说话人日志中可靠静音模型语音活动检测方法
2016-12-12杨登舟徐嘉明夏善红
杨登舟,徐嘉明,刘 加,夏善红
(1.中国科学院 电子学研究所,北京 100190;2.中国科学院大学 电子电气与通信工程学院,北京 100049;3.清华大学 电子工程系,北京 100084)
说话人日志中可靠静音模型语音活动检测方法
杨登舟1,2,徐嘉明1,2,刘 加3,夏善红1
(1.中国科学院 电子学研究所,北京 100190;2.中国科学院大学 电子电气与通信工程学院,北京 100049;3.清华大学 电子工程系,北京 100084)
为了解决传统语音活动检测(VAD)技术分离出的语音段掺杂静音以及帧间频繁跳动产生短语音碎片的问题,提出在说话人日志中能够高效稳定地完成语音活动检测的方法.该方法利用可靠静音模型对语音的区分度高这个特性,通过循环迭代收敛得到稳定划分.建立静音和语音模型,通过帧间连续性原理进行不确定性解码得到帧类属信息,开展低能量短时间语音碎片后处理完成语音活动检测.在富标注说话人日志数据集上测试,实验结果表明,由于对静音模型的描述更加可靠,采用该方法可以减少帧间跳动,减少静音模型对语音的吸收误判,性能比基于子带熵顺序统计滤波(SE-OSF)方法提高明显.
说话人日志;富标注;语音活动检测(VAD);高斯模型;维特比解码
说话人日志(speaker diarization,SD),即说话人分割聚类,确定一段语音音频数据的各时间片段里分别是谁在说话(who spoke when)[1].它是语音信号处理里面经常遇到的问题,既可以作为语音识别和说话人识别的前端处理模块,也可以作为说话人转换独立问题.美国国家标准及技术研究所(National Institute of Standards an Technology,NIST)组织的富标注(rich transcription,RT)评测自从2002年开始将说话人日志纳入评测范围,已经举办多年[1].通常说话人日志包含以下3个方面的内容[2]:1)将语音按照语音和非语音切分成不同的片段,该过程叫做语音活动检测(voice activity detection,VAD)[3];2)将切分出来的语音按照不同说话人分割开来,该过程称为说话人改变点检测 (speaker change detection,SCD)[4];3)将同属于某一个人的语音标注上相同的标签,称为说话人聚类(speaker clustering,SC)[5].从时间顺序上来看,像计算机后台服务日志(每个时间段,产生了新的进程,销毁了无用进程,并实时记录)一样,说话人日志需要告诉用户在每个时间片段,待处理语音中是谁在说话.
早期的语音活动检测算法都是基于距离度量的.从语音中提取出时域的特征(包括短时能量、过零率、过零率变化等)[6],通常信号能量高于噪声能量,信号过零率低于高斯白噪声,信号过零率的变化比噪声大,通过设定门限值,直接作出决策判断.Shen等[7-8]发现频域度量语音和噪声区分度较好的特征-频谱子带熵,信息论表明,信号熵是表征信号不确定度的参量.由于噪声信号(如高斯白噪声)通常随机性比较大,而语音是相对有规律性的信号,表现在频域,即噪声的频谱分布比较均匀,信号频谱分布局部能量起伏较大,因此语音的熵比噪声的熵小得多.之后,Wang等[9-10]开始尝试基于听觉特性的说话人识别中的常用特征——梅尔倒谱系数(Mel—frequence cepstral coefficients,MFCC) ,MFCC特征在说话人识别中的表现一直是不错的.Ramirze等[11-12]考虑到语音信号帧间关联性强的特定,引入最早应用在图像处理领域中的边缘检测算法——顺序统计滤波器(order statistics filter,OSF),将每帧语音与基准帧的相似性距离送入顺序统计滤波器,对波动性较大的相似度距离进行近邻平滑,得到相似度的优化值,然后与初始设置的门限作判决.
在说话人日志领域,语音端点检测算法基本都是基于模型的[13],建立语音模型和静音模型,利用模型的稳定性去克服距离度量中所存在的帧间跳动缺陷,能够得到较好的性能.考虑到说话人日志对语音端点检测要求的苛刻,本文提出基于可靠静音模型(reliable silence model,RSM)的方法,使说话人日志中语音端点检测更加准确,更加稳定,得到更加合理的切分片段,有助于后续分割聚类过程的实现.

图1 说话人日志图示Fig.1 Speaker diarization demonstration
1 说话人日志中语音端点检测
如图1所示,说话人日志需要将语音检测出来,在说话人发生改变的地方作切分,对同一说话人标注同一类属信息.
对说话人日志系统的性能评价采用说话人日志错误率(diarizaiton error rate,DER)指标[1]来检验.将参考时间(整个参考答案中分段的时间总和,包括说话人重叠的语音)和系统实际输出的类属信息进行比对,通过最大匹配原则,将参考答案中的每个人和提交结果中的部分人建立一一映射关系.错误的说话人所属分段都被当做错误说话人时间(speaker error time,SET),参考答案中出现提交结果中未出现的分段称为漏报说话人时间(missed speaker time,MST),参考答案中未出现而提交结果出现的分段称为虚警说话人时间(false alarm speaker time,FAST).分别将这三类不匹配、缺少、多余的时间片段占总参考时间的比率定义为说话人错误率(speaker error rate,SE)、漏报率(missed error rate,Miss)、虚警率(false alarm error rate,FA),系统的性能将由这三者决定,DER=SE+Miss+FA.
从系统性能评价指标DER的定义可以看出,语音活动点检测在说话人日志中的重要性,非语音被误判为语音和虚警率是一致的,语音被误判为非语言和漏报率是一致的.除此之外,还有一个更重要的因素,在多说话人分割和多说话人聚类这两类问题中,语音中掺杂非语音,是非常有害的.在通常的语音识别和说话人识别任务中,往往不需要对VAD切分作严格要求,往往一个文件里很长的语音片段都是属于某一个人的,里面有少量的非语音或干扰语音,但不会影响整个长段的统计特性.然而说话人日志中这方面的需求不同,在单信道、多说话人任务中,往往说话人的转换是非常快速的,短到0.3 ~1.0 s.此时原本用于统计说话人个性特征的有效帧已经不满足条件(在自动说话人识别问题上,Dunn等[14]指出,有效语音片段的长度小于1 s,说话人识别的识别率将急速下降,往往低于70%),因此在这么短的语音数据下,若还有被误判的非语言参杂其中,则要在如此短的时间片段下建立说话人模型,几乎是不可能的.本文提出的基于可靠静音模型的语音活动检测算法在说话人日志系统中使得VAD性能显著提高,并能够得到更加合理的切分片段,有助于后续分割聚类过程的实现.
2 特征与模型
在语音活动检测已提出的各种方法中,研究人员总是想从音频流数据中检测出语音出现的位置,在基于模型的语音检测算法中,总是不断地优化语音模型来提高准确率.现实的情况是一段音频数据里出现的人数是不定的,语音的模型取决于语料中说话人的模型,而人是不定的,因而语音模型的不确定性很大,无法用通用模型去刻画语音模型.如果换个角度去看,语音活动检测是检测语音出现的位置,但是只要得到静音位置,也就知道了语音在什么位置.与建立可靠语音模型不同的是,经过过滤增强的音频流信号中的静音部分往往是低能量低幅度的随机信号,静音数据的稳定性和可靠性比语音更强.
只用能量一个特征维度去表征静音是不全面的.鉴于MFCC特征在说话人识别领域的优秀表现[15],语音信号可以提取MFCC特征,对于静音数据,也可以用相同的方法去提取.从MFCC计算的过程[9]可以发现,提取静音段的MFCC,即将各静音频谱经过三角带通滤波器组,再作离散余弦变换(discrete cosine transform,DCT).由于静音总能量有限,落在各子带的能量也有限,于是对静音提取MFCC就可以将原本的一维能量特征变换到多维特征,而原本的低能量的有限次正负叠加运算可以用高斯模型(Gaussian model)很好地刻画.此时可以用联合高斯分布对噪声建模,得到静音的高斯模型N(us,Σs).一帧特征与静音的相似度L可以通过下式计算:

(1)
将语音信号的MFCC特征建模,语音与噪音的特征有不同的分布,通过模型打分决策去判决语音和静音.由于这是二值分类问题,建立了基于模型的方法,无需设定初始判决门限,很好地解决了传统方法需要提前训练语料得到判决阈值的弊端.传统方法如果允许提前训练好阈值的参数,但不同的阈值只能对部分数据适用,因此无法设置全局最优阈值.

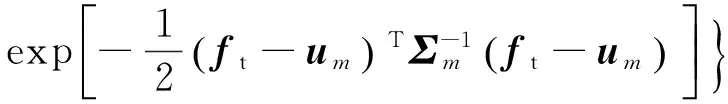
(2)
得到语音模型和静音模型之后,可以根据下式作硬判决得到帧类属信息.
(3)
3 系统实现
采用的VAD系统实现如图2所示,下面将详述各个部分的实现过程.
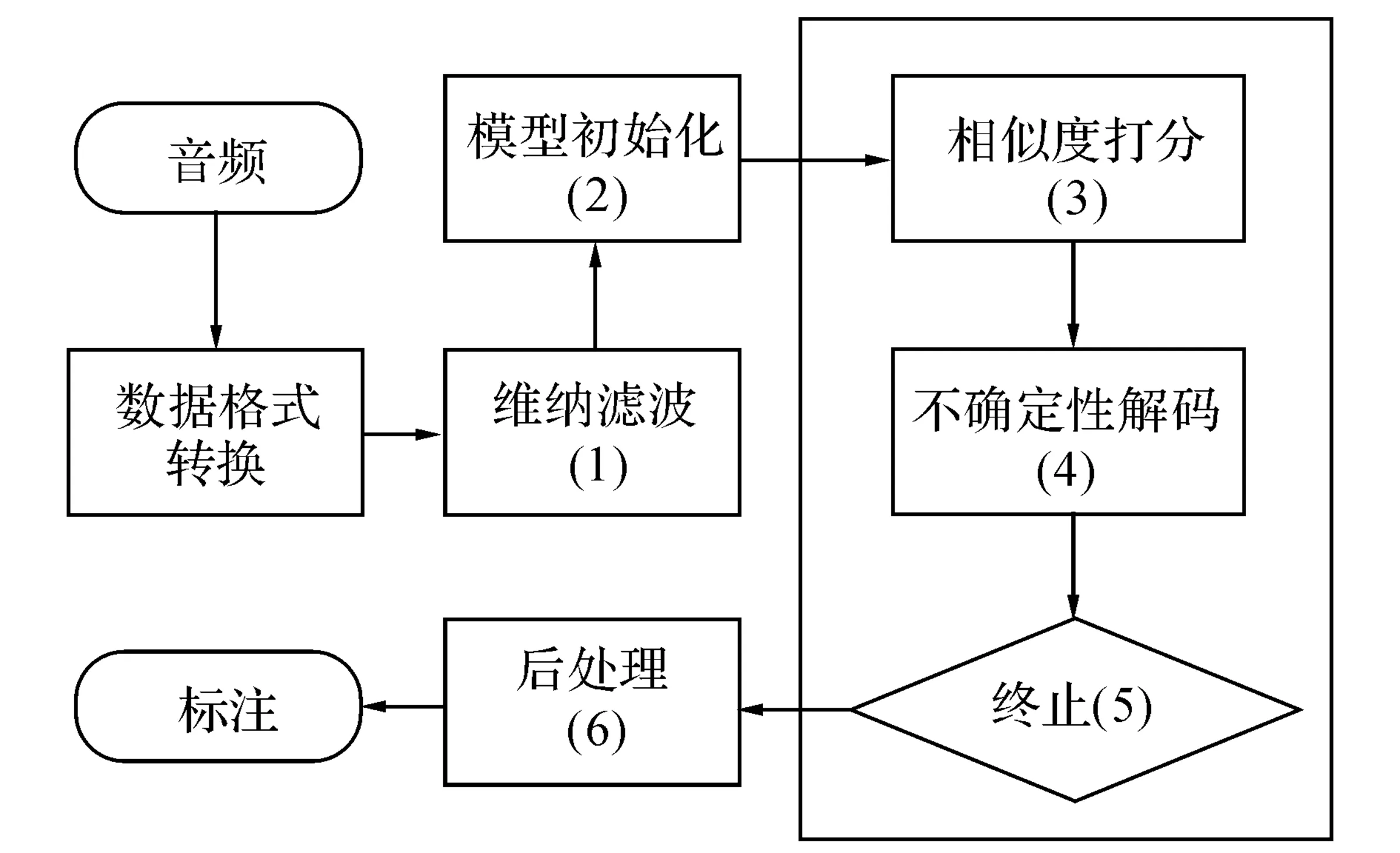
图2 RSM-VAD流程图Fig.2 RSM-VAD flow diagram
3.1 数据预处理和模型初始化
话筒麦克风采集的音频流数据格式往往各不相同,需要作规整统一音频参数,以采样频率Fs重新采样,设置量化精度P,音频平均能量标准化.
由于一般说话人日志中得到的初始音频流背景噪声很强,音频质量较差,通过维纳滤波可以获得较纯净的音频信号,本文采用文献[16]的算法.
按照能量准则可知,信号能量通常高于静音能量,Nwe等[17]指出,取平均音频能量的0.6%作为门限,低于该门限判为静音,高于该门限判为语音,语音虚警率只有2%;取平均能量的33%作为门限,高于该门限判为语音,低于该门限判为静音,静音虚警率只有4%.对各帧能量进行排序,取分帧数据能量较大的pts比例的数据帧作为语音初始数据.利用期望最大化方法(expectation maximization,EM)[18],训练M个混合数的高斯混合模型GMM{M,w,u,Σ};将能量较小的ptv比例的数据训练各个特征维度的均值和方差,得到静音高斯模型N(us,Σs).
3.2 相似性打分和不确定性解码
利用式(1)计算每帧数据在语音模型下的相似度,利用式(2)计算每帧数据在静音模型下的相似度,根据式(3)对每帧进行类属信息标注.
由于不管是语音还是静音通常都会持续一段时间,而且在邻近的时间段内信号短时特性能够得以保持,但会出现起伏不断的跳动.为了稳定地给出判决结果,采用不确定性解码.具体实现使用前后向算法(forword-backword algorithm)[19],图3描述状态转移矩阵,如图4所示为正向Viterbi解码时序状态图,状态转移概率矩阵
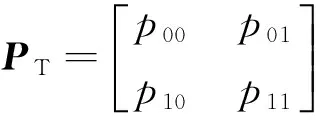

图3 状态转移概率Fig.3 State transition probabilities

图4 时序状态转移图Fig.4 Time-domain state transition sequences
基于动态规划的Viterbi算法在每个时间帧上的各个状态,计算解码状态序列对观察序列的后验概率,保留概率最大的路径,并在每个节点记录下相应的状态信息以便反向获取帧类属解码序列.作完正向Viterbi解码再作反向Viterbi解码,最终依据正向和反向的联合输出概率确定每帧的类属信息.
3.3 循环终止判定和后处理
当两次循环经过Vierbi解码后各帧的类属信息中静音帧占比(静音帧在音频帧中所占比例)改变量达到门限ths_v时,则停止迭代.
对于分割结果中语音片段持续时间小于Td或段平均能量小于Ewm的分段,强制标识为静音.Ewm由Ewm=αEms+(1-α)Emv计算,其中Ems为所有静音段的平均能量的平均值,Emv为所有语音段的平均能量的平均值,α为调节因子.
4 实验结果与性能分析
4.1 实验配置
原始待标注测试音频数据使用NIST RT05、RT06、RT07、RT09评测时所提供的数据.单信道信号取原始多路语音信号中的第一个文件.
在音频规整中,采样频率Fs=8 000,量化位数P=16,平均幅度归一化Am=0.1.
对各帧信号的短时能量进行排序,语音选择高能量帧数的比例pts=0.2,静音选择低能量帧数的比例ptv=0.1.
特征采用36维MFCC特征,包括12维基本特征和一阶差分、二阶差分.在语音模型GMM中,混合数M=16,权重、均值和对角阵协方差矩阵都由输入数据通过EM算法得到.
不确定解码中初始静音和语音分布用语音中实际统计出的静音占比和语音占比计算,状态转移概率矩阵
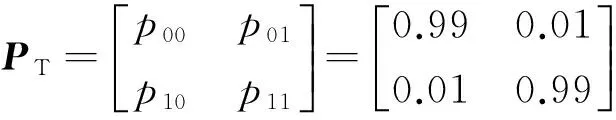
后处理中语音最短持续时间Td=100 ms,能量调节因子α=0.99.
4.2 实验结果与分析

图5 RSM方法中间结果Fig.5 System details of RSM
图5描绘了基于可靠静音模型(RSM)的语音活动检测方法的过程结果.如图5(a)所示为原始语音的时域波形图;如图5(b)所示为RSM-VAD最终的切分结果,黑色为语音,灰色为静音;图5(c)记录下音频各帧数据与语音模型和静音模型的相似度,位于上方平稳的是语音,下方波动起伏大的是静音;如图5(d)所示为将模型相似度打分以后采用前后向算法,双向维特比解码后各帧的语音不确定度曲线.图中,A为振幅,t为时间,L为相似度得分,P为判决是语音的概率.从图5(c)可以看出有较多帧间跳跃(静音曲线上穿语音曲线然后迅速下穿语音曲线),由于采用维特比解码,帧间跳跃现象基本消除.此外,观测图5(c)可以发现,音频各帧数据语音模型的相似度基本恒定,没有较大的起伏,对于语音和静音区分性极弱;静音模型在语音帧下的相似度很小,但在静音帧下相似度很大.从这一点来说,静音的区分性是实现有效VAD的关键.
对于实验结果,使用NIST RT评测提供的打分程序[20]与参考答案进行打分,得到虚警率FA、漏报率Miss以及两种错误之和e=FA+Miss.
基于子带熵的顺序统计滤波方法(subband en-tropy -order statistics filter,SE-OSF)在语音识别和说话人识别中有较好的性能,表1记录了本文提出的RSM方法SE-OSF方法在RT05~09四个年份数据集上的性能统计.虽然SE-OSF在虚警率上稍占优势,但是在漏报率指标上性能明显不如本文提出的方法,本文提出的语音活动检测算法在RT数据集上的总体性能比SE-OSF方法提高了3.76%.

表1 RT数据集上的性能对比
图6考察RSM是否具有稳定性能.在RT05~09四年数据37个文件当中,仅有3个文件的数据出现SE-OSF的性能优于RSM,因此本文提出的算法性能是比较稳定的.
在说话人日志NIST RT09测评中,一共有6家参评单位给出单信道(single distant microphone,SDM)说话人日志系统的性能结果.表2列出5组对比数据,测试数据集是NIST RT09全部数据.5组数据分别对应:SE-OSF子带熵顺序统计滤波方法,本文提出的方法,IIR-NTU是新加坡资讯通信研究院-南洋理工大学的评测结果,LIA是法国Avignon计算技术实验室-EURECOM公司的评测结果,UPC是西班牙加泰罗尼亚理工大学的评测结果.从表2可以看出,本文提出的方法对说话人日志中语音活动检测的性能提高是很明显的.

表2 RT09数据集下几种方法性能对比
注:1)各列数据是对应研究机构所报结果.
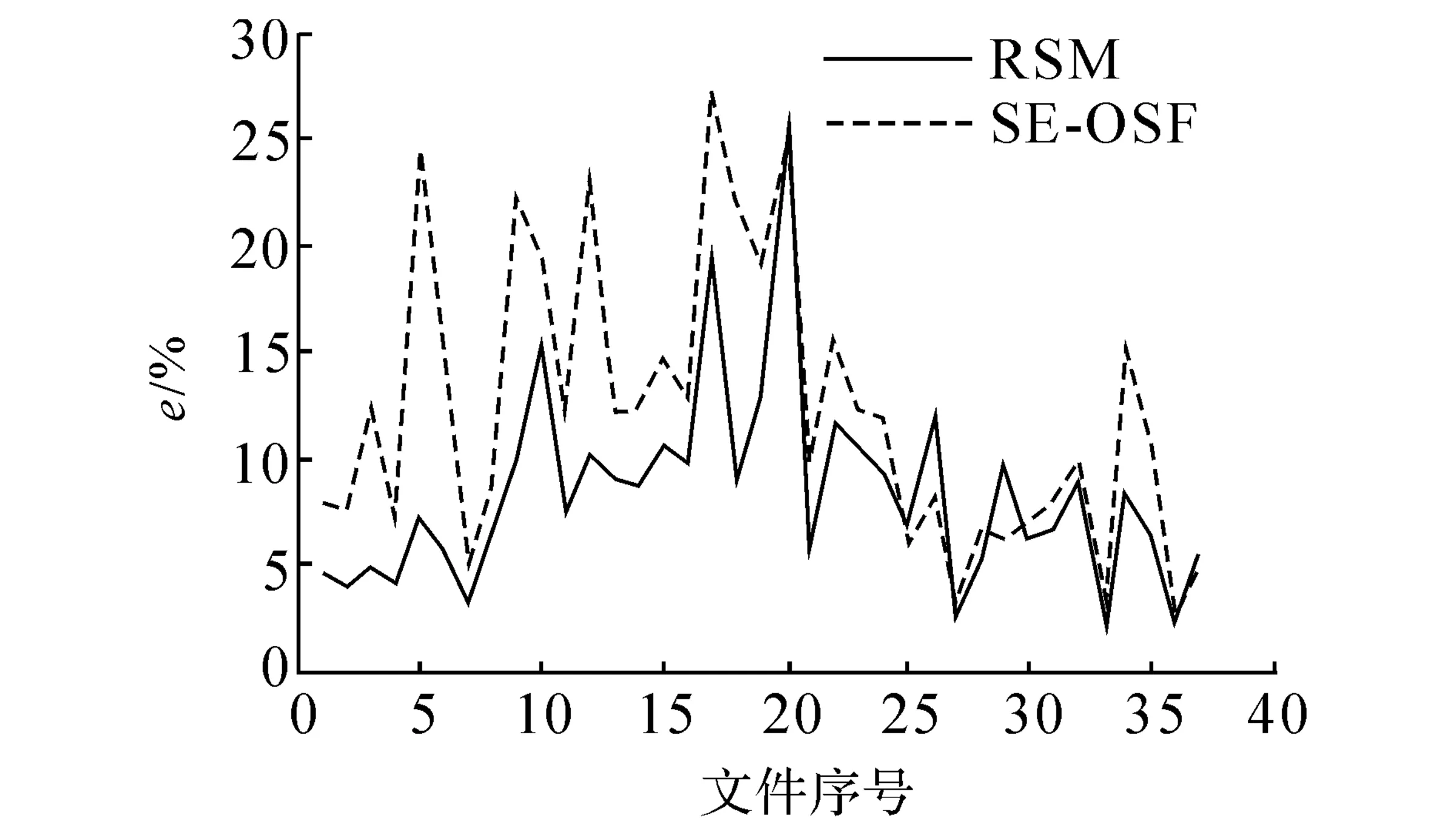
图6 两种方法在RT05~09数据集下的性能对比Fig.6 Performance comparison on RT data-sets 05~09
考察IIR、LIA、UPC三家机构的语音活动检测算法可知,UPC采用近似支持向量机(proximal support vector machine,PSVM)[21]技术训练静音和语音的分类超平面来进行判决,LIA采用39维线性频率倒谱系数(linear frequency cepstrum coefficients,LFCC )[22]特征.2个状态的隐马尔科夫模型(hidden Markov model,HMM),语音状态和静音状态都是用混合数为32的GMM模型表示.IIR采用36维MFCC特征,语音和静音分别用混合数为4和16的GMM模型表示,没有使用维特比解码过程[23].这三家机构的模型都比本文提出的方法复杂,但是语音活动检测的性能没有因为模型的复杂度的增大而提高. 一个本质的原因在于语音和静音的模型有着巨大的差别,语音信号同时包含语义信息和说话人信息,在说话人识别中往往一个人的模型就用至少128个混合数去刻画,在用GMM模型去表征时,越多的混合数对模型的逼近程度越好.静音部分只是一种单一低能量随机扰动的信号,静音本身没有固定的模型,采用单高斯模型对静音信号建模是合适的.增加静音模型的复杂度只会导致过度建模,而现在都是采用迭代的方法去实现最终结果,过度建模的成分会吸收原本不属于这一类别(静音)的帧,降低语音模型和静音模型之间的区分度,从而导致错误率的升高.表3记录了静音和语音模型在不同混合数下的性能,如果都采用单高斯模型(表3中的01_01),由于语音模型的混合数太少,无法很好地区分语音和静音.随着语音模型的混合数增大(01_01->01_16->01_32->01_64),区分性能逐渐变好.相反,若增加静音模型的混合数(01_16->02_16,01_64->02_64),则区分性下降.

表3 模型mixture数的变化对性能的影响
注:1)08_32中的08和32分别为静音/语音的模型混合数.
5 结 语
基于模型的语音活动检测的一个优势在于模型计算得到的相似度在相邻帧之间的变化极小.虽然硬判决可以作为粗判的标准,但是很容易出现2条相似性曲线的交叉,需要进一步通过帧间的关联性将其剔除.本文采用正向-方向维特比解码,在算法稳定性、性能要求更高的说话人日志VAD切分下,比顺序统计滤波(平滑滤波技术)更加有效地缓解了帧间跳动问题.
本文的方法称作可靠静音模型活动语音检测,“可靠”在于以下两个方面.1)抓住语音和静音的主要区分因素-能量,因此用最低能量的一定比例的数据作为静音模型初始化是很可靠的.2)对静音的表征不用高斯混合模型,而用简单的单高斯模型.单高斯模型的表现很稳定,避免了因为使用高斯混合模型过度建模使得部分Mixure对语音帧的吸收,从而提高了静音模型的可靠性.
本文基于可靠静音模型的语音活动检测方法,利用模型相似度打分,再运用动态不确定解码,得到静音分段和语音分段,在单信道说话人日志中达到非常好的效果.在RT数据集上,与基于子带熵顺序统计滤波的活动点检测算法相比,VAD错误率由11.76%下降到8%,性能提高了3.76%,在RT09数据集上比IIR-NTU、LIA、UPC所提供的基于模型的方法有性能上的提升.
[1] The 2009 (RT09) rich transcription meeting recognition evaluation plan.2009-02-24. http:∥itl.nist.gov/iad/mig/tests/rt/2009/docs/rt09-meeting-eval-plan-v2.pdf.
[2] NWE T L, MA B, LI H, et al. Speaker diarization in meeting audio for single distant microphone. [J]. Interspeech, 2010(1): 4073-4076.
[3] MA Y, NISHIHARA A. Efficient voice activity detection algorithm using long-term spectral flatness measure [J]. EURASIP Journal on Audio, Speech, and Music Processing, 2013, 2013(1): 1-18.
[4] MALEGAONKAR S, ARIYAEEINIA A M, SIVAKUMARAN P. Efficient speaker change detection using adapted Gaussian mixture models [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(6): 1859-1869.
[5] FRIEDLAND G, JANIN A, IMSENG D, et al. The ICSI RT-09 speaker diarization system [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(2): 371-381.
[6] RABINER L R, SAMBUR M R. An algorithm for determining the endpoints of isolated utterances [J]. The Bell System Technical Journal, 1975, 54(2): 297-315.
[7] SHEN J L, HUANG J W, LEE L S. Robust entropy-based endpoint detection for speech recognition in noisy environments [C]∥ Proceeding of International Conference on Spoken Language Processing. Sydney: ICSLP, 1998: 232-235.
[8] YANG C H. A novel approach to robust speech endpoint detection in car environments [C]∥ IEEE International Conference on Acoustics, Speech, and Signal Processing. Istanbul: IEEE, 2000:1751-1754.
[9] WANG H, XU Y, LI M. Study on the MFCC similarity-based voice activity detection algorithm [C]∥ 2011 2nd International Conference on Artificial Intelligence, Management Science and Electronic Commerce. Zhengzhou: IEEE, 2011: 4391-4394.
[10] KINNUNEN T, CHERNENKO E, TUONONEN M, et al. Voice activity detection using MFCC features and support vector machine [C]∥International Conference on Speech and Computer. Moscow: Springer, 2007: 556-561.[11] RAMIRZE J, SEGURA J C, BENITEZ C, et al. An effective subband OSF-based VAD with noise reduction for robust speech recognition [J]. IEEE Transactions on Speech and Audio Processing, 2005, 13(6): 1119-1129.
[12] RESTREPO A, HINCAPIE G, PARRA A. On the detection of edges using order statistic filters [C]∥ 1994 IEEE International Conference of Image Processing. Austin: IEEE, 1994: 308-312.
[13] SADJADI S O, HANSEN J H L. Unsupervised speech activity detection using voicing measures and perceptual spectral flux [J]. Signal Processing Letters, 2013, 20(3): 197-200.
[14] DUNN R B, REYNOLDS D A, QUATIERI T F. Approaches to speaker detection and tracking in conversational speech [J]. Digital Signal Processing, 2000, 10(1): 93-112.
[15] REYNOLDS D A, QUATIERI T F, DUNN R B. Speaker verification using adapted Gaussian mixture models [J]. Digital Signal Processing, 2000, 10(1): 19-41.
[16] SCALART P. Speech enhancement based on a priori signal to noise estimation [C]∥ 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing. Atlanta: IEEE, 1996: 629-632.
[17] NWE T L, SUN H, LI H, et al. Speaker diarization in meeting audio [C]∥ IEEE International Conference on Acoustics, Speech and Signal Processing. Taipei: IEEE, 2009: 4073-4076.
[18] DEMPSTER A P, LAIRD N M, RUBIN D B. Maximum likelihood from incomplete data via the EM algorithm [J]. Journal of the Royal Statistical Society, Series B (Methodological),1977,39(1): 1-38.
[19] YU S Z, KOBAYASHI H. Practical implementation of an efficient forward-backward algorithm for an explicit-duration hidden Markov model [J]. IEEE Transactions on Signal Processing, 2006, 54(5): 1947-1951.
[20] NIST, Rich Transcription Spring 2006 Evaluation. 2006-02-27.http:∥www.itl.nist.gov/iad/mig/tests/rt/2006-spring/docs/rto6s-meeting-eval-plan-V2.pdf.
[21] TEMKO A, MACHO D, NADEU C. Enhanced SVM training for robust speech activity detection [C]∥ IEEE International Conference on Acoustics, Speech and Signal Processing. Honolulu: IEEE, 2007: IV-1025-IV-1028.
[22] FREDOUILLE C, BOZONNET S, EVANS N. The LIA-EURECOM RT09 speaker diarization system [C]∥RT09, NIST Rich Transcription Workshop.Melbourne:NIST,2009.
[23] NWE T L, SUN H, MA B, et al. Speaker clustering and cluster purification methods for RT07 and RT09 evaluation meeting data [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(2): 461-473.
Reliable silence model based voice activity detection approach in speaker diarization
YANG Deng-zhou1,2, XU Jia-ming1,2, LIU Jia3, XIA Shan-hong1
(1.InstituteofElectronics,ChineseAcademyofSciences,Beijing100190,China;2.SchoolofElectronic,ElectricalandCommunicationEngineering,UniversityofChineseAcademyofSciences,Beijing100049,China; 3.DepartmentofElectronicEngineering,TsinghuaUniversity,Beijing100084,China)
The performance of traditional voice activity detection (VAD) methods is not stable owing to the impurity of speech segments and short time speech fragments generated by inter-conversion frames. An efficient and stable VAD approach for the task of speaker diarization was presented. Stable speech and silence segments were got by iteratively retrain the speech and silence models until the relative invariability thanks to the discrimination of silence model. Our implementation included several components: modeling silence and speech as Gaussian model and Gaussian mixture model (GMM) separately, uncertainty decoding using frame continuity rule to gain frame attribution, removing short-time and low-energy fragments to finish the detection. Tests were conducted on the rich transcription speaker diarization dataset. Experimental results show that the method can reduce the inter-conversion and make less inaccurate decision sentencing speech to silence, and demonstrate a sustained advantage over the sub-band entropy order statistics filter (SE-OSF) VAD algorithm.
speaker diarization;rich transcription;voice activity detection (VAD);Gaussian model;Viterbi alignment
2014-12-10. 浙江大学学报(工学版)网址: www.journals.zju.edu.cn/eng
国家自然科学基金资助项目(61370034, 61403224).
杨登舟(1986-),男,博士生,从事说话人识别的研究. ORCID: 0000-0003-0696-1497. E-mail: yangdengzhou@sina.com 通信联系人:刘加,男,教授,博导. ORCID: 0000-0002-7156-380X. E-mail: liuj@tsinghua.edu.cn
10.3785/j.issn.1008-973X.2016.01.022
TN 912
A
1008-973X(2016)01-0151-07
