基于SVM算法的个人信用评估方法的完善
2016-11-12黄巍张靓唐友
黄巍,张靓,唐友
(1.黑龙江财经学院,哈尔滨 150025;2.燕京理工学院)
基于SVM算法的个人信用评估方法的完善
黄巍1,张靓2,唐友1
(1.黑龙江财经学院,哈尔滨150025;2.燕京理工学院)
在众多的模式识别工具中,支持向量机(Support Vector Machine,SVM)是一种非常有效的解决工具。提出了基于SVM模型提升金融机构对个人信用评估效率的方法。通过对某银行的用户信用数据进行的研究,设计具体评估流程,利用SVM的SMO算法处理参数优化来构建模型,特点是分类精度高、误判率低,具有较好的稳健性,以此来控制消费信贷风险具有良好的适用性。处理商业银行划分信贷等级,应用此种模式可以解决信贷申请和政策实现,具有一定的实际意义。
SVM;个人信用评估;SMO算法
近年来,随着人们收入的增加,大家的消费观念也在逐步改变,在当前信用关系中个人信用活动成为最具潜力的一部分。它能够引导资金流向、刺激消费需求以及提高居民生活质量等方面发挥着比较重要的作用。
1 个人信用评估现存问题
所谓个人信用评估是根据居民收入和资产,发生借贷情况,然后进行偿还,如果出现信用透支或者是许多不良记录,最终受到处罚,然后将这些信息进行记录、存储,根据实际需求进行评估,决定在此信用下能完成的贷款数量。个人信用管理体系是指管理、监督与保障个人信用活动规范、健康发展的一套规章制度与行为规范。
个人征信评估体系仍需规范,对于消费金融产品来说,最重要的环节就是风险管控,如何评估用户的信用以及消费等级都要确立一套合理规范的体系,无论是数据的获取、产品的完善性还是评分的准确性,都将制约金融机构对个人信用评估的效率。相比美国、德国、日本等国家,中国的个人征信体系建设起步晚,发展不完善,主要依靠银行系统的金融信用数据覆盖面有限。对于现有征信体系,当前最大问题仍是信息“孤岛”。未来,应该尝试建立政府、机构、企业等信息共享平台进行数据整合,尽可能完善我国个人征信体系。随着我国商业银行消费信贷业务的迅猛发展,个人信用评估得到了空前的重视。科学有效的个人信用评估方法成为了商业银行实现风险控制、进一步促进消费信贷发展的关键。因此个人信用评估的研究也便有了重要的应用和现实价值。
2 SVM原理和算法
2.1SVM函数和分类原理
支持向量机是Cortes和Vapnik于1995年提出的,在机器学习中通过拟合函数解决小样本,应用于高维模式线性等模式识别中,具有特有的优势。
支持向量机是一种基于分类边界的方法,其原理是采用分类超平面把空间中两类样本点正确分离,同时获得最大边缘(即正样本和负样本距离超平面最小),对于分类聚集在不同的二维平面上,这样就会设定该算法的目的,在设定目标,进行训练,确定分类的边界,这样可以设定线性和非线性的,如果是多维的比如N维就必须先来设定空间点,再来设计相关空间维中的面,通过这个面在来设计N维中的点和面。如果设定线性分类器使用超过平面,边界就会超出曲面。线性划分如图1。这样可根据新的数据相对于分类边界位置进行分类判断。
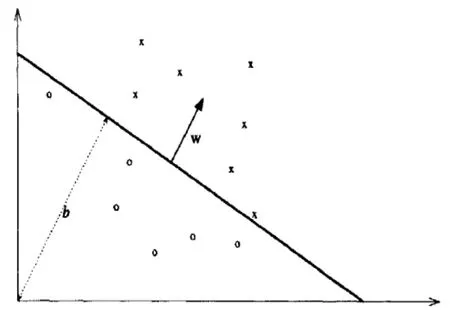
图1 线性划分Fig.1Linear division
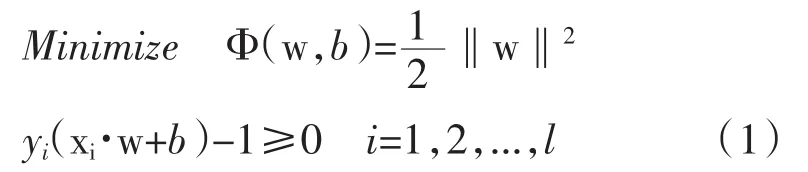
最优分类超平面方法向量就是范数最小的满足约束w。其目标函数和约束函数分别是上下凹的二次型,如果有凸规划是非常严格的。可以根据一些理论根据来解决这种规划问题如最优理论再通过下面的公式来解决。
那么约束性非线性规划问题如下公式(1)。
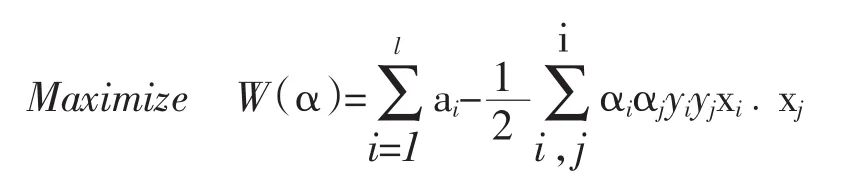
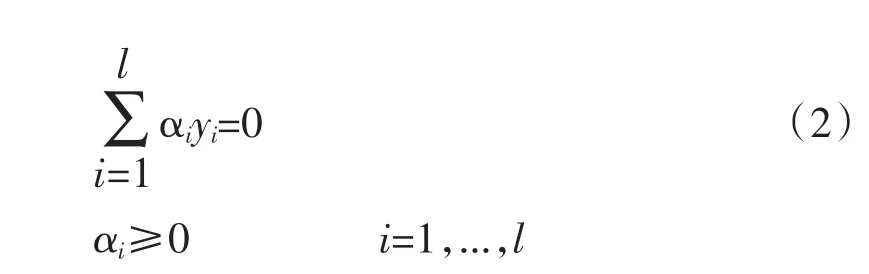
其中αi是样本点xi的Lagrange乘子。根据Kuhn-Tunker条件定理指出:无效约束所针对的Lagrange乘子是为0;因此其物理意义是说非支持向量xi的Lagrange乘子是0。所以分类规则仅由恰好在超平面边缘上的少数支持向量来决定,这和其他样本没关。即为“支持向量机”。
而对非线形情况,只将在对偶问题中的点积通过卷积核函数K(xi,xj)来代替。针对样本点不可分的情况,来构造软边缘分类面,最终获得Wolfe对偶问题同原来是相似的,就是α多了个上限约束。因此这个上限C也代表着对错分样本的惩罚力度,通过在边缘之内的样本对分类面的构造能够起到的作用是比较有限制的,即所谓“软边缘”。最后,针对求最大值是可以转化为取负来求最小值,那么数学模型表达式如公式(3)。其中H是个半正定的对称矩阵[yiyjK(xi,xj)]li,j=1(其线性表示(XY)T(XY),X=[x1,x2,…,xl],Y=diag(y1,y2,…,yl)),而α=[α1,α2,…,αl]T是个对偶问题也具有约束的一个二次规划,它通过Kuhn-Tucker条件(SVM的文献中称为Kaush-Kuhn-Tucker,KKT)也可等价地转换为式子(4)。其中ui是一个分类面(在非线性下不确定是超平面)函数作用在xi上的输出式子(5)。
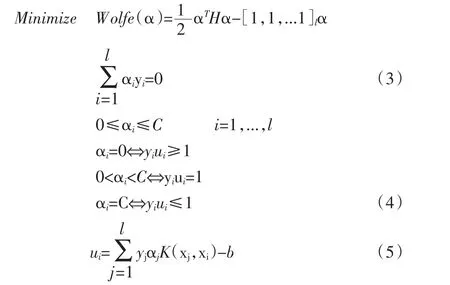
对于KKT条件在研究的问题中有具体的意义:一是xi为非支持向量,处在分类面边缘以外,其中Lagrange乘子是0,对分类面构造是无影响的;二是xi为正好在分类面上的支持向量,针对的Lagrange乘子为非0;三是xi在分类面边缘以内甚至被错分,其中Lagrange乘子是受到上限的限制而为0。
2.2SMO算法和构建思路
在计算机内存无法承受数据量时,也就是成千上万的样本时,我们就要采用一些办法来解决,也就是不同的算法块和分解等。如果我们每次训练多个样本就可能会同时处理两个样本,这里面提供SMO(串行最小化)的方法,这里包含两个重要算法就是α的选择,还有一个是α的更新处理。
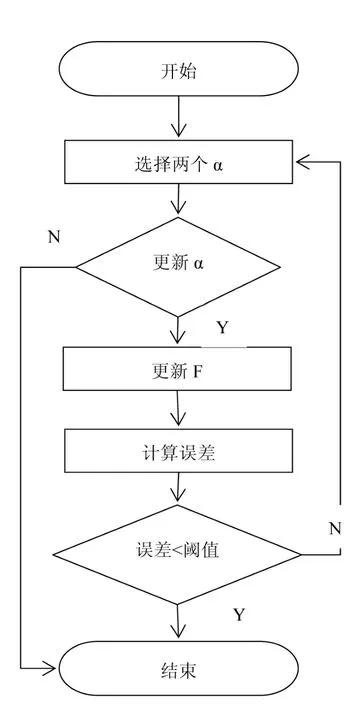
图2 训练基本流程Fig.2Basic training process
2.2.1α的选择算法
事实上,许沁想错了。许沁在葛局长的心中,早已没有任何位置了。当然这并不是位置的问题,而是为官之道。在葛局长看来,许沁是条狗,是条随时会咬人的狗,是条翻脸不认人的狗。一旦受到威胁或伤害,她会逮谁咬谁。葛局长不能不严加提防,因而断然割断了和许沁的任何联系。
通过选择两个与KKT条件违背的比较严重的两个αi,设定为内外循环。在外层循环中通常因为边界样本的问题需要调整和遍历,这是非常重要,而边界样本常常是不能得到进一步调整,因此留在边界上。可以在此过程中找出(yi=1,αi<C)或(yi=-1,αi>0)的所有样本中-yi*∂(di)值最大的(这是比较可能不满足-yi*∂(αi)≤b条件的样本)。内层循环:将外层循环中选定的样本αi,去找到这样的样本αj,使得样本最大。将公式(6)中更新α的一个算式,表示的是在选定αi,那么αj为更新算子下,样本最大。如果选择α的过程中发现已经符合了KKT条件,那么算法结束。
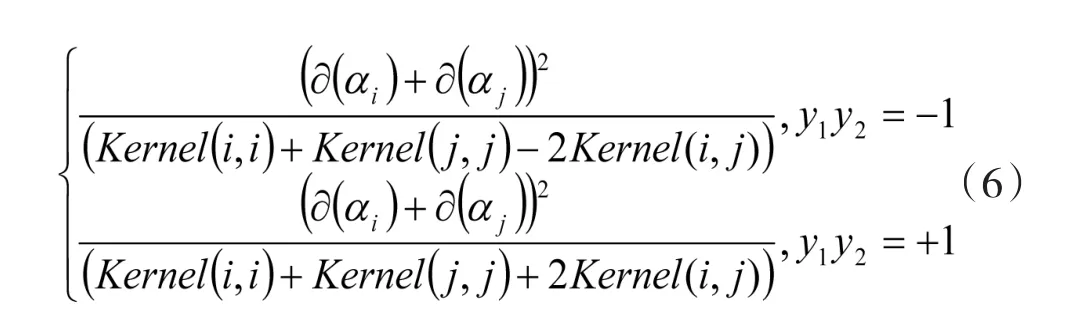
2.2.2α的更新算法
在我们使用SMO算法时,需要每次去设计样本,或者转化约束形式为直线约束:α1+y1y2α2=d(d
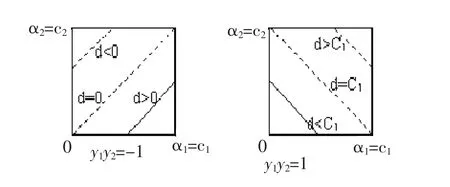
图3 约束转化Fig.3Constraint Transformation

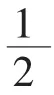
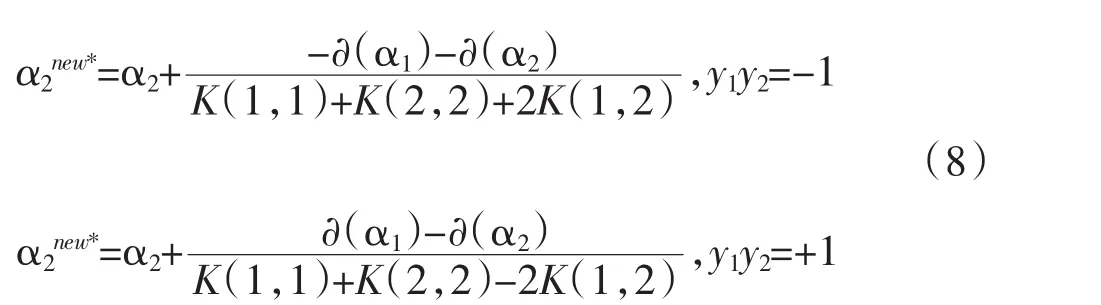
最终获得结果如式子(9)。
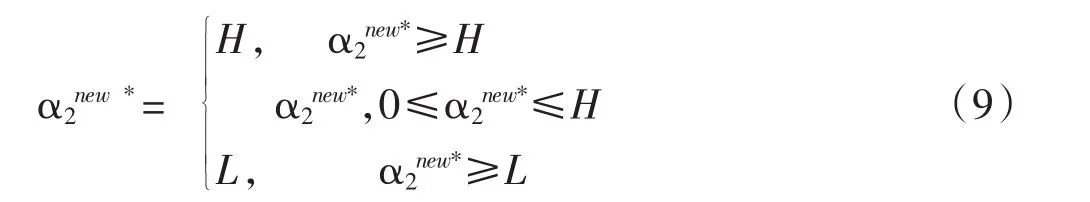
由于在运算时使用大量的内存,这样运算速度就会慢,当数据量大时如果采用SVM算法,那么速度就会下降。那么来设计一个好的方法,就是一边读取一边运算,运算完就倒出内存,让系统继续执行。这样样本在运算时就会减少,我们再设计样本训练时α[i]一旦达到边界(α[i]=0或α[i]=C),α[i]就不变了,这样样本变小,最终通过SVM来处理样本。我们在公式中检验样本参数α[i]的值来设定达到边界的问题,我们需要去掉边界样本来进行下一步运算。
通过公式(10)所展示的,在不确定这里面参数b时,我们要想得到最优解就需要去使用SVM(0<α[i]<C)的样本带入,在当前使用公式得到b的情况很多需要我们不停去探索,那种方法才是最有效的。在libSVM中,去设定y=-1与y=1的两种支持向量求得b,然后再取平均值。
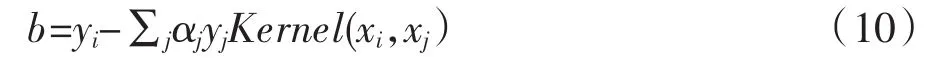
SMO和SVM两个算法都是将处理整个二次规划问题,可以很好地处理小问题,那么两者之间不同的是SMO这种方法可以去处理分解小规模,之后再来判断两者样本的问题,如果我们采取问题分析理解的方式来处理的化,会完善的很好。
我们进行个人信用评估处理和实践上,会有不同的误判,一是把好的客户当做不好的来处理,在客户到银行办理业务时拒绝不同意为其贷款,另外一种是将不好的客户当做好的处理,那么不讲诚信的人也能到银行贷到款,办成业务等等,为了避免这几种形式错误产生,我们需要建立模型,通过不同因子来完成参数设定决定模型的可信度,那么通过建立SVM方法,设置参数,为决定性参数和惩罚性因素。这样利用SVM建立个人评估模型是非常具有说服力的,选择RBF核函数,通过这个核函数具有较强的非线性映射能力。但是如果用SMO就不能完成这样的效果,会有一组参数来处理误判的可能。
3 样本数据分析
我们通过从某个工商银行在最近两年的个人信用贷款的数据中,获得发放消费贷款等数据信息,去除掉缺失的样本数据,会获得2 114个样本,那么怎么来判断违约的数据,如何设置违约次数,设定一个标准或者一个区域,这个标准就是用户在分期付款时,滞后还款,或者不能保证金额还款。在西方一些发达国家同一年中出现违约不能超过4回,否则信用大大降低,而在我们国家信用评估才刚刚开始所以设置样本标注要松一些,这里面我们定义10,如下面表1。
根据这些数据,我们去分开抽样,将样本设置违不违约。只有抽出的实例来看看这两种情况的对比,如果因为样本不平衡那就是模型不稳健,如果出现这两种情况非常接近的化或者很相似,然后进行稳定处理,通过选择高于两倍的方差,去检查不对的数据,通过上面的方法我们选择所有的样本进行训练和检查,并随机处理这几个部分。一部分是1 056个样本,在这里面有514个违约样本,还有542个未违约样本来进行训练来设置模型;在第二部分1 058个样本,里面有496个违约样本,还有562个是未违约样本,进行检验模型的应用效果。
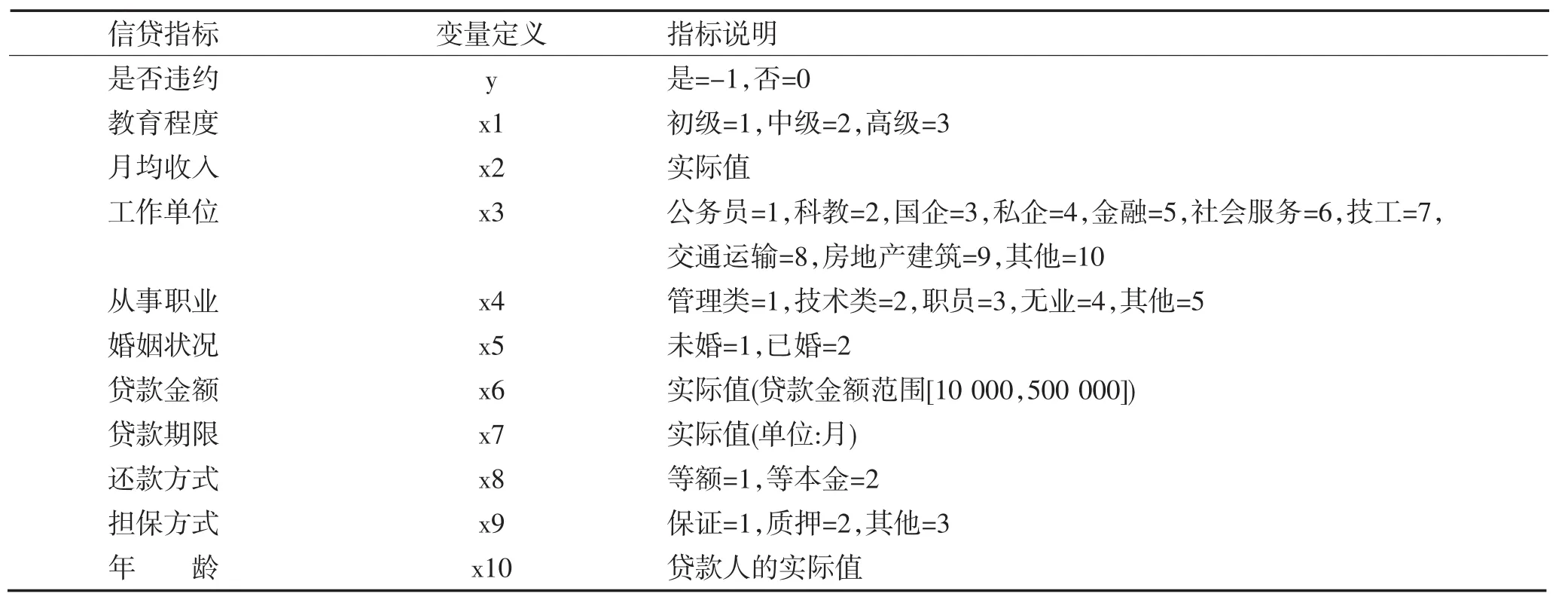
表1 指标和说明Table 1Index and instructions
为了收敛模型加快,根据要处理模型来进行不同数据进行训练和检验,然后进行处理,那么根据表格中的指标值去形成不同变量如离散型和连续型等等,根据上面的选择参数来设计两种变量(x1、x3、x4、x5、x7、x8、x9),根据最大最小进行方法完善,通过下面公式所示。其中Y∈[0,1]代表归一变化后的变量值;Xmin与Xmax来表示不同变量X的最小值和最大值。

针对连续型变量(x2、x6、x10),是通过对变量值的分布状况进行处理,这3个变量变化都近似正态分布。
4 评估模型完善
4.1个人信用评估流程
通过设计信用评估参数,来完成操作流程设计,通过设计两种方法,特别是SVM方法来完善模型,其流程模型如图4。
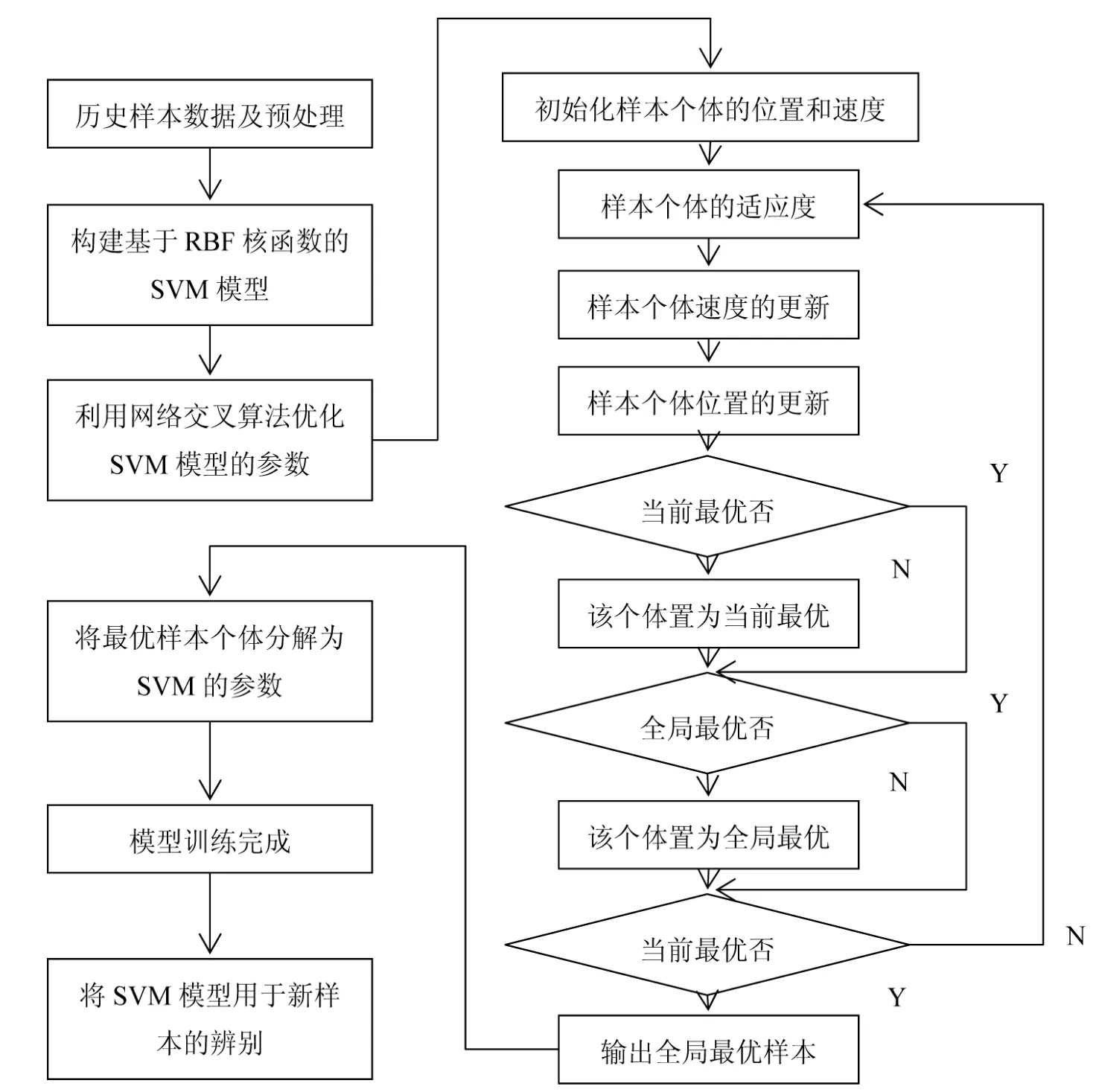
图4 信用评估流程Fig. 4Credit Evaluation Process
4.2SVM模型的建立过程
假设训练数据(x1,yi),…,(xl,yl),x∈Rn,y∈{+1,-1}通过设定平面(w·x)-b=0来确定分开,根据我们预测不同样本,进行比对,根据测得距离来判定选择的最大能力(即为边缘最大)的分类超平面可得到最佳的推广能力(最为稳妥地处理两种样本界限),离此最近的少数样本点来分成那些是最优平面,通过对比样本来设定,根据式子(12)描述样本间隔为Δ的分类超平面。
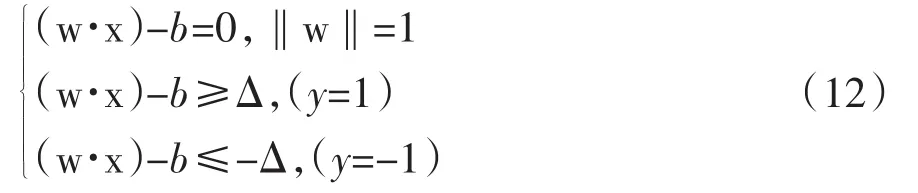
如果把这个分类超平面进行归一化:让Δ=1,通过w与b去设置不同比例缩放。根据设定离超平面最近的样本点SVM满足式子(13)。向量到超平面的距离为1/||w||。因此,这个最优化问题是通过公式(1)来进行运算。

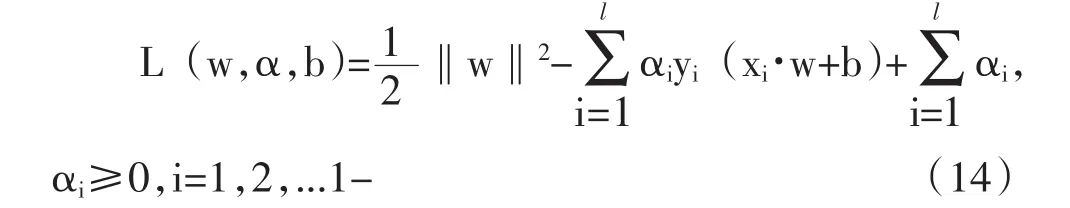
在完成公式对偶处理后,通过样本中的问题来支持向量形式展示,通过这方面使用SVM出测试推广非线性情况。
通过去创建SVM模型的评估系统,开始建立这个模型,是想让我们去分析核函数,然后去设置RBF径向基来完成较强的非线性能力,在进行较为广泛的使用中,通过RBF来设置SVM标准,还要需要之前提到的核心函数以及又决定左右的惩罚因子等等。通过选择参数应该具有很强的影响力,再通过不同方式的验证来确定SVM的设定标准,这样就能够明确其中的最有参数是什么,利用惩罚因子的查找范围[2-5210],核心参数查找范围为[2-1025],重新设置Cn+1=2*Cn和γn+1=2*γn。那么我们能得到的最优参数为来源于真是数据引入模型运算的惩罚因子C=8.0和核心参数γ=0.003 906 25。利用交叉验证确定分类精度可达94.697%,最后在根据标准SVM算出最优参数对样本进行训练,最终得到的参数w,b的结果为:w=-2.733 8与b=-0.245 840。
根据得到的参数w,b通过公式(14)获得SVM的决策函数值。由于个人信用评估实质上是分类的问题,所以,通过最终把样本划分为违约和未违约类。因此先对信用评估中出现的两类误判进行说明。在银行与其他金融机构当中,第二类误判是损失更大的。通过SMO算法的SVM模型在训练样本上的分类结果见表2。把训练后的SVM模型应用大检验样本判别,来得到分类结果。

表2 两类误判结果Table 2Results of two false positives
4.3结果分析
根据表2可以得出,SVM在训练样本与检验样本上,2误判的个数比1类误判的个数少很多,这表明研究采用SMO算法针对2误判的控制是非常有效的,这也可以使商业银行在实践操作中尽量避免信用风险。在分类精度上,模型的训练样本与检验样本上都可以达到95%,可以说效果是非常好的,相比曾经用过的统计模型还有神经网络模型去得到运算结果,能说明分类效果才能达到这样的效果。进行训练样本交叉检验样本上分类结果的变化趋势来看,SVM分类精度有0.94%的下降,因此该模型的稳健性是比较理想的,对于动态变化的信用数据更具有适用性。
5 结论
研究采用SVM的SMO算法完善个人信用评估方法,在进行个人信用数据获取并分析时,通过结果来分析该模型,能够有效的控制信用评估中给银行造成的损失,有利于规避信贷风险。因此,目前通过银行的个人信用信息、在信用影响的环境动态变化情况下,选择SVM模型是具有优势的。
[1]Angilella S,Mazzu S.The financing of innovative SMEs:A multicriteria credit rating model[J]. European Journal of Operational Researchc,2015,26(2):344-252.
[2]叶菁菁.P2P网贷个人信用评估国内外研究综述[J].商业经济研究,2015(11):34-39.
[3]陈昊洁,姜明辉.个人信用行为评估方法再思考[J].学术交流,2015(12):12-15.
[4]王慧勤,雷刚.基于LIBSVM的风速预测方法研究[J].科学技术与工程,2011(22):23-25.
[5]黄勇.完善我国个人信用社会征信体系的对策探讨[J].征信,2012(5):67-69.
[6]李娴.基于GCV的LS-SVM模型选择在个人信用评估中的应用[J].河南大学学报:自然科学版,2011,41(3):15-19.
Perfection of Personal Credit Evaluation Method Based on SVM Algorithm
Huang Wei1,Zhang Liang2,Tang You1
(1.Heilongjiang Institute of Finance and Economics,Haerbin 150025;2.Yanjing Polytechnic Institute)
Among many pattern recognition tools,Support Vector Machine(Support Vector Machine,SVM)is a very effective one.A model based on SVM was proposed to promote efficiency of financial institution of personal credit evaluation method.Through researching user credit data of a bank,designing the specific evaluation process,using the SVM SMO algorithm to build the model of processing parameter optimization,it was characterized by high classification precision and low misjudgment rate,so it was stable and could control the consumption credit risk.Dealing with commercial bank credit rating,application of this model would solve the credit application and policy implementation,which had a certain practical significance.
SVM;personal credit evaluation;SMO algorithm
F832.479
A
1002-2090(2016)02-0105-06
10.3969/j.issn.1002-2090.2016.02.022
2016-01-04
黄巍(1981-),女,副教授,哈尔滨工业大学毕业,现主要从事金融投资方面的研究工作。
唐友(1979-),男,教授,E-mail:tangyou9000@163.com。
