IQA在数字化文献质量评估中的应用研究
2016-11-30张海燕
张海燕
(南京信息工程大学,210044)
IQA在数字化文献质量评估中的应用研究
张海燕
(南京信息工程大学,210044)
IQA(Image Quality Assessment图像质量评价)是一种测评数字化文献质量优劣的客观方法。文章利用IQA对不同扫描模式、不同扫描分辨率获得的数字化文献分别进行图像质量测值和文字识别错误测值,结合图表对测值进行了波动分析。研究发现,数字化文献的质量高低并非完全取决于扫描分辨率,在常规的黑白、4阶灰度扫描模式下,并非扫描分辨率越高,图像质量就越好,而是当分辨率取200 - 400 DPI时获得的图像质量测值最低而图像质量最好。基于测值的波动分析,进一步给出了文献数字化在不同模式下比较理想的扫描分辨率范围。
文献数字化;文献扫描;IQA; 图像质量评估
1 引言
随着科技的进步,电子文献的兴起打破了纸质文献长期一统天下的局面。对于非再生性的古籍文献、拓片、甲骨、家谱、舆图、手稿、地图、书籍、乐谱等,如何能够更好地得到传承使用及保存,如何能够被更广泛地阅读,文献数字化技术应该说是解决这一难题的有效途径[1]。文献的数字化过程一般是从扫描文献开始,然后对扫描的图像做进一步预处理,最后形成电子文档。虽然技术上还存在着标准的多样性与需求的单一性的矛盾等问题,但是文献数字化技术也已经逐渐形成了一定的技术标准,然而对数字化文献的质量进行评估的研究却并不多见,目前大部分研究主要集中在图像质量评价上[2]。
最近十几年,电子文献直接采用文本文档,不但阅读方便,而且可以直接拷贝引用。然而不管是纸质文献,还是电子文档,读者都是通过眼睛阅读页面的文献直接获取其中的信息,页面质量越好,读者阅读起来就越舒服。基于IQA的数字化文献质量评估,就是根据人眼的生理特性和人的视觉心理,提出基于图像质量评价体系的文献数字化理论依据和操作方法,对不同扫描模式下的数字化文献的质量进行客观分析,根据文献来源科学地确定扫描模式和扫描分辨率,提高了文献数字化质量。
2 数字化文献质量的测量
2.1 数字化文献质量的基本要求
文献数字化不但对文献有保护作用,同时也有利于文献的利用和研究[3]。东南大学朱成林等认为在古籍文献数字化过程中,OCR(optical character register,光学字符识别)等技术的识别正确率不高,导致研究效率低下,不同机构开发的古籍数据库的质量差距也较大,为保障研究的可信度,研究者在参考数字文献的过程中依然需要与纸本原文进行对照[4]。要解决这一问题,数字化后的电子文献就必须符合两个基本要求:(1)文本能够拷贝引用。如果文献不能被直接拷贝引用,还需手工输入,就会使得文献的利用研究效能大为降低。(2)文本清晰,阅读舒服。要求数字化后的文献能够符合人眼的生理特性和人的视觉心理,读者无需再参考纸本文献,在阅读电子文献时的感觉和阅读原有的纸质文献一样清晰舒服。不管是数字化文献,还是纯文本的电子文献,必须符合上述两个基本要求,读者才会接受并愿意典藏起来。
文献能够拷贝引用涉及到OCR技术。如何降低OCR的文字识别错误率,提高OCR图像质量值是问题的关键。文献能够舒服清晰地阅读涉及到人眼的视觉特性和图像质量。文献的图像质量是首要的,即使是纯文本的电子文献。
2.2 影响OCR准确率的主要因素
OCR这一概念最早于1929年由德国科学家Tausheck提出[5]。随后美国科学家Handel描述了利用光学技术对文字进行识别的概念模型。OCR技术即是利用光学技术对文字和字符进行扫描识别,并将其转化为计算机内码的技术。影响OCR准确率的主要因素包括:
(1)OCR软件的性能。不同的OCR软件有着不同的性能,导致这种差异的原因是多方面的,其中最主要的原因是软件开发和传承方面。起步早、技术力量雄厚的软件公司,OCR软件的内核模式、特征提取等方面有着明显的优势,其软件的文字识别准确率会远远高于其它一些起步晚、实力小的公司。
一款好的OCR软件,其高性能不仅体现在版面分析、边缘提取、倾斜校正、去噪、对灰度图像二值化、对二值图像伪灰度化等图像的预处理方面,同时在样本字库的建立、文本行字的切分、预分类、特征提取、匹配方法、细分类、识别字典、词句确认等文字识别方面,性能也会高于一般的OCR软件,尤其在表格、字体识别等细节方面优势明显。
CHIP全球测试中心中国实验室在2000年便对中国6款著名的中文OCR软件从图像预处理、版面分析、理解、文字块检出、文字的行、字切分、图像文字的规范化、文字特征的提取、与特征库比较分类、判别、后处理等各个方面进行了重点测试。测试结果:汉王OCR新世纪专业版以其令人信服的高识别率遥遥领先,尚书五号OCR增强版与汉王 OCR新世纪专业版使用的是同一个程序内核,也拥有极高的识别率。此外,丹青中英文文件辨识系统V4.0、清华紫光OCRMF7.5、清华文通TH-OCRMF7.5等,也被广泛应用。
(2)文献的来源。数字化文献的来源很多,不同来源的数字化文献有着不同的特质,需要不同特质的OCR软件与之配套。如,针对发黄的古籍善本需要注意标点符号的识别,繁体字、通假字等字体的转换[6];对于陈旧版本的乐谱则需要注意音符的附点、连线的识别,必须利用计算机光学乐谱识别技术(OMR),把乐谱图像自动转化为通用的数字音乐格式[7];票据的OCR识别对识别结果的精度要求很高,误识率理论上要求趋近于零,识别对象较少,主要集中于金额、日期、账号[8]。因此,针对不同待识别对象,采用不同“特质”的OCR软件,文字识别的准确率将大大提高。
(3)数字化设备设置。文献数字化采用的设备主要是扫描仪。针对不同的文献,扫描仪如何设置,扫描模式、扫描分辨率如何确定,是影响数字化文献质量的重要因素,也是提高数字化文献质量的关键。
2.3 基于人眼视觉特性的图像质量评价
由于人眼是图像的最终观测者, 所以主观图像质量评价方法是惟一最准确的方法,传统的图像质量评价算法由于没有充分考虑人眼的视觉特性,使得质量评价结果与实际图像的人眼感知质量不符[9]。基于人眼视觉特性的图像质量评价就是根据人眼对图像边缘信息非常敏感这一特性,通过比较失真彩色图像与原始参考图像的边缘,以及除边缘之外的背景相似程度,最终确定失真图像的质量,这样的评价结果更接近图像的实际视觉感知质量。
2.4 IQA在测量文献质量中的应用
2.4.1 IQA原理简述
在自然界中,自然场景内本身具备大量的平坦区域和丰富的边缘和轮廓信息,其频率分布有一定的规律——人类大脑皮层细胞的响应与自然场景的统计信息呈对数关系[10]。自然场景中的平坦区域以及边缘和轮廓的关系,首先表现在空间上相关,即:图像空间上相邻的像素点有着相似的灰度值,像素点在空间上离得越远,两者灰度值差异越大。如果一个像素点越亮,则相邻的像素点也越亮,随着像素间间距的加大,相关性随之降低。根据自然图像的变换不变性,借助傅里叶变换,可以从像素的亮度和坐标的相关性中恢复出图像的“自然性”。
考察数字化文献的质量,就是考察文献中每个页面的图像质量。每个页面的图像并非是扫描仪直接扫描馆藏文献而成,还必须经过倾斜、二值化等图像预处理环节,最后才能形成数字化文献[11]。无论扫描仪的质量多么高、图像预处理环节多么完美,与原文献资料相比,用户所看到的数字化文献总是存在或多或少的失真。图像的失真不是人们所期望的,但利用人眼的视觉特性,建立相应的图像质量评估(IQA)模型可以评估这些失真。失真越大的图像质量越差,反之,图像质量越好。利用IQA方法,可以方便地测量出数字化文献中每页图像的评估值;并能根据这些值判断出图像的自然度。
2.4.2 IQA测量文献页面质量
数字化文献是由一页一页的图像构成的,测定数字化文献的页面质量,要把每一页图像提取出来,然后利用IQA图像评估方法,测定页面图像质量值。
数字化文献页面的提取采用PDF Image Extraction Wizard,可以批量通篇提取,也可以设定页码范围提取图像页面。电子文本文献尽管本质上不是图像,但因为最后的显示是借助于字符码调用系统字库图像,所以最终仍是以图像形式展现在用户的面前,字符图像和背景构成的画面就是读者阅读的图像。这种图像如果质量差,用户阅读不舒服,就会影响文献的阅读效果。用户的阅读界面就是IQA要评估的图像,因此可以通过屏幕截图,采样归档。
3 多种扫描模式下的文献质量测评
3.1 多种模式下的数字化文献测量
数字化文献的图像质量,就是文献每个页面的图像质量的平均。每个页面的图像质量虽然跟原有文献的质量有着直接关系,但数字化过程中扫描模式的设置以及页面的预处理,也在很大程度上影响着一幅图像的质量。这里采用HP服务器的广告页面作为数字化的源文献,页面为奶油背景色,文字有黑白的、有彩色的,还有internet网址,是测量数字化的良好选择。扫描仪是方正z3000,其分辨率是1600x1600dpi。选用清华同方的Cajviewer测量OCR文字识别准确率。图像质量的测量采用MATLAB平台上的全盲图像测量软件Natural Image Quality Evaluator (NIQE)[12]。
利用NSS像素和相邻像素之间的对数规律及图像与距离预测系数矩阵,得出了较好的图像质量评估值,建立了客观评估值与图像内容的相关性,而且运算方便,精度高。
扫描时共分七个分辨等级,分别是75、100、200、300、400、600、1200(DPI),扫描模式分4个等级,即黑白(bw)、四阶灰色(gray)、256彩色(8bit)、真彩色(24bit)。所有的扫描图像都用PHOTOSHOP倾斜矫正、页面切割等预处理,以避免次要因素影响到最终的结果评析。这些扫描图像最终形成PDF格式的文献,以便阅读和测量。
软件在进行OCR识别时,能够识别半个字符或者大句号识别为小句号的,文字错误值设定为0.5。图像质量的测量值越小表示图像质量越高。得到的图像质量测量值如表1所示,文字识别错误值如表2所示。
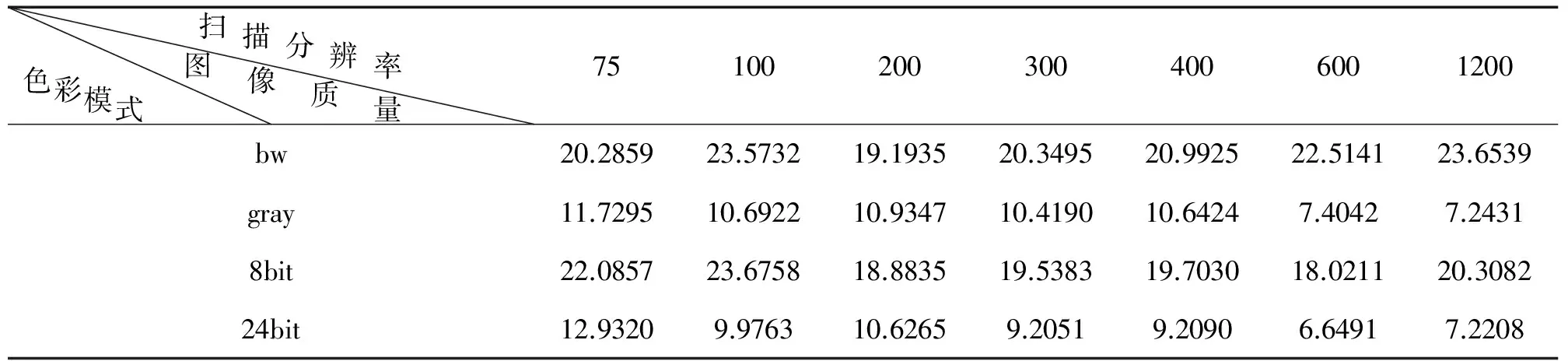
表1 图像质量测量值

表2 文字识别错误值
3.2 测量结果评析
为了直观、方便地分析测量结果,下面给出了图像质量测量值和文字识别错误值的二维坐标图,如图1、图2所示。
根据图1和图2的结果分析,不难得出以下结论:
(1)从图1可以看出扫描模式为bw黑白模式下,扫描分辨率设为200DPI,图像质量值最低,表明此时图像质量最佳,随着分辨率的增高反而图像质量值增大,图像质量越差;对于gray灰度模式、8bit彩色模式、256bit真彩模式下,扫描分辨率在600DPI处,图像质量值最低,图像质量最佳。因此对于不同类型的文献,为了保证数字化后文献质量,可以采用不同的分辨率。如水墨画、油画等的数字化,扫描模式分辨率可以选择600DPI以上,同时选择真彩模式。而黑白的纯文本(包含发黄的古籍文献)类型的数字化,分辨率可以选择200至400DPI之间,甚至只考虑200DPI的分辨率。
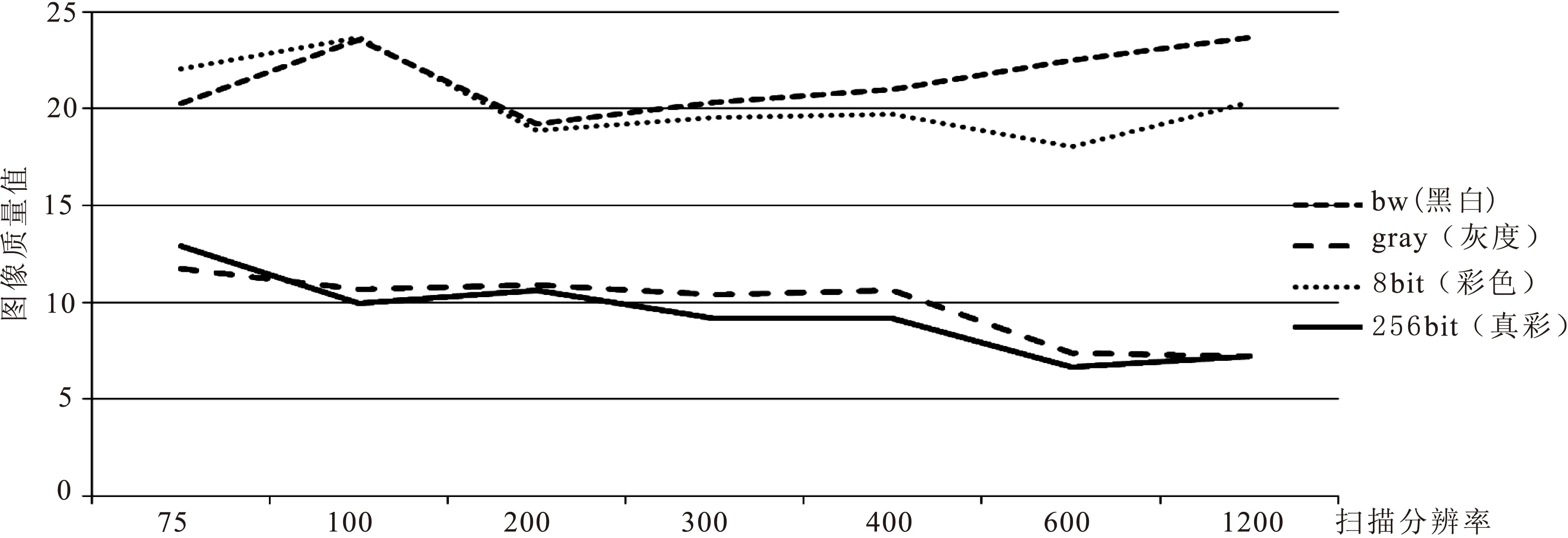
图1 图像质量值

图2 文字识别错误率
(2)从图2可以看出,分辨率在75-200DPI之间时,各种扫描模式的文字识别错误个数均产生了一个很大的跃变,分辨率在75DPI处的文字识别错误个数甚至远远超过19;扫描分辨率在200-400DPI之间,图像质量整体比较稳定,但是文献扫描模式设为8bit彩色模式时,分辨率在300DPI处文字的识别错误个数发生明显跃变,故应避免将分辨率设在300DPI附近;当分辨率设在400DPI-1200DPI之间时,黑白、灰度及彩色模式下文献识别错误率都很理想,近乎为零,但扫描模式为24bit真彩色模式,扫描分辨率在600DPI处文字的错误率发生明显的跃变。这主要是由于扫描仪内核软件插值所致,因此24bit真彩色模式下分辨率设为300-400DPI或1200DPI时文献质量最优。因此,在实际工作中进行文献数字化时,需要考虑机器分辨率的范围,扫描分辨率也必须避开扫描仪内核软件插值后的分辨率,不能简单地认为数字化时分辨率越高文献质量越好。
(3)数字化工作可以从质量评估开始。在实际进行数字化工作时,应首先进行源文献的质量评估,然后进行不同扫描模式下文献质量测评;根据测评结果再进行大规模的数字化。不同模式的文献质量测量值可以相互参考,但不能直接比较,如黑白的图像质量值是19,真彩色的图像测量值为13,却不能表明黑白模式的文献质量比真彩模式的文献质量差。
研究选取图像的视觉感知重要区域作为考察对象,一方面它提供了可靠的线性规律,另一方面它可以很好的解决客观评价值与图像内容相关性的问题。原始图像视觉感知重要区域的子带能量在对数域内具有很强的线性规律,而失真图像却会破坏这种规律。以上是比较宏观的描述,在具体评价的时候,可以从影像各个波段的最小值、最大值、值域、均值、标准差、波段间的协方差和相关系数等具体定量指标进行确认[14]。
4 结语
文献数字化不但是数字图书馆实现的前提条件,也是个人进行科学研究可以借用的手段。如何保证文献数字化能够阅读舒服、引用方便是文献数字化一直研究的课题。利用IQA(Image Quality Assessment)图像质量评价体系对数字化文献的质量进行评估,可以为文献的数字化提供一种客观的尺度,可以使得用户在具体文献数字化时有了精细的参考。
文献数字化要保证理想的质量,还必须考虑到不同的文献类型。文献类型不一样,具体数字化时的要求也不一样。基于IQA的数字化文献质量评估方法,还可以根据不同类型的文献,测定出理想参数,帮助用户数字化时取得比较好的效果;同样是书画,但不同时期的书画有着各自的理想系数,这也能使其数字化时多一个参考。
[1] 宋琳琳,李海涛.大型文献数字化项目元数据互操作调查与启示[J].中国图书馆学报,2012(5):27-38.
[2] 杨勇.图书馆馆藏文献数字化建设若干问题的思考[J].大理学院学报,2006,5(3):53-57.
[3] 李国新.中国古籍资源数字化的进展与任务[J].大学图书馆学报,2002,20(1):21-26.
[4] 朱成林,袁曦临.中国古籍的数字化导读研究[J].图书馆建设,2014(11):50-55.
[5] 中文OCR软件横向评测 汉字识别 谁强谁弱?[J].电子计算机与外部设备,2000(5):84-87,89-91,93-94.
[6] 刘金荣.古籍资源数字化过程中的问题[J].吉林省教育学院学报(下旬),2015(8):144-146.
[7] 王紫剑.馆藏陈旧版本乐谱的数字化与应用[J].黑龙江史志,2014(17):278-279.
[8] 张殿东,包常新,温尚卓.OCR技术在银行票据识别系统中的应用[J].山东科学,2005(2):68-70.
[9] D. J. Field.Relations between the statistics of natural images and the response properties of cortical cells[J]. Journal of Optical Society of American, vol. 4, no. 12, Dec, 1987.
[10] 金波.基于自然图像信息统计的无参考图像质量评估研究[D].无锡:江南大学,2012.
[11] 楼斌.基于NSS与HVS的图像质量评价方法研究[D].杭州:浙江大学,2009.
[12] A. Schaaf and J. H. Hateren. Modelling the Power Spectra of Natural Images:statistics and information[J]. Vision research, 1996,36(17):2759-2770.
[13] Naturalness Image Quality Evaluator (NIQE)[EB/OL]. [2015-10-14].http://live.ece.utexas.edu/research/Quality.
[14] 付伟,顾晓东,汪源源. 基于人眼视觉特性的彩色图像质量评价[J].微电子学与计算机,2010(2):59-63,67.
(责任编辑:王靖雯)
Research on Image Quality Assessment of Digitalized Document with IQA
ZHANG Hai-yan
(Nanjing University of Information Science and Technology, Nanjing 210044, China)
IQA is an objective method to evaluate the quality of digital documents. In this paper, IQA is used to measure the image quality and text recognition error in different scanning modes and different scanning resolutions. The study finds that the quality level of digital documents is not completely determined by the scan resolutions. In the conventional scanning mode of black-white and fourth order gray-scale, the higher scan resolution doesn’t lead to the better image quality. The best image quality is obtained when its measured value is the lowest with the 200-400 DPI resolution. Based on the analysis of the fluctuation of the measured value, the paper further gives the ideal scanning resolution range of the literature digitization in different modes.
document digitization; document scanning; IQA; Image Quality Assessment
南京信息工程大学图书馆科技项目(nl-2015001);南京信息工程大学实验室开放项目(15KF046)
G255
A
1006-1525(2016)06-0046-05
张海燕,女,馆员。
2016-02-22
