多单元散列表与TCAM结合的OpenFlow流表查找方法
2016-11-24李春强董永强吴国新
李春强,董永强,2,吴国新,2
(1.东南大学计算机科学与工程学院,江苏 南京 211189;2.东南大学计算机网络和信息集成教育部重点实验室,江苏 南京 211189)
多单元散列表与TCAM结合的OpenFlow流表查找方法
李春强1,董永强1,2,吴国新1,2
(1.东南大学计算机科学与工程学院,江苏 南京 211189;2.东南大学计算机网络和信息集成教育部重点实验室,江苏 南京 211189)
在OpenFlow网络中,交换机通过标准化的接口接受基于流的规则,执行基于流的报文处理。流表的查找是OpenFlow交换机的核心功能,TCAM以其优异的性能广泛用于OpenFlow流表的查找,然而基于TCAM的OpenFlow流表查找具有较高的成本与能耗。为了降低流表查找的成本与能耗,提出了多单元散列表与TCAM结合的OpenFlow流表存储与查找的方法。通过理论分析与仿真测试,给出了查找结构成本优化后的散列表、TCAM的容量配置;在该配置下,Hash-TCAM流表查找结构比单纯使用TCAM的方案节约90%以上的成本,有效降低了能耗,同时保持了相近的查找性能。
OpenFlow;三态内容寻址存储器;散列表;流表
1 引言
为了在已有的网络基础设施中构建网络创新研究的实验环境,软件定义网络(SDN, software defined networking)作为一种新型的网络体系结构被提出,OpenFlow[1]技术作为实现 SDN的一种具体方案,受到了学术界和工业界的普遍关注和广泛研究。OpenFlow系统实现了数据转发和控制功能的分离,通过独立的控制器来控制网络设备(称为OpenFlow交换机)的转发行为;OpenFlow控制器在逻辑上采用集中式的控制方式,OpenFlow交换机通过标准化的接口接收来自控制器的报文处理规则,执行基于流的报文处理。OpenFlow机制以其良好的可编程、可控制等特性,已被应用于数据中心、企业网、校园网中网络流量的管理与控制。
流表是OpenFlow机制的核心,它是流表项的集合,流表项的基本格式如图1所示,主要有匹配字段(Match Fields)、计数器(Counters)和操作(Instructions)等部分组成,其中,匹配字段可以包含多个匹配项,涵盖了链路层、网络层和传输层等层次的报文头部字段,计数器根据匹配到的报文进行统计,操作则指明匹配到该流表项的报文应该执行的操作,比如转发、丢弃、修改等。

图1OpenFlow流表项格式
随着OpenFlow规范的不断更新,流表项匹配字段从最初的十元组[1](如图2所示),逐步增加了VLAN优先级等字段,后续MPLS和IPv6等协议字段也逐渐扩展到OpenFlow标准[2~4]中,流表的匹配字段越来越长,流表的规模越来越大。OpenFlow交换机收到数据报文后,提取报文的头部信息查询OpenFlow流表,根据流表中匹配到的规则对报文执行相应的操作;为了实现高速的流表匹配,OpenFlow交换机通常采用三重内容可寻址存储器(TCAM, ternary content addressable memory)存储与查找流表[1,2,5],这种不断扩展的数据转发面抽象,需要占用大量的TCAM资源,大大增加了硬件成本。
TCAM可以完全并行地查找整个数据字段的集合,具有优异的查找性能。然而TCAM这种高性能并行查找机制带来了高的能耗与散热问题;同时TCAM的成本也非常高,TCAM单比特成本大约相当于静态随机存储器(SRAM, static random access memory)的30倍[6];TCAM能耗也明显超出SRAM数倍[6,7],并且会随并行匹配字段的条目数及宽度而增加[7]。设备的成本与性能决定了一项技术能否被推广与普及,因此,降低OpenFlow交换机的成本与能耗是目前亟待解决的关键问题。OpenFlow流表的查找是其核心功能,实现高性能、低成本、低能耗的流表查找成为OpenFlow交换机实现的基本要求。
针对基于TCAM的OpenFlow流表查找方案具有较高能耗与成本的问题,提出了将多单元散列表与 TCAM 结合的 OpenFlow流表存储与查找的方法。本文的主要贡献包括以下几点。
1) 提出将多单元散列表与 TCAM 结合的OpenFlow流表存储与查找的方法,使用连续的存储空间存储位于同一散列桶中的多个查找单元,其中每个查找单元包含一个流表表项的索引信息。
2) 分析了散列表的冲突溢出率,根据散列冲突溢出的变化率,展示了多单元散列表—TCAM查找结构以及二级多单元散列表—TCAM具有良好的成本优势。
3) 在散列表中,通过流表表项关键字指纹代替关键字的匹配减少单次存储器读操作的数据位数,并进一步降低了散列表的成本。
4) 通过理论分析有效配置TCAM与散列表的容量,优化了OpenFlow流表的存储与查找的成本及能耗,并通过仿真测试进行了验证。

图2十元组格式的流表项匹配字段
2 相关技术介绍
2.1 降低流表存储开销及能耗的研究
随着OpenFlow应用范围的扩大,OpenFlow流表的规模越来越大,匹配字段的位数越来越多,从OpenFlow1.1版[2]开始提出了通过多级流表和流水线查找结构来压缩流表存储空间,但其压缩效果与流表表项匹配字段的具体内容密切相关。当级数较多时会显著增加报文处理的时延,同时增加了OpenFlow交换机硬件设计的复杂度。文献[8~12]提出了基于分解的OpenFlow流表匹配方法,按照流表匹配字段在报文头部的协议层次,将OpenFlow流表划分成多个子表;进行规则匹配时,报文头被分割成多个字段,每个字段独立地执行查找操作;根据每个查找操作的返回结果合并后,再执行一次查找获得匹配的流表规则。该类方案的主要问题在于流表一个条目的更新可能会涉及子表中的多个条目,更新过程较为复杂。
文献[13,14]提出了通过压缩流表减少 TCAM使用的方案,采用启发式方法,求解语义等同的流表集合,结果导致压缩的效果与流表的内容密切相关,压缩比不确定,而且无法支持实时更新流表的条目。文献[15,16]提出了基于决策树的 OpenFlow流表匹配方案,同样采用启发式算法构建匹配规则的决策树,需要多次查表才能确定匹配的流表条目;匹配字段位数越多,查找的时延越高,查找的性能受到限制。
为了降低OpenFlow流表匹配的能耗,文献[5]根据数据报文的局部性,通过增加报文预测电路,通过缓存某段时间内频繁访问的流表条目来尝试减少与TCAM中流表进行匹配的操作。该方案虽然考虑了降低OpenFlow交换机功耗与时延的问题,但并未降低基于TCAM的OpenFlow流表存储与查找的成本。
2.2 基于散列表的存储与查找
散列表具有良好的平均查找性能且易于实现,因此将散列表应用到网络报文处理上得到了广泛的研究[17]。当多个关键字通过散列运算映射到同一个散列桶,称为散列冲突,散列冲突是影响散列查找性能的主要因素,如何有效处理散列冲突是散列表实现高效查找的关键。通常,借助于链表(拉链法)或开放地址探测(开放定址法)等方式解决散列冲突。但无论是拉链法还是开放定址法,当待查找的条目存在散列冲突时,需要多次存储器访问才能获得查找结果,因此不能确保最差情形下的查找性能。
文献[18]提出一种基于开放地址探测的散列冲突处理方案,该方案中使用2个子散列表,每个条目插入时在2个子表中各有一个候选的位置,但只插入到其中一个。当插入一个新条目时,根据关键字使用不同的散列函数计算在2个子表中的位置,只要任意一个位置为空则可以将该条目插入该空位置;当2个位置均非空时,选择一个子表的位置将新条目插入,并将被替换的条目插入到另一表中的候选位置,如果另一表中的相应位置非空,继续进行迭代,直到找到一个空闲的位置;如果经过一定的迭代次数仍无法找到空闲位置,则需要执行rehash操作或者将被替代的条目放入TCAM[19]。对于该方案而言,通过并行地查找2个子散列表,可以确保查找的性能;然而在插入新条目时,可能需要多次移动表中的条目,插入的性能是不确定的,无法满足流表的实时更新要求。
基于散列表的存储与查找方案虽然可以使用SRAM、短时延动态随机存储器(RLDRAM, reduced-latency dynamic random access memory)等功耗、成本相对较低的存储器,但随着散列表利用率的增加,散列冲突出现的概率也会增加,从而会导致散列表处理性能下降、查找性能不确定的问题,这对高速网络报文处理是难以容忍的;基于TCAM的OpenFlow流表存储与查找方案,可以实现高效确保的查找性能,但其成本与功耗相对较高,这会影响OpenFlow技术的普及与推广。因此,本文将这2种方案进行结合,对以流量管理[20,21]或报文转发[22]为主要功能的OpenFlow交换机,降低其流表存储与查找的成本及能耗。
3 Hash-TCAM混合流表存储与查找方案
图3(a)给出了常规的Hash-TCAM混合流表查找结构。由于使用网络处理器(NP, network processor)[23,24]、专用集成电路(ASIC, application specific integrated circuits)执行报文处理是OpenFlow交换机常见的实现方式,如果NP或ASIC带有一定容量的片内TCAM[25],则流表的查找结构如图3(b)所示。

图3Hash-TCAM混合流表查找结构
方案的基本思路是将散列表作为OpenFlow流表的精确匹配与存储的主要措施,用TCAM处理散列表的冲突溢出。通常,TCAM每个时钟周期都可以执行一次查找,SRAM每个时钟周期也可以执行一次读操作,在没有散列冲突溢出的情况下,散列查找只需要执行一次 SRAM 读操作就可以查到对应条目,因此将冲突溢出的条目存储到TCAM中,避免因多次SRAM读操作导致的查找性能下降,于是每个时钟周期均可以执行一次OpenFlow流表的查找操作,确保了流表的查找性能。
3.1 OpenFlow流表存储成本优化的问题
Hash-TCAM 混合流表方案的目标是通过合理分配散列表与TCAM的容量,优化Hash-TCAM混合流表查找结构的成本,降低其能耗,实现高性能的流表存储与查找。由于混合查找结构的成本由散列表与 TCAM 2部分组成,设散列表的总成本为CH,TCAM表的总成本为CT,总的流表条目数为N,散列表容量为 H个散列桶,散列表的负载系数单个散列桶容纳的关键字条目数为ω,单个散列条目的成本为Ch,散列表冲突溢出的条目数为Θ,TCAM的容量为T个条目,单个TCAM条目的成本为Ct,则Hash-TCAM混合流表查找结构的成本优化问题可以记为

其中,式(1)中 Ctotal表示整个存储与查找结构的总成本,为优化的目标函数;式(2)的不等式是约束条件,表示 TCAM 的容量不少于散列冲突溢出的条目数;式(3)和式(4)分别表示散列表和 TCAM 的成本。取TCAM的容量恰好可容纳散列表冲突溢出的条目数

对于容量为 H个散列桶、单散列桶容量为 ω条目的散列表,散列表容量为h个条目,则

记单个 TCAM 条目的成本为散列条目成本的m倍,即

将式(5)~式(7)代入式(1)得
由于散列表的成本CH是散列表容量的增函数;TCAM的成本由散列冲突溢出的条目数Θ决定,对于相同结构的散列表,散列冲突溢出的条目数Θ随散列表容量增加而减少,是散列表容量h的减函数,记 Θ=Θ(h)。通过分析散列容量 h的变化对总成本Ctotal的影响,可以得出 OpenFlow流表存储与查找结构最优成本下的散列表及TCAM各自的容量配置。记 Δh为散列表条目数的增量,散列表容量 h+Δh下的混合存储与查找结构的成本为则


由式(9)可得出

3.2 散列表的冲突分析
对于散列查找而言,当出现散列冲突时,可能需要多次访问存储器,而存储器的访问是影响查找性能的关键因素。为了减少查找过程中存储器的访问次数、保持高的查找性能,本文采用多单元散列表,即单个散列桶使用连续的存储空间容纳多个查找单元,其中,每个查找单元包含一个散列条目。通过这样的设计,一次存储器读操作可以读取多个散列条目。
散列表的冲突溢出条目数跟散列表的负载系数及结构密切相关,不同的散列表结构在使用相同容量存储器的情形下,冲突溢出条目数不同,称为散列表的冲突溢出率。下面分析不同结构及负载系数下的冲突溢出率。采用具有良好随机性的循环冗余校验(CRC, cyclic redundancy check)作为散列函数,N个数据随机分布在H个键值中,对于任意一个特定的键值,每个数据进入这一键值的概率为,N个数据中恰好有k个进入这一键值的概率服从二项分布,其中,;即散列桶中恰好有k 个条目的概率其中

对于单条目散列桶的普通散列表,负载系数为λ时,冲突溢出率可按式(11)计算。

对于散列桶容量为ω的多单元散列表,负载系数为λ时,冲突溢出率可按式(12)计算。

为了比较多单元散列表与普通散列表在相同容量下的冲突溢出率,取散列桶数目为N、负载系数为1的多单元散列表与散列桶容量为1、负载系数为的普通散列表进行分析。根据式(11)和式(12)可得出两者的冲突溢出率随散列表容量的变化趋势,如图4所示。

图4散列冲突溢出率随散列表的容量增加的变化趋势
从图4可以看出,在相同散列表容量情形下,多单元散列表的冲突溢出率明显低于普通散列表的冲突溢出率;而且随着散列表容量增加,多单元散列表的冲突溢出率下降幅度也明显大于普通散列表。因此,在数据总线宽度允许的条件下,应尽可能选择单元数多的多单元散列表存储与查找OpenFlow流表,以优化流表的存储与查找成本。

表1多单元散列表冲突溢出率
根据式(12),表 1给出了多单元散列表不同的散列桶单元数目、负载系数λ下的冲突溢出率。对于表1中散列桶单元数为ω、负载系数为λ的散列表,散列桶的数目为,表的容量为;散列桶单元数同为 ω,负载系数分别为 λ、λ+1相邻的 2个表格单元,其容量差为,根据式(10)可知,当两者的冲突溢出率差值接近时,其存储与查找结构的成本接近最优值。
3.3 多单元散列表的结构及处理方法
3.3.1 存储与查找结构
由于OpenFlow流表表项的匹配关键字包含的位数非常多(OpenFlow1.0规范中至少包含228 bit),为了能够实现多个单元的并行比较,需要对匹配关键字进行压缩,可以使用具有良好随机性的散列函数将流表的匹配关键字压缩成位数较少的固定长度的指纹(fingerprint)[26],在散列查找时通过指纹的比较发现匹配的流表表项。基于多单元散列表的OpenFlow流表结构如图5所示,每个散列桶包含ω个查找单元,每个查找单元由标识位、指纹、流表指针3个部分组成,其中,标识位表示该查找单元中的流表条目是否有效,在删除流表表项时只要将对应的标识位置为无效即可,表项指针指向具体的流表条目。
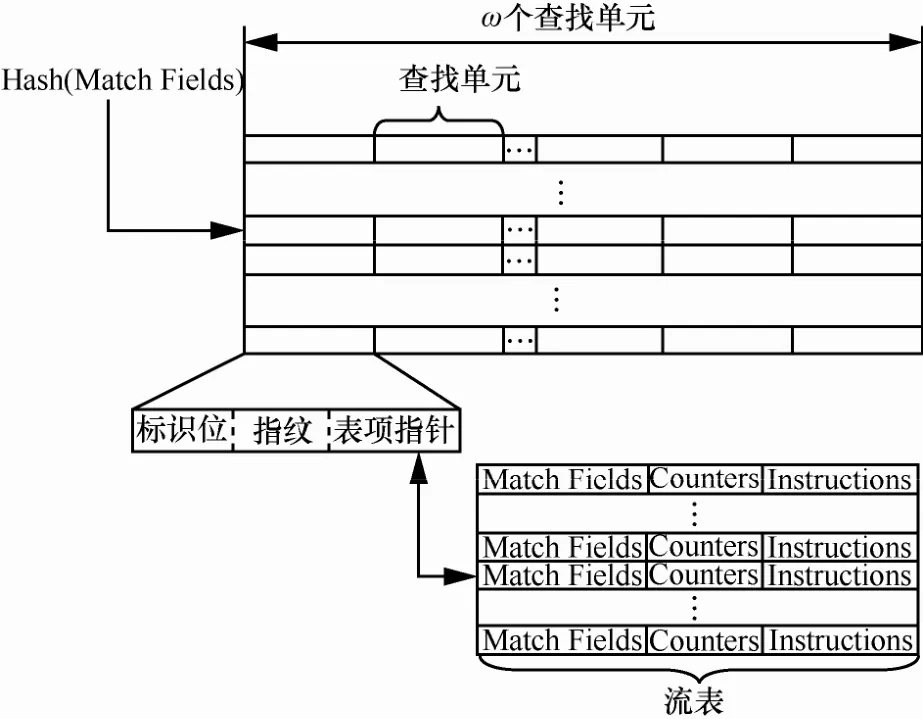
图5基于多单元散列表的OpenFlow流表结构
3.3.2处理流程
图6是Hash-TCAM OpenFlow流表查找的处理流程,其输入为匹配关键字key。TCAM的查找操作与SRAM的读操作可以并行的执行,当TCAM查找操作返回的流表项指针有效时,直接根据该流表指针读取流表条目,不必再判断寄存器Registers中的内容及后续操作。当TCAM查找操作返回的流表指针无效时,则需要根据寄存器中的指纹判断散列表中是否存在匹配的流表表项,如果存在匹配的指纹,则根据对应的流表指针读取相应的流表条目,并比较流表条目中的关键字与查找使用的关键字是否一致,如果不一致,则说明存在指纹冲突需要插入新的流表条目。当在TCAM与散列表中均未查找到匹配的流表条目,则请求插入新的流表条目。

图6Hash-TCAM OpenFlow流表查找流程
图7是Hash-TCAM OpenFlow流表表项插入的处理流程,其输入为流表关键字key及流表条目,在当前流表中未发现流表关键字key对应的流表条目时,则执行流表表项的插入。插入新的流表条目时,首先尝试向散列表中插入,如果由于散列冲突溢出或指纹冲突,则插入到TCAM 中。在删除散列表中的流表条目时,只需要将标识位置为无效即可。
3.4 匹配关键字指纹
将取值范围较大的匹配关键字映射到取值范围较小的指纹,可能会发生不同的匹配关键字映射到同一个指纹的现象,称之为指纹冲突。为了确保查找的性能,需要将发生指纹冲突的匹配关键字存储在TCAM中。较少位数的指纹意味着散列表的容量小、成本低;但位数越少,指纹冲突的概率就越大,增加TCAM的成本,同时影响查找结构的性能。下面分析指纹冲突的发生率与指纹位数的关系。记位于同一散列桶的n个单元的指纹不出现冲突的概率为 Pnc(n),指纹的位数为 w,任意关键字映射到指纹后随机地分布在[0, 2w−1]的范围内,n个单元均不存在指纹冲突的概率为


图7Hash-TCAM OpenFlow流表表项插入处理流程
式(13)中 U=2w,指纹冲突率 Pc≤1−Pnc(n),即

根据式(14),图8给出了2单元至8单元散列表的指纹冲突率上限与指纹位数的关系,从图8可以看出,当指纹的位数越多,冲突率的上限越小,对于多单元散列表,单元数目越多指纹冲突率上限越大;当指纹位数超过21 bit时,冲突溢出率的上限低于10−5。指纹发生冲突的概率上限与指纹的位数相关,而与匹配关键字的原始位数无关。

图8多单元散列表的指纹冲突率上限
3.5 两级多单元散列表的结构及操作
3.5.1 存储与查找结构
多级散列表[27,28]在实现散列表高利用率的同时,可以有效降低散列冲突的溢出率。然而如果散列表的级数较多,当执行删除操作时,则需要在不同级的子表之间执行散列条目的移动,才能保持低的冲突溢出概率[29];而散列条目的移动会影响整个散列表的操作性能,而且散列表的级数过多,也会增加电路设计的复杂度,增加查找的成本与能耗。因此,为了进一步降低 OpenFlow流表的查找成本,提出了两级多单元散列表的OpenFlow流表查找结构,如图9所示。该结构使用了主表与辅表两级子表,每个子表都使用多单元散列表;为了便于实现,每个子表的散列桶的单元数也相同,每个查找单元的格式与 3.3节中的相同。

图9两级多单元散列表的详细结构

图10两级多单元Hash-TCAM OpenFlow流表查找处理流程
3.5.2 处理流程
图 10是两级多单元 Hash-TCAM OpenFlow流表查找的处理流程,其输入为匹配关键字key。在执行关键字查找时,TCAM查找与散列查找并行执行;对于散列查找,主表与辅表SRAM的读操作也并行地执行;当TCAM查找操作返回的流表项指针无效时,需要根据 Register1、Register2中的内容判断散列表中是否存在匹配的流表项,否则直接根据TCAM中返回的流表项指针读取流表条目,不必再判断 Register中的内容及其后续操作。
图11是两级多单元Hash-TCAM OpenFlow流表表项插入的处理流程,其输入为:流表关键字key及流表条目。在流表中未查找到流表关键字key对应的流表条目时,则执行流表表项的插入。插入新的流表条目时,首先尝试向散列表的主表中插入,如果由于散列冲突溢出或指纹冲突,则尝试向散列表的辅表中插入,如果仍然存在散列冲突溢出或指纹冲突,则插入到TCAM中。
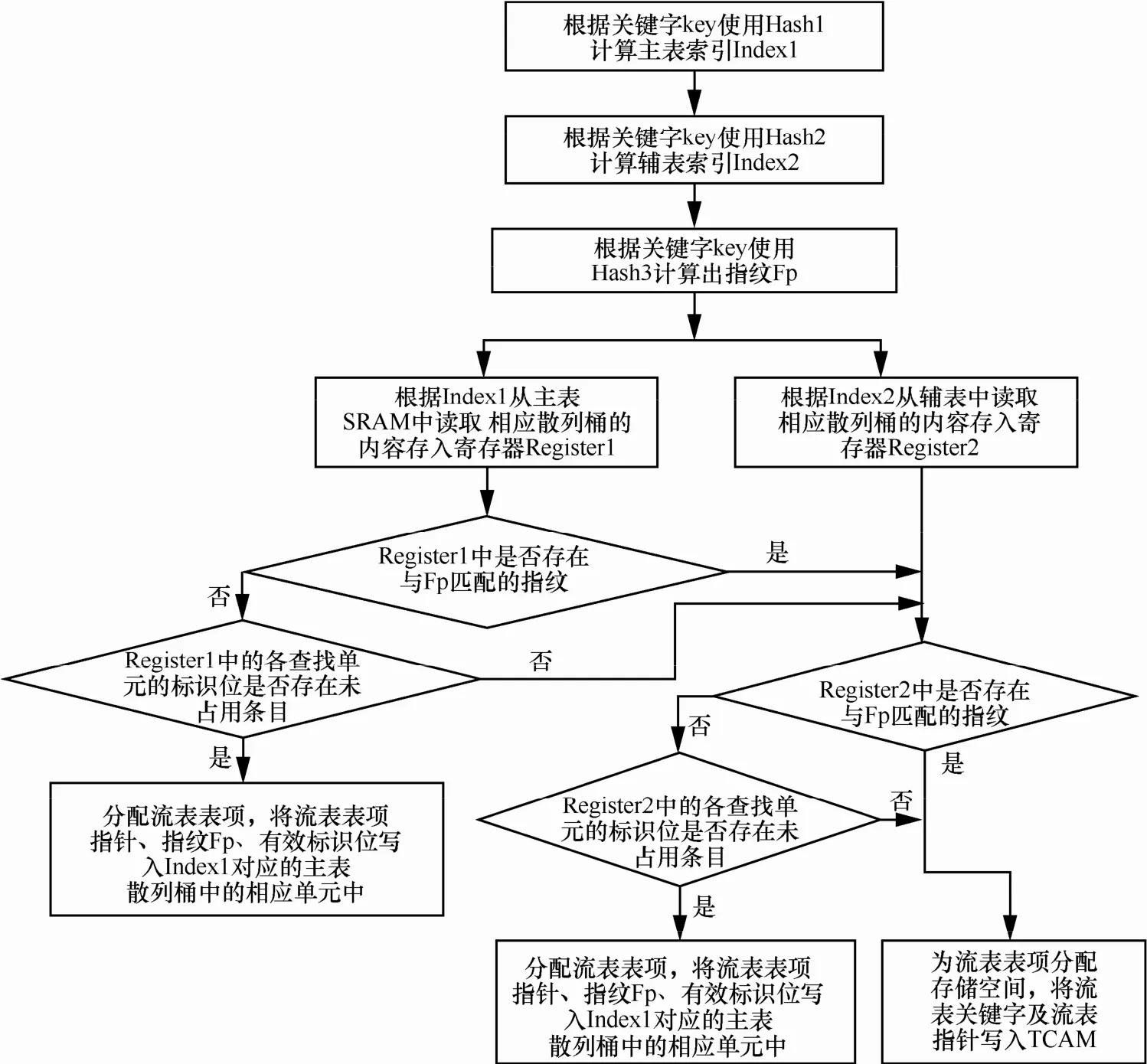
图11两级多单元Hash-TCAM OpenFlow流表插入处理流程
3.5.3 散列冲突溢出分析
下面分析散列桶单元数相同,两级多单元散列表与单级多单元散列表的冲突溢出率。设单级多单元散列表容量为H个散列桶,单个散列桶的容量为2ω个查找单元,负载系数为 2λ,冲突溢出率可按式(15)计算

设两级多单元散列表主表容量为H个散列桶,单个散列桶的容量为ω个查找单元,主表的冲突溢出率ε可按式(16)计算。
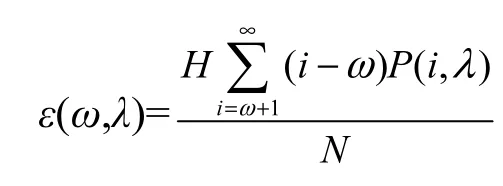

辅表容量为ε(ω, λ)的H个散列桶,单个散列桶的容量同样为ω个查找单元,负载系数为λ,则两级多单元散列表的冲突溢出率可按式(17)计算。

两级多单元散列表的总容量为(1+ε(ω,λ))Hω 个查找单元,其冲突溢出率为ε2(ω,λ);单级多单元散列表的容量为 H·2ω个查找单元,其冲突溢出率为ε(2ω,2λ);在 1≤ω≤40, 1≤λ≤ω 的条件下,通过计算可以得出 ε2(ω,λ)<ε(2ω,2λ),即与单级多单元散列表相比,两级多单元散列表在使用更少的存储空间的条件下,可以实现更低的冲突溢出率。
4 测试与仿真分析
散列表冲突溢出率是Hash-TCAM查找结构成本计算的基础,因此散列表冲突溢出率的理论模型的准确性,对Hash-TCAM混合查找结构的成本计算非常关键,通过实验测试散列表冲突溢出率的理论值与实际数据的吻合度。流表关键字的指纹冲突会对查找性能产生影响,应该尽量避免指纹冲突,并通过实验测试理论上限分析的合理性。
本节使用自生成的伪随机数与 2所大学的数据中心报文Trace[30]数据对流表Hash-TCAM混合存储与查找结构中的散列表的冲突溢出率、指纹冲突率进行测试,对散列表与TCAM容量配置的有效性进行了分析,考察了混合存储查找结构的成本与能耗。
为了验证散列表的冲突溢出率理论分析的准确性,分别生成了64K、128K、256K、512K、1M、2M、4M、8M个伪随机数(其中,K=1024,M=1024×1024),每个伪随机数96 bit,作为关键字存储到散列表中。
为了验证方案针对实际网络数据的适用性,将 Trace数据集[30]中的报文头部作为流表中的匹配字段存储到散列表中。由于通过报文头部的<IP源地址、IP目的地址、传输层源端口号、传输层目的端口号>便可以唯一地标识一个数据流,因此测试中只取了报文头的这4个部分作为流表的匹配字段。提取UNV1中的20个文件、UNV2中的8个文件,将报文头四元组作为流表的匹配字段,2个数据集分别包含556601个条目和191474个条目。
测试过程中,使用 CRC-32[31]算法生成散列查找的索引,计算匹配关键字指纹使用的函数为Jenkins Hash[32]。
4.1 散列表冲突溢出测试
图12给出了2单元至8单元散列表的冲突溢出率,图中的纵坐标为百分比,横坐标为散列表的负载系数λ。从图中可以看出,无论是使用随机数据作为关键字存储在散列表中,还是数据中心Trace数据提取出的报文头作为关键字存储在散列表中,实验得出的冲突溢出率与理论值均非常吻合。
图 12中的理论值是散列表冲突溢出率的理论期望值,由于散列桶中表项的条目数服从二项分布,散列冲突的溢出条目数的期望值也服从二项分布,根据棣莫弗—拉普拉斯中心极限定理可知,当流表的条目数很大时,冲突溢出的概率非常接近其期望值,因此,散列冲突溢出率实验值与其理论期望值非常接近。
4.2 指纹冲突测试
图13给出了2单元至8单元散列表的指纹冲突率,图中的横坐标为匹配关键字指纹的位数,纵坐标为冲突率,即发生指纹冲突的数目与总条目数之比,其中的指纹冲突率的理论值是冲突率的上限。从图中可以看出,无论是使用随机数据生成的指纹存储在散列表中,还是Trace数据集中的报文头计算出的指纹存储在散列表中,指纹冲突率均不超过理论值给出的上限。随着单元数的增加,指纹冲突率呈现增长的趋势。由于发生指纹冲突的概率非常小,几个指纹冲突就会导致测试结果呈现出较大的波动,但总的来看指纹的冲突率均不高于其理论上限。
4.3 成本与能耗分析
对于散列查找而言,需要存储内容包括:匹配关键字,匹配关键字的指纹、有效标识位、流表指针。根据3.2节的理论分析与4.2节的仿真测试,匹配关键字的指纹长度取21 bit以上时,其指纹冲突率低于10−5,与散列冲突溢出率相比可以忽略不计;有效标识位为1 bit,流表指针的位数为lb N,N为流表条目数。这样,当流表的条目数不超过8 M的情况下,对于散列查找,除了匹配关键字以外每个条目还需要不超过45 bit的存储开销。OpenFlow流表匹配关键字的位数通常超过228 bit,所以单个散列条目的容量不超过TCAM条目的倍。假定TCAM的单比特成本是SRAM的30倍[6],则单个 TCAM 条目成本是散列条目的 25倍以上。OpenFlow交换机的报文处理芯片对外接口等实现因素限制了散列桶的单元数,表2给出了散列桶单元数为2~8时成本最优的Hash-TCAM存储与查找结构中散列表、TCAM的配置,以及整个查找结构的成本。其中,N为总的流表条目数,散列表的主表、辅表以及TCAM 配置是根据散列冲突溢出率的理论值计算出的。其中UNV1与UNV2的TCAM条目数是由3.1节中的测试得出,N1=556601,N2=191474;UNV1与UNV2的成本是归一化的成本。
从表2的数据可以看出,随着散列桶单元数的增加,Hash-TCAM 流表存储与查找结构的成本逐渐降低,即使散列桶为 2单元的情形下,,Hash-TCAM 存储与查找结构的最优成本可以比只使用 TCAM的方案节约 90%以上的成本。
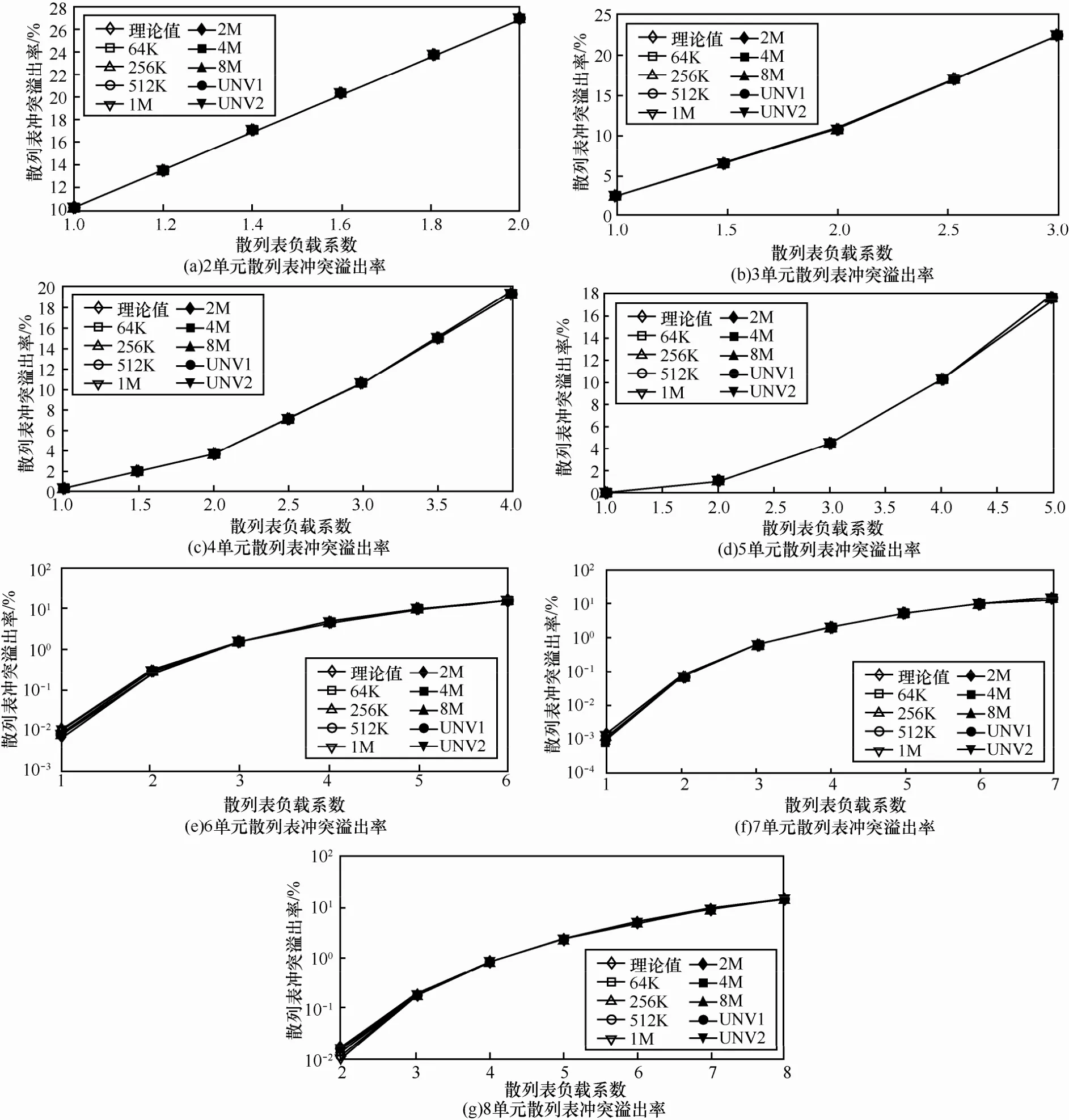
图12多单元散列表冲突溢出率
为了确保Hash-TCAM混合结构的查找性能,当执行查找时并行地查找散列表的主表、辅表以及TCAM,因此其能耗包括这3部分的查找能耗。在0.18 µm生产工艺、工作电压为1.8 V的情况下,当TCAM容量超过256 Kbit情形,其能耗相当于相同容量SRAM访问能耗的15倍以上[7],且TCAM的能耗随并行匹配字段条目数及宽度增加[6,7];即使1K条目的OpenFlow流表,占用的TCAM也超过256 Kbit,因此计算时取TCAM的能耗是相同容量SRAM的15倍。为了方便计算,记容量为N个流表条目的TCAM能耗为15,表2中UNV1与UNV2的能耗是归一化后的能耗。仍以散列桶为2单元的散列表为例,Hash-TCAM 存储与查找结构成本最优条件下,其能耗与只使用 TCAM 的方案相比可以节约85%以上。
4.4 性能分析

图13多单元散列表指纹冲突率
基于两级多单元散列表与TCAM的OpenFlow流表查找,需要同时并行地查找TCAM、主表与辅表,包含的操作有:散列表索引的计算、指纹的计算、寄存器内容与指纹的比较、一次 TCAM 查找、一次主表SRAM读操作、一次辅表SRAM读操作。对报文处理器而言,SRAM的读写操作以及TCAM查找是报文处理器的性能瓶颈;衡量报文处理器查表性能的指标是单位时间的查找次数;对 SRAM 每个时钟周期都可以执行一次读取操作[33];当OpenFlow交换机收到报文执行OpenFlow流表查找时,其中,TCAM查找、主表SRAM的读操作、辅表SRAM的读操作均可以并行地执行,即每个时钟周期都可以执行一次TCAM查找、主表SRAM的读取以及辅表SRAM的读取;因此基于两级多单元散列表的OpenFlow流表查找的性能与基于TCAM的流表查找性能是相当的。
SystemC[34]一种应用广泛的系统级建模与仿真的语言,能够完成对电子系统从软件到硬件的全部过程进行建模,因此本节使用SystemC对两级多单元Hash-TCAM混合OpenFlow流表存储与查找结构进行了建模与仿真(具体的软件仿真环境为SystemC2.1与Microsoft VC++6.0)。仿真模型中以数据中心报文 Trace数据[30]中提取的报文流作为输入数据执行流表的查找与插入;其中,SRAM与 TCAM 采用相同的时钟频率,目前,常见的SRAM及TCAM时钟频率有250 MHz、333 MHz、450 MHz,即TCAM可以实现每秒250M、333M、450M次的查找,SRAM可以实现每秒250M、333M、450M 次的读写操作,因此,仿真时分别采用这些时钟频率,仿真过程中关键字的指纹采用了23 bit。分别对2~8单元的两级多单元Hash-TCAM混合查找结构和纯 TCAM 查找结构的查找性能进行了测试,图 14所示的仿真结果表明,两级多单元Hash-TCAM 混合查找结构在相同时钟频率的情况下,与纯TCAM查找方案具有相近的查找性能。

表2Hash-TCAM表的配置与成本及能耗
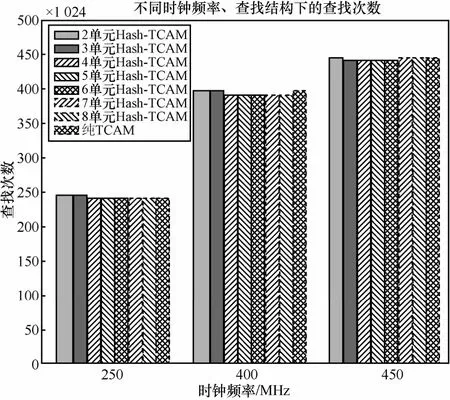
图14Hash-TCAM与纯TCAM的查找次数对比
5 结束语
针对基于TCAM的OpenFlow流表存储与查找机制存在的高成本、高能耗问题,提出了基于多单元 Hash-TCAM 的混合流表查找机制。为了优化OpenFlow流表存储与查找的成本与能耗,进一步采用两级多单元散列表机制,在确保流表查找性能的同时,降低散列表的成本。
理论分析与仿真测试表明,基于多单元Hash-TCAM 混合流表查找结构,针对精确匹配的流表条目,在优化配置情况下,可以节约成本90%以上,同时有效降低了其能耗;所提出的方案非常适合流量管理或报文转发为主要功能的 OpenFlow交换机。尤其是当执行报文处理的NP或ASIC带有一定容量的片内TCAM时,只需要配置适当容量的SRAM或RLDRAM用作流表的散列匹配,便可以实现高性能、低成本、低能耗的OpenFlow流表查找。
[1]MCKEOWN N, ANDERSON T, BALAKRISHNAN H, et al. Open-Flow: enabling innovation in campus networks [J]. ACM SIGCOMM Computer Communication Review, 2008, 38(2): 69-74.
[2]Open Networking Foundation. OpenFlow switch specification Version 1.1.0 (Wire Protocol 0x02)[S/OL].https://www. opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/ openflow/openflow-spec-v1.1.0.pdf, 2011.
[3]Open Networking Foundation. OpenFlow switch specification Version 1.3.0 (Wire Protocol 0x04) [S/OL]. https://www. opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/ openflow/openflow-spec-v1.3.0.pdf, 2012.
[4]Open Networking Foundation. OpenFlow switch specification Version 1.5.0 (Protocol version 0x06) [S/OL]. https://www. opennetwork-ing.org/images/stories/downloads/sdn-resources/onf-specifications/ openflow/openflow-switch-v1.5.0.pdf, 2014.
[5]CONGDON P T, MOHAPATRA P, FARRENS M, et al. Simultaneously reducing latency and power consumption in OpenFlow switches[J].IEEE/ACM Transactions on Networking, 2014, 22(3): 1007-1020.
[6]TAYLOR D E. Survey and taxonomy of packet classification techniques [J]. ACM Computing Surveys, 2005, 37(3): 238-275.
[7]AGRAWAL B, SHERWOOD T. Modeling ternary CAM power and delay model: extensions and uses[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2008, 16(5): 554-564.
[8]刘中金, 李勇, 苏厉, 等. TCAM 存储高效的 OpenFlow多级流表映射机制[J]. 清华大学学报(自然科学版), 2014, 54: 437-442.LIU Z J, LI Y, SU L, et al. TCAM-efficient flow table mapping scheme for OpenFlow multiple-table pipelines[J]. Journal of Tsinghua Univ Sciamp;Technol, 2014, 54: 437-442.
[9]GE J, CHEN Z, WU Y, et al. H-SOFT: a heuristic storage space optimization algorithm for flow table of OpenFlow [J]. Concurrency and Computation: Practice and Experience, 2015, 27(13):3497-3509.
[10]CHEN Z, WU Y, GE J, et al. A new lookup model for multiple flow tables of OpenFlow with implementation and optimization considerations [C]//IEEE International Conference on Computer and Information Technology (CIT). Xi’an, IEEE, 2014:528-532.
[11]鄂跃鹏, 陈智, 葛敬国,等. 一种高效的OpenFlow流表存储与查找实现方法[J]. 中国科学:信息科学, 2015, 45(10): 1280-1288.E Y P, CHEN Z, GE J, et al. An efficient implementation of storage and lookup for flow tables in OpenFlow [J]. Scientia Sinica Informationis, 2015, 45(10): 1280-1288.
[12]SUN H, SUN Y, VALGENTI V C, et al. OpenFlow accelerator: a decomposition-based hashing approach for flow processing[C]//24th International Conference on Computer Communication and Networks(ICCCN). Las Vegas: IEEE, 2015: 1-10.
[13]ZHU H, XU M, LI Q, et al. MDTC: An efficient approach to TCAM-based multidimensional table compression[C]//IFIP Networking Conference. Toulouse, IFIP, 2015:1- 9.
[14]MCGEER R, YALAGANDULA P. Minimizing rule sets for TCAM implementation[C]//IEEE INFOCOM. Rio de Janeiro, IEEE, 2009:1314-1322.
[15]VEERAMANI S, KUMAR M M, NOOR S K. Hybrid trie based partitioning of TCAM based openflow switches[C]//IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS). Chennai, IEEE, 2013: 1-5.
[16]LIM H, LEE S, SWARTZLANDER E E J. A new hierarchical packet classification algorithm [J]. Computer Networks, 2012, 56(13):3010-3022.
[17]CORMODE G, THOTTAN M. Algorithms for next generation networks [M]. London: Springer, 2010: 181-218.
[18]PAGH R, RODLER F. Cuckoo hashing[J]. Journal of Algorithms,2004, 51(2): 122-144.
[19]KIRSCH A, MITZENMACHER M, WIEDER U. More robust hashing:cuckoo hashing with a stash[C]//16th Annual European Symposium on Algorithms, Karlsruhe (L). Springer Verlag, Heidelberg, 2008: 611-622.
[20]CURTIS A R, KIM W, YALAGANDULA P. Mahout: low overhead datacenter traffic management using end-host-based elephant detection[C]//IEEE INFOCOM. Shanghai, 2011: 1629-1637.
[21]MOHAMMAD A F, RADHAKRISHNAN S, RAGHAVAN B, et al.Hedera: dynamic flow scheduling for datacenter networks[C]//USENIX Association NSDI. San Jose: USENIX, 2010: 281-296.
[22]LI D, SHANG Y, CHEN C. Software defined green data center network with exclusive routing[C]//IEEE INFOCOM. Toronto, IEEE,2014: 1743-1751.
[23]FERKOUSS O E, SNAIKI I, MOUNAOUARO, et al. A 100Gig network processor platform for OpenFlow[C]//Conf Network and Service Management (CNSM), Paris: IEEE, 2011.
[24]LUO Y,CASCON P, MURRAY E, et al. Accelerating OpenFlow switching with network processors[C]//ACM/IEEE Symposium on Architecture for Networking and Communications Systems(ANCS).Princeton, ACM, 2009: 70-71.
[25]RECEP O. Intel® Ethernet Switch FM6000: SDN with Open-Flow[EB/OL].http://www.intel.com/content/www/us/en/switch-silicon/ethernet-switch-fm6000-sdn-paper.html, 2014.
[26]MICHAEL O R. Fingerprinting by random polynomials[R]. Center for Research in Computing Technology Harvard University Report TR-15-81, 1981.
[27]BRODER A Z, KARLIN A R. Multilevel adaptive hashing[C]//ACM-SIAM Symposium on Discrete Algorithm. San Francisco,ASSOC COMP MACHINERY, 1990: 43-53.
[28]KUMAR S, TURNER J, CROWLEY P. Peacock hashing: deterministic and updatable hashing for high performance networking[C]//IEEE INFOCOM. Phoenix, IEEE, 2008: 101-105.
[29]KIRSCH A, MICHAEL M. On the Performance of multiple choice hash tables with moves on deletes and inserts[C]//46th Annual Allerton Conference on Communication, Control, and Computing, 2008:1285-1290.
[30]THEOPHILUS B. Data set for IMC 2010 data center measurement[EB/OL]. http://pages.cs.wisc.edu/~tbenson/IMC10_Data.html, 2010.
[31]BRAYER K, HAMMOND J L. Evaluation of error detection polynomial performance on the AUTOVON channel[C]//National Telecommunications Conference. New Orleans, IEEE, 1975: 21-25.
[32]https://en.wikipedia.org/wiki/Jenkins_hash_function[EB/OL].
[33]GIRISH K. QDR®-II, QDR-II+, DDR-II, and DDR-II+ Design Guide[EB/OL].http://www.cypress.com/file/38596/download, 2015.
[34]http://accellera.org/downloads/standards/systemc[EB/OL].
OpenFlow table lookup scheme integrating multiple-cell Hash table with TCAM
LI Chun-qiang1, DONG Yong-qiang1,2, WU Guo-xin1,2
(1.School of Computer Science and Engineering, Southeast University, Nanjing 211189, China;2.Key Laboratory of Computer Network and Information Integration, Ministry of Education, Southeast University, Nanjing 211189, China)
In OpenFlow networks, switches accept flow rules through standardized interfaces, and perform flow-based packet processing. To facilitate the lookup of flow tables, TCAM has been widely used in OpenFlow switches. However,TCAM is expensive and consumes a large amount of power. A hybrid lookup scheme integrating multiple-cell Hash table with TCAM was proposed for flow table matching to simultaneously reduce the cost and power consumption of lookup structure without sacrificing the lookup performance. By theoretical analysis and extensive experiments, optimal capacity configuration of Hash table and TCAM was achieved with the optimized cost of flow table lookup. The experiment results also show that the proposed lookup scheme can save over 90% cost and the power consumption of flow table matching can be reduced significantly compared with the pure TCAM scheme while keeping the similar lookup performance.
OpenFlow, ternary content addressable memory, Hash table, flow table
s:The National High Technology Research and Development Program of China (863 Program) (No.2013AA013503),The National Natural Science Foundation of China (No.61272532, No.61370209), The Future Networks Prospective Research Program of Jiangsu Province (No.BY2013095-2-06)
TP393
A
10.11959/j.issn.1000-436x.2016204
2016-01-25;
2016-08-30
吴国新,gwu@seu.edu.cn
国家高技术研究发展计划(“863”计划)基金资助项目(No.2013AA013503);国家自然科学基金资助项目(No.61272532,No.61370209);江苏省未来网络前瞻性研究基金资助项目(No.BY2013095-2-06)

李春强(1975-),男,山东沾化人,东南大学博士生,主要研究方向为数据中心网络体系结构及传输控制、报文转发及查找算法等。
董永强(1973-),男,河南渑池人,博士,东南大学副研究员,主要研究方向为网络体系结构、移动网络计算、高效内容分发等。
吴国新(1956-),男,安徽芜湖人,东南大学教授、博士生导师,主要研究方向为网络协议、网络安全和自组网等。
