基于粗糙集理论的文本分类属性约简算法
2016-11-23李美聪郭新辰
韩 玉,李美聪,郭新辰
(1.东北电力大学 理学院,吉林 吉林 132012;2.海南热带海洋学院 数学系,三亚 572022)
基于粗糙集理论的文本分类属性约简算法
韩 玉1,李美聪1,郭新辰2
(1.东北电力大学 理学院,吉林 吉林 132012;2.海南热带海洋学院 数学系,三亚 572022)
针对文本分类的特征空间高维问题,本文提出了一种基于粗糙集的属性约简算法及其改进的约简算法。利用该算法有效降低了文本特征向量的维数。通过利用20 Newsgroups数据集进行试验测试,在召回率、准确率和F-1度的指标上均具有较明显的优势。
粗糙集;属性约简;文本分类
文本分类[1-2]是指根据带有类别的文本集合的特点,根据每一个类别的文本子集合的共有特点,找出一个分类函数或分类模型分类器,根据该模型可以把其他文本映射到已有类别中的一个,从而实现自动对文本分类。粗糙集理论[3]是建立在分类机制的基础上的,它将分类理解为在特定空间上的等价关系,而等价关系构成了对该空间的划分,它将知识理解为对数据的划分,每一被划分的集合称为概念,其主要思想是利用己知的知识库,将不精确或不确定的知识用己知的知识库中的知识来近似刻画。该理论与其他处理不确定不精确问题理论的区别是:它无需提供问题所需处理的数据集合之外的任何先验信息,因此和其它理论有很强的互补性。
在文本分类和粗糙集理论的基础上,提出了基于粗糙集的文本分类系统[4];研究了粗糙集理论中的属性约简算法,并找出合适的用于启发式属性约简的属性重要性衡量方法;对于粗糙集理论中的启发式属性约简算法进行改进,根据此约简算法提出一个基于改进启发式属性约简的粗糙集文本分类系统,实验结果表明:将改进后的属性约简算法运用在文本分类模型中,能够得到较好的分类效果。
1 基于粗糙集理论的属性约简
1.1 粗糙集理论

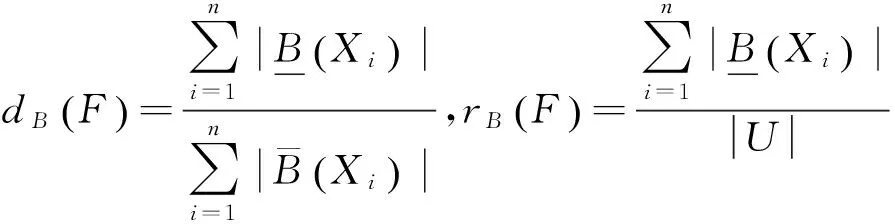
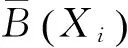
1.2 基于粗糙集的属性约简
1.2.1 属性约简
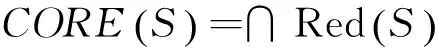
1.2.2 模型的建立(特征选择[10])


表1 文本分类决策表
在文本分类中,此决策表有如下特点:条件属性集规模庞大,即n值很大,原因是文本向量空间的高维性。因此本文后续工作就是对文本进行降维。
1.3 属性约简算法及其改进算法
1.3.1 属性约简算法的描述
为了利用粗糙集理论中属性重要性的相关结论,首先介绍几个重要的定义。

扩张分辨能力的大小可以反映属性对所属集合的继续分类所产生的影响能力,当IaADD=0时,说明属性a对子集B的分类能力不产生影响,不应该继续添加该属性。
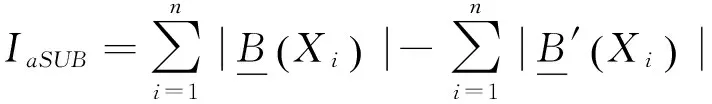
缩减分辨能力的大小也可以反映属性对所属集合的继续分类所产生的影响能力,当IaSUB=0时,说明属性a对子集B的分类能力不产生影响,可以删减该属性。
通过对属性子集的扩张分辨能力和属性子集的缩减分辨能力的定义,本文定义以下属性约简算法:
第一步:求解S的属性集中条件属性集C的核R=CORE(C);
第二步:根据属性子集的缩减分辨能力IaSUB对所有属性进行排序;
第三步:按照IaSUB从大到小的顺序依次将属性ai加入到约简集中,并判断R=R∪{ai}是否是S的一个约简集,如果是,则输出R=R∪{ai},如果不是,则C=C-{ai},并继续执行第三步。
2.3.2 改进的属性约简算法
本文将粗糙集理论应用于文本分类。对于属性的重要性评价主要有两种:其一是基于特征选择的属性评价标准[11];其二是基于粗糙集理论本身的属性评价标准[12]。
由于属性约简算法中存在很多需要属性核约简的工作量,因此对属性约简算法的改进可以增加属性的重要性权重,因此综合粗糙集理论和文本特征选择的属性重要性评价,根据重要性进行约简,以下定义评价公式。
定义3:文本特征选择属性重要性采用CHI,其特征选择性能在文本分类中效果优于其它方法,具体公式如下:
例1:I do believe this is a critical need for Americans. I do believe that we can have in this country a health care system for everyone.(认知)

进行特征选择时,选择CHI值大的特征。
定义4:如果考虑到两种属性重要性衡量权重的重要性同等重要
(1)当特征项i只在一种文本类别中出现时,Ii=CHI×Ri;
(2)当特征项i在两种以上文本类别中出现时,Ii=CHImax×Ri。
第一步:求解S的属性集中条件属性集C关于决策属性D的绝对核R=CORED(C);
第二步:根据属性子集的缩减分辨能力IaSUB对所有属性进行排序,然后在根据每个属性ai的重要性Ii的值进行大小排序;
一般的启发式属性约简算法在对于属性约简过程中都只是利用一种启发式信息,进行一次选择,改进后的启发式属性约简算法,利用了两种启发式约简信息,减少了冗余信息,应该得到更精简的属性约简集。
下面我们将改进后的启发式属性约简算法运用到文本分类系统中来验证其可行性。
2.4 实验结果及分析
2.4.1 分类结果的评价指标
为了检验分类算法的性能,需要从算法的复杂度、有效性以及算法描述的易理解程度三个方面进行分析,本文仅从算法有效性进行分析,包括以下几个方面:
(1)查准率:应该分类的文本数量与最终分到该类别的文本数量之间的比值,查准率越高,说明算法越有效,计算方法为:
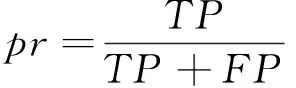
其中:TP表示应该分类到该类型的文本数量(被正确地分到该类的文本数);FP表示被错误分类到该类型的文本数量(被错误地分到该类的文本数)。
(2)查全率:被正确分类到该类型中的文本数量与实际该类型中文本的数量之间的比值,该数值越大,说明分类越全面,计算方法为:
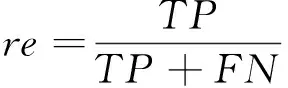
其中:TP表示应该分类到该类型的文本数量;FN表示应该被分到该类型却被遗漏的文本数量(本应属于该类,但没分到该类的文本数)。
以上两种指标的综合可以用F-Measure方法表示:
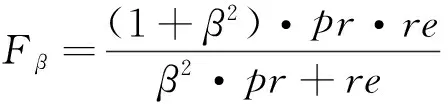
其中,参数β表示pr与re之间的重要程度。当β=0时,Fβ=pr即为查准率;当β→时,Fβ为查全率;当β=1时,表示考察查准率和查全率同样重要,此时
被称为F1-Measure。
2.4.2 实验设置
本次实验数据是从新闻语料语料库中抽取了一部分进行实验,共分为8个类别,其中类别包括alt.atheism,comp.graphics,rec.autos,misc.forsale,sci.crypt,sci.med,Sci.space,talk.politics.guns,共7605篇文本,其中训练文本4571篇,测试文本3034篇。

表2 语料库中训练文本和测试文本的分布情况
2.4.3 实验结果及分析
实验过程中,在训练阶段,首先用粗糙集理论提取出文本的分类规则,然后将预处理后的测试文本通过规则的匹配确定其类别。我们设计文本分类系统功能包括:训练,分类(即测试)和评价。评价结果如下:

表3 文本分类系统的评价结果1
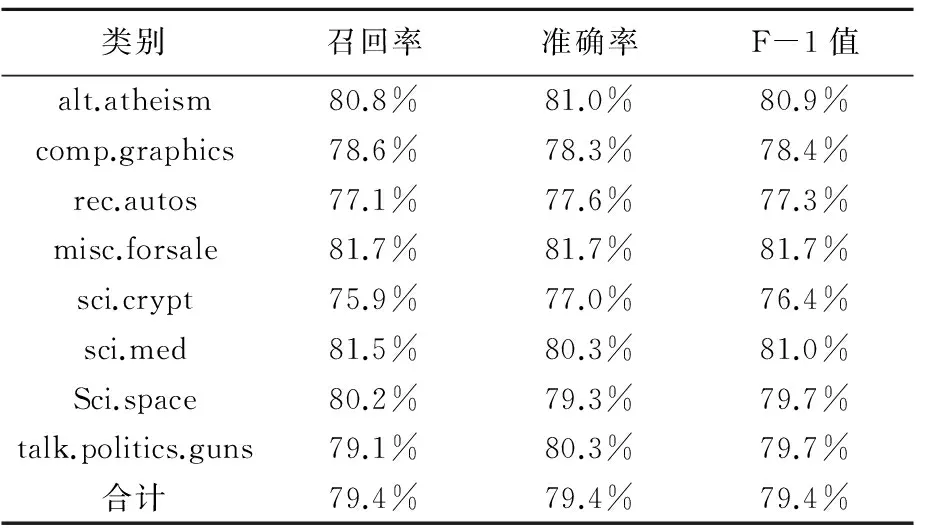
表4 文本分类系统的评价结果2
由表3和表4的分类评价结果,我们可以看出:对于测试集的7605篇测试文本,运用改进属性约简算法的粗糙集文本分类系统进行文本分类后,再利用提到的文本分类评价指标的计算方法计算得到每一个类别的召回率、准确率和F-l值,在经过平均计算出整个系统的召回86.0%,准确率85.5%,F-1值85.6%,改进之前召回率79.4%,准确率79.4%,F-1值79.4%,即该改进的系统能够得到较高的召回率、准确率和F-l值,具有较好的分类效果。
3 结 论
本文对于粗糙集理论中的启发式属性约简算法进行改进,利用两种约简信息,将传统的一次约简变为二次约简,由于冗余信息会干扰启发式属性约简算法的分类结果,因此利用改进后的属性约简算法可以减少冗余信息的干扰,得到更精简的属性约简集。该方法在保持规则的分类能力基本不变的情况下分类准确率较高,极大地压缩了文本特征子集的向量维数,避免基于向量比较文本分类方法计算量较大的问题。
实验结果表明:无论是召回率、准确率还是F-1值,改进后的属性约简算法相对于启发式属性约简算法都有很大较高,得到了很好的分类效果,证明了改进属性约简算法的有效性。但存在的缺点是对于大型数据库,其训练时间较长。
笔者认为在以后的工作中还有一些问题可以考虑进一步深入研究:
(1)语料库往往是一个文本分类系统进行分类效果好坏的关键因素,可以研究怎样建立一个科学合理的语料库及建设语料库应遵循的规则。
(2)本文所设计的模型是基于小规模的考虑,并且实验所选用的语料库也是小规模的,将它应用于大规模的真实环境是未来的工作。
[1] 潘雪增,廖一星.文本分类及其特征降维研究[D].杭州:浙江大学,2012.
[2] 林亚平,杨昂.文本分类算法研究[D].长沙:湖南大学,2002.
[3] 王国胤,姚一豫,于 洪.粗糙集理论与应用研究综述[J].计算机学报,2009,32(7):1229-1246.
[4] 张桂芸,王丽红.基于粗糙集理论的文本分类技术研究[D].天津:天津师范大学,2009.
[5] Pawlak Z.Rough Sets[J].International Journal of Computer and Information Sciences,1982,11(5):341-356.
[6] 武尚,程红福,明晓乐.基于优势关系的粗糙集扩展研究[J].计算机与数字工程,2014,8(6):943-947.
[7] 徐凌雁.基于粗糙集的BP神经网络空气品质预测模型[J].东北电力大学学报,2015,33(5):81-87.
[8] 张志飞,苗夺谦.基于粗糙集的文本分类特征选择算法[J].智能系统学报,2009,4(5):453-457.
[9] 吴守领,杨颖,杨磊,刘磊.基于粗糙集的决策表属性约简方法的研究[J].计算技术与发展,2012,22(1):32-35.
[10] Wenhao Shu,Hong Shen.Incremental feature selection based on rough set in dynamic incomplete data[J]. Pattern Recognition,2014,47(12):3890-3906.
[11] 张玉芳,万斌候.文本分类中的特征降维方法研究[J].计算机应用研究,2012,29(7):2541-2543.
[12] 李远远,云俊.基于粗糙集的综合评价方法研究[J].武汉理工大学学报:信息与管理工程版,2009,31(6):981-985.
The Text Classification Attribute Reduction Algorithm Based on the Rough Set Theory
HAN Yu1,LI Mei-cong1,GUO Xin-chen2
(1.College Of Science,Northeast Dianli University,Jilin 132012,China;2.Department of Mathematics,Hainan Tropical Ocean College,572022,China)
In view of high dimension problems of text feature space in text classification,This paper proposes a kind of attribute reduction algorithm based on rough set theory and its improved algorithm,Greatly reduce the dimension of text feature vector.By using 20 newsgroups data sets to test,the precision rate and recall rate and F-1 degree index all has a clear advantage.
Rough set;Attribute reduction;Text classification
2016-04-12
吉林省教育厅科研项目(2015-248)
韩 玉(1978-),男,吉林省洮南市人,东北电力大学理学院副教授,博士,主要研究方向:数理统计、数据挖掘.
1005-2992(2016)05-0092-05
O144.4
A
