支持实体识别的XML编码方案
2016-12-12李天辉穆宝良
李天辉, 穆宝良
(沈阳师范大学 科信软件学院, 沈阳 110034)
支持实体识别的XML编码方案
李天辉, 穆宝良
(沈阳师范大学 科信软件学院, 沈阳 110034)
提出了XML文档的一种start-end-type(SET)编码方法,SET编码基于起止编码的思想,并把起止编码的三元组(start,end,level)改进为四元组(start,end,level,type),增加了表示XML文档中结点类型的type值。对四元组中的前3个值提出了新的实现算法,而第4个元素type值由前3个元素的值自动计算出来。SET编码不仅可以快速判断出结点之间的祖先/后代、父亲/孩子关系,而且还可以根据type值快速判断出XML文档中各结点的类型。经过实验测试,SET编码不仅具有良好的编码性能,还能根据各结点类型对XML数据进行实体识别,为进一步研究根据实体类型对XML数据进行查询提供条件。
大数据; 起止编码; SET编码; 深度优先遍历; 实体结点
0 引 言
对网络中大量存在的XML数据如何进行高效的查询[1-4]已成为大数据[5]研究的一部分。通常,利用给出的查询路径表达式,在目标XML文档树上进行导航并返回匹配结果。为了求得满足条件约束的匹配结果,必须对祖先/后代或父亲/孩子关系的文档位置关系的进行判断,所以不可避免在XML文档上进行结构连接[6]的计算,查询效率很低。为了提高查询的效率,本文在起止编码的基础上提出了SET编码。SET编码不仅可以快速的判断结点之间的祖先/后代、父亲/孩子关系,而且支持对XML文档结点的类型的识别。
1 相关研究
对XML文档的编码[7],是指按照某种规则对XML文档树中的每一个结点分配唯一的编码,目的是通过任意2个结点的编码,能够直接判断出2个结点之间的结构关系,进而能够高效地支持对XML数据的索引和查询。目前提出的编码主要分为4种常见的方法:区域编码[8]、前缀编码[9]、K分树编码和支持动态更新的编码[10]方法。下面对区域编码和起止编码做简要介绍。
1.1 区域编码
根据文献[7],区域编码采用树的前序遍历和后序遍历的值为树中的结点进行编码,每一个结点赋予了一个二元组(start,end)。这样前序值和后序值就可以唯一确定一个结点及结点间的位置关系。基于这种思想,出现很多区域编码,其中起止编码[11]是最常用的一种编码方式。
1.2 起止编码
起止编码改进了区域编码,采用深度优先遍历XML文档中所有结点,并对每个结点用三元组(start,end,level)表示。用level代表结点在文档树中的层次。
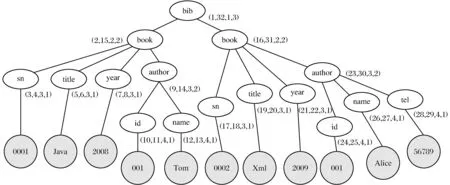
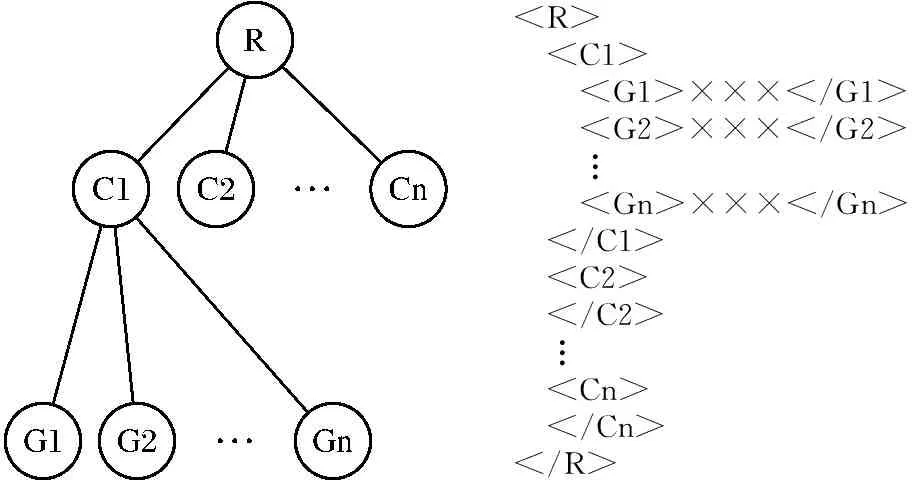
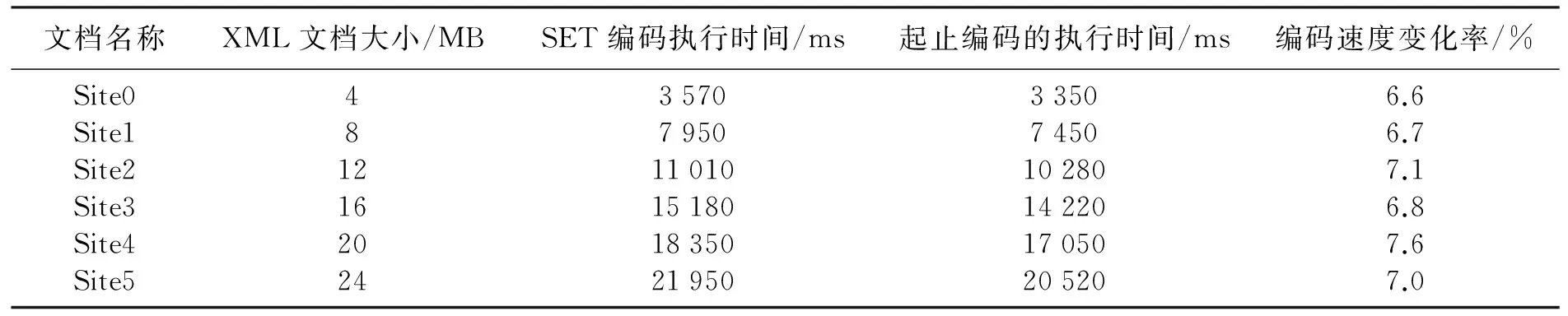
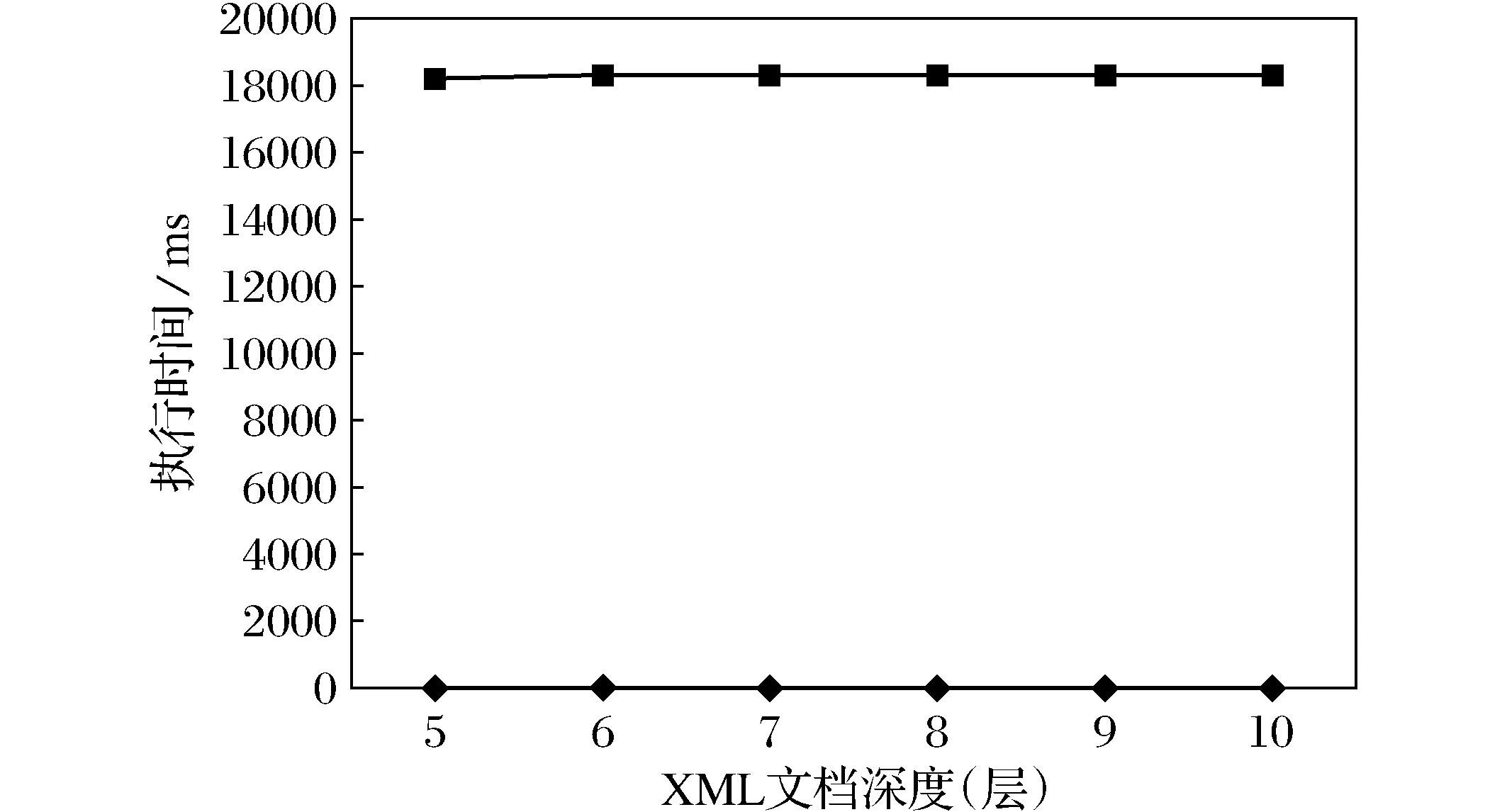
起止编码不仅能很容易判断出文档结点间的位置关系,且还能进一步判断出2个结点之间是否存在父子关系。对于给定的XML文档中的2个结点m、n,其对应的起止编码分别为Cm=(m.start,m.end,m.level)、Cn=(n.start,n.end,n.level),当m.start 2.1 SET(start-end-type Coding)编码方案 为了在查询过程中不但能判断出文档结点间的祖先/后代、父亲/孩子关系,还要能识别出XML文档中各结点的类型,本文提出了对XML文档的SET编码。SET编码是在起止编码的基础上,把起止编码表示结点的三元组(start,end,level)改进为四元组(start,end,level,type),其中第4个元素type代表该结点的类型。根据文献[12-15],结点类型可分为4种:实体结点、属性结点、叶子结点和连接结点。具体定义如下:1)实体结点:DTD中带*的结点或含有多个属性的结点;2)属性结点:只含有一个值结点的结点;3)叶子结点:属性的值结点(叶子结点不做起止编码);4)连接结点:如果一个结点不是实体结点,属性结点,叶子结点即为连接结点。 如图1即为SET编码的文档树(type元素类型的取值:“2”代表实体结点类型,“1”代表属性结点类型,“3”代表连接结点类型)。 图1 图书数据D1的SET编码文档树Fig.1 The SET encoding document tree of Book data D1 2.2 SET编码实现算法 SET编码四元组中前3个元素的编码与起止编码的编码思想基本相同,但本文提出了计算前3个元素值的新算法,而四元组中的type元素值是按照上述XML文档结点分类方法并根据四元组中的前3个编码值计算出来的。 2.2.1 计算SET编码四元组中前2个元素start,end值的新算法 计算SET编码前2个元素值是对XML文档树的深度优先遍历。过程如下:设R是XML文档树的根结点,首先从根结点出发,并对R访问起止编码开始元素start赋值,即R.start=i(i是整数,初值为1,每访问结点1次,i都做自加运算i++)。然后选择一个孩子结点C,然后对孩子结点C进行起止编码开始元素start赋值,即C.start=i+1,然后对孩子的孩子结点G进行访问,开始编码标记G.start=i+1。这样直到访问到没有孩子结点时,对该结点进行回访,并给其编码结束元素end赋值,还是延续原编码开始元组的顺序号递增,即G.end=i+1。此时,再根据同样的规则访问其兄弟结点及其兄弟的孩子结点,也用同样的方法为其编码开始元素start和编码元素end的值顺次递增。如果所有的兄弟结点都访问完毕就回访其父结点,并给父结点的编码结束元素end赋值,再访问父结点的兄弟结点,依此类推,最后回访到根结点R,并对根结点编码结束标记end赋值,即R.end=i。因为每个结点访问2次,所以最后的i值一定是所有结点数的2倍。 在计算SET编码的前2个元素start,end的值时,本文根据遍历XML文档树结点和解析XML文件元素的对应关系,直接对XML文档进行编码。 设XML文档根结点为R,孩子结点为C1,C2,…,Cn,孩子的孩子结点为G1,G2,…,Gn,该文档对应的树模型和XML文档如图2所示。 图2 XML文档的树模型与文档对应图 Fig.2 XML document tree model corresponds to diagram and documentation 如前所述,对XML文档结点的深度优先遍历的起止编码的访问和回访顺序为:R C1 G1 G1* G2 G2* …Gn Gn* C1* C2 C2*…Cn Cn* R*。其中带*的为回访,即代表该结点的起止编码结束。 而对于图2右的XML文档,XML元素标签在文档中的排列顺序为: 2.2.2 计算SET编码四元组中第3个元素level值的实现算法 SET编码的第3元素level值可以按如下方法确定:当程序访问指针读到根结点R时,把当前的层次level值设置为j(j初值为1)。而指针读取R的孩子结点C1时,把当前的level值设置为j=j+1(j=2,即为第2层)。再读到C1的孩子结点G1时,把当前的level值设置为j=j+1(j=3,即为第3层)。因为G1无孩子结点,所以直接回访G1,即可计算出该结点的(G1.start,G1.end)元组的值,即该结点被访问结束。然后程序访问指针返回到上一层,此时level的值设置为j=j-1(j=2,代表回到第2层),接下来继续访问C1的下一个孩子结点G2,level值的计算方法同上,直至C1的所有孩子结点都访问完毕,这时需要回访C1,即可算出(G1.start,G1.end)元组的值,C1结点被访问结束。此时访问指针再返回到上一层,即回到根结点所在层次,此时level的值设置为j=j-1(j=1,代表回到第一层),然后再访问根结点的其他孩子结点,level的值再次设置为j=j+1(j=2,回到第2层),其他同上。当读完所有孩子结点,程序访问指针返回到根结点R,level的值设置为j=j-1(j=1,回到第一层),即根结点R的level值为1。 如果元素结点中含有属性,形如 2.2.3 计算SET编码四元组中第4个元素type值的实现算法 用以上方法计算出SET编码的前3个元素的值后,就可以根据这3个元素的值自动计算出第4个元素type的值,即结点的类型。 首先,规定type元素类型的取值:“2”代表实体结点类型,“1”代表属性结点类型,“3”代表连接结点类型。计算方法如下: 1) 如果一个结点M只含有叶子结点,则结点M为属性结点。 公式(1):if(M.end-M.start)=1, 则M.type=“1”。(由于叶子结点不做编码,所以属性结点的起止编码值差为1。) 2) 如果一个结点M有多个属性,则结点M为实体结点。 公式(2):if(M.end-M.start)>=3,且M.level!=1,则M.type=“2”。(因为实体结点至少有一个属性结点。) 3) 如果一个结点M有多个孩子结点,且孩子结点中有2个或2个以上含有相同标签或者每一个孩子结点都是实体结点,则M结点为连接结点。 公式(3):allchildrenequals(M.childrens)=true OR allchildrenisentity(M.childrens)=true,则M.type=“3”。(allchildrenequals()为判断是否含有2个或2个以上具有相同标签的孩子结点的函数;allchildrenisentity()为判断是否所有孩子结点都为实体结点的函数。) 综上所述,SET编码可以分为计算start,end值、level值和type值3个部分,具体算法如下: 算法1 XML文档SET编码 输入:XML文档;输出:XML文档的SET编码 ∥计算SET编码前3个元组,start,end,level编码 读取XML文档元素标签 if(qName是元素开始标签){ tagsStack.push(qName) ∥结点名称入堆栈 入栈元素开始编码设为i=i+1;元素读取指针深度设为j=j+1; hashmap.put(qName,estart);∥把元素开始标签编码存入hashmap中 ∥处理属性,属性也是XML文档树的一个结点,也需要编码 int len = attrs.getLength(); for (int k = 0; k {i=i+2; ∥属性结点也是元素的一个分支,占2个编码 string attrsname=(String)attrs.getQName(k); ∥属性结点可以直接放入indenhashmap中 int start=i-1; ∥开始编码 int end=i; ∥终止编码 int level=j+1; ∥结点的层次 inputhashmap(attrsname,start,end,level); if(qName是元素结束标签) {元素读取指针深度设为j=j+1; if (堆栈非空){ key1=栈顶元素标签名 if(当前元素结束标签名==栈顶元素标签名)元素一对标签配对成功 hashmap.remove(qName);∥能够配对的标签出哈斯表。元素的终止编码设为i;元素读取指针深度设为j=j-1; 函数inputhashmap(qname,start,end,level) /*根据start,end,level值计算配对成功结点的类型,然后生成完整的SET编码(start,end,level,type)四元组。*/ if(end-start==1) type=1; ∥属性结点 else if(end-start>=3 && level!=1) type=2;∥实体结点 else type=3;∥连接结点 indentityhashmap.put(name,(start, end, level,type))}}}} 本算法是根据SET编码的前3个元素(start, end, level)的值计算出第4个元素type的值。主要通过函数inputhashmap()来计算实体的匹配结点,而结点的匹配用堆栈技术来实现的。 为了测试SET编码的性能,用Java语言实现了本文提出的SET编码算法。在实验中对XMark数据集进行了SET编码与起止编码并进行了比较,同时还测试了随着XML文档复杂性的增加时对XML文档中各结点类型识别的有效性。 3.1 SET编码与起止编码的性能比较测试与分析 实验系统将生成的SET编码与起止编码存储到identityHashmap之中。identityHashmap类利用哈希表实现Map 接口,比较键(和值)时使用引用相等性代替对象相等性。即在IdentityHashMap中,当且仅当(k1=k2) 时,才认为2个键k1和k2相等(在正常Map实现(如HashMap)中,当且仅当满足下列条件时才认为2个键 k1和 k2相等:(k1=null?k2=null: e1.equals(e2)))。 为了比较SET编码与起止编码的编码性能,使用由Xmark标准提供的XML数据生成器生成六个大小分别为4、8、12、16、20、24 M的XML文档。实验中分别对这些大小不同的文档进行SET编码与起止编码,采集测试数据如表1所示。 表1 XMark数据SET编码与起止编码的实验数据Tab.1 Experimental data of SET encoding of XMark data 表1是在目标XML文档层次深度保持不变的情况下对不同大小的XML数据进行SET编码与起止编码的执行时间的测试数据。从表中数据可以看出,在同等条件下SET编码的执行时间比起止编码略多,这是因为SET编码为四元组(start,end,level,type),而起止编码为三元组(start,end,level)。SET编码是在计算tpye元素的值时候比起止编码多花费了一些时间,但是多消耗的时间的增长率是非常低的,且编码速度变化率也很稳定,说明SET编码有较好的编码性能。 3.2 SET编码识别实体结点的有效性测试与分析 能识别出XML文档中的实体结点是SET编码的主要目标。而影响SET编码识别实体结点的主要因素是XML文档树的深度,随着文档深度的增加使XML文档越来越复杂。通过实验对不同深度的20 M大小的XML文档进行SET编码测试并采集数据(文档深度在5以下时,实体识别准确率全部为100%,表中略去),结果如图3所示。 图3 SET编码算法在不同深度文档上的执行时间Fig.3 The execution time of SET coding in differentdepth of document 图3为SET编码算法在不同深度的文档上的执行时间,可以看出算法的执行时间与XML文档的深度关系不大,说明SET编码速度受XML文档深度的影响很小。 图4 SET编码算法在不同深度文档中辨别实体结点的正确率Fig.4 The correct rate of SET coding algorithm to distinguishthe entities in different depth of document 图4为SET编码算法在不同深度文档中辨别实体结点的准确率。当XML文档深度小于5层时,算法辨别实体结点的准确率非常高。而当文档深度逐渐增加时,算法辨别实体结点的准确率呈下降趋势。特别当深度达到10以上时,准确率呈快速下降趋势。因此可以说明,XML文档越复杂,出现多值属性的概率越高,从而使SET编码算法辨别实体结点的准确率呈下降趋势。这是SET编码算法有待改进之处。 3.3 性能分析 SET编码继承了起止编码的优点,具有较好的编码性能。如果XML文档中的属性结点不存在多值属性,那么用SET编码进行实体结点识别是准确的。如果一个结点含有多值属性,那么这个结点的start和end值一定不是连续的,即它们的编码差值要大于或等于3。根据公式(2),可得出这个结点是实体结点,但实际上是属性结点。此为SET编码的不足之处。解决这个问题有2种办法: 1)人工识别,但在文档很大时可操作性不强; 2)人工智能自动识别,识别程序需要维护一个庞大的知识库,难度大。本文暂不做研究。 SET编码较起止编码增加了表示XML文档中结点类型的值,所以增加了编码的存储容量,容量增加比率为33%。SET编码以存储空间换取了编码新的功能,为进一步研究根据实体类型对XML数据进行查询提供条件。 基于起止编码提出了含有四元组(start,end,level,type)的SET编码。其中第4个元素type代表XML文档的结点类型,并对XML文档结点类型进行了划分。根据实验测试结果,SET编码具有良好的编码性能,很容易判断出文档结点间的祖先/后代、父亲/孩子关系及结点之间的层次关系,并且还可以根据type元素的值快速地判断出XML文档中各结点的类型。 [1]DEUTSCH A,FERNANDEZM,FLORESCU D.A query language for XML[C]∥Intemationl world wide web conference Toronto, 1999:1155-1169. [2]MIN J K,LEE J,CHUNG C W.An efficient XML encoding and labeling method for query processing and updating on dynamic XML data[J]. J Syst Software, 2009,82(3):503-515. [3]REN J D,YIN X P,GUO X D.A dynamic labeling scheme for XML document[J]. JCC,2006,3(5):61-65. [4]杨小萍,李德录,周文勤. 一种降低XML文档更新代价的扩展Dewey编码方案[J]. 沈阳师范大学学报(自然科学版), 2010,28(2):214-217. [5]涂新莉,刘波,林伟伟. 大数据研究综述[J]. 计算机应用研究, 2014,31(6):1612-1616. [6]万常选,刘云生,徐升华,等. 基于区间编码的XML索引结构的有效结构连接[J]. 计算机学报, 2005,25(1):113-127. [7]孟小峰. XML数据管理概念与技术[M]. 北京:清华大学出版社, 2009:59-60. [8]罗道锋,孟小峰,蒋瑜. XML数据扩展前序编码的更新方法[J]. 软件学报, 2005,16(5):810-818. [9]YANG B, FONTOURA M,SHEKITA E J.5.Rajago Palan,and K.5.Beyer.Virtualeuxsor For XMLjoins[C]∥CIKM, 2004:523-532. [10]ZHANG C,NAUGHTON J F,DEWITT D J,et al. On supporting containment queries in relational database management systems[C]∥ACM SIGMOD, 2001:442-446. [11]LIU Z,CHEN Y.Identifying meaningful return information for XML keyword search[C]∥Management of Data(SIGMOD 2007), 2007:329-340. [12]YU C,JAGADISH H V. Querying complex structured databases[C]∥Very Large Data Bases (VLOB 2007 ), 2007:1010-1021. [13]王国仁,于戈,杨晓春,等. XML数据管理技术[M]. 北京:电子工业出版社, 2007:91-93. [14]DEBAR H,BECKER M,SIBON I D.A neural network component for an intrusion detection system[M]. Berlin: Security and Privacy, 1992:256-266. [15]GAO Debin,SREITER M K,SONG D. Behavioral distance measurement using hidden Markov models[M]. New Jersey: IEEE, 2006:19-40. XML coding scheme for entity recognition LITianhui,MUBaoliang (Software College, Shenyang Normal University, Shenyang 110034, China) In the present paper, a start-end-type (SET) coding method in the treatment of XML document is proposed based on the idea of start-end coding, and the start-end coding triplets (start, end, level) is developed into a four-tuple (start, end, level, type), which increases an XML document type node as the type value. This paper also proposes a new implementation algorithm for the first three values of the four tuple, and the type values of the fourth elements can be calculated automatically by the first three elements. SET coding not only can quickly determine the relationship between ancestor and descendant, or father and son of nodes, but also the type of XML document based on type value. After the experiment, SET coding not only has good coding performance, but also can recognize the of XML data entity according to node types, it can be the basis for the further study of XML data query according to the entity type. big data; start-end coding; SET coding; depth first traversal; entity node 2016-06-13。 辽宁省教育厅科学研究一般项目(L2012388)。 李天辉(1976-),男,辽宁兴城人,沈阳师范大学讲师,硕士。 1673-5862(2016)04-0473-06 TP3l1 A 10.3969/ j.issn.1673-5862.2016.04.0202 XML文档的SET编码方案及实现算法
3 SET编码性能分析

4 结 语
