一种大规模网络数据缓存方法的改进
2016-11-30余光华
余光华
(岭南师范学院 网络与信息中心,广东 湛江 524048)
一种大规模网络数据缓存方法的改进
余光华
(岭南师范学院 网络与信息中心,广东 湛江 524048)
针对传统的网络海量数据缓存方法中容易出现数据丢失和召回错误,数据访问和调度性能差等问题,提出一种大规模网络海量数据缓存方法的改进方法.构建网络缓存空间的数据分布结构模型,进行大规模网络海量数据的信息流模型构建和时间序列分析.采用模糊C均值聚类算法对提取的关联维特征进行聚类处理,实现缓存模型优化.仿真结果表明,采用该方法进行大规模网络海量数据缓存优化设计,有效降低缓存开销,扩展缓存空间,数据的吞吐性和召回性等指标参量优于传统方法.
网络;海量数据;相空间重构;关联维
0 引 言
随着网络信息技术的发展,大量的文件、文字、图片、声音和视频等数据信息通过网络进行传输和通信,形成大数据网络空间.网络是大数据信息的资源池,在网络空间中,大规模网络数据以几何级数增长,形成海量网络数据在网络信道中存储和通信,大规模海量网络数据在网络中存储方式主要有两种,一是以Deep Web数据库为代表的云存储资源数据库,实现对海量数据的永久性存储,方便用户检索和访问;二是以数据寄存器为代表的网络缓存区,通过数据缓存实现对即时数据的实时访问和调度,缓存数据具有暂时性和实时性等特点,数据缓存区不占用用户和网络的存储空间,具有实时高效访问调度的优点,受到广泛应用.通过设计大规模海量数据缓存方法,提高数据的即时调度和存取能力,研究大规模网络海量数据缓存改进方法具有重要意义.
传统方法中,数据缓存方法主要有基于模糊C均值聚类的数据缓存模型、基于特征子空间建模的数据缓存算法、基于决策树模型构建的数据缓存算法、基于串口寄存器级联配置的数据缓存系统设计方法等[1-3].上述方法采用对缓存数据的优化聚类分析和特征提取方法,实现缓存数据的实时调度和访问,提高数据缓存的特征指向性,降低缓冲容量,取得一定的研究成果.文献[4]提出一种基于列表的循环堆栈控制大规模网络数据缓存方法,在存储架构模型中,采用PCI总线扩展,进行存储软件设计,但是该方法的数据传输和缓存架构总线协议设计过程比较复杂,数据存储和计算的开销较大;文献[5]提出一种负载均衡调度的海量数据存储优化架构设计方法,实现海量网络数据的缓存优化,降低数据存储开销,但该缓存系统在进行海量数据存储过程中,受到缓存数据吞吐容量和性能约束,降低数据缓存的召回性能,数据访问调度准确性不好;文献[6]采用存储区域自动筛选控制的网络海量数据缓存方法,随着存储量和干扰增大,数据缓存中会出现数据丢失和召回错误,影响数据访问和调度性能.因此,本文提出一种大规模网络海量数据的缓存改进方法,并通过仿真实验进行性能测试,数据缓存的指标性能优于传统方法.

图 1 大规模网络海量数据缓存系统输入输出模型Fig.1 Input and output model of large-scale network mass data cache system
1 数据分布结构分析与数据信息流构建
1.1 网络缓存空间的数据分布结构模型
为实现对大规模网络海量数据缓存方法优化设计,进行网络缓存空间的数据分布结构分析,在大型网络数据存储系统中,数据存储内核由内部层次属性进行数据调度和I/O输入,网络内部存储器通过采样数据缓冲区实现响应内核中断,采用四元组(Ei,Ej,d,t)表达决策树模型下数据缓存的主特征,构建大规模网络海量数据缓存系统的信息特征采样模型,设A⊂V,B⊂V且A∩B=φ,进行数据结构分析,缓存数据副本放置于合适站点时,建立数据缓存区语义节点本体信任关系模型,实现数据层次化访问和缓存调度[7-15],根据上述分析,得到大规模网络海量数据缓存系统输入输出模型,如图1所示.

(1)
其中:上角标θ(t)表示数据合并集的谐振函数.大规模网络海量数据缓存空间的训练样本可通过数据聚类的属性集实现包络特征分解,特征分解的表达式为
(2)
其中:s(t)为缓存区的大数据标量时间序列;h(t)表示数据抗干扰滤波函数;H[s(t)]表示数据结构特征分布响应函数. 通过构建网络缓存空间的数据分布结构模型,实现对大规模网络海量数据结构分析,在此基础上,进行缓存数据的信息流模型构建和特征提取.
1.2 大规模网络海量数据信息流模型构建
大规模网络海量数据信息流在缓存区根据标签划分为(TagBlock)个时间片,在缓存区采集数据集合S,当X⊆U,R⊆A条件成立时,各个存储子集间组成一组非线性时间序列,大规模网络海量数据在缓存区的信道状态响应函数表达式为
(3)
根据数据随机概率分布校验集,构建大规模网络海量数据的目标端信息分量,采用多普勒频移特征表示大规模网络海量数据从存储目标端到远端存储节点的校验数据块结合,即
(4)
其中:yb表示大规模网络海量数据在缓存区的频率变化量;y0为大规模网络海量数据在数据传输信道内的载波频率;z表示传输脉宽.在此基础上,在数据信息流的分数阶Fourier域中构建缓存数据的随机概率分布函数为
(5)
在网络缓存区域中,采用时频特征分解方法进行网络数据信息流幅度调制,幅度调制的展开结果为
(6)

图 2 大规模网络海量数据的信息流模型Fig.2 Large-scale network information flow model of huge amounts of data
当客户端发出文件存储请求时,将存储系统中加权权重ωk按照vk和ek进行协方差分解,得到网络缓存存储节点的自适应控制加权权重ω(ek,uk),以此为基础计算文件服务器中的数据缓存校验信息存储子集,计算式为

(7)
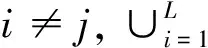
2 网络海量数据缓存方法优化实现
2.1 网络海量数据相空间重构和关联维特征
在上述构建大规模网络海量数据的时间序列分析模型的基础上,进行大规模网络海量数据缓存方法优化设计.传统方法采用存储区域自动筛选控制的网络海量数据缓存方法,随着存储量和干扰的增大,数据缓存中容易出现数据丢失和召回错误.因此,本文提出一种基于大规模缓存数据信息流相空间重构和关联维特征聚类的网络海量数据优化缓存模型,对网络海量数据时间序列进行相空间重构.根据Takens嵌入定理,把大规模缓存数据信息流通过高维空间映射重构在相空间模型中,得到大规模缓存数据信息流相空间重构的光滑流场函数
(8)
对于Φ:M→R2d+1,大规模缓存数据信息流的相空间轨迹满足:
(9)
对于大规模缓存数据时间序列{x(t0+iΔt)}, i=0,1,…,N-1,计算嵌入矢量的概率密度特征为
(10)
其中:在tn+1时刻和tn时刻之间数据序列存在关联特征.采用关联维指数特征分解,得到缓存数据信息流的相空间重构公式为
(11)
其中:x(t0)表示大规模网络海量数据在嵌入相空间中的非线性差分矢量;Δt是缓冲区对数据的采样时间间隔,满足K=N-(m-1)J.在上述重构的相空间中进行关联维特征提取,大规模网络海量数据分布的缓存区为一个多层节点的相轨迹子空间,采用多径向量重组进行关联维特征分解,得到多径重组规律定义为
(12)
当相空间重构的时延参数满足最优特征分解时,进行关联维特征提取的平均互信息函数为
(13)
(14)
对大规模网络海量数据进行最近邻点联合概率分布重组,对提取的关联维特征在相空间中进行低维轨线映射,得到输出的关联维特征集合,在重构的相空间中进行关联维特征提取. 关联维特征集合为
(15)
其中:τ表示嵌入式时延;pi表示大规模网络海量数据时间序列x(t)出现在相空间特征轨迹的概率;pij(τ)表示x(t)出现在相空间的近邻点区域i的联合概率.以上述特征提取结果为输入数据,进行特征聚类处理和缓存算法改进设计.
2.2 数据缓存方法优化实现
根据上述网络海量数据相空间重构和关联维特征,采用模糊C均值聚类算法对提取的关联维特征进行聚类处理,降低数据缓存开销,实现缓存模型优化.算法改进实现的过程描述如下:对大规模网络海量数据进行模糊C均值聚类的特征核函数为
(16)
在m维相空间中计算数据聚类的融合中心,实现缓存区域识别,得到数据聚类中心为
(17)
随着m增加到(m+1),模糊C均值聚类中心收敛,对于两个标量数据时间序列y1和y2,通过模糊C均值聚类把缓存数据分为若干数据块,进行缓存区域的自适应分区识别,识别数学模型为
(18)
信息流通过远端存储节点进行自适应重组,提高数据存储的空间,此时,在缓存区域数据信息流形成新的映射,即
(19)
在重构的相空间中,采用模糊自适应控制方法,结合C均值聚类,进行迭代运算,计算第i点xi和第j点xj的关联维信息特征,把提取的信息关联到缓存区域S-Table上.通过上述算法处理,提高了数据缓存的空间区域,降低了数据存储开销,实现了算法的改进.
3 仿真实验与性能测试
通过仿真实验,测试本文设计的大规模网络海量数据的数据缓存优化方法的性能实验中,通过串口总线、VXI总线、CAN总线构建网络数据的传输、通信和数据采集调度模块,采用高速模块内部触发机制进行数据缓存区域的总线控制.实验的硬件环境及技术指标为:RAM缓冲区的D/A分辨率为13位,采样数据在缓冲区通过PCI总线及桥接电路进行循环跟踪控制,RAM中含有32MB的外部存储空间.采用Matlab仿真工具,进行大规模网络海量数据的缓存仿真,首先进行海量数据的外部接口片选和时间序列采样,设定RCR[1,2]和XCR[1,2]作为采样函数,大数据缓存系统内配置引脚寄存器,采样数据量从100MB到1GB进行线性增长,得到大规模网络数据的时间序列波形,对网络海量数据时间序列进行相空间重构,在重构空间中进行关联维特征提取,实现数据缓存空间优化.为了对比性能,采用本文方法和传统方法,以大规模网络海量数据在缓存区的空间特征分布为对比,得到结果如图3所示.

(a) 传统方法 (b) 本文方法图 3 大规模网络海量数据在缓存区的空间特征分布Fig.3 Spatial distribution of large scale data in the cache area

图 4 数据缓存区的吞吐性能对比Fig.4 Comparison of throughput performance of data cache
从图3可见,采用本文方法进行大规模网络海量数据缓存优化设计,数据在缓存区的特征分布规则性更好,能有效降低缓存开销,扩展缓存空间.以数据缓存的吞吐性和召回性为指标参量定量分析性能,得到对比结果如图4所示,从图4可见,采用本文方法进行数据缓存的吞吐量较高.计算得知,采用本文方法进行数据缓存调度的召回率为98.67%,比传统方法高5.99%,性能较好,指标参量优于传统方法.
4 结束语
数据缓存区不占用户和网络的存储空间,具有实时高效访问调度的优点,受到广泛应用,本文研究数据缓存优化方法,提出一种基于大规模缓存数据信息流相空间重构和关联维特征聚类的网络海量数据优化缓存模型,结果表明,采用本文方法进行数据缓存的容量较高,在缓存区的数据特征分布更规则,降低了存储开销,提高了数据的吞吐量.
[1] 孙婷婷. 基于五元组的词语搭配自动抽取[J]. 电子设计工程,2015,26(19):75-78.
SUN Tingting. Automatic collocation extraction based on quintuple[J].Electronic Design Engineering,2015,26(19):75-78.
[2] CAO Junwei,LI Keqin,STOJMENOVIC I. Optimal power allocation and load distribution for multiple heterogeneous multi-core server processors across clouds and data centers[J]. IEEE Transactions on Computers,2014,63(1):45-58.
[3] CHONG F T,HECK M J R,RANGANATHAN P,et al. Data center energy efficiency:Improving energy efficiency in data centers beyond technology scaling[J]. IEEE Design & Test,2014,31(1):93-104.
[4] 黄国兵,金勇,贾荣兴,等. 某电能量远方终端双平面网络接口设计[J]. 西安工程大学学报,2016,23(1):102-106.
HUANG Guobing,JIN Yong,JIA Rongxing,et al. Design of double network interface for an energy remote terminal unit[J]. Journal of Xi’an Polytechnic University,2016,23(1):102-106.
[5] 侯森,罗兴国,宋克. 基于信息源聚类的最大熵加权信任分析算法[J]. 电子学报,2015,43(5):993-999.
HOU Sen,LUO Xingguo,SONG Ke. A maximum entropy weighted trust-analysis algorithm based on sources clustering[J]. Chinese Journal of Electronics,2015,43(5):993-999.
[6] 张普宁,刘元安,吴帆,等. 物联网中适用于内容搜索的实体状态匹配预测方法[J]. 电子与信息学报,2015,37(12):2815-2820.
ZHANG Puning,LIU Yuan′an,WU Fan,et al. An entity state matching prediction method for content-based search in the internet of things[J].Journal of Electronic and Information Technology,2015,37(12):2815-2820.
[7] 马其琪,鲍爱达. 基于DDR3 SDRAM的高速大容量数据缓存设计[J]. 计算机测量与控制,2015,23(9):3112-3113.
MA Qiqi,BAO Aida. High speed and large capacity data buffer design based on DDR3 SDRAM[J]. Computer Measurement & Control,2015,23(9):3112-3113.
[8] 史玉良,王捷. 一种多租户云数据存储缓存管理机制[J]. 计算机研究与发展,2014,51(11):2528-2537.
SHI Yuliang,WANG Jie.A multi-tenant memory management mechanism for cloud data storage[J]. Journal of Computer Research and Development.2014,51(11):2528-2537.
[9] 周恩强,张伟,卢宇彤,等. 一种面向大规模数据密集计算的缓存方法[J]. 计算机研究与发展,2015,52(7):1522-1530.
ZHOU Enqiang,ZHANG Wei,LU Yutong,et al. A cache approach for large scale data-intensive computing[J]. Journal of Computer Research and Development.2015,52(7):1522-1530.
[10] CATTIVELLI F S,SAYED A H. Distributed detection over adaptive networks using diffusion adaptation[J]. IEEE Transactions on Signal Processing,2011,59(5):1917-1932.
[11] 杨诗琦,虞红芳,罗龙. IP网络中的快速路由微环避免算法[J]. 计算机应用,2015,35(12):3325-3330.
YANG Shiqi,YU Hongfang,LUO Long. Fast routing micro-loop avoidance algorithm in IP network[J]. Journal of Computer Applications,2015,35(12):3325-3330.
[12] CLAD F,MERINDOL P,PANSIOT J J,et al. Graceful convergence in link-state IP networks:A lightweight algorithm ensuring minimal operational impact[J]. IEEE ACM Transactions on Networking,2014,22(1):300-312.
[13] MOGHADAM A A,KUMAR M,RADHA H. Common and innovative visuals:A sparsity modeling framework for video[J]. IEEE Transactions on Image Processing,2014,23(9):4055-4069.
[14] ALEXE B,DESELAERS T,FERRARI V. Measuring the objectness of image windows[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2189-2202.
[15] 崔永君,张永花. 基于特征尺度均衡的Linux系统双阈值任务调度算法[J]. 计算机科学,2015,42(6):181-184.
CUI Yongjun,ZHNAG Yonghua. Linux system dual threshold scheduling algorithm based on characteristic scale equilibrium[J]. Computer Science,2015,42(6):181-184.
[16] 陈志涛. 高吞吐量抗干扰性物联网混合服务器协议设计[J]. 科技通报,2014,30(4):65-67.
CHEN Zhitao. Design of protocol for hybrid server with high output capacity and anti-interference in internet of things[J]. Bulletin of Science and Technology,2014,300(4):65-67.
[17] 陆兴华,陈平华. 基于定量递归联合熵特征重构的缓冲区流量预测算法[J]. 计算机科学,2015,42(4):68-71.
LU Xinghua,CHEN Pinghua. Traffic prediction algorithm in buffer based on recurrence quantification union entropy feature reconstruction[J]. Computer Science,2015,42(4):68-71.
编辑、校对:赵 放
An improve data caching method for large scale network
YU Guanghua
(Network and Information Center,Lingnan Normal University,Zhanjiang 524048,Guangdong,China)
In view of the problems of traditional method of the storage area network mass data cache method, such as prone to loss of data in the data cache and recall errors, data access and poor scheduling performance, an improved method of large-scale network mass data caching method is put forward. Web cache space structure model of the distribution of data is constructed as well as a large scale network information flow model of huge amounts of data and time series analysis. Fuzzy C-means clustering algorithm is used to cluster the extracted, correlation dimension characteristics,fufilling caching optimization model. The simulation results show that this method effectively reduces the cache overhead, extends the cache space,and indices such as throughput and recall of the data parameter are superior to those of traditional methods.
network; massive data;phase space reconstruction; correlation dimension
1674-649X(2016)04-0504-06
10.13338/j.issn.1674-649x.2016.04.017
2016-03-15
余光华(1979—),男,江西省武宁市人,岭南师范学院实验师,研究方向为计算机网络技术.E-mail:Ygh168@163.com
余光华.一种大规模网络数据缓存方法的改进[J].西安工程大学学报,2016,30(4):504-509.
YUGuanghua.Animprovedatacachingmethodforlargescalenetwork[J].JournalofXi′anPolytechnicUniversity,2016,30(4):504-509.
TP
A
