基于包含多个刚体运动目标的单目视频三维重建研究*
2016-11-07李沛燃黄文杰陶晓斌
李沛燃 黄文杰 陶晓斌
(华中科技大学自动化学院 武汉 430074)
基于包含多个刚体运动目标的单目视频三维重建研究*
李沛燃黄文杰陶晓斌
(华中科技大学自动化学院武汉430074)
基于单目视频的动态场景重建一直是一个非常艰巨的任务。目前大多数的研究主要集中在基于单目视频的静态场景重建,而对动态视频重建的关注比较少。此外,未知数量的运动目标和稠密重建增加了动态场景重建的难度。论文将提出一个完整的重建系统用于恢复包含多个刚体运动目标的单目视频中的动态场景结构。主要通过大尺度光流法获得特征点轨迹,并在此基础上对独立目标进行姿态估计,并提出了基于超像素的精确目标分割算法,目的是获得每一个实体的稠密重建。
场景重建; 特征点轨迹; 分割; 运动恢复结构
Class NumberTP391
1 引言
近年来,3D静态场景的建模已经取得了突破性的进展。其中,大多数的研究都是遵循一个特定的步骤:首先提取一组图像中的特征点,然后对多幅视图的特征点进行匹配,基于匹配的特征点恢复相机参数,从而得到场景的三维结构[1~2]。其中,Snavely,N.主要通过SFM (structure from motion) 从无序图片中恢复未知相机的姿态和获得稀疏点云[2]。除了稀疏点云的重建以外,很多研究也集中在多视图稠密重建[9]。其中,Seitz,S.M.对多种立体匹配算法进行比较,并且是第一个提供已标定的多视图数据集[13]。Kolev,K.在前者的基础之上提出了一个全局能量模型,融合了轮廓信息和立体信息[14]。值得一提的是,深度信息也是一个非常有前景的3D重建方法[11],主要思想是通过恢复图像的深度信息,融合多幅深度图进行稠密重建。此外,很多研究集中于基于单个视频的稠密表面重建,主要包括基于场景流(scene flow)[15],mesh-based 稠密表面重建[16],patch-base稠密表面重建[17]。
但是,大多数捕获的视频中,动态场景视频比较常见。而上述的研究只能用于处理静态场景,它们在应对多目标运动场景方面是十分有限的。最近,Bergen,J.提出了一个包含动态运动目标的场景分割标准[5],它是一个重要的3D运动估计和重建的预处理过程。 视频重建主要有基于两个视图[4]和基于多个视图[3,6]。其中,文献[3~4]对像素水平的分割和每个运动目标的稠密重建的关注度非常低。文献[6]利用特征点轨迹处理多视图的场景重建,但是它并没有分割出运动目标和对其进行稠密重建。此外上述研究并没有提出一个完整的动态场景的重建方法。
针对上述问题的局限性,本文提出了一个完整的基于包含多个刚体运动目标的单目动态视频的重建系统,用于解决包含多个刚体运动目标的重建问题。
2 本文的系统框架
本文的主要贡献在于提出了一个完整的基于包含多个刚体运动目标的单目动态视频的重建系统,其中包括精确的刚体目标分割和每个运动实体的稠密重建。重建结果的好坏,取决于能否准确地分割得到前景运动目标以及背景目标的准确轮廓,以及能否准确计算出相机的运动参数。目前,这些都是计算机视觉领域的重点与难点问题。
场景的运动来源主要有两个:一个是相机的运动,一个是物体的运动。静态背景的运动只来源于相机本身的运动,而运动目标的运动同时受相机运动和目标运动影响,所以每个运动目标的运动与静态背景的运动是不同的。假设每幅图像中的每个刚体目标对应一个虚拟相机,虚拟相机的参数由相机自身运动和目标运动共同影响得到。这样,对于视频中的每个刚体目标,对应的虚拟相机的参数也可以遵循标准的SFM(structure from motion)方法获得。
本文首先利用传统的光流方法计算视频序列的特征点轨迹,并对特征点轨迹进行部分剔除,然后通过特征点轨迹分类算法将特征点轨迹聚为不同的类。基于运动的一致性准则,不同运动目标代表不同的运动类型,所以同一目标的运动轨迹会归为同一类。但是,这些轨迹是稀疏的。为了单独地重建每一个运动目标以及背景,这里需要精确的边界轮廓。因此,提出了一个自动地基于超像素的多标记Graph-cut算法,目的是为了得到每一个目标的精确边界。在图像分割之后,基于每一个分割区域和相应的特征点轨迹,估计目标所对应的虚拟相机的参数和对应的稀疏三维点云,最后利用PMVS[9]获得每一个目标的稠密实体。整个的流程图如图1所示。

图1 流程图

图2 动态场景的分割
3 动态场景的分割
为了获得每一个目标的三维信息,需要解决分割问题。首先应用光流算法进行特征点的提取和跟踪,获得长轨迹。然后利用特征点轨迹分类算法将特征点轨迹归类为不同的目标。最后利用基于超像素的多标记Graph-cut算法获得目标的准确轮廓,从而得到准确的目标分割结果。算法流程图如图2所示。
3.1特征点轨迹的获取
在运动视觉领域中,序列图像之间光流场的求解,目的在于揭示致密目标点之间的匹配关系,通过目标点之间连续的匹配关系,可以得到目标点的运动轨迹,论文中称为特征点轨迹。特征点轨迹的准确性对于恢复相机参数非常重要。
基于连续图像的运动轨迹的估计有很多种方法。最常见的两种方法是光流(optical flow)和特征跟踪(Feature Tracking)。Kanade-Lucas-Tomasi(KLT)是一种比较著名的特征跟踪算法。通过对光流法和KLT特征跟踪算法进行比较,可以发现,就计算对象而言,光流法可以对图像进行均匀采样,跟踪所有像素的运动,而特征跟踪方法是通过选取算法选取一些点;就计算方法而言,光流法采用了微分方法,而特征跟踪方法是基于图像块的匹配。
论文中,采用文献[8]提出的基于大尺度变换和GPU加速的光流法,来获取连续帧之间的特征点轨迹。它在准确度和时间消耗上都优于KLT算法。其跟踪特征点轨迹原理:
1) 对一个连续的视频帧序列进行处理。
2) 针对第一帧图像,采用均匀采样的方法获取特征点。
3) 基于大尺度变分模型获取特征点在每一帧的跟踪结果。
4) 其中,当出现没有纹理的区域时,特征点将不存在。同时,新的特征点将被提取出来,不同于很多其他的方法,不需要特征点轨迹是相同的长度,因为在估计目标的三维结构时,只需要任意两帧之间的匹配特征点。
3.2特征点轨迹的分类
一个单目动态视频包含未知的运动目标。首先,基于大尺度变换光流算法提取特征点轨迹,T={t1,t2,…,tk}代表特征点轨迹,L={l1,l2,…,lk}代表特征点轨迹T所对应的标记,其中li∈{1,2,…,m},i∈{1,2,…,k}。Brox等提出相同目标的运动向量满足运动一致性,可以用于将特征点轨迹聚为不同的类[7]。分析特征点长轨迹聚类的效果比两帧之间的聚类的效果更好,基于光流的一致性运动和运动的最大不相似性可知,所有的特征点轨迹将被聚为m类。考虑两个特征点轨迹ti和tj,其运动的最大不相似性可以表示为
(1)
此外,轨迹的最近空间距离估计可以表示为
(2)

ω(ti,tj)=e-λd2(ti,tj)
(3)
这样可以得到一个k*k的相似性矩阵W。通过谱聚类算法对相似度矩阵W进行聚类,每一个特征点轨迹ti将被分配一个标记。图2(a)显示了两个运动目标的运动,图2(b)显示了其聚类结果。
3.3基于多标记Graph-cut的目标分割
场景中目标重建结果的好坏与场景中目标的分割有非常大的关系,因此获取场景中运动目标的准确轮廓是非常重要的。这里提出了基于超像素的多标记自动分割算法。在获取特征点轨迹的聚类结果之后,首先,利用“SLIC”[19]超像素分割算法,对图像进行边界保存完好的超像素分割,如图2(c)。S={s1,s2,…,sN}代表超像素集合,在建立多标记能量函数之前,第一步,需要对超像素进行筛选,如图2(d),因为光流的稀疏性以及一些纹理不丰富的区域采集不到光流点,通过筛选准则将不符合的超像素进行剔除,对于一个超像素,其筛选准则如下:
1) 如果超像素中通过的所有特征点轨迹属于同一个标记,那么,超像素赋予相同的标记;
2) 如果超像素中没有通过任何的特征点轨迹,那么,这个超像素将被抛弃。
3) 如果超像素中通过的特征点轨迹属于不同的标记,那么这个超像素将被抛弃;
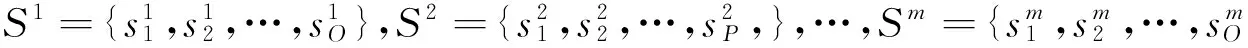
(4)
其中,S代表图像中所有超像素的集合,N⊂S*S代表基于超像素的邻接关系。
数据项D(s,Ls)度量分配每一个超像素s到Ls的GMM模型值。Ss,q(Ls,Lq)度量临界超像素s,q之间能量,通过迭代每一个超像素的分配标记和更新GMM参数解决最小化能量问题。
4 虚拟相机参数估计和稠密估计
在准确分割之后,原始的视频被分为m个子序列,每一个子序列包含一个单独的目标实体。如图2(f)显示了每一个子序列的其中三帧。每一个子序列对应一组虚拟相机。基于特征点轨迹,虚拟相机参数可以通过SFM估计得到,基于bundle adjustment中的最小化重投影误差获取参数。
特别地,基于宽基线和最大的匹配对数来选取初始的相机对估计初始的相机参数,然后,通过bundle adjustment进行参数调整。接着,和已重建三维点匹配数量超过一定阈值的新图片被加入,新图片的相机参数通过PnP方法进行估计,然后新的点也会通过三角化得到,最后利用bundle adjustment进行一次全局优化。上述步骤被重复进行直到没有图片满足要求。通过这个方法,可以得到每一个虚拟相机的参数,以及每个刚体目标初始的稀疏三维点云。基于估计的虚拟相机参数,利用PMVS算法[9]可以获得每一个运动实体的稠密重建。最后,通过泊松表面[18]重建得到每一个实体的网格模型,并且进行纹理映射可以得到有纹理的网格模型。
5 实验分析
通过单个摄像机拍摄采集真实世界的单目动态视频,对上述方法进行测试。其中,利用了四个视频序列作为测试序列,分别包含一个运动目标和包含两个运动目标的单目动态场景,实验效果如下。
5.1包含一个运动目标的单目动态场景
图3是“one box”序列图像(1280*720)中的三帧图像,分别为第0,55,99帧。在这个序列中,包含一个运动的盒子,盒子从左向右运动,摄像机围绕整个场景拍摄。这个视频序列包含100帧连续图像。图3(b)为基于特征点轨迹分类算法得到的分类结果。因为运动的盒子与背景的运动信息不同,所以基于运动信息的特征点轨迹分类算法可以明显的将前景运动盒子和静态背景分离。其中盒子标记为黑色的点,而背景标记为灰色的点。图3(c)为目标的分割结果,基于超像素对特征点轨迹进行过滤后,通过分割算法分别得到了盒子和背景的精确边界。图3(d)显示了盒子和背景的稀疏重建结果,其中盒子包含1078个稀疏点,背景包含8664个稀疏点。图3(e)显示了盒子和背景的稠密重建结果,其中盒子包含4625个稠密点,背景包含40020个稠密点。图3(f)显示了盒子和背景的纹理。通过这个方法,恢复了单目动态场景中运动盒子和静态背景的3D场景信息。
另外两个相似的实验验证恢复包含一个运动目标的单目场景的三维信息的可行性,如图4和如图5。图4显示了序列“cup”的3D重建结果。图5显示了序列“horse”的3D重建结果。在这两个实验中,“cup”和“horse”上存在一些空洞,这是因为这些区域缺少足够的纹理信息。
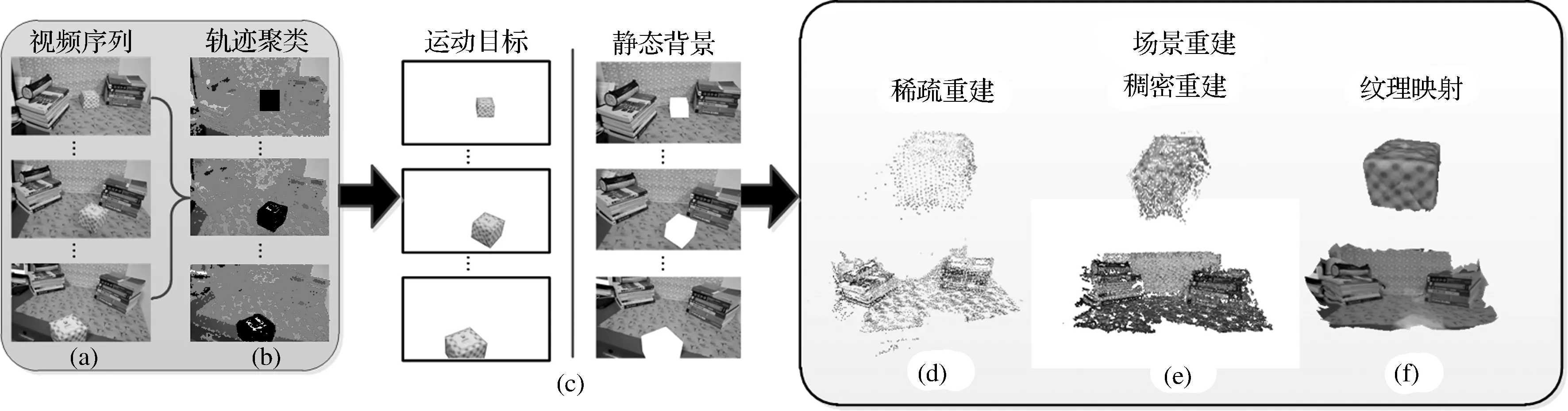
图3 “one box”序列图像的重建结果

图4 “cup”序列图像的重建结果

图5 “horse”序列图像的重建结果

图6 “two boxes”序列图像的重建结果
5.2包含两个运动目标的单目动态场景
另外一个证明是当场景中包含两个独立运动目标。它可以证明场景中可以处理多个运动的目标。图6显示了输入的包含两个运动盒子box1和box2的序列图像。其中,box1从右向左运动,box2从左向右运动,摄像机从左向右围绕场景拍摄。图6(b)显示光流点跟踪和基于特征点轨迹聚类算法后得到的结果,其中box1和box2分别标记为白色和灰色,背景上的特征点轨迹被标记为黑色。图6(c)为得到的精确的两个运动目标和静态背景的精确的分割结果。图6(d)显示了box1从稀疏重建到纹理映射的结果,通过稀疏重建包含1037个稀疏点,通过稠密重建增长到4736个稠密点。图6(e)显示了box从稀疏重建到纹理映射的结果。其中稀疏重建591个点,稠密重建得到3282个点。图6(f)得到了静态背景从稀疏重建到纹理映射结果。其中稀疏重建2345个,稠密重建43969个。
6 结语
本文提出一个完整的基于包含多个刚体运动目标的单目动态场景视频的重建系统。该方法包含三个主要的步骤。 1) 通过光流跟踪法获取特征点轨迹,并基于运动信息获得特征点轨迹的聚类结果; 2) 每一个运动实体都被自动的分割出来,并被分配一个虚拟相机; 3) 通过标准的SFM方法分别单独估计每个运动目标对应的虚拟相机的参数和稀疏三维点云,接着通过PMVS获得目标的稠密重建结果。为了可视化,纹理映射方法也同时被使用。通过上述方法,恢复了包含多个刚体运动目标的单目运动场景的三维结构。
[1] Hartley, R, I., Zisserman, A. Multiple View Geometry in Computer Vision[M]. Cambridge: Cambridge University Press, second edition,2004.
[2] Snavely, N., Steven, S. M., Szeliski, R. Photo Tourism: Exploring image collections in 3D[J]. ACM Transactions on Graphics,2006,25(3):835-846.
[3] Han,M., Kanade, T. Reconstruction of a scene with multiple linearly moving objects[J]. IJCV,2004,59(3):285-300.
[4] Vidal, R., Ma, Y., Soatto, S., et al. Two-view multibody structure from motion[J]. IJCV,2006,68(1):7-25.
[5] Bergen, J., Burt, P., Hingorani, R., et al. A benchmark for the comparison of 3D motion segmentation algorithms[C]//Proc. CVPR,2007:1-8.
[6] Ozden, K. E., Schindler, K., Gool, L. J. V. Simultaneous segmentation and 3D reconstruction of monocular image sequences[C]//Proc. ICCV,2007:1-8.
[7] Brox, T., Malik, J. Object segmentation by long term analysis of point trajectories[C]//Proc. ECCV,2010:282-295.
[8] Sundaram, N., Brox, T., Keutzer, K. Dense point trajectories by GPU accelerated large displacement optical flow[C]//Proc. ECCV,2010:438- 451.
[9] Furukawa, Y., Ponce,J. Accurate, Dense, and Robust Multiview Stereopsis[C]//Proc. PAMI,2009,32(8):1362-1376.
[10] Carsten Rother, Vladimir Kolmogorov, Andrew Blake. “GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts[C]//Proc. PAMI,2009,32(8):1362-1376.
[11] Goesele, M., Snavely, N., Curless, B., et al. MultiView stereo for community photo collections[C]//Proc. ICCV,2007:1-8.
[12] Liu, L., Tao, B. Image segmentation by iterative optimization of multiphase multiple piecewise constant model and Four-Color relabeling[J]. Pattern Recognition,2011,44(12):2819-2833.
[13] Seitz, S. M., Curless, B., Diebel, J., et al. A comparison and evaluation of Multi-View stereo reconstruction algorithms[C]//Proc. CVPR,2006:519-528.
[14] Kolev, K., Klodt, M., Brox, T., et al. Continuous global optimization in multiview 3d reconstruction[C]//Proc. IJCV,2009,84(1):80-96.
[15] Newcombe, R., Davison, A. Live dense reconstruction with a single moving camera[C]//Proc. CVPR,2010:1498-1505.
[16] Ummenhofer, B., Brox, T. Dense 3d reconstruction with a hand-held camera[C]//Proc. DAGM,2012:103-112.
[17] Kang, Z., Medioni, G. Progressive 3D Model Acquisition with a Commodity Hand-held Camera[C]//Proc. WACV,2015:270-277.
[18] Kazhdan, M., Bolitho, M., Hoppe, H. Poisson Surface Reconstruction[C]//Proc. Symp. Geometry Processing,2006.
[19] Achanta, R., Shaji, A., Smith, K., et al. SLIC superpixels compared to state-of-the-art superpixel methods[C]//Proc. PAMI,2012,34(11):2274-2282.
3D Reconstructing Dynamic Scene From Monoculartvideo Containing Multiple Moving Rigid Objects
LI PeiranHUANG WenjieTAO Xiaobin
(School of Automation, Huazhong University of Science and Technology, Wuhan430074)
3D reconstruction of dynamic scene from a single video has been a challenging task. While traditional methods can only recover the structure of a static scene from the motion of a moving camera, how to reconstruct the scene with dynamicobjects has been paid less attention. In addition, the unknown number of moving objects and the dense reconstruction of each moving object make the problem more difficult. In this paper, a method for reconstructing monocular dynamic scene with multiple moving rigid objects captured by a single moving camera is proposed. It combines applying large displacement optical flow to get point trajectories, and gets the pose of dependent objects and their exact boundary. Finally the dense reconstruction of each object will be gotten.
reconstruction, dynamic scene, segmentation, structure from motion
2016年4月10日,
2016年5月25日
李沛燃,女,硕士研究生,研究方向:模式识别与智能系统。黄文杰,男,硕士研究生,研究方向:模式识别与智能系统。陶晓斌,男,硕士研究生,研究方向:模式识别与智能系统。
TP391
10.3969/j.issn.1672-9722.2016.10.037
