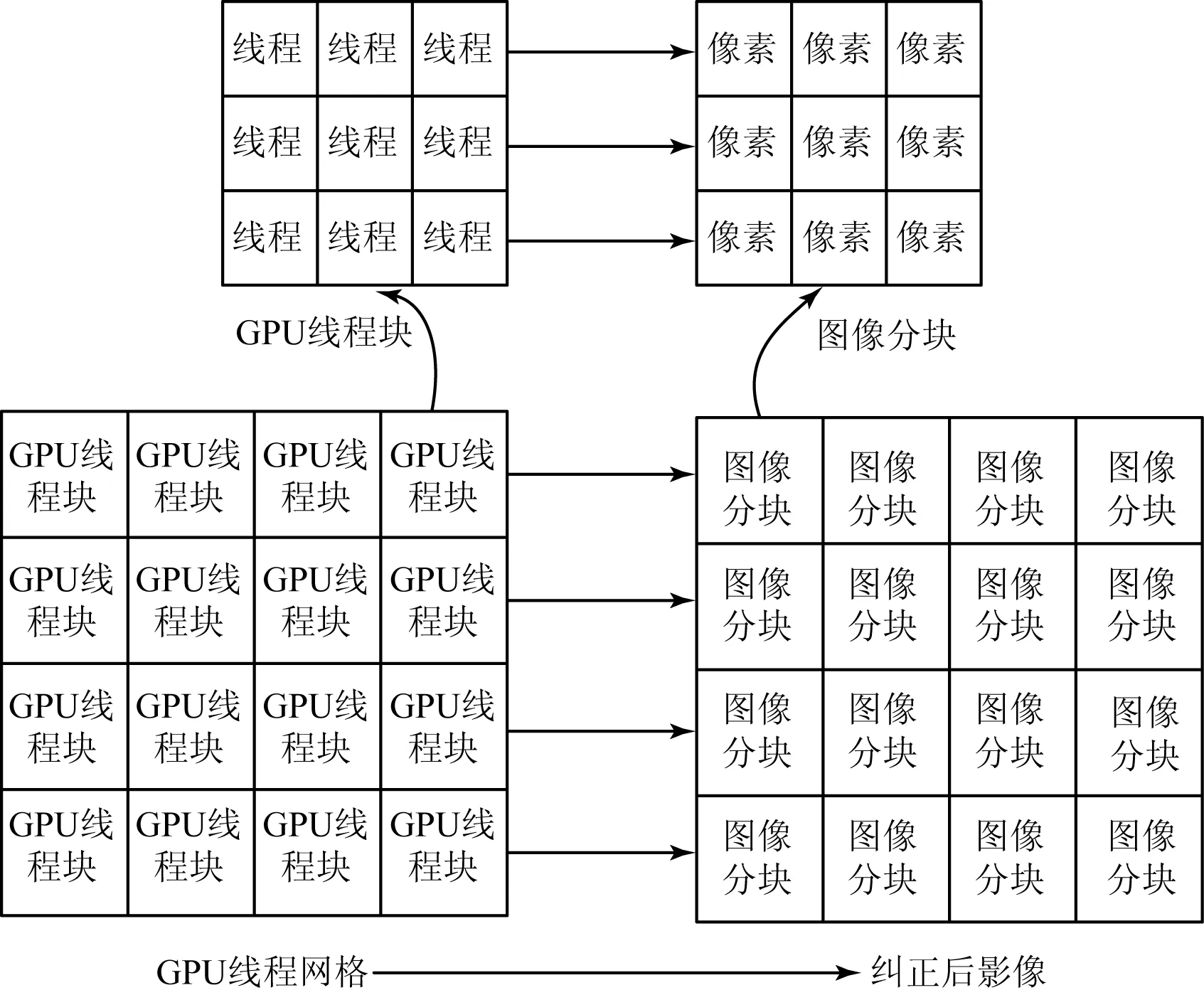
图1 常规的GPU正射校正并行化映射
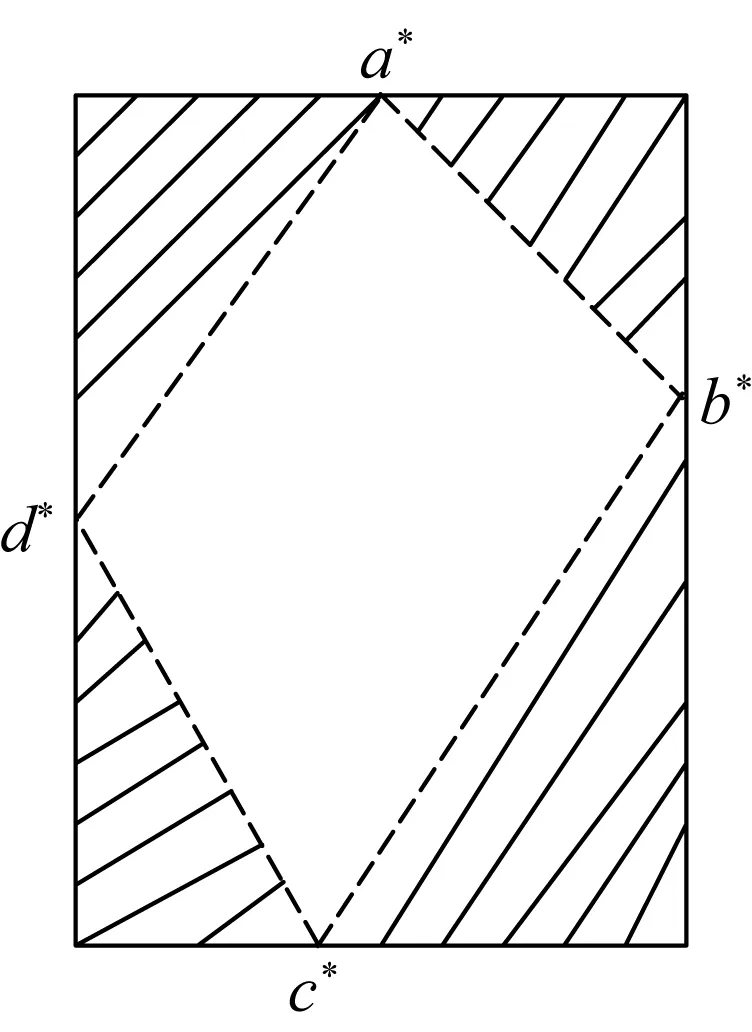
图2给出了原始影像与纠正后影像的对应关系,将对应位置在原始影像范围内的纠正影像像素称为有效像素。在坐标转换和重采样过程中只需计算有效像素的灰度值,其余像素赋值为零。常规GPU正射校正并行处理不考虑有效像素,而是将纠正影像的每个像素都进行计算,故增加了GPU的工作量。

(a)原始影像
(b)纠正后影像
Fig.2 Mapping relationship between original image and corrected image
本文将考虑纠正后影像的有效像素,将改进后并行算法映射到GPU中,减少GPU的负载,从而降低影像纠正的处理时间。
3 改进的正射校正算法及其并行化
3.1 算法描述
改进的正射校正算法通过正射校正直接法计算出有效像素区域,即通过计算图2中原始影像的4个角点a,b,c,d,得出纠正影像的点a*,b*,c*,d*,利用4条线段a*b*,b*c*,c*d*,d*a*即可确定有效像素区域的边界。通过每条扫描线与4个线段的交点,可以得出有效像素区域每一行像素的起始点和结束点。
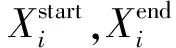
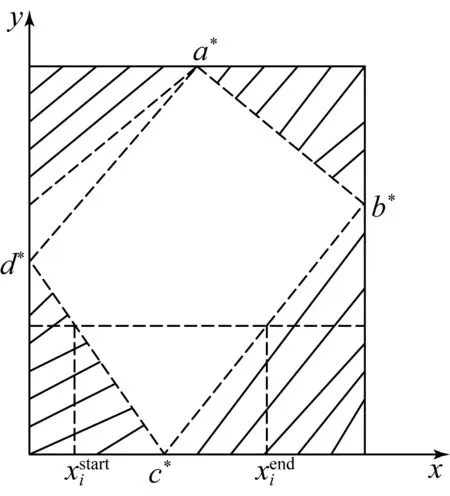
图3 有效像素区域边界的求解过程
3.2 改进算法的并行化
3.2.1 粗粒度并行化分析
纠正影像的每一行都有各自的有效像素区域的起始点和结束点,且各行之间不相干。每行之间可以同时进行处理,因此非常适合用线程块实现粗粒度并行。如图4所示,将每一行像素与一维线程块Block建立映射关系,由每个线程块的索引号blockIdx.x对应纠正影像的行号。
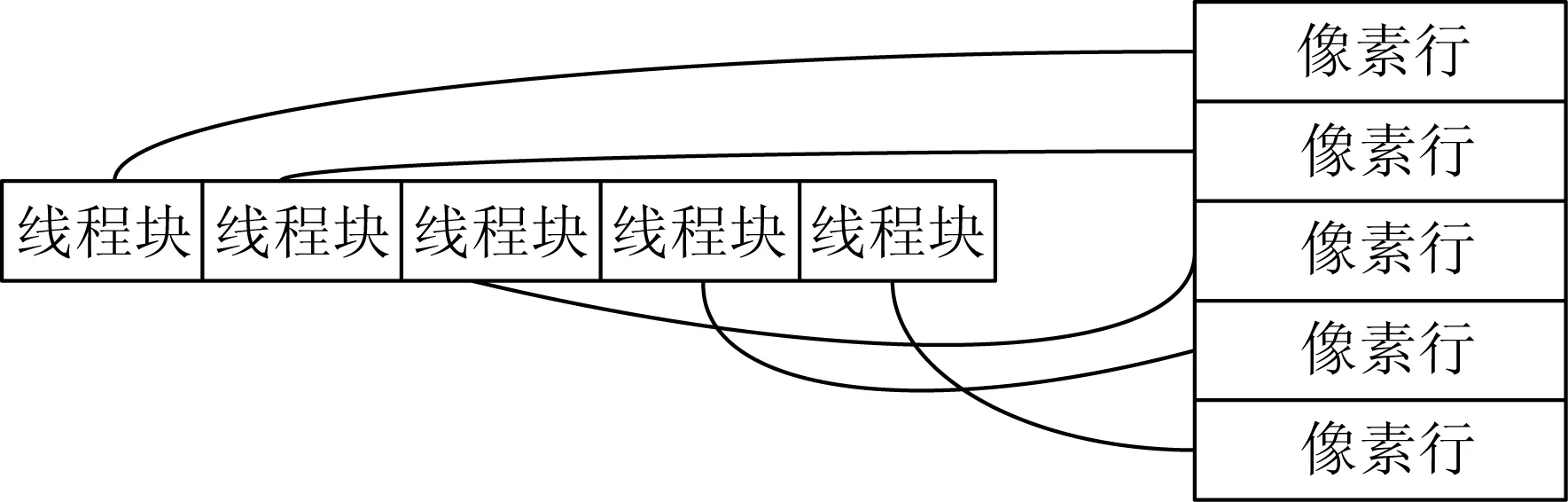
图4 改进的GPU正射校正粗粒度并行化映射
3.2.2 细粒度并行化分析
线程块中的线程以线程束warp的形式在多处理器上运行,各个线程映射到标量处理器核心。如图5所示,线程块Block的每一个线程映射到纠正影像对应行的一个像素点,实现对像素的并行处理,实现线程间的细粒度并行化。
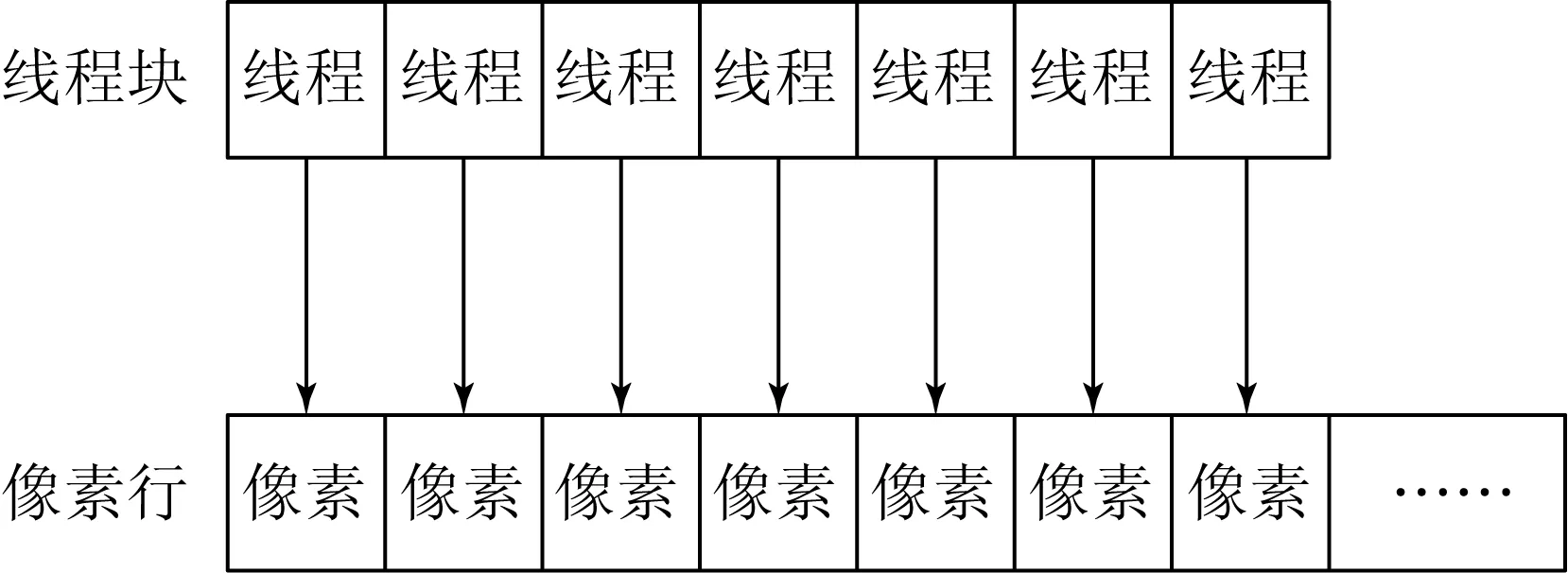
图5 改进的GPU正射校正细粒度并行化映射
4 改进的GPU算法优化加速
4.1 执行配置选择
GPU进行核函数计算时,都要对线程网格和线程块的大小进行配置。线程网格内的多个线程块以任意顺序独立执行,线程块中线程以warp为单位在流多处理器调度运行。线程块网格和线程块的大小设置,需考虑以下几个限制:①线程块中线程数小于1 024。②流多处理器中线程块数量小于8。③流式多处理器中线程数小于1 536。为了有效隐藏延长,应至少满足active warps≥6,active blocks≥2[19]。
正射校正算法中选择一维线程块Block处理一行像素,大小为256=8 warps>6 warps,同时1 536/256=6>2,这样一个流多处理器可以同时投入6个线程块,1 536个线程,调度性能最优,能很好地隐藏计算延迟。由于线程块小于纠正影像一行的像素个数,因此每个线程通过线程索引threadIdx.x加threadDim.x进行循环迭代计算,直至一行所有像素计算完。
线程网格大小一般由问题的规模和处理方式决定,不能小于流多处理数量的2倍。在本文并行算法中,线程网格配置为一维的线程网格,大小为纠正影像的行数,远远大于流多处理器数量的2倍。
4.2 存储器优化
GPU线程在运行过程中可以访问设备中多种存储器,不同存储空间的访问延迟周期不同,因此如何改进计算访问比和各存储层次的延迟隐藏是存储优化的核心[20]。
4.2.1 共享存储器访问优化
每个线程块都对应一个共享存储器且对块内所有线程可见,块内线程可通过共享存储器进行通信。共享内存提供了快速的读写速度,在无存储体冲突时访存速度在4个时钟周期以内,而全局存储器访问延迟为400~600个时钟周期。所以将全局内存中数据读入到共享内存中可大大提高核函数的执行速度。
并行算法将有效区域边界数组ValidPixel[height][2]读取到共享存储器,当索引号为blockIdx.x的线程块中的线程索引与ValidPixel[i][0]、ValidPixel[i][1]比较时,无需重复访问全局内存,造成效率低下。当warp内线程同时对共享内存同一地址ValidPixel[i][0]或ValidPixel[i][1]发出读请求时,可被广播到所有线程中。
4.2.2 常量存储器访问优化
常量存储器是GPU设备中的只读存储器,存储空间为64 kB,同时含有8 kB的cache,访问速度远远快于全局内存。当half-warp都需要相同的读取请求时,读取操作会广播到half-warp中的所有线程中。此外,线程通过从常量内存缓存中读取数据,这也加快了访问速度。
在正射校正并行算法中,物空间坐标系和像空间坐标系的变换参数在每个像素点进行坐标变换时都会使用到,而且在计算过程中不会变化。因此将物、像空间坐标系的变换参数放入只读常量存储器中可以提高核函数的执行效率。
5 实验结果与分析
本文实验用CPU型号为AMD Athlon(tm) Ⅱ 640,4核处理器,主频3.0 GHz,内存为10.0 G;GPU为Fermi架构的 NVIDIA GTX580,16个流多处理器,512颗计算核心,1.5 G的全局存储器。
本文从一次拍摄任务完成后的所有航空光学影像中随机选取10张摄影参数相同的航空几何畸变影像(3波段),每张影像经过重采样仿真出大小分别为1 000×1 000、2 000×2 000、3 000×3 000、4 096×4 096、5 000×5 000的航空影像,从而得到不同大小的畸变影像各10张,以确保相同大小的畸变影像纠正后的影像大小完全相同。
5.1 效率分析
对相同大小的10张畸变影像,分别采用基于CPU、常规GPU并行算法、改进GPU并行算法进行正射校正处理(重采样分别采用最近邻插值法、双线性插值法、双三次插值法)。取10次运行结果的平均值作为相同大小影像正射校正的处理时间,实验结果如表1、表2所示。
表1 在实验环境下CPU和常规GPU算法正射校正所用时间对比
Tab.1 Comparison of orthorectification times between CPU and conventional GPU algorithm in experimental environment
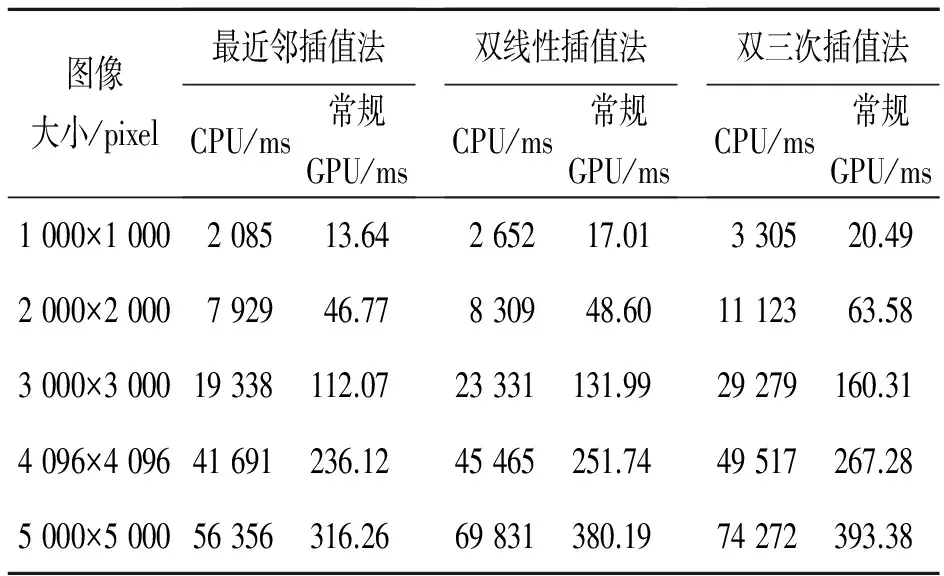
图像大小/pixel最近邻插值法CPU/ms常规GPU/ms双线性插值法CPU/ms常规GPU/ms双三次插值法CPU/ms常规GPU/ms1000×1000208513.64265217.01330520.492000×2000792946.77830948.601112363.583000×300019338112.0723331131.9929279160.314096×409641691236.1245465251.7449517267.285000×500056356316.2669831380.1974272393.38
表2 在实验环境下CPU和改进GPU算法正射校正所用时间对比
Tab.2 Comparison of orthorectification times between CPU and improved GPU algorithm in experimental environment
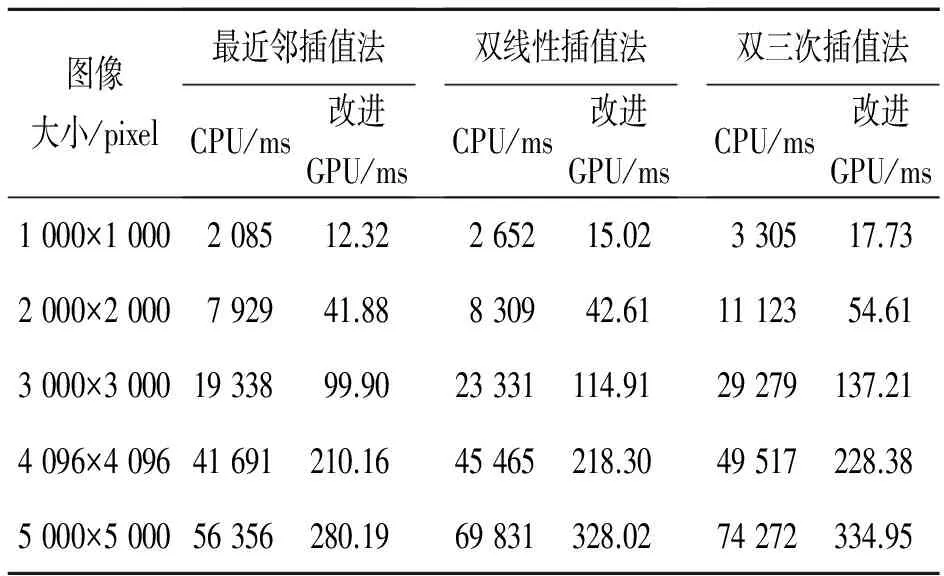
图像大小/pixel最近邻插值法CPU/ms改进GPU/ms双线性插值法CPU/ms改进GPU/ms双三次插值法CPU/ms改进GPU/ms1000×1000208512.32265215.02330517.732000×2000792941.88830942.611112354.613000×30001933899.9023331114.9129279137.214096×409641691210.1645465218.3049517228.385000×500056356280.1969831328.0274272334.95
从表1、表2可以明显看出,使用CPU串行算法进行光学影像正射校正执行时间很长,而使用GPU并行算法(常规算法和改进算法)进行光学影像正射校正执行时间较前者大幅度减小,并且改进的GPU算法的减小幅度更大一些。
为了更好地对算法进行评价,本文使用时间加速比来评价算法的效果。定义如下[21]:
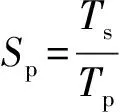
(3)
式中:Ts为表1、2中CPU串行算法进行光学航空影像正射校正的执行时间;Tp为表1、2中GPU并行算法进行光学航空影像正射校正的执行时间(包括CPU和GPU之间数据传输时间);Sp为算法时间加速比。图6、图7分别列出了常规GPU并行算法和改进GPU并行算法分别相对于CPU串行算法正射校正的时间加速比。可以看出:
(1)使用GPU多线程并行算法对影像进行正射校正相对于CPU串行校正加速效果非常明显。常规的GPU并行算法的时间加速比为152.86~188.80倍,改进的GPU并行算法的时间加速比达169.24~221.74倍。
(2)当重采样方法一定时,常规的GPU并行校正算法和改进的GPU并行校正算法的加速比都随着影像的增大而增大。当影像大小为5 000×5 000时,加速比达到了最大。这是由于GPU在进行正射校正时,算法加速比与校正时间成正比[3],因此光学航空影像越大,GPU处理时间越长,时间加速比也就越大。
(3)在影像大小一定的情况下,当使用双三次插值法进行灰度重采样时,算法复杂度最大,GPU并行算法的校正处理时间最长,故算法加速比也最大。相应的,在使用最近邻插值法时GPU并行算法的校正时间最短,算法复杂度最小,算法加速比也就最小。
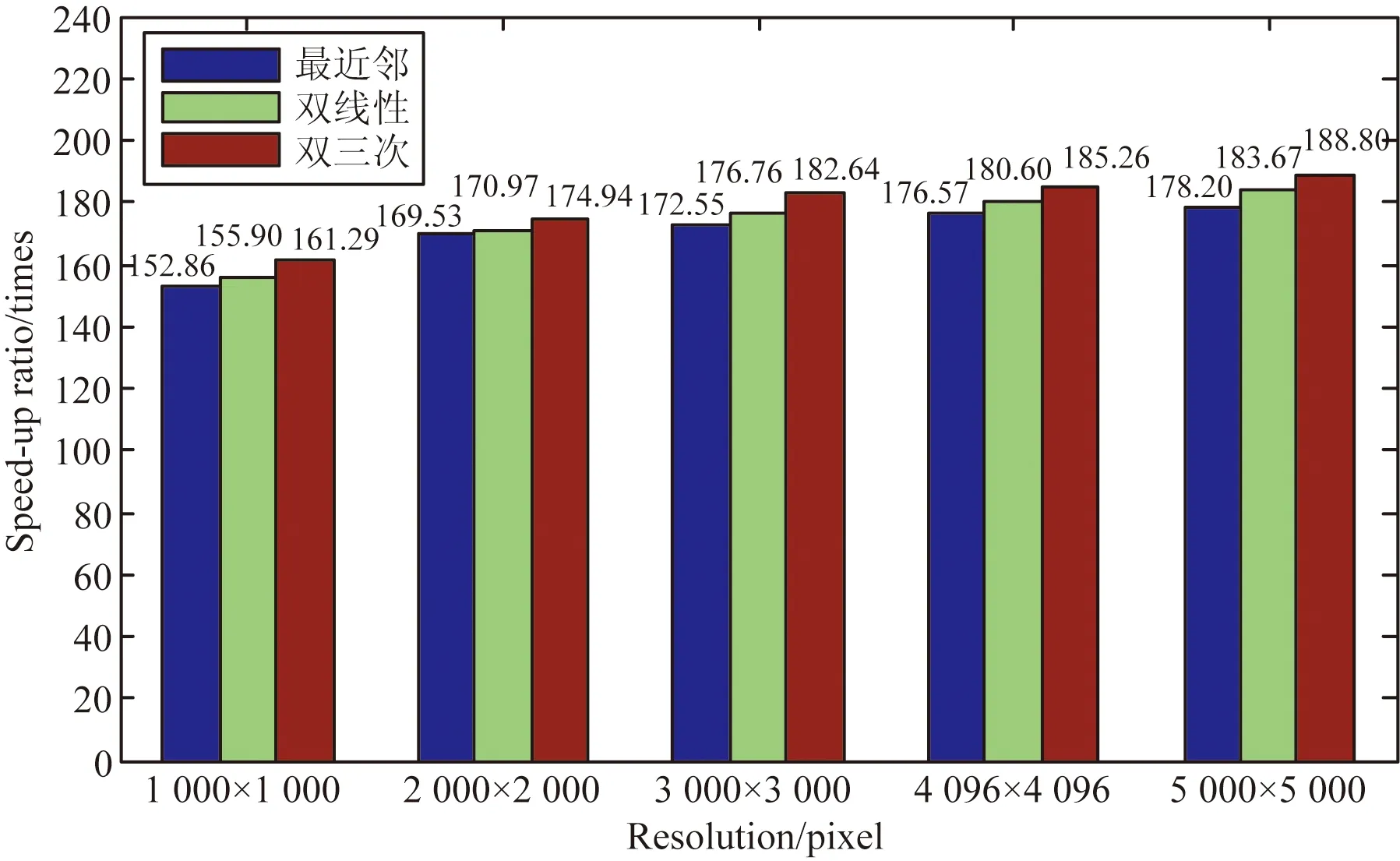
图6 常规GPU并行算法相对CPU串行算法的加速比
Fig.6 Speed-up ratio of conventional GPU parallel algorithm relative to CPU serial algorithm

图7 改进的GPU并行算法相对CPU串行算法的加速比
Fig.7 Speed-up ratio of improved GPU parallel algorithm relative to CPU serial algorithm
将改进的GPU并行算法与常规的GPU并行算法进行比较,定义改进的GPU并行算法的加速比与常规的GPU并行算法的加速比之间的比值为性能提升比,如表3所示。可以看出:
(1)相对于常规的GPU并行校正算法,无论采用何种重采样方式,改进的GPU并行校正算法的性能提升比都大于1,执行效率也得到了提升,从而验证了改进的GPU并行算法的有效性。
(2)由于Fermi架构的GPU内含有L1、L2缓存[22],从而提高了访存速度,另外非有效区域像素占纠正影像全部像素的比例不大,因此改进后的GPU并行算法相对于常规的GPU并行算法性能提升比不是很大,最大没有超过1.2倍。
(3)在影像大小一定的情况下,在3种重采样方式中,双三次插值法的性能提升比最大,最高可达1.17倍以上。
表3 改进GPU并行算法与常规GPU并行算法试验结果比较
Tab.3 Comparison of experimental results of improved GPU parallel algorithm and conventional GPU algorithm
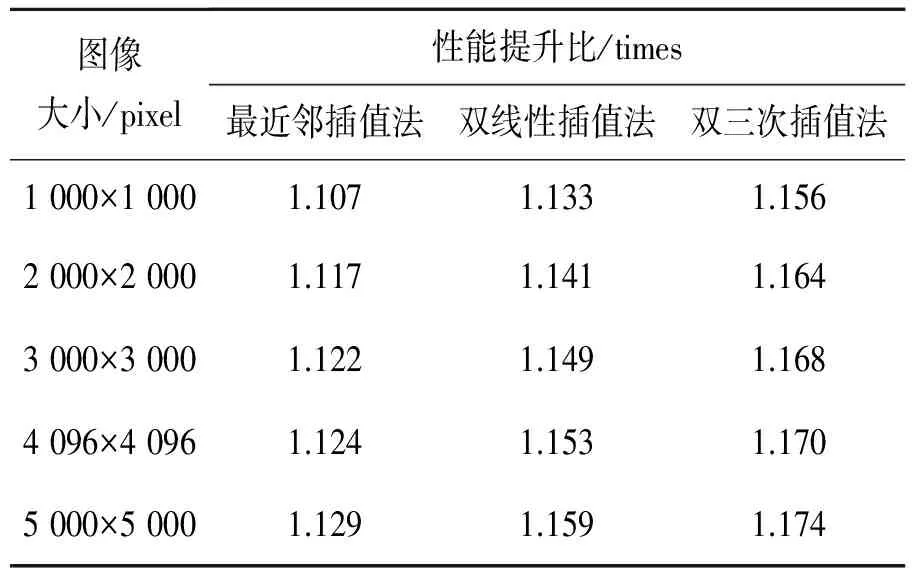
图像大小/pixel性能提升比/times最近邻插值法双线性插值法双三次插值法1000×10001.1071.1331.1562000×20001.1171.1411.1643000×30001.1221.1491.1684096×40961.1241.1531.1705000×50001.1291.1591.174
将改进的GPU并行算法参照第4节进行进一步优化,实验结果如表4所示。
表4 优化的改进GPU并行算法正射校正执行时间
Tab.4 Execution time of optimized GPU-improved parallel algorithm

图像大小/pixel执行时间/ms最近邻插值法双线性插值法双三次插值法1000×100011.7614.3617.032000×200040.9341.7753.683000×300099.12113.49136.134096×4096208.56216.17227.215000×5000277.27326.13332.38
从表4可以看出:无论对于何种重采样方式,优化的改进GPU并行算法的执行时间均进一步减小,相对常规GPU并行算法的性能提升比也得到了进一步提高。
与CPU串行处理方法相比,优化的改进GPU并行算法加速比如图8所示,加速比最大达到了220倍以上,可以满足光学航空影像正射校正的快速处理。
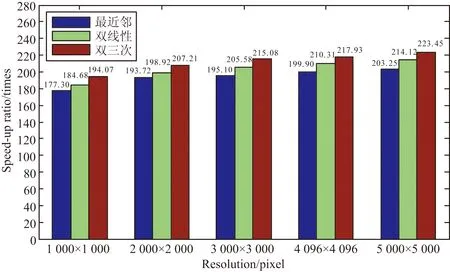
图8 优化的改进GPU算法相对CPU串行算法的加速比
Fig.8 Speed-up ratio of optimized GPU-improved parallel algorithm relative to CPU serial algorithm
5.2 精度分析
为了验证改进GPU并行校正算法的校正精度,将改进GPU并行算法纠正的影像与CPU串行算法纠正的影像相减,得到两者的差值影像,如图9所示。从图中可以看出,改进GPU并行算法和CPU串行算法纠正后的影像中一些区域像素之间存在着灰度值差异。这主要由于改进GPU并行算法进行影像校正时采用的是单精度浮点计算,因此造成GPU并行算法校正的影像校正精度稍微下降,但是这些差异在允许的范围之内,纠正后的影像仍然能够满足实际应用的需要,进而验证了改进的GPU并行校正算法的有效性。

图9 GPU校正影像与CPU校正影像的差值影像
另外本文采用的Fermi架构GPU,具有和CPU一样的双精度浮点数运算能力。为了提高正射校正的精度,可以在GPU并行校正算法中使用双精度浮点运算。通过统计改进GPU并行算法纠正的影像与CPU串行算法纠正的影像之间差值影像的灰度直方图,可以看出两者的影像灰度值完全一致,但是算法的执行效率较单精度下降很多,因为GPU的双精度浮点运算速度只是单精度浮点运算速度的1/10左右,大大降低了影像校正的速度。
5.3 噪声干扰
为了进一步验证噪声对改进GPU并行算法校正几何畸变影像的影响,本文将实验几何畸变影像加入高斯噪声,利用改进GPU并行校正算法进行处理并优化,实验结果如表5所示。
通过对比表4和表5可以看出,改进GPU并行算法的执行时间基本没有变化,噪声对改进GPU并行校正算法的执行效率没有影响,这是因为图像噪声并没有影响几何畸变影像校正的计算量,因此利用改进GPU并行算法进行影像校正的执行时间几乎不变。
表5 优化的改进GPU并行算法对噪声畸变影像正射校正的执行时间
Tab.5 Execution time of noise distortion orthorectification for optimizated GPU-improved parallel algorithm
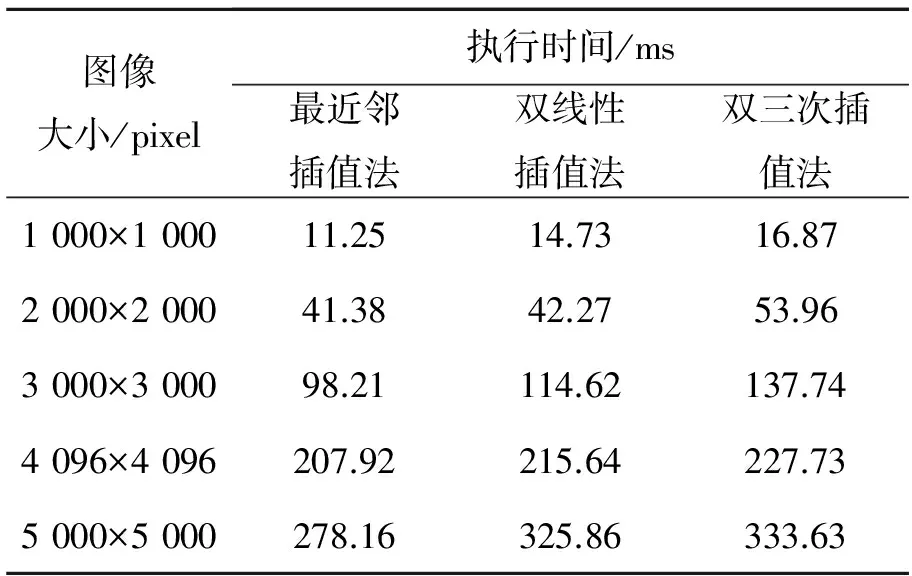
图像大小/pixel执行时间/ms最近邻插值法双线性插值法双三次插值法1000×100011.2514.7316.872000×200041.3842.2753.963000×300098.21114.62137.744096×4096207.92215.64227.735000×5000278.16325.86333.63
将改进GPU并行算法纠正的噪声影像与CPU串行算法纠正的无噪声影像做差,得到了两者的差值影像,可以看出两者存在着很明显的像素灰度值差异,相较图9差值影像的差异更大,说明改进GPU并行算法纠正的噪声影像精度下降很大。这主要由于噪声严重影响了纠正影像重采样的计算结果,因此在对几何畸变影像做正射校正之前需要尽量消除噪声以及其他畸变的干扰。
6 结 论
本文针对光学航空影像获取信息实时性的要求以及海量影像数据在CPU上串行正射校正效率慢的问题,探讨了利用GPU并行算法进行正射校正。首先介绍了正射校正原理,并利用常规GPU并行算法对光学影像进行校正。在此基础上,引入了“有效像素区域”以减少GPU的计算量,设计了改进的GPU并行算法,并且通过配置选择以及存储器优化进一步提高了算法的效率,最后分析了GPU并行算法的精度,并利用噪声图像对GPU并行算法进行验证。实验结果表明:优化后的改进GPU并行算法显著提高了正射校正的速度,相对于CPU串行算法加速比最大达223倍以上,基本能够满足海量影像数据快速校正处理的要求,但是由于算法的单精度计算导致影像校正精度下降,误差在允许范围之内,纠正后的影像仍然能够满足实际应用的需要。
[1] 蒋艳凰,杨学军,易会战.卫星遥感图像并行几何校正算法研究[J].计算机学报,2004,27(7):944-951. JIANG Y H, YANG X J, YI H ZH. Parallel algorithm of geometrical correction for satellite images [J].ChineseJournalofComputer, 2004, 27 (7): 994-951. (in Chinese)
[2] 王海峰,陈庆奎.图形处理器通用计算关键技术研究综述[J].计算机学报,2013,36(4):757-772. WANG H F, CHEN Q K. General purpose computing of graphics processing unit: a survey [J].ChineseJournalofComputer, 2013,36(4):757-772. (in Chinese)
[3] 方留杨,王密,李德仁.CPU和GPU协同处理的光学卫星遥感影像正射校正方法[J].测绘学报,2013,42(5):668-675. FANG L Y, WANG M, LI D R. A CPU-GPU co-processing orthographic rectification approach for optical satellite imagery [J].ActaGeodaeticaetCartographicasinica,2013,42(5):668-675. (in Chinese)
[4] 吴鑫,张建奇,杨琛.Jetson TK1 平台实现快速红外图像背景预测算法[J].红外与激光工程,2015,44(9):2615-2621. WU X, ZHANG J Q,YANG CH. Efficient infrared image background prediction with Jetson TK1 [J].InfraredandLaserEngineering, 2015,44(9):2615-2621. (in Chinese)
[5] 石坤,郝颖明,王明明,等.海面背景红外实时仿真[J]. 红外与激光工程,2012,41(1):25-29. SHI K, HAO Y M,WANG M M,etal.. Real-time simulation method of infrared sea background [J].InfraredandLaserEngineering, 2012,41(1):25-29. (in Chinese)
[6] 朱兵,付飞蚺.基于GPU的虚拟内窥镜场景实时绘制算法[J].液晶与显示,2013,28(1):127-131. ZHU B,FU F R. Real-time rendering algorithm of scene in virtual endoscopy based on GPU [J].ChineseJournalofLiquidCrystalsandDisplays,2013,28(1):127-131. (in Chinese)
[7] 李大禹.基于多GPU的液晶自适应光学波前处理器[J].液晶与显示,2016,31(5):491-496. LI D Y. Liquid crystal adaptive optics wavefront processor based on multi-GPU [J].ChineseJournalofLiquidCrystalsandDisplays, 2016,31(5):491-496. (in Chinese)
[8] GRANATA D, AMATO U, ALFANO B. MRI denoising by nonlocal means on multi-GPU [J].JournalofReal-TimeImageProcessing, 2016:1-11.
[9] HERMANN M, SCHULTZ A C,SCHULTZ T,etal.. Accurate interactive visualization of large deformations and variablility in biomedical image ensembles [J].IEEETransactionsonVisualization&ComputerGraphics, 2016, 22(1): 708-717.
[10] 王晶,李仕.运动模糊视频图像在图形处理器平台上的实时恢复[J].光学 精密程,2010,18(10):2262-2268. WANG J,LI SH.Real-time restoration of motion-blurred video images on GPU [J].Opt.PrecisionEng.,2010, 18(10): 2262-2268. (in Chinese)
[11] 李仕,孙辉,张葆.航空成像像移补偿的并行计算[J].光学 精密工程, 2009, 17(1) : 226-230. LI SH, SUN H, ZHANG B. Parallel restoration for motion-blurred aerial image [J].Opt.PrecisionEng., 2009,17(1): 226-230. (in Chinese)
[12] 李仕,张葆,孙辉.航空斜视成像异速像移的实时恢复[J].光学 精密工程,2009,17(4):895-900. LI SH, ZHANG B, SUN H. Real-time restoration for aerial side-oblique images with different motion rates [J].Opt.PrecisionEng., 2009, 17(4): 895-900. (in Chinese)
[13] 杨靖宇,张永生,李正国,等.遥感影像正射纠正的GPU-CPU协同处理研究[J].武汉大学:信息科学版,2011,36(9):1043-1046. YANG J Y, ZHANG Y SH, LI ZH G,etal.. GPU-CPU cooperate processing of RS image ortho-rectification [J].GeomaticsandInformationScienceofWuhanUniversity, 2011, 36(9): 1043-1046.(in Chinese)
[14] JAVIER R S, MARIA C C, JULIO M H. GPU geocorrection for airborne pushbroom imagers [J].IEEETransactionsonGeoscienceandRemoteSensing, 2012,50(11): 4409-4419.
[15] ULRIKE THOMAS,FRANZ KURZ,RUPERT MULLER,etal.. GPU-Based orthorectification of digital airbororne camera images in real time [J].TheInternationalArchivesofthePhotogrammetry,RemoteSensingandSpatialInformationSciences,2008:589-594.
[16] LIN J, LI Y CH LI D L. The orthorectified technology for UAV aerial remote sensing image based on the Programmable GPU [J].35thInternationalSymposiumonRemoteSensingofEnvironment,2014:1-6.
[17] 李德仁,王树跟,周月琴.摄影测量与遥感概论[M].第2版.北京:测绘出版社,2008. LI D R, WANG SH G, ZH Y Q.AnIntroductiontoPhotogrammetryandRemoteSensing[M]. 2nd ed. Beijing: Surveying and Mapping Press,2008. (in Chinese)
[18] 张祖勋,张剑清.数字摄影测量学[M].武汉:武汉测绘科技大学出版社,1997:218-219. ZHANG Z X,ZHANG J Q.AnIntroductiontoDigitalPhotogrammetry[M]. Wuhan:Wuhan Surveying and Mapping Science Technology University Press, 1997: 218-219. (in Chinese)
[19] NVIDIA Corporation. CUDA Programming Guide 1.0,http://www.nvidia.com,2009(8):11.
[20] 马安国,成玉,唐遇星,等.GPU异构系统中的存储层次和负载均衡策略研究[J].国防科技大学报,2009,31(5):38-43. MA A G,CHENG Y, TANG Y X,etal.. Research on memory hierarchy and load balance strategy in heterogeneous system based on GPU[J].JournalofNationalUniversityDefenseTechnology, 2009,31(5):38-43. (in Chinese)
[21] 邹贤才,李建成,汪海洪,等.OpenMP并行计算在卫星重力数据处理中的应用[J].测绘学报,2010,39(6):636-641. ZOU X C, LI J CH, WANG H H,etal.. Application of parallel computing with OpenMP in data processing for satellite gravity [J].ActaGeodaeticaetCartographicaSinica,2010,39(6):636-641. (in Chinese)
[22] DAGA MAYANK, ASHWIN M AJI FENG WU-CHUN. On the efficacy of a fused CPU+GPU processor for parallel computer [C].Proceedingofthe2011SymposiumonApplicationAcceleratorsinHigh-PerformanceComputing.Knoxvile,TN,USA, 2011:141-149.

全吉成(1960-),男,吉林和龙人,博士,教授,博士生导师,1983年、2011年于空军工程学院分别获得学士、博士学位,主要从事三维可视化技术方面的研究。E-mail: jicheng_quan@126.com

王 平(1991-),男,山东济宁人,硕士研究生,2014年于空军航空大学获得学士学位,主要从事数字图像处理和GPU并行计算的研究。E-mail: wpsdjnws@163.com
(版权所有 未经许可 不得转载)
Orthorectification of optical aerial images by GPU acceleration
QUAN Ji-cheng, WANG Ping*, WANG Hong-wei
(Department of Aeronautic and Astronautic Intelligence,AviationUniversityofAirForce,Changchun130022,China)
An optical aerial image orthorectification parallel algorithm by Graphic Processing Unit(GPU) acceleration was presented to improve the image real-time processing ability and the serial orthorectification efficiency for massive image data on a CPU. The principle of optical image orthorectification algorithm was introduced, and the parallel processing of orthorectification algorithm was described. To reduce the computational load of GPU execution, the concept of “effective pixel region” was introduced and an improved GPU parallel correction algorithm was designed. Then, the efficiency of the algorithm was improved through configuration options and a memory access optimization. Finally, the algorithm precision was analyzed, and impact of the noise on the algorithm was verified. The experimental results show that the optimized improved-GPU parallel algorithm significantly improves the speed of the correction. When the image size is 5 000×5 000, the speed up is 223 times as compared with the CPU serial algorithm. Although the GPU single precision calculation method and noise interference will cause the serious decline of correction precision, it is still in an allowable error range. As a result, the GPU algorithm implements the orthorectification of optical aerial images rapidly and the corrected images satisfy the need of practical applications.
orthorectification; Graphic Processing Unit(GPU); parallel algorithm; effective pixel region
2016-06-13;
2016-08-05.
吉林省自然科学基金资助项目(No.20130101069JC);军内武器装备重点科研计划资助项目(No.KJ2012240)
1004-924X(2016)11-2863-09
P237
A
10.3788/OPE.20162411.2863
*Correspondingauthor,E-mail:wpsdjnws@163.com
