基于迭代预测降低巧合正确性测试用例影响的软件错误定位方法
2016-11-02苏小红王甜甜马培军
赵 群,苏小红,王甜甜,马培军
(哈尔滨工业大学计算机科学与技术学院,哈尔滨 150001)
基于迭代预测降低巧合正确性测试用例影响的软件错误定位方法
赵 群,苏小红,王甜甜,马培军
(哈尔滨工业大学计算机科学与技术学院,哈尔滨150001)
巧合正确性测试用例是指某个测试用例虽然在执行程序时覆盖了错误的代码行,但是其测试结果依然是正确的。在测试用例集中,巧合正确性测试用例是普遍存在的。巧合正确性测试用例对基于程序谱的软件错误定位方法的错误定位精度产生很大的影响。为了避免这一影响,本文提出一种基于迭代预测降低巧合正确性测试用例影响的方法。该方法的基本思想是通过迭代的方法,预测巧合正确性测试用例的数目N,再对候选测试用例的巧合正确性可疑值进行排序,去掉可疑值较高的前N个巧合正确性测试用例,利用新的测试集进行错误定位,直到找到错误语句,或者候选的巧合正确性测试用例的个数小于迭代预测值N为止。使用Siemens Suite测试用例集对系统进行了测试,测试结果表明该方法能够有效提高基于程序谱的软件错误定位方法的错误定位精度。
错误定位;巧合正确性;测试用例;迭代;预测
0 引 言
目前,自动化软件错误定位技术有多种[1],但是,由于巧合正确性测试用例的存在,使得这类错误定位方法所计算出来的错误语句的可疑值偏低,影响软件错误定位方法的精确性。本文首先通过举例,解释巧合正确性测试用例的含义,然后具体介绍方法是如何实现的,主要从方法提出的动机,方法的基本框架,预测当前测试用例集中巧合正确性测试用例个数和对巧合正确性测试用例进行排序4个方面展开,最后通过实验测试方法的有效性,得出结论。
1 巧合正确性测试用例的特征
1.1 巧合正确性测试用例的特征
巧合正确性测试用例是指某个测试用例虽然在执行程序时覆盖了错误的代码行,但是其测试结果依然是正确的。编程人员在源代码开发过程中不可避免地会引入程序错误,当测试人员进行测试的时候,对可执行程序执行测试用例,可能发生如下情况:Tests运行到了错误的代码行,使得错误的代码被感染(infection),错误的程序状态产生了,而后感染又被传播(infection propagation),最终导致软件失效(failure)[2]。当对出错的程序进行测试的时候,只有同时具备了下述3个条件[2],程序员才能够发现错误:
1)这次测试运行到了错误代码行,也就是说,缺陷被激活;
2)错误的程序状态被传播,影响到后续程序的运行状态;
3)错误状态的传播影响到了最终的输出结果。
由此可见,有2种特殊的情况出现:
1)测试运行到了错误的代码行,但是缺陷并没有被传播,也没有影响到后续程序的运行状态,即仅满足了上述条件1);
2)测试运行到了错误的代码行,同时,缺陷被传播了,但是,没有影响到最终的输出结果,即满足了条件1)和条件2),但是,没有满足条件3)。
当上述2种情况发生时,并不会影响程序的输出结果,这便是巧合正确性测试用例。
1.2巧合正确性测试用例举例
程序中使用到的一些运算符,例如算术运算符+、-、∗、/、%,当程序员在设计测试用例的时候,可能会产生巧合正确性测试用例。这种情况下产生的巧合正确性测试用例的伪代码示例如下:

针对上面这个第4行存在错误的程序,进行测试,当测试用例选择a=3,b=0的时候,并且当if语句条件为计算sum的时候,执行该测试用例,其执行轨迹通过了第5行的出错语句,这时的result=a-b=3-0=3,此时其与正确的结果result=a+b=3+0=3是完全一样的。显然,这个bug并不会影响输出的结果。即测试运行到了错误的代码行,但是没有影响输出结果,依然为成功的测试用例,这个测试用例就是本文所说的巧合正确性测试用例。
2 基于迭代预测降低巧合正确性影响的错误定位方法
2.1方法的基本思想
本文的主要思想就是预测当前巧合正确性测试用例个数和使用TOP(k)加权排名方法对测试用例排名。如图1所示,本文在执行过程中,当获得可疑度排名序列以后,预测当前可能的巧合正确性测试用例(Coincidental Correctness,简称为CC)个数,再利用TOP(k)加权排名方法,对经过筛选的测试用例排序,删除排名较高的前N个测试用例,用新的测试集继续迭代,直到找到错误语句,或者求得的候选测试用例的个数小于迭代预测出的N值为止。
2.2预测当前测试用例集中巧合正确性测试用例个数
本文在首次获得待测程序的可疑值排名序列后,需要程序员来人工检测排在第一位(包括并列第一的)的程序语句,假设为E,并且判断某条(或多条)是否是错误的语句,如果是,则迭代过程停止,输出错误语句;如果不是,则继续迭代预测。在每次迭代预测过程中,都要预测当前测试用例集中含有的巧合正确性测试用例的个数N。下面就详细解释N如何得到的。
目前的自动化软件错误定位技术通常假设待测程序只含有一个错误,如果程序员在检测集合E的时候,发现E并不包含错误语句的时候,在最好的情况下,程序语句可疑值排名在次高位置的语句集合E’将包含错误语句,并且由于假设待测程序中仅包含一个错误,即可假设在最好的情况下,覆盖了排名次高位的语句集合E’的那些成功的测试用例包含了当前所有巧合正确性测试用例,记为N。
2.3对巧合正确性测试用例进行排序
为了进一步预测到底哪些测试用例属于巧合正确性测试用例,本文采用TOP(k)加权排名方法,预测一个成功的测试用例是巧合正确性测试用例的可能性大小,这个方法最终会得到一个测试用例可疑值降序排名列表,列表中随着排名的降低,使巧合正确性测试用例的可能性也随之降低,反之则升高。该方法目的是去掉列表中前N个测试用例,用剩下的测试用例继续迭代。
这个TOP(k)加权排名方法第一步是要获得与巧合性正确测试用例有关系的程序语句集合CCE(Coincidental Correctness Element),然后认为覆盖了一条或者多条这样的语句的测试用例集合为CCT(Coincidental Correctness Test),集合CCT里面的测试用例都有可能是巧合正确性测试用例,再对这部分测试用例进行加权排名,最后得到巧合正确性测试用例的可能性排名。
2.3.1求解CCE[3]
CCE(Coincidental Correctness Element)指的是满足指定条件的程序语句的集合,使得集合中的程序语句与巧合正确性测试用例的关系相对较大,把集合中的一条语句称为CCE。
可以成为CCE中的一条程序语句,必须满足以下两个条件:
1)fT(cce)=1.0——被所有错误的测试用例所覆盖;2)0<PT(cce)<θ——被少部分正确的测试用例所覆盖;
其中,fT(cce)是指被失败的测试用例所覆盖的概率;PT(cce)是指被成功的测试用例所覆盖的概率。
这里θ的取值范围需要说明一下,因为已有文献表明,目前的测试用例集中大部分含有60%以下的巧合正确性测试用例,还有一部分测试用例集是含有60%~90%的巧合正确性测试用例,如果θ的值取到小于60%的话,那么很可能有一部分cce就找不到了,被遗漏下了,带来实验误差,因此,本文将θ的取值限定在(0.6,0.9)之间。
2.3.2求解CCT[3]
TOP(k)加权排名方法的目的就在于获得CCT这个集合,为集合中的测试用例赋权值排名。CCT指的是与巧合正确性测试用例关系密切的测试用例的集合。把覆盖一条上述方法求得的cce或者多条cce的测试用例叫做cct,cct的集合就是CCT,并且为其赋权值,求出巧合正确性测试用例可能性大小的排序序列。
2.3.3CCT排名
采用TOP(k)加权排名方法对求得的CCT中的测试用例赋以一定的权值。研究表明,如果一个成功的测试用例和一个失败的测试用例的语句覆盖信息越相似,就越有可能是巧合正确性测试用例。基于这个理论,通过计算成功测试用例和失败测试用例覆盖信息的相似程度,来评价一个成功的测试用例为巧合正确性测试用例的可能性,相似程度越高,则巧合正确性的可能性越高,反之则越低。相似度的计算方法如下。
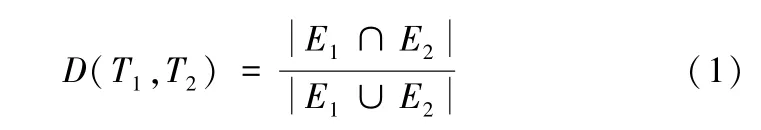
式中,Ei(i=1,2)表示测试用例Ti(i=1,2)所执行的程序语句的集合。用2个集合的交集中元素的个数除以2个集合并集中元素的个数就得到了任意2个测试用例的相似度。
利用上述公式可以求得测试用例集中任意一个成功的测试用例与任意一个失败的测试用例的相似程度,那么计算一个成功的测试用例与整个测试集中所有失败测试用例的评价相似度,计算方法如下。
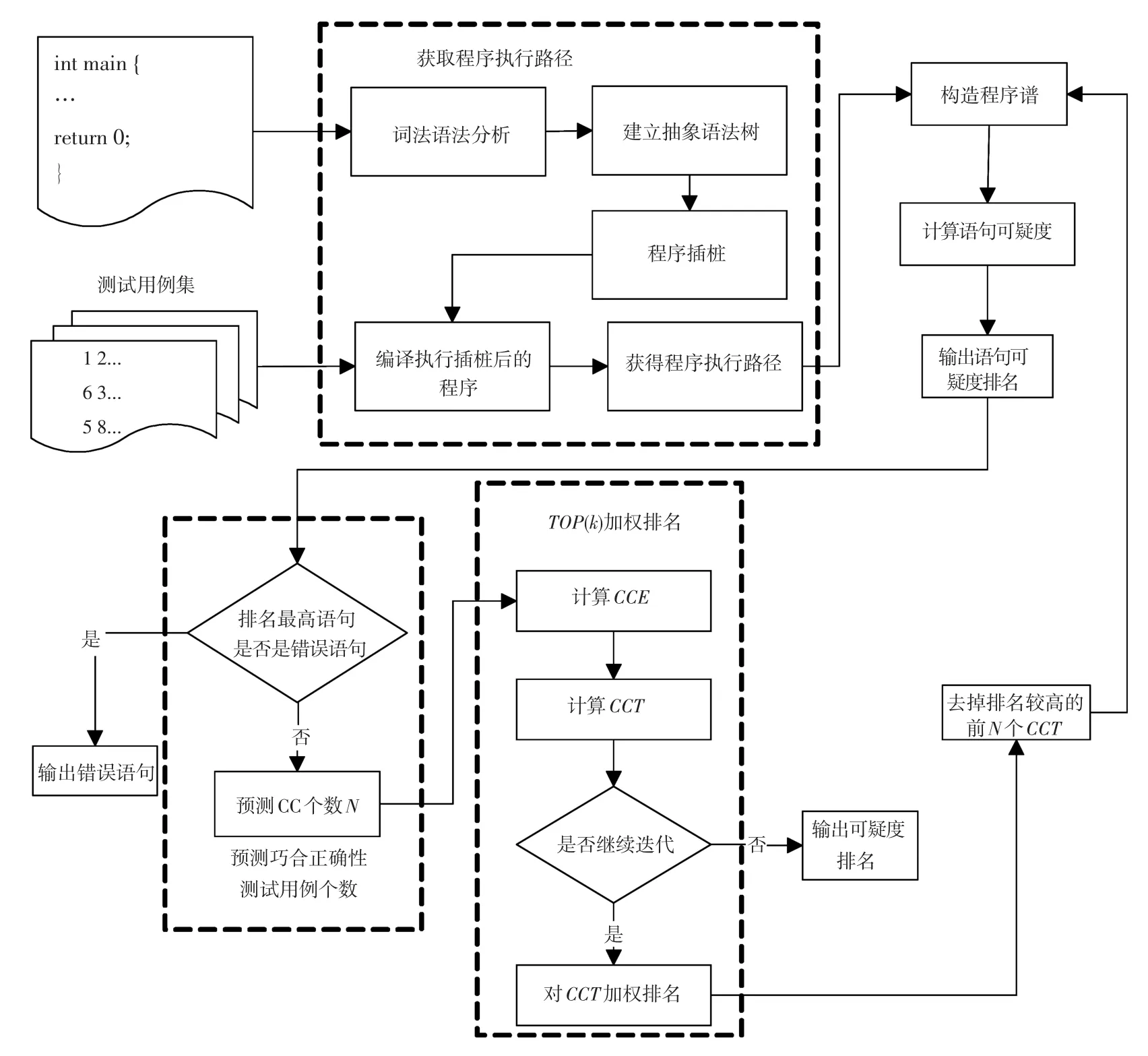
图1 方法的总体框架图Fig.1 Overall frame of the algorithm

式中,Prox(p)代表该测试用例集中每一个成功的测试用例p和其他所有的失败的测试用例F之间的相似度。同理,Prox(p)结果越大,这个测试用例就越可能是巧合正确性测试用例。
在计算得到相似度以后,可用如下公式(3)计算每个CCT的权值。计算公式为:
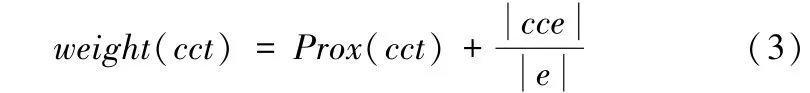
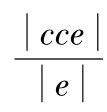
2.4实验结果
为了验证本文方法的有效性,现采用Siemens Suite测试集进行实验,实验对照组采用经典的SBFL方法Tarantula和 Ochiai方法,分别在不同的θ取值下完成实验,评价指标采用发现错误时候,比经典SBFL方法需要检查代码减少量百分比。实验结果如表1所示。

表1 不同θ取值下发现错误时平均检查代码减少量的百分比结果Tab.1 Code reduction percentage when finding error under different value of θ
从表1中可以看出当θ分别取0.7、0.8和0.9时,发现错误情况下,基于迭代预测降低巧合正确性测试用例影响的错误定位方法比Tarantula方法平均少检查的代码比例分别为2.1%、2.7%和3%,而比Ochiai方法平均少检查的代码比例分别为2.3%、3.1%和3.5%。还可以看出,随着θ取值的增大,平均检查的代码量在逐渐减少。分析原因,这是因为,当θ取值逐渐减小,而当前测试集中实际含有的巧合正确性测试用例又相当多的时候,此时根据2.3中介绍的理论,就会有一部分CCE没有被挑选出来,而与此同时,如果错误的语句正好又被遗漏了,相应计算的CCT实际上根本没有覆盖错误语句,这样就会在客观上增加巧合正确性测试用例识别的误报率,因此使得θ逐渐减小的时候,代码检测减少量也随之变小。
通过实验得出,本文的方法可以在降低巧合正确性测试用例对基于程序谱的软件错误定位方法精度的影响的基础上,进一步提高错误定位精度。
3 结束语
为了降低巧合正确性测试用例对基于程序谱的软件错误定位方法精度的影响,本文应用迭代预测和TOP(k)加权排名的思想,在每次迭代过程中预测出当前测试集中巧合正确性测试用例的个数N,再通过TOP(k)加权排名方法,对候选测试用例集进行排序,去除排名较高的前N个巧合正确性测试用例。本文的创新点主要有如下2点:
1)使用TOP(k)加权排名方法时,对测试集中的测试用例进行筛选,选出了与巧合正确性测试用例关系密切的测试集CCT,再对候选CCT集合进行排序;
2)TOP(k)加权排名方法中,对CCT进行排序时采用相似度作为权值计算公式进行排序。
但是,本文在为CCT排序时所使用的权值计算公式,只考虑到了2个影响因子,在以后的工作中会尝试将更多的影响因子考虑进来;在求解CCE的过程中使用的θ值都是固定的,后续研究将尝试每次迭代的过程都选用不同的θ值,进一步提高错误定位的精度。
[1]梅宏,王千祥,张路,等.软件分析技术进展[J].计算机学报,2009,32(9):1697-1710.
[2]LATTNER C,ADVE V.LLVM:A compilation framework for lifelong program analysis&transformation[C]//Code Generation and Optimization,2004,CGO 2004.Interational Symposium on.IEEE. Palo Alto,California:IEEE,2004:75-86.
[3]CHANG C H,PAIGE R.From regular expressions to dfa's using compressed nfa′s[C]//Combinatorial Pattern Matching.Berlin Heidelberg:Springer,1992:90-110.
[4]RABIN M O,SCOTT D.Finite automata and their decision problems[J].IBM journal of research and development,1959,3(2):114-125.
[5]DeRemer F L.Practical translators for LR(k)languages[D]. Massachusetts:Massachusetts Institute of Technology,1969.
A method based on iterative prediction to lower the effection from coincidental correctness
ZHAO Qun,SU Xiaohong,WANG Tiantian,MA Peijun
(School of Computer Science and Technology,Harbin Institute of Technology,Harbin 150001,China)
There are lots of coincidental correctness in tests suit.As a result of the existence of coincidental correctness,the software error locating method based on the application spectrum of precision could be affected by a lot of coincidental correctness test cases. Therefore,this paper proposes a method based iterative prediction to improve the error code lines of dubious value.The main idea of the method is by iterative method,prediction accuracy of coincidence N is the number of test cases,and then the correctness suspicious coincidence that test cases to the candidate value for sorting,get rid of dubious value higher N coincidence correctness before test cases,until you find false statements,or seeking candidates for the number of test cases is less than the number of iteration to predict N.The system is tested by using Siemens Suite,and the results show that the method could effectively improve the software error locating precision based on the application spectrum.
error locating;coincidental correctness;test cases;iteration;prediction
TP311
A
2095-2163(2016)03-0119-04
2015-06-23
国家自然科学基金(61173021)。
赵 群(1989-),女,硕士研究生,主要研究方向:软件工程、软件错误定位;苏小红(1966-),女,博士后,教授,博士生导师,主要研究方向:软件工程、智能信息处理与信息融合、图像处理等;王甜甜(1980-),女,博士,副教授,主要研究方向:程序分析、计算机辅助教学;马培军(1963-),男,博士,教授,博士生导师,主要研究方向:软件工程、智能信息处理与信息融合。
