基于Fisher比的Bark小波包变换的语音特征提取算法
2016-11-30王晓华蒋细伟
王晓华,屈 雷,张 超,蒋细伟
(西安工程大学 电子信息学院,陕西 西安 710048)
基于Fisher比的Bark小波包变换的语音特征提取算法
王晓华,屈 雷,张 超,蒋细伟
(西安工程大学 电子信息学院,陕西 西安 710048)
为解决MFCC特征参数在噪声环境中识别率低的问题,提出一种基于Fisher比的Bark小波包变换特征提取算法.首先采用小波包变换构造Bark滤波器代替三角形的Mel滤波器.其次采用Fisher对Bark滤波后的特征参数进行选择,去除大量干扰信息,节省特征匹配的时间.仿真实验表明,该算法明显提高系统的识别率和鲁棒性.
Fisher;Bark;小波包变换;MFCC;说话人识别
0 引 言
随着社会发展和科学技术的提高,说话人识别技术的研究取得飞速的发展[1-3].在说话人识别流程中最重要的一个环节是特征提取,通过对说话人语音信号的个性特征进行处理获得特征参数,是直接影响说话人识别系统性能的根本原因[4-5].
语音信号特征提取方法大致分为以下几类:(1)基于时域处理方法,通过短时过零分析、短时自相关函数、平均幅度差等方法提取特征参数,这些方法简单、运算量小、物理意义明确,但不适合在噪声环境中使用;(2)基于频域处理的方法,通过短时傅立叶变换(STFT)[6]、小波变换[7]、Wigner分布[8]、倒谱分析[9]等方法提取特征参数,这些方法与语音感知过程密切相关,在安静环境中表现很好,但对于噪声环境中仍需继续研究;(3)基于概率论方法,通过线性判别分析[10]、主成分分析[11]、独立分量分析[12]等方法提取特征参数,这些方法比较复杂,需要大量原始数据提取特征,运算量很大,但效果不错;(4)基于新理论的方法,通过混沌理论[13]、分形理论[14]等方法提取特征参数,这些算法的运算量大,只适用于一些特定的噪声,具有一定的局限性.
最常用的MFCC参数在纯语音下测试的识别率可以高达99.5%,但是在噪声环境中测试的识别率仅为60%[15].文献[6]对MFCC识别率低的原因进行了深入的分析,表明纯语音的特征参数和加噪语音的特征参数差异明显,各维参数分布已经产生变化,变化会随噪声的增强而加剧,识别率必然下降.在MFCC特征参数提取过程中,时频分析采用的是STFT,它对平稳信号进行分析会产生很好的效果.但是对于非平稳信号进行分析时,不仅要具有较高的频率分辨率,还要具有较高的时间分辨率,STFT在这种情况下不能兼顾[6].小波变换的特点是多分辨率分析,适合分析复杂多变的语音信号.
人耳能够在嘈杂的环境中分辨出说话者,具有很强的抗噪性,因此在提取特征参数时引入人耳听觉特征比其他特征参数有更好的鲁棒性[16].通过Mel频率构造的Mel滤波器组在频率上重叠,使用小波包变换直接构造Mel滤波器组比较复杂.但可以使用另一种听觉特征Bark尺度感知特征,结合小波包对频带进行划分,构造出新的特征参数.该特征参数维数较多,各维参数对识别效果的贡献不一样.融入概率论的方法,采用Fisher比对参数进行选择,获得了新的特征参数.
1 新的特征值提取算法
1.1 Bark尺度感知频率
在1961年Eberhard Zwicker根据人耳基底膜特征提出了Bark尺度,根据人耳掩蔽效应的实验结果,Heinrich Barkhausen等提出频率群的概念,将20~220 50Hz的频率可以划分为25个频率群.人耳基底膜被大脑分为很多小模块,每个模块都与一个频率群相对应并负责该频率的语音信号,每次人耳获得一段语音信号时,大脑都会对这些频率群进行叠加处理,成为人们所了解的语音[17].Bark尺度频率b与实际频率f的转化关系为
f=600sinh(b/6).
(1)
实验得到的频率群满足公式(1),根据该频率群的每个中心频率、带宽、上下限频率设计Bark滤波器.
1.2 Bark尺度的小波包变换
小波包变换可以灵活地划分频率,构造出与Bark尺度感知频率特性相似的小波包分解结构.对于8kHz采样频率的语音信号(最高频率为4kHz),共包含17个频率群,使用小波包构造这17个频带,小波包分解结构如图1所示.
文献[18]实验表明,语音信号小于600Hz的低频部分和大于3 000Hz的高频部分携带说话人特征较多,详细地划分这2部分的频带可以提高识别率.在上面的分解基础上对低频(小于625Hz)和高频(大于3 000Hz)细分,即图1中矩形框中的节点再分解一次,最后得到24个频带.将这些频带从低频到高频排列,获得每个节点的频率范围如表1所示.
1.3 小波函数的选择
在小波包变换中,小波函数的选择会影响到计算速度和语音信号的有效性,选取合适的小波函数具有重要意义.在特征参数提取时,只在Bark尺度对语音信号进行小波包分解,不需要进行信号重构,所以线性相位的要求不必考虑.在计算特征参数的过程中,采用每个频带能量作为说话人的特征信息,要求小波函数具有可以保证小波包分解过程中能量不丢失的正交性.随着Daubechies(db)小波阶数N的增加,小波函数和尺度函数的时域波形愈发平滑,频谱成分也愈发密集,滤波器的频率特性也就更好.在实际应用中应考虑时频分辨率和计算速度的要求,采用db6小波是一种比较合理的选择[19].

图 1 Bark尺度小波包变换的分解结构Fig.1 Decomposition structure diagram of Bark scale wavelet packet transform
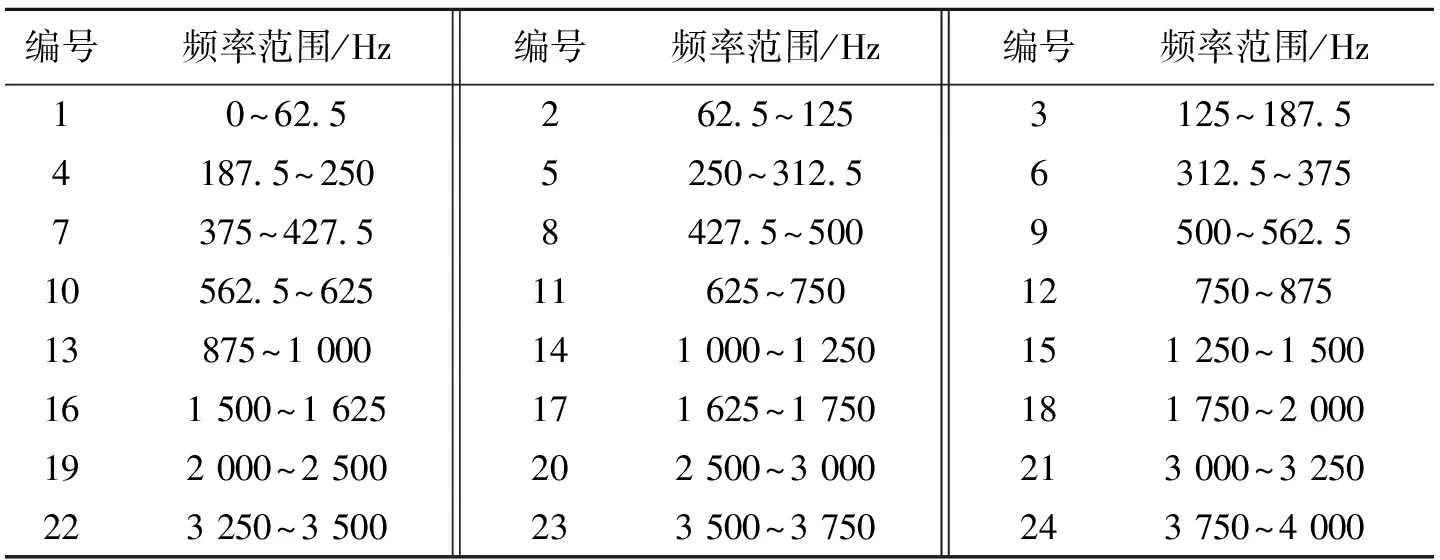
编号频率范围/Hz编号频率范围/Hz编号频率范围/Hz10~6252625~1253125~187541875~2505250~312563125~3757375~427584275~5009500~5625105625~62511625~75012750~87513875~1000141000~1250151250~1500161500~1625171625~1750181750~2000192000~2500202500~3000213000~3250223250~3500233500~3750243750~4000
1.4 Fisher比的特征选择
为保证识别效果,MFCC特征参数用于说话人识别需要20~30维特征,虽然多维特征丰富了特征信息,但各维参数对识别效果的贡献不同.这样就出现了大量的干扰信息,降低识别速度而且有可能降低识别效果.所以必须对特征参数进行选择.
在模式识别中,Fisher准则是将特征向量投影到最佳方向而获得最大的类间距离.1964年,Bell实验室的Pmzansky和Matllews在Fisher准则的基础上提出方差之比(F比),并将其作为有效的度量说话人特征参数准则,定义为

(2)

F值越大,表示某一维特征更适合成为说话人的个性特征.实验表明,经Fisher比选择后的特征参数可以更有效地表征说话人的个性特征,提高识别系统的识别效率[10].
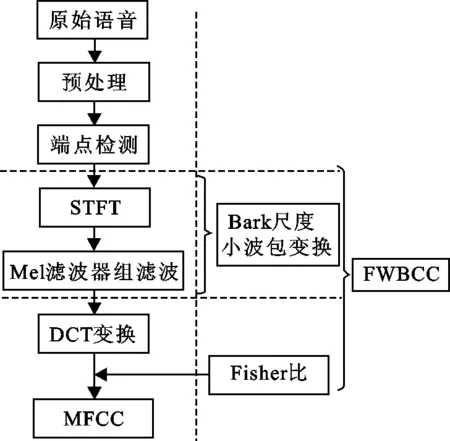
图 2 MFCC和FWBCC的提取过程对比Fig.2 Comparison of extraction process of MFCC and FWBCC

图 3 WBCC和一阶差分参数各维Fisher比Fig.3 Each dimension Fisher of WBCC and first-order differential parameters

图 4 说话人识别系统测试界面Fig.4 Test interface of speaker recognition system
1.5 构造新特征参数
通过db6小波进行Bark尺度小波包变换,将语音信号分解在24个频带内,之后构造每个频带的特征参数.将新特征参数命名为Fisher比Bark小波包倒谱系数(FWBCC),其提取流程与MFCC类似.不同之处在于:(1)使用小波包变换代替了STFT;(2)采用了Bark尺度代替了Mel尺度;(3)使用Fisher比对特征进行选取.图2为MFCC和FWBCC的特征参数提取过程对比.
FWBCC提取的具体步骤描述如下:
(1) Bark尺度小波包变换,对语音信号预处理和端点检测后,将获得的每帧语音信号进行Bark尺度小波包变换,求出24组频带的小波包系数(每组系数个数不同);
(2) 计算频带能量,第n帧第m个频带能量按照如下公式计算得到:

(3)
式中:Wn(m,k)表示一帧语音小波包变换系数;Nm表示第m个频带中小波包变换系数个数.
(3) 计算DCT倒谱,将24维频带能量通过DCT变换,一般取前12维的数据进行计算:

(4)
(4) Fisher比选择,特征参数中加入动态特征,可以提升系统的识别性能,所以对得到的WBCC静态特征需要进行一阶差分处理得到相应的动态特征.根据式(2)计算出12维WBCC和12维一阶差分动态特征中每一维的Fisher比,如图3所示,可以发现特征参数每一维的贡献是不同的.根据Fisher比的大小,选出WBCC的第2,3,8,10,11,12维和一阶差分参数的第3,4,6,9,10,11维.
通过上述4个步骤从WBCC和一阶差分参数中各选出Fisher比最大的6组,组合成12维的特征参数就是文中根据Fisher比的Bark尺度小波包变换提取的FWBCC特征参数.
2 仿真实验与分析
2.1 实验配置
在Matlab软件环境下编写测试界面如图4所示,对特征提取算法进行实验测试.
训练数据来自安静环境下获得的15人(10男5女)语音,以8kHz为采样率,16bit量化.语音为10个数字(0~9),每个数字录音大约是1s,共10s,录20次语音为训练数据,通过端点检测[20]将语音信号分割后作为每个数字的训练模板,即每个人有10个对应不同的数字的模板.识别测试数据是根据录音提示在安静环境下录制4~9位的数字,作为说话人识别测试的原始数据.
2.2 实验结果及分析
为了验证使用FWBCC特征后系统的准确性,在实验室中进行测试.根据界面文本提示录音,先对语音信号进行预处理和端点检测,获得一帧一帧的语音信号,对每一帧数据分别提取24维MFCC特征(包括一阶差分参数)、24维WBCC和12维的FWBCC特征参数,最后使用VQ建立模型进行测试,实验结果如图5所示.
为了验证使用FWBCC特征后系统的鲁棒性,分别将测试的原始数据与white噪声混合成信噪比(SNR)为20dB、10dB、5dB、0dB的带噪语音信号,进行实验测试(8位数字),实验结果如图6所示.

图 5 3种特征参数的识别结果折线图 图6 4种SNR下的两种特征参数的识别结果折线图 Fig.5 The recognition results of three kinds of feature parameters Fig.6 The recognition results of the two feature parameters in four SNR
根据以上实验结果可以得出:
(1) 改进的特征参数的识别效果比MFCC好,识别率有所提高.因为改进的特征参数采用了小波包变换进行分析,可以更好获得非平稳性的说话人特征,具有更好区分能力.
(2) FWBCC特征参数的识别效果比WBCC略好.WBCC特征参数通过Fisher比选择后,排除大量的干扰信息,获得贡献率更好的特征参数FWBCC,识别结果要高于WBCC参数.虽然识别率提高的很小,但是特征维数压缩了一半,提高系统的运算速度.
(3) 文本位数越多识别效果越好.因为提示文本越多,提取特征后信息量也越大,识别率会提高.但是识别速度会下降,当文本位数为8位时效果最好.
(4) 随着环境噪声的增大,系统的识别率下降.使用MFCC特征参数的识别率下降20%左右,而使用FWBCC特征参数的识别率仅仅下降6%左右,所以,使用FWBCC特征参数的系统鲁棒性较好.
3 结束语
对常用的MFCC提取算法进行改进,提出基于Fisher比的Bark小波包变换特征提取算法,以人类听觉系统特征为依据,使用小波包变换在Bark尺度划分频带,计算频带能量,采用Fisher比选择出12维特征参数.实验结果表明,使用该算法提取的FWBCC特征参数进行识别测试,识别率和鲁棒性都有所提高,对说话人识别系统的实际应用具有一定的价值.
[1] LI P,TANG H.Design of a low-power coprocessor for mid-size vocabulary speech recognition systems[J].IEEE Transactions on Circuits and Systems I:Regular Papers,2011,58(5):961-970.
[2] 栗志意,张卫强,何亮,等.基于总体变化子空间自适应的 i-vector 说话人识别系统研究[J].自动化学报,2014,40(8):1836-1840.
LI Zhiyi,ZHANG Weiqiang,HE Liang,et al.Total variability subspace adaptation based speaker recognition[J].Acta Automatica Sinica,2014,40(8):1836-1840.
[3] 李云红,李子琳.基于DSP的语音识别系统设计[J].纺织高校基础科学学报,2012,25(1):107-110.
LI Yunhong,LI Zilin.The design of voice recognition system controller based on DSP[J].Basic Sciences Journal of Textile Universities,2012,25(1):107-110.
[4] DEHAK N,KENNY P J,DEHAK R,et al.Front-end factor analysis for speaker verification[J].IEEE Transactions on Audio Speech & Language Processing,2011,19(4):788-798.
[5] 李爱平,党幼云.VQ声纹识别算法和实验[J].西安工程科技学院学报,2007,21(6):848-851.
LI Aiping,Dang Youyun.Algorithm and experiment of speaker recognition system based on VQ[J].Journal of Xi′an University of Engineering Science & Technology,2007,21(6):848-851.
[6] 胡政权,曾毓敏,宗原,等.说话人识别中MFCC参数提取的改进[J].计算机工程与应用,2014,50(7):217-220.
HU Zhengquan,ZENG Yumin,ZONG Yuan,et al.Improvement of MFCC parameters extraction in speaker recognition[J].Computer Engineering and Applications,2014,50(7):217-220.
[7] 杨丽坤,徐洋.基于小波包变换的加权语音特征参数[J].计算机应用与软件,2014,31(8):168-171.
YANG Likun,XU Yang.Weighted speech feature parameters based on wavelet packet transform[J].Computer Applications & Software,2014,31(8):168-171.
[8] 徐郑丹,于凤芹.基于SPWD时频脊特征提取的汉语声调识别[J].计算机应用与软件,2014,31(3):142-145.
XU Zhengdan,YU Fengqin.Chinese tone recognition based on SPWD time-frequency ridge feature extraction[J].Computer Applications & Software,2014,31(3):142-145.
[9] 甄斌,吴玺宏,刘志敏,等.语音识别和说话人识别中各倒谱分量的相对重要性[J].北京大学学报:自然科学版,2001,37(3):371-378.
ZHEN Bin,WU Xihong,LIU Zhimin,et al.On the importance of components of the MFCC in speech and speaker recognition[J].Acta Scientiarum Naturalium Universitatis Pekinensis,2001,37(3):371-378.
[10] 鲜晓东,樊宇星.基于Fisher比的梅尔倒谱系数混合特征提取方法[J].计算机应用,2014,34(2):558-561.
XIAN Xiaodong,FAN Yuxing.Parameter extraction method for Mel frequency cepstral coefficients based on Fisher criterion[J].Journal of Computer Applications,2014,34(2):558-561.
[11] 马金龙,景新幸,杨海燕,等.主成分分析和K-means聚类在说话人识别中的应用[J].计算机应用,2015,35(S1):127-129.
MA Jinlong,JING Xinxing,YANG Haiyan,et al.Application of principal component analysis and K-means clustering in speaker recognition[J].Journal of Computer Applications,2015,35(S1):127-129.
[12] 董治强,刘琚,邹欣,等.基于ICA的语音信号表征和特征提取方法[J].山东大学学报:工学版,2010,40(4):19-22.
DONG Zhiqiang,LIU Ju,ZOU Xin,et al.Speech signal representation and feature extraction based on ICA[J].Journal of Shandong University:Engineering Science,2010,40(4):19-22.
[13] SONG T,LEE K,KO H.Robust visual voice activity detection using chaos theory under illumination varying environment[C]//International Conference on Consumer Electronics.IEEE:Las Vegas,2014:562-563.
[14] SHAFIEE S,ALMASGANJ F,VAZIRNEZHAD B,et al.A two-stage speech activity detection system considering fractal aspects of prosody[J].Pattern Recognition Letters,2010,31(9):936-948.
[15] SINGH L,CHETTY G.A comparative study of recognition of speech using improved MFCC algorithms and Rasta filters[J].Communication in Computer Information Science,2012,285(1):304-314.
[16] 张晓俊,陶智,吴迪,等.采用多特征组合优化的语音特征参数研究[J].通信技术,2012,45(12):98-100.
ZHANG Xiaojun,TAO Zhi,WU Di,et al.Study of speech characteristic parameters by optimized multi-feature combination[J].Communications Technology,2012,45(12):98-100.
[17] 高明明,常太华,杨国田,等.基于子带主频率信息的语音特征提取算法[J].计算机工程,2009,35(18):161-163.
GAO Mingming,CHANG Taihua,YANG Guotian,et al.Speech feature extraction algorithm based on subband dominant frequency information[J].Computer Engineering,2009,35(18):161-163.
[18] 陈春辉,冯刚.基于听觉小波包自适应语音增强方法[J].华南师范大学学报:自然科学版,2013,45(2):55-59.
CHEN Chunhui,FENG Gang.An adaptive speech enhancement method based on hearing wavelet packet transformation[J].Journal of South China Normal University:Natural Science Edition,2013,45(2):55-59.
[19] 谢军,李乐,刘文峰.振动信号噪声消除中的小波基选择研究[J].科学技术与工程,2011,11(25):5997-6000.
XIE Jun,LI Le,LIU Wenfeng.Research on wavelet base selection for vibration signal denoising[J].Science Technology & Engineering,2011,11(25):5997-6000.
[20] 王晓华,屈雷.基于时频参数融合的自适应语音端点检测算法[J].计算机工程与应用,2015,51(20):203-207.
WANG Xiaohua,QU lei.Self-adaptive voice activity detection algorithm based on fusion of time-frequency parameter[J].Computer Engineering and Applications,2015,51(20):203-207.
编辑、校对:孟 超
Speech feature extraction algorithm based on the Bark wavelet packet transform with Fisher
WANG Xiaohua, QU Lei, ZHANG Chao, JIANG Xiwei
(School of Electronics and Information, Xi′an Polytechnic University,Xi′an 710048, China)
In order to solve the problem of low recognition rate of MFCC parameter, a feature extraction algorithm based on the Bark wavelet packet transform with Fisher is put forward. Firstly, wavelet packet transform is used to construct Bark filter, which can replace the triangular Mel filter. According to the Fisher criterion, feature parameters filtered by Bark filter are adopted, removing the interference information and saving the time of feature matching. Simulation results show that the algorithm is able to enhance the recognition rate and robustness.
Fisher;Bark;wavelet packet transform;MFCC;speaker recognition
1674-649X(2016)04-0452-06
10.13338/j.issn.1674-649x.2016.008
2015-03-14
国家自然科学基金资助项目(61301276);陕西省自然科学基金资助项目(150518);西安工程大学学科资助项目(107090811);国家级大学生创新创业计划训练资助项目(201510709367)
王晓华(1972—),女,黑龙江省齐齐哈尔市人,西安工程大学副教授,研究方向为模式识别、智能机器人.
E-mail:w_xiaohua@126.com
王晓华,屈雷,张超,等.基于Fisher比的Bark小波包变换的语音特征提取算法[J].西安工程大学学报,2016,30(4):452-457.
WANG Xiaohua,QU Lei,ZHANG Chao,et al.Speech feature extraction algorithm based on the Bark wavelet packet transform with Fisher[J].Journal of Xi′an Polytechnic University,2016,30(4):452-457.
TN 912.3
A
