基于进化模糊规则的Web新闻文本挖掘与分类方法
2016-11-26史玉珍吕琼帅
史玉珍, 吕琼帅
(平顶山学院 软件学院,河南 平顶山 467000)
基于进化模糊规则的Web新闻文本挖掘与分类方法
史玉珍*, 吕琼帅
(平顶山学院 软件学院,河南 平顶山 467000)
针对现有Web新闻文本分类方法准确率低且不能适应文本类型变化的问题,提出一种基于进化模糊规则的Web新闻文本挖掘和分类方法.首先,对每篇Web文本进行术语提取,并利用词频-逆向文档频率(TF-IDF)算法过滤掉一些具有较低描述能力的术语.然后,基于计算收集到的新的新闻文本内容与类别之间的余弦距离,利用eClass0分类器创建和更新模糊规则的数量和属性.最后,根据模糊规则推理和余弦距离进行文本分类.实验结果表明,该方法具有较高的正确分类率,且能够自适应Web新闻文本类别的变化.
Web新闻;文本分类;进化模糊规则;余弦距离;词频-逆向文档频率算法
学者提出了多种Web新闻文本分类方法,例如,[1]提出一种基于人工神经网络(ANN)的Web文本分类方法.[2]提出了一种基于K最近邻(KNN)的文本分类器,通过计算待分类文档与其最近的 K个邻近文档之间的距离来进行分类.然而,其分类速度受到训练文档的数量影响.[3]利用信息增益提取文本特征,并基于支持向量机(SVM)进行Web文本分类.然而,上述方法都是将新闻分类为预定义的类别中,没有考虑到Web新闻文本类型的不断变化.为此,本文提出了一种基于进化模糊规则的Web新闻分类方法,对每篇Web文本进行术语提取和术语过滤,形成精简术语集.根据新的新闻文本内容更新模糊规则的数量和属性,自适应文本类型动态变化,最终实现文本分类.实验结果表明,本文方法能够在线处理大规模网页新闻数据且具有较高的正确分类率.
1 本文方法框架
本文基于文本内容,提出一种将Web新闻文本分类到不同类别的分类方法.本文分类器能根据新闻文本内容的改变,动态更新分类器的结构和参数.本文方法的结构主要由两个不同阶段组成:
(1) 文本术语提取:包括术语生成和术语滤波两个步骤,对每篇文本创建术语集合.
(2) 基于进化模糊规则的文本分类:创建和持续更新与获取文本对应的进化模糊规则,并将新闻文本分类到预定义的不同类别中.
2 文本术语提取
术语提取模块用于提取网页中不同话题领域的新闻文本,然后用一组术语总结每篇文本,其中,每个术语都有对应的相关性值.一旦获取分类的新闻文本(Ak),则将该文本作为字符串考虑,并使用接下来两步完成分析:术语生成和术语滤波.
2.1 术语生成
该步骤用于获取每篇文本的最相关性术语.其通过使用数据挖掘和预测分析工具RapidMiner[4]来完成该任务.术语生成步骤如下:
(1) 标记化:将文本流分为短语、单词、符号或其他元素,从而获取标记序列,用于有意义关键词的识别.
(2) 删除无用词:将对文本挖掘无用的词(例如介词、冠词和代词)列入禁用词表,并从文本中删除.以此降低标记序列量,有助于提高系统性能.
(3) 词干提取:从单词中提取出词干.由于一些形式不同的单词的意思可能相同,因此需要根据单词的词干对相同含义的单词进行合并,进一步减少文档中不同术语的数量.
2.2 术语滤波
术语生成模块产生与每个文档相关的术语集合.然而,在所有新闻框架中,也应该考虑不同术语的相关性.为此,在收集过程中,根据整个集合中术语的发生频率,过滤掉新闻语料库中较少出现的术语.
为了给每个术语分配相关值,本文利用一种信息检索方法:词频-逆向文档频率(TF-IDF)算法[5].TF-IDF通过确定特定新闻文本中单词的相对频率,来获取与新闻文本相关的术语关联性(术语词频-逆向文档频率指数).与非常常见的单词相比,较少出现在文本中的单词将存在较高的TF-IDF值.该过程中,每个新闻文本的输出为语料库中每个术语对应的TF-IDF值,用于精简语料库.
3 基于进化模糊规则的文本分类
在本文方法中,基于进化模糊规则分类由两个模块组成:(1)创建进化模糊规则,(2)网页新闻分类.本文基于eClass0分类器[6]创建和更新模糊规则.eClass0是一种基于模糊规则(FRB)的分类器,其使用了由流数据进化而来的模糊规则.特别地,eClass0具有0阶Takagi-Sugeno后项,因此本文模糊规则具有如下结构:

上式中,i为规则数量;n为输入变量(语料库术语)的数量;Ai存储了文本中术语i的TF-IDF值;Proti存储对应类(类别)中其中一个原型(聚类中心)的术语i的TF-IDF值.
3.1 创建进化模糊规则
本文创建进化模糊规则模型中,根据收集到的新闻文本的内容更新规则数量和属性.一旦网页新闻文本被收集和分析,则发送它对应的TF-IDF值到创建进化模糊规则模型中.通过该模型创建的规则数量依赖于同一类别新闻文本的异构性.如[7]中描述,原型是一种数据样本,这些样本群组属于一种特定类.使用第一个数据样本初始化分类器,并作为一种新规则.基于新数据样本作为原型的潜力,产生了一种新原型,并代替现存原型.
如果本文考虑新的新闻文本Ak和它的类别Cj,则根据以下两步更新或创建模糊规则:(1)计算Ak的潜力;(2)更新Ak的所有原型;(3)如果需要,插入Ak作为新原型(类别Cj的原型);(4)如果需要,删除现存原型.接下来将详细介绍这些步骤.
(1) 计算Ak的潜力:根据等式(1)计算第k个新闻文本(Ak)的潜力(P),P描述了新的新闻文本与其他k-1个文本在数据空间中距离累积函数.该函数结果表示围绕某一篇文本的数据密度.

(1)
式中distance表示数据空间中两个新闻文本之间的距离.本文使用余弦距离作为文本之间的距离,因为它能够容忍不同样本拥有不同数量的属性,即两篇文本有不同数量的术语.余弦距离表达式如下:
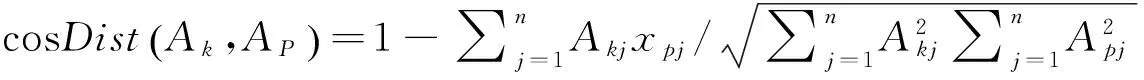
(2)
式中Ak和AP分别表示用于测量距离的两篇新文本,n表示样本间不同属性的数量.
然而,如果使用等式(1),则需要存储所有新闻文本,这与本文提出问题的实时性和在线应用相背.为此,本文提出了一种针对潜力P的递归表达式:
(3)

(2) 更新所有Ak的原型:特定原型周围的数据空间的密度会随着新插入新闻文本而改变,所以需要更新现存原型.递归等式(3)的使用能够有效提高更新速度.
(3) 如果需要,将插入的Ak作为新原型:在这步中,将Ak的潜力与所有现存原型的潜力进行比较.如果该值比其他所有现存原型都高,则创建一种新原型:
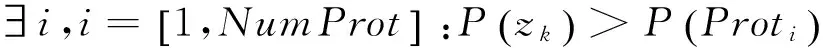
(4)
因此,如果Ak存在较高的描述能力和泛化能力,则通过添加一种新的原型来进化分类器,即添加模糊规则中一种新规则.
(4) 如果需要,将删除现存原型:添加一种新原型后,本文检查是否新添加的原型能很好描述任何现存原型.这意味着描述原型紧密性的隶属度函数值是一种高斯贝尔函数,该函数泛化能力较强:
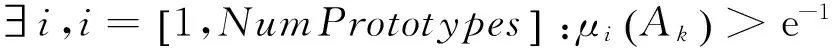
(5)
数据样本与原型之间的隶属度函数计算如下:

(6)
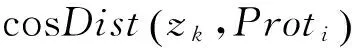
(7)
3.2 模糊规则进化举例
这里举例说明一个“健康”类别的新闻文本的进化模糊规则.将第一次收集的新闻文本创建第一个原型,第一个规则可能是这样的:
初始模糊规则——健康类例子1:
if("hom"~0397) AND ("drug"~02389) AND…AND ("doctor"~01876) THEN Category="HEALTH"
随着不断的收集和处理新的新闻文本,需要进化规则集合.本文举例进化形成的2个不同原型来描述健康类别,可解释性规则表述如下.
进化模糊规则——健康类例子2:
if("hom"~02886) AND ("drug"~03468) AND… AND ("disease"~01876) THEN Category="HEALTH"
if("drug"~03260) AND ("doctor"~04503) AND…AND ("patient" is 03973) THEN Category="HEALTH"
3.3 网页新闻分类
分类模块将一篇新的新闻文本(Az)分类到预先分析的一种类别中.由于一个类别被一个或多个原型描述,因此需要通过余弦距离比较Az和所有原型,并使用最小距离确定最近相似度.如(8)所示:
(8)
式中Az表示需要分类的网页新闻文本,NumProt表示现存原型的数量(规则数量),Proti表示第i个原型,cosDist表示两篇新闻文本之间的余弦距离.
4 实验及分析
4.1 数据集
为了论证本文方法的有效性,从纽约时报在线新闻收集了3 000篇英文新闻文本,且这些文本分为6个类别:艺术、商业、健康、科学、运动和旅行,每类分别拥有500篇新闻文本.为了验证不同数量类别文本场景下的算法性能,创建了包含两种或更多类别的4种数据集:(1)健康vs科学,(2)健康vs科学vs运动,(3)商业vs健康vs科学vs运动,(4)艺术vs商业vs健康vs科学vs运动vs旅行.
首先,根据文本方法中的提取模块来提取3 000篇文本的主要术语.然而,初步提取的不同术语的数量非常多(超过6 000个不同术语),因此本文删除了一些TF-IDF值低于阈值(修剪阈值)的术语.如果设置修剪阈值=1,那么最终的术语数量会降到了300个左右.为了获得最优的修剪阈值,本文进行不同阈值下的分类性能实验,根据实验结果确定最优阈值.
4.2 修剪阈值实验
为了确定最优修剪阈值,本文在不同数据集和不同阈值下进行分类准确性实验.通过删除不具有描述能力的术语能进一步提高新闻文本准确分类率.例如,若本文使用修剪阈值=2,并将新闻文本仅分类到两种类别(科学和健康)时,术语数量从2 892降低到61个,然而,正确分类率从61%提高到87%.因此,该修剪过程对这种环境很有必要.我们可以针对不同的场景设置不同的最优阈值.一般地,当修剪阈值高于1.5时,实验结果比较好.另外,分类类别越多,则分类率越低.这是因为,分类类别越多,错误分类为其他类的概率越大.
4.3 性能比较
为了论证本文方法的性能,将本文方法与其他现有文本分类器进行比较,分别为[1]提出的ANN分类法、[2]提出的K-NN分类法和[3]提出的SVM分类法.其中,对于数据集1和2,设定本文修剪阈值为2.0;对于数据集3和4,设定阈值为1.8.实验结果如表1所示.
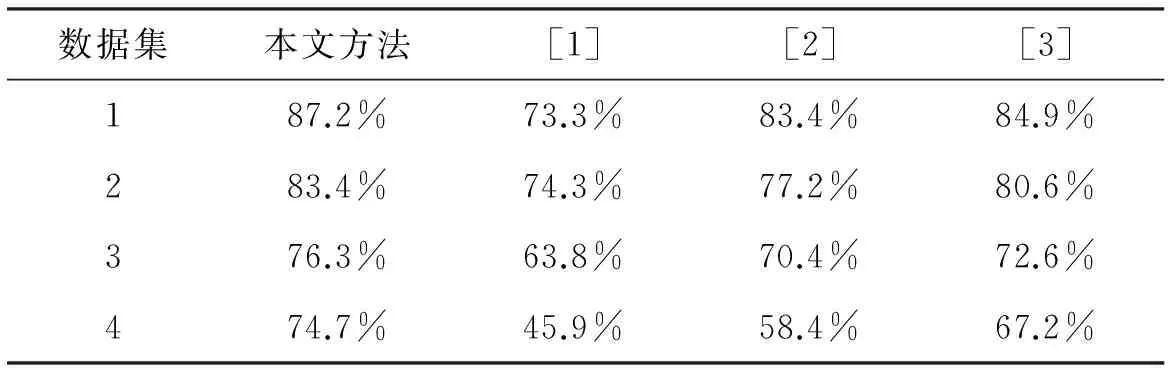
表1 各种方法的分类准确率
从表1可以看出,在不同数据集下,本文方法准确分类新闻文本的百分比最高,而[1]最低.这是因为,基于ANN的分类器需要大量神经元节点,且训练过程非常耗时,计算复杂度非常高.然而,本文采用的eClass0分类器是一种能实时处理数据流的增量式分类器.该分类器不需要存储整个数据流,因此能处理大量数据,另外本文结合了可进化的模糊规则提高了分类精度.
5 总 结
本文提出一种基于进化模糊规则的Web新闻文本挖掘和分类方法.在不影响性能的前提下,通过降低术语集来提高算法的执行效率.另外,能够根据收集到的新闻文本构建模糊规则,并动态更新规则数量和属性,以自适应文本类型变化.与现有神经网络或统计的分类方法相比,本文方法具有较高的分类准确率.
[1] GHIASSI M, OLSCHIMKE M, MOON B, et al. Automated text classification using a dynamic artificial neural network model[J]. Expert Systems with Applications, 2012, 39(12): 967-976.
[2] 钟将, 刘荣辉. 一种改进的KNN文本分类[J]. 计算机工程与应用, 2012, 48(2): 142-144.
[3] ZHANG S, ZHANG S X. Researching in Web technology classification based on improved support vector machine[J]. Applied Mechanics & Materials, 2013, 27(4):563-566.
[4] RISTOSKI P, BIZER C, PAULHEIM H. Mining the Web of linked data with rapidMiner[J]. Web Semantics Science Services & Agents on the World Wide Web, 2015, 35(3):142-151.
[5] 刘露, 彭涛, 左万利,等. 一种基于聚类的PU主动文本分类方法[J]. 软件学报, 2014, 25(11): 2 571-2 583.
[6] KAN E Y Y, CHAN W K, TSE T H. EClass: An execution classification approach to improving the energy-efficiency of software via machine learning[J]. Journal of Systems & Software, 2012, 85(4): 960-973.
[7] BARUAH R D, ANGELOV P, ANDREU J. Simpl_eClass: Simplified potential-free evolving fuzzy rule-based classifiers.[C]// Systems, Man, and Cybernetics (SMC), 2011 IEEE International Conference on IEEE, 2011:2 249-2 254.
责任编辑:龙顺潮
Web News Text Mining and Classification Method Based on Evolving Fuzzy Rule
SHIYu-zhen*,LVQiong-shuai
(College of Software, Pingdingshan University, Pingdingshan 467000 China)
For the issues that the existing Web news text classification accuracy is low and can't adapt to the change of text types, a Web news text mining and classification method based on evolving fuzzy rule is proposed. Firstly, the term of each Web text is extracted, and the term frequency-inverse document frequency (TF-IDF) algorithm is used to filter out some terms with lower description ability. Then, the cosine distance between the new news text content and category is calculated, and the cosine distance is used to create and update the fuzzy rules and the number of attributes by eClass0 classifier. Finally, text classification is done according to the fuzzy rule reasoning and cosine distance. The experimental results show that this method has higher correct classification rate, and can adapt the change of Web news text category.
Web news; text classification; evolving fuzzy rule; cosine distance; frequency-inverse document frequency
2015-11-22
河南省科技厅科技重点攻关项目(142102210226)
史玉珍(1975-),女,河南 舞阳人,副教授. E-mail:shiyuzhenpdsu@126.com
TP391
A
1000-5900(2016)02-0099-05
