机器学习在大数据中的常用方法及其重要性
2016-11-04祁威
机器学习在大数据中的常用方法及其重要性
伴随着大数据时代的来到,大数据吸引了众多学术界和产业界人士的关注。大数据的特征被归纳为5V:Volume、Velocity、Variety、Value、veracity。大数据在各种行业和领域已经得到了广泛应用。从数据仓库到BI和data mining;从自动驾驶到智能搜索;包括云计算、并行计算等在内的技术,极大的提高了人们的生产生活水平,正在改变着人们的生产生活方式,如何从大数据中挖掘出人们需要的知识,需要充分利用机器学习原理和方法。
我们现在处于一个信息爆炸的时代,每天都会产生大量的数据,包括商业数据、天气数据、人文数据等。看似杂乱无章的数据中,隐藏着对人类极为重要,有价值的知识。小到一个公司企业能够从大量的、数据类型多样的、有价值的数据中挖掘出对企业的发展有价值的信息,就能在商业风云中立于不败之地;大到一个民族,一个国家,利用机器学习的算法和原理,从大数据中挖掘出各类信息,就可以预测和预防灾害的发生,提高人民的生产生活水平。
信息时代,大数据已经同人们密切相关,国家提出大数据发展战略,利用“大数据”和“互联网+”思维推动国家经济文化的发展,鼓励大众创新,万众创业,使科技的发展与创新惠及家家户户。面对大数据时代的挑战,我们需要构建机器学习原理和方法,让大数据真正发挥出它的价值与力量。
机器学习关键算法及其重要性
人工神经网络及其重要性
人工神经网络是对生物神经网络的模拟。生物的脑是由大量的神经元组成的,人类的大脑有10∧10~10∧11个神经元,每个神经元又与大量的神经元互连,构成了一个极其复杂的神经网络。其中每个神经元由胞体、树突和轴突构成。神经元的轴突与另外神经元的树突相连接,构成突触,各类神经信号在神经元的突触处理后,如果信号强度大于某个阈值,则该信号继续向前传播。根据生物神经元,人类建立了人工神经元网络模型:
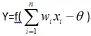
人工神经网络模型是机器学习的一种算法。人工神经网络模型包含BP人工神经网络、过程神经网络、径向基神经网络、深度学习网络等。
深度神经网络是人工神经网络中重要的一个算法,尤其是Google利用深度神经网络编写的AlphaGo战胜李世石后,深度神经网络进一步引起了人类的关注。IBM、谷歌、百度等利用深度学习网络进行语音识别、机器翻译,语义挖掘系统的设计,也有了很大的进展。深度神经网络又包括几个重要的算法,包括卷积神经网络、受限波尔茨曼机等。
深度神经网络就是通过增加隐含层神经元的个数来提高人工神经网络的性能的。深度神经网络每一层都会设置一个权值和阈值,通过对深度神经网络的训练,在误差允许的范围内,最终确定该深度神经网络的权值和阈值,从可以利用该深度神经网络进行信号的识别,预测等功能。深度神经网络的每一层是一个特征提取的过程,一层输出作为下一层的输入,实现输入信息的分层特征提取。以图像识别为例,第一层提取的特征可能是点,而第二层提取的可能就是图像线的特征,第三层可能就是面,最终表示层一幅完整的图像,通过特征的组合判断图像是哪一种物体。
SVM算法在大数据中的应用及其重要性
支持向量机(SVM)是机器学习算法中最具有健壮性和准确性的算法之一。对于线性可分的问题,SVM是要找到间隔最大的超平面将两种不同的样本分开,间隔最大的超平面具有最好的泛化能力。
用变量a表示权重向量,变量b表示最优超平面偏移,那么超平面定义为:
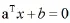
x样本到最优超平面的距离为:
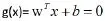
r=g(x)/(||a||)为超平面确定的判别函数。SVM就是要可以最大化两个类别之间间距的参数a和b的值。然后通过求解对偶问题得到变量a和b的值,进而可以在非线性可分的问题中引入核函数。
现实世界中的许多问题都是线性不可分的,对偶问题目标函数是无限的,那么最优化问题是不可解的。对于线性不可分问题的解决方法有两个:一种是软间隔优化,另一种都是利用核技巧将线性不可分问题转变为线性可分问题。核技巧是找到一个核函数,将低维空间中的数据映射到高维空间中,使数据在高维空间中是线性可分的。软间隔优化是放松了限制输入空间,允许存在某些错误。但是当遇到某些极度线性不可分问题或者分类的错误过多时,软间隔优化是不可行的。核技巧在遇到复杂的实际问题时,也不总能保证问题是线性可分的。所以在实际应用中我们会综合使用两种方法,更有效地解决线性不可分问题。
支持向量机在分类、聚类、模式识别、人脸识别、机器的故障检测、时间序列预测、生物工程、数据挖掘、手写体识别、函数拟合等领域都有广泛的应用。
GMM-HMM算法在大数据中的应用及其重要性
GMM-HMM是一个用于语音识别的模型。Hidden Markov Model是一个有隐节点和可见节点的马尔科夫过程。其中隐节点代表状态,可见节点代表能够听到的语音或者看到的时序信号。我们需要首先指定一个HMM模型,在训练时,给出n个训练样本,并且用MLE算法估计如下参数:状态初始概率,状态转移概率和输出概率。
使用HMM需要解决Likelihood、Decoding、Training三个问题。其中Likelihood表示HMM产生一个序列x的概率。Decoding表示给定一个序列x,从中找出最有可能从属的HMM模型的状态序列。Training表示给定一个序列,训练HMM参数。
GMM-高斯混合模型,可以简单理解为几个高斯的叠加。每个状态都有一个GMM,而每个GMM都有一些参数,我们要通过训练,得到这些概率参数,训练出这些参数,在给定一个序列时,就可以识别出状态转移的概率。
语音识别的过程我们可以概括为:首先将一段音频分割成多个单词,针对每个单词提取MFCC特征序列,然后将该序列输入每一个已经训练好的HMM模型中,最后利用每一个单词的状态转移概率算出每一个state序列生成该单词的概率,取最大概率,为我们选出需要的词语。
机器学习成为大数据的基石
我们现在处在大数据的时代,机器学习可以被最大化的利用起来。比如随着人工智能、移动穿戴等的发展,大量的数据随之产生,不仅数据的数据越来越多,数据的种类也越来越丰富,比如数据即包括文字,图片,也包括音频,视频等非结构化的数据,这使得机器学习可利用的数据越来越多。同时分布式技术的发展,也使机器学习的运行速度越来越快,可以更方便人们的使用,处在大数据的时代背景下,机器学习也正在发挥出它的优势。
大数据的本质是要挖掘出数据的价值,机器学习是挖掘数据价值的关键。机器学习对于大数据是不可缺少的,反过来,大量的数据同时增加了机器学习算法的准确度,因此机器学习的发展兴亡也离不开大数据。同时在机器学习算法的速度需求方面,对于并行计算和内存计算的需求也越来越高。因此大数据与机器学习是相互依存,相辅相成的关系。
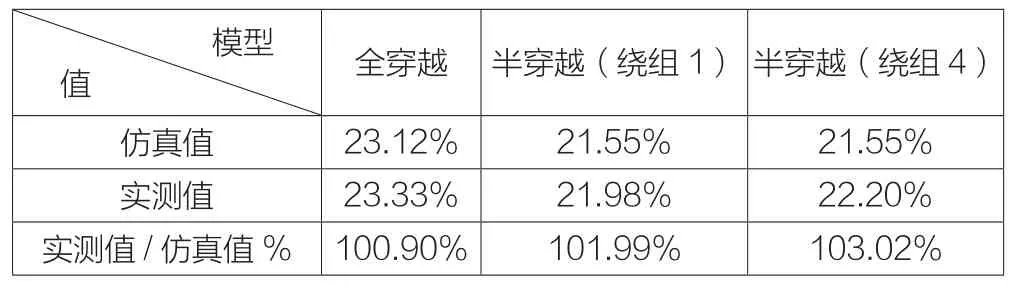
表1
实测半穿越阻抗>21%,满足客户要求。
通过结果对比看出,仿真的阻抗与实测的阻抗基本完全一致,说明仿真计算的结果非常精确。
解耦率
通过变压器容量和绕组连接方法计算得出,高压绕组2(HV shang)和绕组3(HV xia的额定电流为5.714A,低压绕组1(LV shang)额定电流为729.28A。
半穿越仿真时,得出绕组2(HV shang)和绕组3(HV xia)中的电流分配如图5。
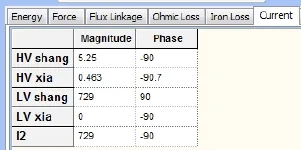
图5
H V上分配的电流比例为K=5.25/5.714*100%=91.88%,解耦率>90%,满足客户要求,且与试验测得的电流分配基本一致。
结语
本文通过MagNet软件仿真轴向双分裂变压器的全穿越、半穿越阻抗,并获得了半穿越运行时并联的高压绕组中的电流分配,从而算出解耦率。如果采用传统电磁计算的方法,不论是半穿越阻抗,还是解耦率都很难算准。本文为开发及设计特殊结构变压器,提出了一种新的、行之有效的方法。
10.3969/j.issn.1001- 8972.2016.15.019
