基于EEMD的异常声音特征提取*
2016-11-07陈志全乔树山
陈志全 杨 骏 乔树山
(中国科学院微电子研究所 北京 100029)
基于EEMD的异常声音特征提取*
陈志全杨骏乔树山
(中国科学院微电子研究所北京100029)
针对使用梅尔倒谱系数MFCC,LPCC等传统语音特征时异常声音识别率低的问题,结合到异常声音具有高度非平稳、非线性的特点,提出一种基于总体平均经验模态分解的异常声音特征提取方法。首先对声音进行分帧,对每一帧信号提取模态函数。对不同层模态函数提取包括短时能量,能量比,短时平均过零率,MFCC等特征,对信号的特征向量分段取均值作为最终的特征。基于这些特征的特征组合,采用支持向量机作为分类模型对七种异常声音进行识别,并测试了不同信噪比条件下识别的效果,结果表明基于EEMD的特征相比MFCC,LPCC等特征能有效提高识别率。
异常声音识别; 经验模态分解; 特征提取; 支持向量机
Class NumberTP311
1 引言
近些年随着人工智能等相关技术的发展,安全监控在社会安全和国防中的作用愈发突出。目前的主要监控技术都是基于视频监控发展起来的,视频监控也为安全监控以及办案取证等提供了较为直接的证据支持。然而视频监控容易受光线、天气等因素的影响,而且其监控方向一般固定,只能监控一部分区域。相比于视频监控,声音监控具有以下优势:声音是一维信号,复杂度低,易获取;声音具有无向性,能够揭示区域内的异常状况。
异常声音检测和识别是声音监控主要的两个部分。在异常声音检测方面,文献[1]采用支持向量机(Support Vector Machine,SVM)检测是否有欢呼声和掌声,文中将音频按0.5s滑动分窗,并对每一个窗内的判别结果进行平滑。最终获得的F-value为79.71%。文献[2]采用四个OC-SVM分别对四类异常声音进行建模,将待识别的声音输入四个模型,比较模型输出选择其中一个作为声音的类别,其实质是一个声音识别算法,当声音种类较少时能够有效识别声音的种类,但种类较多时很难比较模型之间的输出进而得出正确的分类。文献[3]针对室内异常声音检测问题,提出一种基于集成学习的异常声音检测方法:先将声音按帧提取特征,然后将每一帧声音按内容分为不同的类别,接着利用一个异事件检测器对连续帧进行判别,此方法引入了环境的上下文作为判断的一个依据,但是不适合环境较为复杂的情况。文献[4]检验了不同的帧长对于声音检测的最终影响,结果表明不同的帧长对声音的影响较大。
目前,异常声音识别采用的特征主要是梅尔倒谱系数(MFCC),线性预测系数(LPC),短时能量和短时平均过零率等时域和频域特征。由于MFCC主要考虑了人耳的听觉原理,在语音识别中效果较好。但是相比语音信号,异常声音更具非平稳性,较为难以建模。故将MFCC作为特征识别异常声音,识别效果往往不够好。所以特征提取一直是异常声音识别研究的重点:文献[5]采用了基于MPFG-7的特征,并利用SVM作为分类器,对10种环境声音的识别率达到81.25%。文献[6]提出一种基于卷积非负矩阵分解的文特征提取方法来对环境声音检测和建模,非负矩阵分解能够有效发现描述信号短时谱的基本的频谱块,文章实验结果显示在低信噪比条件下此特征的检测和识别效果好于MFCC,能够作为MFCC的一种有效补充,结合MFCC能够提高声音检测识别系统的鲁棒性。文献[7]提出一种基于时频分析的特征提取方法:首先利用匹配追踪(Matching Pursuit,MP)时频分布技术构建信号的时频矩阵,接着运用非负矩阵分解技术分解信号的时频矩阵,最后对分解的向量提取时域和频域的特征。此特征对于文章中10种环境声音的识别率相对MFCC提高10%。文献[8~9]都提出基于匹配追踪算法的特征提取方法,并用于多种环境声音识别,结果表明基于MP的特征结合MFCC能够有效提高环境声音的识别率,但是MP算法选取原子较为麻烦,需要根据声音种类做出调整。文献[10]采用四个OC-SVM分别对四类异常声音进行建模,将待识别的声音输入四个模型,比较模型输出选择其中一个作为声音的类别,其实质是一个声音识别算法,当声音种类较少时能够有效识别声音的种类,但种类较多时很难比较模型之间的输出进而得出正确的分类。
考虑到异常声音具有高度非平稳性,非线性的特点,本文提出基于总体平均经验模态分解模式分量的异常声音特征提取方法。相比传统的MFCC等特征,能有效提高识别率且鲁棒性更好。
2 经验模态分解及总体平均经验模态分解
2.1经验模态分解原理(Empirical Mode Decomposition,EMD)
EMD是N.E.Huang于1998年提出的一种基于新的自适应信号处理方法。他将任意复杂信号分解成一系列固有模态函数(Intrinsic Mode Function,IMF)的和,每一个IMF体现了包含在原信号中的不同频率尺度的振荡特性,这种基本模式分量必须满足两个条件:信号的零点数于极点数相等或至多相差一个,以及由它的极大值和极小值确定的上下包络线关于时间轴对称。EMD分解的实质就是一组滤波过程,它逐级将信号不同尺度的波动或趋势分开。EMD方法提出后,很快被应用于医学、雷达、地震信号处理分析等相关领域中。
EMD是一种迭代循环算法,有三个基本的前提: 1) 信号有一个以上的极大值和极小值点; 2) 极值点间的时间推移定义特征的时间尺度; 3) 如果信号没有极值点只有曲折点,先对信号微分一次或多次找到极值点,再进行积分运算得到最后的结果。分解成的IMF反映了信号的内部特征,低阶IMF频率较高,随着阶数升高频降低。图1显示了典型枪声的EMD分解后的各IMF。算法的具体步骤如下:取原始信号为s(t):
1) 确定信号s(t)的全部极大值和极小值,根据极大值和极小值作三次样条插值将所有极大值和极小值连接起来,构造s(t)的上下包络线smax(t)和smin(t)。取两者的均值为平均包络线s1(t)。
2) 将信号s(t)与平均包络线s1(t)相减,得到一个新序列h1(t),即:
h1(t)=s(t)-s1(t)
(1)
3) 判断h1(t)是否满足IMF条件,若不满足,则再将h1(t)替换原信号s(t),重复步骤1)和2),得到h11(t),即:
h11(t)=h1(t)-s1(t)
(2)
假设筛选k次后h1K(t)满足IMF条件,则称其为第一阶本征模态函数,记为:
c1=h1k(t)
(3)
4) 从信号中减去c1(t),得到第一阶剩余信号r1(t),即:
r1(t)=s(t)-c1(t)
(4)
5) 将剩余信号r1(t)重复执行上述步骤,这一过程称为筛选过程,直到余项为单调函数不可再分为止。这样原信号即可由各阶IMF分量以及余项rn(t)表示:
(5)
2.2总体平均经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)
EMD被成功运用于各种信号处理领域中,但是随着研究的深入,研究者们发现EMD仍然存在一些问题,较为严重的就是存在模态混叠现象导致IMF失真,严重影响信号的特征提取效果。所谓的模态混叠是指一个IMF中包含多个频率尺度的信号分量,或者不同的IMF中包含了同一尺度的信号分量,结果表现为相邻两个IMF的波形互相混叠,相互影响。为了解决此问题,Huang提出一种改进方法:EEMD。EEMD分解信号时,先将原信号与不同的随机白噪声混合,并对混合后的信号进行多次EMD分解,再对得到的所有IMF分量求总体平均,得到最终的IMF作为原始信号的基函数。相比EMD,EEMD消除了模态混合问题,使得最终的IMF具有更明确的物理意义,较真实地反映了信号内在的本质。图2显示了典型枪声经过EEMD分界后的各个IMF情况。EEMD算法的五个步骤如下:
1) 对原始信号s(t)加入白噪声,设定EMD执行的迭代次数N;
2) 构建重构信号sn(t)=s(t)+wn(t),其中wn(t)(n=1,…,N)是与原信号等长度的随机高斯白噪声;
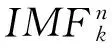
4) 重复执行2)与3)直到完成N次分解,得到所有的IMF;
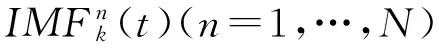
(6)
3 异常声音特征提取
3.1传统的声学特征
1) 梅尔倒谱系数(Mel Frequency Cepstrum Coefficients,MFCC)
MFCC是语音识别中最常用的特征,也是非语音识别最常用的特征之一。它通过将标准频率取对数映射到Mel频域,更加地符合人耳对不同频段的听觉响应特点。对信号作在Mel频域作傅里叶变换,并经过一组部分重叠的滤波器组获取不同频段上的信号的能量,最后通过离散余弦变换去除耦合即可得到声音信号的MFCC特征。本文中MFCC阶数为12阶。
2) 线性预测系数(Linear Prediction Coefficient,LPC),线性预测倒谱系数(Linear Prediction Cepstrum Coefficient,LPCC)
LPC的基本原理是一个语音的采样值能够用过去多个语音采样值的线性组合来逼近,它能较为精确地估计语音参数,用较少的参数就可以有效而又正确地表现语音信号的时域和频域的特性。LPCC是基于LPC利用自相关等方法求取的倒谱系数,被有效地运用在语音识别领域。
3) 频谱延展度(Spectral Spread,SS),频谱质心(Spectral Centroid,SC)
SS是指信号在对数频谱域的二阶中心矩。它描述了信号在对数频谱质心周围的分布状况。频谱质心是指信号对数能量谱的重心,它描述了信号能量谱的形状,揭示能量谱中高频及低频的比重,反映了信号在频域的分布情况。
4) 短时能量,短时过零率
短时过零率指信号在一帧内符号改变的次数,它粗略地估计出了信号的频率变化情况。短时能量指信号在一帧(本文中帧长50ms)时间内的能量值,通过短时能量的变化一定程度上也能反映出信号在时域的幅度的变化情况。
3.2基于EEMD的异常声音特征
由前所述,信号经过EEMD后成为若干个IMF分量,每个分量代表了声音信号发生的不同阶段,具有不同的物理意义。因此我们认为每个IMF分量带有不同的信息,基于每一层IMF提取特征能够代表原声音信号的特点。先对信号分帧,然后利用EEMD分解每一帧信号,对分解得到的每一层IMF提取特征,将所有层的特征组合成为信号最终的特征,同时为了能能够使用SVM作为分类器,输入的特征必须是单维和等长的,因此将信号平均分为四段,然后最后按段对信号的特征取均值,再将四段特征组合成为最后的特征。本文中提取的IMF层数为8层。具体流程见图3。

图3 基于EEMD的异常声音特征提取流程示意图
基于EEMD的特征主要包括以下几种:
1) 模态函数能量EEMD_EN及能量比值EEMD_RATIO
不同的模态函数对应信号的不同的发生阶段,为此可以认为每一个模态的能量值能够代表声音信号的特性。因此将对每一层信号提取短时能量,故总共n层EEMD分解对应的短时能量就组成一个n维的能量特征,称之为EEMD_EN。本文中采用的分解层数n=8。另外,由于不同的IMF分量具有不同的意义,不同层的模态函数的能量相对于原始信号能量的比值Ki式(7)也能刻画信号的特性,最后将每一层的比值组合构成信号的最终特征,称之为EEMD_RATIO。
(7)
其中xj指信号的IMF各个点对应的幅度。E指原信号的能量。
2) 模态函数梅尔倒谱系数EEMD_MFCC
由前可知,MFCC指信号在梅尔倒谱域不同频带的能量。对于声音信号的每一个IMF,其在梅尔倒谱域的能量也能刻画信号不同振动趋势的特性,因此对于每一个IMF提取的MFCC组成的特征能够更加细腻地刻画信号的变化特性,因此我们认为基于IMF的MFCC能够作为信号的特征,称之为EEMD_MFCC。本文中每一个信号最终提取出的EEMD_MFCC共96维。
3) 模态函数短时过零率EEMD_ZCR
原理同上,ZCR能粗略估计信号的频率变化情况。因此也提取了不同层IMF的短时过零率作为特征,特征维数为8维。
4 实验介绍及结果
音频识别中常用的分类器有神经网络(Neural Net,NN),支持向量机(Support Vector Machine,SVM),隐马尔科夫模型(Hide Markov Model,HMM)等。相比其他分类器SVM具有更好的泛化能力,且具有较好的可解释性。已经有相当多的文献证明SVM的识别效果好于NN和HMM。本文采用SVM作为分类器。通过Matlab调用台湾林智仁的LIBSVM软件包。
由于还没有统一公开的异常声音音效资源,本文的音效资源主要来自网络,包括findsound.com上的声音资源以及ideal sound 6000 series中的部分资源。其中有七种异常声音包括枪声、爆炸声、尖叫声、玻璃破碎声、警报声、撞击声、狗叫等。七种异常声音的长度从约0.4s~2s不等,采样率为44.1KHz,详细情况见表1。
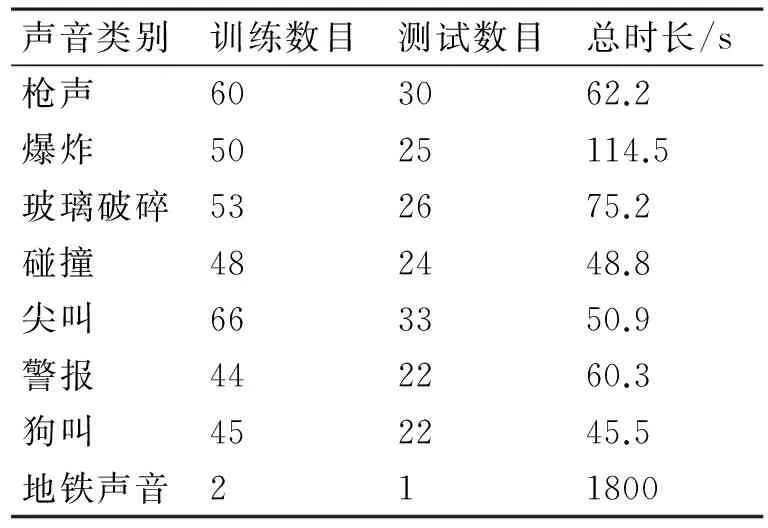
表1 各类声音资源情况
背景声音采用的是录取的北京地铁北土城站大厅的声音,总时长为30min。背景声音主要包括人说话的声音,脚步声,拉动行李箱的声音,大厅中电视机的声音,地铁经过时发出的声音以及电视机的声音等等。
为了测试基于EEMD的特征的效果,对每个异常声音按式(8)加入地铁背景噪声以及白噪声:
snr=10*log(gain*ex/en)
(8)
其中ex指异常声音的平均能量,en是环境声音的平均能量,event指异常声音事件,ambinece指公背景噪声。地铁声音录取自北京地铁北土城站,背景声音包括乘客的脚步声,说话声,大厅中的广播声,大厅电视的声音。然后测试了不同特征在不同的信噪比条件下的识别率,结果见表2。
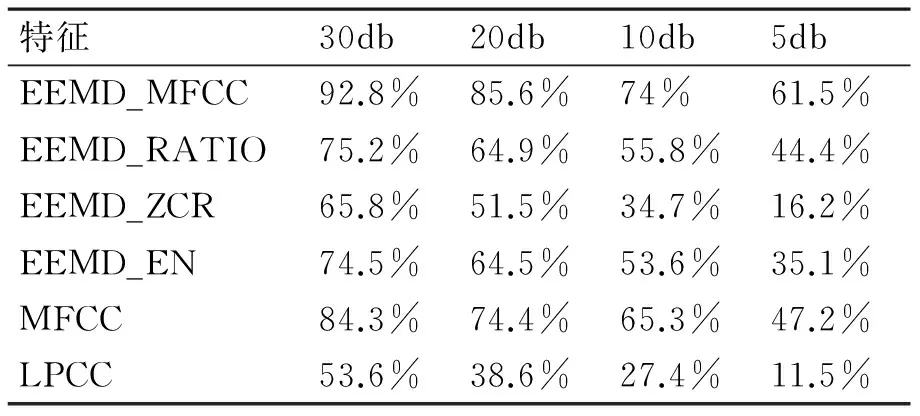
表2 各类特征在地铁背景条件下的识别率
由表1可见相比MFCC,EEMD_MFCC能有效提高异常声音的识别率,在四种信噪比条件下能够平均提高10.6%。此外EEMD_RATIO,EEMD_EN也具有一定的识别能力。为了能够进一步提高最终的识别效果,测试了不同的特征组合的识别率,结果见表3。
由表3可见采取EEMD_MFCC+EEMD_RATIO作为特征组合能够获取较好的识别率。我们接着检测了以EEMD_MFCC+EEMD_RATIO作为特征时各类异常声音的识别情况,表4给出了各类声音识别的混淆矩阵。
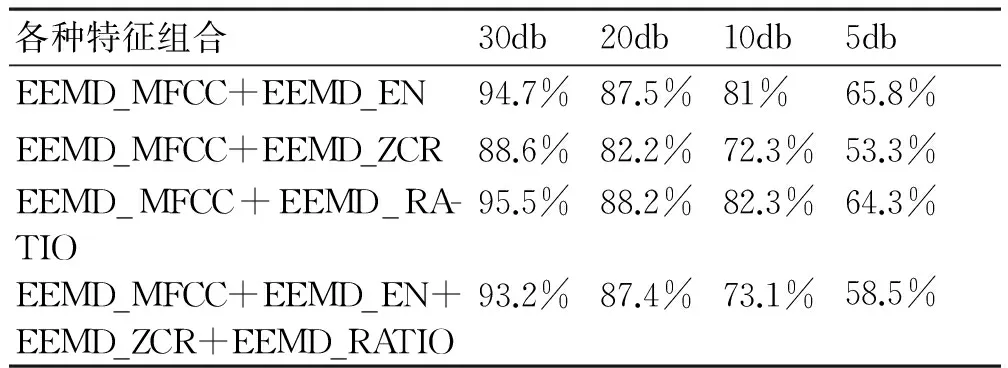
表3 基于EEMD的各类特征组合识别率

表4 30db信噪比条件下异常声音识别混淆矩阵
5 结语
针对传统声学特征MFCC作为特征识别异常声音效果不够好的问题,本文基于异常声音具有非线性和非平稳性的特点,提出基于EEMD的异常声音特征提取方法。对信号提取IMF分量,然后对每一层IMF分量提取能量,能量比,MFCC特征组合成最终的特征,实验结果证明相比于MFCC,基于EEMD的特征在地铁公共环境下,能够有效提高识别率。由文中所述可知,不同层的IMF代表不同的振动模式,如果能够选取最能代表每一类声音的IMF来提取特征将能更好的描述信号的特点,从而极大提高识别率,这将是下一阶段的研究重点。
[1] L. Lu, F. Ge, Q. Zhao, et al. A SVM-Based Audio Event Detection System[C]//Electrical and Control Engineering (ICECE), 2010 International Conference on, Wuhan,2010:292-295.
[2] Aurino F, Folla M, Gargiulo F, et al. One-Class SVM Based Approach for Detecting Anomalous Audio Events[C]//International Conference on Intelligent NETWORKING and Collaborative Systems. IEEE,2014:145-151.
[3] Lee Y, Han D K, Ko H. Acoustic Signal Based Abnormal Event Detection in Indoor Environment using Multiclass Adaboost[J]. IEEE Transactions on Consumer Electronics,2013,59(3):615-622.
[4] Peng L, Yang D, Chen X. Multi frame size feature extraction for acoustic event detection[C]//Asia-Pacific Signal and Information Processing Association, 2014 Summit and Conference. IEEE,2014.
[5] Lin C H, Tu M C, Chin Y H, et al. SVM-Based Sound Classification Based on MPEG-7 Audio LLDs and Related Enhanced Features[J]. Communications in Computer and Information Science,2012,310:536-543.
[6] C. V. Cotton, D. P. W. Ellis. Spectral vs. spectro-temporal features for acoustic event detection[C]//Applications of Signal Processing to Audio and Acoustics (WASPAA), 2011 IEEE Workshop on, New Paltz, NY,2011:69-72.
[7] B. Ghoraani, S. Krishnan. Time-Frequency Matrix Feature Extraction and Classification of Environmental Audio Signals[J]. IEEE Transactions on Audio, Speech, and Language Processing,2011,19(7):2197-2209.
[8] Li M, Li Y. Ecological environmental sounds classification based on genetic algorithm and matching pursuit sparse decomposition[C]//Image and Signal Processing (CISP), 2012 5th International Congress on. IEEE,2012:1439-1443.
[9] Chu S, Narayanan S, Kuo C C J. Environmental Sound Recognition With Time-Frequency Audio Features[J]. IEEE Transactions on Audio Speech & Language Processing,2009,17(6):1142-1158.
[10] F. Aurino, M. Folla, F. Gargiulo, et al. One-Class SVM Based Approach for Detecting Anomalous Audio Events[C]//Intelligent Networking and Collaborative Systems (INCoS), 2014 International Conference on, Salerno,2014:145-151.
Abnormal Sound Feature Extraction Based on EEMD
CHEN ZhiquanYANG JunQIAO Shushan
(Institute of Micro-electronics, University of Chinese Academy of Sciences, Beijing100029)
Aiming at solving the low recognition rate of abnormal sound recognition caused by using MFCC, LPCC as feature, the project proposes a feature extraction method for abnormal sound based on Ensemble Empirical Mode Decomposition (EEMD) combining the high nonlinearity and non-stationary. First the abnormal sounds are segmented into frames and every frame of the sound is decomposed into IMFS, then features including energy, cross rate, energy ratio, and MFCC are extracted for every IMF. Finally the feature vectors are segmented and the means of every segment are computed as the final features. Using these features as input, then the project adopts SVM as classifier to recognize seven kinds of abnormal sounds, and the recognition rate is tested in railway background. Experiment results show that these features can improve the recognition rate comparing with MFCC.
abnormal sound recognition, empirical mode decomposition, feature extraction, support vector machine
2016年4月11日,
2016年5月21日
中科院战略性先导科技专项:极低功耗智能感知技术(编号:XDA06020401)资助。
陈志全,男,硕士研究生,研究方向:信号处理,模式识别。杨骏,男,研究员,研究方向:人工智能,语音信号处理,计算机视觉,应用系统架构。乔树山,男,副研究员,研究方向:信号处理,数字集成电路设计。
TP311
10.3969/j.issn.1672-9722.2016.10.002
